
2022 年 15 个机器学习面试问题和答案
已发表: 2021-01-08您是希望在机器学习领域取得成功的人吗? 如果是这样,对你来说太好了!
但首先,您必须为破冰船——ML 面试做好准备。
由于准备面试的过程可能会让人不知所措,因此我们决定介入 - 这是机器学习面试中 15 个最常见问题的精选列表!
- 深度学习和机器学习有什么区别?
机器学习涉及应用和使用高级算法来解析数据,发现数据中隐藏的模式并从中学习,最后应用所学的见解来做出明智的业务决策。 至于深度学习,它是机器学习的一个子集,涉及使用从人脑的神经网络结构中汲取灵感的人工神经网络。 深度学习广泛用于特征检测。
- 定义——精确度和召回率。
精度或正预测值衡量或更精确地预测模型声称的真实阳性数量与其实际声称的阳性数量相比。
召回率或真阳性率是指模型声称的阳性数与整个数据中存在的实际阳性数相比。

加入来自世界顶级大学的在线机器学习课程——硕士、高管研究生课程和 ML 和 AI 高级证书课程,以加快您的职业生涯。
- 解释术语“偏差”和“方差”。 '
在训练过程中,学习算法的预期误差通常被分类或分解为两部分——偏差和方差。 虽然“偏差”是由于在学习算法中使用简单假设而导致的错误情况,但“方差”表示由于该学习算法在数据分析中的复杂性而导致的错误。 偏差衡量学习算法创建的平均分类器与目标函数的接近程度,方差衡量学习算法的预测对于不同训练数据集的变化程度。
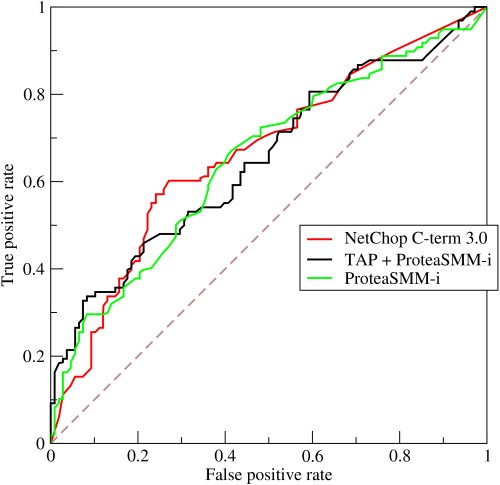
- ROC 曲线如何发挥作用?
ROC 或接收者操作特征曲线是真阳性率和假阳性率在不同阈值下的变化的图形表示。 它是诊断测试评估的基本工具,通常用作模型灵敏度(真阳性)与触发误报概率(假阳性)之间的权衡取舍。
资源
- 该曲线描绘了敏感性和特异性之间的权衡——如果敏感性增加,特异性就会降低。
- 如果曲线更靠近左轴和 ROC 空间的顶部,则测试通常更准确。 但是,如果曲线更接近 ROC 空间的 45 度对角线,则测试的准确性或可靠性会降低。
- 切点处切线的斜率表示该特定检验值的似然比 (LR)。
- 曲线下面积衡量测试精度。
- 解释类型 1 和类型 2 错误之间的区别?
类型 1 错误是一种误报错误,它“声称”发生了事件,而实际上没有发生任何事情。 误报错误的最佳示例是误报火警——当没有火灾时警报开始响起。 与此相反,类型 2 错误是一种假阴性错误,当某些事情确实发生时,它“声称”没有发生任何事情。 告诉孕妇她没有怀孕是第 2 类错误。
- 为什么贝叶斯被称为“朴素贝叶斯”?
朴素贝叶斯之所以被称为“朴素”,是因为它虽然有很多实际应用,但它基于在现实生活数据中不可能找到的假设——数据集中的所有特征都是至关重要的、独立的和平等的。 在朴素贝叶斯方法中,条件概率被计算为单个组件概率的纯乘积,从而暗示特征的完全独立性。 不幸的是,这个假设在现实世界中永远无法实现。
- 术语“过度拟合”是什么意思? 你能避免吗? 如果是这样,怎么做?
