
我的 API 驱动网站如何帮助我环游世界
已发表: 2022-03-10(这是一个赞助帖子。)最近,我决定重建我的个人网站,因为它已经有六年历史了,而且看起来——礼貌地说——有点“过时”。 目标是包括一些关于我自己的信息、一个博客区域、我最近的副项目列表以及即将发生的事件。
当我不时地做客户工作时,我不想处理一件事——数据库! 以前,我为所有想要我的人建立了 WordPress 网站。 编程部分对我来说通常很有趣,但是发布、将数据库移动到不同的环境以及实际发布,总是很烦人。 廉价的托管服务提供商只提供糟糕的 Web 界面来设置 MySQL 数据库,而通过 FTP 访问上传文件一直是最糟糕的部分。 我不想为我的个人网站处理这个问题。
所以我对重新设计的要求是:
- 基于 JavaScript 和前端技术的最新技术堆栈。
- 一种内容管理解决方案,可从任何地方编辑内容。
- 一个性能良好的网站,结果很快。
在本文中,我想向您展示我构建的内容以及我的网站如何令人惊讶地成为我的日常伴侣。
定义内容模型
在网络上发布东西似乎很容易。 选择一个内容管理系统 ( CMS ),它为每个需要的页面提供所见即所得的编辑器(您所见即所得),并且所有编辑器都可以轻松管理内容。 就是这样,对吧?
在建立了几个客户网站之后,从小咖啡馆到成长中的初创公司,我发现神圣的 WYSIWYG 编辑器并不总是我们都在寻找的灵丹妙药。 这些界面旨在使构建网站变得容易,但重点是:
建立网站并不容易
要在不经常破坏网站的情况下构建和编辑网站的内容,您必须对 HTML 有深入的了解,并且至少了解一点 CSS。 这不是你可以从你的编辑那里得到的。
我见过用所见即所得编辑器构建的可怕的复杂布局,当一切都因系统太脆弱而崩溃时,我无法开始命名所有情况。 这些情况会导致争吵和不适,各方都在为不可避免的事情互相指责。 我总是试图避免这些情况,并为编辑创造舒适、稳定的环境,以避免愤怒的电子邮件尖叫,“救命! 一切都被打破。”
结构化内容为您省去了一些麻烦
我很快就了解到,当我将所有需要的网站内容分成几个块时,人们很少会破坏事情,每个块相互关联而不考虑任何表示。 在 WordPress 中,这可以使用自定义帖子类型来实现。 每个自定义帖子类型都可以包含多个属性,这些属性具有自己易于掌握的文本字段。 我把思考的概念完全埋没在页面中。
我的工作是连接内容片段并从这些内容块中构建网页。 这意味着编辑只能在他们的网站上做很少的视觉变化。 他们对内容负责,而且只对内容负责。 视觉上的改变必须由我来完成——不是每个人都能为网站设计样式,我们可以避免脆弱的环境。 这个概念感觉像是一个很好的权衡,通常很受欢迎。
后来,我发现我正在做的是定义一个内容模型。 Rachel Lovinger 在她的优秀文章“内容建模:一项大师技能”中定义了如下内容模型:
“内容模型记录了给定项目将拥有的所有不同类型的内容。 它包含每种内容类型元素及其相互关系的详细定义。”
从内容建模开始对大多数客户来说都很好,除了一个。
“Stefan,我没有定义你的数据库模式!”
