
如何为机器学习选择特征选择方法
已发表: 2021-06-22目录
功能选择介绍
机器学习模型使用了许多特征,其中只有少数是重要的。 如果使用不必要的特征来训练数据模型,则模型的准确性会降低。 此外,模型的复杂性增加,泛化能力下降,导致模型有偏差。 “有时越少越好”这句话与机器学习的概念很吻合。 许多用户都面临过这个问题,他们发现很难从他们的数据中识别出相关特征集,而忽略所有不相关的特征集。 不太重要的特征被称为是因为它们对目标变量没有贡献。
因此,机器学习中的重要过程之一是特征选择。 目标是为机器学习模型的开发选择最好的特征集。 特征选择对模型的性能有巨大的影响。 除了数据清理,特征选择应该是模型设计的第一步。
机器学习中的特征选择可以概括为
- 自动或手动选择对预测变量或输出贡献最大的那些特征。
- 不相关特征的存在可能会导致模型的准确性降低,因为它会从不相关的特征中学习。
特征选择的好处
- 减少数据的过度拟合:更少的数据会导致更少的冗余。 因此,对噪声做出决策的机会较少。
- 提高模型的准确性:误导数据的可能性较小,提高了模型的准确性。
- 训练时间减少:去除不相关的特征会降低算法复杂度,因为只存在较少的数据点。 因此,算法训练得更快。
- 模型的复杂性随着对数据的更好解释而降低。
有监督和无监督的特征选择方法
特征选择算法的主要目标是为模型的开发选择一组最佳特征。 机器学习中的特征选择方法可以分为监督方法和无监督方法。
- 监督方法:监督方法用于从标记数据中选择特征,也用于相关特征的分类。 因此,所建立的模型的效率有所提高。
- 无监督方法:这种特征选择方法用于未标记的数据。
监督方法下的方法列表
机器学习中特征选择的监督方法可以分为

1. 包装方法
这种类型的特征选择算法基于算法的结果来评估特征的性能过程。 也称为贪心算法,它使用特征子集迭代地训练算法。 停止标准通常由训练算法的人定义。 模型中特征的添加和删除是基于模型的先前训练进行的。 在这种搜索策略中可以应用任何类型的学习算法。 与过滤方法相比,这些模型更准确。
Wrapper 方法中使用的技术有:
- 前向选择:前向选择过程是一个迭代过程,在每次迭代后添加改进模型的新特征。 它从一组空的功能开始。 迭代将继续并停止,直到添加不会进一步提高模型性能的特征。
- 向后选择/消除:该过程是一个迭代过程,从所有特征开始。 每次迭代后,从初始特征集中移除最不重要的特征。 迭代的停止标准是模型的性能没有随着特征的移除而进一步提高。 这些算法在 mlxtend 包中实现。
- 双向消除:在双向消除方法中同时应用正向选择和反向消除技术两种方法,以达到一个独特的解决方案。
- 详尽的特征选择:也称为评估特征子集的蛮力方法。 创建了一组可能的子集,并为每个子集构建了一个学习算法。 选择其模型提供最佳性能的子集。
- 递归特征消除(RFE):该方法被称为贪心方法,因为它通过递归地考虑越来越小的特征集来选择特征。 一组初始特征用于训练估计器,并使用 feature_importance_attribute 获得它们的重要性。 然后删除最不重要的特征,只留下所需数量的特征。 这些算法在 scikit-learn 包中实现。
图 4:展示递归特征消除技术的代码示例
2. 嵌入式方法