通常,在训练过程中,模型会被输入大量数据。 在这个过程中,数据甚至从样本数据集中存在的不准确信息和噪声中开始学习。 这会对模型在新数据上的性能产生负面影响,即模型无法准确地将新实例/数据与训练集分开。 这被称为过度拟合。
是的,可以避免过度拟合。 这是如何做:
- 收集更多数据(来自不同来源)以使用不同样本训练模型。
- 应用使用 bagging 方法的集成方法(例如,随机森林),通过将多个决策树的结果并列在数据集的不同单元上来最小化预测的变化。
- 确保使用交叉验证技术。
- 命名监督学习中用于校准的两种方法。
监督学习中的两种校准方法是——普拉特校准和等渗回归。 这两种方法都是专门为二进制分类而设计的。
- 为什么要修剪决策树?
需要修剪决策树以去除预测能力较弱的分支。 这有助于最小化决策树模型的复杂度并优化其预测准确性。 修剪可以自上而下或自下而上进行。 减少错误修剪、成本复杂度修剪、错误复杂度修剪和最小错误修剪是一些最常用的决策树修剪方法。

- F1分数是什么意思?
简单来说,F1 分数是衡量模型性能的指标——模型的 Precision 和 Recall 的平均值,接近 1 的结果是最好的,接近 0 的结果是最差的。 F1 分数可用于不重视真阴性的分类测试。
- 区分生成算法和判别算法。
生成算法学习数据的类别,而判别算法学习不同数据类别之间的区别。 在分类任务方面,判别模型通常超过生成模型。
- 什么是集成学习?
集成学习使用学习算法的组合来优化模型的预测性能。 在这种方法中,分类器或专家等多个模型都被战略性地生成和组合,以防止模型中的过度拟合。 它主要用于增强模型的预测、分类、函数逼近、性能等。
- 定义“内核技巧”。
内核技巧方法涉及使用可以在更高维和隐式特征空间中操作的内核函数,而无需显式计算该维度内点的坐标。 核函数计算特征空间中存在的所有数据对的图像之间的内积。 与坐标的显式计算相比,此过程的计算成本更低,并且被称为内核技巧。
- 您应该如何处理数据集中丢失或损坏的数据?
要在数据集中查找丢失/损坏的数据,您必须删除行和列或将它们替换为其他值。 Pandas 库有两种很好的方法来查找丢失/损坏的数据——isnull() 和 dropna()。 这两个函数都专门设计用于帮助您查找数据缺失/损坏的数据行/列并删除这些值。
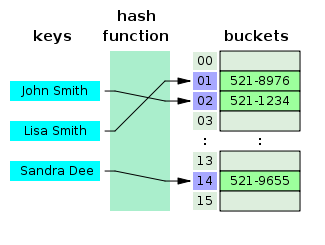
- 什么是哈希表?
哈希表是一种创建关联数组的数据结构,其中通过使用哈希函数将键映射到特定值。 哈希表主要用于数据库索引。
资源
这个问题列表只是为了向您介绍机器学习的基础知识,坦率地说,这二十个问题只是沧海一粟。 正如我们所说,机器学习正在进步,因此,随着时间的推移,新的概念将会出现。 因此,完成 ML 面试的关键在于保持不断学习和提升技能的冲动。 因此,开始并在互联网上肆虐、阅读期刊、加入在线社区、参加 ML 会议和研讨会——学习的方式有很多。
要进入一个大的组织,一个知名机构的证书是必不可少的。 查看 IIIT-B 的机器学习和 AI 执行 PG 计划,并从顶级 ML 和 AI 公司获得工作帮助。
集成学习的局限性是什么?
集成方法可以帮助减少方差和开发更稳健的模型。 然而,使用集成技术也有一些缺点,例如缺乏可解释性和性能。 此外,请记住,集成的功效源于它们聚合多个模型的能力,这些模型专注于问题的不同方面。 但是,它们确实有更长的预测期,因为您可能需要来自数百个模型的预测。 即使他们有更好的预测,准确性的提高也可能不值得。
学习机器学习需要多少时间?
在机器学习方面,用于相同目的的复杂技术可能很容易吓到人们。 但是,一点一点地理解它并不难。 统计学、高等数学等方面的经验无疑会帮助您快速掌握所有概念。 但是,由于教育背景和技能因人而异,一个人可能在三周内学习 ML,而另一个人可能需要一年时间。
机器学习如何在我们的日常生活中使用?
Gmail 通过使用机器学习将电子邮件分类为主要电子邮件、促销电子邮件、社交电子邮件和更新电子邮件,将它们分类为重要电子邮件。 公司正在利用神经网络根据最新交易频率、交易金额和商家类型等数据检测欺诈交易。 抄袭检测器也利用机器学习。 说到 ML 工程,大约需要六个月的时间才能完成。