
2021 年前端性能清单(PDF、Apple Pages、MS Word)
已发表: 2022-03-10本指南得到了我们在 LogRocket 的朋友的大力支持,LogRocket 是一项结合前端性能监控、会话重放和产品分析的服务,可帮助您建立更好的客户体验。 LogRocket跟踪关键指标,包括。 DOM 完成、第一个字节的时间、第一个输入延迟、客户端 CPU 和内存使用情况。 立即免费试用 LogRocket。

Web 性能是一个棘手的问题,不是吗? 我们如何真正知道我们在性能方面的立场,以及我们的性能瓶颈到底是什么? 是昂贵的 JavaScript、缓慢的网络字体交付、沉重的图像还是缓慢的渲染? 我们是否对 tree-shaking、范围提升、代码分割以及所有带有交叉点观察器、渐进式水化、客户端提示、HTTP/3、服务工作者和 - 哦我的 - 边缘工作者的花哨的加载模式进行了足够的优化? 而且,最重要的是,我们甚至从哪里开始提高绩效,我们如何建立长期的绩效文化?
过去,性能往往只是事后才想到的。 通常推迟到项目的最后,它可以归结为缩小、连接、资产优化以及可能对服务器的config文件进行一些微调。 现在回想起来,事情似乎发生了很大的变化。
性能不仅仅是一个技术问题:它影响从可访问性到可用性再到搜索引擎优化的方方面面,并且在将其纳入工作流程时,必须根据其性能影响来制定设计决策。 性能必须不断地被测量、监控和改进,而网络日益复杂的问题带来了新的挑战,使得跟踪指标变得困难,因为数据会因设备、浏览器、协议、网络类型和延迟而有很大差异( CDN、ISP、缓存、代理、防火墙、负载平衡器和服务器都在性能中发挥作用)。
所以,如果我们对提高性能时必须牢记的所有事情进行概述——从项目开始到网站的最终发布——那会是什么样子? 您将在下面找到2021 年(希望是公正和客观的)前端性能检查表— 对您可能需要考虑的问题的更新概述,以确保您的响应时间快速、用户交互顺畅且您的网站不消耗用户的带宽。
目录
- 全部在单独的页面上
- 准备:计划和指标
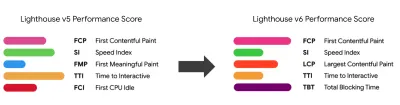
绩效文化、Core Web Vitals、绩效概况、CrUX、Lighthouse、FID、TTI、CLS、设备。 - 设定切合实际的目标
性能预算、性能目标、RAIL 框架、170KB/30KB 预算。 - 定义环境
选择框架、基线性能成本、Webpack、依赖项、CDN、前端架构、CSR、SSR、CSR + SSR、静态渲染、预渲染、PRPL 模式。 - 资产优化
Brotli、AVIF、WebP、响应式图像、AV1、自适应媒体加载、视频压缩、网络字体、谷歌字体。 - 构建优化
JavaScript 模块、模块/无模块模式、tree-shaking、代码拆分、范围提升、Webpack、差异服务、Web Worker、WebAssembly、JavaScript 包、React、SPA、部分水合、交互导入、第 3 方、缓存。 - 交付优化
延迟加载、交叉点观察器、延迟渲染和解码、关键 CSS、流式传输、资源提示、布局转换、服务工作者。 - 网络、HTTP/2、HTTP/3
OCSP 装订、EV/DV 证书、打包、IPv6、QUIC、HTTP/3。 - 测试和监控
审核工作流程、代理浏览器、404 页面、GDPR cookie 同意提示、性能诊断 CSS、可访问性。 - 快速获胜
- 下载清单(PDF、Apple Pages、MS Word)
- 我们走吧!
(您也可以只下载清单 PDF (166 KB) 或下载可编辑的 Apple Pages 文件 (275 KB) 或 .docx 文件 (151 KB)。祝大家优化愉快!)
准备:计划和指标
微优化对于保持性能正常运行非常有用,但牢记明确定义的目标至关重要——可衡量的目标会影响整个过程中做出的任何决策。 有几种不同的模型,下面讨论的模型非常固执——只要确保尽早设定自己的优先级即可。
- 建立绩效文化。
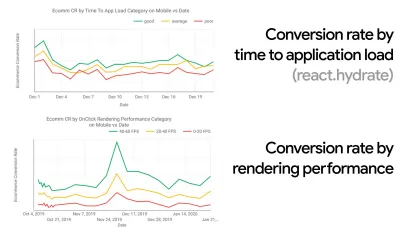
在许多组织中,前端开发人员确切地知道常见的潜在问题是什么以及应该使用什么策略来解决这些问题。 然而,只要没有对绩效文化的既定认可,每个决策都会变成部门的战场,将组织打碎成孤岛。 您需要业务利益相关者的支持,并且要获得它,您需要建立案例研究或概念证明,以证明速度(尤其是我们稍后将详细介绍的核心 Web Vitals )收益指标和关键绩效指标( KPI )他们关心。例如,为了使性能更加有形,您可以通过显示转换率和应用程序加载时间以及渲染性能之间的相关性来揭示收入性能的影响。 或者搜索机器人的爬取率(PDF,第 27-50 页)。
如果开发/设计和业务/营销团队之间没有强有力的一致性,绩效将无法长期维持。 研究客户服务和销售团队的常见投诉,研究高跳出率和转化率下降的分析。 探索提高性能如何帮助缓解其中一些常见问题。 根据您正在与之交谈的利益相关者群体调整论点。
在移动设备和桌面设备上运行性能实验并衡量结果(例如,使用 Google Analytics)。 它将帮助您使用真实数据建立公司量身定制的案例研究。 此外,使用 WPO Stats 上发布的案例研究和实验数据将有助于提高企业对性能为何重要以及它对用户体验和业务指标的影响的敏感性。 但是,仅说明性能很重要是不够的——您还需要建立一些可衡量和可跟踪的目标,并随着时间的推移观察它们。
如何到那? 在她关于建立长期绩效的演讲中,艾莉森麦克奈特分享了一个关于她如何帮助在 Etsy 建立绩效文化的综合案例研究(幻灯片)。 最近,Tammy Everts 谈到了小型和大型组织中高效绩效团队的习惯。
在组织中进行这些对话时,重要的是要记住,就像 UX 是一系列体验一样,Web 性能也是一种分布。 正如 Karolina Szczur 指出的那样,“期望一个数字能够提供令人渴望的评级是一个有缺陷的假设。” 因此,绩效目标需要细化、可跟踪和有形。
- 目标:比你最快的竞争对手至少快 20%。
根据心理学研究,如果你想让用户觉得你的网站比竞争对手的网站快,你需要至少快 20%。 研究您的主要竞争对手,收集有关他们在移动和桌面上的表现的指标,并设置有助于您超越他们的阈值。 不过,要获得准确的结果和目标,请确保首先通过研究分析来全面了解用户体验。 然后,您可以模仿第 90 个百分位数的体验进行测试。为了对竞争对手的表现有一个良好的第一印象,您可以使用 Chrome UX Report( CrUX ,一个现成的 RUM 数据集,Ilya Grigorik 的视频介绍和 Rick Viscomi 的详细指南),或 Treo,一个 RUM 监控工具由 Chrome 用户体验报告提供支持。 这些数据是从 Chrome 浏览器用户那里收集的,因此报告将是特定于 Chrome 的,但它们会为您提供相当全面的性能分布,最重要的是 Core Web Vitals 分数,分布在您的各种访问者中。 请注意,新的 CrUX 数据集在每个月的第二个星期二发布。
或者,您也可以使用:
- Addy Osmani 的 Chrome 用户体验报告比较工具,
- 速度记分卡(还提供收入影响估算器),
- 真实用户体验测试比较或
- SiteSpeed CI(基于综合测试)。
注意:如果您使用 Page Speed Insights 或 Page Speed Insights API(不,它没有被弃用!),您可以获得特定页面的 CrUX 性能数据,而不仅仅是聚合。 此数据对于为“着陆页”或“产品列表”等资产设置性能目标可能更有用。 如果您使用 CI 测试预算,如果您使用 CrUX 设置目标,则需要确保您的测试环境与 CrUX 匹配(感谢 Patrick Meenan! )。
如果您需要一些帮助来展示速度优先级背后的原因,或者您希望在性能较慢的情况下可视化转换率衰减或跳出率增加,或者您可能需要在您的组织中倡导 RUM 解决方案,Sergey Chernyshev 构建了一个 UX 速度计算器,这是一个开源工具,可帮助您模拟数据并将其可视化以推动您的观点。
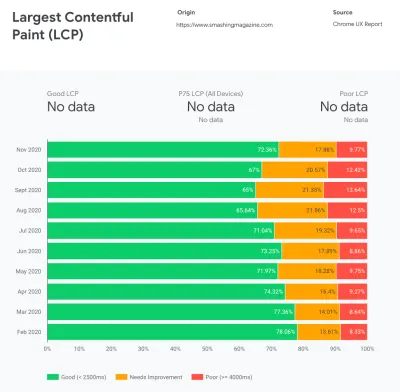
CrUX 生成随时间推移的性能分布概览,并收集来自 Google Chrome 用户的流量。 您可以在 Chrome UX Dashboard 上创建自己的。 (大预览) 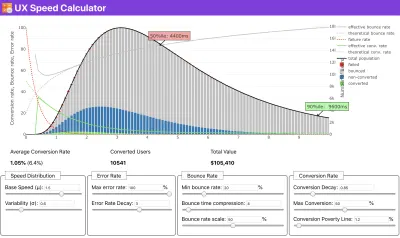
就在您需要证明性能以推动您的观点时:UX 速度计算器根据真实数据可视化性能对跳出率、转化率和总收入的影响。 (大预览) 有时您可能想更深入一点,将来自 CrUX 的数据与您已经必须快速找出减速、盲点和低效率所在的任何其他数据相结合——为您的竞争对手或您的项目。 在他的工作中,Harry Roberts 一直在使用 Site-Speed Topography 电子表格,他用它来按关键页面类型分解性能,并跟踪它们之间的不同关键指标。 您可以将电子表格下载为 Google 表格、Excel、OpenOffice 文档或 CSV。
网站速度地形,其中关键指标代表网站上的关键页面。 (大预览) 如果您想一路走下去,您可以在站点的每个页面上运行 Lighthouse 性能审计(通过 Lightouse Parade),并将输出保存为 CSV。 这将帮助您确定竞争对手的哪些特定页面(或页面类型)表现更差或更好,以及您可能希望将精力集中在哪些方面。 (对于您自己的站点,最好将数据发送到分析端点!)。

使用 Lighthouse Parade,您可以在站点的每个页面上运行 Lighthouse 性能审计,并将输出保存为 CSV。 (大预览) 以这种方式收集数据、设置电子表格、削减 20% 并设置您的目标(绩效预算)。 现在你有一些可测量的东西来测试。 如果您牢记预算并尝试仅发送最少的有效负载以快速进行交互,那么您就走在了合理的道路上。
需要资源才能开始?
- Addy Osmani 写了一篇非常详细的文章,内容涉及如何开始性能预算、如何量化新功能的影响以及超出预算时从哪里开始。
- Lara Hogan 关于如何使用性能预算进行设计的指南可以为设计师提供有用的指导。
- Harry Roberts 发布了关于设置 Google Sheet 的指南,以显示第三方脚本对性能的影响,使用 Request Map,
- Jonathan Fielding 的绩效预算计算器、Katie Hempenius 的 perf-budget-calculator 和 Browser Calories 可以帮助创建预算(感谢 Karolina Szczur 的提醒)。
- 在许多公司中,绩效预算不应该是雄心勃勃的,而是务实的,作为避免滑过某个点的标志。 在这种情况下,您可以选择过去两周内最差的数据点作为阈值,然后从那里获取。 绩效预算,务实地向您展示了实现这一目标的策略。
- 此外,通过设置带有图表报告构建大小的仪表板,使性能预算和当前性能都可见。 有许多工具可以让您实现这一目标:SiteSpeed.io 仪表板(开源)、SpeedCurve 和 Calibre 只是其中的一小部分,您可以在 perf.rocks 上找到更多工具。

