
混合有形和无形:使用 Adobe XD 设计多模式界面
已发表: 2022-03-10(本文由 Adobe 赞助。)用户界面在不断发展。 支持语音的界面正在挑战图形用户界面的长期主导地位,并迅速成为我们日常生活中常见的一部分。 自动语音识别 (APS) 和自然语言处理 (NLP) 方面的重大进展,以及令人印象深刻的消费者基础(数百万内置语音助手的移动设备),影响了基于语音的界面的快速开发和采用。
以语音为主要界面的产品越来越受欢迎。 仅在美国,就有 4730 万成年人可以使用智能扬声器(占美国成年人口的五分之一),而且这个数字还在增长。 但语音接口不仅在个人和家庭使用中有着光明的未来。 随着人们习惯于语音界面,他们也会在商业环境中期待它们。 想象一下,很快您就可以通过说“显示我的演示文稿”之类的话来触发会议室投影仪。
很明显,人机交流正在迅速扩展到包括书面和口头互动。 但这是否意味着未来的界面将是纯语音的? 尽管有一些科幻小说的描述,但语音不会完全取代图形用户界面。 相反,我们将在一种新的界面格式中实现语音、视觉和手势的协同作用:支持语音的多模式界面。
在本文中,我们将:
- 探索启用语音的界面的概念并审查不同类型的启用语音的界面;
- 找出为什么支持语音的多模式用户界面将成为首选的用户体验;
- 了解如何使用 Adobe XD 构建多模式 UI。
语音用户界面 (VUI) 的状态
在深入了解语音用户界面的细节之前,我们必须定义什么是语音输入。 语音输入是一种人机交互,其中用户说出命令而不是编写命令。 语音输入的美妙之处在于它对人们来说是一种更自然的交互——用户在与系统交互时不受特定语法的限制; 他们可以用许多不同的方式来组织他们的输入,就像他们在人类对话中所做的那样。
语音用户界面为其用户带来以下好处:
- 更少的交互成本
尽管使用支持语音的界面确实会产生交互成本,但这个成本(理论上)比学习新 GUI 的成本要小。 - 免提控制
VUI 非常适合用户忙碌的时候——例如,在开车、做饭或锻炼时。 - 速度
当提出问题比打字和阅读结果更快时,语音非常好。 例如,在汽车中使用语音时,向导航系统说出地点比在触摸屏上输入位置更快。 - 情感和个性
即使我们听到声音但看不到说话者的图像,我们也可以在脑海中想象说话者。 这有机会提高用户参与度。 - 可访问性
视觉障碍用户和行动障碍用户可以使用语音与系统交互。
三种类型的语音接口
根据语音的使用方式,它可能是以下类型的接口之一。
屏幕优先设备中的语音代理
Apple Siri 和 Google Assistant 是语音代理的主要例子。 对于这样的系统,语音更像是对现有 GUI 的增强。 在许多情况下,代理是用户旅程的第一步:用户触发语音代理并通过语音提供命令,而所有其他交互都使用触摸屏完成。 例如,当您向 Siri 提问时,它会以列表的形式提供答案,您需要与该列表进行交互。 结果,用户体验变得支离破碎——我们使用语音来启动交互,然后转向触摸来继续它。
纯语音设备
这些设备没有视觉显示; 用户依赖音频进行输入和输出。 Amazon Echo 和 Google Home 智能扬声器是此类产品的主要示例。 缺乏视觉显示是对设备向用户传达信息和选项的能力的重大限制。 因此,大多数人使用这些设备来完成简单的任务,例如播放音乐和获得简单问题的答案。

语音优先设备
使用语音优先系统,该设备主要通过语音命令接受用户输入,但也有一个集成的屏幕显示。 这意味着语音是主要的用户界面,但不是唯一的。 “一图胜千言”这句老话仍然适用于现代语音系统。 人脑具有难以置信的图像处理能力——当我们在视觉上看到复杂的信息时,我们可以更快地理解复杂的信息。 与纯语音设备相比,语音优先设备允许用户访问更多信息并使许多任务更容易。
Amazon Echo Show 是采用语音优先系统的设备的典型示例。 视觉信息逐渐成为整体系统的一部分——屏幕上没有加载应用程序图标; 相反,该系统鼓励用户尝试不同的语音命令(建议口头命令,例如“试试‘Alexa,告诉我下午 5:00 的天气’”)。 屏幕甚至使诸如在烹饪时检查食谱等常见任务变得更加容易——用户无需仔细聆听并将所有信息留在脑海中; 当他们需要信息时,他们只需看一下屏幕。

