
CNN 中的图像分类:你需要知道的一切
已发表: 2021-02-25目录
介绍
在浏览 Facebook 提要时,您是否想过合影中的人是如何被 Facebook 的软件自动标记的? 在你看到的每个 Facebook 交互式用户界面的背后,都有一个复杂而强大的算法,用于识别和标记我们上传到社交媒体平台的每张图片。 对于我们的每一张照片,我们只会帮助提高算法的效率。 是的,图像分类是我们看到人工智能应用最广泛使用的算法之一。
最近,卷积神经网络 (CNN) 已成为深度学习最有力的支持者之一。 这些卷积网络的一种流行应用是图像分类。 在本教程中,我们将介绍卷积神经网络的基础知识,了解构建 CNN 模型所涉及的各个层,最后可视化图像分类任务的示例。
图像分类
在深入了解深度学习和卷积神经网络的细节之前,让我们了解一下图像分类的基础知识。 一般来说,图像分类被定义为我们将图像作为输入给使用特定算法构建的模型的任务,该算法输出图像所属的类别或类别的概率。 我们将图像标记到特定类别的这个过程称为监督学习。
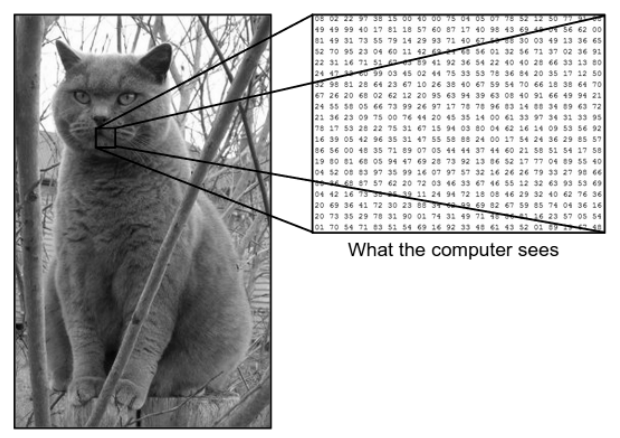
我们看到图像的方式与机器(计算机)看到相同图像的方式之间存在巨大差异。 对我们来说,我们能够可视化图像并根据颜色和大小对其进行表征。 另一方面,对于机器来说,它所看到的只是数字。 看到的数字称为像素。
每个像素都有一个介于 0 和 255 之间的值。因此,使用这些数字数据,机器需要一些预处理步骤,以便导出一些特定的模式或特征,将一个图像与另一个图像区分开来。 卷积神经网络帮助我们构建能够从图像中导出特定模式的算法。
我们看到的与计算机看到的
 来源-计算机和人眼之间的差异
来源-计算机和人眼之间的差异

图像分类的深度学习
现在我们已经了解了什么是图像分类,现在让我们看看如何使用人工智能来实现它。 为此,我们使用流行的深度学习方法。 深度学习是人工智能的一个子集,它利用大型图像数据集从各种图像中识别和派生模式,以区分图像数据集中存在的各种类别。
深度学习面临的主要挑战是,对于一个庞大的数据库,它需要很长时间,并且计算成本很高。 然而,作为一种深度学习算法的卷积神经网络很好地解决了这个问题。
卷积神经网络
在深度学习中,卷积神经网络是一类深度神经网络,主要用于视觉图像。 它们是由 Yann LeCunn 于 1998 年提出的人工神经网络 (ANN) 的一种特殊架构。 卷积神经网络由两部分组成。
第一部分由卷积层和池化层组成,主要特征提取过程在其中进行。 在第二部分中,Fully Connected 和 Dense 层对提取的特征执行几个非线性变换,并充当分类器部分。 学习 CNN 进行图像分类。
考虑上面显示的人和机器看到的图像示例。 正如我们所看到的,计算机看到了一个像素阵列。 例如,如果图像大小为 500×500,那么数组的大小将为 500x500x3。 这里,500 代表每个高度和宽度,3 代表 RGB 通道,其中每个颜色通道由一个单独的数组表示。 像素强度从 0 到 255 不等。
现在对于图像分类,计算机将在基本级别查找特征。 根据我们人类的说法,猫的这些基本特征是它的耳朵、鼻子和胡须。 而对于计算机来说,这些基本特征是曲率和边界。 通过这种方式,通过使用几个不同的层,例如卷积层和池化层,计算机从图像中提取基本级别的特征。
