
高斯朴素贝叶斯:你需要知道什么?
已发表: 2021-02-22目录
高斯朴素贝叶斯
朴素贝叶斯是一种用于许多分类功能的概率机器学习算法,它基于贝叶斯定理。 高斯朴素贝叶斯是朴素贝叶斯的扩展。 虽然其他函数用于估计数据分布,但高斯或正态分布是最容易实现的,因为您需要计算训练数据的均值和标准差。
什么是朴素贝叶斯算法?
朴素贝叶斯是一种概率机器学习算法,可用于多种分类任务。 朴素贝叶斯的典型应用是文档分类、过滤垃圾邮件、预测等。 该算法基于 Thomas Bayes 的发现,因此得名。
之所以使用“Naive”这个名称,是因为该算法在其模型中包含了彼此独立的特征。 对一个特征值的任何修改都不会直接影响算法的任何其他特征的值。 朴素贝叶斯算法的主要优点是它是一种简单而强大的算法。
它基于概率模型,可以轻松地对算法进行编码,并且可以实时快速进行预测。 因此,该算法是解决实际问题的典型选择,因为它可以调整为立即响应用户请求。 但在我们深入研究朴素贝叶斯和高斯朴素贝叶斯之前,我们必须知道条件概率是什么意思。
条件概率解释
我们可以通过一个例子更好地理解条件概率。 当你抛硬币时,领先或落后的概率为 50%。 同样,当你掷骰子时,得到 4 的概率是 1/6 或 0.16。
如果我们拿一副牌,假设它是黑桃,得到一张 Q 的概率是多少? 由于已经设置了必须是黑桃的条件,因此分母或选择集变为 13。黑桃中只有一个皇后,因此选择黑桃皇后的概率变为 1/13= 0.07。

事件 A 给定事件 B 的条件概率是指在事件 B 已经发生的情况下,事件 A 发生的概率。 在数学上,给定 B 的 A 的条件概率可以表示为 P[A|B] = P[A AND B] / P[B]。
让我们考虑一个稍微复杂的例子。 以一所共有 100 名学生的学校为例。 这个人群可以分为 4 类——学生、教师、男性和女性。 考虑下面给出的表格:
| 女性 | 男性 | 全部的 | |
| 老师 | 8 | 12 | 20 |
| 学生 | 32 | 48 | 80 |
| 全部的 | 40 | 50 | 100 |
在这里,在给定他是男人的条件下,学校的某个居民是老师的条件概率是多少。
要计算这一点,您必须过滤 60 名男性的子群体并向下钻取到 12 名男教师。
所以,期望的条件概率 P[Teacher | 男] = 12/60 = 0.2
P(教师|男)= P(教师∩男)/P(男)= 12/60 = 0.2
这可以表示为教师(A)和男性(B)除以男性(B)。 同理,B给定A的条件概率也可以计算出来。 我们用于朴素贝叶斯的规则可以从以下符号中得出:
P (A | B) = P (A ∩ B) / P(B)
P (B | A) = P (A ∩ B) / P(A)
贝叶斯法则
在贝叶斯规则中,我们从可以从训练数据集中找到的 P (X | Y) 找到 P (Y | X)。 为此,您只需将上述公式中的 A 和 B 替换为 X 和 Y。 对于观察,X 是已知变量,Y 是未知变量。 对于数据集的每一行,假设 X 已经发生,您必须计算 Y 的概率。

但是,如果 Y 中的类别超过 2 个,会发生什么情况? 我们必须计算每个 Y 类的概率以找出获胜的类。
通过贝叶斯规则,我们从 P (X | Y) 找到 P (Y | X)
从训练数据中得知:P(X | Y) = P(X ∩ Y) / P(Y)
P(证据|结果)
未知 – 对测试数据进行预测:P (Y | X) = P (X ∩ Y) / P(X)
P(结果|证据)
贝叶斯法则 = P (Y | X) = P (X | Y) * P (Y) / P (X)
朴素贝叶斯
