
使用 React 和 Tesseract.js (OCR) 进行图像到文本的转换
已发表: 2022-03-10数据是每个软件应用程序的支柱,因为应用程序的主要目的是解决人类问题。 为了解决人类的问题,有必要掌握一些关于它们的信息。
这些信息被表示为数据,尤其是通过计算。 在网络上,数据主要以文本、图像、视频等形式收集。 有时,图像包含旨在处理以实现特定目的的基本文本。 这些图像大多是手动处理的,因为没有办法以编程方式处理它们。
无法从图像中提取文本是我在上一家公司亲身经历的数据处理限制。 我们需要处理扫描的礼品卡,而且我们必须手动完成,因为我们无法从图像中提取文本。
公司内部有一个叫做“运营”的部门,负责手动确认礼品卡和记入用户账户。 虽然我们有一个网站,用户可以通过它与我们联系,但礼品卡的处理是在幕后手动进行的。
当时,我们的网站主要使用 PHP(Laravel)作为后端,JavaScript(jQuery 和 Vue)作为前端。 只要管理层认为这个问题很重要,我们的技术堆栈就足以与 Tesseract.js 一起工作。
我愿意解决问题,但从业务或管理层的角度来看,没有必要解决问题。 离开公司后,我决定做一些研究,试图找到可能的解决方案。 最终,我发现了 OCR。
什么是 OCR?
OCR 代表“光学字符识别”或“光学字符阅读器”。 它用于从图像中提取文本。
OCR 的演变可以追溯到几项发明,但 Optophone、“Gismo”、CCD 平板扫描仪、Newton MesssagePad 和 Tesseract 是将字符识别提升到另一个实用水平的主要发明。
那么,为什么要使用 OCR? 嗯,光学字符识别解决了很多问题,其中一个触发了我写这篇文章。 我意识到从图像中提取文本的能力确保了很多可能性,例如:
- 规定
由于某些原因,每个组织都需要规范用户的活动。 该法规可用于保护用户的权利并保护他们免受威胁或诈骗。
从图像中提取文本使组织能够处理图像上的文本信息以进行监管,尤其是当图像由某些用户提供时。
例如,可以通过 OCR 实现类似于 Facebook 的对用于广告的图像上的文本数量的调节。 此外,OCR 还可以在 Twitter 上隐藏敏感内容。 - 可搜索性
搜索是最常见的活动之一,尤其是在互联网上。 搜索算法主要基于操作文本。 通过光学字符识别,可以识别图像上的字符,并使用它们为用户提供相关的图像结果。 简而言之,现在可以借助 OCR 搜索图像和视频。 - 可访问性
图像上的文本一直是可访问性的挑战,并且图像上的文本很少是经验法则。 使用 OCR,屏幕阅读器可以访问图像上的文本,从而为其用户提供一些必要的体验。 - 数据处理自动化 数据处理主要是自动化的规模化。 图像上的文本是数据处理的一个限制,因为除了手动之外无法处理文本。 光学字符识别 (OCR) 使得以编程方式提取图像上的文本成为可能,从而确保数据处理自动化,尤其是在处理图像上的文本时。
- 印刷材料的数字化
一切都在数字化,还有很多文件需要数字化。 支票、证书和其他物理文件现在可以使用光学字符识别进行数字化。
找出上面所有的用途加深了我的兴趣,所以我决定更进一步,问一个问题:
“我如何在 Web 上使用 OCR,尤其是在 React 应用程序中?”
这个问题让我想到了 Tesseract.js。
什么是 Tesseract.js?