在卷积神经网络模型中,有几种类型的层,例如 -
- 输入层
- 卷积层
- 池化层
- 全连接层
- 输出层
- 激活函数
在我们进入图像分类中的应用之前,让我们简要介绍每一层。
输入层
从名称中,我们了解到这是将输入图像输入 CNN 模型的层。 根据我们的要求,我们可以将图像重塑为不同的大小,例如 (28,28,3)
卷积层
然后是最重要的层,它由一个固定大小的过滤器(也称为内核)组成。 卷积的数学运算是在输入图像和滤波器之间进行的。 这是从图像中提取大部分基本特征(例如锐利边缘和曲线)的阶段,因此该层也称为特征提取器层。
池化层
执行卷积操作后,我们执行池化操作。 这也称为下采样,其中图像的空间体积被减少。 例如,如果我们对尺寸为 28×28 的图像执行步长为 2 的池化操作,则图像尺寸缩小到 14×14,它会缩小到原始尺寸的一半。
全连接层
全连接层 (FC) 放置在 CNN 模型的最终分类输出之前。 这些层用于在分类之前将结果展平。 它涉及几个偏差、权重和神经元。 在分类之前附加一个 FC 层会产生一个 N 维向量,其中 N 是模型必须从中选择一个类的多个类。
输出层
最后,输出层由标签组成,该标签主要使用 one-hot 编码方法进行编码。
激活函数
这些激活函数是任何卷积神经网络模型的核心。 这些函数用于确定神经网络的输出。 简而言之,它决定了一个特定的神经元是否应该被激活(“激发”)。 这些通常是对输入信号执行的非线性函数。 然后将此转换后的输出作为输入发送到下一层神经元。 有几种激活函数,例如 Sigmoid、ReLU、Leaky ReLU、TanH 和 Softmax。
基本 CNN 架构
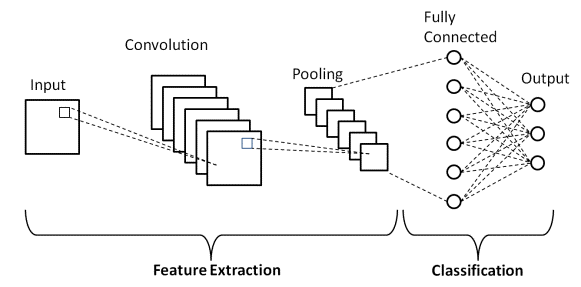
资料来源:基本 CNN 架构
如前所述,上图是卷积神经网络模型的基本架构。 现在我们已经准备好图像分类和 CNN 的基础知识,现在让我们深入研究它的实时问题应用。 了解有关基本 CNN 架构的更多信息。
卷积神经网络实现
现在我们已经了解了图像分类和卷积神经网络的基础知识,让我们用 Python 编码可视化它在 TensorFlow/Keras 中的实现。 在此,我们将使用基本 LeNet 架构构建一个简单的卷积神经网络模型,在训练集和测试集上训练模型,最终获得模型在测试集数据上的准确性。
问题集
在这篇用于构建和训练卷积神经网络模型的文章中,我们将使用著名的 Fashion MNIST 数据集。 MNIST 代表修改后的国家标准与技术研究所。 Fashion-MNIST 是 Zalando 文章图像的数据集——由 60,000 个示例的训练集和 10,000 个示例的测试集组成。 每个示例都是 28×28 灰度图像,与来自 10 个类别的标签相关联。
每个训练和测试示例都分配给以下标签之一:
0 – T 恤/上衣
1 – 裤子
2 – 套头衫
3 – 连衣裙
4 – 外套
5 – 凉鞋
6 – 衬衫
7 – 运动鞋
8 – 包
9 – 踝靴
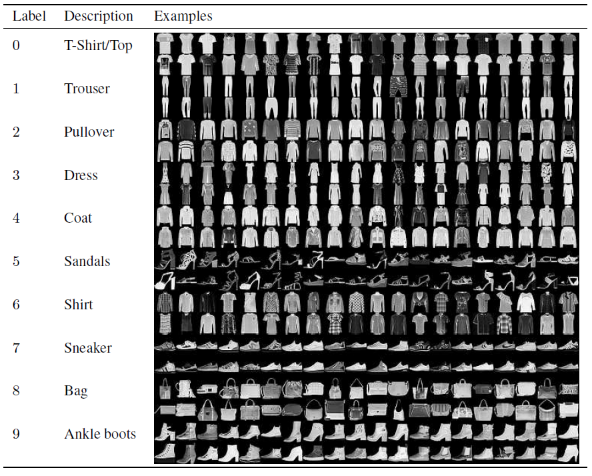
来源:时尚 MNIST 数据集图像

程序代码
第 1 步 - 导入库
