
多项式回归:重要性,逐步实施
已发表: 2021-01-29目录
介绍
在这个广阔的机器学习领域,我们大多数人会研究的第一个算法是什么? 是的,它是线性回归。 线性回归主要是人们在机器学习编程的最初几天学习的第一个程序和算法,它对线性类型的数据具有其自身的重要性和力量。
如果我们遇到的数据集不是线性可分的怎么办? 如果线性回归模型无法在自变量和因变量之间推导出任何类型的关系怎么办?
还有另一种类型的回归,称为多项式回归。 顾名思义,多项式回归是一种回归算法,它将因变量 (y) 和自变量 (x) 之间的关系建模为 n 次多项式。 在本文中,我们将了解多项式回归背后的算法和数学以及它在 Python 中的实现。
什么是多项式回归?
如前所述,多项式回归是线性回归的一种特殊情况,其中具有指定 (n) 次的多项式方程拟合在非线性数据上,从而在因变量和自变量之间形成曲线关系。
y= b 0 +b 1 x 1 + b 2 x 1 2 + b 3 x 1 3 +…… b n x 1 n
这里,

y是因变量(输出变量)
x1是自变量(预测变量)
b 0是偏差
b 1 , b 2 , ....bn是回归方程中的权重。
随着多项式方程( n )的阶数越高,多项式方程越复杂,模型有可能出现过拟合,这将在后面讨论。
回归方程的比较
简单线性回归 ===> y= b0+b1x
多元线性回归 ===> y= b0+b1x1+ b2x2+ b3x3+…… bnxn
多项式回归 ===> y= b0+b1x1+ b2x12+ b3x13+…… bnx1n
从以上三个等式中,我们可以看出它们之间存在一些细微的差别。 简单和多元线性回归与多项式回归方程的不同之处在于它的次数仅为 1。多元线性回归由多个变量 x1、x2 等组成。 尽管多项式回归方程只有一个变量 x1,但它有一个度数 n,可以将其与其他两个区别开来。
需要多项式回归
从下图中我们可以看到,在第一个图中,试图将一条线性线拟合到给定的一组非线性数据点上。 可以理解,直线很难与这种非线性数据形成关系。 因此,当我们训练模型时,损失函数会增加,从而导致高误差。
另一方面,当我们应用多项式回归时,可以清楚地看到这条线非常适合数据点。 这意味着拟合数据点的多项式方程得出了数据集中变量之间的某种关系。 因此,对于数据点以非线性方式排列的这种情况,我们需要多项式回归模型。
Python中多项式回归的实现
从这里开始,我们将在 Python 中构建一个机器学习模型,实现多项式回归。 我们将比较线性回归和多项式回归得到的结果。 让我们首先了解我们要用多项式回归解决的问题。
问题描述
在这种情况下,考虑一家初创公司希望从一家公司雇用几名候选人的情况。 公司中不同的职位有不同的职位空缺。 初创公司有前公司每个角色的薪水细节。 因此,当候选人提到他或她以前的薪水时,初创公司的 HR 需要用现有数据进行验证。 因此,我们有两个独立变量,即位置和级别。 因变量(输出)是要使用多项式回归预测的薪水。
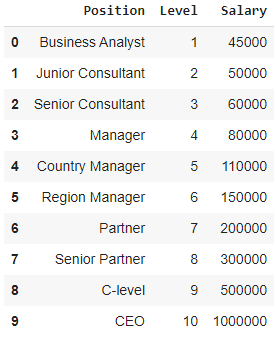
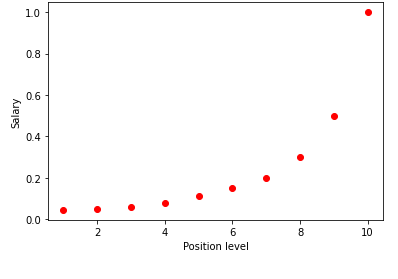
在图表中可视化上表时,我们看到数据本质上是非线性的。 换句话说,随着水平的提高,工资会以更高的速度增长,从而给我们一个如下所示的曲线。
第 1 步:数据预处理构建任何机器学习模型的第一步是导入库。 在这里,我们只需要导入三个基本库。 之后,从我的 GitHub 存储库中导入数据集,并分配因变量和自变量。 自变量存储在变量 X 中,因变量存储在变量 y 中。
将 numpy 导入为 np
将 matplotlib.pyplot 导入为 plt
将熊猫导入为 pd
dataset = pd.read_csv('https://raw.githubusercontent.com/mk-gurucharan/Regression/master/PositionSalaries_Data.csv')

X = dataset.iloc[:, 1:-1].values
y = dataset.iloc[:, -1].values
这里在术语 [:, 1:-1] 中,第一个冒号表示必须取所有行,术语 1:-1 表示要包含的列是从第一列到倒数第二列,由下式给出-1。
第 2 步:线性回归模型在下一步中,我们将建立一个多元线性回归模型,并使用它从自变量中预测工资数据。 为此,从 sklearn 库中导入了 LinearRegression 类。 然后将其拟合到变量 X 和 y 上以进行训练。
从 sklearn.linear_model 导入线性回归
回归器 = 线性回归()
regressor.fit(X, y)
建立模型后,在可视化结果时,我们会得到下图。