Tesseract.js 是一个 JavaScript 库,可将原始 Tesseract 从 C 编译为 JavaScript WebAssembly,从而使 OCR 在浏览器中可访问。 Tesseract.js 引擎最初是用 ASM.js 编写的,后来被移植到 WebAssembly,但在某些不支持 WebAssembly 的情况下,ASM.js 仍然充当备份。
正如 Tesseract.js 网站上所说,它支持 100 多种语言,自动文本定位和脚本检测,用于阅读段落、单词和字符边界框的简单界面。
Tesseract 是用于各种操作系统的光学字符识别引擎。 它是免费软件,在 Apache 许可证下发布。 Hewlett-Packard 在 1980 年代开发了 Tesseract 作为专有软件。 它于 2005 年作为开源版本发布,自 2006 年以来其开发一直由 Google 赞助。
Tesseract 的最新版本第 4 版于 2018 年 10 月发布,它包含一个新的 OCR 引擎,该引擎使用基于长短期记忆 (LSTM) 的神经网络系统,旨在产生更准确的结果。
了解 Tesseract API
要真正了解 Tesseract 的工作原理,我们需要分解它的一些 API 及其组件。 根据 Tesseract.js 文档,有两种方法可以使用它。 以下是第一种方法及其分解:
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } recognize方法将图像作为第一个参数,语言(可以是多个)作为第二个参数, { logger: m => console.log(me) }作为最后一个参数。 Tesseract 支持的图像格式是 jpg、png、bmp 和 pbm,它们只能作为元素(img、视频或画布)、文件对象( <input> )、blob 对象、图像的路径或 URL 和 base64 编码图像提供. (阅读此处了解有关 Tesseract 可以处理的所有图像格式的更多信息。)
语言以字符串形式提供,例如eng 。 +符号可用于连接多种语言,如eng+chi_tra 。 语言参数用于确定要在图像处理中使用的训练语言数据。
注意:您会在此处找到所有可用的语言及其代码。
{ logger: m => console.log(m) }对于获取有关正在处理的图像的进度信息非常有用。 logger 属性采用一个函数,该函数将在 Tesseract 处理图像时被多次调用。 logger 函数的参数应该是一个具有workerId 、 jobId 、 status和progress作为其属性的对象:
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progress是一个介于 0 和 1 之间的数字,以百分比表示图像识别过程的进度。
Tesseract 自动生成对象作为 logger 函数的参数,但也可以手动提供。 随着识别过程的发生,每次调用函数时都会更新logger对象属性。 因此,它可用于显示转换进度条、更改应用程序的某些部分或用于实现任何所需的结果。
上面代码中的result是图像识别过程的结果。 result的每个属性都有属性 bbox 作为其边界框的 x/y 坐标。
以下是result对象的属性、含义或用途:
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text:所有已识别的文本作为字符串。 -
lines:每个已识别的文本行的数组。 -
words: 每个已识别单词的数组。 -
symbols:每个已识别字符的数组。 -
paragraphs:每个已识别段落的数组。 我们将在本文后面讨论“信心”。
Tesseract 也可以更强制地使用,如:
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();这种方法与第一种方法有关,但实现方式不同。
createWorker(options)创建一个 Web 工作者或节点子进程,该进程创建一个 Tesseract 工作者。 工作人员帮助设置 Tesseract OCR 引擎。 load()方法加载 Tesseract 核心脚本, loadLanguage()加载作为字符串提供给它的任何语言, initialize()确保 Tesseract 完全准备好使用,然后使用识别方法处理提供的图像。 terminate() 方法停止工作程序并清理所有内容。
注意:请查看 Tesseract API 文档以获取更多信息。
现在,我们必须构建一些东西来真正了解 Tesseract.js 的有效性。
我们要建造什么?
我们将构建一个礼品卡 PIN 提取器,因为从礼品卡中提取 PIN 是导致这次写作冒险的问题。
我们将构建一个从扫描的礼品卡中提取 PIN 的简单应用程序。 当我着手构建一个简单的礼品卡别针提取器时,我将带您了解我在此过程中面临的一些挑战、我提供的解决方案以及根据我的经验得出的结论。
- 转到源代码 →
下面是我们将用于测试的图像,因为它具有一些在现实世界中可能存在的真实属性。

我们将从卡中提取AQUX-QWMB6L-R6JAU 。 那么,让我们开始吧。
React 和 Tesseract 的安装
在安装 React 和 Tesseract.js 之前有一个问题需要解决,问题是,为什么将 React 与 Tesseract 一起使用? 实际上,我们可以将 Tesseract 与 Vanilla JavaScript、任何 JavaScript 库或框架(如 React、Vue 和 Angular)一起使用。
在这种情况下使用 React 是个人喜好。 最初,我想使用 Vue,但我决定使用 React,因为我对 React 比对 Vue 更熟悉。
现在,让我们继续安装。
要使用 create-react-app 安装 React,您必须运行以下代码:
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.js要么
npm install tesseract.js我决定使用 yarn 来安装 Tesseract.js,因为我无法使用 npm 安装 Tesseract,但 yarn 可以轻松完成工作。 您可以使用 npm,但根据我的经验,我建议使用 yarn 安装 Tesseract。
现在,让我们通过运行以下代码来启动我们的开发服务器:
yarn start要么
npm start运行 yarn start 或 npm start 后,您的默认浏览器应该会打开一个如下所示的网页:

如果页面未自动启动,您也可以在浏览器中导航到localhost:3000 。
安装 React 和 Tesseract.js 之后,下一步是什么?
