
用户体验设计师的定量数据工具
已发表: 2022-03-10许多用户体验设计师有点害怕数据,认为它需要对统计和数学有深入的了解。 尽管这对于高级数据科学来说可能是正确的,但对于大多数 UX 设计师所需的基础研究数据分析来说却并非如此。 由于我们生活在一个日益数据驱动的世界,基本的数据素养对几乎所有专业人士都有用——不仅仅是用户体验设计师。
Google 的交互设计师 Aaron Gitlin 认为,许多设计师还不是数据驱动的:
“虽然许多企业宣传自己是数据驱动的,但大多数设计师都是由直觉、协作和定性研究方法驱动的。”
— Aaron Gitlin,“成为数据感知设计师”
通过这篇文章,我想为用户体验设计师提供知识和工具,以将数据整合到他们的日常生活中。
但首先,一些数据概念
在本文中,我将讨论结构化数据,即可以在表格中表示的数据,包括行和列。 正如 Devin Pickell(G2 Crowd 的内容营销专家,撰写有关数据和分析的文章)在他的文章“结构化与非结构化数据 - 有什么区别?”中指出的那样,非结构化数据本身就是一个主题,更难分析。 如果结构化数据可以用表格的形式表示,主要的概念是:
数据集
我们打算分析的整个数据集。 例如,这可以是 Excel 表格。 存储数据集的另一种流行格式是逗号分隔值文件 (CSV)。 CSV 文件是简单的文本文件,用于存储类似表格的信息。 每个 CSV 行对应于表格中的一行,并且每个 CSV 行都有(自然地)用逗号分隔的值,这些值对应于表格单元格。
数据点
数据集表中的单行是一个数据点。 这样,数据集就是数据点的集合。
数据变量
数据点行中的单个值表示一个数据变量——简单地说,一个表格单元格。 我们可以有两种类型的数据变量:定性变量和定量变量。 定性变量(也称为分类变量)具有一组离散的值,例如color = red/green/blue 。 定量变量具有数值,例如height = 167 。 与定性变量不同,定量变量可以取任何值。
创建我们的数据项目
现在我们知道了基础知识,是时候动手创建我们的第一个数据项目了。 该项目的范围是通过导入、处理和绘制数据的整个数据流来分析数据集。 首先,我们将选择我们的数据集,然后我们将下载并安装用于分析数据的工具。
汽车数据集
出于本文的目的,我选择了一个汽车数据集,因为它简单直观。 数据分析将简单地确认我们对汽车的了解——这很好,因为我们的重点是数据流和工具。
我们可以从免费数据集的最大来源之一 Kaggle 下载二手车数据集。 您需要先注册。
下载文件后,打开并查看。 这是一个非常大的 CSV 文件,但您应该了解要点。 此文件中的一行将如下所示:
19500,2015,2965,Miami,FL,WBA3B1G54FNT02351,BMW,3如您所见,这个数据点有几个用逗号分隔的变量。 既然我们现在有了数据集,让我们来谈谈工具。
贸易工具
我们将使用 R 语言和 RStudio 来分析数据集。 R 是一种非常流行且易于学习的语言,不仅被数据科学家使用,还被金融市场、医学和许多其他领域的人们使用。 RStudio 是开发 R 项目的环境,并且有免费版本,对于我们作为 UX 设计师的需求已经绰绰有余。
一些用户体验设计师很可能使用 Excel 来处理他们的数据工作流。 如果这意味着您,请尝试 R — 您很有可能会喜欢它,因为它易于学习,并且比 Excel 更灵活、更强大。 将 R 添加到您的工具包中会有所作为。
安装工具
首先,我们需要下载并安装 R 和 RStudio。 您应该先安装 R,然后再安装 RStudio。 R 和 RStudio 的安装过程都简单明了。
项目设置