这个项目的想法是建立一个庞大的网站,该网站应该通过提供大量内容来创造大量自然流量——在多个不同页面和位置显示的所有变体。 我召开了一次会议,讨论我们处理这个项目的策略。
我想定义所有应该包含的页面和内容模型。 无论客户想到什么小部件或侧边栏,我都希望它被明确定义。 我的目标是创建一个可靠的内容结构,以便为编辑器提供易于使用的界面,并提供可重用的数据以任何可以想到的格式显示。
事实证明,这个项目的想法不是很清楚,我无法得到所有问题的答案。 项目负责人不明白我们应该从适当的内容建模(而不是设计和开发)开始。 对他来说,这只是一大堆页面。 重复的内容和巨大的文本区域以添加大量文本,这似乎不是问题。 在他看来,我关于结构的问题是技术性的,他们不应该担心。 长话短说,我没有做这个项目。
重要的是,内容建模与数据库无关。
这是关于使您的内容易于访问和面向未来。 如果您不能在项目启动时定义对内容的需求,那么以后重用它将非常困难,如果不是不可能的话。
正确的内容建模是当前和未来网站的关键。
内容丰富:无头 CMS
很明显,我也想为我的网站遵循一个好的内容建模。 然而,还有一件事。 我不想处理存储层来构建我的新网站,所以我决定使用 Contentful,一个无头 CMS,我目前正在研究它(完全免责声明!)。 “无头”意味着该服务提供了一个 Web 界面来管理云中的内容,它提供了一个 API,它将以 JSON 格式返回我的数据。 选择这个 CMS 帮助我立即提高工作效率,因为我在几分钟内就有了可用的 API,而且我不必处理任何基础设施设置。 Contentful 还提供了一个免费计划,非常适合小型项目,例如我的个人网站。
获取所有博客文章的示例查询如下所示:
<a href="https://cdn.contentful.com/spaces/space_id/entries?access_token=access_token&content_type=post">https://cdn.contentful.com/spaces/space_id/entries?access_token=access_token&content_type=post</a>简短版本的响应如下所示:
{ "sys": { "type": "Array" }, "total": 7, "skip": 0, "limit": 100, "items": [ { "sys": { "space": {...}, "id": "455OEfg1KUskygWUiKwmkc", "type": "Entry", "createdAt": "2016-07-29T11:53:52.596Z", "updatedAt": "2016-11-09T21:07:19.118Z", "revision": 12, "contentType": {...}, "locale": "en-US" }, "fields": { "title": "How to React to Changing Environments Using matchMedia", "excerpt": "...", "slug": "how-to-react-to-changing-environments-using-match-media", "author": [...], "body": "...", "date": "2014-12-26T00:00+02:00", "comments": true, "externalUrl": "https://4waisenkinder.de/blog/2014/12/26/handle-environment-changes-via-window-dot-matchmedia/" }, {...}, {...}, {...}, {...}, {...}, {...} ] } }Contentful 最重要的一点是它非常擅长内容建模,这是我所需要的。 使用提供的 Web 界面,我可以快速定义所有需要的内容片段。 Contentful 中特定内容模型的定义称为内容类型。 这里要指出的一件好事是对内容项之间的关系进行建模的能力。 例如,我可以轻松地将作者与博客文章联系起来。 这可以产生结构化的数据树,非常适合在各种用例中重用。
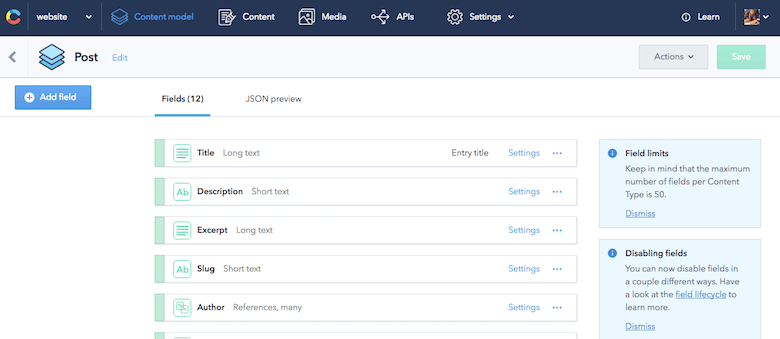
因此,我设置了我的内容模型,没有考虑我将来可能想要构建的任何页面。
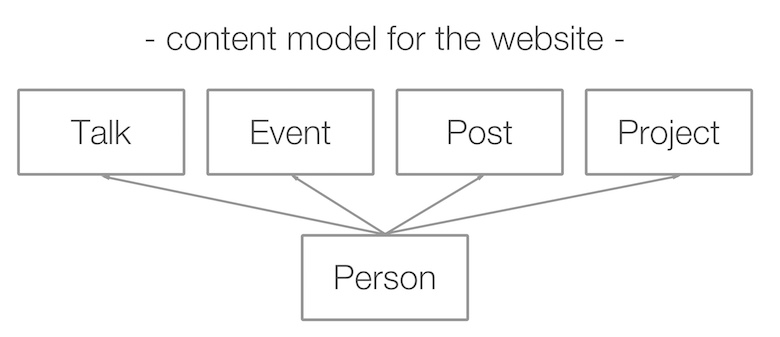
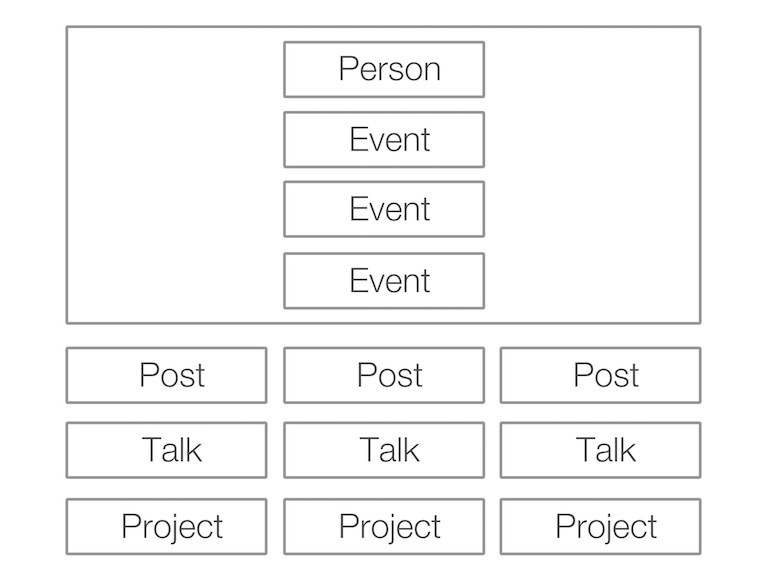
下一步是弄清楚我想用这些数据做什么。 我问了一个我认识的设计师,他想出了一个网站的索引页面,结构如下。