构建任何深度学习模型的第一步是导入程序所需的库。 在我们的示例中,由于我们使用的是 TensorFlow 框架,我们将导入 Keras 库以及其他重要的库,例如用于计算的数字和用于绘制绘图的 matplotlib。
#TensorFlow – 导入库
将 numpy 导入为 np
将 matplotlib.pyplot 导入为 plt
%matplotlib 内联
将张量流导入为 tf
从张量流导入 Keras
第 2 步 - 获取和拆分数据集
导入库后,下一步是下载数据集并将 Fashion MNIST 数据集拆分为各自的 60,000 个训练数据和 10,000 个测试数据。 幸运的是,keras 为我们提供了一个预定义的函数来导入 Fashion MNIST 数据集,我们可以使用自己理解的简单代码行将它们拆分到下一行。
#TensorFlow – 获取和拆分数据集
fashion_mnist = keras.datasets.fashion_mnist
(train_images_tf, train_labels_tf), (test_images_tf, test_labels_tf) = fashion_mnist.load_data()
第 3 步 - 可视化数据
由于数据集与图像及其相应标签一起下载,为了让用户更清楚,始终建议查看数据,以便我们了解我们正在处理的数据类型,构建卷积神经网络相应的网络模型。 在这里,通过下面给出的这个简单代码块,我们将可视化随机打乱的训练数据集的前 3 张图像。
#TensorFlow – 数据可视化
定义 imshowTensorFlow(img):
plt.imshow(img, cmap='灰色')
打印(“标签:”,img [0])
imshowTensorFlow(train_images_tf[0])
标签:9标签:0标签:3
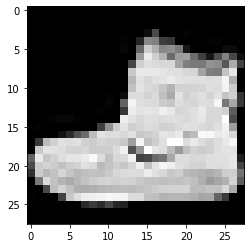


上面给出的图像及其标签可以使用上面 Fashion MNIST 数据集详细信息中给出的标签进行验证。 由此,我们推断我们的数据图像是一个灰度图像,高度为 28 像素,宽度为 28 像素。
因此,可以使用 (28,28,1) 的输入大小来构建模型,其中 1 代表灰度图像。
第 4 步 - 构建模型
如上所述,在本文中,我们将使用 LeNet 架构构建一个简单的卷积神经网络。 LeNet 是 Yann LeCun 等人提出的卷积神经网络结构。 1989年。一般来说,LeNet是指LeNet-5,是一个简单的卷积神经网络。
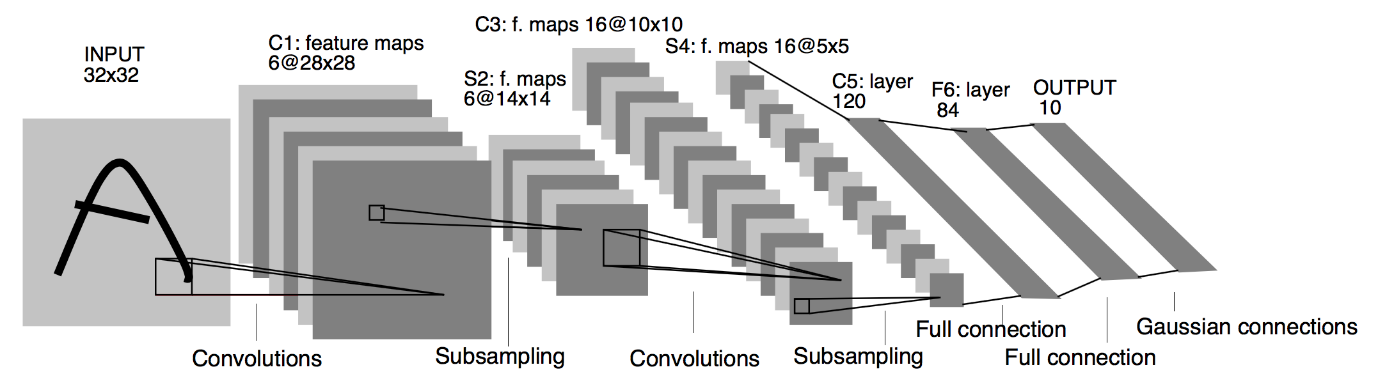
资料来源:LeNet 架构
从上面给出的 LeNet CNN 模型的架构图中,我们看到有 5+2 层。 第一层和第二层是卷积层,然后是池化层。 同样,第三和第四层由卷积层和池化层组成。 作为这些操作的结果,输入图像的大小从 28×28 减小到 7×7。
LeNet 模型的第五层是全连接层,它使前一层的输出变平。 接下来是两个 Dense 层,CNN 模型的最终输出层由一个具有 10 个单元的 Softmax 激活函数组成。 Softmax 函数为 Fashion MNIST 数据集的 10 个类别中的每一个预测类别概率。
#TensorFlow – 构建模型
模型 = keras.Sequential([