引入多模式接口
在 UI 设计中使用语音时,不要将语音视为可以单独使用的东西。 Amazon Echo Show 等设备包括一个屏幕,但使用语音作为主要输入方法,从而提供更全面的用户体验。 这是迈向新一代用户界面的第一步:多模式界面。
多模式界面是将语音、触摸、音频和不同类型的视觉效果融合在一个无缝的 UI 中的界面。 Amazon Echo Show 是充分利用支持语音的多模式界面的设备的绝佳示例。 当用户与 Show 交互时,他们会像使用纯语音设备一样发出请求; 但是,他们收到的响应可能是多模式的,包含语音和视觉响应。
多模式产品比仅依赖视觉或仅依赖语音的产品更复杂。 为什么任何人都应该首先创建多模式界面? 要回答这个问题,我们需要退后一步,看看人们如何看待他们周围的环境。 人有五种感官,我们的感官共同作用就是我们感知事物的方式。 例如,当我们在现场音乐会上听音乐时,我们的感官会协同工作。 去除一种感觉(例如,听觉),体验就会呈现出完全不同的背景。

长期以来,我们一直认为用户体验完全是视觉或手势设计。 是时候改变这种想法了。 多模式设计是一种思考和设计将我们的感官能力联系在一起的体验的方式。
多模式界面让用户和机器的交流感觉更人性化。 它们为更深入的互动开辟了新的机会。 而今天,设计多模式界面变得更加容易,因为过去限制与产品交互的技术限制正在被消除。
GUI和多模式界面之间的区别
这里的关键区别在于,像 Amazon Echo Show 这样的多模式界面同步语音和视觉界面。 因此,当我们在设计体验时,声音和视觉不再是独立的部分; 它们是系统提供的体验的组成部分。
视觉和语音频道:何时使用
将语音和视觉视为输入和输出的渠道很重要。 每个渠道都有自己的优势和劣势。
让我们从视觉效果开始。 很明显,有些信息在我们看到时比在听到时更容易理解。 当您需要提供以下内容时,视觉效果会更好:
- 很长的选项列表(阅读很长的列表将花费大量时间并且难以理解);
- 数据量大的信息(例如图表);
- 产品信息(例如,在线商店中的产品;很可能,您希望在购买前查看产品)和产品比较(由于选项列表很长,仅使用语音很难提供所有信息) .
然而,对于某些信息,我们可以很容易地依靠口头交流。 语音可能适合以下情况:
- 用户命令(语音是一种高效的输入方式,允许用户快速向系统发出命令并绕过复杂的导航菜单);
- 简单的用户说明(例如,对处方的例行检查);
- 警告和通知(例如,在驾驶过程中与语音通知配对的音频警告)。
虽然这些是视觉和语音结合的一些典型案例,但重要的是要知道我们不能将两者分开。 只有语音和视觉协同工作,我们才能创造更好的用户体验。 例如,假设我们想购买一双新鞋。 我们可以使用语音向系统请求“给我看 New Balance 鞋子”。 系统会处理您的请求并直观地提供产品信息(我们比较鞋子的一种更简单的方法)。
设计支持语音的多模式界面需要了解的内容
语音是 UX 设计师最激动人心的挑战之一。 尽管它很新颖,但设计支持语音的多模式界面的基本规则与我们用于创建视觉设计的规则相同。 设计师应该关心他们的用户。 他们的目标应该是通过以有效的方式解决他们的问题来减少用户的摩擦,并优先考虑清晰性以使用户的选择清晰。
但多模式界面也有一些独特的设计原则。
确保您解决了正确的问题
设计应该解决问题。 但解决正确的问题至关重要; 否则,您可能会花费大量时间来创建不会给用户带来太多价值的体验。 因此,请确保您专注于解决正确的问题。 语音交互应该对用户有意义; 用户应该有令人信服的理由使用语音而不是其他交互方式(例如点击或点击)。 这就是为什么当你创建一个新产品时——甚至在开始设计之前——进行用户研究并确定语音是否会改善用户体验是至关重要的。
从创建用户旅程图开始。 分析旅程图并找到将语音作为渠道的地方将使用户体验受益。
- 寻找用户可能会遇到摩擦和挫折的旅程中的地方。 使用语音会减少摩擦吗?
- 考虑用户的上下文。 语音是否适用于特定环境?
