
学习机器学习的朴素贝叶斯算法 [附示例]
已发表: 2021-02-25目录
介绍
在数学和编程中,一些最简单的解决方案通常是最强大的解决方案。 朴素贝叶斯算法就是这种说法的一个经典例子。 即使机器学习领域的强大和快速的进步和发展,这种朴素贝叶斯算法仍然是最广泛使用和最有效的算法之一。 朴素贝叶斯算法在各种问题中都有应用,包括分类任务和自然语言处理 (NLP) 问题。
贝叶斯定理的数学假设是这种朴素贝叶斯算法背后的基本概念。 在本文中,我们将介绍贝叶斯定理的基础知识,朴素贝叶斯算法及其在 Python 中的实现以及一个实时示例问题。 除了这些,我们还将看看朴素贝叶斯算法与其竞争对手相比的一些优点和缺点。
概率基础
在我们冒险理解贝叶斯定理和朴素贝叶斯算法之前,让我们先回顾一下我们现有的概率基础知识。
正如我们都知道的定义,给定一个事件 A,该事件发生的概率由 P(A) 给出。 在概率上,如果事件 A 的发生不改变事件 B 的发生概率,则将两个事件 A 和 B 称为独立事件,反之亦然。 另一方面,如果一个事件的发生改变了另一个事件的概率,那么它们被称为从属事件。
让我们介绍一个叫做条件概率的新术语。 在数学中,由 P (A| B) 给出的两个事件 A 和 B 的条件概率定义为在事件 B 已经发生的情况下,事件 A 发生的概率。 根据两个事件 A 和 B 之间的关系,它们是独立的还是独立的,条件概率以两种方式计算。
- 两个相关事件A 和 B的条件概率由 P (A| B) = P (A and B) / P (B) 给出
- 两个独立事件A 和 B的条件概率表达式为: P (A| B) = P (A)
了解了概率和条件概率背后的数学原理,现在让我们继续研究贝叶斯定理。

贝叶斯定理
在统计和概率论中,贝叶斯定理也称为贝叶斯规则,用于确定事件的条件概率。 换句话说,贝叶斯定理基于对可能与事件相关的条件的先验知识来描述事件的概率。
为了以更简单的方式理解它,请考虑我们需要知道房屋价格的概率非常高。 如果我们知道其他参数,例如附近的学校、医疗商店和医院的存在,那么我们可以对其进行更准确的评估。 这正是贝叶斯定理所执行的。
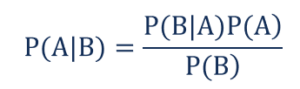
这样,
- P(A|B) – 事件 A 发生的条件概率,假设事件 B 已经发生,也称为后验概率。
- P(B|A) – 事件 B 发生的条件概率,假设事件 A 已经发生,也称为似然概率。
- P(A) – 事件 A 发生的概率,也称为先验概率。
- P(B) – 事件 B 发生的概率,也称为边际概率。
假设我们有一个简单的机器学习问题,其中包含“n”个自变量,而作为输出的因变量是一个布尔值(真或假)。 假设独立属性本质上是分类的,让我们在这个例子中考虑 2 个类别。 因此,使用这些数据,我们需要计算似然概率 P(B|A) 的值。
因此,通过观察上述内容,我们发现我们需要计算 2*(2^ n -1 ) 个参数才能学习此机器学习模型。 同样,如果我们有 30 个布尔独立属性,那么要计算的参数总数将接近 30 亿个,这在计算成本上是非常高的。
使用贝叶斯定理构建机器学习模型的困难导致了朴素贝叶斯算法的诞生和发展。
朴素贝叶斯算法
为了实用,需要降低贝叶斯定理的上述复杂度。 这正是在朴素贝叶斯算法中通过做一些假设来实现的。 所做的假设是每个特征都对结果做出独立且平等的贡献。
朴素贝叶斯算法是一种监督学习算法,它基于主要用于解决分类问题的贝叶斯定理。 它是构建机器学习模型以进行快速预测的最简单和最准确的分类器之一。 在数学上,它是一个概率分类器,因为它使用事件的概率函数进行预测。
示例问题
为了理解假设背后的逻辑,让我们通过一个简单的数据集来获得更好的直觉。
| 颜色 | 类型 | 起源 | 盗窃? |
| 黑色的 | 轿车 | 进口的 | 是的 |
| 黑色的 | 越野车 | 进口的 | 不 |
| 黑色的 | 轿车 | 国内的 | 是的 |
| 黑色的 | 轿车 | 进口的 | 不 |
| 棕色的 | 越野车 | 国内的 | 是的 |
| 棕色的 | 越野车 | 国内的 | 不 |
| 棕色的 | 轿车 | 进口的 | 不 |
| 棕色的 | 越野车 | 进口的 | 是的 |
| 棕色的 | 轿车 | 国内的 | 不 |
从上面给出的数据集中,我们可以推导出我们为上面的朴素贝叶斯算法定义的两个假设的概念。
- 第一个假设是所有特征都是相互独立的。 在这里,我们看到每个属性都是独立的,例如颜色“红色”独立于汽车的类型和产地。
- 接下来,每个特征都被赋予同等的重要性。 同样,仅了解汽车的类型和来源并不足以预测问题的输出。 因此,没有一个变量是不相关的,因此它们都对结果做出了同等的贡献。