浏览器卡路里可帮助您设置性能预算并衡量页面是否超过这些数字。 (大预览) 一旦你有了预算,就可以将它们整合到你的构建过程中,使用 Webpack Performance Hints 和 Bundlesize、Lighthouse CI、PWMetrics 或 Sitespeed CI,以强制执行拉取请求的预算,并在 PR 评论中提供分数历史记录。
要将性能预算公开给整个团队,请通过 Lightwallet 在 Lighthouse 中集成性能预算,或使用 LHCI Action 进行快速 Github Actions 集成。 如果你需要一些自定义的东西,你可以使用webpagetest-charts-api,一个端点API,从WebPagetest结果构建图表。
不过,性能意识不应仅来自性能预算。 就像 Pinterest 一样,您可以创建一个自定义eslint规则,该规则禁止从已知依赖重的文件和目录导入,并且会使包膨胀。 设置可以在整个团队中共享的“安全”包列表。
此外,考虑对您的业务最有利的关键客户任务。 研究、讨论和定义关键操作的可接受时间阈值,并建立整个组织已批准的“UX 就绪”用户时间标记。 在许多情况下,用户旅程将涉及许多不同部门的工作,因此在可接受的时间安排方面保持一致将有助于支持或阻止未来的性能讨论。 确保增加的资源和功能的额外成本是可见和理解的。
将绩效工作与其他技术计划相结合,从正在构建的产品的新功能到重构,再到接触新的全球受众。 因此,每次关于进一步发展的对话发生时,性能也是对话的一部分。 当代码库是新鲜的或刚刚被重构时,实现性能目标要容易得多。
此外,正如 Patrick Meenan 所建议的,在设计过程中计划加载顺序和权衡是值得的。 如果您尽早确定哪些部分更关键,并定义它们应该出现的顺序,您还将知道什么可以延迟。 理想情况下,该顺序也将反映 CSS 和 JavaScript 导入的顺序,因此在构建过程中处理它们会更容易。 此外,请考虑在加载页面时(例如,尚未加载 Web 字体时)处于“中间”状态的视觉体验应该是什么。
一旦你在你的组织中建立了强大的绩效文化,目标是比你以前的自己快 20% ,以便随着时间的推移保持优先事项的机智(谢谢,Guy Podjarny! )。 但是要考虑客户的不同类型和使用行为(Tobias Baldauf 称之为节奏和群组),以及机器人流量和季节性影响。
计划,计划,计划。 尽早进行一些快速的“唾手可得”优化可能很诱人——这可能是一个快速获胜的好策略——但如果没有计划和设置现实,公司将很难将性能放在首位- 量身定制的绩效目标。
- 选择正确的指标。
并非所有指标都同样重要。 研究哪些指标对您的应用程序最重要:通常,它将由您可以多快开始渲染界面中最重要的像素以及您可以多快为这些渲染像素提供输入响应来定义。 这些知识将为您提供持续努力的最佳优化目标。 最后,定义体验的不是加载事件或服务器响应时间,而是对界面感觉有多快的感知。这是什么意思? 与其关注整个页面加载时间(例如,通过onLoad和DOMContentLoaded时间),不如优先考虑客户认为的页面加载。 这意味着专注于一组略有不同的指标。 事实上,选择正确的指标是一个没有明显赢家的过程。
根据 Tim Kadlec 的研究和 Marcos Iglesias 在他的演讲中的笔记,传统指标可以分为几组。 通常,我们需要所有这些来全面了解性能,在您的特定情况下,其中一些会比其他更重要。
- 基于数量的指标衡量请求的数量、权重和性能得分。 有利于发出警报和监控随时间的变化,但不利于理解用户体验。
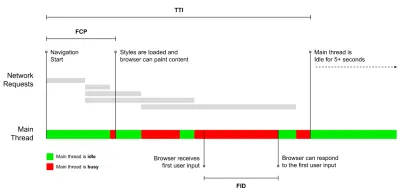
- 里程碑指标使用加载过程生命周期中的状态,例如Time To First Byte和Time To Interactive 。 适合描述用户体验和监控,不太适合了解里程碑之间发生的情况。
- 渲染指标提供对内容渲染速度的估计(例如,开始渲染时间、速度指数)。 适合测量和调整渲染性能,但不适合测量重要内容何时出现并可以与之交互。
- 自定义指标为用户测量特定的自定义事件,例如 Twitter 的 Time To First Tweet 和 Pinterest 的 PinnerWaitTime。 适合准确描述用户体验,但不适合扩展指标和与竞争对手进行比较。
为了完成这幅图,我们通常会在所有这些组中寻找有用的指标。 通常,最具体和最相关的是:
- 互动时间(TTI)
布局稳定的点,关键的网络字体可见,主线程足以处理用户输入——基本上是用户可以与 UI 交互的时间标记。 了解用户必须等待多长时间才能无延迟地使用该网站的关键指标。 Boris Schapira 写了一篇关于如何可靠地测量 TTI 的详细文章。 - 第一输入延迟(FID)或输入响应
从用户第一次与您的网站交互到浏览器实际能够响应该交互的时间。 很好地补充了 TTI,因为它描述了图片的缺失部分:当用户实际与网站交互时会发生什么。 仅用作 RUM 指标。 在浏览器中有一个用于测量 FID 的 JavaScript 库。 - 最大含量涂料(LCP)
当页面的重要内容可能已加载时,标记页面加载时间线中的点。 假设页面中最重要的元素是用户视口中可见的最大元素。 如果元素在折叠的上方和下方都呈现,则只有可见部分被认为是相关的。 - 总阻塞时间 ( TBT )
有助于量化页面在变得可靠交互之前的非交互性严重程度的指标(即,主线程在至少 5 秒内没有运行超过 50 毫秒(长任务)的任何任务)。 该指标测量第一次绘制和交互时间 (TTI) 之间的总时间量,其中主线程被阻塞足够长的时间以防止输入响应。 因此,难怪低 TBT 是良好性能的良好指标。 (谢谢,阿尔乔姆,菲尔) - 累积布局移位 ( CLS )
该指标突出显示了用户在访问网站时遇到意外布局变化(重排)的频率。 它检查了不稳定的元素及其对整体体验的影响。 分数越低越好。 - 速度指数
衡量页面内容在视觉上填充的速度; 分数越低越好。 速度指数分数是根据视觉进度的速度计算的,但它只是一个计算值。 它对视口大小也很敏感,因此您需要定义一系列与您的目标受众相匹配的测试配置。 请注意,随着 LCP 成为更相关的指标,它变得不那么重要了(感谢 Boris,Artem! )。 - 花费的 CPU 时间
一个指标,显示主线程被阻塞的频率和时间,用于绘画、渲染、脚本和加载。 高 CPU 时间是janky体验的明确指标,即当用户在他们的操作和响应之间体验到明显的延迟时。 使用 WebPageTest,您可以在“Chrome”选项卡上选择“捕获开发工具时间线”,以在使用 WebPageTest 在任何设备上运行时公开主线程的故障。 - 组件级 CPU 成本
就像所花费的 CPU 时间一样,这个由 Stoyan Stefanov 提出的指标探讨了JavaScript 对 CPU 的影响。 这个想法是使用每个组件的 CPU 指令计数来单独了解它对整体体验的影响。 可以使用 Puppeteer 和 Chrome 来实现。 - 挫折指数
虽然上面提到的许多指标解释了特定事件何时发生,但 Tim Vereecke 的 FrustrationIndex 关注的是指标之间的差距,而不是单独查看它们。 它查看最终用户感知的关键里程碑,例如标题可见、第一个内容可见、视觉准备就绪和页面准备就绪,并计算一个分数,表明加载页面时的挫败程度。 差距越大,用户感到沮丧的机会就越大。 可能是用户体验的良好 KPI。 Tim 发表了一篇关于 FrustrationIndex 及其工作原理的详细文章。 - 广告权重影响
如果您的网站依赖于广告产生的收入,那么跟踪广告相关代码的权重很有用。 Paddy Ganti 的脚本构建了两个 URL(一个正常,一个阻止广告),通过 WebPageTest 提示生成视频比较并报告一个增量。 - 偏差指标
正如 Wikipedia 工程师所指出的,您的结果中存在多少差异的数据可以告诉您您的仪器有多可靠,以及您应该对偏差和异常值给予多少关注。 较大的差异表明设置中需要进行调整。 它还有助于了解某些页面是否更难以可靠地测量,例如由于第三方脚本导致显着变化。 跟踪浏览器版本以了解推出新浏览器版本时的性能变化可能也是一个好主意。 - 自定义指标
自定义指标由您的业务需求和客户体验定义。 它要求您识别重要的像素、关键脚本、必要的 CSS 和相关资产,并衡量它们交付给用户的速度。 为此,您可以监控英雄渲染时间,或使用性能 API,为对您的业务重要的事件标记特定时间戳。 此外,您可以通过在测试结束时执行任意 JavaScript 来使用 WebPagetest 收集自定义指标。
请注意,第一次有意义的绘画(FMP)没有出现在上面的概述中。 它用于深入了解服务器输出任何数据的速度。 Long FMP 通常表示 JavaScript 阻塞了主线程,但也可能与后端/服务器问题有关。 但是,该指标最近已被弃用,因为它在大约 20% 的情况下似乎不准确。 它被有效地替换为更可靠且更易于推理的 LCP。 Lighthouse 不再支持它。 仔细检查以用户为中心的最新性能指标和建议,以确保您在安全页面上(感谢 Patrick Meenan )。
Steve Souders 详细解释了其中许多指标。 重要的是要注意,虽然 Time-To-Interactive 是通过在所谓的实验室环境中运行自动审计来衡量的,但 First Input Delay 代表实际的用户体验,实际用户会遇到明显的滞后。 一般来说,始终测量和跟踪它们可能是一个好主意。
根据您的应用程序的上下文,首选指标可能会有所不同:例如,对于 Netflix TV UI,按键输入响应能力、内存使用率和 TTI 更为关键,而对于 Wikipedia,第一次/最后一次视觉变化和 CPU 时间花费指标更为重要。
注意:FID 和 TTI 都不考虑滚动行为; 滚动可以独立发生,因为它是脱离主线程的,所以对于许多内容消费网站来说,这些指标可能不那么重要(谢谢,Patrick! )。
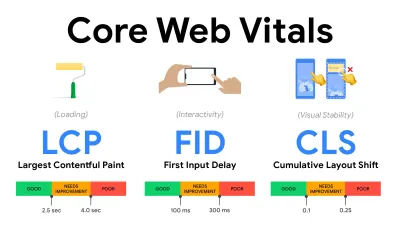
- 测量和优化 Core Web Vitals 。
长期以来,性能指标都是相当技术性的,专注于服务器响应速度和浏览器加载速度的工程视图。 多年来,这些指标发生了变化——试图找到一种方法来捕捉实际的用户体验,而不是服务器时间。 2020 年 5 月,Google 发布了 Core Web Vitals,这是一组以用户为中心的新性能指标,每个指标都代表了用户体验的不同方面。对于其中的每一个,谷歌都推荐了一系列可接受的速度目标。 至少75% 的页面浏览量应超过良好范围才能通过此评估。 这些指标迅速获得关注,随着 Core Web Vitals 在 2021 年 5 月成为 Google 搜索的排名信号(页面体验排名算法更新),许多公司将注意力转向了他们的绩效得分。
让我们一一分解每个核心网络生命力,以及有用的技术和工具,以优化您在考虑这些指标的情况下的体验。 (值得注意的是,通过遵循本文中的一般建议,您最终会获得更好的 Core Web Vitals 分数。)
- 最大内容涂料( LCP ) < 2.5 秒。
测量页面的加载,并报告在视口中可见的最大图像或文本块的渲染时间。 因此,LCP 会受到延迟渲染重要信息的所有因素的影响——无论是服务器响应时间慢、CSS 阻塞、运行中的 JavaScript(第一方或第三方)、Web 字体加载、昂贵的渲染或绘画操作、懒惰- 加载的图像、骨架屏幕或客户端渲染。
为了获得良好的体验,LCP 应在页面首次开始加载后的2.5 秒内发生。 这意味着我们需要尽早渲染页面的第一个可见部分。 这将需要为每个模板定制关键 CSS,编排<head>-order 并预取关键资产(我们稍后会介绍)。LCP 分数低的主要原因通常是图像。 要在 Fast 3G 上以 <2.5 秒的时间交付 LCP(托管在经过良好优化的服务器上,全是静态的,没有客户端渲染并且图像来自专用图像 CDN)意味着最大理论图像大小仅为 144KB 左右。 这就是为什么响应式图像很重要,以及提前预加载关键图像(使用
preload)。快速提示:要发现页面上的 LCP,在 DevTools 中,您可以将鼠标悬停在性能面板中“Timings”下的 LCP 徽章上(感谢 Tim Kadlec !)。
- 首次输入延迟( FID ) < 100ms。
衡量 UI 的响应能力,即浏览器在对离散的用户输入事件(如点击或单击)做出反应之前忙于其他任务的时间。 它旨在捕获因主线程繁忙而导致的延迟,尤其是在页面加载期间。
目标是每次交互都保持在 50-100 毫秒内。 为此,我们需要识别长任务(阻塞主线程超过 50 毫秒)并将它们分解,将一个包代码拆分为多个块,减少 JavaScript 执行时间,优化数据获取,延迟第三方的脚本执行,将 JavaScript 移动到 Web 工作者的后台线程,并使用渐进式水化来降低 SPA 中的再水化成本。快速提示:一般来说,获得更好 FID 分数的可靠策略是通过将较大的捆绑包分解成较小的捆绑包并在用户需要时提供所需的服务,从而最大限度地减少主线程上的工作,因此不会延迟用户交互. 我们将在下面详细介绍。
- 累积布局偏移( CLS ) < 0.1。
测量 UI 的视觉稳定性以确保流畅和自然的交互,即在页面生命周期内发生的每个意外布局转换的所有单独布局转换分数的总和。 每当已经可见的元素更改其在页面上的位置时,就会发生单独的布局转换。 它的评分基于内容的大小和移动的距离。
因此,每次出现转变时——例如,当备用字体和网络字体具有不同的字体指标,或者广告、嵌入或 iframe 迟到,或者图像/视频尺寸未保留,或者后期 CSS 强制重绘,或者更改由后期 JavaScript——它对 CLS 分数有影响。 良好体验的推荐值是 CLS < 0.1。
值得注意的是,Core Web Vitals 应该随着时间的推移而发展,具有可预测的年度周期。 对于第一年的更新,我们可能期望将 First Contentful Paint 提升为 Core Web Vitals,降低 FID 阈值并更好地支持单页应用程序。 我们可能还会看到负载增加后对用户输入的响应,以及安全、隐私和可访问性 (!) 考虑。
与 Core Web Vitals 相关,有很多有用的资源和文章值得研究:
- Web Vitals 排行榜可让您将自己的分数与移动设备、平板电脑、台式机以及 3G 和 4G 上的竞争对手进行比较。
- Core SERP Vitals,一个 Chrome 扩展程序,可在 Google 搜索结果中显示来自 CrUX 的 Core Web Vitals。
- 布局转换 GIF 生成器,使用简单的 GIF 可视化 CLS(也可从命令行获得)。
- web-vitals 库可以收集核心 Web Vitals 并将其发送到 Google Analytics、Google Tag Manager 或任何其他分析端点。
- 使用 WebPageTest 分析 Web Vitals,Patrick Meenan 在其中探讨了 WebPageTest 如何公开有关 Core Web Vitals 的数据。
- Optimizing with Core Web Vitals, a 50-min video with Addy Osmani, in which he highlights how to improve Core Web Vitals in an eCommerce case-study.
- Cumulative Layout Shift in Practice and Cumulative Layout Shift in the Real World are comprehensive articles by Nic Jansma, which cover pretty much everything about CLS and how it correlates with key metrics such as Bounce Rate, Session Time or Rage Clicks.
- What Forces Reflow, with an overview of properties or methods, when requested/called in JavaScript, that will trigger the browser to synchronously calculate the style and layout.
- CSS Triggers shows which CSS properties trigger Layout, Paint and Composite.
- Fixing Layout Instability is a walkthrough of using WebPageTest to identify and fix layout instability issues.
- Cumulative Layout Shift, The Layout Instability Metric, another very detailed guide by Boris Schapira on CLS, how it's calcualted, how to measure and how to optimize for it.
- How To Improve Core Web Vitals, a detailed guide by Simon Hearne on each of the metrics (including other Web Vitals, such as FCP, TTI, TBT), when they occur and how they are measured.
So, are Core Web Vitals the ultimate metrics to follow ? 不完全的。 They are indeed exposed in most RUM solutions and platforms already, including Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (in the filmstrip view already), Newrelic, Shopify, Next.js, all Google tools (PageSpeed Insights, Lighthouse + CI, Search Console etc.) and many others.
However, as Katie Sylor-Miller explains, some of the main problems with Core Web Vitals are the lack of cross-browser support, we don't really measure the full lifecycle of a user's experience, plus it's difficult to correlate changes in FID and CLS with business outcomes.
As we should be expecting Core Web Vitals to evolve, it seems only reasonable to always combine Web Vitals with your custom-tailored metrics to get a better understanding of where you stand in terms of performance.
- 最大内容涂料( LCP ) < 2.5 秒。
- Gather data on a device representative of your audience.
To gather accurate data, we need to thoroughly choose devices to test on. In most companies, that means looking into analytics and creating user profiles based on most common device types. Yet often, analytics alone doesn't provide a complete picture. A significant portion of the target audience might be abandoning the site (and not returning back) just because their experience is too slow, and their devices are unlikely to show up as the most popular devices in analytics for that reason. So, additionally conducting research on common devices in your target group might be a good idea.Globally in 2020, according to the IDC, 84.8% of all shipped mobile phones are Android devices. An average consumer upgrades their phone every 2 years, and in the US phone replacement cycle is 33 months. Average bestselling phones around the world will cost under $200.
A representative device, then, is an Android device that is at least 24 months old , costing $200 or less, running on slow 3G, 400ms RTT and 400kbps transfer, just to be slightly more pessimistic. This might be very different for your company, of course, but that's a close enough approximation of a majority of customers out there. In fact, it might be a good idea to look into current Amazon Best Sellers for your target market. ( Thanks to Tim Kadlec, Henri Helvetica and Alex Russell for the pointers! ).
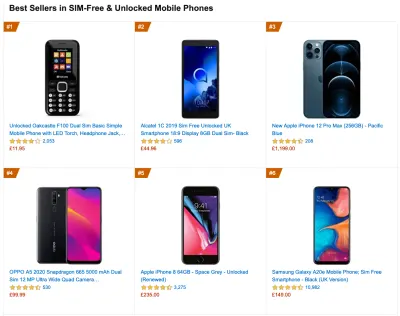
When building a new site or app, always check current Amazon Best Sellers for your target market first. (大预览) What test devices to choose then? The ones that fit well with the profile outlined above. It's a good option to choose a slightly older Moto G4/G5 Plus, a mid-range Samsung device (Galaxy A50, S8), a good middle-of-the-road device like a Nexus 5X, Xiaomi Mi A3 or Xiaomi Redmi Note 7 and a slow device like Alcatel 1X or Cubot X19, perhaps in an open device lab. For testing on slower thermal-throttled devices, you could also get a Nexus 4, which costs just around $100.
Also, check the chipsets used in each device and do not over-represent one chipset : a few generations of Snapdragon and Apple as well as low-end Rockchip, Mediatek would be enough (thanks, Patrick!) .
If you don't have a device at hand, emulate mobile experience on desktop by testing on a throttled 3G network (eg 300ms RTT, 1.6 Mbps down, 0.8 Mbps up) with a throttled CPU (5× slowdown). Eventually switch over to regular 3G, slow 4G (eg 170ms RTT, 9 Mbps down, 9Mbps up), and Wi-Fi. To make the performance impact more visible, you could even introduce 2G Tuesdays or set up a throttled 3G/4G network in your office for faster testing.
Keep in mind that on a mobile device, we should be expecting a 4×–5× slowdown compared to desktop machines. Mobile devices have different GPUs, CPU, memory and different battery characteristics. That's why it's important to have a good profile of an average device and always test on such a device.
- Synthetic testing tools collect lab data in a reproducible environment with predefined device and network settings (eg Lighthouse , Calibre , WebPageTest ) and
- Real User Monitoring ( RUM ) tools evaluate user interactions continuously and collect field data (eg SpeedCurve , New Relic — the tools provide synthetic testing, too).
- use Lighthouse CI to track Lighthouse scores over time (it's quite impressive),
- run Lighthouse in GitHub Actions to get a Lighthouse report alongside every PR,
- run a Lighthouse performance audit on every page of a site (via Lightouse Parade), with an output saved as CSV,
- use Lighthouse Scores Calculator and Lighthouse metric weights if you need to dive into more detail.
- Lighthouse is available for Firefox as well, but under the hood it uses the PageSpeed Insights API and generates a report based on a headless Chrome 79 User-Agent.

Luckily, there are many great options that help you automate the collection of data and measure how your website performs over time according to these metrics. Keep in mind that a good performance picture covers a set of performance metrics, lab data and field data:
The former is particularly useful during development as it will help you identify, isolate and fix performance issues while working on the product. The latter is useful for long-term maintenance as it will help you understand your performance bottlenecks as they are happening live — when users actually access the site.
By tapping into built-in RUM APIs such as Navigation Timing, Resource Timing, Paint Timing, Long Tasks, etc., synthetic testing tools and RUM together provide a complete picture of performance in your application. You could use Calibre, Treo, SpeedCurve, mPulse and Boomerang, Sitespeed.io, which all are great options for performance monitoring. Furthermore, with Server Timing header, you could even monitor back-end and front-end performance all in one place.
Note : It's always a safer bet to choose network-level throttlers, external to the browser, as, for example, DevTools has issues interacting with HTTP/2 push, due to the way it's implemented ( thanks, Yoav, Patrick !). For Mac OS, we can use Network Link Conditioner, for Windows Windows Traffic Shaper, for Linux netem, and for FreeBSD dummynet.
As it's likely that you'll be testing in Lighthouse, keep in mind that you can:
- Set up "clean" and "customer" profiles for testing.
While running tests in passive monitoring tools, it's a common strategy to turn off anti-virus and background CPU tasks, remove background bandwidth transfers and test with a clean user profile without browser extensions to avoid skewed results (in Firefox, and in Chrome).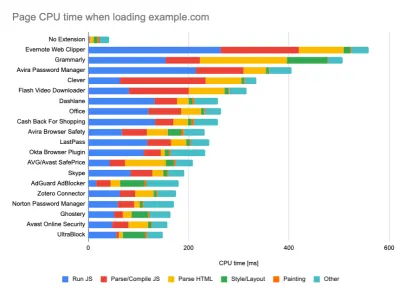
DebugBear's report highlights 20 slowest extensions, including password managers, ad-blockers and popular applications like Evernote and Grammarly. (大预览) However, it's also a good idea to study which browser extensions your customers use frequently, and test with dedicated "customer" profiles as well. In fact, some extensions might have a profound performance impact (2020 Chrome Extension Performance Report) on your application, and if your users use them a lot, you might want to account for it up front. Hence, "clean" profile results alone are overly optimistic and can be crushed in real-life scenarios.
- 与您的同事分享绩效目标。
确保团队中的每个成员都熟悉绩效目标,以避免产生误解。 每一个决定——无论是设计、营销还是介于两者之间的任何决定——都会对绩效产生影响,在整个团队中分配责任和所有权将简化以后以绩效为中心的决策。 根据性能预算和早期定义的优先级映射设计决策。
设定切合实际的目标
- 100 毫秒响应时间,60 fps。
为了让交互感觉流畅,界面有 100 毫秒来响应用户的输入。 再长一点,用户就会认为应用程序滞后。 以用户为中心的性能模型 RAIL 为您提供了健康的目标:为了允许 <100 毫秒的响应,页面必须最迟在每 <50 毫秒后将控制权交还给主线程。 估计输入延迟告诉我们是否达到了该阈值,理想情况下,它应该低于 50 毫秒。 对于动画这样的高压点,能做的最好什么都不做,不能做的绝对最少。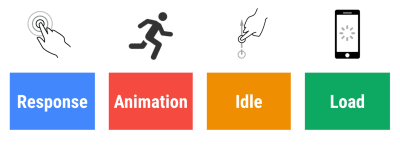
RAIL,以用户为中心的性能模型。 此外,每一帧动画应该在 16 毫秒内完成,从而达到每秒 60 帧(1 秒 ÷ 60 = 16.6 毫秒)——最好在 10 毫秒以下。 因为浏览器需要时间将新帧绘制到屏幕上,所以您的代码应该在达到 16.6 毫秒标记之前完成执行。 我们开始讨论 120fps(例如 iPad Pro 的屏幕以 120Hz 运行),Surma 已经介绍了一些 120fps 的渲染性能解决方案,但这可能不是我们目前正在关注的目标。
对性能预期持悲观态度,但对界面设计持乐观态度并明智地使用空闲时间(检查 idlize、idle-until-urgent 和 react-idle)。 显然,这些目标适用于运行时性能,而不是加载性能。
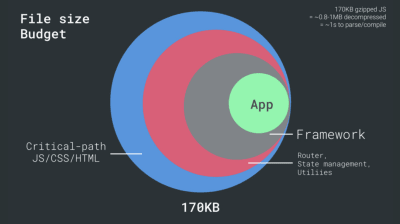
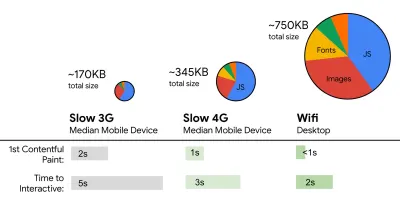
- FID < 100ms, LCP < 2.5s, TTI < 5s on 3G, 关键文件大小预算 < 170KB (gzipped)。
虽然这可能很难实现,但一个好的最终目标是 Time to Interactive 低于 5 秒,而对于重复访问,目标是低于 2 秒(只有通过服务人员才能实现)。 以 2.5 秒以下的最大内容绘制为目标,并最大限度地减少总阻塞时间和累积布局偏移。 可接受的首次输入延迟低于 100 毫秒至 70 毫秒。 如上所述,我们考虑的基准是 200 美元的 Android 手机(例如 Moto G4),在慢速 3G 网络上,模拟 400ms RTT 和 400kbps 传输速度。我们有两个主要的限制因素,它们有效地形成了在网络上快速交付内容的合理目标。 一方面,由于 TCP 慢启动,我们有网络传输限制。 HTML 的前 14KB——10 个 TCP 数据包,每个 1460 字节,大约 14.25 KB,尽管不是字面意思——是最关键的有效负载块,也是预算中唯一可以在第一次往返中交付的部分(由于移动唤醒时间,这是您在 400 毫秒 RTT 时 1 秒内获得的所有数据)。

