
构建推荐系统机器学习的简单指南 [2022]
已发表: 2021-03-11当今的大多数互联网企业都倾向于提供个性化的用户体验。 机器学习中的推荐系统是一种特殊类型的基于 Web 的个性化应用程序,它为用户提供有关他们可能感兴趣的内容的个性化推荐。 推荐系统也称为推荐系统。
目录
什么是推荐系统?
机器学习中的推荐系统可以预测用户对一堆事物的需求,并推荐最需要的事物。
推荐系统是应用于企业的机器学习技术最广泛的应用之一。
我们可以在零售、视频点播或音乐流媒体中找到大规模的推荐系统。
推荐系统试图将独特的数据揭示模型的一部分自动化,其中个人试图发现具有相似品味的其他人,然后要求他们推荐新项目。
加入来自世界顶级大学的在线机器学习课程——硕士、高管研究生课程和 ML 和 AI 高级证书课程,以加快您的职业生涯。

推荐系统的类型
- 根据您的兴趣进行个性化推荐。
- 非个性化 - 其他客户现在正在查看的内容。
推荐系统的需求是什么?
我们在机器学习中需要推荐系统的关键原因之一是,由于互联网,人们可以选择购买的选择太多。
过去,人们过去常常在实体店购物,那里的商品供应有限。
例如,放置在视频租赁店的电影数量取决于商店的规模。 网络允许人们访问大量的在线资源。 Netflix 拥有大量电影。 随着可用信息量的增加,出现了一个新问题,人们发现很难从各种各样的选项中进行选择。 因此,推荐系统应运而生。
推荐系统在哪里使用?
- 大型电子商务网站使用此工具来推荐消费者可能希望购买的商品。
- 网络个性化。
推荐系统如何工作?
- 我们可以向客户推荐在其他客户中普遍受欢迎的东西。
- 我们可以根据客户的产品选择将客户分成几组,并建议他们可能购买的东西。
上述两种技术都有其缺点。 在第一种情况下,最流行、最主流的东西对每个客户都是一样的。 因此,每个人都可能会收到类似的建议。 而在第二个中,随着客户数量的增加,作为建议突出显示的事物的数量也会增加。 因此,很难将所有客户端分组到不同的部分。
现在,我们将看看推荐系统是如何工作的。
数据采集
这是创建推荐系统的第一步,也是最重要的一步。 信息经常通过两种方法收集:显式和隐式。
显性信息将是故意提供的数据,即客户做出的贡献,如电影评论。 隐含信息是指未特意提供但从可访问的信息流中收集的数据,例如点击、搜索历史、请求历史等。
资料库
信息量表明模型建议的真实性。 信息类型在从大量人群中挑选数据方面具有重要作用。 该容量可以包括一个标准的 SQL 和 NoSQL 信息库或一种形式的文章存储。
数据过滤
在收集和存储之后,需要对这些数据进行过滤以提取信息以做出最终推荐。 各种算法使过滤过程更容易。
推荐系统算法
软件系统利用项目/用户的历史迭代和属性向用户提供建议。
构建推荐系统有两种方法。
1. 基于内容的推荐
- 使用项目/用户的属性
- 推荐与用户过去喜欢的项目相似的项目
2.协同过滤
- 推荐类似用户喜欢的项目
- 探索多样化的内容
基于内容的推荐
监督机器学习诱导分类器区分有趣和不感兴趣的用户项目。

推荐系统的目标是预测用户未评级事物的分数。 内容过滤背后的基本思想是,每件事都有一些亮点 x。
例如,电影《最后的爱》是一部爱情片,精彩片段 x1 得分高,而 x2 得分低。
(电影收视数据)
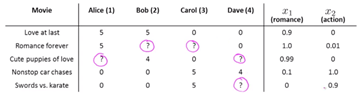
资源
每个人都有一个参数 θ,它告诉他们有多喜欢爱情片,有多喜欢动作片。
如果 θ = [1, 0.1],个人喜欢爱情片而不是动作片。
我们可以通过线性回归为每个人找到最佳 θ。
(符号)
r(i,j):如果用户 j 对电影 i 评分,则为 1(否则为 0)
y(i,j):用户 j 对电影 i 的评分(如果已定义)
θ(j):用户向量参数
x(i):电影 i 特征向量
预测评分[用户 j,电影 i]:(θ(j))ᵀx(i)
m(j): # 用户 j 率的电影数量
nᵤ:用户数
n:电影的特征数
阅读:机器学习项目的想法和主题
协同过滤
内容过滤的缺点是它需要所有内容的辅助数据。
例如,爱情和动作等分类是电影的辅助数据。 找到观看电影并为每部电影添加辅助数据的人的成本很高。
基本假设
- 兴趣相近的用户有着共同的偏好。
- 有足够多的用户偏好可用。
主要方法
- 基于用户
- 基于项目
怎么可能列出电影的所有特征? 如果想添加新功能怎么办? 我们是否应该将新功能添加到所有电影中?
