
2021 年前端性能:规划和指标
已发表: 2022-03-10本指南得到了我们在 LogRocket 的朋友的大力支持,LogRocket 是一项结合前端性能监控、会话重放和产品分析的服务,可帮助您建立更好的客户体验。 LogRocket跟踪关键指标,包括。 DOM 完成、第一个字节的时间、第一个输入延迟、客户端 CPU 和内存使用情况。 立即免费试用 LogRocket。

目录
- 准备:计划和指标
绩效文化、Core Web Vitals、绩效概况、CrUX、Lighthouse、FID、TTI、CLS、设备。 - 设定切合实际的目标
性能预算、性能目标、RAIL 框架、170KB/30KB 预算。 - 定义环境
选择框架、基线性能成本、Webpack、依赖项、CDN、前端架构、CSR、SSR、CSR + SSR、静态渲染、预渲染、PRPL 模式。 - 资产优化
Brotli、AVIF、WebP、响应式图像、AV1、自适应媒体加载、视频压缩、网络字体、谷歌字体。 - 构建优化
JavaScript 模块、模块/无模块模式、tree-shaking、代码拆分、范围提升、Webpack、差异服务、Web Worker、WebAssembly、JavaScript 包、React、SPA、部分水合、交互导入、第 3 方、缓存。 - 交付优化
延迟加载、交叉点观察器、延迟渲染和解码、关键 CSS、流式传输、资源提示、布局转换、服务工作者。 - 网络、HTTP/2、HTTP/3
OCSP 装订、EV/DV 证书、打包、IPv6、QUIC、HTTP/3。 - 测试和监控
审核工作流程、代理浏览器、404 页面、GDPR cookie 同意提示、性能诊断 CSS、可访问性。 - 快速获胜
- 一切都在一页上
- 下载清单(PDF、Apple Pages、MS Word)
- 订阅我们的电子邮件通讯不要错过下一个指南。
准备:计划和指标
微优化对于保持性能正常运行非常有用,但牢记明确定义的目标至关重要——可衡量的目标会影响整个过程中做出的任何决策。 有几种不同的模型,下面讨论的模型非常固执——只要确保尽早设定自己的优先级即可。
- 建立绩效文化。
在许多组织中,前端开发人员确切地知道常见的潜在问题是什么以及应该使用什么策略来解决这些问题。 然而,只要没有对绩效文化的既定认可,每个决策都会变成部门的战场,将组织打碎成孤岛。 您需要业务利益相关者的支持,并且要获得它,您需要建立案例研究或概念证明,以证明速度(尤其是我们稍后将详细介绍的核心 Web Vitals )收益指标和关键绩效指标( KPI )他们关心。例如,为了使性能更加有形,您可以通过显示转换率和应用程序加载时间以及渲染性能之间的相关性来揭示收入性能的影响。 或者搜索机器人的爬取率(PDF,第 27-50 页)。
如果开发/设计和业务/营销团队之间没有强有力的一致性,绩效将无法长期维持。 研究客户服务和销售团队的常见投诉,研究高跳出率和转化率下降的分析。 探索提高性能如何帮助缓解其中一些常见问题。 根据您正在与之交谈的利益相关者群体调整论点。
在移动设备和桌面设备上运行性能实验并衡量结果(例如,使用 Google Analytics)。 它将帮助您使用真实数据建立公司量身定制的案例研究。 此外,使用 WPO Stats 上发布的案例研究和实验数据将有助于提高企业对性能为何重要以及它对用户体验和业务指标的影响的敏感性。 但是,仅说明性能很重要是不够的——您还需要建立一些可衡量和可跟踪的目标,并随着时间的推移观察它们。
如何到那? 在她关于建立长期绩效的演讲中,艾莉森麦克奈特分享了一个关于她如何帮助在 Etsy 建立绩效文化的综合案例研究(幻灯片)。 最近,Tammy Everts 谈到了小型和大型组织中高效绩效团队的习惯。
在组织中进行这些对话时,重要的是要记住,就像 UX 是一系列体验一样,Web 性能也是一种分布。 正如 Karolina Szczur 指出的那样,“期望一个数字能够提供令人渴望的评级是一个有缺陷的假设。” 因此,绩效目标需要细化、可跟踪和有形。
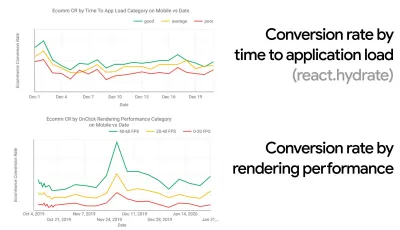