对于 TCP 连接,我们从一个小的拥塞窗口开始,并在每次往返时将其加倍。 在第一次往返中,我们可以容纳 14 KB。 来自:Ilya Grigorik 的高性能浏览器网络。 (大预览) (注意:由于 TCP 通常在很大程度上未充分利用网络连接,因此 Google 开发了 TCP 瓶颈带宽和 RRT( BBR ),这是一种 TCP 延迟控制的 TCP 流量控制算法。专为现代网络设计,它可以响应实际的拥塞,而不是像 TCP 那样丢包,它明显更快,具有更高的吞吐量和更低的延迟——并且算法的工作方式不同。(谢谢,维克多,巴里! )
另一方面,由于 JavaScript 解析和执行时间,我们对内存和 CPU 有硬件限制(我们稍后会详细讨论)。 为了实现第一段中所述的目标,我们必须考虑 JavaScript 的关键文件大小预算。 对于预算应该是多少(这在很大程度上取决于您的项目的性质),意见各不相同,但 170KB JavaScript gzip 的预算已经在中端手机上解析和编译需要 1 秒。 假设 170KB 在解压后扩展为该大小的 3 倍(0.7MB),这可能是 Moto G4/G5 Plus 上“体面”用户体验的丧钟。
以 Wikipedia 网站为例,2020 年,在全球范围内,Wikipedia 用户的代码执行速度提高了 19%。 因此,如果您的年度网络性能指标保持稳定,这通常是一个警告信号,因为随着环境的不断改善,您实际上正在倒退(Gilles Dubuc 的博客文章中有详细信息)。
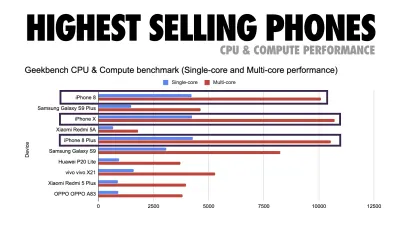
如果您想瞄准东南亚、非洲或印度等成长型市场,您将不得不考虑一组截然不同的限制条件。 Addy Osmani 涵盖了主要的功能手机限制,例如低成本、高质量的设备、高质量网络的不可用和昂贵的移动数据——以及这些环境的PRPL-30 预算和开发指南。
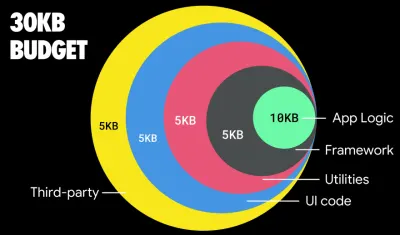
根据 Addy Osmani 的说法,延迟加载路由的推荐大小也小于 35 KB。 (大预览) 
如果针对功能手机,Addy Osmani 建议使用 PRPL-30 性能预算(压缩后 30KB + 缩小的初始捆绑包)。 (大预览) 事实上,Google 的 Alex Russell 建议将 gzip 压缩后的 130-170KB 作为合理的上限。 在现实世界的场景中,大多数产品甚至都没有接近:今天的中位数捆绑大小约为 452KB,与 2015 年初相比增长了 53.6%。在中产阶级移动设备上,这占 12-20 秒的时间-To-Interactive 。
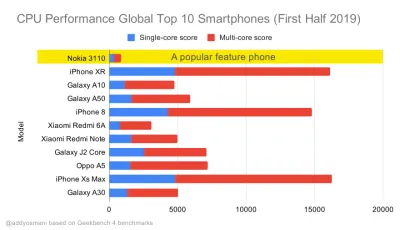
2019 年全球最畅销智能手机的 Geekbench CPU 性能基准测试。JavaScript 强调单核性能(请记住,它本质上比 Web 平台的其他部分更单线程)并且受 CPU 限制。 来自 Addy 的文章“在 20 美元的功能手机上快速加载网页”。 (大预览) 不过,我们也可以超出捆绑包大小的预算。 例如,我们可以根据浏览器主线程的活动设置性能预算,即开始渲染之前的绘制时间,或跟踪前端 CPU 占用率。 Calibre、SpeedCurve 和 Bundlesize 等工具可以帮助您控制预算,并且可以集成到您的构建过程中。
最后,性能预算可能不应该是一个固定值。 根据网络连接,性能预算应该适应,但较慢连接的有效负载更加“昂贵”,无论它们如何使用。
注意:在广泛传播的 HTTP/2、即将到来的 5G 和 HTTP/3、快速发展的手机和蓬勃发展的 SPA 时代,设置如此严格的预算可能听起来很奇怪。 然而,当我们处理网络和硬件的不可预测性时,它们听起来确实是合理的,包括从拥挤的网络到缓慢发展的基础设施,再到数据上限、代理浏览器、保存数据模式和偷偷摸摸的漫游费用。
定义环境
- 选择并设置您的构建工具。
不要过分关注这些天所谓的酷。 坚持您的构建环境,无论是 Grunt、Gulp、Webpack、Parcel 还是工具组合。 只要你得到你需要的结果并且你在维护你的构建过程没有问题,你就做得很好。在构建工具中,Rollup 和 Snowpack 一直受到关注,但 Webpack 似乎是最成熟的工具,有数百个插件可用于优化构建的大小。 注意 Webpack 路线图 2021。
最近出现的最著名的策略之一是在 Next.js 和 Gatsby 中使用 Webpack 进行粒度分块,以最大限度地减少重复代码。 默认情况下,可以为不使用它的路由请求未在每个入口点共享的模块。 这最终成为一种开销,因为下载的代码比必要的多。 通过 Next.js 中的粒度分块,我们可以使用服务器端构建清单文件来确定哪些输出的块被不同的入口点使用。
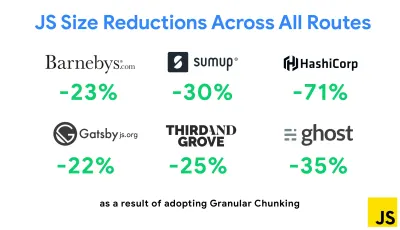
为了减少 Webpack 项目中的重复代码,我们可以使用粒度分块,在 Next.js 和 Gatsby 中默认启用。 图片来源:艾迪·奥斯马尼。 (大预览) 使用 SplitChunksPlugin,根据多个条件创建多个拆分块,以防止跨多个路由获取重复代码。 这改善了导航期间的页面加载时间和缓存。 在 Next.js 9.2 和 Gatsby v2.20.7 中发布。
不过,开始使用 Webpack 可能会很困难。 所以如果你想深入研究 Webpack,这里有一些很棒的资源:
- Webpack 文档——显然——是一个很好的起点,Webpack - Raja Rao 的 The Confusing Bits 和 Andrew Welch 的 An Annotated Webpack Config 也是如此。
- Sean Larkin 有一个关于 Webpack 的免费课程:核心概念和 Jeffrey Way 为每个人发布了一个很棒的关于 Webpack 的免费课程。 它们都是深入研究 Webpack 的绝佳介绍。
- Webpack Fundamentals 是一个非常全面的 4 小时课程,由 FrontendMasters 发布,由 Sean Larkin 教授。
- Webpack 示例有数百个现成的 Webpack 配置,按主题和用途分类。 奖励:还有一个生成基本配置文件的 Webpack 配置配置器。
- awesome-webpack 是一个有用的 Webpack 资源、库和工具的精选列表,包括 Angular、React 和框架无关项目的文章、视频、课程、书籍和示例。
- 使用 Webpack 进行快速生产资产构建的旅程是 Etsy 的案例研究,该案例研究团队如何从使用基于 RequireJS 的 JavaScript 构建系统切换到使用 Webpack,以及他们如何优化他们的构建,平均在4 分钟内管理超过 13,200 个资产。
- Webpack 性能技巧是 Ivan Akulov 的一个金矿主题,其中包含许多以性能为中心的技巧,包括专门针对 Webpack 的技巧。
- awesome-webpack-perf 是一个金矿 GitHub 存储库,其中包含有用的 Webpack 工具和插件以提高性能。 也由 Ivan Akulov 维护。
- 使用渐进增强作为默认值。
尽管如此,经过这么多年,将渐进增强作为前端架构和部署的指导原则是一个安全的选择。 首先设计和构建核心体验,然后使用功能强大的浏览器的高级功能增强体验,创造弹性体验。 如果您的网站在次优网络上运行速度较慢且浏览器较差且屏幕较差的机器上运行得很快,那么它只会在速度较快且浏览器良好且网络良好的机器上运行得更快。事实上,通过自适应模块服务,我们似乎正在将渐进增强提升到另一个层次,为低端设备提供“精简”核心体验,并为高端设备提供更复杂的功能。 渐进式增强不太可能很快消失。
- 选择强大的性能基准。
有很多未知因素影响加载——网络、热节流、缓存驱逐、第三方脚本、解析器阻塞模式、磁盘 I/O、IPC 延迟、安装的扩展、防病毒软件和防火墙、后台 CPU 任务、硬件和内存限制, L2/L3 缓存、RTTS 的差异——JavaScript 的体验成本最高,仅次于默认阻止渲染的 Web 字体和通常消耗过多内存的图像。 随着性能瓶颈从服务器转移到客户端,作为开发人员,我们必须更详细地考虑所有这些未知因素。170KB 的预算已经包含关键路径 HTML/CSS/JavaScript、路由器、状态管理、实用程序、框架和应用程序逻辑,我们必须彻底检查网络传输成本、解析/编译时间和运行时成本我们选择的框架。 幸运的是,在过去几年中,我们已经看到浏览器解析和编译脚本的速度有了巨大的改进。 然而,JavaScript 的执行仍然是主要瓶颈,因此密切关注脚本执行时间和网络可能会产生影响。
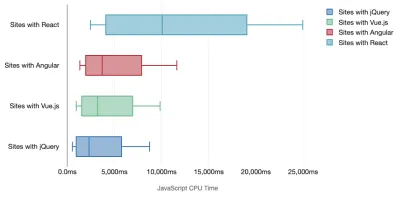
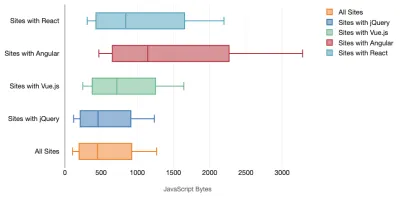
Tim Kadlec 对现代框架的性能进行了出色的研究,并在“JavaScript 框架有成本”一文中对其进行了总结。 我们经常谈论独立框架的影响,但正如 Tim 所说,在实践中,使用多个框架并不少见。 也许是旧版本的 jQuery 正在慢慢迁移到现代框架,以及一些使用旧版本 Angular 的遗留应用程序。 因此,探索 JavaScript 字节和 CPU 执行时间的累积成本更合理,这很容易使用户体验几乎无法使用,即使在高端设备上也是如此。
一般来说,现代框架不会优先考虑功能较弱的设备,因此手机和台式机上的体验在性能方面通常会大不相同。 根据研究,使用 React 或 Angular 的网站在 CPU 上花费的时间比其他网站多(当然这并不一定说 React 在 CPU 上比 Vue.js 更昂贵)。
根据 Tim 的说法,有一件事是显而易见的:“如果您使用框架来构建您的网站,那么您就需要在初始性能方面进行权衡——即使在最好的情况下也是如此。”
- 评估框架和依赖项。
现在,并不是每个项目都需要一个框架,也不是单页应用程序的每个页面都需要加载一个框架。 在 Netflix 的案例中,“从客户端移除 React、多个库和相应的应用程序代码将 JavaScript 的总量减少了超过 200KB,导致 Netflix 的注销主页的 Time-to-Interactivity 减少了 50% 以上。” 然后,团队利用用户在登陆页面上花费的时间来为用户可能登陆的后续页面预取 React(请继续阅读以了解详细信息)。那么,如果您完全删除关键页面上的现有框架怎么办? 使用 Gatsby,您可以检查 gatsby-plugin-no-javascript,它会从静态 HTML 文件中删除 Gatsby 创建的所有 JavaScript 文件。 在 Vercel 上,您还可以允许在生产中为某些页面禁用运行时 JavaScript(实验性)。
一旦选择了一个框架,我们将至少使用它几年,所以如果我们需要使用一个框架,我们需要确保我们的选择是明智的和经过深思熟虑的——尤其是对于我们的关键性能指标关心。
数据显示,默认情况下,框架非常昂贵:58.6% 的 React 页面交付超过 1 MB 的 JavaScript,36% 的 Vue.js 页面加载的 First Contentful Paint 小于 1.5 秒。 根据 Ankur Sethi 的一项研究,“无论你如何优化它,你的 React 应用程序在印度普通手机上的加载速度永远不会超过 1.1 秒。你的 Angular 应用程序总是至少需要 2.7 秒才能启动。您的 Vue 应用程序的用户需要等待至少 1 秒钟才能开始使用它。” 无论如何,您可能不会将印度作为您的主要市场,但在网络条件欠佳的情况下访问您的网站的用户将获得类似的体验。
当然,可以快速制作 SPA,但它们并不是开箱即用的快速,因此我们需要考虑制作和保持快速所需的时间和精力。 尽早选择轻量级的基准性能成本可能会更容易。
那么我们如何选择框架呢? 在选择选项之前,至少考虑大小的总成本 + 初始执行时间是个好主意; Preact、Inferno、Vue、Svelte、Alpine 或 Polymer 等轻量级选项可以很好地完成工作。 基线的大小将定义应用程序代码的约束。
正如 Seb Markbage 所指出的,衡量框架启动成本的一个好方法是首先渲染一个视图,然后删除它,然后再次渲染,因为它可以告诉您框架如何扩展。 第一次渲染往往会预热一堆延迟编译的代码,更大的树在扩展时可以从中受益。 第二个渲染基本上是模拟页面上的代码重用如何随着页面复杂性的增长而影响性能特征。
您可以通过探索特性、可访问性、稳定性、性能、包生态系统、社区、学习曲线、文档、工具、跟踪记录,在 Sacha Greif 的 12 分制评分系统上评估您的候选人(或一般的任何 JavaScript 库) 、团队、兼容性、安全性等。
Perf Track 大规模跟踪框架性能。 (大预览) 您还可以依赖在较长时间内在网络上收集的数据。 例如,Perf Track 大规模跟踪框架性能,显示使用 Angular、React、Vue、Polymer、Preact、Ember、Svelte 和 AMP 构建的网站的原始聚合Core Web Vitals 分数。 您甚至可以指定和比较使用 Gatsby、Next.js 或 Create React App 构建的网站,以及使用 Nuxt.js (Vue) 或 Sapper (Svelte) 构建的网站。
一个好的起点是为您的应用程序选择一个好的默认堆栈。 Gatsby (React)、Next.js (React)、Vuepress (Vue)、Preact CLI 和 PWA Starter Kit 提供了合理的默认值,可以在普通移动硬件上开箱即用地快速加载。 另外,请查看针对 React 和 Angular 的 web.dev 框架特定的性能指南(感谢 Phillip! )。
或许您可以采用一种更令人耳目一新的方法来完全构建单页应用程序——Turbolinks,一个 15KB 的 JavaScript 库,它使用 HTML 而不是 JSON 来呈现视图。 因此,当您点击链接时,Turbolinks 会自动获取页面,交换其
<body>并合并其<head>,所有这些都不会产生整个页面加载的成本。 您可以查看有关堆栈(Hotwire)的快速详细信息和完整文档。
- 客户端渲染还是服务器端渲染? 两个都!
这是一个相当激烈的谈话。 最终的方法是设置某种渐进式引导:使用服务器端渲染来获得快速的 First Contentful Paint,但还包括一些最少的必要 JavaScript 以保持与 First Contentful Paint 接近的交互时间。 如果在 FCP 之后 JavaScript 来得太晚,浏览器会在解析、编译和执行后期发现的 JavaScript 时锁定主线程,从而束缚站点或应用程序的交互性。为避免这种情况,请始终将函数的执行分解为单独的异步任务,并在可能的情况下使用
requestIdleCallback。 考虑使用 WebPack 的动态import()支持延迟加载 UI 的部分,避免加载、解析和编译成本,直到用户真正需要它们(感谢 Addy! )。如上所述,交互时间 (TTI) 告诉我们导航和交互之间的时间。 具体来说,该指标是通过查看初始内容呈现后的第一个 5 秒窗口来定义的,其中没有任何 JavaScript 任务花费超过 50 毫秒(长任务)。 如果发生超过 50 毫秒的任务,则重新开始搜索 5 秒窗口。 结果,浏览器将首先假定它到达Interactive ,只是为了切换到Frozen ,最终切换回Interactive 。
一旦我们到达Interactive ,我们就可以 - 按需或在时间允许的情况下 - 启动应用程序的非必要部分。 不幸的是,正如 Paul Lewis 所注意到的,框架通常没有可以向开发人员展示的简单优先级概念,因此对于大多数库和框架来说,渐进式引导并不容易实现。
不过,我们正在到达那里。 这些天来,我们可以探索几个选择,Houssein Djirdeh 和 Jason Miller 在他们关于 Rendering on the Web 的演讲以及 Jason 和 Addy 关于现代前端架构的文章中对这些选项进行了很好的概述。 下面的概述基于他们的出色工作。
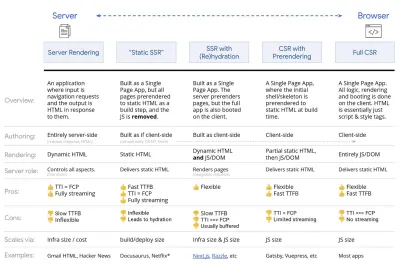
- 完整的服务器端渲染(SSR)
在 WordPress 等经典 SSR 中,所有请求都完全在服务器上处理。 请求的内容作为完成的 HTML 页面返回,浏览器可以立即呈现它。 因此,例如,SSR 应用程序不能真正使用 DOM API。 First Contentful Paint 和 Time to Interactive 之间的差距通常很小,并且页面可以在 HTML 流式传输到浏览器时立即呈现。这避免了在客户端获取数据和模板的额外往返,因为它是在浏览器得到响应之前处理的。 但是,我们最终会得到更长的服务器思考时间,从而导致第一个字节的时间,并且我们没有利用现代应用程序的响应式和丰富的特性。
- 静态渲染
我们将产品构建为单页应用程序,但所有页面都使用最少的 JavaScript 作为构建步骤预先呈现为静态 HTML。 这意味着通过静态渲染,我们可以提前为每个可能的 URL生成单独的 HTML 文件,这是很多应用程序无法承受的。 但是由于不必动态生成页面的 HTML,我们可以实现始终如一的快速首字节时间。 因此,我们可以快速显示一个登录页面,然后为后续页面预取一个 SPA 框架。 Netflix 采用了这种方法,将加载和交互时间减少了 50%。 - 使用(重新)水合的服务器端渲染(通用渲染,SSR + CSR)
我们可以尝试使用两全其美的方法——SSR 和 CSR 方法。 通过混合水化,从服务器返回的 HTML 页面还包含一个脚本,用于加载成熟的客户端应用程序。 理想情况下,实现快速的 First Contentful Paint(如 SSR),然后通过(重新)水化继续渲染。 不幸的是,这种情况很少见。 更常见的情况是,页面看起来确实准备好了,但它无法响应用户的输入,从而产生愤怒的点击和放弃。使用 React,我们可以在 Express 等 Node 服务器上使用
ReactDOMServer模块,然后调用renderToString方法将顶级组件呈现为静态 HTML 字符串。使用 Vue.js,我们可以使用 vue-server-renderer 使用
renderToString将 Vue 实例渲染为 HTML。 在 Angular 中,我们可以使用@nguniversal将客户端请求转换为完全由服务器渲染的 HTML 页面。 使用 Next.js (React) 或 Nuxt.js (Vue) 也可以开箱即用地实现完全服务器渲染的体验。这种方法有其缺点。 因此,我们确实获得了客户端应用程序的完全灵活性,同时提供了更快的服务器端渲染,但我们最终也会在 First Contentful Paint 和 Time To Interactive 之间存在更长的差距,并且增加了 First Input Delay。 补液非常昂贵,通常仅此策略还不够好,因为它会严重延迟 Time To Interactive。
- 使用渐进式水化 (SSR + CSR) 的流式服务器端渲染
为了最小化 Time To Interactive 和 First Contentful Paint 之间的差距,我们一次渲染多个请求,并在生成内容时分块发送内容。 因此,我们不必在将内容发送到浏览器之前等待完整的 HTML 字符串,从而改进了 Time To First Byte。在 React 中,我们可以使用 renderToNodeStream() 来代替
renderToString()() 来管道响应并以块的形式发送 HTML。 在 Vue 中,我们可以使用可以管道和流式传输的 renderToStream()。 使用 React Suspense,我们也可以为此目的使用异步渲染。在客户端,我们不是一次启动整个应用程序,而是逐步启动组件。 应用程序的部分首先通过代码拆分分解为独立的脚本,然后逐渐水合(按照我们的优先级顺序)。 事实上,我们可以先对关键成分进行水合,然后再对其余成分进行水合。 然后,每个组件可以不同地定义客户端和服务器端渲染的角色。 然后,我们还可以推迟某些组件的水合,直到它们出现,或者用户交互需要,或者浏览器空闲时。
对于 Vue,Markus Oberlehner 发布了一份关于使用用户交互水合以及 vue-lazy-hydration 减少 SSR 应用程序的交互时间的指南,这是一个早期插件,可在可见性或特定用户交互上启用组件水合。 Angular 团队使用 Ivy Universal 进行渐进式补水。 您也可以使用 Preact 和 Next.js 实现部分水合。
- 三态渲染
有了服务工作者,我们可以使用流式服务器渲染来进行初始/非 JS 导航,然后让服务工作者在安装后为导航渲染 HTML。 在这种情况下,Service Worker 会预先呈现内容并启用 SPA 风格的导航,以便在同一会话中呈现新视图。 当您可以在服务器、客户端页面和服务工作者之间共享相同的模板和路由代码时,效果很好。
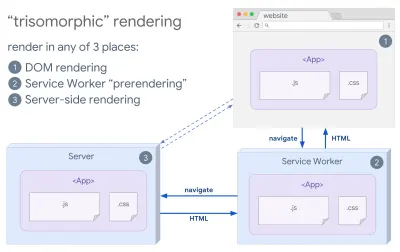
三态渲染,在任何 3 个地方都具有相同的代码渲染:在服务器上、在 DOM 中或在 service worker 中。 (图片来源:Google Developers)(大图预览) - 带有预渲染的 CSR
预渲染类似于服务器端渲染,但不是在服务器上动态渲染页面,而是在构建时将应用程序渲染为静态 HTML。 虽然静态页面无需太多客户端 JavaScript 即可完全交互,但预渲染的工作方式有所不同。 基本上,它在构建时将客户端应用程序的初始状态捕获为静态 HTML,而通过预渲染,必须在客户端上启动应用程序才能使页面具有交互性。使用 Next.js,我们可以通过将应用程序预渲染为静态 HTML 来使用静态 HTML 导出。 在 Gatsby 中,一个使用 React 的开源静态站点生成器,在构建期间使用
renderToStaticMarkup方法而不是renderToString方法,预加载主 JS 块并预取未来路由,没有简单静态页面不需要的 DOM 属性。对于 Vue,我们可以使用 Vuepress 来达到同样的目的。 你也可以在 Webpack 中使用 prerender-loader。 Navi 也提供静态渲染。
结果是更好的 Time To First Byte 和 First Contentful Paint,我们减少了 Time To Interactive 和 First Contentful Paint 之间的差距。 如果预计内容会发生很大变化,我们就不能使用这种方法。 此外,必须提前知道所有 URL 才能生成所有页面。 所以一些组件可能会使用预渲染来渲染,但如果我们需要动态的东西,我们必须依赖应用程序来获取内容。
- 完整的客户端渲染(CSR)
所有逻辑、渲染和启动都在客户端完成。 结果通常是 Time To Interactive 和 First Contentful Paint 之间的巨大差距。 结果,应用程序经常感觉迟缓,因为整个应用程序必须在客户端上启动才能呈现任何内容。由于 JavaScript 有性能成本,随着 JavaScript 的数量随着应用程序的增长而增长,激进的代码拆分和延迟 JavaScript 将绝对有必要驯服 JavaScript 的影响。 对于这种情况,如果不需要太多交互性,服务器端渲染通常是更好的方法。 如果这不是一个选项,请考虑使用 App Shell 模型。
一般来说,SSR 比 CSR 快。 然而,对于许多应用程序来说,它仍然是一个相当频繁的实现。
那么,客户端还是服务器端? 一般来说,将完全客户端框架的使用限制在绝对需要它们的页面上是一个好主意。 对于高级应用程序,单独依赖服务器端渲染也不是一个好主意。 如果做得不好,服务器渲染和客户端渲染都是一场灾难。
无论您是倾向于 CSR 还是 SSR,请确保您尽快渲染重要的像素,并将该渲染与 Time To Interactive 之间的差距最小化。 如果您的页面没有太大变化,请考虑预渲染,并尽可能推迟框架的启动。 使用服务器端渲染将 HTML 分块流式传输,并为客户端渲染实现渐进式水合- 并在可见性、交互或空闲时间进行水合,以获得两全其美的效果。
- 完整的服务器端渲染(SSR)

