
保持 Node.js 快速:制作高性能 Node.js 服务器的工具、技术和技巧
已发表: 2022-03-10如果您使用 Node.js 构建任何东西的时间已经足够长,那么您无疑已经经历了意外速度问题的痛苦。 JavaScript 是一种事件的异步语言。 这可能会使关于性能的推理变得棘手,这一点将变得显而易见。 Node.js 的迅速流行暴露了对适合服务器端 JavaScript 约束的工具、技术和思维的需求。
在性能方面,在浏览器中工作的东西不一定适合 Node.js。 那么,我们如何确保 Node.js 实现快速且适合目的? 让我们来看一个动手示例。
工具
Node 是一个非常通用的平台,但主要的应用程序之一是创建网络进程。 我们将专注于分析最常见的这些:HTTP Web 服务器。
我们需要一个工具,可以在测量性能的同时用大量请求攻击服务器。 例如,我们可以使用 AutoCannon:
npm install -g autocannon其他优秀的 HTTP 基准测试工具包括 Apache Bench (ab) 和 wrk2,但 AutoCannon 是用 Node 编写的,提供类似(或有时更大)的负载压力,并且非常容易安装在 Windows、Linux 和 Mac OS X 上。
在我们建立了基线性能测量之后,如果我们决定我们的流程可以更快,我们将需要一些方法来诊断流程的问题。 诊断各种性能问题的一个很好的工具是 Node Clinic,它也可以使用 npm 安装:
npm install -g clinic这实际上安装了一套工具。 我们将使用 Clinic Doctor 和 Clinic Flame(围绕 0x 的包装)。
注意:对于这个动手示例,我们需要 Node 8.11.2 或更高版本。
代码
我们的示例案例是一个具有单一资源的简单 REST 服务器:在/seed/v1处公开为 GET 路由的大型 JSON 有效负载。 服务器是一个app文件夹,它由一个package.json文件(取决于restify 7.1.0 )、一个index.js文件和一个util.js文件组成。
我们服务器的index.js文件如下所示:
'use strict' const restify = require('restify') const { etagger, timestamp, fetchContent } = require('./util')() const server = restify.createServer() server.use(etagger().bind(server)) server.get('/seed/v1', function (req, res, next) { fetchContent(req.url, (err, content) => { if (err) return next(err) res.send({data: content, url: req.url, ts: timestamp()}) next() }) }) server.listen(3000) 该服务器代表了提供客户端缓存的动态内容的常见情况。 这是通过etagger中间件实现的,该中间件为内容的最新状态计算ETag标头。
util.js文件提供了在这种情况下通常使用的实现部分、从后端获取相关内容的函数、etag 中间件和按分钟提供时间戳的时间戳函数:
'use strict' require('events').defaultMaxListeners = Infinity const crypto = require('crypto') module.exports = () => { const content = crypto.rng(5000).toString('hex') const ONE_MINUTE = 60000 var last = Date.now() function timestamp () { var now = Date.now() if (now — last >= ONE_MINUTE) last = now return last } function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } function fetchContent (url, cb) { setImmediate(() => { if (url !== '/seed/v1') cb(Object.assign(Error('Not Found'), {statusCode: 404})) else cb(null, content) }) } return { timestamp, etagger, fetchContent } }绝不将此代码作为最佳实践的示例! 此文件中有多种代码异味,但我们会在测量和分析应用程序时找到它们。
