
如何在机器学习中实现分类?
已发表: 2021-03-12机器学习在各个领域的应用在过去几年中突飞猛进,而且还在继续。 机器学习模型最受欢迎的任务之一是识别对象并将它们分成指定的类。
这是分类方法,是机器学习最流行的应用之一。 分类用于将大量数据分成一组离散值,这些离散值可能是二进制的,例如 0/1、是/否,也可能是多类的,例如动物、汽车、鸟类等。
在接下来的文章中,我们将了解机器学习中分类的概念,所涉及的数据类型,并了解机器学习中用于对多个数据进行分类的一些最流行的分类算法。
目录
什么是监督学习?
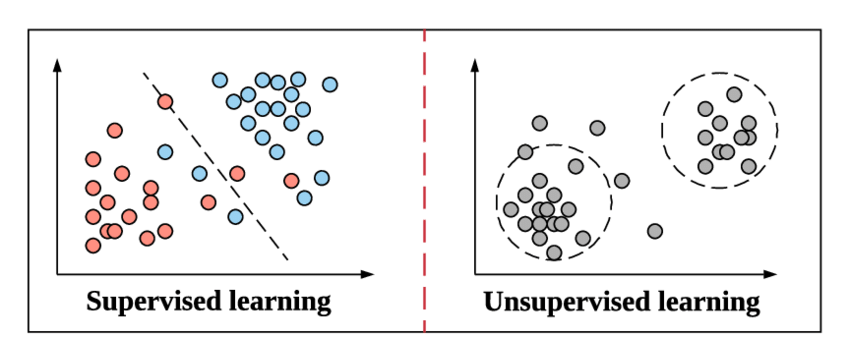
当我们准备深入了解分类及其类型的概念时,让我们快速了解监督学习的含义以及它与机器学习中其他无监督学习方法的区别。
让我们从高中物理课上举一个简单的例子来理解这一点。 假设有一个涉及新方法的简单问题。 如果我们遇到一个必须使用相同方法解决的问题,我们难道不都参考使用相同方法的示例问题并尝试解决它吗? 一旦我们对那个方法有信心,我们就不需要再次引用它并继续解决它。
资源

这与监督学习在机器学习中的工作方式相同。 它通过例子来学习。 为了让它更简单,在监督学习中,整个数据都被提供了它们相应的标签,因此在训练过程中,机器学习模型看起来将其特定数据的输出与相同数据的真实输出进行比较,并尝试最小化预测标签值和真实标签值之间的误差。
我们将在本文中介绍的分类算法遵循这种监督学习方法,例如垃圾邮件检测和对象识别。
无监督学习是上面的一个步骤,其中数据不带有标签。 从数据中导出模式并给出输出取决于机器学习模型的责任和效率。 聚类算法遵循这种无监督学习方法。
什么是分类?
分类被定义为识别、理解并将对象或数据分组到预设的类别中。 通过在机器学习模型的训练过程之前对数据进行分类,我们可以使用各种分类算法将数据分类为几个类别。 与回归不同,分类问题是输出变量是一个类别,例如“是”或“否”或“疾病”或“无疾病”。
在大多数机器学习问题中,一旦将数据集加载到程序中,在训练之前,将数据集分成固定比例的训练集和测试集(通常为 70% 的训练集和 30% 的测试集)。 这种分裂过程允许模型执行反向传播,其中它试图通过几个数学近似来纠正其预测值与真实值的误差。
同样,在我们开始分类之前,会创建训练数据集。 分类算法对其进行训练,同时在每次迭代(称为一个时期)对测试数据集进行测试。
资源
最常见的分类算法应用程序之一是过滤电子邮件,以确定它们是“垃圾邮件”还是“非垃圾邮件”。 简而言之,我们可以将机器学习中的分类定义为“模式识别”的一种形式,其中这些应用于训练数据的算法用于从数据中提取多种模式(例如相似的单词或数字序列、情绪等.)。
分类是将给定的一组数据分类为类的过程; 它可以在结构化或非结构化数据上执行。 它首先预测给定数据点的类别。 这些类也称为输出变量、目标标签等。一些算法具有内置的数学函数来近似从输入数据点变量到输出目标类的映射函数。 分类的主要目标是确定新数据将属于哪个类/类别。
