
GraphQL 入门:API 设计的演变(第 2 部分)
已发表: 2022-03-10在第 1 部分中,我们研究了 API 在过去几十年中是如何演变的,以及每个 API 如何让位于下一个。 我们还讨论了使用 REST 进行移动客户端开发的一些特殊缺点。 在本文中,我想看看移动客户端 API 设计的发展方向——特别强调 GraphQL。
当然,多年来有很多人、公司和项目试图解决 REST 的缺点:HAL、Swagger/OpenAPI、OData JSON API 和许多其他小型或内部项目都试图为 REST 带来秩序。无规范的 REST 世界。 与其按照世界的本来面目提出渐进式改进,或者尝试组装足够多的不同部分以使 REST 成为我所需要的,我想尝试一个思想实验。 鉴于对过去有效和无效的技术的理解,我想利用今天的限制和我们极具表现力的语言来尝试勾勒出我们想要的 API。 让我们从开发人员的经验向后工作,而不是向前实现(我在看你的 SQL)。
最小的 HTTP 流量
我们知道每个(HTTP/1)网络请求的成本在从延迟到电池寿命的很多方面都很高。 理想情况下,我们的新 API 的客户将需要一种方法,以尽可能少的往返请求他们需要的所有数据。
最小有效载荷
我们还知道,普通客户端在带宽、CPU 和内存方面是资源受限的,因此我们的目标应该是只发送客户端需要的信息。 为此,我们可能需要一种方法让客户端请求特定的数据。
人类可读
我们从 SOAP 时代了解到,API 很难与之交互,人们一提到它就会做鬼脸。 工程团队希望使用我们多年来一直依赖的相同工具,例如curl 、 wget和Charles以及我们浏览器的网络选项卡。
工具丰富
我们从 XML-RPC 和 SOAP 中学到的另一件事是,客户端/服务器契约和类型系统尤其有用。 如果可能的话,任何新的 API 都将具有 JSON 或 YAML 等格式的轻量级,并具有更结构化和类型安全的合约的自省能力。
局部推理的保留
多年来,我们已经就如何组织大型代码库的一些指导原则达成一致——主要的原则是“关注点分离”。 不幸的是,对于大多数项目来说,这往往会以集中式数据访问层的形式出现故障。 如果可能,应用程序的不同部分应该可以选择管理自己的数据需求以及其他功能。
由于我们正在设计一个以客户端为中心的 API,让我们从在这样的 API 中获取数据的情况开始。 如果我们知道我们需要进行最少的往返,并且我们需要能够过滤掉我们不想要的字段,我们需要一种方法来遍历大量数据并只请求其中的部分对我们有用。 查询语言似乎很适合这里。
我们不需要像处理数据库一样询问我们的数据问题,因此像 SQL 这样的命令式语言似乎是错误的工具。 事实上,我们的主要目标是遍历预先存在的关系并限制我们应该能够用相对简单和声明性的东西来做的事情。 业界已经很好地将 JSON 用于非二进制数据,所以让我们从类似 JSON 的声明性查询语言开始。 我们应该能够描述我们需要的数据,并且服务器应该返回包含这些字段的 JSON。

声明式查询语言满足最小负载和最小 HTTP 流量的要求,但还有另一个好处可以帮助我们实现另一个设计目标。 许多声明性语言、查询和其他语言都可以像数据一样被有效地操作。 如果我们仔细设计,我们的查询语言将允许开发人员将大型请求分解并以对他们的项目有意义的任何方式重新组合它们。 使用这样的查询语言将帮助我们朝着保留本地推理的最终目标迈进。
一旦您的查询变成“数据”,您就可以做很多令人兴奋的事情。 例如,您可以拦截所有请求并将它们批处理,类似于虚拟 DOM 批处理 DOM 更新的方式,您还可以使用编译器在构建时提取小查询以预缓存数据,或者您可以构建复杂的缓存系统像阿波罗缓存。
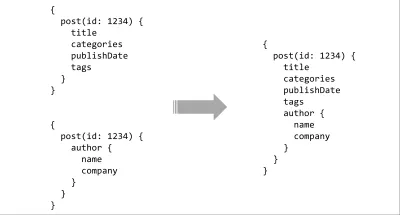
API 愿望清单上的最后一项是工具。 我们已经通过使用查询语言获得了其中的一些,但真正的力量来自于将它与类型系统配对。 通过服务器上的简单类型模式,丰富的工具几乎有无限的可能性。 查询可以根据合约进行静态分析和验证,IDE 集成可以提供提示或自动完成,编译器可以对查询进行构建时优化,或者可以将多个模式拼接在一起形成一个连续的 API 界面。

设计一个将查询语言和类型系统配对的 API 可能听起来像是一个戏剧性的提议,但多年来人们一直在以各种形式对此进行试验。 XML-RPC 在 90 年代中期推动了类型化响应,其继任者 SOAP 统治了多年! 最近,还有 Meteor 的 MongoDB 抽象、RethinkDB (RIP) Horizon、Netflix 令人惊叹的 Falcor,它们多年来一直用于 Netflix.com,最后是 Facebook 的 GraphQL。 在本文的其余部分,我将专注于 GraphQL,因为虽然 Falcor 等其他项目正在做类似的事情,但社区的思想份额似乎压倒性地支持它。
什么是 GraphQL?