设置上传表单
在这种情况下,我们将调整我们刚刚在浏览器中查看的主页(App.js)以包含我们需要的表单:
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App 上面代码中需要我们注意的部分是函数handleChange 。
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } 在该函数中, URL.createObjectURL通过event.target.files[0]获取选定的文件,并创建一个可以与 HTML 标签(如 img、audio 和 video)一起使用的参考 URL。 我们使用setImagePath将 URL 添加到状态。 现在,现在可以使用imagePath访问 URL。
<img src={imagePath} className="App-logo" alt="image"/> 我们将图像的 src 属性设置为{imagePath}以便在处理之前在浏览器中预览它。
将所选图像转换为文本
由于我们已经抓取了所选图像的路径,我们可以将图像的路径传递给 Tesseract.js 以从中提取文本。
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default App我们将函数“handleClick”添加到“App.js”中,它包含 Tesseract.js API,该 API 获取所选图像的路径。 Tesseract.js 接受“imagePath”、“language”、“a setting object”。
下面的按钮被添加到表单中以调用“handClick”,只要单击该按钮就会触发图像到文本的转换。
<button onClick={handleClick} style={{height:50}}> convert to text</button>当处理成功时,我们从结果中访问“置信度”和“文本”。 然后,我们使用“setText(text)”将“text”添加到状态中。
通过添加到<p> {text} </p> ,我们显示提取的文本。
很明显,“文本”是从图像中提取出来的,但什么是置信度?
置信度显示转换的准确性。 置信度在 1 到 100 之间。1 代表最差,而 100 代表准确度最好。 它还可用于确定提取的文本是否应被接受为准确的。
那么问题是哪些因素会影响置信度得分或整个转换的准确性? 它主要受三个主要因素的影响——所用文档的质量和性质、从文档创建的扫描质量以及 Tesseract 引擎的处理能力。
现在,让我们将下面的代码添加到“App.css”中以设置应用程序的样式。
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }这是我第一次测试的结果:
Firefox 中的结果
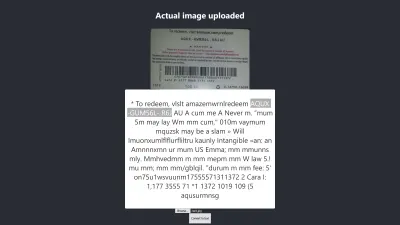
上述结果的置信度为 64。值得注意的是,礼品卡图像颜色较深,肯定会影响我们得到的结果。

如果您仔细查看上图,您会发现卡片上的图钉在提取的文本中几乎是准确的。 这是不准确的,因为礼品卡不是很清楚。
等一下! 它在 Chrome 中会是什么样子?
Chrome 中的结果
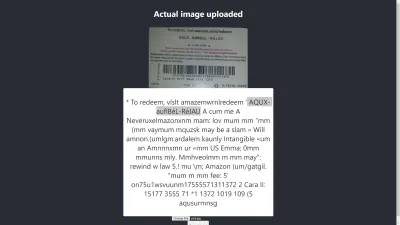
啊! 在 Chrome 中结果更糟。 但是为什么 Chrome 中的结果与 Mozilla Firefox 不同呢? 不同的浏览器以不同的方式处理图像及其颜色配置文件。 这意味着,可以根据浏览器以不同方式呈现图像。 通过向 Tesseract 提供预渲染的image.data ,它可能会在不同的浏览器中产生不同的结果,因为根据使用的浏览器向 Tesseract 提供不同的image.data 。 正如我们将在本文后面看到的那样,预处理图像将有助于获得一致的结果。
我们需要更加准确,以确保我们获得或提供正确的信息。 所以我们必须更进一步。
让我们多尝试一下,看看最终能不能达到目的。
测试准确性
有很多因素会影响使用 Tesseract.js 进行图像到文本的转换。 这些因素中的大多数都与我们要处理的图像的性质有关,其余的取决于 Tesseract 引擎如何处理转换。
在内部,Tesseract 在实际 OCR 转换之前对图像进行预处理,但它并不总是给出准确的结果。
作为一种解决方案,我们可以对图像进行预处理以实现准确的转换。 我们可以对图像进行二值化、反转、扩张、歪斜或重新缩放,以便为 Tesseract.js 对其进行预处理。
图像预处理本身就是一项大量工作或一个广泛的领域。 幸运的是,P5.js 提供了我们想要使用的所有图像预处理技术。 我没有仅仅因为我们想使用其中的一小部分而重新发明轮子或使用整个库,而是复制了我们需要的那些。 所有的图像预处理技术都包含在 preprocess.js 中。
什么是二值化?