机器学习中的分类算法类型
根据应用分类算法的数据类型,有两大类算法,线性模型和非线性模型。
线性模型
- 逻辑回归
- 支持向量机 (SVM)
非线性模型
- K-最近邻(KNN)分类
- 内核支持向量机
- 朴素贝叶斯分类
- 决策树分类
- 随机森林分类
在本文中,我们将简要介绍上述每种算法背后的概念。
机器学习中分类模型的评估
在我们进入上述这些算法的概念之前,我们必须了解如何评估基于这些算法构建的机器学习模型。 评估我们的模型在训练集和测试集上的准确性至关重要。
交叉熵损失或对数损失
这是我们将用于评估输出在 0 和 1 之间的分类器性能的第一种类型的损失函数。这主要用于二元分类模型。 对数损失公式由下式给出,
对数损失 = -((1 – y) * log(1 – yhat) + y * log(yhat))
其中,这是预测值,y 是实际值。
混淆矩阵
混淆矩阵是一个 NXN 矩阵,其中 N 是被预测的类数。 混淆矩阵为我们提供了一个矩阵/表格作为输出,并描述了模型的性能。 它由矩阵形式的预测结果组成,我们可以从中得出几个性能指标来评估分类模型。 它的形式是,
| 实际正面 | 实际负数 | |
| 预测阳性 | 真阳性 | 假阳性 |
| 预测负数 | 假阴性 | 真阴性 |
下面给出了可以从上表中得出的一些性能指标。
1.Accuracy——正确预测总数的比例。
2. 阳性预测值或精度——正确识别的阳性病例的比例。
3. 负预测值——正确识别的负例的比例。
4. 敏感性或召回率——正确识别的实际阳性病例的比例。
5. 特异性——被正确识别的实际负面案例的比例。
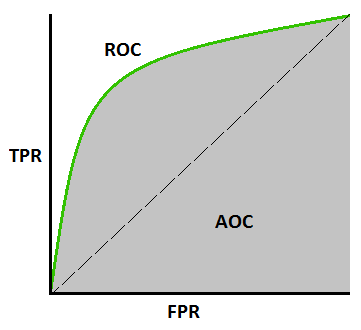
AUC-ROC 曲线 –
这是评估任何机器学习模型的另一个重要曲线指标。 ROC曲线代表接收器操作特征曲线,AUC代表曲线下面积。 ROC 曲线是用 TPR 和 FPR 绘制的,其中 TPR(真阳性率)在 Y 轴上,FPR(假阳性率)在 X 轴上。 它显示了分类模型在不同阈值下的性能。
资源
1. 逻辑回归
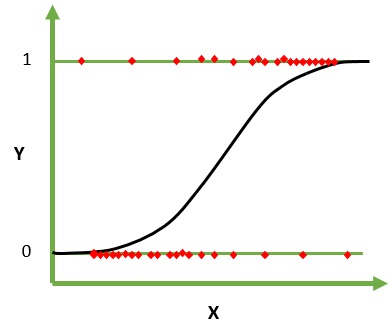
逻辑回归是一种用于分类的机器学习算法。 在该算法中,描述单个试验的可能结果的概率使用逻辑函数建模。 它假设输入变量是数字的并且具有高斯(钟形曲线)分布。
逻辑函数,也称为 sigmoid 函数,最初被统计学家用来描述生态学中的人口增长。 sigmoid 函数是一种数学函数,用于将预测值映射到概率。 Logistic 回归具有 S 形曲线,可以取 0 到 1 之间的值,但从不完全处于这些限制。
资源