- 想想语音的独特之处。 记住使用语音的独特优势,例如免提和免眼交互。 语音可以为体验增加价值吗?
创建对话流
理想情况下,您设计的界面应该需要零交互成本:用户应该能够满足他们的需求,而无需花费额外的时间来学习如何与系统进行交互。 仅当语音交互类似于真实对话而不是以语音命令格式包装的系统对话时才会发生这种情况。 良好 UI 的基本规则很简单:计算机应该适应人类,而不是相反。
人们很少有平坦的、线性的对话(只持续一回合的对话)。 这就是为什么要使与系统的交互感觉像现场对话,设计师应该专注于创建对话流。 每个对话流都包含对话——系统和用户之间发生的路径。 每个对话都将包括系统的提示和用户可能的反应。
会话流可以以流程图的形式呈现。 每个流程都应该关注一个特定的用例(例如,使用系统设置闹钟)。 对于流程中的大多数对话,当事情脱轨时,考虑错误路径至关重要。
用户的每个语音命令都包含三个关键要素:意图、话语和时隙。
- 意图是用户与启用语音的系统交互的目标。
意图只是定义一组词背后的目的的一种奇特方式。 与系统的每次交互都会给用户带来一些实用性。 无论是信息还是动作,实用程序都是有目的的。 了解用户的意图是启用语音的界面的关键部分。 当我们设计 VUI 时,我们并不总是能确定用户的意图是什么,但我们可以很准确地猜测出来。 - 话语是用户如何表达他们的请求。
通常,用户有不止一种方法来制定语音命令。 例如,我们可以通过说“将闹钟设置为早上 8 点”、“闹钟明天早上 8 点”甚至“我需要早上 8 点起床”来设置闹钟。 设计者需要考虑每一种可能的话语变化。 - 槽是用户在命令中使用的变量。 有时用户需要在请求中提供附加信息。 在我们的闹钟示例中,“8 am”是一个时隙。
不要把话放在用户的嘴里
人们知道如何说话。 不要试图教他们命令。 避免使用诸如“要发送会议预约,您需要说‘日历,会议,创建新会议’”之类的短语。 如果必须解释命令,则需要重新考虑设计系统的方式。 始终以自然语言对话为目标,并尝试适应不同的说话风格)。
力求一致性
您需要在不同环境中实现语言和语音的一致性。 一致性将有助于在交互中建立熟悉度。
始终提供反馈
系统状态的可见性是良好 GUI 设计的基本原则之一。 系统应始终在合理的时间内通过适当的反馈让用户了解正在发生的事情。 同样的规则也适用于 VUI 设计。
- 让用户知道系统正在监听。
当设备正在侦听或处理用户请求时显示视觉指示器。 没有反馈,用户只能猜测系统是否在做某事。 这就是为什么即使像 Amazon Echo 和 Google Home 这样的纯语音设备在收听或搜索答案时也会给我们很好的视觉反馈(闪光灯)。 - 提供对话标记。
对话标记告诉用户他们在对话中的位置。 - 确认任务何时完成。
例如,当用户向支持语音的智能家居系统询问“关掉车库的灯”时,系统应该让用户知道该命令已成功执行。 未经确认,用户将需要走进车库并检查灯光。 它违背了智能家居系统的目的,即让用户的生活更轻松。
避免长句
在设计支持语音的系统时,请考虑向用户提供信息的方式。 当您使用长句子时,相对容易让用户因过多的信息而不知所措。 首先,用户无法在短期记忆中保留大量信息,因此很容易忘记一些重要信息。 此外,音频是一种慢速媒介——大多数人的阅读速度比他们听的快得多。
尊重用户的时间; 不要朗读冗长的音频独白。 在设计响应时,使用的词越少越好。 但请记住,您仍然需要为用户提供足够的信息来完成他们的任务。 因此,如果您不能用几句话概括答案,请将其显示在屏幕上。
按顺序提供后续步骤
用户不仅会被长句子压得喘不过气来,而且一次选择的数量也会让用户不知所措。 将与支持语音的系统的交互过程分解成小块至关重要。 限制用户在任何时候的选择数量,并确保他们每时每刻都知道该做什么。
在设计具有许多功能的复杂语音系统时,您可以使用渐进式披露技术:仅提供完成任务所需的选项或信息。
拥有强大的错误处理策略
当然,系统应该首先防止错误发生。 但是,无论您的语音系统有多好,您都应该始终针对系统无法理解用户的场景进行设计。 您的责任是针对此类情况进行设计。
以下是创建策略的一些实用技巧:
- 不要责怪用户。
在对话中,没有错误。 尽量避免诸如“你的答案不正确”之类的回答。 - 提供错误恢复流程。
