
机器学习中的梯度下降:它是如何工作的?
已发表: 2021-01-28目录
介绍
机器学习最关键的部分之一是优化其算法。 机器学习中几乎所有的算法都有一个优化算法作为算法的核心。 众所周知,优化是任何算法的最终目标,即使是处理现实生活中的事件或处理市场上基于技术的产品时也是如此。
目前有很多优化算法用于人脸识别、自动驾驶汽车、基于市场的分析等多种应用中。同样,在机器学习中,此类优化算法也发挥着重要作用。 一种如此广泛使用的优化算法是我们将在本文中介绍的梯度下降算法。
什么是梯度下降?
在机器学习中,梯度下降算法是最常用的算法之一,但它却让大多数新手感到困惑。 在数学上,梯度下降是一种一阶迭代优化算法,用于找到可微函数的局部最小值。 简单来说,这种梯度下降算法用于找到函数参数(或系数)的值,这些参数用于尽可能低地最小化成本函数。 成本函数用于量化构建的机器学习模型的预测值与实际值之间的误差。
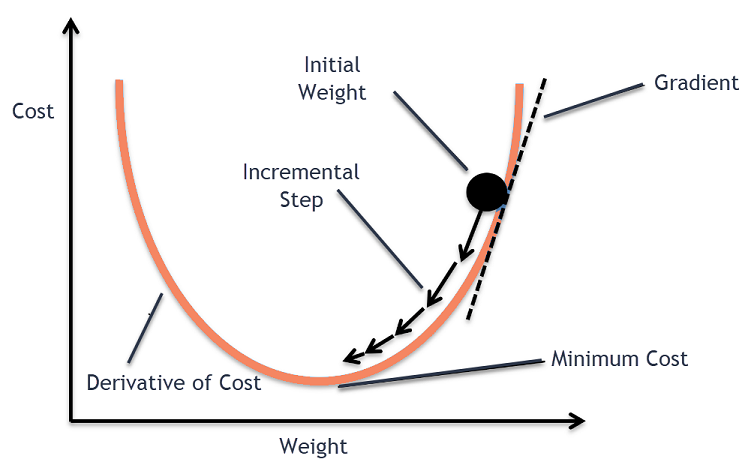
梯度下降直觉
考虑一个大碗,你通常会用它来盛水果或吃麦片。 这个碗将是成本函数(f)。
现在,碗表面任何部分的随机坐标将是成本函数系数的当前值。 碗的底部是最好的系数集,它是函数的最小值。
在这里,目标是每次迭代计算系数的不同值,评估成本并选择具有更好成本函数值(较低值)的系数。 在多次迭代中,会发现碗的底部具有最小化成本函数的最佳系数。

以这种方式,梯度下降算法起作用以产生最小的成本。
加入来自世界顶级大学的在线机器学习课程——硕士、高管研究生课程和 ML 和 AI 高级证书课程,以加快您的职业生涯。
梯度下降程序
这个梯度下降过程从最初为成本函数的系数分配值开始。 这可以是接近 0 的值或小的随机值。
系数 = 0.0
接下来,通过将其应用于成本函数并计算成本来获得系数的成本。
成本 = f(系数)
然后,计算成本函数的导数。 成本函数的这种导数是通过微积分的数学概念获得的。 它为我们提供了函数在计算其导数的给定点的斜率。 这个斜率需要知道在下一次迭代中系数将向哪个方向移动以获得较低的成本值。 这是通过观察计算的导数的符号来完成的。
delta = 导数(成本)
一旦我们从计算的导数中知道哪个方向是下坡,我们需要更新系数值。 为此,一个参数称为学习参数,使用 alpha (α)。 这用于控制系数在每次更新时可以改变的程度。
系数 = 系数 - (alpha * delta)
资源
以这种方式,重复此过程,直到系数的成本等于 0.0 或足够接近于零。 这是梯度下降算法的过程。
梯度下降算法的类型
在现代,现代机器学习和深度学习算法中使用了三种基本类型的梯度下降。 这三种类型之间的主要区别在于其计算成本和效率。 根据使用的数据量、时间复杂度和准确性,以下是三种类型。
- 批量梯度下降
- 随机梯度下降
- 小批量梯度下降
批量梯度下降
这是梯度下降算法的第一个也是基本版本,其中一次使用整个数据集来计算成本函数及其梯度。 由于整个数据集一次性更新,因此这种类型的梯度计算可能非常缓慢,并且对于那些超出设备内存容量的数据集是不可能的。

因此,这种批量梯度下降算法仅用于较小的数据集,并且当训练示例的数量很大时,批量梯度下降不是首选。 相反,使用随机和小批量梯度下降算法。
随机梯度下降
这是另一种梯度下降算法,其中每次迭代只处理一个训练示例。 在此,第一步是随机化整个训练数据集。 然后,仅使用一个训练样本来更新系数。 这与批量梯度下降形成对比,其中仅在评估所有训练示例时才更新参数(系数)。
随机梯度下降 (SGD) 的优点是这种类型的频繁更新提供了详细的改进率。 然而,在某些情况下,这可能会在计算上变得昂贵,因为它每次迭代只处理一个示例,这可能导致迭代次数非常大。
小批量梯度下降
这是一种最近开发的算法,比批处理和随机梯度下降算法都快。 它是最优选的,因为它是前面提到的两种算法的组合。 在这种情况下,它将训练集分成几个小批次,并在计算该批次的梯度后对每个批次执行更新(如在 SGD 中)。