首先,我不得不说我撒了一点谎。 我们上面构建的 API 是 GraphQL。 GraphQL 只是你的数据的类型系统,一种用于遍历它的查询语言——其余的只是细节。 在 GraphQL 中,您将数据描述为互连图,并且您的客户专门询问它需要的数据子集。 有很多关于 GraphQL 实现的令人难以置信的事情的演讲和写作,但核心概念非常易于管理且不复杂。
为了使这些概念更加具体,并帮助说明 GraphQL 如何尝试解决第 1 部分中的一些问题,本文的其余部分将构建一个 GraphQL API,该 API 可以为本系列第 1 部分中的博客提供支持。 在进入代码之前,需要记住一些关于 GraphQL 的事情。
GraphQL 是规范(不是实现)
GraphQL 只是一个规范。 它定义了一个类型系统以及一个简单的查询语言,仅此而已。 首先,GraphQL 不以任何方式绑定到特定语言。 从 Haskell 到 C++ 都有超过两打的实现,其中 JavaScript 只是其中之一。 规范公布后不久,Facebook 发布了 JavaScript 的参考实现,但由于他们不在内部使用它,Go 和 Clojure 等语言的实现可能会更好或更快。
GraphQL 的规范没有提及客户端或数据
如果您阅读规范,您会注意到明显缺少两件事。 首先,除了查询语言之外,没有提到客户端集成。 由于 GraphQL 的设计,像 Apollo、Relay、Loka 等工具是可能的,但它们绝不是使用它的一部分或必需的。 其次,没有提到任何特定的数据层。 同一个 GraphQL 服务器可以并且经常这样做,从一组异构的源中获取数据。 它可以从 Redis 请求缓存数据,从 USPS API 进行地址查找并调用基于 protobuff 的微服务,而客户端永远不会知道其中的区别。
复杂性的逐步披露
对许多人来说,GraphQL 已经达到了强大和简单的罕见交集。 它在使简单的事情变得简单和使困难的事情成为可能方面做得非常出色。 让服务器运行并通过 HTTP 提供类型化数据只需几行代码,使用几乎任何你能想象到的语言。
例如,GraphQL 服务器可以包装现有的 REST API,其客户端可以通过常规 GET 请求获取数据,就像您与其他服务交互一样。 你可以在这里看到一个演示。 或者,如果项目需要更复杂的工具集,则可以使用 GraphQL 执行字段级身份验证、发布/订阅订阅或预编译/缓存查询等操作。
示例应用程序
本示例的目的是用大约 70 行 JavaScript 代码展示 GraphQL 的强大功能和简单性,而不是编写详尽的教程。 我不会详细介绍语法和语义,但这里的所有代码都是可运行的,并且在文章末尾有一个指向该项目的可下载版本的链接。 如果在经历了这些之后,您想更深入地挖掘,我的博客上有一个资源集合,可以帮助您构建更大更强大的服务。
对于演示,我将使用 JavaScript,但任何语言的步骤都非常相似。 让我们从使用令人惊叹的 Mocky.io 的一些示例数据开始。
作者
{ 9: { id: 9, name: "Eric Baer", company: "Formidable" }, ... }帖子
[ { id: 17, author: "author/7", categories: [ "software engineering" ], publishdate: "2016/03/27 14:00", summary: "...", tags: [ "http/2", "interlock" ], title: "http/2 server push" }, ... ] 第一步是使用express和express-graphql中间件创建一个新项目。
bash npm init -y && npm install --save graphql express express-graphql 并使用快速服务器创建index.js文件。
const app = require("express")(); const PORT = 5000; app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); 要开始使用 GraphQL,我们可以从 REST API 中的数据建模开始。 在名为schema.js的新文件中添加以下内容:
const { GraphQLInt, GraphQLList, GraphQLObjectType, GraphQLSchema, GraphQLString } = require("graphql"); const Author = new GraphQLObjectType({ name: "Author", fields: { id: { type: GraphQLInt }, name: { type: GraphQLString }, company: { type: GraphQLString }, } }); const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author }, categories: { type: new GraphQLList(GraphQLString) }, publishDate: { type: GraphQLString }, summary: { type: GraphQLString }, tags: { type: new GraphQLList(GraphQLString) }, title: { type: GraphQLString } } }); const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post) } } }); module.exports = new GraphQLSchema({ query: Blog }); 上面的代码将我们 API 的 JSON 响应中的类型映射到 GraphQL 的类型。 