- 目标:比你最快的竞争对手至少快 20%。
根据心理学研究,如果你想让用户觉得你的网站比竞争对手的网站快,你需要至少快 20%。 研究您的主要竞争对手,收集有关他们在移动和桌面上的表现的指标,并设置有助于您超越他们的阈值。 不过,要获得准确的结果和目标,请确保首先通过研究分析来全面了解用户体验。 然后,您可以模仿第 90 个百分位数的体验进行测试。为了对竞争对手的表现有一个良好的第一印象,您可以使用 Chrome UX Report( CrUX ,一个现成的 RUM 数据集,Ilya Grigorik 的视频介绍和 Rick Viscomi 的详细指南),或 Treo,一个 RUM 监控工具由 Chrome 用户体验报告提供支持。 这些数据是从 Chrome 浏览器用户那里收集的,因此报告将是特定于 Chrome 的,但它们会为您提供相当全面的性能分布,最重要的是 Core Web Vitals 分数,分布在您的各种访问者中。 请注意,新的 CrUX 数据集在每个月的第二个星期二发布。
或者,您也可以使用:
- Addy Osmani 的 Chrome 用户体验报告比较工具,
- 速度记分卡(还提供收入影响估算器),
- 真实用户体验测试比较或
- SiteSpeed CI(基于综合测试)。
注意:如果您使用 Page Speed Insights 或 Page Speed Insights API(不,它没有被弃用!),您可以获得特定页面的 CrUX 性能数据,而不仅仅是聚合。 此数据对于为“着陆页”或“产品列表”等资产设置性能目标可能更有用。 如果您使用 CI 测试预算,如果您使用 CrUX 设置目标,则需要确保您的测试环境与 CrUX 匹配(感谢 Patrick Meenan! )。
如果您需要一些帮助来展示速度优先级背后的原因,或者您希望在性能较慢的情况下可视化转换率衰减或跳出率增加,或者您可能需要在您的组织中倡导 RUM 解决方案,Sergey Chernyshev 构建了一个 UX 速度计算器,这是一个开源工具,可帮助您模拟数据并将其可视化以推动您的观点。
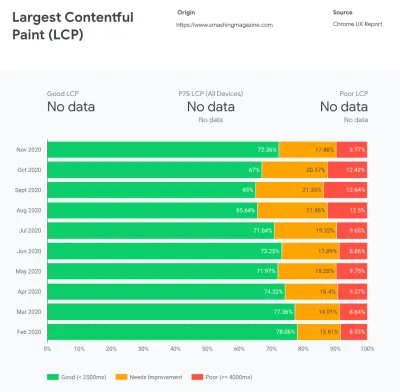
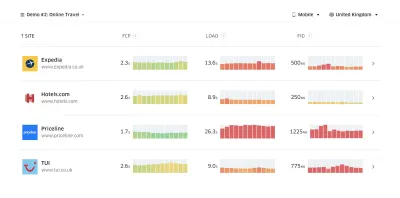
CrUX 生成随时间推移的性能分布概览,并收集来自 Google Chrome 用户的流量。 您可以在 Chrome UX Dashboard 上创建自己的。 (大预览) 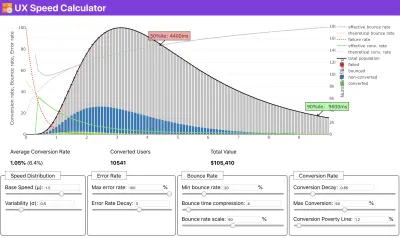
就在您需要证明性能以推动您的观点时:UX 速度计算器根据真实数据可视化性能对跳出率、转化率和总收入的影响。 (大预览) 有时您可能想更深入一点,将来自 CrUX 的数据与您已经必须快速找出减速、盲点和低效率所在的任何其他数据相结合——为您的竞争对手或您的项目。 在他的工作中,Harry Roberts 一直在使用 Site-Speed Topography 电子表格,他用它来按关键页面类型分解性能,并跟踪它们之间的不同关键指标。 您可以将电子表格下载为 Google 表格、Excel、OpenOffice 文档或 CSV。
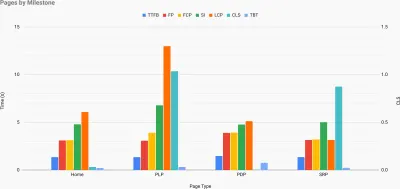
网站速度地形,其中关键指标代表网站上的关键页面。 (大预览) 如果您想一路走下去,您可以在站点的每个页面上运行 Lighthouse 性能审计(通过 Lightouse Parade),并将输出保存为 CSV。 这将帮助您确定竞争对手的哪些特定页面(或页面类型)表现更差或更好,以及您可能希望将精力集中在哪些方面。 (对于您自己的站点,最好将数据发送到分析端点!)。

使用 Lighthouse Parade,您可以在站点的每个页面上运行 Lighthouse 性能审计,并将输出保存为 CSV。 (大预览) 以这种方式收集数据、设置电子表格、削减 20% 并设置您的目标(绩效预算)。 现在你有一些可测量的东西来测试。 如果您牢记预算并尝试仅发送最少的有效负载以快速进行交互,那么您就走在了合理的道路上。
需要资源才能开始?