总而言之,A 和 B 在给定 C 条件下是条件独立的,当且仅当,给定 C 发生的知识,A 是否发生的知识不提供关于 B 发生可能性的信息,并且 B 是否发生的知识不提供关于A发生的可能性。 这些假设使贝叶斯算法 -朴素。 因此得名朴素贝叶斯算法。
因此,对于上述问题,贝叶斯定理可以重写为 -
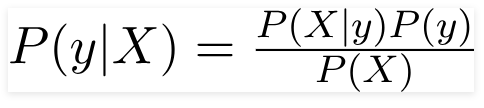
这样,
- 独立的特征向量,X = (x 1 , x 2 , x 3 ……x n ) 表示汽车的颜色、类型和起源等特征。
- 输出变量 y 只有两个结果是或否。
因此,通过代入上述值,我们得到朴素贝叶斯公式:
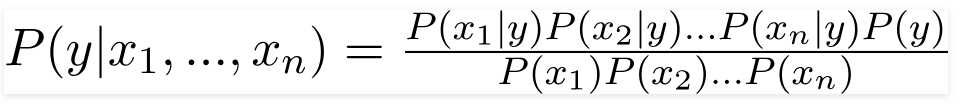
为了计算后验概率 P(y|X),我们必须针对输出为每个属性创建一个频率表。 然后将频率表转换为似然表,然后我们最终使用朴素贝叶斯方程来计算每个类的后验概率。 具有最高后验概率的类被选为预测的结果。 以下是所有三个预测变量的频率和可能性表。
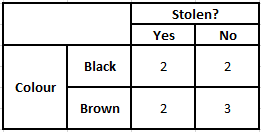
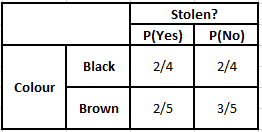
颜色频率表 颜色似然表
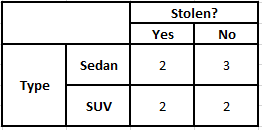
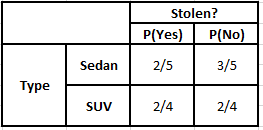
类型频率表 类型似然表

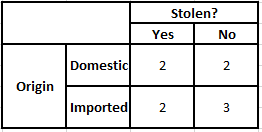
起源频率表 起源似然表
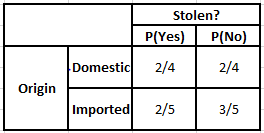
考虑我们需要计算以下给定条件的后验概率的情况——
| 颜色 | 类型 | 起源 |
| 棕色的 | 越野车 | 进口的 |
因此,根据上面给出的公式,我们可以计算出后验概率,如下所示 -
P(是 | X) = P(布朗 | 是) * P(SUV | 是) * P(进口 | 是) * P(是)
= 2/5 * 2/4 * 2/5 * 1
= 0.08
P(No | X) = P(Brown | No) * P(SUV | No) * P(进口| No) * P(No)
= 3/5 * 2/4 * 3/5 * 1
= 0.18
从以上计算的数值,由于No的后验概率大于Yes(0.18>0.08),则可以推断进口产地为棕色、SUV类型的汽车被归类为“No”。 因此,汽车没有被盗。
用 Python 实现
现在我们已经了解了朴素贝叶斯算法背后的数学原理,并通过一个示例对其进行了可视化,让我们来看看它的 Python 语言机器学习代码。
相关:朴素贝叶斯分类器
问题分析
为了使用 Python 在机器学习中实现朴素贝叶斯分类程序,我们将使用非常著名的“鸢尾花数据集”。 鸢尾花数据集或费舍尔鸢尾花数据集是英国统计学家、优生学家和生物学家 Ronald Fisher 于 1998 年引入的多元数据集。这是一个非常小且基本的数据集,由非常少的数字数据组成,包含有关 3 类的信息属于鸢尾属植物的花是——
- 鸢尾花
- 鸢尾花
- 弗吉尼亚鸢尾
这三个物种中的每一个都有 50 个样本,总计 150 行的数据集。 该数据集中使用的 4 个属性(或)自变量是——
- 萼片长度(厘米)
- 萼片宽度厘米
- 花瓣长度厘米
- 花瓣宽度厘米
因变量是由上述给定的四个属性标识的花的“物种”。
第 1 步 - 导入库
与往常一样,构建任何机器学习模型的首要步骤是导入相关库。 为此,我们将加载 NumPy、Mathplotlib 和 Pandas 库来预处理数据。
将 numpy 导入为 np
将 matplotlib.pyplot 导入为 plt
将熊猫导入为 pd
第 2 步 - 加载数据集
用于训练朴素贝叶斯分类器的鸢尾花数据集应加载到 Pandas DataFrame 中。 4 个自变量应分配给变量 X,最终输出种类变量分配给 y。
dataset = pd.read_csv(' https://raw.githubusercontent.com/mk-gurucharan/Classification/master/IrisDataset.csv' )X = dataset.iloc[:,:4].values
y = 数据集['species'].valuesdataset.head(5)>>
萼片长度 萼片宽度 花瓣长度 花瓣宽度 种
5.1 3.5 1.4 0.2 塞托萨
4.9 3.0 1.4 0.2 塞托萨
4.7 3.2 1.3 0.2 塞托萨
4.6 3.1 1.5 0.2 塞托萨
5.0 3.6 1.4 0.2 塞托萨
第 3 步 - 将数据集拆分为训练集和测试集