一个GraphQLObjectType对应一个 JavaScript Object ,一个GraphQLString对应一个 JavaScript String等等。 需要注意的一种特殊类型是最后几行的GraphQLSchema 。 GraphQLSchema是 GraphQL 的根级导出——查询遍历图的起点。 在这个基本示例中,我们只定义query ; 这是您定义突变(写入)和订阅的地方。

接下来,我们将在index.js文件中将模式添加到我们的 express 服务器。 为此,我们将添加express-graphql中间件并将模式传递给它。
const graphqlHttp = require("express-graphql"); const schema = require("./schema.js"); const app = require("express")(); const PORT = 5000; app.use(graphqlHttp({ schema, // Pretty Print the JSON response pretty: true, // Enable the GraphiQL dev tool graphiql: true })); app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); 此时,虽然我们没有返回任何数据,但我们有一个工作的 GraphQL 服务器,它向客户端提供其模式。 为了使启动应用程序更容易,我们还将在package.json添加一个启动脚本。
"scripts": { "start": "nodemon index.js" }, 运行项目并转到 https://localhost:5000/ 应该会显示一个名为 GraphiQL 的数据浏览器。 只要 HTTP Accept标头未设置为application/json ,GraphiQL 就会默认加载。 使用application/json通过fetch或cURL调用相同的 URL 将返回 JSON 结果。 随意使用内置文档并编写查询。

完成服务器唯一剩下要做的就是将底层数据连接到模式中。 为此,我们需要定义resolve函数。 在 GraphQL 中,查询从上到下运行,并在遍历树时调用resolve函数。 例如,对于以下查询:
query homepage { posts { title } } GraphQL 将首先调用posts.resolve(parentData)然后调用 posts.title.resolve posts.title.resolve(parentData) 。 让我们从在我们的博客文章列表中定义解析器开始。
const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post), resolve: () => { return fetch('https://www.mocky.io/v2/594a3ac810000053021aa3a7') .then((response) => response.json()) } } } }); 我在这里使用isomorphic-fetch包来发出 HTTP 请求,因为它很好地演示了如何从解析器返回 Promise,但你可以使用任何你喜欢的东西。 这个函数将返回一个博客类型的帖子数组。 GraphQL 的 JavaScript 实现的默认解析函数是parentData.<fieldName> 。 例如,作者姓名字段的默认解析器是:
rawAuthorObject => rawAuthorObject.name这个单一的覆盖解析器应该为整个 post 对象提供数据。 我们仍然需要为 Author 定义解析器,但是如果您运行查询以获取主页所需的数据,您应该会看到它正在工作。
由于我们的帖子 API 中的 author 属性只是作者 ID,当 GraphQL 查找定义名称和公司的 Object 并找到 String 时,它只会返回null 。 要连接作者,我们需要将 Post 模式更改为如下所示:
const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author, resolve: (subTree) => { // Get the AuthorId from the post data const authorId = subTree.author.split("/")[1]; return fetch('https://www.mocky.io/v2/594a3bd21000006d021aa3ac') .then((response) => response.json()) .then(authors => authors[authorId]); } }, ... } });现在,我们有一个完整工作的 GraphQL 服务器,它包装了一个 REST API。 完整的源代码可以从这个 Github 链接下载,或者从这个 GraphQL 启动板运行。