要获得我们起点的完整源代码,可以在此处找到慢速服务器。
剖析
为了进行分析,我们需要两个终端,一个用于启动应用程序,另一个用于对其进行负载测试。
在一个终端的app文件夹中,我们可以运行:
node index.js在另一个终端中,我们可以像这样分析它:
autocannon -c100 localhost:3000/seed/v1这将打开 100 个并发连接并用请求轰炸服务器十秒钟。
结果应该类似于以下内容(Running 10s test @ https://localhost:3000/seed/v1 — 100 个连接):
| 统计 | 平均 | 标准差 | 最大限度 |
|---|---|---|---|
| 延迟(毫秒) | 3086.81 | 1725.2 | 5554 |
| 请求/秒 | 23.1 | 19.18 | 65 |
| 字节/秒 | 237.98 KB | 197.7 KB | 688.13 KB |
结果会因机器而异。 然而,考虑到“Hello World”Node.js 服务器很容易在产生这些结果的机器上每秒处理 30000 个请求,因此平均延迟超过 3 秒的每秒 23 个请求是令人沮丧的。
诊断
发现问题区域
借助 Clinic Doctor 的 –on-port 命令,我们可以使用单个命令诊断应用程序。 在我们运行的app文件夹中:
clinic doctor --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.js这将创建一个 HTML 文件,该文件将在分析完成后在我们的浏览器中自动打开。
结果应如下所示:
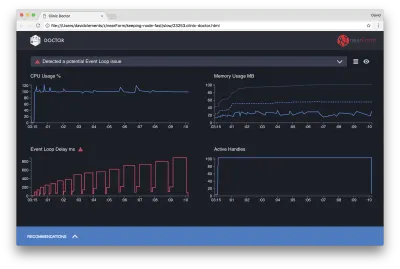
Doctor 告诉我们,我们可能遇到了 Event Loop 问题。
除了 UI 顶部附近的消息,我们还可以看到 Event Loop 图表是红色的,并且显示出不断增加的延迟。 在深入研究这意味着什么之前,让我们首先了解诊断出的问题对其他指标的影响。
我们可以看到 CPU 始终处于或高于 100%,因为该进程努力处理排队的请求。 Node 的 JavaScript 引擎(V8)在这种情况下实际上使用了两个 CPU 内核,因为机器是多核的,而 V8 使用了两个线程。 一个用于事件循环,另一个用于垃圾收集。 当我们看到在某些情况下 CPU 飙升至 120% 时,该进程正在收集与已处理请求相关的对象。
我们在内存图中看到了这种相关性。 Memory 图表中的实线是 Heap Used 指标。 每当 CPU 出现峰值时,我们都会看到 Heap Used 线下降,表明内存正在被释放。
活动句柄不受事件循环延迟的影响。 活动句柄是表示 I/O(如套接字或文件句柄)或计时器(如setInterval )的对象。 我们指示 AutoCannon 打开 100 个连接( -c100 )。 活动句柄保持一致的计数为 103。其他三个是 STDOUT、STDERR 句柄和服务器本身的句柄。
如果我们点击屏幕底部的 Recommendations 面板,我们应该会看到如下内容:
短期缓解
对严重性能问题的根本原因分析可能需要时间。 对于实时部署的项目,值得为服务器或服务添加过载保护。 过载保护的想法是监视事件循环延迟(除其他外),如果超过阈值,则响应“503 Service Unavailable”。 这允许负载均衡器故障转移到其他实例,或者在最坏的情况下意味着用户将不得不刷新。 过载保护模块可以为 Express、Koa 和 Restify 提供最小的开销。 Hapi 框架具有提供相同保护的负载配置设置。
了解问题区域
正如 Clinic Doctor 中的简短解释所解释的,如果事件循环被延迟到我们观察到的水平,则很可能一个或多个函数正在“阻塞”事件循环。
识别这个主要的 JavaScript 特性对于 Node.js 尤为重要:在当前执行的代码完成之前,不会发生异步事件。
这就是为什么setTimeout不能精确的原因。
例如,尝试在浏览器的 DevTools 或 Node REPL 中运行以下命令:
console.time('timeout') setTimeout(console.timeEnd, 100, 'timeout') let n = 1e7 while (n--) Math.random() 由此产生的时间测量永远不会是 100 毫秒。 它可能在 150 毫秒到 250 毫秒的范围内。 setTimeout调度了一个异步操作( console.timeEnd ),但是当前执行的代码还没有完成; 还有两行。 当前执行的代码称为当前的“tick”。 要完成滴答, Math.random必须被调用一千万次。 如果这需要 100 毫秒,那么超时解决之前的总时间将是 200 毫秒(加上setTimeout函数实际预先排队超时所需的时间,通常是几毫秒)。
在服务器端上下文中,如果当前tick 中的操作需要很长时间才能完成请求,则无法处理数据获取,因为在当前tick 完成之前不会执行异步代码。 这意味着计算量大的代码会减慢与服务器的所有交互。 因此建议将资源密集型工作拆分为单独的进程并从主服务器调用它们,这样可以避免在很少使用但昂贵的路由上降低其他常用但便宜的路由的性能的情况。
示例服务器有一些阻塞事件循环的代码,所以下一步是找到该代码。
分析
快速识别性能不佳的代码的一种方法是创建和分析火焰图。 火焰图将函数调用表示为彼此重叠的块——不是随着时间的推移,而是在聚合中。 它被称为“火焰图”的原因是因为它通常使用橙色到红色的配色方案,其中越红的块是“更热”的函数,这意味着它越有可能阻塞事件循环。 捕获火焰图的数据是通过对 CPU 进行采样来进行的——这意味着获取当前正在执行的函数及其堆栈的快照。 热量由分析期间给定函数位于每个样本的堆栈顶部(例如当前正在执行的函数)的时间百分比确定。 如果它不是在该堆栈中被调用的最后一个函数,那么它可能会阻塞事件循环。
让我们使用clinic flame来生成示例应用程序的火焰图:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.js结果应该在我们的浏览器中打开,如下所示:
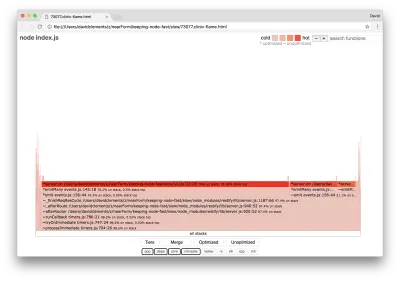
块的宽度表示它在 CPU 上花费的总时间。 可以观察到三个主要堆栈占用了最多的时间,它们都将server.on突出显示为最热的函数。 事实上,所有三个堆栈都是相同的。 它们之所以不同,是因为在分析期间优化和未优化的函数被视为单独的调用帧。 以*为前缀的函数由 JavaScript 引擎优化,以~为前缀的函数未优化。 如果优化状态对我们不重要,我们可以通过按下 Merge 按钮进一步简化图表。 这应该会导致类似于以下内容的视图:
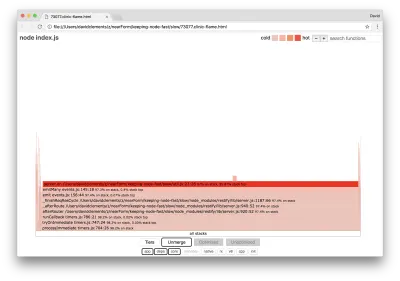
从一开始,我们就可以推断出违规代码在应用程序代码的util.js文件中。
slow 函数也是一个事件处理程序:导致该函数的函数是核心events模块的一部分, server.on是作为事件处理函数提供的匿名函数的后备名称。 我们还可以看到,此代码与实际处理请求的代码不在同一个滴答中。 如果是这样,来自核心http 、 net和stream模块的函数将在堆栈中。
这些核心功能可以通过扩展火焰图的其他小得多的部分来找到。 例如,尝试使用 UI 右上角的搜索输入来搜索send ( restify和http内部方法的名称)。 它应该在图表的右侧(函数按字母顺序排序):
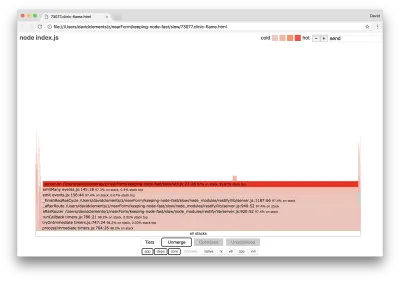
请注意所有实际的 HTTP 处理块相对较小。
我们可以单击以青色突出显示的块之一,它将展开以显示诸如writeHead之类的函数并write http_outgoing.js文件(Node 核心http库的一部分):
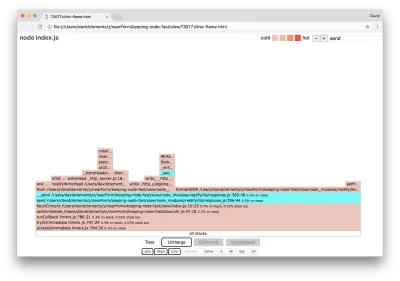
我们可以单击所有堆栈返回主视图。
这里的关键点是,即使server.on函数与实际的请求处理代码不在同一个滴答中,它仍然会通过延迟其他性能代码的执行来影响整体服务器性能。

调试
我们从火焰图中知道,有问题的函数是util.js文件中传递给server.on的事件处理程序。
让我们来看看:
server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) 众所周知,密码学往往很昂贵,序列化( JSON.stringify )也是如此,但为什么它们不出现在火焰图中呢? 这些操作在捕获的样本中,但它们隐藏在cpp过滤器后面。 如果我们按下cpp按钮,我们应该会看到如下内容:
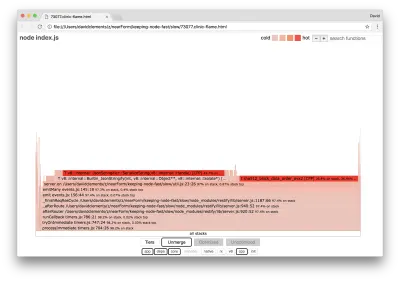