- Addy Osmani 写了一篇非常详细的文章,内容涉及如何开始性能预算、如何量化新功能的影响以及超出预算时从哪里开始。
- Lara Hogan 关于如何使用性能预算进行设计的指南可以为设计师提供有用的指导。
- Harry Roberts 发布了关于设置 Google Sheet 的指南,以显示第三方脚本对性能的影响,使用 Request Map,
- Jonathan Fielding 的绩效预算计算器、Katie Hempenius 的 perf-budget-calculator 和 Browser Calories 可以帮助创建预算(感谢 Karolina Szczur 的提醒)。
- 在许多公司中,绩效预算不应该是雄心勃勃的,而是务实的,作为避免滑过某个点的标志。 在这种情况下,您可以选择过去两周内最差的数据点作为阈值,然后从那里获取。 绩效预算,务实地向您展示了实现这一目标的策略。
- 此外,通过设置带有图表报告构建大小的仪表板,使性能预算和当前性能都可见。 有许多工具可以让您实现这一目标:SiteSpeed.io 仪表板(开源)、SpeedCurve 和 Calibre 只是其中的一小部分,您可以在 perf.rocks 上找到更多工具。

浏览器卡路里可帮助您设置性能预算并衡量页面是否超过这些数字。 (大预览) 一旦你有了预算,就可以将它们整合到你的构建过程中,使用 Webpack Performance Hints 和 Bundlesize、Lighthouse CI、PWMetrics 或 Sitespeed CI,以强制执行拉取请求的预算,并在 PR 评论中提供分数历史记录。
要将性能预算公开给整个团队,请通过 Lightwallet 在 Lighthouse 中集成性能预算,或使用 LHCI Action 进行快速 Github Actions 集成。 如果你需要一些自定义的东西,你可以使用webpagetest-charts-api,一个端点API,从WebPagetest结果构建图表。
不过,性能意识不应仅来自性能预算。 就像 Pinterest 一样,您可以创建一个自定义eslint规则,该规则禁止从已知依赖重的文件和目录导入,并且会使包膨胀。 设置可以在整个团队中共享的“安全”包列表。
此外,考虑对您的业务最有利的关键客户任务。 研究、讨论和定义关键操作的可接受时间阈值,并建立整个组织已批准的“UX 就绪”用户时间标记。 在许多情况下,用户旅程将涉及许多不同部门的工作,因此在可接受的时间安排方面保持一致将有助于支持或阻止未来的性能讨论。 确保增加的资源和功能的额外成本是可见和理解的。
将绩效工作与其他技术计划相结合,从正在构建的产品的新功能到重构,再到接触新的全球受众。 因此,每次关于进一步发展的对话发生时,性能也是对话的一部分。 当代码库是新鲜的或刚刚被重构时,实现性能目标要容易得多。
此外,正如 Patrick Meenan 所建议的,在设计过程中计划加载顺序和权衡是值得的。 如果您尽早确定哪些部分更关键,并定义它们应该出现的顺序,您还将知道什么可以延迟。 理想情况下,该顺序也将反映 CSS 和 JavaScript 导入的顺序,因此在构建过程中处理它们会更容易。 此外,请考虑在加载页面时(例如,尚未加载 Web 字体时)处于“中间”状态的视觉体验应该是什么。
一旦你在你的组织中建立了强大的绩效文化,目标是比你以前的自己快 20% ,以便随着时间的推移保持优先事项的机智(谢谢,Guy Podjarny! )。 但是要考虑客户的不同类型和使用行为(Tobias Baldauf 称之为节奏和群组),以及机器人流量和季节性影响。
计划,计划,计划。 尽早进行一些快速的“唾手可得”优化可能很诱人——这可能是一个快速获胜的好策略——但如果没有计划和设置现实,公司将很难将性能放在首位- 量身定制的绩效目标。
- 选择正确的指标。
并非所有指标都同样重要。 研究哪些指标对您的应用程序最重要:通常,它将由您可以多快开始渲染界面中最重要的像素以及您可以多快为这些渲染像素提供输入响应来定义。 这些知识将为您提供持续努力的最佳优化目标。 最后,定义体验的不是加载事件或服务器响应时间,而是对界面感觉有多快的感知。这是什么意思? 与其关注整个页面加载时间(例如,通过onLoad和DOMContentLoaded时间),不如优先考虑客户认为的页面加载。 这意味着专注于一组略有不同的指标。 事实上,选择正确的指标是一个没有明显赢家的过程。