二值化是将图像的像素转换为黑色或白色。 我们想对之前的礼品卡进行二值化,以检查准确性是否会更好。
以前,我们从礼品卡中提取了一些文本,但目标 PIN 并没有我们想要的准确。 因此,需要找到另一种方法来获得准确的结果。
现在,我们要对礼品卡进行二值化,即将其像素转换为黑白,这样我们就可以看到是否可以达到更好的精度水平。
下面的函数将用于二值化,它包含在一个名为 preprocess.js 的单独文件中。
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImage上面的代码有什么作用?
我们引入画布来保存图像数据以应用一些过滤器,对图像进行预处理,然后将其传递给 Tesseract 进行转换。
第一个preprocessImage函数位于preprocess.js中,并通过获取其像素来准备画布以供使用。 函数thresholdFilter通过将其像素转换为黑色或白色来对图像进行二值化。
让我们调用preprocessImage看看从之前的礼品卡中提取的文本是否可以更准确。
当我们更新 App.js 时,它现在应该看起来像这样的代码:
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default App首先,我们必须使用以下代码从“preprocess.js”中导入“preprocessImage”:
import preprocessImage from './preprocess'; 然后,我们在表单中添加一个画布标签。 我们将 canvas 和 img 标签的 ref 属性分别设置为{ canvasRef }和{ imageRef } 。 refs 用于从 App 组件访问画布和图像。 我们使用“useRef”获取画布和图像,如下所示:
const canvasRef = useRef(null); const imageRef = useRef(null);在这部分代码中,我们将图像合并到画布中,因为我们只能在 JavaScript 中预处理画布。 然后我们将其转换为以“jpeg”为图像格式的数据 URL。
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");“dataUrl”作为要处理的图像传递给 Tesseract。
现在,让我们检查提取的文本是否会更准确。
测试#2

上图显示了 Firefox 中的结果。 很明显,图像的暗部分已更改为白色,但对图像进行预处理并不能得到更准确的结果。 情况更糟。
第一次转换只有两个不正确的字符,但这次转换有四个不正确的字符。 我什至尝试更改阈值级别,但无济于事。 我们没有得到更好的结果不是因为二值化不好,而是因为二值化图像并不能以适合 Tesseract 引擎的方式修复图像的性质。
让我们看看它在 Chrome 中的样子:

我们得到相同的结果。
通过二值化图像得到更差的结果后,需要检查其他图像预处理技术,看看我们是否可以解决问题。 所以,接下来我们将尝试膨胀、反转和模糊。
让我们从本文使用的 P5.js 中获取每种技术的代码。 我们会将图像处理技术添加到 preprocess.js 中并一一使用。 在使用它们之前,有必要了解我们想要使用的每一种图像预处理技术,因此我们将首先讨论它们。
什么是膨胀?
膨胀是将像素添加到图像中对象的边界,以使其更宽、更大或更开放。 “扩张”技术用于预处理我们的图像以增加图像上对象的亮度。 我们需要一个函数来使用 JavaScript 扩大图像,因此将扩大图像的代码片段添加到 preprocess.js。
什么是模糊?
模糊是通过降低图像的清晰度来平滑图像的颜色。 有时,图像有小点/补丁。 要删除这些补丁,我们可以模糊图像。 模糊图像的代码片段包含在 preprocess.js 中。
什么是反转?
反转是将图像的浅色区域变为深色,将深色区域变为浅色。 例如,如果图像具有黑色背景和白色前景,我们可以将其反转,使其背景为白色,前景为黑色。 我们还添加了将图像反转为 preprocess.js 的代码片段。
在“preprocess.js”中添加dilate 、 invertColors和blurARGB后,我们现在可以使用它们来预处理图像。 要使用它们,我们需要更新 preprocess.js 中初始的“preprocessImage”函数:
preprocessImage(...)现在看起来像这样:
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } 在上面的preprocessImage中,我们对图像应用了四种预处理技术: blurARGB()用于去除图像上的点,dilate( dilate()用于增加图像的亮度, invertColors()用于切换图像的前景色和背景色以及thresholdFilter()将图像转换为更适合 Tesseract 转换的黑白。
thresholdFilter()将image.data和level作为其参数。 level用于设置图像应该是多白或多黑。 我们通过反复试验确定了thresholdFilter级别和blurRGB半径,因为我们不确定图像应该是多白、多暗或多平滑才能让 Tesseract 产生出色的结果。
测试#3
这是应用四种技术后的新结果:

上图代表了我们在 Chrome 和 Firefox 中得到的结果。
哎呀! 结果很可怕。
与其使用所有四种技术,不如一次使用其中两种?