- 我们可以静态服务多少?
无论您是在处理大型应用程序还是小型站点,都值得考虑哪些内容可以从 CDN(即 JAM 堆栈)静态提供,而不是动态生成。 即使您拥有数千种产品和数百个具有大量个性化选项的过滤器,您仍可能希望静态提供关键登录页面,并将这些页面与您选择的框架分离。有很多静态站点生成器,它们生成的页面通常非常快。 The more content we can pre-build ahead of time instead of generating page views on a server or client at request time, the better performance we will achieve.
In Building Partially Hydrated, Progressively Enhanced Static Websites, Markus Oberlehner shows how to build out websites with a static site generator and an SPA, while achieving progressive enhancement and a minimal JavaScript bundle size. Markus uses Eleventy and Preact as his tools, and shows how to set up the tools, add partial hydration, lazy hydration, client entry file, configure Babel for Preact and bundle Preact with Rollup — from start to finish.
With JAMStack used on large sites these days, a new performance consideration appeared: the build time . In fact, building out even thousands of pages with every new deploy can take minutes, so it's promising to see incremental builds in Gatsby which improve build times by 60 times , with an integration into popular CMS solutions like WordPress, Contentful, Drupal, Netlify CMS and others.
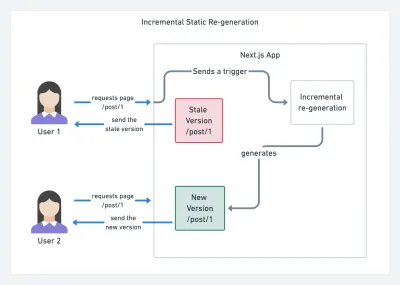
Incremental static regeneration with Next.js. (Image credit: Prisma.io) (Large preview) Also, Next.js announced ahead-of-time and incremental static generation, which allows us to add new static pages at runtime and update existing pages after they've been already built, by re-rendering them in the background as traffic comes in.
Need an even more lightweight approach? In his talk on Eleventy, Alpine and Tailwind: towards a lightweight Jamstack, Nicola Goutay explains the differences between CSR, SSR and everything-in-between, and shows how to use a more lightweight approach — along with a GitHub repo that shows the approach in practice.
- Consider using PRPL pattern and app shell architecture.
Different frameworks will have different effects on performance and will require different strategies of optimization, so you have to clearly understand all of the nuts and bolts of the framework you'll be relying on. When building a web app, look into the PRPL pattern and application shell architecture. The idea is quite straightforward: Push the minimal code needed to get interactive for the initial route to render quickly, then use service worker for caching and pre-caching resources and then lazy-load routes that you need, asynchronously.
- Have you optimized the performance of your APIs?
APIs are communication channels for an application to expose data to internal and third-party applications via endpoints . When designing and building an API, we need a reasonable protocol to enable the communication between the server and third-party requests. Representational State Transfer ( REST ) is a well-established, logical choice: it defines a set of constraints that developers follow to make content accessible in a performant, reliable and scalable fashion. Web services that conform to the REST constraints, are called RESTful web services .As with good ol' HTTP requests, when data is retrieved from an API, any delay in server response will propagate to the end user, hence delaying rendering . When a resource wants to retrieve some data from an API, it will need to request the data from the corresponding endpoint. A component that renders data from several resources, such as an article with comments and author photos in each comment, may need several roundtrips to the server to fetch all the data before it can be rendered. Furthermore, the amount of data returned through REST is often more than what is needed to render that component.
If many resources require data from an API, the API might become a performance bottleneck. GraphQL provides a performant solution to these issues. Per se, GraphQL is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data. Unlike REST, GraphQL can retrieve all data in a single request , and the response will be exactly what is required, without over or under -fetching data as it typically happens with REST.
In addition, because GraphQL is using schema (metadata that tells how the data is structured), it can already organize data into the preferred structure, so, for example, with GraphQL, we could remove JavaScript code used for dealing with state management, producing a cleaner application code that runs faster on the client.
If you want to get started with GraphQL or encounter performance issues, these articles might be quite helpful:
- A GraphQL Primer: Why We Need A New Kind Of API by Eric Baer,
- A GraphQL Primer: The Evolution Of API Design by Eric Baer,
- Designing a GraphQL server for optimal performance by Leonardo Losoviz,
- GraphQL performance explained by Wojciech Trocki.
- Will you be using AMP or Instant Articles?
Depending on the priorities and strategy of your organization, you might want to consider using Google's AMP or Facebook's Instant Articles or Apple's Apple News. You can achieve good performance without them, but AMP does provide a solid performance framework with a free content delivery network (CDN), while Instant Articles will boost your visibility and performance on Facebook.The seemingly obvious benefit of these technologies for users is guaranteed performance , so at times they might even prefer AMP-/Apple News/Instant Pages-links over "regular" and potentially bloated pages. For content-heavy websites that are dealing with a lot of third-party content, these options could potentially help speed up render times dramatically.
Unless they don't. According to Tim Kadlec, for example, "AMP documents tend to be faster than their counterparts, but they don't necessarily mean a page is performant. AMP is not what makes the biggest difference from a performance perspective."
A benefit for the website owner is obvious: discoverability of these formats on their respective platforms and increased visibility in search engines.
Well, at least that's how it used to be. As AMP is no longer a requirement for Top Stories , publishers might be moving away from AMP to a traditional stack instead ( thanks, Barry! ).
Still, you could build progressive web AMPs, too, by reusing AMPs as a data source for your PWA. Downside? Obviously, a presence in a walled garden places developers in a position to produce and maintain a separate version of their content, and in case of Instant Articles and Apple News without actual URLs (thanks Addy, Jeremy!) .
- Choose your CDN wisely.
As mentioned above, depending on how much dynamic data you have, you might be able to "outsource" some part of the content to a static site generator, pushing it to a CDN and serving a static version from it, thus avoiding requests to the server. In fact, some of those generators are actually website compilers with many automated optimizations provided out of the box. As compilers add optimizations over time, the compiled output gets smaller and faster over time.Notice that CDNs can serve (and offload) dynamic content as well. So, restricting your CDN to static assets is not necessary. Double-check whether your CDN performs compression and conversion (eg image optimization and resizing at the edge), whether they provide support for servers workers, A/B testing, as well as edge-side includes, which assemble static and dynamic parts of pages at the CDN's edge (ie the server closest to the user), and other tasks. Also, check if your CDN supports HTTP over QUIC (HTTP/3).
Katie Hempenius has written a fantastic guide to CDNs that provides insights on how to choose a good CDN , how to finetune it and all the little things to keep in mind when evaluating one. In general, it's a good idea to cache content as aggressively as possible and enable CDN performance features like Brotli, TLS 1.3, HTTP/2, and HTTP/3.
Note : based on research by Patrick Meenan and Andy Davies, HTTP/2 prioritization is effectively broken on many CDNs, so be careful when choosing a CDN. Patrick has more details in his talk on HTTP/2 Prioritization ( thanks, Barry! ).
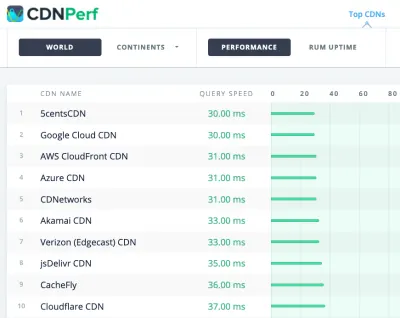
CDNPerf measures query speed for CDNs by gathering and analyzing 300 million tests every day. (大预览) When choosing a CDN, you can use these comparison sites with a detailed overview of their features:
- CDN 比较,用于 Cloudfront、Aazure、KeyCDN、Fastly、Verizon、Stackpach、Akamai 等的 CDN 比较矩阵。
- CDN Perf 通过每天收集和分析 3 亿个测试来衡量 CDN 的查询速度,所有结果均基于来自全球用户的 RUM 数据。 另请检查 DNS 性能比较和云性能比较。
- CDN Planet Guides 概述了特定主题的 CDN,例如 Serve Stale、Purge、Origin Shield、Prefetch 和 Compression。
- Web Almanac:CDN 采用和使用提供有关顶级 CDN 提供商、他们的 RTT 和 TLS 管理、TLS 协商时间、HTTP/2 采用等的见解。 (不幸的是,数据仅来自 2019 年)。
资产优化
- 使用 Brotli 进行纯文本压缩。
2015 年,谷歌推出了 Brotli,这是一种新的开源无损数据格式,现在所有现代浏览器都支持这种格式。 为 Brotli 实现编码器和解码器的开源 Brotli 库具有 11 个预定义的编码器质量级别,更高的质量级别需要更多的 CPU 以换取更好的压缩比。 较慢的压缩最终会导致更高的压缩率,但 Brotli 仍然可以快速解压缩。 值得注意的是,压缩级别为 4 的 Brotli 比 Gzip 更小且压缩速度更快。在实践中,Brotli 似乎比 Gzip 更有效。 意见和经验各不相同,但如果您的网站已经使用 Gzip 进行了优化,您可能会期望在大小缩减和 FCP 时间方面至少有一位数的改进,最多也有两位数的改进。 您还可以估计您的站点的 Brotli 压缩节省。
只有当用户通过 HTTPS 访问网站时,浏览器才会接受 Brotli。 Brotli 受到广泛支持,许多 CDN 都支持它(Akamai、Netlify Edge、AWS、KeyCDN、Fastly(目前仅作为直通)、Cloudflare、CDN77),即使在尚不支持的 CDN 上也可以启用 Brotli (与服务人员)。
问题是,由于使用 Brotli 以高压缩级别压缩所有资产的成本很高,因此许多托管服务提供商无法全面使用它,因为它会产生巨大的成本开销。 事实上,在最高级别的压缩下,Brotli非常慢,以至于服务器在等待动态压缩资产时开始发送响应所需的时间可能会抵消文件大小的任何潜在收益。 (但如果您在构建期间有时间使用静态压缩,当然,更高的压缩设置是首选。)
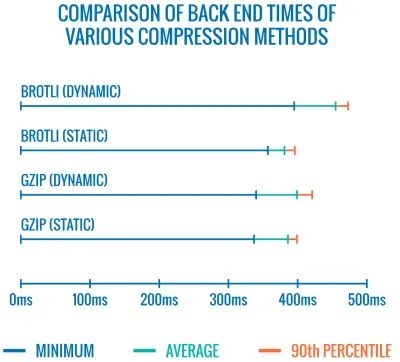
各种压缩方法的后端时间比较。 不出所料,Brotli 比 gzip 慢(目前)。 (大预览) 不过,这可能正在改变。 Brotli 文件格式包括一个内置的静态字典,除了包含多种语言的各种字符串外,它还支持对这些单词应用多种转换的选项,增加了它的多功能性。 在他的研究中,Felix Hanau 发现了一种改进 5 到 9 级压缩的方法,方法是使用“比默认字典更专业的子集”并依靠
Content-Type标头告诉压缩器是否应该使用HTML、JavaScript 或 CSS 的字典。 结果是“在使用有限的字典使用方法以高压缩级别压缩 Web 内容时,性能影响可以忽略不计(CPU 比正常情况下的 12% 多 1% 到 3%)。”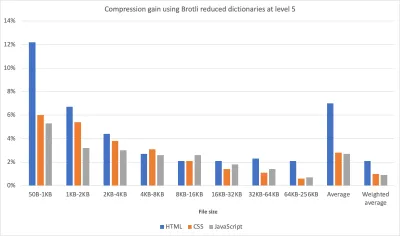
使用改进的字典方法,我们可以在更高的压缩级别上更快地压缩资产,同时只使用 1% 到 3% 的 CPU。 通常,压缩级别 6 比 5 最多会使 CPU 使用率增加 12%。 (大预览) 最重要的是,通过 Elena Kirilenko 的研究,我们可以使用以前的压缩工件实现快速高效的 Brotli 再压缩。 根据 Elena 的说法,“一旦我们通过 Brotli 压缩了资产,并且我们尝试动态压缩动态内容,其中的内容类似于我们提前可用的内容,我们就可以显着缩短压缩时间。 "
这种情况多久发生一次? 例如,交付JavaScript 捆绑包子集(例如,当部分代码已经缓存在客户端或使用 WebBundles 提供动态捆绑包时)。 或者使用基于预先知道的模板的动态 HTML,或者动态子集的 WOFF2 字体。 根据 Elena 的说法,当删除 10% 的内容时,我们可以获得 5.3% 的压缩改进和 39% 的压缩速度改进,当删除 50% 的内容时,压缩率提高了 3.2%,压缩速度提高了 26%。
Brotli 压缩越来越好,所以如果你能绕过动态压缩静态资产的成本,那绝对是值得的。 不用说,Brotli 可以用于任何纯文本负载——HTML、CSS、SVG、JavaScript、JSON 等等。
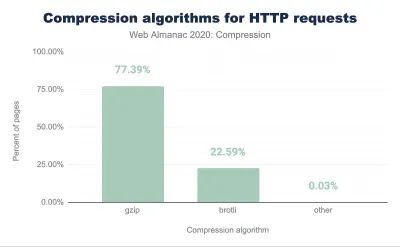
注意:截至 2021 年初,大约 60% 的 HTTP 响应是在没有基于文本的压缩的情况下交付的,其中 30.82% 使用 Gzip 压缩,9.1% 使用 Brotli 压缩(无论是在移动设备上还是在桌面上)。 例如,23.4% 的 Angular 页面没有被压缩(通过 gzip 或 Brotli)。 然而,通常打开压缩是通过简单的开关翻转来提高性能的最简单的方法之一。
策略? 在最高级别使用 Brotli+Gzip 预压缩静态资产,并在级别 4-6 使用 Brotli 动态压缩(动态)HTML。 确保服务器正确处理 Brotli 或 Gzip 的内容协商。
- 我们是否使用自适应媒体加载和客户端提示?
它来自旧新闻的土地,但它始终是一个很好的提醒,使用带有srcset、sizes和<picture>元素的响应式图像。 特别是对于媒体占用量大的网站,我们可以通过自适应媒体加载(在本例中为 React + Next.js)更进一步,为慢速网络和低内存设备提供轻量体验,为快速网络和高内存设备提供完整体验-内存设备。 在 React 的上下文中,我们可以通过服务器上的客户端提示和客户端上的 react-adaptive-hooks 来实现它。随着客户提示的广泛采用,响应式图像的未来可能会发生巨大变化。 客户端提示是 HTTP 请求标头字段,例如
DPR、Viewport-Width、Width、Save-Data、Accept(指定图像格式首选项)等。 他们应该通知服务器有关用户浏览器、屏幕、连接等的细节。因此,服务器可以决定如何用适当大小的图像填充布局,并仅以所需格式提供这些图像。 通过客户端提示,我们将资源选择从 HTML 标记移到客户端和服务器之间的请求-响应协商中。
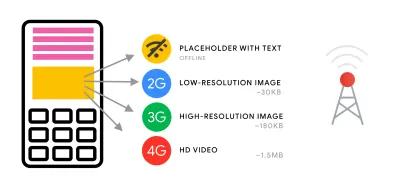
正在使用的自适应媒体服务。 我们向离线用户发送带文本的占位符,向 2G 用户发送低分辨率图像,向 3G 用户发送高分辨率图像,向 4G 用户发送高清视频。 通过在 20 美元的功能手机上快速加载网页。 (大预览) 正如 Ilya Grigorik 不久前指出的那样,客户提示完成了图片 - 它们不是响应式图像的替代品。 “
<picture>元素在 HTML 标记中提供了必要的艺术方向控制。客户端提示为生成的图像请求提供注释,从而实现资源选择自动化。Service Worker 在客户端提供完整的请求和响应管理功能。”例如,服务工作者可以将新的客户端提示标头值附加到请求中,重写 URL 并将图像请求指向 CDN,根据连接性和用户偏好调整响应等。它不仅适用于图像资产,而且适用于几乎所有其他请求也是如此。
对于支持客户端提示的客户端,可以测量到图像节省 42% 的字节和 70th+ 百分位数的 1MB+ 更少的字节。 在 Smashing Magazine 上,我们也可以测量到 19-32% 的改进。 基于 Chromium 的浏览器支持客户端提示,但在 Firefox 中仍在考虑中。
但是,如果您同时为客户端提示提供正常的响应式图像标记和
<meta>标记,则支持的浏览器将评估响应式图像标记并使用客户端提示 HTTP 标头请求适当的图像源。 - 我们是否使用响应式图像作为背景图像?
我们当然应该! 使用image-set,现在 Safari 14 和除 Firefox 之外的大多数现代浏览器都支持,我们也可以提供响应式背景图像:background-image: url("fallback.jpg"); background-image: image-set( "photo-small.jpg" 1x, "photo-large.jpg" 2x, "photo-print.jpg" 600dpi);基本上,我们可以有条件地提供具有
1x描述符的低分辨率背景图像,以及具有2x描述符的高分辨率图像,甚至是具有600dpi描述符的打印质量图像。 但请注意:浏览器不会为辅助技术提供有关背景图像的任何特殊信息,因此理想情况下,这些照片只是装饰。 - 我们使用 WebP 吗?
图像压缩通常被认为是一种快速的胜利,但在实践中它仍然没有得到充分利用。 当然,图像不会阻塞渲染,但它们会严重影响 LCP 分数,而且通常它们对于正在使用它们的设备来说太重太大了。所以至少,我们可以探索为我们的图像使用 WebP 格式。 事实上,随着 Apple 在 Safari 14 中增加对 WebP 的支持,WebP 传奇已接近尾声。因此,经过多年的讨论和辩论,截至今天,所有现代浏览器都支持 WebP。 因此,如果需要(请参阅 Andreas Bovens 的代码片段)或使用内容协商(使用
Accept标头),我们可以使用<picture>元素和 JPEG 后备来提供 WebP 图像。不过,WebP 并非没有缺点。 虽然 WebP 图像文件的大小与等效的 Guetzli 和 Zopfli 相比,但该格式不支持像 JPEG 这样的渐进式渲染,这就是为什么用户可以使用良好的 JPEG 更快地看到完成的图像,尽管 WebP 图像可能会通过网络变得更快。 使用 JPEG,我们可以用一半甚至四分之一的数据提供“体面”的用户体验,然后再加载其余的数据,而不是像 WebP 那样使用半空图像。
您的决定将取决于您追求的目标:使用 WebP,您将减少有效负载,使用 JPEG,您将提高感知性能。 您可以在 Google 的 Pascal Massimino 的 WebP Rewind 演讲中了解有关 WebP 的更多信息。
要转换为 WebP,您可以使用 WebP Converter、cwebp 或 libwebp。 Ire Aderinokun 也有一个非常详细的关于将图像转换为 WebP 的教程——Josh Comeau 在他关于拥抱现代图像格式的文章中也是如此。

关于 WebP 的彻底讨论:Pascal Massimino 的 WebP Rewind。 (大预览) Sketch 原生支持 WebP,并且可以使用 Photoshop 的 WebP 插件从 Photoshop 中导出 WebP 图像。 但也有其他选择。
如果您使用的是 WordPress 或 Joomla,有一些扩展可以帮助您轻松实现对 WebP 的支持,例如 Optimus 和 WordPress 的 Cache Enabler 以及 Joomla 自己支持的扩展(通过 Cody Arsenault)。 您还可以使用 React、样式化组件或 gatsby-image 抽象出
<picture>元素。啊——不要脸的插头! — Jeremy Wagner 甚至出版了一本关于 WebP 的 Smashing 书,您可能想看看您是否对 WebP 周围的一切感兴趣。
- 我们使用 AVIF 吗?
您可能已经听说了一个重大消息:AVIF 已经登陆。 它是一种源自 AV1 视频关键帧的新图像格式。 它是一种开放、免版税的格式,支持有损和无损压缩、动画、有损 Alpha 通道,并且可以处理锐利的线条和纯色(这是 JPEG 的一个问题),同时提供更好的结果。事实上,与 WebP 和 JPEG 相比, AVIF 的性能要好得多,在相同的 DSSIM 下(使用近似人类视觉的算法,两个或多个图像之间的(不)相似性),文件大小中值节省高达 50%。 事实上,在他关于优化图像加载的详尽文章中,Malte Ubl 指出,AVIF“在一个非常重要的方面始终优于 JPEG。这与 WebP 不同,WebP 并不总是产生比 JPEG 更小的图像,实际上可能是一个网络 -由于缺乏对渐进式加载的支持而导致的损失。”