根据 Tim Kadlec 的研究和 Marcos Iglesias 在他的演讲中的笔记,传统指标可以分为几组。 通常,我们需要所有这些来全面了解性能,在您的特定情况下,其中一些会比其他更重要。
- 基于数量的指标衡量请求的数量、权重和性能得分。 有利于发出警报和监控随时间的变化,但不利于理解用户体验。
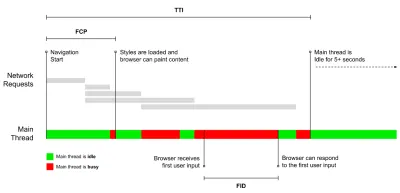
- 里程碑指标使用加载过程生命周期中的状态,例如Time To First Byte和Time To Interactive 。 适合描述用户体验和监控,不太适合了解里程碑之间发生的情况。
- 渲染指标提供对内容渲染速度的估计(例如,开始渲染时间、速度指数)。 适合测量和调整渲染性能,但不适合测量重要内容何时出现并可以与之交互。
- 自定义指标为用户测量特定的自定义事件,例如 Twitter 的 Time To First Tweet 和 Pinterest 的 PinnerWaitTime。 适合准确描述用户体验,但不适合扩展指标和与竞争对手进行比较。
为了完成这幅图,我们通常会在所有这些组中寻找有用的指标。 通常,最具体和最相关的是:
- 互动时间(TTI)
布局稳定的点,关键的网络字体可见,主线程足以处理用户输入——基本上是用户可以与 UI 交互的时间标记。 了解用户必须等待多长时间才能无延迟地使用该网站的关键指标。 Boris Schapira 写了一篇关于如何可靠地测量 TTI 的详细文章。 - 第一输入延迟(FID)或输入响应
从用户第一次与您的网站交互到浏览器实际能够响应该交互的时间。 很好地补充了 TTI,因为它描述了图片的缺失部分:当用户实际与网站交互时会发生什么。 仅用作 RUM 指标。 在浏览器中有一个用于测量 FID 的 JavaScript 库。 - 最大含量涂料(LCP)
当页面的重要内容可能已加载时,标记页面加载时间线中的点。 假设页面中最重要的元素是用户视口中可见的最大元素。 如果元素在折叠的上方和下方都呈现,则只有可见部分被认为是相关的。 - 总阻塞时间 ( TBT )
有助于量化页面在变得可靠交互之前的非交互性严重程度的指标(即,主线程在至少 5 秒内没有运行超过 50 毫秒(长任务)的任何任务)。 该指标测量第一次绘制和交互时间 (TTI) 之间的总时间量,其中主线程被阻塞足够长的时间以防止输入响应。 因此,难怪低 TBT 是良好性能的良好指标。 (谢谢,阿尔乔姆,菲尔) - 累积布局移位 ( CLS )
该指标突出显示了用户在访问网站时遇到意外布局变化(重排)的频率。 它检查了不稳定的元素及其对整体体验的影响。 分数越低越好。 - 速度指数
衡量页面内容在视觉上填充的速度; 分数越低越好。 速度指数分数是根据视觉进度的速度计算的,但它只是一个计算值。 它对视口大小也很敏感,因此您需要定义一系列与您的目标受众相匹配的测试配置。 请注意,随着 LCP 成为更相关的指标,它变得不那么重要了(感谢 Boris,Artem! )。 - 花费的 CPU 时间
一个指标,显示主线程被阻塞的频率和时间,用于绘画、渲染、脚本和加载。 高 CPU 时间是janky体验的明确指标,即当用户在他们的操作和响应之间体验到明显的延迟时。 使用 WebPageTest,您可以在“Chrome”选项卡上选择“捕获开发工具时间线”,以在使用 WebPageTest 在任何设备上运行时公开主线程的故障。 - 组件级 CPU 成本
就像所花费的 CPU 时间一样,这个由 Stoyan Stefanov 提出的指标探讨了JavaScript 对 CPU 的影响。 这个想法是使用每个组件的 CPU 指令计数来单独了解它对整体体验的影响。 可以使用 Puppeteer 和 Chrome 来实现。 - 挫折指数
虽然上面提到的许多指标解释了特定事件何时发生,但 Tim Vereecke 的 FrustrationIndex 关注的是指标之间的差距,而不是单独查看它们。 它查看最终用户感知的关键里程碑,例如标题可见、第一个内容可见、视觉准备就绪和页面准备就绪,并计算一个分数,表明加载页面时的挫败程度。 差距越大,用户感到沮丧的机会就越大。 可能是用户体验的良好 KPI。 Tim 发表了一篇关于 FrustrationIndex 及其工作原理的详细文章。 - 广告权重影响