使用 Node.js 渲染 HTML 页面
现在到了棘手的部分。 到目前为止,我不必处理存储和数据库,这对我来说是一项了不起的成就。 那么,当我只有一个可用的 API 时,如何构建我的网站?
我的第一种方法是自己动手的方法。 我开始编写一个简单的 Node.js 脚本,该脚本将检索数据并从中呈现一些 HTML。
预先渲染所有 HTML 文件满足了我的主要要求之一。 可以非常快速地提供静态 HTML。
那么,让我们看看我使用的脚本。
'use strict'; const contentful = require('contentful'); const template = require('lodash.template'); const fs = require('fs'); // create contentful client with particular credentials const client = contentful.createClient({ space: 'your_space_id', accessToken: 'your_token' }); // cache templates to not read // them over and over again const TEMPLATES = { index : template(fs.readFileSync(`${__dirname}/templates/index.html`)) }; // fetch all the data Promise.all([ // get posts client.getEntries({content_type: 'content_type_post_id'}), // get events client.getEntries({content_type: 'content_type_event_id'}), // get projects client.getEntries({content_type: 'content_type_project_id'}), // get talk client.getEntries({content_type: 'content_type_talk_id'}), // get specific person client.getEntries({'sys.id': 'person_id'}) ]) .then(([posts, events, projects, talks, persons]) => { const renderedHTML = TEMPLATES.index({ posts, events, projects, talks, person : persons.items[0] }) fs.writeFileSync(`${__dirname}/build/index.html`, renderedHTML); console.log('Rendered HTML'); }) .catch(console.error); <!doctype html> <html lang="en"> <head> <!-- ... --> </head> <body> <!-- ... --> <h2>Posts</h2> <ul> <% posts.items.forEach( function( talk ) { %> <li><%- talk.fields.title %> <% }) %> </ul> <!-- ... --> </body> </html>这工作得很好。 我可以以一种完全灵活的方式构建我想要的网站,做出关于文件结构和功能的所有决定。 使用完全不同的数据集渲染不同的页面类型完全没有问题。 每个与 HTML 渲染附带的现有 CMS 的规则和结构作斗争的人都知道,完全的自由可能是一件好事。 尤其是当数据模型随着时间的推移变得更加复杂时,包括许多关系——灵活性会得到回报。
在这个 Node.js 脚本中,创建了一个 Contentful SDK 客户端,并使用客户端方法getEntries获取所有数据。 客户端提供的所有方法都是 Promise 驱动的,这样可以很容易地避免深度嵌套的回调。 对于模板,我决定使用 lodash 的模板引擎。 最后,对于文件读取和写入,Node.js 提供了原生fs模块,然后用于读取模板并写入呈现的 HTML。
但是,这种方法有一个缺点。 这是非常简单的。 即使这种方法完全灵活,也感觉像是在重新发明轮子。 我正在构建的基本上是一个静态站点生成器,并且已经有很多。 是时候重新开始了。
寻找真正的静态站点生成器