提供在对话中来回切换的选项,甚至退出系统,而不会丢失重要信息。 保存用户在旅程中的状态,以便他们可以从上次中断的地方重新与系统互动。 - 让用户重播信息。
提供使系统重复问题或答案的选项。 这对于用户难以将所有信息提交到他们的工作记忆中的复杂问题或答案可能会有所帮助。 - 提供停止措辞。
在某些情况下,用户对收听某个选项不感兴趣,并希望系统停止谈论它。 停止措辞应该帮助他们做到这一点。 - 优雅地处理意料之外的话语。
无论你在系统设计上投入多少,都会出现系统不理解用户的情况。 优雅地处理此类案件至关重要。 不要害怕让系统承认缺乏理解。 系统应该传达它所理解的内容并提供有用的提示。 - 使用分析来改进您的错误策略。
分析可以帮助您识别错误的转折和误解。
跟踪上下文
确保系统理解用户输入的上下文。 例如,当有人说他们想预订下周飞往旧金山的航班时,他们可能会在对话流中提到“它”或“城市”。 系统应该记住所说的内容,并能够将其与新收到的信息相匹配。

了解您的用户以创建更强大的交互
当启用语音的系统使用附加信息(例如用户上下文或过去的行为)来了解用户想要什么时,它会变得更加复杂。 这种技术被称为智能解释,它要求系统主动了解用户并能够相应地调整他们的行为。 这些知识将帮助系统为复杂的问题提供答案,例如“我应该为妻子的生日买什么礼物?”
赋予您的 VUI 个性
无论您是否计划,每个支持语音的系统都会对用户产生情感影响。 人们将声音与人类而非机器联系起来。 根据 Speak Easy Global Edition 的研究,74% 的语音技术普通用户希望品牌能够为其支持语音的产品提供独特的声音和个性。 通过个性建立同理心并实现更高水平的用户参与度是可能的。
尝试在您呈现的声音和语气中反映您独特的品牌和身份。 构建启用语音的代理的角色,并在创建对话时依赖此角色。
建立信任
当用户不信任一个系统时,他们就没有使用它的动力。 这就是为什么建立信任是产品设计的要求。 有两个因素对建立的信任水平有重大影响:系统能力和有效结果。
建立信任始于设定用户期望。 传统的 GUI 有很多视觉细节来帮助用户了解系统的功能。 借助支持语音的系统,设计人员可以依赖的工具更少。 尽管如此,让系统自然可发现仍然至关重要。 用户应该了解系统可以做什么和不可以做什么。 这就是为什么启用语音的系统可能需要用户入职,在其中讨论系统可以做什么或知道什么。 在设计入职培训时,尝试提供有意义的示例,让人们知道它可以做什么(示例比说明更有效)。
当谈到有效的结果时,人们知道支持语音的系统是不完美的。 当系统提供答案时,一些用户可能会怀疑答案是否正确。 发生这种情况是因为用户没有任何关于他们的请求是否被正确理解或使用什么算法来找到答案的信息。 为防止出现信任问题,请使用支持证据的屏幕——在屏幕上显示原始查询——并提供有关算法的一些关键信息。 例如,当用户询问“给我看 2018 年排名前五的电影”时,系统可以说,“这里是 2018 年美国票房排名前五的电影”。
不要忽视安全和数据隐私
与属于个人的移动设备不同,语音设备往往属于某个位置,例如厨房。 通常,同一地点有不止一个人。 试想一下,其他人可以与可以访问您所有个人数据的系统进行交互。 Amazon Alexa、Google Assistant 和 Apple Siri 等一些 VUI 系统可以识别个人声音,这为系统增加了一层安全性。 尽管如此,它并不能保证系统能够在 100% 的情况下根据用户独特的语音签名识别用户。
语音识别在不断改进,在不久的将来模仿声音将很难或几乎不可能。 但是,在当前现实中,提供额外的身份验证层以向用户保证他们的数据是安全的至关重要。 如果您设计的应用程序可以处理敏感数据,例如健康信息或银行详细信息,您可能需要包含额外的身份验证步骤,例如密码或指纹或面部识别。
进行可用性测试
可用性测试是任何系统的强制性要求。 尽早测试,经常测试应该是您设计过程的基本规则。 尽早收集用户研究数据,并迭代您的设计。 但测试多模式接口有其自身的特点。 以下是应考虑的两个阶段:
- 构思阶段
试驾您的示例对话框。 练习大声朗读示例对话。 一旦你有了一些对话流,记录对话的双方(用户的话语和系统的响应),并听录音以了解它们听起来是否自然。 - 产品开发的早期阶段(使用 lo-fi 原型进行测试)