加载数据集和变量后,下一步是准备将接受训练过程的变量。 在这一步中,我们必须将 X 和 y 变量拆分为训练和测试数据集。 为此,我们将随机分配 80% 的数据到将用于训练目的的训练集,其余 20% 的数据作为测试集,在其上测试经过训练的朴素贝叶斯分类器的准确性。
从 sklearn.model_selection 导入 train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
第 4 步 - 特征缩放
虽然这是这个小数据集的附加过程,但我添加它是为了让您在更大的数据集中使用它。 在这种情况下,训练和测试集中的数据被缩小到 0 到 1 之间的值范围。这降低了计算成本。
从 sklearn.preprocessing 导入 StandardScaler
sc = 标准缩放器()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
第 5 步 – 在训练集上训练朴素贝叶斯分类模型
正是在这一步中,我们从 sklearn 库中导入了朴素贝叶斯类。 对于这个模型,我们使用高斯模型,还有其他几个模型,如伯努利、分类和多项式。 因此,将 X_train 和 y_train 拟合到分类器变量以进行训练。
从 sklearn.naive_bayes 导入 GaussianNB
分类器 = GaussianNB()
分类器.fit(X_train, y_train)
第 6 步 – 预测测试集结果 –
我们使用训练的模型预测测试集的物种类别,并将其与物种类别的真实值进行比较。
y_pred = 分类器.predict(X_test)
df = pd.DataFrame({'真实值':y_test, '预测值':y_pred})
df>>
实际值 预测值
setosa setosa
setosa setosa
弗吉尼亚弗吉尼亚
杂色杂色
setosa setosa
setosa setosa
………………
维吉尼亚杂色
弗吉尼亚弗吉尼亚
setosa setosa
setosa setosa
杂色杂色
杂色杂色
在上面的比较中,我们看到有一个错误的预测是预测 Versicolor 而不是Virginica。
第 7 步 - 混淆矩阵和准确性
当我们处理分类时,评估我们的分类器模型的最佳方法是在测试集上打印混淆矩阵及其准确性。
从 sklearn.metrics 导入混淆矩阵
cm=confusion_matrix(y_test, y_pred) from sklearn.metrics import accuracy_score
打印(“准确性:”,accuracy_score(y_test,y_pred))
厘米>>精度:0.9666666666666667
>>array([[14, 0, 0],
[ 0, 7, 0],
[ 0, 1, 8]])
结论
因此,在本文中,我们已经了解了朴素贝叶斯算法的基础知识,了解了分类背后的数学原理以及一个手动解决的示例。 最后,我们实现了一个机器学习代码来使用朴素贝叶斯分类算法来解决一个流行的数据集。
如果您有兴趣了解更多关于人工智能、机器学习的信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,该文凭专为在职专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业, IIIT-B 校友身份、5 个以上实用的实践顶点项目和顶级公司的工作协助。
概率在机器学习中有何帮助?
我们可能不得不根据现实世界场景中的部分或不完整信息做出决定。 概率帮助我们量化此类系统中的不确定性并管理任务的风险。 传统方法仅适用于特定行动的确定性结果,但在任何预测模型中总是存在一定范围的不确定性。 这种不确定性可能来自输入数据中的许多参数,例如数据中的噪声。 此外,来自概率定理的贝叶斯观点可以帮助从输入数据中识别模式。 为此,概率使用最大似然估计概念,因此有助于产生相关结果。
混淆矩阵有什么用?
混淆矩阵是一个 2x2 矩阵,用于解释分类模型的性能。 必须知道输入数据的真实值才能使其正常工作,因此无法表示未标记的数据。 它由假阳性(FP)、真阳性(TP)、假阴性(FN)和真阴性(TN)的数量组成。 使用来自训练集和测试集的计数将预测分类为这些类。 它帮助我们可视化有用的参数,例如准确度、精确度、召回率和特异性。 它相对容易理解,并让您对算法有一个清晰的了解。
朴素贝叶斯模型有哪些不同类型?
所有类型都主要基于贝叶斯定理。 朴素贝叶斯模型一般有高斯、伯努利和多项式三种。 高斯朴素贝叶斯辅助输入参数的连续值,它假设所有输入数据类别都是均匀分布的。 伯努利的朴素贝叶斯是一种基于事件的模型,其中数据特征是独立的并以布尔值的形式出现。 多项朴素贝叶斯也是基于基于事件的模型。 它具有矢量形式的数据特征,表示基于事件发生的相关频率。