著名的静态站点生成器,例如 Jekyll 或 Middleman,通常处理将呈现为 HTML 的 Markdown 文件。 编辑使用这些,网站是使用 CLI 命令构建的。 不过,这种方法未能满足我最初的要求之一。 我希望无论身在何处都能够编辑该站点,而不是依赖于我私人计算机上的文件。
我的第一个想法是使用 API 呈现这些 Markdown 文件。 虽然这会奏效,但感觉不太对劲。 与我最初的解决方案相比,渲染 Markdown 文件以稍后转换为 HTML 仍然是两个步骤,并没有带来很大的好处。

幸运的是,有 Contentful 集成,例如 Metalsmith 和 Middleman。 我决定为这个项目选择 Metalsmith,因为它是用 Node.js 编写的,而且我不想引入 Ruby 依赖项。
Metalsmith 转换源文件夹中的文件并将它们呈现在目标文件夹中。 这些文件不一定是 Markdown 文件。 你也可以用它来转译 Sass 或优化你的图像。 没有限制,而且非常灵活。
使用 Contentful 集成,我能够定义一些源文件作为配置文件,然后可以从 API 获取所需的一切。
--- title: Blog contentful: content_type: content_type_id entry_filename_pattern: ${ fields.slug } entry_template: article.html order: '-fields.date' filter: include: 5 layout: blog.html description: >- Recent articles by Stefan Judis. --- 此示例配置使用父blog.html文件呈现博客文章区域,包括 API 请求的响应,但也使用article.html模板呈现多个子页面。 子页面的文件名通过entry_filename_pattern定义。
如您所见,有了这样的东西,我可以轻松地构建我的页面。 此设置完美地确保所有页面都依赖于 API。
将服务与您的项目联系起来
唯一缺少的部分是将站点与 CMS 服务连接起来,并在编辑任何内容时使其重新呈现。 这个问题的解决方案——webhooks,如果你使用像 GitHub 这样的服务,你可能已经熟悉了。
Webhook 是软件作为服务向先前定义的端点发出的请求,通知您发生了某些事情。 例如,当有人在您的一个存储库中打开拉取请求时,GitHub 可以回复您。 关于内容管理,我们可以在这里应用相同的原则。 每当内容发生问题时,ping 端点并让特定环境对其做出反应。 在我们的例子中,这意味着使用 metalsmith 重新渲染 HTML。
为了接受 webhook,我还使用了 JavaScript 解决方案。 我选择的托管服务提供商 (Uberspace) 可以在服务器端安装 Node.js 和使用 JavaScript。
const http = require('http'); const exec = require('child_process').exec; const server = http.createServer((req, res) => { res.setHeader('Content-Type', 'text/plain'); // check for secret header // to not open up this endpoint for everybody if (req.headers.secret === 'YOUR_SECRET') { res.end('ok'); // wait for the CDN to // invalidate the data setTimeout(() => { // execute command exec('npm start', { cwd: __dirname }, (error) => { if (error) { return console.log(error); } console.log('Rebuilt success'); }); }, 1000 * 120 ); } else { res.end('Not allowed'); } }); console.log('Started server at 8000'); server.listen(8000); 此脚本在端口 8000 上启动一个简单的 HTTP 服务器。它检查传入请求的正确标头,以确保它是来自 Contentful 的 webhook。 如果请求被确认为 webhook,则执行预定义的命令npm start以重新渲染所有 HTML 页面。 您可能想知道为什么会有超时。 这需要暂停操作片刻,直到云中的数据失效,因为存储的数据是从 CDN 提供的。