我们可以将 AVIF 用作渐进增强,将 WebP 或 JPEG 或 PNG 传递给旧版浏览器。 (大预览)。 请参阅下面的纯文本视图。 具有讽刺意味的是,AVIF 的性能甚至比大型 SVG 还要好,尽管它当然不应被视为 SVG 的替代品。 它也是最早支持 HDR 颜色支持的图像格式之一; 提供更高的亮度、色位深度和色域。 唯一的缺点是目前 AVIF 不支持渐进式图像解码(还没有?),与 Brotli 类似,高压缩率编码目前相当慢,尽管解码速度很快。
AVIF 目前在 Chrome、Firefox 和 Opera 中得到支持,而对 Safari 的支持预计很快就会到来(因为 Apple 是创建 AV1 的小组的成员)。
那么,如今提供图像的最佳方式是什么? 对于插图和矢量图,(压缩的)SVG 无疑是最佳选择。 对于照片,我们使用带有
picture元素的内容协商方法。 如果支持 AVIF,我们发送 AVIF 图像; 如果不是这样,我们首先回退到 WebP,如果 WebP 也不支持,我们切换到 JPEG 或 PNG 作为后备(如果需要,应用@media条件):<picture> <source type="image/avif"> <source type="image/webp"> <img src="image.jpg" alt="Photo" width="450" height="350"> </picture>坦率地说,我们更有可能在
picture元素中使用一些条件:<picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture><picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture>对于选择使用
prefers-reduced-motion运动的客户,您可以通过将动画图像与静态图像交换更进一步:<picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture><picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture>在过去的几个月里,AVIF 获得了相当大的关注:
- 我们可以在 DevTools 的 Rendering 面板中测试 WebP/AVIF 回退。
- 我们可以使用 Squoosh、AVIF.io 和 libavif 对 AVIF 文件进行编码、解码、压缩和转换。
- 我们可以使用 Jake Archibald 的 AVIF Preact 组件,它在 worker 中解码 AVIF 文件并将结果显示在画布上,
- 为了只向支持的浏览器提供 AVIF,我们可以使用 PostCSS 插件和 315B 脚本在您的 CSS 声明中使用 AVIF。
- 我们可以使用 CSS 和 Cloudlare Workers 逐步交付新的图像格式,以动态更改返回的 HTML 文档,从
accept头推断信息,然后根据需要添加webp/avif等类。 - AVIF 已经在 Cloudinary 中可用(有使用限制),Cloudflare 在 Image Resizing 中支持 AVIF,您可以在 Netlify 中启用带有自定义 AVIF 标头的 AVIF。
- 在动画方面,AVIF 的表现与 Safari 的
<img src=mp4>一样好,总体上优于 GIF 和 WebP,但 MP4 的表现仍然更好。 - 一般来说,对于动画,AVC1 (h264) > HVC1 > WebP > AVIF > GIF,假设基于 Chromium 的浏览器将永远支持
<img src=mp4>。 - 您可以在 Netflix 的 Aditya Mavlankar 的 AVIF for Next Generation Image Coding 演讲和 Cloudflare 的 Kornel Lesinski 的 AVIF 图像格式演讲中找到有关 AVIF 的更多详细信息。
- AVIF 的所有内容的绝佳参考:Jake Archibald 关于 AVIF 的综合帖子已登陆。
那么未来的AVIF呢? Jon Sneyers 不同意:AVIF 的性能比 JPEG XL 差 60%,JPEG XL 是另一种由 Google 和 Cloudinary 开发的免费开放格式。 事实上,JPEG XL 似乎全面表现得更好。 但是,JPEG XL 仍处于标准化的最后阶段,还不能在任何浏览器中工作。 (不要与来自优秀的 Internet Explorer 9 次的 Microsoft JPEG-XR 混淆)。
- JPEG/PNG/SVG 是否正确优化?
当您在着陆页上工作时,英雄图像的加载速度至关重要编码器专注于感知性能,并利用 Zopfli 和 WebP 的学习成果。 唯一的缺点:处理时间慢(每百万像素 CPU 需要一分钟)。对于 PNG,我们可以使用 Pingo,对于 SVG,我们可以使用 SVGO 或 SVGOMG。 如果您需要从网站快速预览、复制或下载所有 SVG 资源,svg-grabber 也可以为您完成。
每一篇图像优化文章都会说明这一点,但保持矢量资源的干净和紧凑总是值得一提的。 确保清理未使用的资产,删除不必要的元数据并减少艺术品中的路径点数量(以及 SVG 代码)。 (谢谢,杰里米! )
不过,也有一些有用的在线工具可用:
- 使用 Squoosh 以最佳压缩级别(有损或无损)压缩、调整大小和处理图像,
- 使用 Guetzli.it 通过 Guetzli 压缩和优化 JPEG 图像,它适用于具有锐利边缘和纯色的图像(但可能会慢一些)。
- 使用响应式图像断点生成器或 Cloudinary 或 Imgix 等服务来自动优化图像。 此外,在许多情况下,单独使用
srcset和sizes将获得显着的好处。 - 要检查响应式标记的效率,您可以使用imaging-heap,这是一个命令行工具,可以测量视口大小和设备像素比的效率。
- 您可以将自动图像压缩添加到您的 GitHub 工作流程中,因此没有图像可以在未压缩的情况下投入生产。 该操作使用可处理 PNG 和 JPG 的 mozjpeg 和 libvips。
- 为了优化存储,您可以使用 Dropbox 的新 Lepton 格式将 JPEG 平均压缩 22%。
- 如果您想尽早显示占位符图像,请使用 BlurHash。 BlurHash 拍摄一张图片,并为您提供一个短字符串(仅 20-30 个字符!),代表该图片的占位符。 该字符串足够短,可以很容易地作为字段添加到 JSON 对象中。
BlurHash 是图像占位符的小型紧凑表示。 (大预览) 有时仅优化图像并不能解决问题。 为了缩短开始渲染关键图像所需的时间,延迟加载不太重要的图像并延迟任何脚本在关键图像已经渲染后加载。 最安全的方法是混合延迟加载,当我们使用本机延迟加载和延迟加载时,该库可以检测通过用户交互触发的任何可见性更改(使用我们稍后将探讨的 IntersectionObserver)。 此外:
- 考虑预加载关键图像,这样浏览器就不会太晚发现它们。 对于背景图片,如果你想更加激进,可以使用
<img src>将图片添加为普通图片,然后将其隐藏在屏幕之外。 - 考虑通过根据媒体查询指定不同的图像显示尺寸来使用 Sizes 属性交换图像,例如,操纵
sizes以交换放大镜组件中的源。 - 查看图像下载不一致的情况,以防止前景和背景图像的意外下载。 注意默认加载但可能永远不会显示的图像——例如在轮播、手风琴和图像画廊中。
- 确保始终在图像上设置
width和height。 注意 CSS 中的aspect-ratio属性和intrinsicsize属性,这将允许我们设置图像的宽高比和尺寸,因此浏览器可以提前预留一个预定义的布局槽以避免页面加载期间的布局跳转。
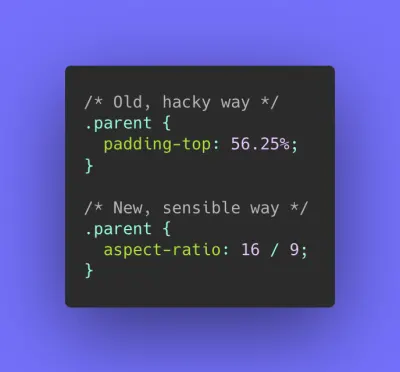
现在应该只是几周或几个月的事情,纵横比登陆浏览器。 已经在 Safari Technical Preview 118 中。 目前在 Firefox 和 Chrome 中处于领先地位。 (大预览) 如果您喜欢冒险,您可以使用 Edge 工作程序(基本上是位于 CDN 上的实时过滤器)来切分和重新排列 HTTP/2 流,以通过网络更快地发送图像。 边缘工作者使用 JavaScript 流,这些流使用您可以控制的块(基本上它们是在 CDN 边缘上运行的 JavaScript,可以修改流响应),因此您可以控制图像的交付。
使用服务人员,为时已晚,因为您无法控制线路上的内容,但它确实适用于 Edge 工作者。 因此,您可以在为特定登录页面逐步保存的静态 JPEG 之上使用它们。
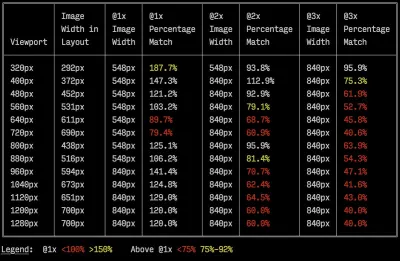
成像堆的示例输出,这是一个命令行工具,用于测量视口大小和设备像素比的效率。 (图片来源)(大预览) 还不够好? 好吧,您还可以使用多背景图像技术提高图像的感知性能。 请记住,使用对比度和模糊不必要的细节(或去除颜色)也可以减小文件大小。 啊,你需要放大一张小照片而不损失质量吗? 考虑使用 Letsenhance.io。
到目前为止,这些优化只涵盖了基础知识。 Addy Osmani 发布了一份关于基本图像优化的非常详细的指南,该指南非常深入地介绍了图像压缩和色彩管理的细节。 例如,您可以模糊图像的不必要部分(通过对其应用高斯模糊滤镜)以减小文件大小,最终您甚至可能开始去除颜色或将图片变为黑白以进一步减小大小. 对于背景图像,从 Photoshop 中以 0 到 10% 的质量导出照片也是完全可以接受的。
在 Smashing Magazine 上,我们使用后缀
-opt作为图像名称 - 例如,brotli-compression-opt.png; 每当图像包含该后缀时,团队中的每个人都知道该图像已被优化。啊,不要在网络上使用 JPEG-XR ——“在 CPU 上解码 JPEG-XRs 软件端的处理抵消甚至超过了字节大小节省的潜在积极影响,尤其是在 SPA 的上下文中”(不是与 Cloudinary/Google 的 JPEG XL 混合)。

- 视频是否正确优化?
到目前为止,我们涵盖了图像,但我们避免了关于好的 ol' GIF 的对话。 尽管我们喜欢 GIF,但现在是时候彻底放弃它们了(至少在我们的网站和应用程序中)。 与其加载影响渲染性能和带宽的繁重的动画 GIF,不如切换到动画 WebP(GIF 作为后备)或完全用循环的 HTML5 视频替换它们。与图像不同,浏览器不会预加载
<video>内容,但 HTML5 视频往往比 GIF 更轻更小。 不是一个选项? 好吧,至少我们可以使用有损 GIF、gifsicle 或 giflossy 为 GIF 添加有损压缩。Colin Bendell 的测试表明,Safari 技术预览中
img标签内的内嵌视频显示速度至少比 GIF 快 20 倍,解码速度快 7 倍,而且文件大小只是一小部分。 但是,其他浏览器不支持它。在好消息的土地上,视频格式多年来一直在大规模发展。 很长一段时间以来,我们一直希望 WebM 能够成为统治一切的格式,而 WebP(基本上是 WebM 视频容器内的一张静止图像)将成为过时的图像格式的替代品。 的确,Safari 现在支持 WebP,但尽管 WebP 和 WebM 近来获得了支持,但这一突破并没有真正发生。
尽管如此,我们仍然可以将 WebM 用于大多数现代浏览器:
<!-- By Houssein Djirdeh. https://web.dev/replace-gifs-with-videos/ --> <!-- A common scenartio: MP4 with a WEBM fallback. --> <video autoplay loop muted playsinline> <source src="my-animation.webm" type="video/webm"> <source src="my-animation.mp4" type="video/mp4"> </video>但也许我们可以完全重新审视它。 2018 年,开放媒体联盟发布了一种新的有前途的视频格式,称为AV1 。 AV1 具有类似于 H.265 编解码器(H.264 的演变)的压缩,但与后者不同的是,AV1 是免费的。 H.265 许可证定价促使浏览器供应商改用性能相当的 AV1: AV1(就像 H.265)的压缩率是 WebM 的两倍。

AV1 很有可能成为网络视频的终极标准。 (图片来源:Wikimedia.org)(大预览) 事实上,苹果目前使用的是 HEIF 格式和 HEVC(H.265),而最新 iOS 上的所有照片和视频都是以这些格式保存的,而不是 JPEG。 虽然 HEIF 和 HEVC (H.265) 还没有正确地暴露在网络上(还没有?),但 AV1 是——而且它正在获得浏览器的支持。 因此,在您的
<video>标签中添加AV1源代码是合理的,因为所有浏览器供应商似乎都参与其中。目前,最广泛使用和支持的编码是 H.264,由 MP4 文件提供,因此在提供文件之前,请确保您的 MP4 使用多通道编码进行处理,使用 frei0r iirblur 效果(如果适用)进行模糊处理,并且moov atom 元数据被移动到文件的头部,而您的服务器接受字节服务。 Boris Schapira 为 FFmpeg 提供了精确的指令以最大限度地优化视频。 当然,提供 WebM 格式作为替代方案也会有所帮助。
需要更快地开始渲染视频但视频文件仍然太大? 例如,每当您在登录页面上有大型背景视频时? 一种常用的技术是首先将第一帧显示为静止图像,或者显示一个经过高度优化的短循环片段,可以解释为视频的一部分,然后,只要视频缓冲足够,就开始播放实际的视频。 Doug Sillars 编写了一份详细的背景视频性能指南,在这种情况下可能会有所帮助。 (谢谢,Guy Podjarny! )。
对于上述场景,您可能需要提供响应式海报图片。 默认情况下,
video元素只允许一张图片作为海报,这不一定是最佳的。 我们可以使用 Responsive Video Poster,这是一个 JavaScript 库,允许您为不同的屏幕使用不同的海报图像,同时还添加过渡叠加和视频占位符的完整样式控制。研究表明,视频流质量会影响观看者的行为。 事实上,如果启动延迟超过 2 秒左右,观众就会开始放弃视频。 超过这一点,延迟增加 1 秒会导致放弃率增加大约 5.8%。 因此,视频开始时间的中位数为 12.8 秒也就不足为奇了,其中 40% 的视频至少有 1 个停顿,20% 的视频至少有 2 秒的停顿视频播放。 事实上,在 3G 上,视频停顿是不可避免的,因为视频播放速度快于网络提供的内容。
那么,解决方案是什么? 通常小屏幕设备无法处理我们为桌面服务的 720p 和 1080p。 根据 Doug Sillars 的说法,我们可以创建更小的视频版本,并使用 Javascript 来检测小屏幕的来源,以确保在这些设备上快速流畅地播放。 或者,我们可以使用流式视频。 HLS 视频流将向设备提供适当大小的视频——抽象出为不同屏幕创建不同视频的需要。 它还将协商网络速度,并根据您使用的网络速度调整视频比特率。
为了避免带宽浪费,我们只能为实际可以播放视频的设备添加视频源。 或者,我们可以完全从
video标签中删除autoplay属性,并使用 JavaScript 为更大的屏幕插入autoplay。 此外,我们需要在video上添加preload="none"来告诉浏览器在它真正需要文件之前不要下载任何视频文件:<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>然后我们可以专门针对实际支持 AV1 的浏览器:
<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.av1.mp4" type="video/mp4; codecs=av01.0.05M.08"> <source src="video.hevc.mp4" type="video/mp4; codecs=hevc"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>然后我们可以在某个阈值(例如 1000 像素)上重新添加
autoplay:/* By Doug Sillars. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ */ <script> window.onload = addAutoplay(); var videoLocation = document.getElementById("hero-video"); function addAutoplay() { if(window.innerWidth > 1000){ videoLocation.setAttribute("autoplay",""); }; } </script>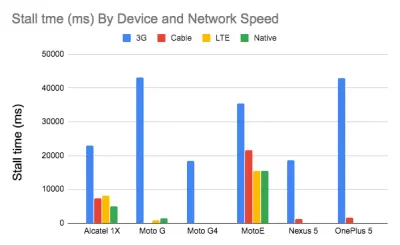
按设备和网络速度划分的档数。 速度更快的网络上的速度更快的设备几乎没有停顿。 根据道格·西拉斯的研究。 (大预览) 视频播放性能本身就是一个故事,如果您想详细了解它,请查看 Doug Sillars 关于视频当前状态和视频交付最佳实践的另一个系列,其中包括有关视频交付指标的详细信息、视频预加载、压缩和流式传输。 最后,您可以使用 Stream 或 Not 检查视频流的速度或速度。
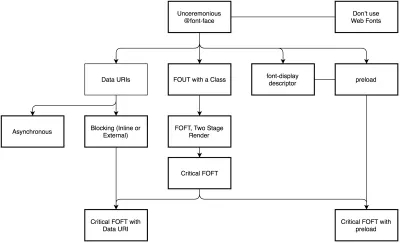
- 网络字体交付是否优化?
The first question that's worth asking is if we can get away with using UI system fonts in the first place — we just need to make sure to double check that they appear correctly on various platforms. If it's not the case, chances are high that the web fonts we are serving include glyphs and extra features and weights that aren't being used. We can ask our type foundry to subset web fonts or if we are using open-source fonts, subset them on our own with Glyphhanger or Fontsquirrel. We can even automate our entire workflow with Peter Muller's subfont, a command line tool that statically analyses your page in order to generate the most optimal web font subsets, and then inject them into our pages.WOFF2 support is great, and we can use WOFF as fallback for browsers that don't support it — or perhaps legacy browsers could be served system fonts. There are many, many, many options for web font loading, and we can choose one of the strategies from Zach Leatherman's "Comprehensive Guide to Font-Loading Strategies," (code snippets also available as Web font loading recipes).
Probably the better options to consider today are Critical FOFT with
preloadand "The Compromise" method. Both of them use a two-stage render for delivering web fonts in steps — first a small supersubset required to render the page fast and accurately with the web font, and then load the rest of the family async. The difference is that "The Compromise" technique loads polyfill asynchronously only if font load events are not supported, so you don't need to load the polyfill by default. Need a quick win? Zach Leatherman has a quick 23-min tutorial and case study to get your fonts in order.In general, it might be a good idea to use the
preloadresource hint to preload fonts, but in your markup include the hints after the link to critical CSS and JavaScript. Withpreload, there is a puzzle of priorities, so consider injectingrel="preload"elements into the DOM just before the external blocking scripts. According to Andy Davies, "resources injected using a script are hidden from the browser until the script executes, and we can use this behaviour to delay when the browser discovers thepreloadhint." Otherwise, font loading will cost you in the first render time.
When everything is critical, nothing is critical. preload only one or a maximum of two fonts of each family. (Image credit: Zach Leatherman – slide 93) (Large preview) It's a good idea to be selective and choose files that matter most, eg the ones that are critical for rendering or that would help you avoiding visible and disruptive text reflows. In general, Zach advises to preload one or two fonts of each family — it also makes sense to delay some font loading if they are less critical.
It has become quite common to use
local()value (which refers to a local font by name) when defining afont-familyin the@font-facerule:/* Warning! Not a good idea! */ @font-face { font-family: Open Sans; src: local('Open Sans Regular'), local('OpenSans-Regular'), url('opensans.woff2') format ('woff2'), url('opensans.woff') format('woff'); }The idea is reasonable: some popular open-source fonts such as Open Sans are coming pre-installed with some drivers or apps, so if the font is available locally, the browser doesn't need to download the web font and can display the local font immediately. As Bram Stein noted, "though a local font matches the name of a web font, it most likely isn't the same font . Many web fonts differ from their "desktop" version. The text might be rendered differently, some characters may fall back to other fonts, OpenType features can be missing entirely, or the line height may be different."
Also, as typefaces evolve over time, the locally installed version might be very different from the web font, with characters looking very different. So, according to Bram, it's better to never mix locally installed fonts and web fonts in
@font-facerules. Google Fonts has followed suit by disablinglocal()on the CSS results for all users, other than Android requests for Roboto.Nobody likes waiting for the content to be displayed. With the
font-displayCSS descriptor, we can control the font loading behavior and enable content to be readable immediately (withfont-display: optional) or almost immediately (with a timeout of 3s, as long as the font gets successfully downloaded — withfont-display: swap). (Well, it's a bit more complicated than that.)However, if you want to minimize the impact of text reflows, we could use the Font Loading API (supported in all modern browsers). Specifically that means for every font, we'd creata a
FontFaceobject, then try to fetch them all, and only then apply them to the page. This way, we group all repaints by loading all fonts asynchronously, and then switch from fallback fonts to the web font exactly once. Take a look at Zach's explanation, starting at 32:15, and the code snippet):/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));To initiate a very early fetch of the fonts with Font Loading API in use, Adrian Bece suggests to add a non-breaking space
nbsp;at the top of thebody, and hide it visually witharia-visibility: hiddenand a.hiddenclass:<body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body><body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body>This goes along with CSS that has different font families declared for different states of loading, with the change triggered by Font Loading API once the fonts have successfully loaded:
body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }If you ever wondered why despite all your optimizations, Lighthouse still suggests to eliminate render-blocking resources (fonts), in the same article Adrian Bece provides a few techniques to make Lighthouse happy, along with a Gatsby Omni Font Loader, a performant asynchronous font loading and Flash Of Unstyled Text (FOUT) handling plugin for Gatsby.
Now, many of us might be using a CDN or a third-party host to load web fonts from. In general, it's always better to self-host all your static assets if you can, so consider using google-webfonts-helper, a hassle-free way to self-host Google Fonts. And if it's not possible, you can perhaps proxy the Google Font files through the page origin.
It's worth noting though that Google is doing quite a bit of work out of the box, so a server might need a bit of tweaking to avoid delays ( thanks, Barry! )
This is quite important especially as since Chrome v86 (released October 2020), cross-site resources like fonts can't be shared on the same CDN anymore — due to the partitioned browser cache. This behavior was a default in Safari for years.