与序列化和加密相关的内部 V8 指令现在显示为最热门的堆栈并且占用了大部分时间。 JSON.stringify方法直接调用 C++ 代码; 这就是为什么我们看不到 JavaScript 函数的原因。 在密码学案例中, createHash和update等函数在数据中,但它们要么是内联的(这意味着它们在合并视图中消失),要么太小而无法呈现。
一旦我们开始对etagger函数中的代码进行推理,很快就会发现它的设计很糟糕。 为什么我们要从函数上下文中获取server实例? 有很多散列正在进行,所有这些都是必要的吗? 实现中也没有If-None-Match标头支持,这将减轻某些实际场景中的一些负载,因为客户端只会发出头部请求来确定新鲜度。
让我们暂时忽略所有这些点,并验证在server.on中执行的实际工作确实是瓶颈的发现。 这可以通过将server.on代码设置为空函数并生成新的火焰图来实现。
将etagger函数更改为以下内容:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } 传递给server.on的事件侦听器函数现在是空操作。
让我们再次运行clinic flame :
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.js这应该会产生类似于以下内容的火焰图:
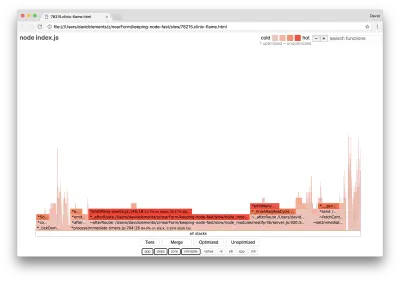
这看起来更好,我们应该注意到每秒请求的增加。 但为什么事件发射代码如此火爆? 我们预计此时 HTTP 处理代码会占用大部分 CPU 时间,在server.on事件中根本没有执行任何操作。
这种类型的瓶颈是由于执行的功能超出了应有的程度。
util.js顶部的以下可疑代码可能是一个线索:
require('events').defaultMaxListeners = Infinity 让我们删除这一行并使用--trace-warnings标志开始我们的进程:
node --trace-warnings index.js如果我们在另一个终端中使用 AutoCannon 进行分析,如下所示:
autocannon -c100 localhost:3000/seed/v1我们的过程将输出类似于:
(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)
Node 告诉我们有很多事件被附加到服务器对象上。 这很奇怪,因为有一个布尔值检查事件是否已附加,然后提前返回,基本上使attachAfterEvent在附加第一个事件后成为无操作。
我们看一下attachAfterEvent函数:
var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } 条件检查错误! 它检查attachAfterEvent是否为 true 而不是afterEventAttached 。 这意味着在每个请求上都会将一个新事件附加到server实例,然后在每个请求之后触发所有先前附加的事件。 哎呀!
优化
现在我们已经发现了问题区域,让我们看看我们是否可以让服务器更快。
低垂的果实
让我们放回server.on监听器代码(而不是一个空函数)并在条件检查中使用正确的布尔名称。 我们的etagger函数如下所示:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (afterEventAttached === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } }现在我们通过再次分析来检查我们的修复。 在一个终端启动服务器:
node index.js然后使用 AutoCannon 配置文件:
autocannon -c100 localhost:3000/seed/v1 我们应该会在 200 倍的改进范围内看到结果(运行 10 秒测试 @ https://localhost:3000/seed/v1 — 100 个连接):
| 统计 | 平均 | 标准差 | 最大限度 |
|---|---|---|---|
| 延迟(毫秒) | 19.47 | 4.29 | 103 |
| 请求/秒 | 5011.11 | 506.2 | 5487 |
| 字节/秒 | 51.8 MB | 5.45 MB | 58.72 MB |
平衡潜在的服务器成本降低和开发成本很重要。 我们需要在自己的情境中定义优化项目需要走多远。 否则,将 80% 的努力投入到 20% 的速度提升上可能太容易了。 项目的限制是否证明了这一点?