keras.layers.Conv2D(input_shape=(28,28,1), filters=6, kernel_size=5, strides=1, padding=”same”, activation=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, strides=2),
keras.layers.Conv2D(16, kernel_size=5, strides=1, padding=”same”, activation=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, strides=2),
keras.layers.Flatten(),
keras.layers.Dense(120, 激活=tf.nn.relu),
keras.layers.Dense(84, 激活=tf.nn.relu),
keras.layers.Dense(10, 激活=tf.nn.softmax)
])
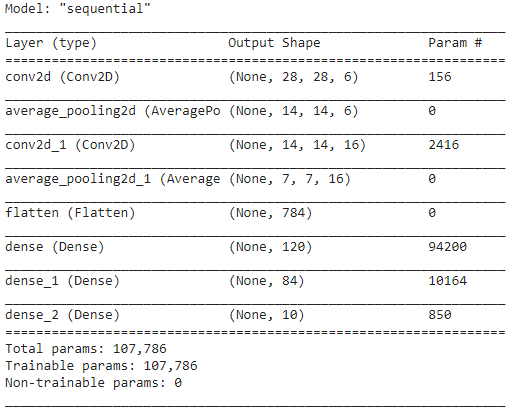
第 5 步 - 模型摘要
一旦 LeNet 模型的层最终确定,我们就可以继续编译模型并查看设计的 CNN 模型的摘要版本。
#TensorFlow – 模型摘要
model.compile(loss=keras.losses.categorical_crossentropy,
优化器='亚当',
指标=['acc'])
模型.summary()
在此,由于最终输出有超过 2 个类(10 个类),我们使用分类交叉熵作为损失函数,并使用 Adam Optimizer 来构建我们的模型。 模型总结如下。
第 6 步 - 训练模型
最后,我们开始了 LeNet CNN 模型的训练过程。 首先,我们重塑训练数据集并通过除以 255.0 将其归一化为更小的值,以降低计算成本。 然后将训练标签从整数类向量转换为二进制类矩阵。 例如,标签 3 转换为 [0, 0, 0, 1, 0, 0, 0, 0, 0]
#TensorFlow – 训练模型
train_images_tensorflow = (train_images_tf / 255.0).reshape(train_images_tf.shape[0], 28, 28, 1)
test_images_tensorflow = (test_images_tf / 255.0).reshape(test_images_tf.shape[0], 28, 28 ,1)
train_labels_tensorflow=keras.utils.to_categorical(train_labels_tf)
test_labels_tensorflow=keras.utils.to_categorical(test_labels_tf)
H = model.fit(train_images_tensorflow, train_labels_tensorflow, epochs=30, batch_size=32)
在 30 个 epoch 后的训练结束时,我们得到最终的训练准确率和损失:
时代 30/30