根据您的环境,此 HTTP 服务器可能无法通过 Internet 访问。 我的站点使用 apache 服务器提供服务,因此我需要添加一个内部重写规则以使正在运行的节点服务器可以访问 Internet。
# add node endpoint to enable webhooks RewriteRule ^rerender/(.*) https://localhost:8000/$1 [P]API优先和结构化数据:永远的好朋友
此时,我能够在云中管理我的所有数据,并且我的网站会在更改后做出相应的反应。
到处重复
在路上是我生活的重要组成部分,因此有必要随时掌握信息,例如给定场地的位置或我预订的酒店——通常存储在谷歌电子表格中。 现在,这些信息散布在电子表格、几封电子邮件、我的日历以及我的网站上。
我不得不承认,我在日常流程中创建了很多数据重复。
结构化数据的时刻
我梦想有一个单一的事实来源(最好是在我的手机上),以快速了解即将发生的事件,还可以获得有关酒店和场地的更多信息。 我的网站上列出的事件目前还没有所有信息,但是在 Contentful 中向内容类型添加新字段确实很容易。 因此,我将所需的字段添加到“事件”内容类型。
将这些信息放入我的网站 CMS 从来都不是我的意图,因为它不应该在线显示,但是通过 API 访问它让我意识到我现在可以用这些数据做完全不同的事情。
使用 JavaScript 构建本机应用程序
多年来,构建移动应用程序一直是一个话题,并且有几种方法可以解决这个问题。 渐进式 Web 应用程序 (PWA) 是当今特别热门的话题。 使用 Service Worker 和 Web App Manifest,可以构建完整的类似应用程序的体验,从主屏幕图标到使用 Web 技术管理的离线行为。
有一个缺点要提。 渐进式 Web 应用程序正在兴起,但还没有完全实现。 例如,现在 Safari 不支持 Service Worker,到目前为止,Apple 方面只是“正在考虑”。 这对我来说是一个交易破坏者,因为我也想在 iPhone 上拥有一个支持离线的应用程序。
所以我寻找替代品。 我的一个朋友真的很喜欢 NativeScript,并且一直在告诉我这个相当新的技术。 NativeScript 是一个开源框架,用于使用 JavaScript 构建真正的原生移动应用程序,因此我决定尝试一下。
了解 NativeScript
NativeScript 的设置需要一些时间,因为您必须安装很多东西来为原生移动环境进行开发。 当您第一次使用npm install nativescript -g安装 NativeScript 命令行工具时,将指导您完成安装过程。
然后,您可以使用脚手架命令来设置新项目: tns create MyNewApp
然而,这不是我所做的。 我在扫描文档时发现了一个用 NativeScript 构建的示例杂货管理应用程序。 所以我拿了这个应用程序,挖掘代码,一步一步地修改它,让它适合我的需要。
我不想深入研究这个过程,但是用我想要的所有信息建立一个查找列表,并没有花费很长时间。
NativeScript 与 Angular 2 配合得非常好,这次我不想尝试,因为发现 NativeScript 本身感觉足够大。 在 NativeScript 中,您必须编写“视图”。 每个视图都包含一个定义基本布局和可选 JavaScript 和 CSS 的 XML 文件。 所有这些都在每个视图的一个文件夹中定义。
可以使用这样的 XML 模板来呈现一个简单的列表:
<!-- call JavaScript function when ready --> <Page loaded="loaded"> <ActionBar title="All Travels" /> <!-- make it scrollable when going too big --> <ScrollView> <!-- iterate over the entries in context --> <ListView items="{{ entries }}"> <ListView.itemTemplate> <Label text="{{ fields.name }}" textWrap="true" class="headline"/> </ListView.itemTemplate> </ListView> </ScrollView> </Page> 这里发生的第一件事是定义一个页面元素。 在这个页面内部,我定义了一个ActionBar来赋予它经典的 Android 外观以及一个合适的标题。 有时为本地环境构建东西可能有点棘手。 例如,要实现有效的滚动行为,您必须使用“ScrollView”。 最后一件事是,只需使用ListView遍历我的事件。 总的来说,感觉很简单!