是的! 我们可以简单地使用invertColors和thresholdFilter技术将图像转换为黑白,并切换图像的前景和背景。 但是我们怎么知道要结合什么和什么技术呢? 根据要预处理的图像的性质,我们知道要组合什么。
例如,必须将数字图像转换为黑白图像,并且必须对带有斑块的图像进行模糊处理以去除点/斑块。 真正重要的是了解每种技术的用途。
要使用invertColors和thresholdFilter ,我们需要在preprocessImage中注释掉blurARGB和dilate :
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }测试#4
现在,这是新的结果:

结果仍然比没有任何预处理的结果差。 在为这个特定图像和其他一些图像调整了每种技术之后,我得出的结论是,具有不同性质的图像需要不同的预处理技术。
简而言之,使用没有图像预处理的 Tesseract.js 为上面的礼品卡产生了最好的结果。 所有其他图像预处理实验都产生了不太准确的结果。
问题
最初,我想从任何亚马逊礼品卡中提取 PIN,但我无法实现,因为没有必要匹配不一致的 PIN 以获得一致的结果。 尽管可以对图像进行处理以获得准确的 PIN,但是当使用另一个具有不同性质的图像时,这种预处理将不一致。
产生的最佳结果
下图展示了实验产生的最佳结果。
测试#5

图片上的文字和提取出来的文字完全一样。 转换具有 100% 的准确性。 我试图重现结果,但只有在使用具有相似性质的图像时才能重现它。
观察与教训
- 一些未经预处理的图像在不同的浏览器中可能会给出不同的结果。 这种说法在第一次测试中很明显。 Firefox 中的结果与 Chrome 中的结果不同。 但是,预处理图像有助于在其他测试中获得一致的结果。
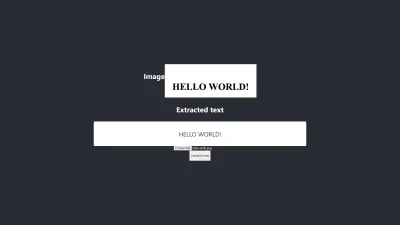
- 白色背景上的黑色往往会产生易于管理的结果。 下图是未经任何预处理的准确结果示例。 通过对图像进行预处理,我也能够获得相同水平的准确度,但我需要进行大量不必要的调整。
转换是 100% 准确的。
- 大字体的文本往往更准确。
- 具有弯曲边缘的字体往往会混淆 Tesseract。 当我使用 Arial(字体)时,我得到了最好的结果。
- OCR 目前还不足以自动进行图像到文本的转换,尤其是在需要超过 80% 的准确度时。 但是,它可以通过提取文本进行手动校正,从而减轻对图像文本进行手动处理的压力。
- OCR 目前还不足以将有用的信息传递给屏幕阅读器以实现可访问性。 向屏幕阅读器提供不准确的信息很容易误导或分散用户的注意力。
- OCR 非常有前途,因为神经网络使学习和改进成为可能。 深度学习将使 OCR 在不久的将来成为游戏规则的改变者。
- 充满信心地做出决定。 置信度分数可用于做出对我们的应用程序产生重大影响的决策。 置信度分数可用于确定是接受还是拒绝结果。 根据我的经验和实验,我意识到任何低于 90 的置信度分数都不是真正有用的。 如果我只需要从文本中提取一些图钉,我预计置信度得分在 75 到 100 之间,低于 75 的任何内容都将被拒绝。
如果我处理文本而不需要提取它的任何部分,我肯定会接受 90 到 100 之间的置信度分数,但拒绝任何低于该分数的分数。 例如,如果我想对支票、历史汇票等文件进行数字化,或者在需要精确副本的情况下,预计准确度会达到 90 或以上。 但是,当准确的副本不重要(例如从礼品卡中获取 PIN)时,75 到 90 之间的分数是可以接受的。 简而言之,置信度分数有助于做出影响我们应用程序的决策。
结论
鉴于图像上的文本造成的数据处理限制以及与之相关的缺点,光学字符识别 (OCR) 是一种值得采用的有用技术。 尽管 OCR 有其局限性,但由于它使用了神经网络,因此它非常有前途。
随着时间的推移,OCR 将在深度学习的帮助下克服其大部分限制,但在此之前,本文重点介绍的方法可以用于处理从图像中提取文本,至少可以减少与手动相关的困难和损失处理——尤其是从业务的角度来看。
现在轮到您尝试 OCR 从图像中提取文本了。 祝你好运!
延伸阅读
- P5.js
- OCR 中的预处理
- 提高输出质量
- 使用 JavaScript 为 OCR 预处理图像
- 使用 Tesseract.js 在浏览器中进行 OCR
- 光学字符识别简史
- OCR 的未来是深度学习
- 光学字符识别时间线