But if it's not possible at all, there is a way to get to the fastest possible Google Fonts with Harry Roberts' snippet:
<!-- By Harry Roberts. https://csswizardry.com/2020/05/the-fastest-google-fonts/ - 1. Preemptively warm up the fonts' origin. - 2. Initiate a high-priority, asynchronous fetch for the CSS file. Works in - most modern browsers. - 3. Initiate a low-priority, asynchronous fetch that gets applied to the page - only after it's arrived. Works in all browsers with JavaScript enabled. - 4. In the unlikely event that a visitor has intentionally disabled - JavaScript, fall back to the original method. The good news is that, - although this is a render-blocking request, it can still make use of the - preconnect which makes it marginally faster than the default. --> <!-- [1] --> <link rel="preconnect" href="https://fonts.gstatic.com" crossorigin /> <!-- [2] --> <link rel="preload" as="style" href="$CSS&display=swap" /> <!-- [3] --> <link rel="stylesheet" href="$CSS&display=swap" media="print" onload="this.media='all'" /> <!-- [4] --> <noscript> <link rel="stylesheet" href="$CSS&display=swap" /> </noscript>Harry's strategy is to pre-emptively warm up the fonts' origin first. Then we initiate a high-priority, asynchronous fetch for the CSS file. Afterwards, we initiate a low-priority, asynchronous fetch that gets applied to the page only after it's arrived (with a print stylesheet trick). Finally, if JavaScript isn't supported, we fall back to the original method.
Ah, talking about Google Fonts: you can shave up to 90% of the size of Google Fonts requests by declaring only characters you need with
&text. Plus, the support for font-display was added recently to Google Fonts as well, so we can use it out of the box.不过要注意一点。 如果您使用
font-display: optional,那么使用preload可能不是最佳选择,因为它会提前触发该 Web 字体请求(如果您有其他需要获取的关键路径资源,则会导致网络拥塞)。 使用preconnect来加快跨域字体请求,但要小心preload,因为从不同来源预加载字体会导致网络争用。 所有这些技术都包含在 Zach 的 Web 字体加载配方中。另一方面,如果用户在可访问性首选项中启用了减少运动或选择了数据保护模式(请参阅
Save-Data标题),则选择退出网络字体(或至少第二阶段渲染)可能是个好主意,或者当用户连接速度较慢时(通过网络信息 API)。如果用户选择了数据保存模式(还有其他用例),我们还可以使用
prefers-reduced-dataCSS 媒体查询来不定义字体声明。 如果来自客户端提示 HTTP 扩展的Save-Data请求标头打开/关闭以允许与 CSS 一起使用,则媒体查询基本上会公开。 目前仅支持在 Chrome 和 Edge 后面的标志。指标? 要衡量 Web 字体加载性能,请考虑All Text Visible指标(所有字体已加载且所有内容以 Web 字体显示的时刻)、Time to Real Italics 以及首次渲染后的Web Font Reflow Count 。 显然,这两个指标越低,性能越好。
你可能会问,可变字体呢? 重要的是要注意可变字体可能需要重要的性能考虑。 它们为我们提供了更广泛的印刷选择设计空间,但它的代价是单个串行请求而不是多个单独的文件请求。
虽然可变字体大大减少了字体文件的整体组合文件大小,但该单个请求可能会很慢,从而阻止页面上所有内容的呈现。 所以子集化和将字体分割成字符集仍然很重要。 不过好的一面是,使用可变字体,默认情况下我们会得到一个重排,因此不需要 JavaScript 来对重绘进行分组。
现在,怎样才能制定防弹的网络字体加载策略呢? 子集字体并为 2-stage-render 准备它们,使用字体
font-display描述符声明它们,使用 Font Loading API 对重绘进行分组并将字体存储在持久服务工作者的缓存中。 在第一次访问时,在阻塞外部脚本之前注入脚本的预加载。 如有必要,您可以使用 Bram Stein 的 Font Face Observer。 如果您对测量字体加载的性能感兴趣,Andreas Marschke 将探索使用 Font API 和 UserTiming API 进行的性能跟踪。最后,不要忘记包含
unicode-range以将大字体分解为较小的特定语言字体,并使用 Monica Dinculescu 的字体样式匹配器来最小化布局中的不和谐变化,因为后备和网页字体。或者,要为备用字体模拟 Web 字体,我们可以使用 @font-face 描述符来覆盖字体指标(演示,在 Chrome 87 中启用)。 (请注意,调整会因复杂的字体堆栈而变得复杂。)
未来看起来光明吗? 通过渐进式字体丰富,最终我们可能能够“在任何给定页面上仅下载所需的字体部分,并且对于该字体的后续请求,可以根据后续页面的要求使用额外的字形集动态地‘修补’原始下载意见”,正如 Jason Pamental 解释的那样。 增量传输演示已经可用,并且正在进行中。
构建优化
- 我们是否确定了我们的优先事项?
最好先知道你在处理什么。 对您的所有资产(JavaScript、图像、字体、第三方脚本和页面上的“昂贵”模块,例如轮播、复杂的信息图表和多媒体内容)进行清点,并将它们分组分解。设置电子表格。 定义旧版浏览器的基本核心体验(即完全可访问的核心内容)、功能强大的浏览器的增强体验(即丰富、完整的体验)和附加功能(非绝对必需且可以延迟加载的资产,例如网络字体、不必要的样式、轮播脚本、视频播放器、社交媒体小部件、大图像)。 多年前,我们发表了一篇关于“提高 Smashing Magazine 的性能”的文章,详细描述了这种方法。
在优化性能时,我们需要反映我们的优先事项。 立即加载核心体验,然后是增强功能,然后是附加功能。
- 你在生产中使用原生 JavaScript 模块吗?
还记得将核心体验发送到旧版浏览器并增强现代浏览器体验的出色技巧吗? 该技术的更新变体可以使用 ES2017+<script type="module">,也称为模块/无模块模式(也由 Jeremy Wagner 作为差分服务引入)。这个想法是编译并提供两个独立的 JavaScript 包:“常规”构建,一个带有 Babel-transforms 和 polyfill,只为真正需要它们的旧版浏览器提供它们,另一个包(相同功能)没有转换或填充物。
因此,我们通过减少浏览器需要处理的脚本数量来帮助减少主线程的阻塞。 Jeremy Wagner 发表了一篇关于差异服务以及如何在构建管道中设置它的综合文章,从设置 Babel 到您需要在 Webpack 中进行哪些调整,以及完成所有这些工作的好处。
默认情况下,原生 JavaScript 模块脚本被延迟,因此在进行 HTML 解析时,浏览器将下载主模块。

默认情况下,原生 JavaScript 模块被延迟。 几乎所有关于原生 JavaScript 模块的东西。 (大预览) 不过需要注意的一点是: module/nomodule 模式在某些客户端上可能会适得其反,因此您可能需要考虑一种解决方法:Jeremy 风险较小的差异服务模式,然而,它避开了预加载扫描器,这可能会以一种可能不会影响性能的方式预料。 (谢谢,杰里米! )
实际上,Rollup 支持将模块作为输出格式,因此我们既可以捆绑代码,也可以在生产环境中部署模块。 Parcel 在 Parcel 2 中具有模块支持。对于 Webpack,module-nomodule-plugin 自动生成模块/nomodule 脚本。
注意:值得一提的是,仅凭功能检测不足以对发送到该浏览器的有效负载做出明智的决定。 就其本身而言,我们无法从浏览器版本推断设备能力。 例如,发展中国家的廉价 Android 手机大多运行 Chrome,尽管内存和 CPU 功能有限,但仍会减少芥末味。
最终,使用设备内存客户端提示头,我们将能够更可靠地定位低端设备。 在撰写本文时,仅在 Blink 中支持标头(通常用于客户端提示)。 由于设备内存也有一个在 Chrome 中可用的 JavaScript API,一个选项可能是基于 API 进行功能检测,如果不支持则回退到模块/无模块模式(谢谢,Yoav! )。
- 您是否在使用摇树、范围提升和代码拆分?
Tree-shaking 是一种清理构建过程的方法,它只包含生产中实际使用的代码,并消除 Webpack 中未使用的导入。 使用 Webpack 和 Rollup,我们还具有范围提升功能,这两种工具都可以检测import链在哪里可以展平并转换为一个内联函数,而不会影响代码。 使用 Webpack,我们也可以使用 JSON Tree Shaking。Code-splitting 是另一个 Webpack 特性,它将你的代码库分成按需加载的“块”。 并非所有的 JavaScript 都必须立即下载、解析和编译。 一旦在代码中定义了分割点,Webpack 就可以处理依赖项和输出文件。 它使您能够保持较小的初始下载并在应用程序请求时按需请求代码。 Alexander Kondrov 对使用 Webpack 和 React 进行代码拆分进行了精彩的介绍。
考虑使用 preload-webpack-plugin 将路由代码拆分,然后提示浏览器使用
<link rel="preload">或<link rel="prefetch">预加载它们。 Webpack 内联指令还可以控制preload/prefetch。 (不过要注意优先级问题。)在哪里定义分割点? 通过跟踪哪些 CSS/JavaScript 块被使用,哪些未被使用。 Umar Hansa 解释了如何使用 Devtools 的代码覆盖来实现它。
在处理单页应用程序时,我们需要一些时间来初始化应用程序,然后才能渲染页面。 您的设置将需要您的自定义解决方案,但您可以注意模块和技术以加快初始渲染时间。 例如,这里介绍了如何调试 React 性能并消除常见的 React 性能问题,以及如何提高 Angular 中的性能。 一般来说,大多数性能问题都来自启动应用程序的初始时间。
那么,什么是积极但又不过分积极地进行代码拆分的最佳方式呢? 根据 Phil Walton 的说法,“除了通过动态导入进行代码拆分之外,[我们] 还可以在包级别使用代码拆分,其中每个导入的节点模块都会根据其包的名称放入一个块中。” Phil 还提供了有关如何构建它的教程。
- 我们可以改进 Webpack 的输出吗?
由于 Webpack 通常被认为是神秘的,因此有很多 Webpack 插件可能会派上用场,以进一步减少 Webpack 的输出。 以下是一些可能需要更多关注的更晦涩难懂的内容。其中一个有趣的来自 Ivan Akulov 的主题。 想象一下,您有一个函数,您调用一次,将其结果存储在一个变量中,然后不使用该变量。 摇树将删除变量,但不会删除函数,因为它可能会被使用。 但是,如果该功能未在任何地方使用,您可能需要将其删除。 为此,请在函数调用前加上
/*#__PURE__*/,这是 Uglify 和 Terser 支持的 - 完成!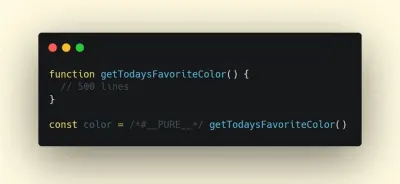
要在未使用其结果时删除此类函数,请在函数调用前添加 /*#__PURE__*/。 通过 Ivan Akulov。(大预览)以下是 Ivan 推荐的其他一些工具:
- purgecss-webpack-plugin 删除未使用的类,尤其是在您使用 Bootstrap 或 Tailwind 时。
- 使用 split-chunks-plugin 启用
optimization.splitChunks: 'all'。 这将使 webpack 自动对您的条目包进行代码拆分,以实现更好的缓存。 - 设置
optimization.runtimeChunk: true。 这会将 webpack 的运行时移动到一个单独的块中——并且还会改进缓存。 - google-fonts-webpack-plugin 下载字体文件,因此您可以从您的服务器提供它们。
- workbox-webpack-plugin 允许您为所有 webpack 资产生成具有预缓存设置的服务工作者。 此外,请查看 Service Worker Packages,这是一份可以立即应用的模块综合指南。 或者使用 preload-webpack-plugin 为所有 JavaScript 块生成
preload/prefetch。 - speed-measure-webpack-plugin 测量你的 webpack 构建速度,提供构建过程中哪些步骤最耗时的洞察。
- 当你的包包含同一个包的多个版本时,duplicate-package-checker-webpack-plugin 会发出警告。
- 使用范围隔离并在编译时动态缩短 CSS 类名。
- 你可以将 JavaScript 卸载到 Web Worker 中吗?
为了减少对 Time-to-Interactive 的负面影响,考虑将繁重的 JavaScript 卸载到 Web Worker 中可能是一个好主意。随着代码库的不断增长,UI 性能瓶颈会出现,从而降低用户体验。 这是因为 DOM 操作在主线程上与 JavaScript 一起运行。 使用网络工作者,我们可以将这些昂贵的操作转移到在不同线程上运行的后台进程。 Web Worker 的典型用例是预取数据和渐进式 Web 应用程序以提前加载和存储一些数据,以便您以后可以在需要时使用它。 您可以使用 Comlink 来简化主页和工作人员之间的通信。 还有一些工作要做,但我们正在到达那里。
有一些关于 Web Worker 的有趣案例研究展示了将框架和应用程序逻辑移动到 Web Worker 的不同方法。 结论:总的来说,仍然存在一些挑战,但已经有一些很好的用例(感谢 Ivan Akulov! )。
从 Chrome 80 开始,一种具有 JavaScript 模块性能优势的Web 工作者新模式已经发布,称为模块工作者。 我们可以更改脚本加载和执行以匹配
script type="module",此外,我们还可以对延迟加载代码使用动态导入,而不会阻塞工作线程的执行。如何开始? 以下是一些值得研究的资源:
- Surma 发布了一篇关于如何在浏览器的主线程中运行 JavaScript 以及何时应该使用 Web Workers 的优秀指南。
- 另外,请查看 Surma 关于主线程架构的讨论。
- Shubhie Panicker 和 Jason Miller 的 A Quest to Guarantee Responsiveness 提供了有关如何使用 Web 工作者以及何时避免使用它们的详细见解。
- 摆脱用户的方式:使用 Web Worker 减少 Jank 重点介绍了使用 Web Worker 的有用模式、worker 之间通信的有效方法、处理主线程之外的复杂数据处理以及测试和调试它们。
- Workerize 允许您将模块移动到 Web Worker 中,自动将导出的函数反映为异步代理。
- 如果你使用 Webpack,你可以使用 workerize-loader。 或者,您也可以使用 worker-plugin。