贝叶斯规则提供了给定条件 X 的 Y 概率公式。但在现实世界中,可能存在多个 X 变量。 当你有独立的特征时,贝叶斯规则可以扩展到朴素贝叶斯规则。 X 是相互独立的。 朴素贝叶斯公式比贝叶斯公式更强大
高斯朴素贝叶斯
到目前为止,我们已经看到 X 属于类别,但是当 X 是连续变量时如何计算概率? 如果我们假设 X 遵循特定分布,则可以使用该分布的概率密度函数来计算似然概率。
如果我们假设 X 服从高斯或正态分布,我们必须代入正态分布的概率密度并将其命名为高斯朴素贝叶斯。 要计算此公式,您需要 X 的均值和方差。
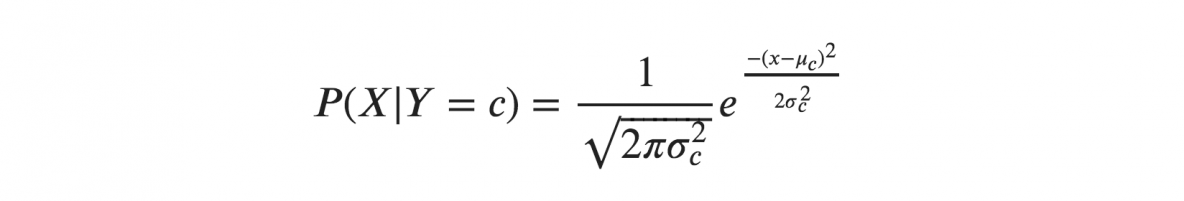
在上述公式中,sigma 和 mu 是为给定的 Y 类 c 计算的连续变量 X 的方差和均值。
高斯朴素贝叶斯的表示
上面的公式通过频率计算了每个类的输入值的概率。 我们可以计算整个分布中每个类别的 x 的均值和标准差。
这意味着除了每个类的概率,我们还必须存储该类的每个输入变量的均值和标准差。
平均值(x)= 1/n * 总和(x)
其中 n 表示实例数,x 是数据中输入变量的值。
标准差(x) = sqrt(1/n * sum(xi-mean(x)^2 ))
这里计算每个 x 的平均值和 x 的平均值的平方根,其中 n 是实例数,sum() 是求和函数,sqrt() 是平方根函数,xi 是特定的 x 值.
使用高斯朴素贝叶斯模型进行预测
高斯概率密度函数可用于通过用变量的新输入值替换参数来进行预测,因此,高斯函数将给出新输入值概率的估计值。
朴素贝叶斯分类器
朴素贝叶斯分类器假设一个特征的值独立于任何其他特征的值。 朴素贝叶斯分类器需要训练数据来估计分类所需的参数。 由于设计和应用简单,朴素贝叶斯分类器可以适用于许多现实生活场景。
结论
高斯朴素贝叶斯分类器是一种快速简单的分类器技术,无需太多努力就能很好地工作,而且准确度很高。
如果您有兴趣了解更多关于人工智能、机器学习的信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,该文凭专为在职专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业, IIIT-B 校友身份、5 个以上实用的实践顶点项目和顶级公司的工作协助。
从世界顶级大学学习ML 课程。 获得硕士、Executive PGP 或高级证书课程以加快您的职业生涯。
什么是朴素贝叶斯算法?
朴素贝叶斯是一种经典的机器学习算法。 朴素贝叶斯起源于统计学,是一种简单而强大的算法。 朴素贝叶斯是基于应用条件概率分析的分类器家族。 在该分析中,使用构成事件的每个单独事件的概率来计算事件的条件概率。 朴素贝叶斯分类器在实践中经常被发现非常有效,尤其是当特征集的维数很大时。
朴素贝叶斯算法有哪些应用?
朴素贝叶斯用于文本分类、文档分类和文档索引。 在朴素贝叶斯中,每个可能的特征在预处理阶段没有分配任何权重,而权重随后在训练和识别阶段分配。 朴素贝叶斯算法的基本假设是特征是独立的。
什么是高斯朴素贝叶斯算法?
高斯朴素贝叶斯是一种基于应用贝叶斯定理和强独立假设的概率分类算法。 在分类的上下文中,独立性是指特征的一个值的存在不会影响另一个值的存在(与概率论中的独立性不同)。 朴素是指使用对象的特征相互独立的假设。 在机器学习的背景下,朴素贝叶斯分类器以具有高度表达性、可扩展性和相当准确的特点而著称,但随着训练集的增长,它们的性能迅速下降。 许多特征有助于朴素贝叶斯分类器的成功。 最值得注意的是,它们不需要对分类模型的参数进行任何调整,它们可以很好地适应训练数据集的大小,并且可以轻松处理连续特征。