在某些情况下,实现 200 倍的改进可能是合适的,而且很容易实现。 在其他情况下,我们可能希望尽可能快地实现我们的实现。 这实际上取决于项目的优先级。
控制资源消耗的一种方法是设定目标。 例如,10 倍的改进,或每秒 4000 个请求。 基于业务需求是最有意义的。 例如,如果服务器成本超出预算 100%,我们可以设定 2 倍改进的目标。
更进一步
如果我们生成服务器的新火焰图,我们应该会看到类似于以下内容:
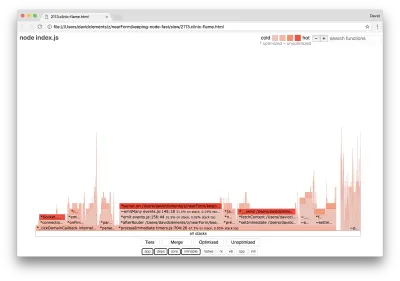
事件监听器仍然是瓶颈,它在分析期间仍然占用了三分之一的 CPU 时间(宽度大约是整个图的三分之一)。
可以取得哪些额外收益,这些变化(以及相关的破坏)是否值得做出?
通过优化的实现,但仍然稍微受到更多限制,可以实现以下性能特征(运行 10 秒测试 @ https://localhost:3000/seed/v1 — 10 个连接):
| 统计 | 平均 | 标准差 | 最大限度 |
|---|---|---|---|
| 延迟(毫秒) | 0.64 | 0.86 | 17 |
| 请求/秒 | 8330.91 | 757.63 | 8991 |
| 字节/秒 | 84.17 MB | 7.64 MB | 92.27 MB |
虽然 1.6 倍的改进是显着的,但有争议的是,创造这种改进所需的努力、更改和代码中断是否合理取决于具体情况。 尤其是与通过单个错误修复对原始实现的 200 倍改进相比时。
为了实现这一改进,使用了相同的配置文件、生成火焰图、分析、调试和优化的迭代技术来到达最终优化的服务器,其代码可以在这里找到。
达到 8000 req/s 的最终更改是:
- 不要构建对象然后序列化,直接构建一串JSON;
- 使用内容的独特之处来定义它的 Etag,而不是创建一个哈希;
- 不要对 URL 进行哈希处理,直接将其用作密钥。
这些更改涉及更多,对代码库的破坏性更大,并且使etagger中间件不太灵活,因为它将负担放在提供Etag值的路由上。 但它在分析机器上实现了每秒额外 3000 个请求。
让我们看一下这些最终改进的火焰图:
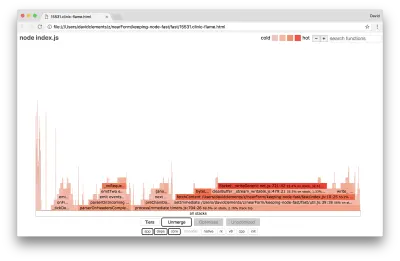
火焰图最热的部分是 Node 核心的一部分,在net模块中。 这是理想的。
防止性能问题
最后,这里有一些关于在部署之前防止性能问题的方法的建议。
在开发过程中使用性能工具作为非正式检查点可以在性能错误进入生产之前过滤掉它们。 建议将 AutoCannon 和 Clinic(或等价物)作为日常开发工具的一部分。
购买框架时,请了解它的性能政策是什么。 如果框架没有优先考虑性能,那么检查它是否与基础设施实践和业务目标一致很重要。 例如,Restify 显然(自第 7 版发布以来)投资于提高库的性能。 然而,如果低成本和高速度是绝对优先考虑的,请考虑 Fastify,它被 Restify 贡献者测量为快 17%。
注意其他影响广泛的库选择——尤其是考虑日志记录。 随着开发人员修复问题,他们可能会决定添加额外的日志输出以帮助将来调试相关问题。 如果使用性能不佳的记录器,这可能会像沸腾的青蛙寓言一样随着时间的推移扼杀性能。 pino 记录器是可用于 Node.js 的最快的换行分隔 JSON 记录器。
最后,永远记住事件循环是一个共享资源。 Node.js 服务器最终受限于最热路径中最慢的逻辑。