如果您的网站依赖于广告产生的收入,那么跟踪广告相关代码的权重很有用。 Paddy Ganti 的脚本构建了两个 URL(一个正常,一个阻止广告),通过 WebPageTest 提示生成视频比较并报告一个增量。 - 偏差指标
正如 Wikipedia 工程师所指出的,您的结果中存在多少差异的数据可以告诉您您的仪器有多可靠,以及您应该对偏差和异常值给予多少关注。 较大的差异表明设置中需要进行调整。 它还有助于了解某些页面是否更难以可靠地测量,例如由于第三方脚本导致显着变化。 跟踪浏览器版本以了解推出新浏览器版本时的性能变化可能也是一个好主意。 - 自定义指标
自定义指标由您的业务需求和客户体验定义。 它要求您识别重要的像素、关键脚本、必要的 CSS 和相关资产,并衡量它们交付给用户的速度。 为此,您可以监控英雄渲染时间,或使用性能 API,为对您的业务重要的事件标记特定时间戳。 此外,您可以通过在测试结束时执行任意 JavaScript 来使用 WebPagetest 收集自定义指标。
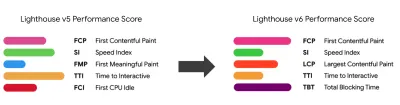
请注意,第一次有意义的绘画(FMP)没有出现在上面的概述中。 它用于深入了解服务器输出任何数据的速度。 Long FMP 通常表示 JavaScript 阻塞了主线程,但也可能与后端/服务器问题有关。 但是,该指标最近已被弃用,因为它在大约 20% 的情况下似乎不准确。 它被有效地替换为更可靠且更易于推理的 LCP。 Lighthouse 不再支持它。 仔细检查以用户为中心的最新性能指标和建议,以确保您在安全页面上(感谢 Patrick Meenan )。

Steve Souders 详细解释了其中许多指标。 重要的是要注意,虽然 Time-To-Interactive 是通过在所谓的实验室环境中运行自动审计来衡量的,但 First Input Delay 代表实际的用户体验,实际用户会遇到明显的滞后。 一般来说,始终测量和跟踪它们可能是一个好主意。
根据您的应用程序的上下文,首选指标可能会有所不同:例如,对于 Netflix TV UI,按键输入响应能力、内存使用率和 TTI 更为关键,而对于 Wikipedia,第一次/最后一次视觉变化和 CPU 时间花费指标更为重要。
注意:FID 和 TTI 都不考虑滚动行为; 滚动可以独立发生,因为它是脱离主线程的,所以对于许多内容消费网站来说,这些指标可能不那么重要(谢谢,Patrick! )。
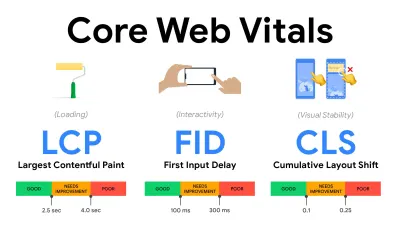
- 测量和优化 Core Web Vitals 。
长期以来,性能指标都是相当技术性的,专注于服务器响应速度和浏览器加载速度的工程视图。 多年来,这些指标发生了变化——试图找到一种方法来捕捉实际的用户体验,而不是服务器时间。 2020 年 5 月,Google 发布了 Core Web Vitals,这是一组以用户为中心的新性能指标,每个指标都代表了用户体验的不同方面。对于其中的每一个,谷歌都推荐了一系列可接受的速度目标。 至少75% 的页面浏览量应超过良好范围才能通过此评估。 这些指标迅速获得关注,随着 Core Web Vitals 在 2021 年 5 月成为 Google 搜索的排名信号(页面体验排名算法更新),许多公司将注意力转向了他们的绩效得分。
让我们一一分解每个核心网络生命力,以及有用的技术和工具,以优化您在考虑这些指标的情况下的体验。 (值得注意的是,通过遵循本文中的一般建议,您最终会获得更好的 Core Web Vitals 分数。)
- 最大内容涂料( LCP ) < 2.5 秒。
测量页面的加载,并报告在视口中可见的最大图像或文本块的渲染时间。 因此,LCP 会受到延迟渲染重要信息的所有因素的影响——无论是服务器响应时间慢、CSS 阻塞、运行中的 JavaScript(第一方或第三方)、Web 字体加载、昂贵的渲染或绘画操作、懒惰- 加载的图像、骨架屏幕或客户端渲染。