但是视图中使用的这些条目是从哪里来的呢? 事实证明,有一个共享上下文对象可用于此目的。 在读取视图的 XML 时,您可能已经注意到该页面具有已loaded的属性集。 通过设置这个属性,我告诉视图在页面加载时调用特定的 JavaScript 函数。
这个 JavaScript 函数在依赖的 JS 文件中定义。 它可以通过简单地使用exports.something出来访问。 要添加数据绑定,我们所要做的就是为页面属性bindingContext设置一个新的 Observable。 NativeScript 中的 Observable 会发出propertyChange事件,这些事件是对 'iews 内的数据更改做出反应所需的,但您不必担心这一点,因为它开箱即用。
const context = new Observable({ entries: null}); const fetchModule = require('fetch'); // export loaded to be called from // List.xml when everything is loaded exports.loaded = (args) => { const page = args.object; page.bindingContext = context; fetchModule.fetch( `https://cdn.contentful.com/spaces/${config.space}/entries?access_token=${config.cda.token}&content_type=event&order=fields.start`, { method: "GET", headers: { 'Content-Type': 'application/json' } } ) .then(response => response.json()) .then(response => context.set('entries', response.items)); } 最后一件事是获取数据并将其设置到上下文中。 这可以通过使用 NativeScript fetch模块来完成。 在这里,您可以看到结果。