通常,批量大小在 30 到 500 之间变化,但没有任何固定大小,因为它们因不同的应用程序而异。 因此,即使有一个巨大的训练数据集,这个算法也会在“b”个小批量中处理它。 因此,它适用于迭代次数较少的大型数据集。
如果 'm' 是训练示例的数量,那么如果 b==m,Mini Batch Gradient Descent 将类似于 Batch Gradient Descent 算法。
机器学习中梯度下降的变体
有了梯度下降的这个基础,已经开发了其他几种算法。 其中一些总结如下。
香草梯度下降
这是梯度下降技术的最简单形式之一。 香草这个名字意味着纯净或没有任何掺假。 在这种情况下,通过计算成本函数的梯度,朝着最小值的方向迈出一小步。 与上述算法类似,更新规则由下式给出,
系数 = 系数 - (alpha * delta)
动量梯度下降
在这种情况下,算法使得我们在采取下一步之前知道前面的步骤。 这是通过引入一个新术语来完成的,该术语是先前更新的乘积和称为动量的常数。 在此,权重更新规则由下式给出,
更新 = 阿尔法 * 德尔塔
速度 = previous_update * 动量
系数 = 系数 + 速度 - 更新
阿达格拉德
ADAGRAD 一词代表自适应梯度算法。 顾名思义,它使用自适应技术来更新权重。 该算法更适合稀疏数据。 这种优化会根据训练期间参数更新的频率改变其学习率。 例如,具有较高梯度的参数具有较慢的学习率,因此我们最终不会超过最小值。 同样,较低的梯度具有更快的学习率,可以更快地得到训练。
亚当
另一种源于梯度下降算法的自适应优化算法是 ADAM,它代表自适应矩估计。 它是 ADAGRAD 和 SGD 与 Momentum 算法的组合。 它是从 ADAGRAD 算法构建的,并且有进一步的缺点。 简单来说,ADAM = ADAGRAD + Momentum。
这样一来,世界上已经开发和正在开发的梯度下降算法的其他几种变体,例如AMSGrad、ADAMax。
结论
在本文中,我们看到了机器学习中最常用的优化算法之一背后的算法,即梯度下降算法及其已开发的类型和变体。
upGrad 提供机器学习和人工智能的执行 PG 计划和机器学习和人工智能的理学硕士,可以指导您建立职业生涯。 这些课程将解释机器学习的必要性以及收集该领域知识的进一步步骤,涵盖从机器学习中的梯度下降等各种概念。
梯度下降算法在哪些方面贡献最大?
任何机器学习算法中的优化都会增加算法的纯度。 梯度下降算法有助于最小化成本函数误差并改进算法的参数。 尽管梯度下降算法在机器学习和深度学习中被广泛使用,但其有效性可以由数据量、迭代次数和首选精度以及可用时间量来确定。 对于小规模数据集,Batch Gradient Descent 是最优的。 随机梯度下降 (SGD) 被证明对于更详细和更广泛的数据集更有效。 相比之下,Mini Batch Gradient Descent 用于更快的优化。
梯度下降面临哪些挑战?
梯度下降优先用于优化机器学习模型以降低成本函数。 然而,它也有它的缺点。 假设梯度由于模型层的最小输出函数而减小。 在这种情况下,迭代不会像模型不会完全重新训练、更新其权重和偏差一样有效。 有时,误差梯度会累积大量权重和偏差以保持迭代更新。 然而,这个梯度变得太大而无法管理,被称为爆炸梯度。 需要解决基础设施要求、学习率平衡、动力。
梯度下降总是收敛吗?
收敛是梯度下降算法成功地将其成本函数最小化到最佳水平的时候。 梯度下降算法试图通过算法参数最小化成本函数。 但是,它可以降落在任何最佳点上,而不一定是具有全局或局部最佳点的点。 没有最佳收敛的原因之一是步长。 更大的步长会导致更多的振荡,并可能偏离全局最优值。 因此,梯度下降可能并不总是收敛到最好的特征,但它仍然落在最近的特征点上。