安装完成后,创建一个项目文件夹——我称之为used-cars-prj 。 在该文件夹中,创建一个名为data的子文件夹,然后将数据集文件(从 Kaggle 下载)复制到该文件夹中,并将其重命名为used-cars.csv 。 现在回到我们的项目文件夹( used-cars-prj )并创建一个名为used-cars.r的纯文本文件。 您最终应该得到与下面的屏幕截图相同的结构。
现在我们有了文件夹结构,我们可以打开 RStudio 并创建一个新的 R 项目。 从File菜单中选择New Project...并选择第二个选项Existing Directory 。 然后选择项目目录( used-cars-prj )。 最后,按下Create Project按钮,您就完成了。 创建项目后,在 RStudio 中打开used-cars.r——这是我们将添加所有 R 代码的文件。
导入数据
我们将在used-cars.r中添加第一行,用于从used-cars.csv文件中读取数据。 请记住,CSV 文件只是用于存储数据的纯文本文件。 我们的第一行 R 代码将如下所示:
cars <- read.csv("./data/used-cars.csv", stringsAsFactors = FALSE, sep=",") 它可能看起来有点吓人,但实际上并非如此——顺便说一句,这是整篇文章中最复杂的一行。 我们这里有read.csv函数,它接受三个参数。
第一个参数是要读取的文件,在我们的例子中是used-cars.csv ,它位于数据文件夹中。 第二个参数stringsAsFactors=FALSE设置为确保“BMW”或“Audi”之类的字符串不会转换为因子(分类数据的 R 术语)——正如您所回忆的那样,定性或分类变量只能具有离散值,例如red/green/blue 。 最后,第三个参数sep=","指定用于分隔 CSV 文件中的值的分隔符类型:逗号。
读取 CSV 文件后,将数据存储到cars数据框对象中。 数据框是一种二维数据结构(如 Excel 表格),它在 R 中对操作数据非常有用。 引入线路并运行后,将为您创建一个cars数据框。 如果您查看 RStudio 的右上角象限,您会注意到cars数据框,位于Environment选项卡下的Data部分。 如果您双击汽车,将在 RStudio 的左上角打开一个新选项卡,并显示cars数据框。 如您所料,它看起来像一个 Excel 表格。
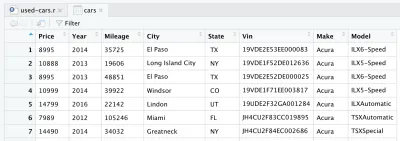
这实际上是我们从 Kaggle 下载的原始数据。 但是由于我们要进行数据分析,我们需要先处理我们的数据集。
数据处理
通过处理,我们的意思是删除、转换或添加信息到我们的数据集,以便为我们想要执行的分析做准备。 我们在数据框对象中有数据,所以现在我们需要安装dplyr库,这是一个用于处理数据的强大库。 要在我们的 R 环境中安装库,我们需要在 R 文件的顶部编写以下行。
install.packages("dplyr")然后,要将库添加到我们当前的项目中,我们将使用下一行:
library(dplyr) 一旦将dplyr库添加到我们的项目中,我们就可以开始处理数据了。 我们有一个非常大的数据集,我们只需要代表同一汽车制造商和型号的数据,以便将其与价格相关联。 我们将使用以下 R 代码仅保留有关 BMW 3 系的数据,并删除其余数据。 当然,您可以从数据集中选择任何其他制造商和型号,并期望具有相同的数据特征。
cars <- cars %>% filter(Make == "BMW", Model == "3")现在我们有了一个更易于管理的数据集,虽然仍然包含超过 11,000 个数据点,但它符合我们的预期目的:分析汽车的价格、年龄和里程分布,以及它们之间的相关性。 为此,我们只需要保留“Price”、“Year”和“Mileage”列并删除其余列 - 这是通过以下行完成的。