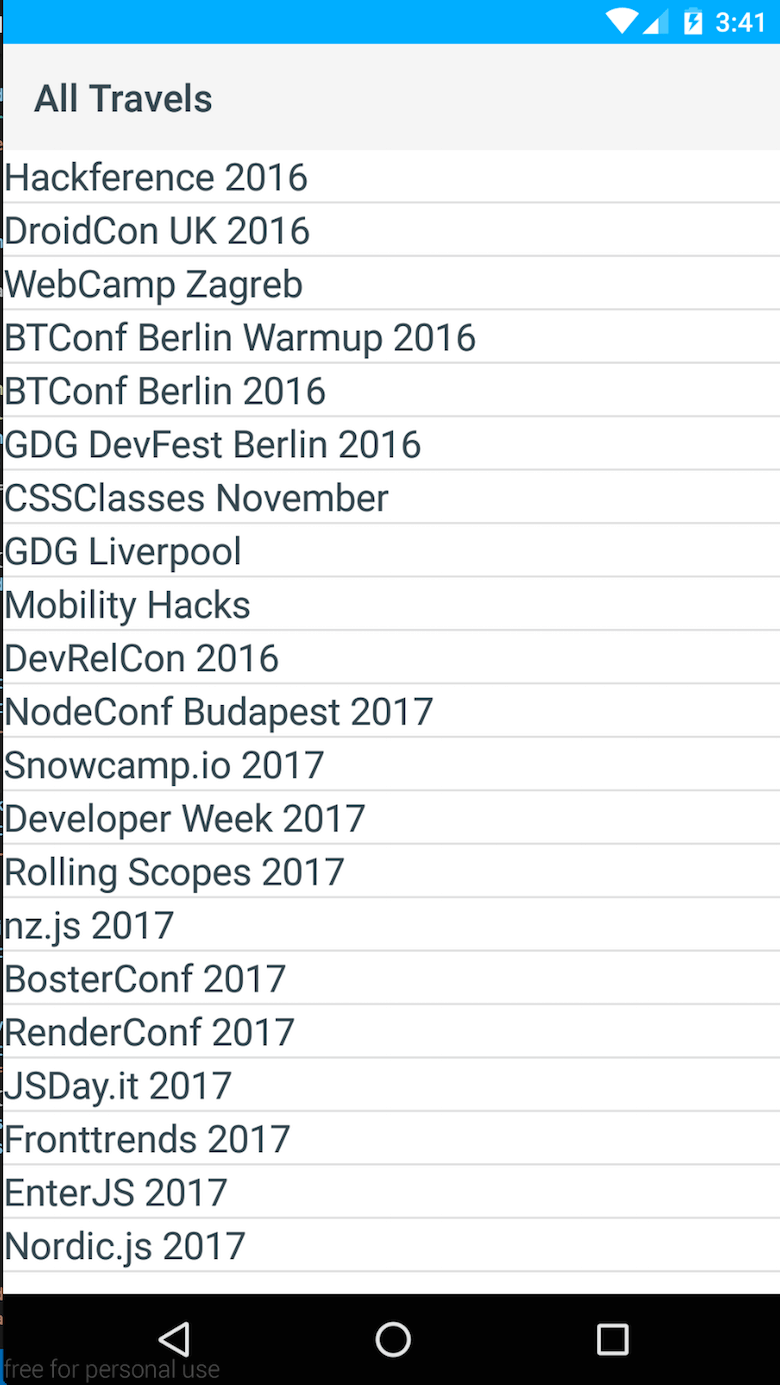
因此,如您所见——使用 NativeScript 构建一个简单的列表并不难。 后来我用另一个视图扩展了该应用程序,并增加了在谷歌地图和网络视图中打开给定地址以查看活动网站的附加功能。
这里要指出的一件事是,NativeScript 仍然很新,这意味着在 npm 上找到的插件通常在 GitHub 上没有很多下载或 star。 起初这让我很恼火,但我使用了几个原生组件(nativescript-floatingactionbutton、nativescript-advanced-webview 和 nativescript-pulltorefresh),它们帮助我获得了原生体验,并且一切都运行良好。
你可以在这里看到改进的结果:
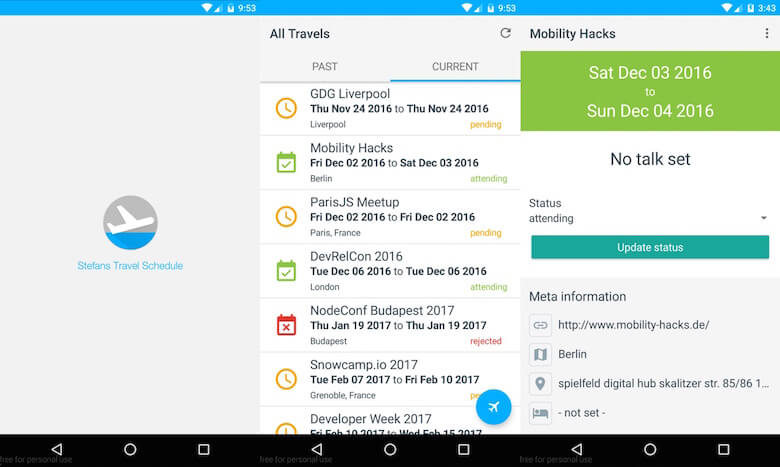
我在这个应用程序中添加的功能越多,我就越喜欢它,并且使用它的次数也越多。 最好的部分是,我可以摆脱数据重复,在一个地方管理所有数据,并且足够灵活,可以在各种用例中显示它。
页面是昨天:结构化内容万岁!
构建这个应用程序再次向我展示了以页面格式保存数据的原则已成为过去。 我们不知道我们的数据会去哪里——我们必须为无限数量的用例做好准备。
回想起来,我取得的成就是:
- 在云中拥有内容管理系统
- 无需处理数据库维护
- 一个完整的 JavaScript 技术栈
- 拥有一个高效的静态网站
- 有一个 Android 应用程序可以随时随地访问我的内容
而最重要的部分:
让我的内容结构化和易于访问帮助我改善了我的日常生活。
这个用例现在对你来说可能看起来微不足道,但是当你想到你每天构建的产品时——在不同平台上你的内容总是有更多用例。 今天,我们承认移动设备终于超越了老式的桌面环境,但汽车、手表甚至冰箱等平台已经在等待它们的聚光灯。 我什至无法想到将会出现的用例。
所以,让我们试着做好准备,把结构化内容放在中间,因为最后它不是关于数据库模式——而是关于为未来构建的。
关于 SmashingMag 的进一步阅读:
- 使用 Node.js 进行网页抓取
- Sails.js 航行:Node.js 的 MVC 风格框架
- 40 个旅行图标来美化您的设计
- Webpack 详细介绍