机器学习中的嵌入式特征选择方法通过包含特征交互并保持合理的计算成本,相对于过滤器和包装器方法具有一定的优势。 嵌入式方法中使用的技术有:
- 正则化:模型通过对模型的参数添加惩罚来避免数据的过度拟合。 系数与惩罚相加,导致一些系数为零。 因此,那些具有零系数的特征被从特征集中移除。 特征选择的方法使用 Lasso(L1 正则化)和弹性网络(L1 和 L2 正则化)。
- SMLR(稀疏多项逻辑回归):该算法通过 ARD 先验(自动相关性确定)对经典的多国逻辑回归进行稀疏正则化。 这种正则化估计每个特征的重要性并修剪对预测无用的维度。 该算法的实现是在 SMLR 中完成的。
- ARD(自动相关性确定回归):该算法将系数权重移向零,并且基于贝叶斯岭回归。 该算法可以在 scikit-learn 中实现。
- 随机森林重要性:此特征选择算法是指定数量的树的聚合。 该算法中基于树的策略根据增加节点的杂质或减少杂质(基尼杂质)进行排序。 树的末端由杂质减少最少的节点组成,树的开始由杂质减少最大的节点组成。 因此,可以通过修剪特定节点下的树来选择重要的特征。
3.过滤方法
在预处理步骤期间应用这些方法。 这些方法非常快速且成本低廉,并且在删除重复、相关和冗余特征方面效果最好。 不是应用任何监督学习方法,而是根据特征的固有特征来评估特征的重要性。 与特征选择的包装方法相比,该算法的计算成本更低。 但是,如果没有足够的数据来推导特征之间的统计相关性,则结果可能比包装方法更差。 因此,这些算法用于高维数据,如果要应用包装器方法,这将导致更高的计算成本。

Filter 方法中使用的技术是:
- 信息增益:信息增益是指从特征中获得多少信息来识别目标值。 然后它测量熵值的减少。 考虑到特征选择的目标值,计算每个属性的信息增益。
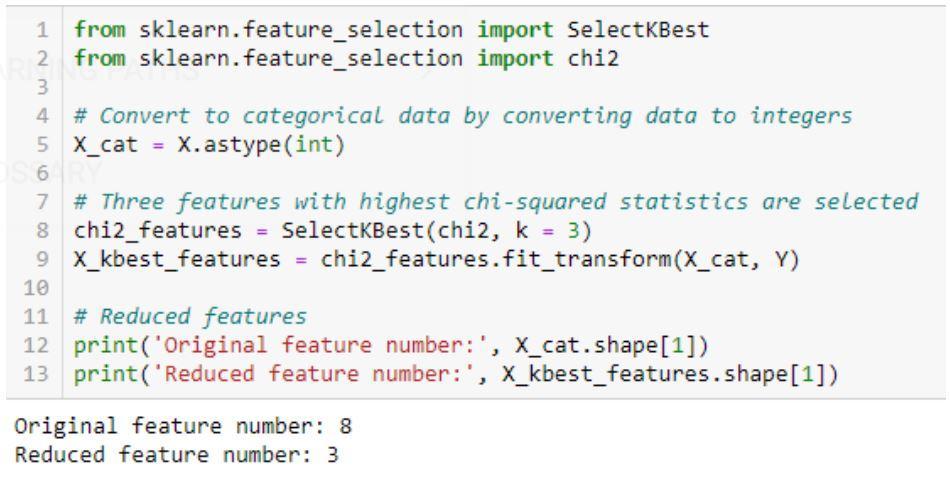
- 卡方检验:卡方法(X 2 )一般用于检验两个分类变量之间的关系。 该测试用于识别来自数据集不同属性的观察值与其期望值之间是否存在显着差异。 零假设表明两个变量之间没有关联。
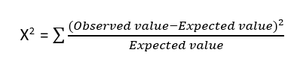
资源
卡方检验的公式
卡方算法的实现:sklearn、scipy
卡方检验代码示例
资源
- CFS(基于相关性的特征选择):该方法遵循“CFS(基于相关的特征选择)的实现:scikit-feature
加入来自世界顶级大学的在线AI 和 ML 课程——硕士、高级管理人员研究生课程和 ML 和 AI 高级证书课程,以加快您的职业生涯。
- FCBF(Fast correlation-based filter):与上述Relief和CFS方法相比,FCBF方法更快更高效。 最初,对所有特征进行对称不确定性的计算。 使用这些标准,然后对特征进行分类并删除冗余特征。
对称不确定性= x 的信息增益 | y 除以它们的熵之和。 FCBF的实现:skfeature
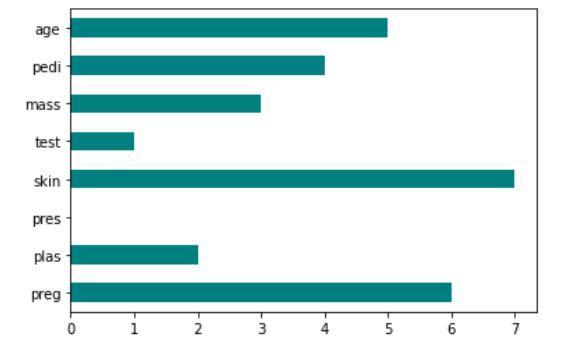
- Fischer 分数: Fischer 比率 (FIR) 定义为每个特征的每个类别的样本均值之间的距离除以它们的方差。 每个特征都是根据他们在 Fisher 标准下的分数独立选择的。 这导致了一组次优的特征。 较大的 Fisher 分数表示选择更好的特征。
