
机器学习的 KNN 分类器:您需要知道的一切
已发表: 2021-09-28还记得人工智能(AI)只是科幻小说和电影的概念吗? 好吧,由于技术进步,人工智能是我们现在每天生活的东西。 从 Alexa 和 Siri 随时待命,到 OTT 平台“挑选”我们想看的电影,人工智能几乎已成为主流,并且在可预见的未来也将出现。
这一切都归功于先进的 ML 算法。 今天,我们将讨论一种这样有用的 ML 算法,即 K-NN 分类器。
作为人工智能和计算机科学的一个分支,机器学习使用数据和算法来模仿人类的理解,同时逐渐提高算法的准确性。 机器学习涉及训练算法以进行预测或分类,并发掘推动企业和应用程序内战略决策制定的关键见解。
KNN(k-nearest neighbour)算法是一种基本的监督机器学习算法,用于解决回归和分类问题陈述。 所以,让我们深入了解更多关于 K-NN 分类器的信息。
目录
监督与无监督机器学习
监督学习和无监督学习是两种基本的数据科学方法,在我们深入了解 KNN 的细节之前了解它们的区别是恰当的。
监督学习是一种机器学习方法,它使用标记的数据集来帮助预测结果。 此类数据集旨在“监督”或训练算法预测结果或准确分类数据。 因此,标记的输入和输出使模型能够随着时间的推移学习,同时提高其准确性。

监督学习涉及两类问题——分类和回归。 在分类问题中,算法将测试数据分配到离散的类别中,例如将猫与狗分开。
一个重要的现实示例是将垃圾邮件分类到与收件箱分开的文件夹中。 另一方面,监督学习的回归方法训练算法来理解自变量和因变量之间的关系。 它使用不同的数据点来预测数值,例如预测企业的销售收入。
相反,无监督学习使用机器学习算法对未标记的数据集进行分析和聚类。 因此,算法无需人工干预(“无监督”)来识别数据中的隐藏模式。
无监督学习模型具有三个主要应用——关联、聚类和降维。 但是,我们不会详细介绍,因为它超出了我们的讨论范围。
K-最近邻 (KNN)
K-Nearest Neighbor或KNN算法是一种基于监督学习模型的机器学习算法。 K-NN 算法的工作原理是假设相似的事物彼此靠近。 因此,K-NN 算法利用新数据点与训练集中点(可用案例)之间的特征相似性来预测新数据点的值。 本质上,K-NN 算法根据最新数据点与训练集中的点的相似程度为其分配一个值。 K-NN 算法在分类和回归问题中都有应用,但主要用于分类问题。
这是一个理解 K-NN 分类器的例子。

资源
在上图中,输入值是与猫和狗都相似的生物。 但是,我们想将它分类为猫或狗。 因此,我们可以使用 K-NN 算法进行此分类。 K-NN 模型将发现新数据集(输入)与可用猫狗图像(训练数据集)之间的相似性。 随后,模型将根据最相似的特征将新数据点放入猫或狗类别中。
同样,A 类(绿点)和 B 类(橙点)具有上述图形示例。 我们还有一个新的数据点(蓝点)将属于任一类别。 我们可以使用 K-NN 算法解决这个分类问题并识别新的数据点类别。
定义 K-NN 算法的属性
以下两个属性最好地定义了 K-NN 算法:
- 它是一种惰性学习算法,因为 K-NN 算法不是立即从训练集中学习,而是存储数据集并在分类时从数据集中训练。
- K-NN 也是一种非参数算法,这意味着它不对基础数据做出任何假设。
K-NN 算法的工作原理
现在,让我们看一下以下步骤,以了解 K-NN 算法的工作原理。
第 1 步:加载训练和测试数据。
第二步:选择最近的数据点,即K的值。
第三步:计算K个邻居的距离(每行训练数据和测试数据的距离)。 欧几里得方法最常用于计算距离。
第四步:根据计算出的欧几里得距离取K个最近邻。
Step 5:在最近的K个邻居中,统计每个类别的数据点个数。
第 6 步:将新数据点分配给邻居数最多的类别。
第七步:结束。 模型现已准备就绪。
加入来自世界顶级大学的在线人工智能课程——硕士、高管研究生课程和 ML 和 AI 高级证书课程,以加快您的职业生涯。
选择 K 的值
K 是 K-NN 算法中的一个关键参数。 因此,在决定 K 值之前,我们需要记住一些要点。
使用误差曲线是确定 K 值的常用方法。下图显示了测试和训练数据的不同 K 值的误差曲线。

资源
在上面的图形示例中,训练数据中 K=1 时的训练误差为零,因为该点的最近邻居是该点本身。 然而,即使 K 值较低,测试误差也很高。这称为高方差或数据过度拟合。 测试误差随着我们增加 K 值而减小,但是在 K 达到一定值之后,我们看到测试误差再次增加,称为偏差或欠拟合。 因此,由于方差,测试数据误差最初很高,随后降低并趋于稳定,并且随着 K 值的进一步增加,由于偏差,测试误差再次上升。