为了获得良好的体验,LCP 应在页面首次开始加载后的2.5 秒内发生。 这意味着我们需要尽早渲染页面的第一个可见部分。 这将需要为每个模板定制关键 CSS,编排<head>-order 并预取关键资产(我们稍后会介绍)。LCP 分数低的主要原因通常是图像。 要在 Fast 3G 上以 <2.5 秒的时间交付 LCP(托管在经过良好优化的服务器上,全是静态的,没有客户端渲染并且图像来自专用图像 CDN)意味着最大理论图像大小仅为 144KB 左右。 这就是为什么响应式图像很重要,以及提前预加载关键图像(使用
preload)。快速提示:要发现页面上的 LCP,在 DevTools 中,您可以将鼠标悬停在性能面板中“Timings”下的 LCP 徽章上(感谢 Tim Kadlec !)。
- 首次输入延迟( FID ) < 100ms。
衡量 UI 的响应能力,即浏览器在对离散的用户输入事件(如点击或单击)做出反应之前忙于其他任务的时间。 它旨在捕获因主线程繁忙而导致的延迟,尤其是在页面加载期间。
目标是每次交互都保持在 50-100 毫秒内。 为此,我们需要识别长任务(阻塞主线程超过 50 毫秒)并将它们分解,将一个包代码拆分为多个块,减少 JavaScript 执行时间,优化数据获取,延迟第三方的脚本执行,将 JavaScript 移动到 Web 工作者的后台线程,并使用渐进式水化来降低 SPA 中的再水化成本。快速提示:一般来说,获得更好 FID 分数的可靠策略是通过将较大的捆绑包分解成较小的捆绑包并在用户需要时提供所需的服务,从而最大限度地减少主线程上的工作,因此不会延迟用户交互. 我们将在下面详细介绍。
- 累积布局偏移( CLS ) < 0.1。
测量 UI 的视觉稳定性以确保流畅和自然的交互,即在页面生命周期内发生的每个意外布局转换的所有单独布局转换分数的总和。 每当已经可见的元素更改其在页面上的位置时,就会发生单独的布局转换。 它的评分基于内容的大小和移动的距离。
因此,每次出现转变时——例如,当备用字体和网络字体具有不同的字体指标,或者广告、嵌入或 iframe 迟到,或者图像/视频尺寸未保留,或者后期 CSS 强制重绘,或者更改由后期 JavaScript——它对 CLS 分数有影响。 良好体验的推荐值是 CLS < 0.1。
值得注意的是,Core Web Vitals 应该随着时间的推移而发展,具有可预测的年度周期。 对于第一年的更新,我们可能期望将 First Contentful Paint 提升为 Core Web Vitals,降低 FID 阈值并更好地支持单页应用程序。 我们可能还会看到负载增加后对用户输入的响应,以及安全、隐私和可访问性 (!) 考虑。
与 Core Web Vitals 相关,有很多有用的资源和文章值得研究:
- Web Vitals 排行榜可让您将自己的分数与移动设备、平板电脑、台式机以及 3G 和 4G 上的竞争对手进行比较。
- Core SERP Vitals,一个 Chrome 扩展程序,可在 Google 搜索结果中显示来自 CrUX 的 Core Web Vitals。
- 布局转换 GIF 生成器,使用简单的 GIF 可视化 CLS(也可从命令行获得)。
- web-vitals 库可以收集核心 Web Vitals 并将其发送到 Google Analytics、Google Tag Manager 或任何其他分析端点。
- 使用 WebPageTest 分析 Web Vitals,Patrick Meenan 在其中探讨了 WebPageTest 如何公开有关 Core Web Vitals 的数据。
- 使用 Core Web Vitals 进行优化,Addy Osmani 的 50 分钟视频,其中他重点介绍了如何在电子商务案例研究中改进 Core Web Vitals。
- Cumulative Layout Shift in Practice 和 Cumulative Layout Shift in the Real World 是 Nic Jansma 撰写的综合性文章,几乎涵盖了有关 CLS 的所有内容,以及它与跳出率、会话时间或 Rage Clicks 等关键指标的关系。
- What Forces Reflow,带有属性或方法的概述,当在 JavaScript 中请求/调用时,将触发浏览器同步计算样式和布局。