逻辑回归主要用于预测二元结果,例如是/否和通过/失败。 自变量可以是分类变量或数值变量,但因变量始终是分类变量。 Logistic 回归的公式由下式给出,
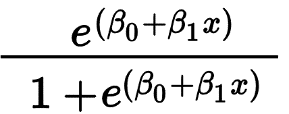
其中 e 表示 S 形曲线,其值介于 0 和 1 之间。
2. 支持向量机
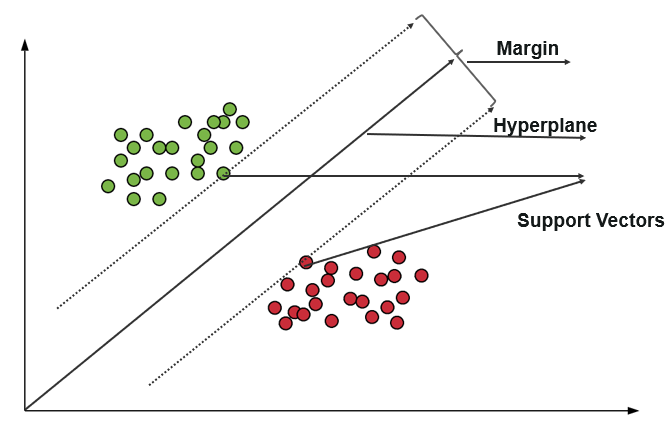
支持向量机 (SVM) 使用算法在极性程度内训练和分类数据,使其达到超出 X/Y 预测的程度。 在 SVM 中,用于分隔类的线称为超平面。 超平面两侧最靠近超平面的数据点称为支持向量,用于绘制边界线。
这种分类中的支持向量机将训练数据表示为空间中的数据点,其中许多类别被分成超平面类别。 当一个新点进入时,通过预测它们属于哪个类别并属于特定空间来对其进行分类。
资源
支持向量机的主要目的是最大化两个支持向量之间的边距。
加入来自世界顶级大学的ML在线课程——硕士、高级管理人员研究生课程和 ML 和 AI 高级证书课程,以加快您的职业生涯。
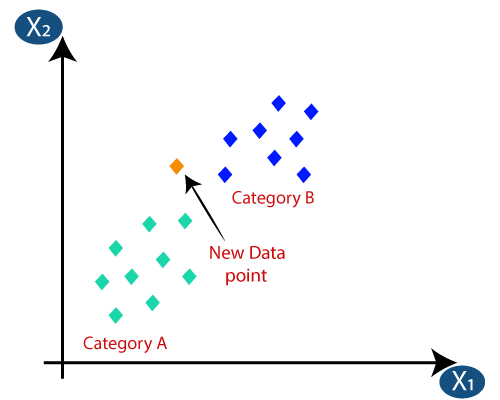
3. K-最近邻(KNN)分类
KNN分类是分类中最简单的算法之一,但因其高效易用而被高度使用。 在这种方法中,整个数据集最初存储在机器中。 然后,选择一个值 - k,它表示邻居的数量。 这样,当一个新的数据点被添加到数据集中时,它会将 k 个最近邻居的类标签的多数票投给该新数据点。 通过这次投票,新数据点被添加到投票最高的特定类中。
资源
4. 内核支持向量机
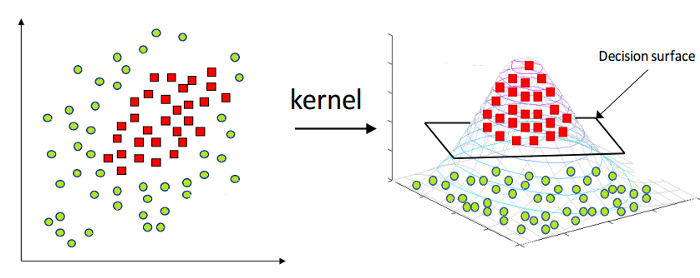
如上所述,线性支持向量机本质上只能应用于线性数据。 然而,世界上所有的数据都不是线性可分的。 因此,我们需要开发一个支持向量机来解释也是非线性可分的数据。 这里出现了内核技巧,也称为内核支持向量机或内核 SVM。
在 Kernel SVM 中,我们选择 RBF 或 Gaussian Kernel 等内核。 所有数据点都映射到更高的维度,在那里它们成为线性可分的。 通过这种方式,我们可以在数据集的不同类别之间创建决策边界。
资源
因此,通过这种方式,利用支持向量机的基本概念,我们可以设计一个非线性的核 SVM。
5.朴素贝叶斯分类
朴素贝叶斯分类的根源属于贝叶斯定理,假设数据集的所有自变量(特征)都是独立的。 它们在预测结果方面具有同等重要性。 贝叶斯定理的这个假设给出了名称——“朴素”。 它用于各种任务,例如垃圾邮件过滤和其他文本分类领域。 朴素贝叶斯计算数据点是否属于某个类别的可能性。
朴素贝叶斯分类的公式由下式给出,
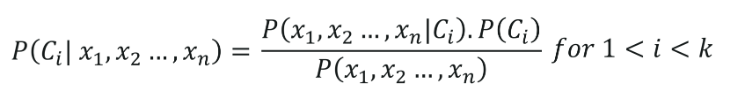
6.决策树分类
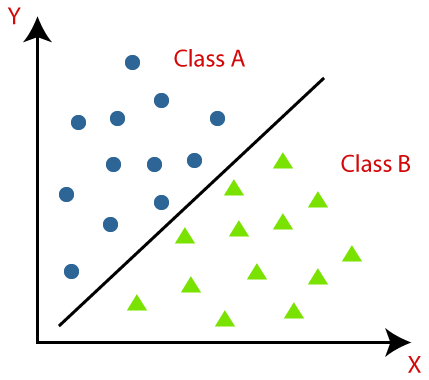