因此,取测试误差稳定且较低的K值作为K的最优值。考虑到上述误差曲线,K=8为最优值。
一个理解 K-NN 算法工作的例子
考虑如下绘制的数据集:

资源
假设在 (60,60) 处有一个新数据点(黑点),我们必须将其分类为紫色或红色类。 我们将使用 K=3,这意味着新数据点将找到三个最近的数据点,两个在红色类中,一个在紫色类中。
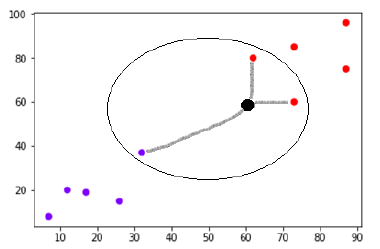
资源
最近邻是通过计算两点之间的欧几里得距离来确定的。 这是一个说明如何完成计算的插图。

资源
现在,由于新数据点(黑点)的最近邻居中有两个(三个中的一个)位于红色类中,因此新数据点也将分配给红色类。
加入来自世界顶级大学的在线机器学习课程——硕士、高级管理人员研究生课程和 ML 和 AI 高级证书课程,以加快您的职业生涯。
K-NN 作为分类器(Python 中的实现)
现在我们已经对 K-NN 算法进行了简单的解释,让我们通过 Python 实现 K-NN 算法。 我们将只关注 K-NN 分类器。
第 1 步:导入必要的 Python 包。

资源
第 2 步:从 UCI 机器学习存储库下载 iris 数据集。 它的网址是“https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data”
第 3 步:为数据集分配列名。

资源
第 4 步:将数据集读取到 Pandas DataFrame。

资源
第 5 步:使用以下脚本行完成数据预处理。

资源
第 6 步:将数据集划分为测试和训练拆分。 下面的代码会将数据集拆分为 40% 的测试数据和 60% 的训练数据。

资源
第七步:数据缩放如下:

资源
第 8 步:使用 sklearn 的 KNeighborsClassifier 类训练模型。

资源
第 9 步:使用以下脚本进行预测:

资源
第 10 步:打印结果。

资源
输出:

资源
接下来是什么? 注册 IIT Madras 和 upGrad 的机器学习高级证书课程
假设你渴望成为一名熟练的数据科学家或机器学习专业人士。 在这种情况下,来自 IIT Madras 和 upGrad 的机器学习和云高级认证课程就是为您准备的!
这个为期 12 个月的在线课程专为希望掌握机器学习、大数据处理、数据管理、数据仓库、云和机器学习模型部署方面的概念的在职专业人士而设计。
以下是一些课程亮点,可让您更好地了解该计划提供的内容:
- IIT Madras 全球认可的著名认证
- 500 多个小时的学习,20 多个案例研究和项目,25 多个行业指导课程,8 多个编码任务
- 全面覆盖 7 种编程语言和工具
- 为期 4 周的行业顶点项目
- 实用的实践研讨会
- 离线对等网络
立即注册以了解有关该计划的更多信息!
结论
随着时间的推移,大数据不断增长,人工智能越来越与我们的生活交织在一起。 因此,对数据科学专业人员的需求急剧增加,他们可以利用机器学习模型的力量来收集数据洞察力并改进关键业务流程,总的来说,我们的世界。 毫无疑问,人工智能和机器学习领域看起来确实很有前景。 使用upGrad ,您可以放心,您在机器学习和云计算领域的职业生涯是值得的!
为什么 K-NN 是一个好的分类器?
与其他机器学习算法相比,K-NN 的主要优势在于我们可以方便地使用 K-NN 进行多类分类。 因此,如果我们需要将数据分为两个以上的类别,或者如果数据包含两个以上的标签,K-NN 是最好的算法。 此外,它非常适合非线性数据,并且具有较高的准确性。
K-NN算法的局限性是什么?
K-NN 算法通过计算数据点之间的距离来工作。 因此,很明显它是一种相对耗时的算法,并且在某些情况下会花费更多时间进行分类。 因此,在使用 K-NN 进行多类分类时,最好不要使用过多的数据点。 其他限制包括高内存存储和对不相关特征的敏感性。
K-NN 的实际应用是什么?
K-NN 在机器学习中有几个现实生活用例,例如手写检测、语音识别、视频识别和图像识别。 在银行业,K-NN 用于根据个人是否具有与违约者相似的特征来预测个人是否有资格获得贷款。 在政治上,K-NN 可用于将潜在选民分为不同的类别,例如“将投票给 X 党”或“将投票给 Y 党”等。