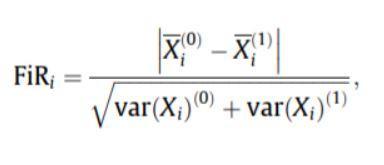
资源
Fischer 分数的公式
Fisher分数的实现:scikit-feature
显示 Fisher 评分技术的代码输出
资源
皮尔逊相关系数:它是量化两个连续变量之间关联的量度。 相关系数的值范围从 -1 到 1,它定义了变量之间的关系方向。
- 方差阈值:方差不满足特定阈值的特征被移除。 通过这种方法去除具有零方差的特征。 考虑的假设是更高方差的特征可能包含更多信息。
图 15:显示方差阈值实现的代码示例
- 平均绝对差 (MAD):该方法计算平均绝对差
与平均值的差异。
显示平均绝对差 (MAD) 实现的代码示例及其输出
资源
- 色散比:色散比定义为给定特征的算术平均值 (AM) 与几何平均值 (GM) 的比值。 对于给定的特征,它的值范围从 +1 到 ∞,因为 AM ≥ GM。
较高的色散比意味着较高的 Ri 值,因此是更相关的特征。 相反,当 Ri 接近 1 时,表示低相关性特征。
- 相互依赖:该方法用于衡量两个变量之间的相互依赖。 从一个变量获得的信息可用于获得另一个变量的信息。
- 拉普拉斯分数:来自同一类的数据通常彼此接近。 一个特征的重要性可以通过它的局部保存能力来评估。 计算每个特征的拉普拉斯分数。 最小值决定了重要的尺寸。 拉普拉斯分数的实现:scikit-feature。
结论
机器学习过程中的特征选择可以概括为任何机器学习模型开发的重要步骤之一。 特征选择算法的过程导致数据的维数减少,同时删除了与所考虑的模型不相关或不重要的特征。 相关特征可以加快模型的训练时间,从而获得高性能。
如果您有兴趣了解有关机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和 AI 执行 PG 计划,该计划专为工作专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业、IIIT -B 校友身份,5 个以上实用的实践顶点项目和顶级公司的工作协助。
过滤器方法与包装器方法有何不同?
包装器方法有助于根据分类器性能衡量特征的帮助程度。 另一方面,过滤器方法使用单变量统计而不是交叉验证性能来评估特征的内在质量,这意味着它们判断特征的相关性。 结果,包装方法更有效,因为它优化了分类器性能。 然而,由于重复的学习过程和交叉验证,包装技术在计算上比过滤方法更昂贵。
什么是机器学习中的顺序前向选择?
这是一种顺序特征选择,尽管它比过滤器选择成本高得多。 这是一种贪心搜索技术,它根据分类器的性能迭代地选择特征,以发现理想的特征子集。 它从一个空的特征子集开始,并在每一轮中继续添加一个特征。 这个特征是从不在我们特征子集中的所有特征池中选择的,当与其他特征结合时,它会产生最好的分类器性能。
使用过滤器方法进行特征选择有什么限制?
过滤器方法在计算上比包装器和嵌入式特征选择方法便宜,但它有一些缺点。 在单变量方法的情况下,该策略在选择特征时经常忽略特征相互依赖性并独立评估每个特征。 与其他两种特征选择方法相比,这有时可能会导致计算性能不佳。