您可能想知道使用这样的 GraphQL 端点需要使用哪些工具。 有很多选择,例如 Relay 和 Apollo,但首先,我认为简单的方法是最好的。 如果您经常使用 GraphiQL,您可能已经注意到它的 URL 很长。 此 URL 只是您的查询的 URI 编码版本。 要在 JavaScript 中构建 GraphQL 查询,您可以执行以下操作:
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);或者,如果您愿意,您可以直接从 GraphiQL 复制粘贴 URL,如下所示:
https://localhost:5000/?query=query%20homepage%20%7B%0A%20%20posts%20%7B%0A%20%20%20%20title%0A%20%20%20%20author%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D&operationName=homepage由于我们有一个 GraphQL 端点和使用它的方法,我们可以将它与我们的 RESTish API 进行比较。 我们需要编写的使用 RESTish API 获取数据的代码如下所示:
使用 RESTish API
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/post/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/author/${postId}`); const getPostWithAuthor = post => { return getAuthor(post.author) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(posts => { const postDetails = posts.map(getPostWithAuthor); return Promise.all(postDetails); }) };使用 GraphQL API
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);总之,我们使用 GraphQL 来:
- 减少九个请求(文章列表、四篇博客文章和每篇文章的作者)。
- 大幅减少发送的数据量。
- 使用令人难以置信的开发人员工具来构建我们的查询。
- 在我们的客户端中编写更简洁的代码。
GraphQL 的缺陷
虽然我相信炒作是有道理的,但没有灵丹妙药,尽管 GraphQL 很棒,但它并非没有缺陷。
数据的完整性
GraphQL 有时看起来像是专门为优质数据而构建的工具。 它通常最适合作为一种网关,将不同的服务或高度规范化的表拼接在一起。 如果从您使用的服务返回的数据是混乱且非结构化的,那么在 GraphQL 下添加数据转换管道可能是一个真正的挑战。 GraphQL 解析函数的范围只是它自己的数据和它的子数据。 如果编排任务需要访问树中同级或父级中的数据,则可能特别具有挑战性。
复杂的错误处理
一个 GraphQL 请求可以运行任意数量的查询,并且每个查询可以访问任意数量的服务。 如果请求的任何部分失败,而不是整个请求失败,GraphQL 默认返回部分数据。 从技术上讲,部分数据可能是正确的选择,而且它非常有用和高效。 缺点是错误处理不再像检查 HTTP 状态码那样简单。 可以关闭此行为,但通常情况下,客户端会遇到更复杂的错误情况。
缓存
尽管使用静态 GraphQL 查询通常是个好主意,但对于像 Github 这样允许任意查询的组织来说,使用 Varnish 或 Fastly 等标准工具进行网络缓存将不再可能。
高 CPU 成本
解析、验证和类型检查查询是一个 CPU 绑定的过程,这可能会导致 JavaScript 等单线程语言的性能问题。
这只是运行时查询评估的问题。
结束的想法
GraphQL 的特性并不是一场革命——其中一些已经存在了近 30 年。 GraphQL 的强大之处在于其完善、集成和易用性的水平使其超过了各个部分的总和。
GraphQL 完成的许多事情可以通过努力和纪律使用 REST 或 RPC 来实现,但是 GraphQL 为可能没有时间、资源或工具自行完成的大量项目带来了最先进的 API。 GraphQL 确实不是灵丹妙药,但它的缺陷往往很小且易于理解。 作为一个构建了相当复杂的 GraphQL 服务器的人,我可以很容易地说,收益很容易超过成本。
这篇文章几乎完全集中在 GraphQL 存在的原因以及它解决的问题上。 如果这激起了您对更多地了解其语义以及如何使用它的兴趣,我鼓励您以最适合您的方式学习,无论是博客、youtube 还是只是阅读源代码(How To GraphQL 特别好)。
如果你喜欢这篇文章(或者如果你讨厌这篇文章)并且想给我反馈,请在 Twitter 上以@ebaerbaerbaer 的身份找到我,或者在 ericjbaer 的 LinkedIn 上找到我。