绿野仙踪测试非常适合测试会话界面。 绿野仙踪测试是一种测试,参与者与他们认为由计算机操作但实际上由人操作的系统进行交互。 测试参与者提出一个问题,另一端有一个真人回答。 这种方法得名于弗兰克鲍姆的《绿野仙踪》一书。 书中,一个普通人躲在窗帘后面,伪装成一个强大的巫师。 该测试允许您绘制出所有可能的交互场景,从而创建更自然的交互。 Say Wizard 是一款出色的工具,可帮助您在 macOS 上运行绿野仙踪语音界面测试。 - 产品开发的后期阶段(使用高保真原型进行测试)
在图形用户界面的可用性测试中,我们经常要求用户在与系统交互时大声说出来。 对于支持语音的系统,这并不总是可行的,因为系统会收听该旁白。 因此,最好观察用户与系统的交互,而不是让他们大声说出来。
如何使用 Adobe XD 创建多模式界面
现在您已经对什么是多模式界面以及设计它们时要记住的规则有了深入的了解,我们可以讨论如何制作多模式界面的原型。
原型设计是设计过程的基本部分。 能够将想法变为现实并与他人分享非常重要。 到目前为止,想要在原型设计中加入语音的设计师几乎没有可以依赖的工具,其中最强大的是流程图。 描绘用户如何与系统交互需要查看流程图的人的大量想象力。 借助 Adobe XD,设计师现在可以访问语音媒体,并可以在他们的原型中使用它。 XD 在一个应用程序中无缝连接屏幕和语音原型。
新体验,相同流程
尽管语音是一种与视觉完全不同的媒介,但在 Adobe XD 中为语音制作原型的过程与为 GUI 制作原型的过程几乎相同。 Adobe XD 团队以一种让任何设计师都感觉自然和直观的方式集成语音。 设计人员可以使用语音触发器和语音播放与原型进行交互:
- 当用户说出特定的单词或短语(话语)时,语音触发器会开始交互。
- 语音播放使设计人员可以访问文本到语音引擎。 XD 会说出设计师定义的单词和句子。 语音播放可用于许多不同的目的。 例如,它可以作为确认(让用户放心)或指导(让用户知道下一步该做什么)。
XD 的伟大之处在于它不会强迫您了解每个语音平台的复杂性。
说得够多了——让我们看看它是如何工作的。 对于您将在下面看到的所有示例,我使用了使用用于 Amazon Alexa 的 Adobe XD UI 工具包创建的画板(这是下载工具包的链接)。 该套件包含为 Amazon Alexa 创建体验所需的所有样式和组件。
假设我们有以下画板:
让我们进入原型模式以添加一些语音交互。 我们将从语音触发器开始。 除了点击和拖动等触发器外,我们现在还可以使用语音作为触发器。 我们可以将任何图层用于语音触发器,只要它们有通向另一个画板的句柄即可。 让我们将画板连接在一起。
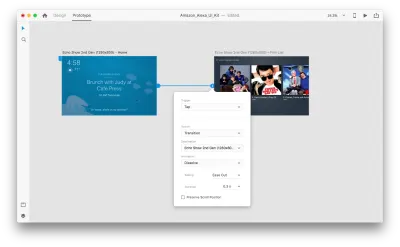
一旦我们这样做,我们将在“触发器”下找到一个新的“语音”选项。 当我们选择此选项时,我们将看到一个“命令”字段,我们可以使用它来输入话语——这就是 XD 实际监听的内容。 用户需要说出此命令才能激活触发器。
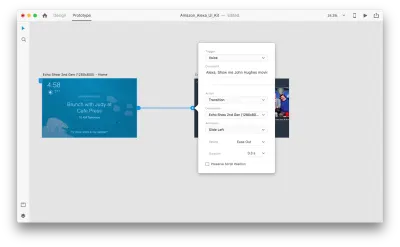
就这样! 我们已经定义了我们的第一个语音交互。 现在,用户可以说点什么,原型就会做出响应。 但是我们可以通过添加语音播放来使这种交互更加强大。 正如我之前提到的,语音播放允许系统说出一些单词。
选择整个第二个画板,然后单击蓝色手柄。 选择一个带有延迟的“时间”触发器并将其设置为 0.2 秒。 在该动作下,您会找到“语音播放”。 我们将记下虚拟助手对我们说的话。
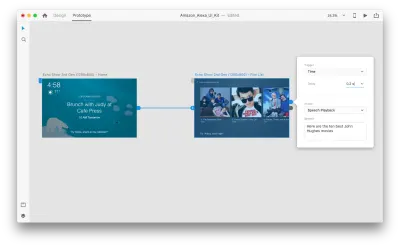
我们已准备好测试我们的原型。 选择第一个画板,然后单击右上角的播放按钮将启动一个预览窗口。 与语音原型交互时,请确保您的麦克风已打开。 然后,按住空格键说出语音命令。 这个输入触发原型中的下一个动作。
使用自动动画使体验更加动态
动画给 UI 设计带来了很多好处。 它具有明确的功能目的,例如:
- 传达对象之间的空间关系(对象来自哪里?这些对象是否相关?);
- 交流可供性(接下来我能做什么?)