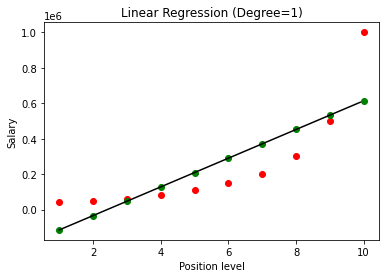
可以清楚地看到,通过尝试在非线性数据集上拟合一条直线,机器学习模型不会导出任何关系。 因此,我们需要使用多项式回归来获得变量之间的关系。
第三步:多项式回归模型在下一步中,我们将在该数据集上拟合多项式回归模型并可视化结果。 为此,我们从名为 PolynomialFeatures 的 sklearn 模块中导入另一个类,在其中我们给出要构建的多项式方程的次数。 然后使用 LinearRegression 类将多项式方程拟合到数据集。
从 sklearn.preprocessing 导入 PolynomialFeatures
从 sklearn.linear_model 导入线性回归
poly_reg = 多项式特征(度 = 2)
X_poly = poly_reg.fit_transform(X)
lin_reg = 线性回归()
lin_reg.fit(X_poly, y)
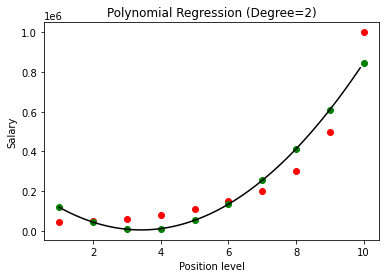
在上述情况下,我们将多项式方程的次数设为 2。在绘制图形时,我们看到有某种曲线是推导出来的,但与实际数据仍有很大偏差(红色)和预测曲线点(绿色)。 因此,在下一步中,我们将多项式的次数增加到更高的数字,例如 3 和 4,然后将其相互比较。
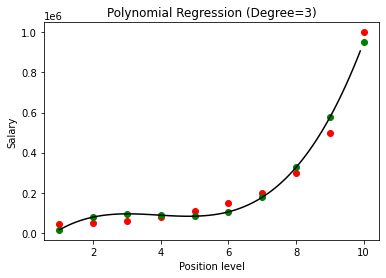
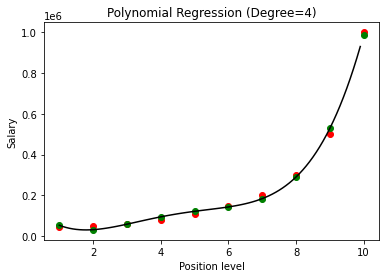
在将多项式回归的结果与 3 和 4 进行比较时,我们看到随着度数的增加,模型可以很好地与数据一起训练。 因此,我们可以推断出更高的次数使多项式方程能够更准确地拟合训练数据。 然而,这是过拟合的完美案例。 因此,精确选择 n 的值以防止过度拟合变得很重要。
什么是过拟合?
顾名思义,当一个函数(或本例中的机器学习模型)过于接近一组有限的数据点时,过度拟合被称为统计中的一种情况。 这会导致函数在处理新数据点时表现不佳。
在机器学习中,如果说一个模型在给定的一组训练数据点上过拟合,那么当将相同的模型引入一组全新的点(比如测试数据集)时,它的表现就会非常糟糕,因为过拟合模型没有很好地概括数据,只是在训练数据点上过拟合。
在多项式回归中,随着多项式次数的增加,模型很有可能在训练数据上过拟合。 在上面显示的示例中,我们看到了多项式回归中过度拟合的典型案例,可以仅通过反复试验来选择最佳度数值来纠正这种情况。
另请阅读:机器学习项目理念
结论
总而言之,多项式回归可用于因变量和自变量之间存在非线性关系的许多情况。 尽管该算法对异常值很敏感,但可以通过在拟合回归线之前对其进行处理来对其进行校正。 因此,在本文中,我们介绍了多项式回归的概念,以及它在 Python 编程中对简单数据集的实现示例。
如果您有兴趣了解有关机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,该文凭专为工作专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业、IIIT- B 校友身份、5 个以上实用的实践顶点项目和顶级公司的工作协助。
从世界顶级大学学习ML 课程。 获得硕士、Executive PGP 或高级证书课程以加快您的职业生涯。
线性回归是什么意思?
线性回归是一种预测性数值分析,通过它我们可以在因变量的帮助下找到未知变量的值。 它还解释了一个因变量和一个或多个自变量之间的联系。 线性回归是一种统计技术,用于证明两个变量之间的联系。 线性回归从一组数据点绘制趋势线。 线性回归可用于从看似随机的数据(例如癌症诊断或股票价格)生成预测模型。 有几种计算线性回归的方法。 普通的最小二乘法是最流行的方法之一,它估计数据中的未知变量并在视觉上转换为数据点和趋势线之间的垂直距离之和。
线性回归的一些缺点是什么?
在大多数情况下,回归分析用于研究以确定变量之间存在联系。 然而,相关性并不意味着因果关系,因为两个变量之间的联系并不意味着一个变量会导致另一个变量的发生。 即使是非常适合数据点的基本线性回归中的一条线也可能无法确保环境与逻辑结果之间的关系。 使用线性回归模型,您可以确定变量之间是否存在任何相关性。 需要额外的调查和统计分析来确定链接的确切性质以及一个变量是否导致另一个变量。
线性回归的基本假设是什么?
在线性回归中,有三个关键假设。 首先,因变量和自变量必须具有线性关系。 因变量和自变量的散点图用于检查这种关系。 其次,数据集中自变量之间的多重共线性应该最小或为零。 这意味着自变量是不相关的。 该值必须受到限制,这由域要求决定。 第三个因素是同方差性。 误差均匀分布的假设是最基本的假设之一。