- CSS Triggers 显示了哪些 CSS 属性触发了 Layout、Paint 和 Composite。
- Fixing Layout Instability 是使用 WebPageTest 来识别和修复布局不稳定问题的演练。
- Cumulative Layout Shift, The Layout Instability Metric,Boris Schapira 关于 CLS 的另一个非常详细的指南,它是如何计算的,如何测量以及如何优化它。
- How To Improvement Core Web Vitals,Simon Hearne 关于每个指标(包括其他 Web Vitals,例如 FCP、TTI、TBT)的详细指南,以及它们何时发生以及如何衡量。
那么,Core Web Vitals 是要遵循的最终指标吗? 不完全的。 它们确实已经暴露在大多数 RUM 解决方案和平台中,包括 Cloudflare、Treo、SpeedCurve、Calibre、WebPageTest(已经在幻灯片视图中)、Newrelic、Shopify、Next.js、所有 Google 工具(PageSpeed Insights、Lighthouse + CI、Search控制台等)和许多其他。
然而,正如 Katie Sylor-Miller 解释的那样,Core Web Vitals 的一些主要问题是缺乏跨浏览器支持,我们并没有真正衡量用户体验的整个生命周期,而且很难关联 FID 和具有业务成果的 CLS。
由于我们应该期待 Core Web Vitals 不断发展,因此始终将Web Vitals 与您定制的指标结合起来似乎是合理的,以更好地了解您在性能方面的立场。
- 最大内容涂料( LCP ) < 2.5 秒。
- 在代表您的受众的设备上收集数据。
为了收集准确的数据,我们需要彻底选择要测试的设备。 在大多数公司中,这意味着研究分析并根据最常见的设备类型创建用户配置文件。 然而,通常仅靠分析并不能提供完整的画面。 很大一部分目标受众可能会因为体验太慢而放弃该网站(并且不再返回),因此他们的设备不太可能成为分析中最受欢迎的设备。 因此,另外对目标群体中的常用设备进行研究可能是一个好主意。根据 IDC 的数据,在 2020 年全球范围内,所有出货的手机中有 84.8% 是 Android 设备。 普通消费者每 2 年升级一次手机,在美国,手机更换周期为 33 个月。 全球最畅销的手机平均售价不到 200 美元。
那么,一个具有代表性的设备是至少 24 个月大的 Android 设备,成本为 200 美元或更少,运行速度较慢,3G,400ms RTT 和 400kbps 传输,只是稍微悲观一些。 当然,这对于您的公司来说可能会非常不同,但这已经足够接近大多数客户了。 事实上,为您的目标市场调查当前的亚马逊畅销书可能是一个好主意。 (感谢 Tim Kadlec、Henri Helvetica 和 Alex Russell 的指点! )。
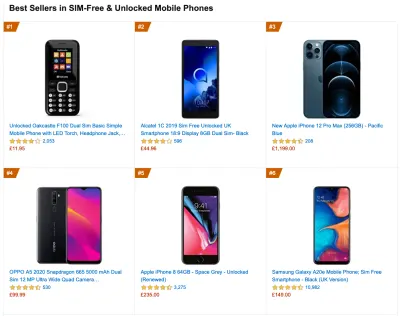
在构建新网站或应用程序时,请始终首先检查目标市场的当前亚马逊畅销书。 (大预览) 那么选择什么测试设备呢? 与上面概述的配置文件非常吻合的那些。 选择稍旧的 Moto G4/G5 Plus、中端三星设备(Galaxy A50、S8)、中端设备(如 Nexus 5X、小米 Mi A3 或小米红米 Note)是一个不错的选择7 和慢速设备,如 Alcatel 1X 或 Cubot X19,可能在开放设备实验室中。 要在速度较慢的热节流设备上进行测试,您还可以购买 Nexus 4,价格仅为 100 美元左右。
此外,请检查每台设备中使用的芯片组,不要过度代表一个芯片组:几代 Snapdragon 和 Apple 以及低端的瑞芯微、联发科就足够了(谢谢,帕特里克!) 。
如果您手头没有设备,可以通过在受限制的 3G 网络(例如 300 毫秒 RTT、1.6 Mbps 下行、0.8 Mbps 上行)和 CPU 限制(5 倍减速)上进行测试来模拟台式机上的移动体验。 最终切换到常规 3G、慢速 4G(例如 170 毫秒 RTT、9 Mbps 下行、9Mbps 上行)和 Wi-Fi。 为了使性能影响更加明显,您甚至可以引入 2G 星期二或在办公室设置节流 3G/4G 网络以加快测试速度。