但功能性目的并不是动画的唯一好处。 动画还使体验更加生动和动态。 这就是为什么 UI 动画应该是多模式界面的自然组成部分。
借助 Adobe XD 中的“自动动画”功能,创建具有沉浸式动画过渡的原型变得更加容易。 Adobe XD 为您完成所有繁重的工作,因此您无需担心。 要在两个画板之间创建动画过渡,您只需复制一个画板,修改克隆中的对象属性(大小、位置和旋转等属性),然后应用自动动画操作。 XD 将自动为每个画板之间的属性差异设置动画。
让我们看看它在我们的设计中是如何工作的。 假设我们在 Amazon Echo Show 中有一个现有的购物清单,并且想要使用语音向清单中添加一个新对象。 复制以下画板:
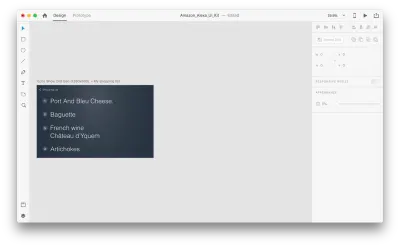
让我们介绍一下布局的一些变化: 添加一个新对象。 我们不限于此,因此我们可以轻松地修改任何属性,例如文本属性、颜色、不透明度、对象的位置——基本上,我们所做的任何更改,XD 都会在它们之间生成动画。
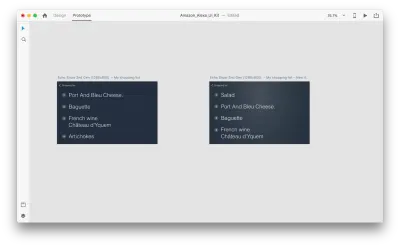
当您在原型模式下使用“动作”中的自动动画将两个画板连接在一起时,XD 将自动为每个画板之间的属性差异设置动画。
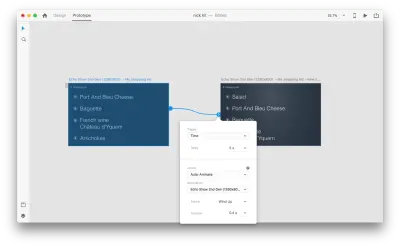
以下是用户对交互的看法:

需要提及的一件关键事情:保持所有层的名称相同; 否则,Adobe XD 将无法应用自动动画。
结论
我们正处于用户界面革命的黎明。 新一代的界面——多模式界面——不仅会给用户更多的权力,也会改变用户与系统交互的方式。 We will probably still have displays, but we won't need keyboards to interact with the systems.
At the same time, the fundamental requirements for designing multimodal interfaces won't be much different from those of designing modern interfaces. Designers will need to keep the interaction simple; focus on the user and their needs; design, prototype, test and iterate.
And the great thing is that you don't need to wait to start designing for this new generation of interfaces. 你可以从今天开始。
本文是 Adobe 赞助的 UX 设计系列的一部分。 Adobe XD 工具专为快速流畅的 UX 设计流程而设计,因为它可以让您更快地从构思转变为原型。 设计、原型制作和分享——都在一个应用程序中。 您可以在 Behance 上查看使用 Adobe XD 创建的更多鼓舞人心的项目,还可以注册 Adobe 体验设计时事通讯,以了解最新的 UX/UI 设计趋势和见解。