决策树是一种监督学习算法,非常适合分类问题,因为它可以在精确的级别上对类进行排序。 它以流程图的形式运行,在其中分离每个级别的数据点。 最终的结构看起来像一棵有节点和叶子的树。

资源
一个决策节点将有两个或多个分支,一个叶子代表一个分类或决策。 在上面的决策树示例中,通过提出几个问题,创建了一个流程图,这有助于我们解决预测是否上市的简单问题。
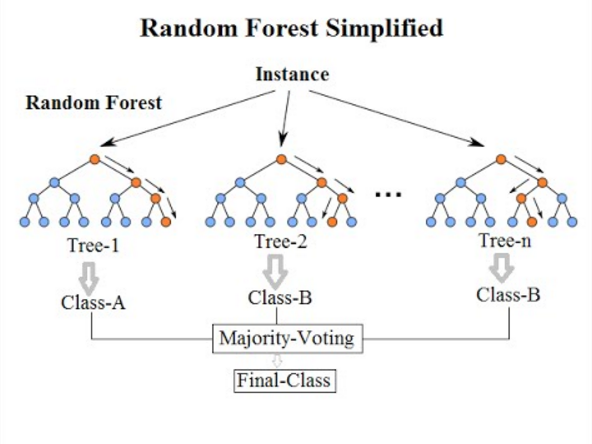
7. 随机森林分类
来到这个列表的最后一个分类算法,随机森林只是决策树算法的扩展。 随机森林是一种具有多个决策树的集成学习方法。 它的工作方式与决策树相同。
资源
随机森林算法是对现有决策树算法的改进,它存在“过度拟合”的主要问题。 与决策树算法相比,它也被认为更快、更准确。
另请阅读:机器学习项目的想法和主题
结论
因此,在这篇关于机器学习分类方法的文章中,我们了解了分类和监督学习的基础知识、分类模型的类型和评估指标,最后总结了所有最常用的机器学习分类模型。
如果您有兴趣了解有关机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和 AI 执行 PG 计划,该计划专为工作专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业、IIIT -B 校友身份,5 个以上实用的实践顶点项目和顶级公司的工作协助。
Q1。 机器学习中最常用的算法是什么?
机器学习采用了许多不同的算法,大致可以分为三大类——监督学习算法、无监督学习算法和强化学习算法。 现在,为了缩小和命名一些最常用的算法,必须提到的是线性回归、逻辑回归、SVM、决策树、随机森林算法、kNN、朴素贝叶斯理论、K-Means、降维、和梯度提升算法。 XGBoost、GBM、LightGBM 和 CatBoost 算法在梯度提升算法中值得特别提及。 这些算法可用于解决几乎任何类型的数据问题。
Q2。 什么是机器学习中的分类和回归?
分类和回归算法都广泛用于机器学习。 但是,它们之间存在许多差异,最终决定了它们的用途或目的。 主要区别在于,虽然分类算法用于分类或预测离散值,如男性-女性或真假,但回归算法用于预测非离散、连续值,如工资、年龄、价格等。决策树,随机森林、核支持向量机和逻辑回归是一些最常见的分类算法,而简单和多元线性回归、支持向量回归、多项式回归和决策树回归是机器学习中最流行的一些回归算法。
Q3。 学习机器学习的先决条件是什么?
要开始机器学习,您无需成为精通的数学家或专家级程序员。 然而,鉴于该领域的广阔,当您即将开始您的机器学习之旅时,您可能会感到害怕。 在这种情况下,了解先决条件可以帮助您顺利开始。 先决条件本质上是理解机器学习概念所需的核心技能。 因此,首先,确保您学习如何使用 Python 进行编码。 接下来,对统计学和数学,尤其是线性代数和多元微积分的基本了解,将是一个额外的优势。