请记住,在移动设备上,与台式机相比,我们应该期待 4 倍至 5 倍的减速。 移动设备具有不同的 GPU、CPU、内存和不同的电池特性。 这就是为什么拥有一个普通设备的良好配置文件并始终在这样的设备上进行测试很重要的原因。
- 综合测试工具通过预定义的设备和网络设置(例如Lighthouse 、 Calibre 、 WebPageTest )和
- 真实用户监控( RUM ) 工具持续评估用户交互并收集现场数据(例如SpeedCurve 、 New Relic——这些工具也提供综合测试)。
- 使用 Lighthouse CI 随时间跟踪 Lighthouse 分数(这非常令人印象深刻),
- 在 GitHub Actions 中运行 Lighthouse 以在每个 PR 旁边获得一份 Lighthouse 报告,
- 在站点的每个页面上运行 Lighthouse 性能审计(通过 Lightouse Parade),输出保存为 CSV,
- 如果您需要深入了解更多细节,请使用 Lighthouse 分数计算器和 Lighthouse 指标权重。
- Lighthouse 也可用于 Firefox,但在底层它使用 PageSpeed Insights API 并基于无头 Chrome 79 用户代理生成报告。

幸运的是,有许多很棒的选项可以帮助您自动收集数据并根据这些指标衡量您的网站在一段时间内的表现。 请记住,良好的性能图片涵盖一组性能指标、实验室数据和现场数据:
前者在开发过程中特别有用,因为它可以帮助您在开发产品时识别、隔离和修复性能问题。 后者对于长期维护很有用,因为它将帮助您了解实时发生的性能瓶颈——当用户实际访问该站点时。
通过利用内置的 RUM API,例如导航计时、资源计时、绘制计时、长任务等,综合测试工具和 RUM 一起提供了应用程序性能的完整图景。 您可以使用 Calibre、Treo、SpeedCurve、mPulse 和 Boomerang、Sitespeed.io,它们都是性能监控的绝佳选择。 此外,使用 Server Timing 标头,您甚至可以在一个地方监控后端和前端性能。
注意:选择浏览器外部的网络级节流器总是更安全的选择,例如,DevTools 与 HTTP/2 推送交互时存在问题,这是由于它的实现方式(感谢 Yoav,Patrick !)。 对于 Mac OS,我们可以使用 Network Link Conditioner、Windows Windows Traffic Shaper、Linux netem 和 FreeBSD dummynet。
由于您可能会在 Lighthouse 中进行测试,请记住您可以:
- 设置“干净”和“客户”配置文件进行测试。
在被动监控工具中运行测试时,关闭防病毒和后台 CPU 任务、删除后台带宽传输并使用没有浏览器扩展的干净用户配置文件进行测试以避免结果偏差(在 Firefox 和 Chrome 中)是一种常见策略。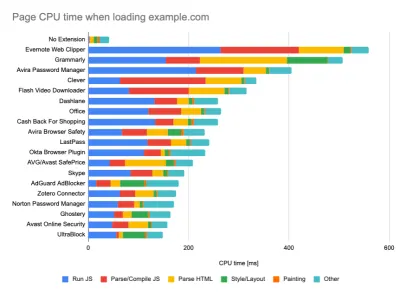
DebugBear 的报告重点介绍了 20 个最慢的扩展,包括密码管理器、广告拦截器以及 Evernote 和 Grammarly 等流行应用程序。 (大预览) 但是,研究您的客户经常使用哪些浏览器扩展,并使用专门的“客户”配置文件进行测试也是一个好主意。 事实上,某些扩展程序可能会对您的应用程序产生深远的性能影响(2020 Chrome 扩展程序性能报告),如果您的用户经常使用它们,您可能需要预先考虑。 因此,仅“干净”的配置文件结果就过于乐观,在现实生活中可能会被粉碎。
- 与您的同事分享绩效目标。
确保团队中的每个成员都熟悉绩效目标,以避免产生误解。 每一个决定——无论是设计、营销还是介于两者之间的任何决定——都会对绩效产生影响,在整个团队中分配责任和所有权将简化以后以绩效为中心的决策。 根据性能预算和早期定义的优先级映射设计决策。
目录
- 准备:计划和指标
- 设定切合实际的目标
- 定义环境
- 资产优化
- 构建优化
- 交付优化
- 网络、HTTP/2、HTTP/3
- 测试和监控
- 快速获胜
- 一切都在一页上
- 下载清单(PDF、Apple Pages、MS Word)
- 订阅我们的电子邮件通讯不要错过下一个指南。