当代码阻塞很长时间时使用 web worker,但是当你依赖 DOM、处理输入响应并且需要最小的延迟时避免使用它们。 (通过 Addy Osmani)(大预览) 请注意,Web Worker 无权访问 DOM,因为 DOM 不是“线程安全的”,它们执行的代码需要包含在单独的文件中。
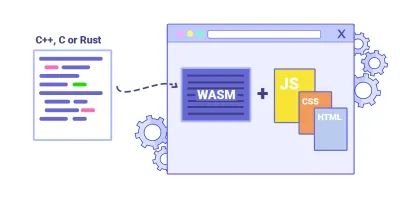
- 你可以将“热路径”卸载到 WebAssembly 吗?
我们可以将繁重的计算任务转移到 WebAssembly ( WASM ),这是一种二进制指令格式,被设计为用于编译 C/C++/Rust 等高级语言的可移植目标。 它的浏览器支持非常出色,并且随着 JavaScript 和 WASM 之间的函数调用变得越来越快,它最近变得可行。 此外,它甚至还支持 Fastly 的边缘云。当然,WebAssembly 不应该取代 JavaScript,但它可以在你注意到 CPU 占用的情况下对其进行补充。 对于大多数 Web 应用程序,JavaScript 更适合,而 WebAssembly 最适合用于计算密集型 Web 应用程序,例如游戏。
如果您想了解有关 WebAssembly 的更多信息:
- Lin Clark 为 WebAssembly 编写了一个详尽的系列文章,Milica Mihajlija 提供了有关如何在浏览器中运行本机代码的总体概述,为什么要这样做,以及这对 JavaScript 和 Web 开发的未来意味着什么。
- 我们如何使用 WebAssembly 将我们的 Web 应用程序加速 20 倍(案例研究)重点介绍了如何用编译的 WebAssembly 取代缓慢的 JavaScript 计算并带来显着的性能改进的案例研究。
- Patrick Hamann 一直在谈论 WebAssembly 日益重要的角色,他揭穿了一些关于 WebAssembly 的神话,探索了它的挑战,我们可以在今天的应用程序中实际使用它。
- Google Codelabs 提供了 WebAssembly 简介,这是一个 60 分钟的课程,您将在其中学习如何使用 C 语言获取本机代码并将其编译为 WebAssembly,然后直接从 JavaScript 调用它。
- Alex Danilo 在他的 Google I/O 演讲中解释了 WebAssembly 及其工作原理。 此外,Benedek Gagyi 分享了一个关于 WebAssembly 的实际案例研究,特别是团队如何将其用作其 C++ 代码库到 iOS、Android 和网站的输出格式。
仍然不确定何时使用 Web Workers、Web Assembly、流或 WebGL JavaScript API 来访问 GPU? 加速 JavaScript 是一个简短但有用的指南,它解释了何时使用什么以及为什么使用 - 还带有一个方便的流程图和大量有用的资源。
- 我们是否只为旧版浏览器提供旧版代码?
由于 ES2017 在现代浏览器中得到了很好的支持,我们可以使用babelEsmPlugin仅转换您所针对的现代浏览器不支持的 ES2017+ 功能。Houssein Djirdeh 和 Jason Miller 最近发布了一份关于如何转译和提供现代和遗留 JavaScript 的综合指南,详细介绍了如何使其与 Webpack 和 Rollup 一起使用,以及所需的工具。 您还可以估计可以在您的网站或应用程序包上减少多少 JavaScript。
所有主流浏览器都支持 JavaScript 模块,因此使用 use
script type="module"让支持 ES 模块的浏览器加载文件,而旧版浏览器可以加载带有script nomodule的旧版本。如今,我们可以编写在浏览器中本地运行的基于模块的 JavaScript,无需转译器或捆绑器。
<link rel="modulepreload">标头提供了一种启动模块脚本的早期(和高优先级)加载的方法。 基本上,这是一种帮助最大化带宽使用的好方法,它告诉浏览器它需要获取什么,这样它就不会在那些漫长的往返过程中遇到任何事情。 此外,Jake Archibald 发表了一篇详细的文章,其中包含值得一读的 ES 模块的陷阱和注意事项。
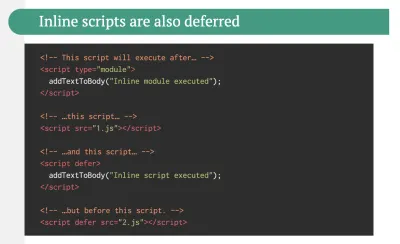
- 通过增量解耦识别和重写遗留代码。
长期存在的项目往往会积聚灰尘和过时的代码。 重新审视您的依赖关系并评估需要多少时间来重构或重写最近造成问题的遗留代码。 当然,这总是一项艰巨的任务,但是一旦您了解遗留代码的影响,您就可以从增量解耦开始。首先,设置指标来跟踪遗留代码调用的比率是保持不变还是下降,而不是上升。 公开劝阻团队不要使用该库,并确保您的 CI 会在拉取请求中使用它时提醒开发人员。 polyfill 可以帮助从遗留代码过渡到使用标准浏览器功能的重写代码库。
- 识别并删除未使用的 CSS/JS 。
Chrome 中的 CSS 和 JavaScript 代码覆盖率可让您了解哪些代码已执行/应用,哪些尚未执行/应用。 您可以开始记录覆盖率,在页面上执行操作,然后探索代码覆盖率结果。 检测到未使用的代码后,使用import()找到这些模块并延迟加载(查看整个线程)。 然后重复覆盖率配置文件并验证它现在在初始加载时发送的代码更少。您可以使用 Puppeteer 以编程方式收集代码覆盖率。 Chrome 也允许您导出代码覆盖率结果。 正如 Andy Davies 所指出的,您可能希望收集现代和旧版浏览器的代码覆盖率。
Puppetter 还有许多其他用例和工具可能需要更多介绍:
- Puppeteer 的用例,例如,自动视觉差异或在每次构建时监控未使用的 CSS,
- 使用 Puppeteer 的 Web 性能食谱,
- 用于记录和生成 Pupeeteer 和 Playwright 脚本的有用工具,
- 此外,您甚至可以直接在 DevTools 中记录测试,
- Nitay Neeman 对 Puppeteer 的全面概述,包括示例和用例。
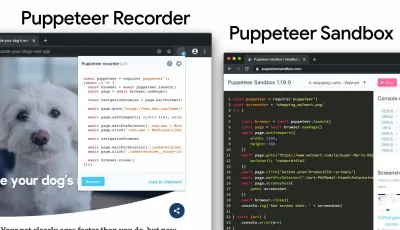
我们可以使用 Puppeteer Recorder 和 Puppeteer Sandbox 来记录浏览器交互并生成 Puppeteer 和 Playwright 脚本。 (大预览) 此外,purgecss、UnCSS 和 Helium 可以帮助您从 CSS 中删除未使用的样式。 如果您不确定某处是否使用了可疑代码,您可以遵循 Harry Roberts 的建议:为特定类创建一个 1×1px 透明 GIF 并将其放入
dead/目录,例如/assets/img/dead/comments.gif。之后,您将特定图像设置为 CSS 中相应选择器的背景,然后等待几个月,如果该文件将出现在您的日志中。 如果没有条目,则没有人会在他们的屏幕上呈现该遗留组件:您可能可以继续将其全部删除。
对于I-feel-adventurous部门,您甚至可以通过使用 DevTools 监控 DevTools,通过一组页面自动收集未使用的 CSS。
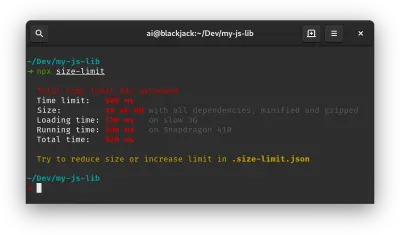
- 修剪 JavaScript 包的大小。
正如 Addy Osmani 所指出的,当您只需要一小部分时,您很有可能会发布完整的 JavaScript 库,以及用于不需要它们的浏览器的过时 polyfill,或者只是重复代码。 为避免开销,请考虑使用 webpack-libs-optimizations 在构建过程中删除未使用的方法和 polyfill。检查并审查您发送到旧版浏览器和现代浏览器的polyfill ,并对它们更具战略性。 看看 polyfill.io,它是一个服务,它接受对一组浏览器功能的请求,并仅返回请求浏览器所需的 polyfill。
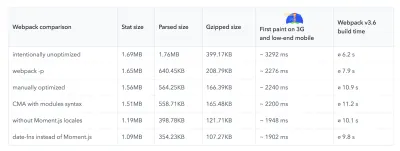
将捆绑审计也添加到您的常规工作流程中。 您多年前添加的重型库可能有一些轻量级替代品,例如 Moment.js(现已停产)可以替换为:
- 原生国际化 API,
- Day.js 具有熟悉的 Moment.js API 和模式,
- 日期-fns 或
- 卢克森。
- 您还可以使用 Skypack Discover,它将人工审核的包裹推荐与注重质量的搜索相结合。
Benedikt Rotsch 的研究表明,从 Moment.js 切换到 date-fns 可以为 3G 和低端手机上的 First Paint 节省大约 300 毫秒。
对于包审计,Bundlephobia 可以帮助您找到将 npm 包添加到包中的成本。 size-limit 通过 JavaScript 执行时间的详细信息扩展了基本的包大小检查。 您甚至可以将这些成本与 Lighthouse 自定义审计相结合。 这也适用于框架。 通过删除或修剪 Vue MDC 适配器(Vue 的材料组件),样式从 194KB 下降到 10KB。
还有许多其他工具可帮助您就依赖项的影响和可行的替代方案做出明智的决定:
- webpack-bundle-analyzer
- 源地图浏览器
- 捆绑好友
- 捆绑恐惧症
- Webpack 分析显示了为什么将特定模块包含在包中。
- bundle-wizard 还为整个页面构建依赖关系图。
- Webpack 大小插件
- 可视化代码的导入成本
作为交付整个框架的替代方案,您可以修剪您的框架并将其编译为不需要额外代码的原始 JavaScript 包。 Svelte 做到了,Rawact Babel 插件也在构建时将 React.js 组件转换为原生 DOM 操作。 为什么? 好吧,正如维护者解释的那样,“react-dom 包含所有可以渲染的可能组件/HTMLElement 的代码,包括用于增量渲染、调度、事件处理等的代码。但是有些应用程序不需要所有这些功能(最初页面加载)。对于此类应用程序,使用本机 DOM 操作来构建交互式用户界面可能是有意义的。
- 我们是否使用部分补水?
随着应用程序中使用的 JavaScript 数量,我们需要想办法尽可能少地发送给客户端。 这样做的一种方法——我们已经简要介绍过——是部分补水。 这个想法很简单:不是执行 SSR 然后将整个应用程序发送到客户端,而是只将应用程序的一小部分 JavaScript 发送到客户端然后进行水合。 我们可以将其视为在一个静态网站上具有多个渲染根的多个微型 React 应用程序。在文章“部分水合的案例(使用 Next 和 Preact)”中,Lukas Bombach 解释了德国新闻媒体之一 Welt.de 背后的团队如何通过部分水合取得更好的性能。 您还可以查看具有解释和代码片段的 next-super-performance GitHub 存储库。
您还可以考虑其他选择:
- Preact 和 Eleventy 的部分水合作用,
- React GitHub repo 中的渐进式水合作用,
- Vue.js 中的惰性水合(GitHub 存储库),
- 当用户与需要它的 UI 交互时,导入交互模式以延迟加载非关键资源(例如组件、嵌入)。
Jason Miller 发布了关于如何使用 React 实现渐进式水合作用的工作演示,因此您可以立即使用它们:演示 1、演示 2、演示 3(也可在 GitHub 上获得)。 另外,您可以查看 react-prerendered-component 库。
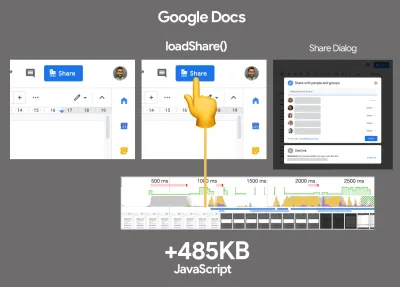
仅当您无法在交互之前预取资源时,才应该对第一方代码进行交互时导入。 (大预览) - 我们是否优化了 React/SPA 的策略?
在单页应用程序中苦苦挣扎? Jeremy Wagner 探讨了客户端框架性能对各种设备的影响,重点介绍了我们在使用某个设备时可能需要注意的一些含义和指导方针。因此,这是 Jeremy 建议用于 React 框架的 SPA 策略(但对于其他框架,它不应该有显着变化):
- 尽可能将有状态组件重构为无状态组件。
- 尽可能预渲染无状态组件以最小化服务器响应时间。 仅在服务器上渲染。
- 对于具有简单交互性的有状态组件,请考虑对该组件进行预渲染或服务器渲染,并将其交互性替换为与框架无关的事件侦听器。
- 如果您必须在客户端上对有状态的组件进行水合,请在可见性或交互上使用惰性水合。
- 对于延迟水合的组件,请在主线程空闲时间使用
requestIdleCallback安排它们的水合。
您可能还想追求或回顾其他一些策略:
- React 应用程序中 CSS-in-JS 的性能注意事项
- 通过仅在必要时加载 polyfill、使用动态导入和延迟水合来减少 Next.js 包大小。
- JavaScript 的秘密:关于 React、性能优化和多线程的故事,一个由 7 部分组成的冗长系列,关于使用 React 改进用户界面挑战,
- 如何测量 React 性能以及如何分析 React 应用程序。
- 在 React 中构建移动优先的网络动画,Alex Holachek 的精彩演讲,以及幻灯片和 GitHub 存储库(感谢您的提示,Addy! )。
- webpack-libs-optimizations 是一个很棒的 GitHub 存储库,其中包含许多有用的特定于 Webpack 的与性能相关的优化。 由伊万·阿库洛夫维护。
- Notion 中的 React 性能改进,Ivan Akulov 编写的关于如何提高 React 性能的指南,其中包含大量有用的指针,可以使应用程序的速度提高 30% 左右。
- React Refresh Webpack Plugin(实验性)允许热重新加载,保留组件状态,并支持钩子和函数组件。
- 注意零包大小的 React 服务器组件,这是一种新提议的组件,不会对包大小产生影响。 该项目目前正在开发中,但非常感谢来自社区的任何反馈(Sophie Alpert 的出色解释)。
- 您是否对 JavaScript 块使用预测预取?
我们可以使用启发式方法来决定何时预加载 JavaScript 块。 Guess.js 是一组工具和库,它们使用 Google Analytics 数据来确定用户最有可能从给定页面访问的下一个页面。 根据从 Google Analytics 或其他来源收集的用户导航模式,Guess.js 构建了一个机器学习模型来预测和预取每个后续页面所需的 JavaScript。因此,每个交互元素都会收到参与度的概率分数,并且基于该分数,客户端脚本决定提前预取资源。 您可以将该技术集成到您的 Next.js 应用程序、Angular 和 React,并且还有一个 Webpack 插件可以自动执行设置过程。
显然,您可能会提示浏览器使用不需要的数据并预取不需要的页面,因此在预取请求的数量上保持相当保守是个好主意。 一个很好的用例是预取结帐中所需的验证脚本,或者在关键的号召性用语进入视口时进行推测性预取。
需要不那么复杂的东西吗? 当出站链接出现在视口中时,DNStradamus 会对其进行 DNS 预取。 Quicklink、InstantClick 和 Instant.page 是小型库,它们在空闲时间自动预取视口中的链接,以尝试使下一页导航加载更快。 Quicklink 允许预取 React Router 路由和 Javascript; 再加上它考虑到数据,所以它不会在 2G 或
Data-Saver开启时预取。 如果模式设置为使用视口预取(这是默认设置),则 Instant.page 也是如此。如果您想详细了解预测预取的科学,Divya Tagtachian 有一个关于预测预取的艺术的精彩演讲,涵盖了从头到尾的所有选项。
- 利用目标 JavaScript 引擎的优化。
研究哪些 JavaScript 引擎在您的用户群中占主导地位,然后探索针对它们进行优化的方法。 例如,在针对 Blink 浏览器、Node.js 运行时和 Electron 中使用的 V8 进行优化时,对单体脚本使用脚本流。脚本流允许在下载开始后在单独的后台线程上解析
async或defer scripts,因此在某些情况下可将页面加载时间提高 10%。 Practically, use<script defer>in the<head>, so that the browsers can discover the resource early and then parse it on the background thread.Caveat : Opera Mini doesn't support script deferment, so if you are developing for India or Africa,
deferwill be ignored, resulting in blocking rendering until the script has been evaluated (thanks Jeremy!) .You could also hook into V8's code caching as well, by splitting out libraries from code using them, or the other way around, merge libraries and their uses into a single script, group small files together and avoid inline scripts. Or perhaps even use v8-compile-cache.
When it comes to JavaScript in general, there are also some practices that are worth keeping in mind:
- Clean Code concepts for JavaScript, a large collection of patterns for writing readable, reusable, and refactorable code.
- You can Compress data from JavaScript with the CompressionStream API, eg to gzip before uploading data (Chrome 80+).
- Detached window memory leaks and Fixing memory leaks in web apps are detailed guides on how to find and fix tricky JavaScript memory leaks. Plus, you can use queryObjects(SomeConstructor) from the DevTools Console ( thanks, Mathias! ).
- Reexports are bad for loading and runtime performance, and avoiding them can help reduce the bundle size significantly.
- We can improve scroll performance with passive event listeners by setting a flag in the
optionsparameter. So browsers can scroll the page immediately, rather than after the listener has finished. (via Kayce Basques). - If you have any
scrollortouch*listeners, passpassive: trueto addEventListener. This tells the browser you're not planning to callevent.preventDefault()inside, so it can optimize the way it handles these events. (via Ivan Akulov) - We can achieve better JavaScript scheduling with isInputPending(), a new API that attempts to bridge the gap between loading and responsiveness with the concepts of interrupts for user inputs on the web, and allows for JavaScript to be able to check for input without yielding to the browser.
- You can also automatically remove an event listener after it has executed.
- Firefox's recently released Warp, a significant update to SpiderMonkey (shipped in Firefox 83), Baseline Interpreter and there are a few JIT Optimization Strategies available as well.
- Always prefer to self-host third-party assets.
Yet again, self-host your static assets by default. It's common to assume that if many sites use the same public CDN and the same version of a JavaScript library or a web font, then the visitors would land on our site with the scripts and fonts already cached in their browser, speeding up their experience considerably. However, it's very unlikely to happen.For security reasons, to avoid fingerprinting, browsers have been implementing partitioned caching that was introduced in Safari back in 2013, and in Chrome last year. So if two sites point to the exact same third-party resource URL, the code is downloaded once per domain , and the cache is "sandboxed" to that domain due to privacy implications ( thanks, David Calhoun! ). Hence, using a public CDN will not automatically lead to better performance.
Furthermore, it's worth noting that resources don't live in the browser's cache as long as we might expect, and first-party assets are more likely to stay in the cache than third-party assets. Therefore, self-hosting is usually more reliable and secure, and better for performance, too.
- Constrain the impact of third-party scripts.
With all performance optimizations in place, often we can't control third-party scripts coming from business requirements. Third-party-scripts metrics aren't influenced by end-user experience, so too often one single script ends up calling a long tail of obnoxious third-party scripts, hence ruining a dedicated performance effort. To contain and mitigate performance penalties that these scripts bring along, it's not enough to just defer their loading and execution and warm up connections via resource hints, iedns-prefetchorpreconnect.Currently 57% of all JavaScript code excution time is spent on third-party code. The median mobile site accesses 12 third-party domains , with a median of 37 different requests (or about 3 requests made to each third party).
Furthermore, these third-parties often invite fourth-party scripts to join in, ending up with a huge performance bottleneck, sometimes going as far as to the eigth-party scripts on a page. So regularly auditing your dependencies and tag managers can bring along costly surprises.
Another problem, as Yoav Weiss explained in his talk on third-party scripts, is that in many cases these scripts download resources that are dynamic. The resources change between page loads, so we don't necessarily know which hosts the resources will be downloaded from and what resources they would be.
Deferring, as shown above, might be just a start though as third-party scripts also steal bandwidth and CPU time from your app. We could be a bit more aggressive and load them only when our app has initialized.
/* Before */ const App = () => { return <div> <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> </div> } /* After */ const App = () => { const[isRendered, setRendered] = useState(false); useEffect(() => setRendered(true)); return <div> {isRendered ? <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> : null} </div> }In a fantastic post on "Reducing the Site-Speed Impact of Third-Party Tags", Andy Davies explores a strategy of minimizing the footprint of third-parties — from identifying their costs towards reducing their impact.
According to Andy, there are two ways tags impact site-speed — they compete for network bandwidth and processing time on visitors' devices, and depending on how they're implemented, they can delay HTML parsing as well. So the first step is to identify the impact that third-parties have, by testing the site with and without scripts using WebPageTest. With Simon Hearne's Request Map, we can also visualize third-parties on a page along with details on their size, type and what triggered their load.
Preferably self-host and use a single hostname, but also use a request map to exposes fourth-party calls and detect when the scripts change. You can use Harry Roberts' approach for auditing third parties and produce spreadsheets like this one (also check Harry's auditing workflow).
Afterwards, we can explore lightweight alternatives to existing scripts and slowly replace duplicates and main culprits with lighter options. Perhaps some of the scripts could be replaced with their fallback tracking pixel instead of the full tag.

Loading YouTube with facades, eg lite-youtube-embed that's significantly smaller than an actual YouTube player. (图片来源)(大预览) If it's not viable, we can at least lazy load third-party resources with facades, ie a static element which looks similar to the actual embedded third-party, but is not functional and therefore much less taxing on the page load. The trick, then, is to load the actual embed only on interaction .
例如,我们可以使用:
- lite-vimeo-embed for the Vimeo player,
- lite-vimeo for the Vimeo player,
- lite-youtube-embed for the YouTube player,
- react-live-chat-loader for a live chat (case study, and another case-study),
- lazyframe for iframes.
One of the reasons why tag managers are usually large in size is because of the many simultaneous experiments that are running at the same time, along with many user segments, page URLs, sites etc., so according to Andy, reducing them can reduce both the download size and the time it takes to execute the script in the browser.
And then there are anti-flicker snippets. Third-parties such as Google Optimize, Visual Web Optimizer (VWO) and others are unanimous in using them. These snippets are usually injected along with running A/B tests : to avoid flickering between the different test scenarios, they hide the
bodyof the document withopacity: 0, then adds a function that gets called after a few seconds to bring theopacityback. This often results in massive delays in rendering due to massive client-side execution costs.
With A/B testing in use, customers would often see flickering like this one. Anti-Flicker snippets prevent that, but they also cost in performance. Via Andy Davies. (大预览) Therefore keep track how often the anti-flicker timeout is triggered and reduce the timeout. Default blocks display of your page by up to 4s which will ruin conversion rates. According to Tim Kadlec, "Friends don't let friends do client side A/B testing". Server-side A/B testing on CDNs (eg Edge Computing, or Edge Slice Rerendering) is always a more performant option.
If you have to deal with almighty Google Tag Manager , Barry Pollard provides some guidelines to contain the impact of Google Tag Manager. Also, Christian Schaefer explores strategies for loading ads.
注意:一些第三方小部件隐藏在审计工具之外,因此它们可能更难以发现和测量。 要对第三方进行压力测试,请在 DevTools 的性能配置文件页面中检查自下而上的摘要,测试如果请求被阻止或超时会发生什么——对于后者,您可以使用 WebPageTest 的 Blackhole 服务器
blackhole.webpagetest.org可以在您的hosts文件中指向特定域。那我们有什么选择呢? 考虑使用服务工作者通过超时来加速资源下载,如果资源在特定超时内没有响应,则返回一个空响应来告诉浏览器继续解析页面。 您还可以记录或阻止不成功或不满足特定条件的第三方请求。 如果可以,请从您自己的服务器而不是从供应商的服务器加载 3rd-party-script 并延迟加载它们。
另一种选择是建立内容安全策略 (CSP)以限制第三方脚本的影响,例如禁止下载音频或视频。 最好的选择是通过
<iframe>嵌入脚本,以便脚本在 iframe 的上下文中运行,因此无法访问页面的 DOM,并且不能在您的域上运行任意代码。 使用sandbox属性可以进一步限制 iframe,因此您可以禁用 iframe 可能执行的任何功能,例如阻止脚本运行、阻止警报、表单提交、插件、访问顶部导航等等。您还可以通过使用功能策略的浏览器内性能检查来检查第三方,这是一项相对较新的功能,可让您
选择加入或退出您网站上的某些浏览器功能。 (作为旁注,它还可用于避免过大和未优化的图像、未调整大小的媒体、同步脚本等)。 目前支持基于 Blink 的浏览器。 /* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'/* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'由于许多第三方脚本在 iframe 中运行,您可能需要彻底限制它们的允许范围。 沙盒 iframe 总是一个好主意,每个限制都可以通过
sandbox属性上的一些allow值来解除。 几乎所有地方都支持沙盒,因此将第三方脚本限制在应允许的最低限度。
ThirdPartyWeb.Today 按类别(分析、社交、广告、托管、标签管理器等)对所有第三方脚本进行分组,并可视化实体脚本执行所需的时间(平均)。 (大预览) 考虑使用交叉口观察器; 这将使广告能够被 iframe ,同时仍然调度事件或从 DOM 获取他们需要的信息(例如广告可见性)。 注意新策略,例如功能策略、资源大小限制和 CPU/带宽优先级,以限制会降低浏览器速度的有害 Web 功能和脚本,例如同步脚本、同步 XHR 请求、 document.write和过时的实现。
最后,在选择第三方服务时,请考虑查看 Patrick Hulce 的 ThirdPartyWeb.Today,该服务按类别(分析、社交、广告、托管、标签管理器等)对所有第三方脚本进行分组,并可视化实体脚本的时长执行(平均)。 显然,最大的实体对其所在页面的性能影响最差。 只需浏览页面,您就会了解您应该期待的性能足迹。
啊,不要忘记通常的嫌疑人:我们可以使用静态社交共享按钮(例如 SSBG)和交互式地图的静态链接而不是交互式地图,而不是使用第三方小部件进行共享。
- 正确设置 HTTP 缓存标头。
缓存似乎是一件显而易见的事情,但要做到正确可能相当困难。 我们需要仔细检查expires、max-age、cache-control和其他 HTTP 缓存标头是否已正确设置。 如果没有适当的 HTTP 缓存标头,浏览器将自动将它们设置为自last-modified以来经过时间的 10%,最终导致潜在的缓存不足和过度缓存。通常,资源应该可以在很短的时间内(如果它们可能会更改)或无限期(如果它们是静态的)可以缓存——您可以在需要时在 URL 中更改它们的版本。 您可以将其称为 Cache-Forever 策略,其中我们可以将
Cache-Control和Expires标头中继到浏览器,以仅允许资产在一年内过期。 因此,如果资产在缓存中,浏览器甚至不会发出请求。例外是 API 响应(例如
/api/user)。 为了防止缓存,我们可以使用private, no store,而不是max-age=0, no-store:Cache-Control: private, no-store使用
Cache-control: immutable以避免在用户点击重新加载按钮时重新验证长显式缓存生命周期。 对于重新加载的情况,immutable的保存了 HTTP 请求并改善了动态 HTML 的加载时间,因为它们不再与大量 304 响应竞争。我们想要使用
immutable的典型示例是名称中带有哈希的 CSS/JavaScript 资产。 对于他们,我们可能希望尽可能长时间地缓存,并确保他们永远不会被重新验证:Cache-Control: max-age: 31556952, immutable根据 Colin Bendell 的研究,
immutable将 304 重定向减少了大约 50%,即使使用了max-age,客户端仍然会在刷新时重新验证并阻止。 Firefox、Edge 和 Safari 都支持它,而 Chrome 仍在争论这个问题。据 Web Almanac 称,“它的使用率已经增长到 3.5%,并且被广泛用于 Facebook 和 Google 第三方响应中。”