cars <- cars %>% select(Price, Year, Mileage)删除其他列后,我们的数据框将如下所示:
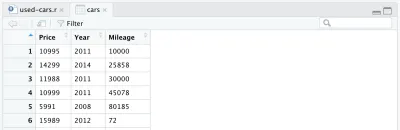
我们还想对我们的数据集进行另一项更改:将制造年份替换为汽车的年龄。 我们可以添加以下两行,第一行计算年龄,第二行更改列名。

cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)最后,我们完整处理的数据框如下所示:
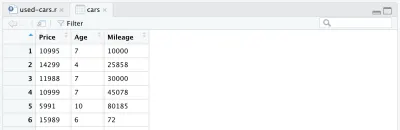
此时,我们的 R 代码将如下所示,这就是数据处理的全部内容。 我们现在可以看到 R 语言是多么简单和强大。 我们只用几行代码就非常显着地处理了初始数据集。
install.packages("dplyr") library(dplyr) cars = read.csv("./data/cars.csv", stringsAsFactors = FALSE, sep=",") cars <- cars %>% filter(Make == "BMW", Model == "3") cars <- cars %>% select(Price, Year, Mileage) cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)数据分析
我们的数据现在是正确的形状,所以我们可以去绘制一些图。 如前所述,我们将关注两个方面:单个变量的分布,以及它们之间的相关性。 可变分布有助于我们了解二手车的中价或高价——或高于特定价格的汽车的百分比。 这同样适用于汽车的年龄和里程。 另一方面,相关性有助于理解年龄和里程等变量如何相互关联。
也就是说,我们将使用两种数据可视化:用于变量分布的直方图和用于相关性的散点图。
价格分布
用 R 语言绘制汽车价格直方图就像这样简单:
hist(cars$Price)一个小提示:如果你在 RStudio 中,你可以逐行运行代码; 例如,在我们的例子中,您只需要运行上面的行来显示直方图。 由于您已经运行过一次,因此无需再次运行所有代码。 直方图应如下所示:
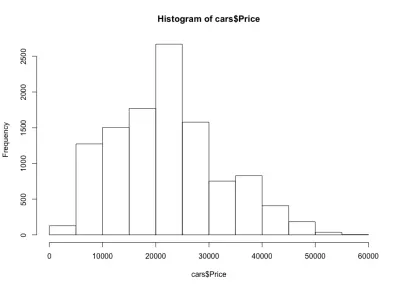
如果我们查看直方图,我们会注意到汽车价格的钟形分布,这正是我们的预期。 大多数汽车都在中档,随着我们向两边移动,我们的车越来越少。 几乎 80% 的汽车价格在 10,000 美元到 30,000 美元之间,我们最多有 2,500 多辆汽车在 20,000 美元到 25,000 美元之间。 在左侧,我们可能有大约 150 辆低于 5,000 美元的汽车,而右侧则更少。 我们可以很容易地看到这些图对于深入了解数据有多么有用。
年龄分布
就像汽车的价格一样,我们将使用类似的线来绘制汽车的年龄直方图。
hist(cars$Age)这是直方图:
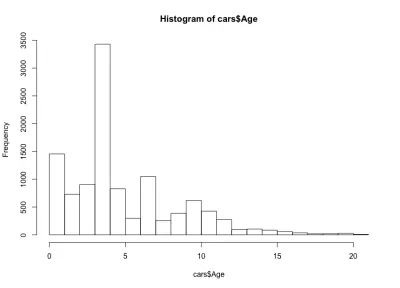
这次直方图看起来违反直觉——我们这里有四个铃铛,而不是简单的铃铛形状。 基本上,分布具有三个局部最大值和一个全局最大值,这是出乎意料的。 看看这种奇怪的汽车年龄分布是否适用于另一家汽车制造商和车型,将会很有趣。 出于本文的目的,我们将继续使用 BMW 3 系数据集,但如果您好奇,可以深入挖掘数据。 关于我们的车龄分布,我们注意到超过 90% 的汽车车龄不到 10 年,超过 80% 的车车龄不到 7 年。 此外,我们注意到大多数汽车的使用年限不到 5 年。
里程分配
现在,关于里程我们能说什么? 当然,我们希望拥有与价格相同的钟形。 这是R代码和直方图:
hist(cars$Mileage) 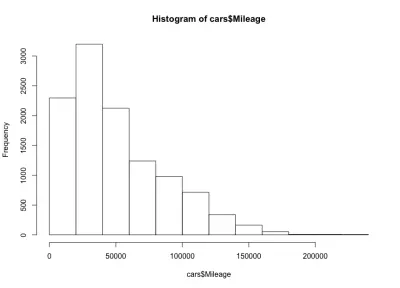
这里我们有一个左倾斜的钟形,这意味着市场上有更多里程更少的汽车。 我们还注意到大多数汽车的行驶里程不到 60,000 英里,而我们的最大行驶里程约为 20,000 到 40,000 英里。
年龄-价格相关
关于相关性,让我们仔细看看汽车年龄与价格的相关性。 我们可能会认为价格与年龄呈负相关——随着汽车年龄的增加,其价格会下降。 我们将使用 R plot函数来显示价格-年龄相关性,如下所示:
plot(cars$Age, cars$Price)情节是这样的:
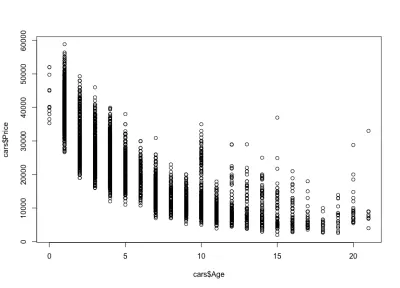
我们注意到汽车的价格随着年龄的增长而下降:有昂贵的新车,也有更便宜的旧车。 我们还可以看到任何特定年龄的价格变化区间,该变化随着汽车的年龄而减小。 这种变化很大程度上是由汽车的里程、配置和整体状态驱动的。 例如,一辆 4 年车龄的汽车,价格在 10,000 美元到 40,000 美元之间变化。
里程-年龄相关性
考虑到里程与年龄的相关性,我们预计里程会随着年龄的增长而增加,这意味着正相关。 这是代码:
plot(cars$Mileage, cars$Age)这是情节:
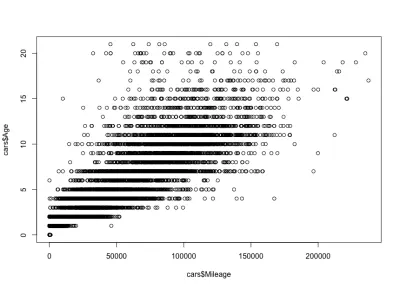
正如你所看到的,汽车的年龄和里程是正相关的,不像汽车的价格和年龄是负相关的。 我们还有一个特定年龄的预期里程变化; 也就是说,同一年龄的汽车具有不同的里程。 例如,大多数 4 年车龄的汽车的行驶里程在 10,000 到 80,000 英里之间。 但也有异常值,里程更大。
里程价格相关性
正如预期的那样,汽车的行驶里程与价格之间将存在负相关,这意味着增加行驶里程会降低价格。
plot(cars$Mileage, cars$Price)这是情节:
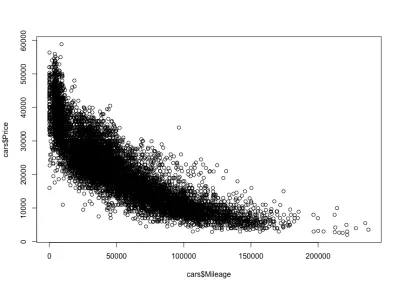
正如我们所料,负相关。 我们还可以注意到 3,000 美元到 50,000 美元之间的总价格区间,以及 0 到 150,000 美元之间的里程。 如果我们仔细观察分布形状,我们会发现里程较少的汽车的价格下降速度要快于里程较多的汽车。 有些汽车的里程几乎为零,价格急剧下降。 此外,超过 200,000 英里的范围——因为里程非常高——价格保持不变。
从数字到数据可视化
在本文中,我们使用了两种类型的可视化:数据分布的直方图和数据相关性的散点图。 直方图是采用数据变量(实际数字)的值并显示它们如何在一个范围内分布的可视化表示。 我们使用 R hist()函数绘制直方图。
另一方面,散点图采用成对的数字并在两个轴上表示它们。 散点图使用plot()函数并提供两个参数:我们要研究的相关性的第一个和第二个数据变量。 因此,两个 R 函数hist()和plot()帮助我们将数字集转换为有意义的视觉表示。
结论
在完成了导入、处理和绘制数据的整个数据流之后,现在事情看起来更加清晰了。 您可以将相同的数据流应用于您将遇到的任何闪亮的新数据集。 例如,在用户研究中,您可以绘制任务时间或错误分布图,还可以绘制任务时间与错误相关性。
要了解有关 R 语言的更多信息,Quick-R 是一个不错的起点,但您也可以考虑 R Bloggers。 有关 R 包的文档,例如dplyr ,您可以访问 RDocumentation。 玩数据可能很有趣,但它对数据驱动世界中的任何 UX 设计师都非常有帮助。 随着越来越多的数据被收集并用于为业务决策提供信息,设计人员从事数据可视化或数据产品的机会越来越多,在这些产品中,了解数据的性质至关重要。