协同过滤解决了这个问题。
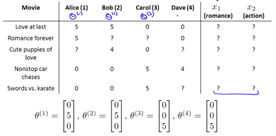
(预测电影的特点)来源
机器学习中推荐系统的问题与维护
问题
- 不确定的用户输入结构
- 寻找用户参与批评研究
- 弱计算
- 结果不佳
- 信息不畅
- 缺乏信息
- 隐私控制(可能不会与收据明确结合)
维护
- 昂贵
- 信息过时了
- 信息质量(巨大,圈层空间发展)
机器学习中的推荐系统植根于各个研究领域,例如信息检索、文本分类,以及应用来自不同领域的不同方法,例如机器学习、数据挖掘和基于知识的系统。
推荐系统的未来
- 提取物通过检查带回来的东西来理解负面评价。
- 如何将当地与提案结合起来。
- 稍后将使用推荐系统来预测对商品的兴趣,从而使之前的通信能够返回到商店网络。
使用 upGrad 提升您在机器学习领域的职业生涯
如果您有兴趣了解有关机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和 AI 执行 PG 计划,该计划专为工作专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业、IIIT -B 校友身份,5 个以上实用的实践顶点项目和顶级公司的工作协助。
你在哪里可以找到现实生活中的推荐系统?
推荐系统或推荐系统可以被概念化为采用机器学习功能的数据过滤应用程序。 如今,推荐系统被广泛用于向特定用户组或个人消费者发送有关最相关产品或服务的推荐。 它搜索隐藏在客户行为数据中的特定模式,显式或隐式收集信息,然后相应地生成建议。 使用推荐系统的一些最著名的品牌是谷歌、Netflix、Facebook 和亚马逊,以及其他全球组织。 事实上,研究表明,亚马逊 35% 的整体购买是产品推荐的结果。
今天有哪些公司在使用人工智能?
从增强客户体验到提高跨行业的业务生产力和提高运营效率,组织现在都在大力投资人工智能。 事实上,无论有意或无意,我们所有人在日常生活中也经常接触到人工智能。 除了特斯拉、苹果和谷歌,今天其他一些成功使用人工智能的知名组织包括 Twitter、优步、亚马逊、YouTube 等。Twitter 自 2017 年以来一直在使用人工智能和自然语言处理,而 Netflix 则专注于整个围绕数据和人工智能进行操作。
当今印度最热门的 AI 工作是什么?
随着人工智能领域的大规模发展,市场对人工智能专业人士的需求空前高涨。 因此,对于那些希望在该技术领域开拓一席之地的人来说,该行业看起来很有希望,并提供一系列令人兴奋的工作选择,而且薪水也很可观。 当今人工智能领域的一些顶级职位包括首席数据科学家、人工智能研究工程师、计算机科学家、机器学习工程师等职位,根据工作经验,年薪从 9.5 到 180 万印度卢比不等、技能组合和其他不同的因素。