1875/1875 [===============================] – 4s 2ms/步 – 损失:0.0421 – acc: 0.9850
训练准确率:98.294997215271 %
训练损失:0.04584110900759697
第 7 步 – 预测结果
最后,一旦我们完成了 CNN 模型的训练过程,我们将在测试数据集上拟合相同的模型并预测 10,000 个测试图像的准确性。
#TensorFlow – 比较结果
预测 = model.predict(test_images_tensorflow)
正确 = 0
对于 i, pred in enumerate(predictions):
如果 np.argmax(pred) == test_labels_tf[i]:
正确 += 1
print('Test Accuracy of the model on the {} test images: {}% with TensorFlow'.format(test_images_tf.shape[0],100 * correct/test_images_tf.shape[0]))
我们得到的输出是,
模型在 10000 张测试图像上的测试准确率:90.67% 使用 TensorFlow
至此,我们结束了使用卷积神经网络构建图像分类模型的程序。
另请阅读:机器学习项目理念
结论
因此,在这篇关于在 CNN 中实现图像分类的教程中,我们了解了图像分类、卷积神经网络背后的基本概念,以及它在 Python 编程语言和 TensorFlow 框架中的实现。
如果您有兴趣了解有关机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,该文凭专为工作专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业、IIIT- B 校友身份、5 个以上实用的实践顶点项目和顶级公司的工作协助。
哪种 CNN 模型被认为最适合图像分类?
用于图像分类的最佳 CNN 模型是 VGG-16,它代表用于大规模图像识别的非常深卷积网络。 VGG 被设计为深度 CNN,在 ImageNet 之外的各种任务和数据集上都优于基线。 该模型的显着特点是,在创建它时,更多的注意力放在了合并优秀的卷积层上,而不是专注于添加大量的超参数。 它总共有 16 层,5 个块,每个块都有一个最大池化层,使其成为一个相当大的网络。
使用 CNN 模型进行图像分类的缺点是什么?
在图像分类方面,CNN 模型非常成功。 然而,使用 CNN 有几个缺点。 如果要识别的图片是倾斜的或者旋转的,那么CNN模型在准确识别图像时就会出现问题。 当 CNN 可视化图像时,没有组件及其部分-整体连接的内部表示。 此外,如果要使用的 CNN 模型包括许多卷积层,则分类过程将需要很长时间。
为什么使用 CNN 模型优于 ANN 将图像数据作为输入?
通过组合过滤器或转换,CNN 可以为作为输入提供的每张图像学习多层特征表示。 由于在 CNN 中要学习的网络参数数量比多层神经网络中的要少得多,因此减少了过度拟合。 使用 ANN 时,神经网络可以学习图像的单个特征表示,但在复杂图像的情况下,ANN 将无法提供改进的可视化或分类,因为它无法学习输入图像中存在的像素依赖性。