根据 Colin Bendell 在 Cloudinary 的研究,Cache-Control: Immutable 将 304 减少了大约 50%。 (大预览) 你还记得旧时重新验证的好方法吗? 当我们用
Cache-Control响应头指定缓存时间时(例如Cache-Control: max-age=604800),在max-age过期后,浏览器会重新获取请求的内容,导致页面加载速度变慢。stale-while-revalidate可以避免这种减速; 它基本上定义了一个额外的时间窗口,在此期间缓存可以使用陈旧的资产,只要它在后台重新验证它是异步的。 因此,它“隐藏”了客户端的延迟(在网络和服务器上)。在 2019 年 6 月至 2019 年 7 月, Chrome 和 Firefox 推出了对 HTTP Cache-Control 标头中的
stale-while-revalidate的支持,因此它应该会改善后续页面加载延迟,因为过时的资产不再处于关键路径中。 结果:重复视图的 RTT 为零。警惕可变标头,尤其是与 CDN 相关的标头,并注意 HTTP 表示变体,这有助于避免在新请求与先前请求略有不同(但不显着)时进行额外的往返验证(感谢 Guy 和 Mark ! )。
此外,请仔细检查您没有发送不必要的标头(例如
x-powered-by、pragma、x-ua-compatible、expires、X-XSS-Protection等),并且您包含有用的安全和性能标头(例如作为Content-Security-Policy、X-Content-Type-Options等)。 最后,请记住单页应用程序中 CORS 请求的性能成本。注意:我们经常假设缓存的资产会被立即检索,但研究表明从缓存中检索对象可能需要数百毫秒。 事实上,根据 Simon Hearne 的说法,“有时网络可能比缓存更快,并且从缓存中检索资产的成本可能很高,因为缓存的资产(不是文件大小)和用户的设备数量很大。例如:Chrome OS 平均缓存检索从具有 5 个缓存资源的 ~50ms 到具有 25 个资源的 ~100ms 翻倍”。
此外,我们通常假设捆绑包大小不是一个大问题,用户会下载一次,然后使用缓存版本。 同时,通过 CI/CD,我们每天多次将代码推送到生产环境,缓存每次都会失效,因此对缓存有策略性很重要。
谈到缓存,有很多资源值得一读:
- 平民缓存控制,与 Harry Roberts 一起深入研究缓存的所有内容。
- Heroku 的 HTTP 缓存标头入门,
- Jake Archibald 的缓存最佳实践,
- Ilya Grigorik 的 HTTP 缓存入门,
- 通过 Jeff Posnick 的 stale-while-revalidate 保持新鲜。
- CS 可视化:Lydia Hallie 的 CORS 是关于 CORS、它如何工作以及如何理解它的出色解释者。
- 谈到 CORS,这里是 Eric Portis 对同源策略的一些复习。
交付优化
- 我们是否使用
defer来异步加载关键的 JavaScript?
当用户请求一个页面时,浏览器获取 HTML 并构造 DOM,然后获取 CSS 并构造 CSSOM,然后通过匹配 DOM 和 CSSOM 生成渲染树。 如果需要解析任何 JavaScript,浏览器在解析之前不会开始渲染页面,从而延迟渲染。 作为开发人员,我们必须明确告诉浏览器不要等待并开始渲染页面。 对脚本执行此操作的方法是使用 HTML 中的defer和async属性。在实践中,事实证明最好使用
defer而不是async。 啊,又有什么区别呢? 根据 Steve Souders 的说法,一旦async脚本到达,它们就会立即执行——只要脚本准备好。 如果这种情况发生得非常快,例如当脚本处于缓存中时,它实际上会阻塞 HTML 解析器。 使用defer,浏览器在解析 HTML 之前不会执行脚本。 因此,除非您需要在开始渲染之前执行 JavaScript,否则最好使用defer。 此外,多个异步文件将以不确定的顺序执行。值得注意的是,关于
async和defer存在一些误解。 最重要的是,async并不意味着只要脚本准备好,代码就会运行。 这意味着只要脚本准备好并且所有先前的同步工作完成,它将运行。 用 Harry Roberts 的话来说,“如果你在同步脚本之后放置一个async脚本,那么你的async脚本只会和最慢的同步脚本一样快。”此外,不建议同时使用
async和defer。 现代浏览器同时支持这两种属性,但只要同时使用这两种属性,async总是会胜出的。如果您想深入了解更多细节,Milica Mihajlija 编写了一份关于更快构建 DOM 的非常详细的指南,详细介绍了推测解析、异步和延迟。
- 使用 IntersectionObserver 和优先级提示延迟加载昂贵的组件。
一般来说,建议延迟加载所有昂贵的组件,例如繁重的 JavaScript、视频、iframe、小部件和潜在的图像。 本机延迟加载已经可用于具有loading属性的图像和 iframe(仅限 Chromium)。 在幕后,此属性延迟资源的加载,直到它到达与视口的计算距离。<!-- Lazy loading for images, iframes, scripts. Probably for images outside of the viewport. --> <img loading="lazy" ... /> <iframe loading="lazy" ... /> <!-- Prompt an early download of an asset. For critical images, eg hero images. --> <img loading="eager" ... /> <iframe loading="eager" ... />该阈值取决于几件事,从要获取的图像资源的类型到有效的连接类型。 但在 Android 上使用 Chrome 进行的实验表明,在 4G 上,97.5% 的延迟加载的首屏图像在可见后 10 毫秒内完全加载,因此应该是安全的。
我们还可以在
<script>、<img>或<link>元素(仅闪烁)上使用importance属性(high或low)。 事实上,这是一种在轮播中取消图像优先级以及重新确定脚本优先级的好方法。 但是,有时我们可能需要更精细的控制。<!-- When the browser assigns "High" priority to an image, but we don't actually want that. --> <img src="less-important-image.svg" importance="low" ... /> <!-- We want to initiate an early fetch for a resource, but also deprioritize it. --> <link rel="preload" importance="low" href="/script.js" as="script" />执行稍微复杂一点的延迟加载的最高效方法是使用 Intersection Observer API,它提供了一种异步观察目标元素与祖先元素或顶级文档视口的交集变化的方法。 基本上,您需要创建一个新的
IntersectionObserver对象,该对象接收一个回调函数和一组选项。 然后我们添加一个目标来观察。回调函数在目标变得可见或不可见时执行,因此当它拦截视口时,您可以在元素变得可见之前开始执行一些操作。 事实上,我们可以通过
rootMargin(根周围的边距)和threshold(单个数字或数字数组,指示我们瞄准的目标可见性的百分比)对何时调用观察者的回调进行精细控制。Alejandro Garcia Anglada 发布了一个关于如何实际实现它的方便教程,Rahul Nanwani 写了一篇关于延迟加载前景和背景图像的详细文章,Google Fundamentals 也提供了关于延迟加载图像和视频的详细教程,以及 Intersection Observer。
还记得带有移动和粘性物体的艺术指导的长篇故事吗? 您也可以使用 Intersection Observer 实现高性能的滚动显示。
再次检查您可以延迟加载的其他内容。 甚至延迟加载翻译字符串和表情符号也会有所帮助。 通过这样做,Mobile Twitter 成功地将新的国际化管道的 JavaScript 执行速度提高了 80%。
一个简短的警告:值得注意的是延迟加载应该是一个例外而不是规则。 延迟加载您真正希望人们快速看到的任何内容可能是不合理的,例如产品页面图像、英雄图像或主导航变为交互所需的脚本。

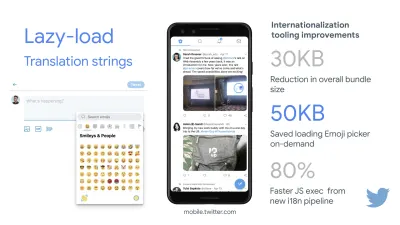
- 逐步加载图像。
您甚至可以通过向页面添加渐进式图像加载来将延迟加载提升到一个新的水平。 与 Facebook、Pinterest、Medium 和 Wolt 类似,您可以先加载低质量甚至模糊的图像,然后随着页面继续加载,使用 BlurHash 技术或 LQIP(低质量图像占位符)将它们替换为完整质量版本技术。如果这些技术是否改善了用户体验,意见会有所不同,但它肯定会缩短首次内容绘制的时间。 我们甚至可以通过使用 SQIP 来自动化它,该 SQIP 创建一个低质量版本的图像作为 SVG 占位符,或带有 CSS 线性渐变的渐变图像占位符。
这些占位符可以嵌入到 HTML 中,因为它们自然可以很好地使用文本压缩方法进行压缩。 在他的文章中,Dean Hume 描述了如何使用 Intersection Observer 来实现这种技术。
倒退? 如果浏览器不支持交叉点观察器,我们仍然可以延迟加载 polyfill 或立即加载图像。 甚至还有一个图书馆。
想要更高级? 您可以跟踪图像并使用原始形状和边缘来创建轻量级 SVG 占位符,首先加载它,然后从占位符矢量图像过渡到(加载的)位图图像。
- 您是否延迟渲染
content-visibility?
对于包含大量内容块、图像和视频的复杂布局,解码数据和渲染像素可能是一项相当昂贵的操作——尤其是在低端设备上。 使用content-visibility: auto,我们可以在容器位于视口之外时提示浏览器跳过子项的布局。例如,您可能会在初始加载时跳过页脚和后期部分的呈现:
footer { content-visibility: auto; contain-intrinsic-size: 1000px; /* 1000px is an estimated height for sections that are not rendered yet. */ }注意content-visibility: auto; 表现得像溢出:隐藏; ,但您可以通过应用
padding-left和padding-right而不是默认的margin-left: auto;,margin-right: auto;和声明的宽度。 填充基本上允许元素溢出内容框并进入填充框,而不会离开整个盒子模型并被切断。另外,请记住,当最终呈现新内容时,您可能会引入一些 CLS,因此最好将
contain-intrinsic-size与适当大小的占位符一起使用(谢谢,Una! )。Thijs Terluin 有更多关于这两个属性以及浏览器如何计算 contains
contain-intrinsic-size的详细信息,Malte Ubl 展示了如何计算它,Jake 和 Surma 的简短视频解释器解释了它是如何工作的。如果您需要更细化,使用 CSS 包含,如果您只需要其他元素的大小、对齐或计算样式,您可以手动跳过 DOM 节点后代的布局、样式和绘制工作——或者该元素当前是画布外。


content-visibility: auto应用于分块内容区域可在初始加载时将渲染性能提升 7 倍。 (大预览)- 您是否使用
decoding="async"延迟解码?
有时内容会出现在屏幕外,但我们希望确保它在客户需要时可用——理想情况下,不阻塞关键路径中的任何内容,而是异步解码和渲染。 我们可以使用decodedecoding="async"来授予浏览器从主线程解码图像的权限,避免用户对用于解码图像的CPU时间的影响(通过Malte Ubl):<img decoding="async" … />或者,对于屏幕外的图像,我们可以先显示一个占位符,当图像在视口内时,使用 IntersectionObserver 触发网络调用以在后台下载图像。 此外,如果 Image Decode API 不可用,我们可以将渲染推迟到使用 img.decode() 解码或下载图像。
例如,在渲染图像时,我们可以使用淡入动画。 Katie Hempenius 和 Addy Osmani 在他们的演讲 Speed at Scale: Web Performance Tips and Tricks from the Trenches 中分享了更多见解。
- 您是否生成并提供关键的 CSS?
为了确保浏览器尽快开始呈现您的页面,收集开始呈现页面第一个可见部分所需的所有 CSS(称为“关键 CSS”或“首屏 CSS”已成为一种常见做法") 并将其包含在页面的<head>中,从而减少往返。 由于在慢启动阶段交换的包的大小有限,关键 CSS 的预算约为 14KB。如果超出此范围,浏览器将需要额外的往返来获取更多样式。 CriticalCSS 和 Critical 使您能够为您正在使用的每个模板输出关键 CSS。 不过,根据我们的经验,没有任何自动系统比为每个模板手动收集关键 CSS 更好,而这确实是我们最近重新采用的方法。
然后,您可以使用 critters Webpack 插件内联关键 CSS 并延迟加载其余部分。 如果可能,请考虑使用 Filament Group 使用的条件内联方法,或动态将内联代码转换为静态资源。
如果您当前使用诸如 loadCSS 之类的库异步加载完整的 CSS ,则实际上没有必要。 使用
media="print",您可以欺骗浏览器异步获取 CSS,但在加载后应用到屏幕环境。 (谢谢,斯科特! )<!-- Via Scott Jehl. https://www.filamentgroup.com/lab/load-css-simpler/ --> <!-- Load CSS asynchronously, with low priority --> <link rel="stylesheet" href="full.css" media="print" onload="this.media='all'" />在收集每个模板的所有关键 CSS 时,通常只探索“首屏”区域。 但是,对于复杂的布局,最好将布局的基础也包括在内,以避免大量的重新计算和重新绘制成本,从而损害您的 Core Web Vitals 分数。
如果用户得到一个直接链接到页面中间的 URL 但 CSS 尚未下载怎么办? 在这种情况下,隐藏非关键内容变得很常见,例如
opacity: 0;内联 CSS 和opacity: 1在完整的 CSS 文件中,并在 CSS 可用时显示。 但它有一个主要缺点,因为连接速度较慢的用户可能永远无法阅读页面的内容。 这就是为什么最好始终保持内容可见,即使它的样式可能不正确。由于缓存,将关键 CSS(和其他重要资产)放在根域上的单独文件中具有好处,有时甚至超过内联。 Chrome 在请求页面时会推测性地打开到根域的第二个 HTTP 连接,这样就不需要 TCP 连接来获取此 CSS。 这意味着您可以创建一组关键的-CSS 文件(例如, critical-homepage.css 、 critical-product-page.css等)并从您的根目录提供它们,而无需内联它们。 (谢谢,菲利普! )
需要注意的是:使用 HTTP/2,关键 CSS 可以存储在单独的 CSS 文件中,并通过服务器推送交付,而不会使 HTML 膨胀。 问题是服务器推送对于跨浏览器的许多陷阱和竞争条件很麻烦。 它从来没有得到一致的支持,并且存在一些缓存问题(参见 Hooman Beheshti 演示文稿的幻灯片 114)。
事实上,这种影响可能是负面的,并且会使网络缓冲区膨胀,从而阻止传递文档中的真实帧。 因此,Chrome 计划暂时取消对 Server Push 的支持也就不足为奇了。
- 尝试重新组合 CSS 规则。
我们已经习惯了关键的 CSS,但还有一些优化可以超越这一点。 哈里·罗伯茨(Harry Roberts)进行了一项非凡的研究,结果令人惊讶。 例如,将主 CSS 文件拆分为单独的媒体查询可能是个好主意。 这样,浏览器将检索具有高优先级的关键 CSS,并以低优先级检索其他所有内容——完全脱离关键路径。另外,避免将
<link rel="stylesheet" />放在async片段之前。 如果脚本不依赖于样式表,请考虑将阻塞脚本置于阻塞样式之上。 如果是这样,则将该 JavaScript 分成两部分并将其加载到 CSS 的任一侧。Scott Jehl 通过使用 service worker 缓存内联 CSS 文件解决了另一个有趣的问题,如果您使用关键 CSS,这是一个常见的问题。 基本上,我们在
style元素上添加一个 ID 属性,以便使用 JavaScript 轻松找到它,然后一小段 JavaScript 找到该 CSS 并使用 Cache API 将其存储在本地浏览器缓存中(内容类型为text/css) 用于后续页面。 为了避免在后续页面上内联,而是在外部引用缓存的资产,我们在第一次访问网站时设置了一个 cookie。 瞧!值得注意的是,动态样式也可能很昂贵,但通常仅在您依赖数百个同时呈现的组合组件的情况下。 因此,如果您使用 CSS-in-JS,请确保您的 CSS-in-JS 库在您的 CSS 不依赖主题或道具时优化执行,并且不要过度组合样式化的组件。 Aggelos Arvanitakis 分享了关于 CSS-in-JS 的性能成本的更多见解。
- 您是否流式传输响应?
流经常被遗忘和忽视,流提供了一个用于读取或写入异步数据块的接口,在任何给定时间,内存中可能只有其中的一个子集可用。 基本上,它们允许发出原始请求的页面在第一块数据可用时立即开始处理响应,并使用针对流式传输优化的解析器来逐步显示内容。我们可以从多个来源创建一个流。 例如,您可以让 service worker构建一个流,其中 shell 来自缓存,而主体来自网络,而不是提供一个空的 UI shell 并让 JavaScript 填充它。 正如 Jeff Posnick 所指出的,如果您的 Web 应用程序由 CMS 提供支持,该 CMS 通过将部分模板拼接在一起来呈现 HTML,该模型直接转换为使用流式响应,模板逻辑复制到服务工作者而不是您的服务器中。 Jake Archibald 的 The Year of Web Streams 文章重点介绍了如何构建它。 性能提升非常明显。
流式传输整个 HTML 响应的一个重要优势是,在初始导航请求期间呈现的 HTML 可以充分利用浏览器的流式 HTML 解析器。 在页面加载后插入到文档中的 HTML 块(这在通过 JavaScript 填充的内容很常见)不能利用这种优化。
浏览器支持? Chrome、Firefox、Safari 和 Edge 的部分支持仍然支持 API 和所有现代浏览器都支持的 Service Worker。 如果您再次感到冒险,您可以检查流式请求的实验性实现,它允许您在仍然生成正文的同时开始发送请求。 在 Chrome 85 中可用。
- 考虑使您的组件具有连接意识。
数据可能很昂贵,并且随着负载的增加,我们需要尊重在访问我们的网站或应用程序时选择节省数据的用户。 Save-Data 客户端提示请求标头允许我们为成本和性能受限的用户定制应用程序和有效负载。实际上,您可以将对高 DPI 图像的请求重写为低 DPI 图像、删除 Web 字体、花哨的视差效果、预览缩略图和无限滚动、关闭视频自动播放、服务器推送、减少显示项目的数量和降低图像质量,或者甚至改变你提供标记的方式。 Tim Vereecke 发表了一篇关于 data-s(h)aver 策略的非常详细的文章,其中包含许多数据保存选项。
谁在使用
save-data,您可能想知道? 全球 18% 的 Android Chrome 用户启用了精简模式(启用Save-Data),而且这个数字可能会更高。 根据 Simon Hearne 的研究,廉价设备的选择加入率最高,但也有很多异常值。 例如:加拿大用户的选择加入率超过 34%(相比之下,美国约为 7%),三星最新旗舰产品的全球用户选择加入率接近 18%。启用
Save-Data模式后,Chrome Mobile 将提供优化的体验,即具有延迟脚本、强制font-display: swap和强制延迟加载的代理网络体验。 自己构建体验比依赖浏览器进行这些优化更明智。当前仅在 Chromium、Android 版本的 Chrome 或桌面设备上的数据保护程序扩展中支持该标头。 最后,您还可以使用网络信息 API 来根据网络类型交付昂贵的 JavaScript 模块、高分辨率图像和视频。 网络信息 API,特别是
navigator.connection.effectiveType使用RTT、downlink、effectiveType值(以及其他一些值)来提供用户可以处理的连接和数据的表示。在这种情况下,Max Bock 谈到了连接感知组件,而 Addy Osmani 谈到了自适应模块服务。 例如,使用 React,我们可以编写一个针对不同连接类型呈现不同的组件。 正如 Max 所建议的,新闻文章中的
<Media />组件可能会输出:-
Offline:带有alt文字的占位符, -
2G/save-data模式:低分辨率图像, - 非 Retina 屏幕上的
3G:中等分辨率图像, - Retina 屏幕上的
3G:高分辨率 Retina 图像, -
4G:高清视频。
Dean Hume 使用服务工作者提供了类似逻辑的实际实现。 对于视频,我们可以默认显示视频海报,然后在更好的连接上显示“播放”图标以及视频播放器外壳、视频元数据等。 作为不支持浏览器的后备方案,我们可以监听
canplaythrough事件并使用Promise.race()如果canplaythrough事件在 2 秒内未触发,则使源加载超时。如果您想更深入地研究,这里有一些资源可以开始:
- Addy Osmani 展示了如何在 React 中实现自适应服务。
- React Adaptive Loading Hooks & Utilities 提供了 React 的代码片段,
- Netanel Basel 探索 Angular 中的连接感知组件,
- Theodore Vorilas 分享了在 Vue 中使用网络信息 API 服务自适应组件的工作原理。
- Umar Hansa 展示了如何选择性地下载/执行昂贵的 JavaScript。
-
- 考虑让您的组件具有设备内存感知能力。
但是,网络连接只为我们提供了一种关于用户上下文的视角。 更进一步,您还可以使用设备内存 API 根据可用设备内存动态调整资源。navigator.deviceMemoryreturns how much RAM the device has in gigabytes, rounded down to the nearest power of two. The API also features a Client Hints Header,Device-Memory, that reports the same value.Bonus : Umar Hansa shows how to defer expensive scripts with dynamic imports to change the experience based on device memory, network connectivity and hardware concurrency.
- Warm up the connection to speed up delivery.
Use resource hints to save time ondns-prefetch(which performs a DNS lookup in the background),preconnect(which asks the browser to start the connection handshake (DNS, TCP, TLS) in the background),prefetch(which asks the browser to request a resource) andpreload(which prefetches resources without executing them, among other things). Well supported in modern browsers, with support coming to Firefox soon.Remember
prerender? The resource hint used to prompt browser to build out the entire page in the background for next navigation. The implementations issues were quite problematic, ranging from a huge memory footprint and bandwidth usage to multiple registered analytics hits and ad impressions.Unsurprinsingly, it was deprecated, but the Chrome team has brought it back as NoState Prefetch mechanism. In fact, Chrome treats the
prerenderhint as a NoState Prefetch instead, so we can still use it today. As Katie Hempenius explains in that article, "like prerendering, NoState Prefetch fetches resources in advance ; but unlike prerendering, it does not execute JavaScript or render any part of the page in advance."NoState Prefetch only uses ~45MiB of memory and subresources that are fetched will be fetched with an
IDLENet Priority. Since Chrome 69, NoState Prefetch adds the header Purpose: Prefetch to all requests in order to make them distinguishable from normal browsing.Also, watch out for prerendering alternatives and portals, a new effort toward privacy-conscious prerendering, which will provide the inset
previewof the content for seamless navigations.Using resource hints is probably the easiest way to boost performance , and it works well indeed. When to use what? As Addy Osmani has explained, it's reasonable to preload resources that we know are very likely to be used on the current page and for future navigations across multiple navigation boundaries, eg Webpack bundles needed for pages the user hasn't visited yet.
Addy's article on "Loading Priorities in Chrome" shows how exactly Chrome interprets resource hints, so once you've decided which assets are critical for rendering, you can assign high priority to them. To see how your requests are prioritized, you can enable a "priority" column in the Chrome DevTools network request table (as well as Safari).
Most of the time these days, we'll be using at least
preconnectanddns-prefetch, and we'll be cautious with usingprefetch,preloadandprerender. Note that even withpreconnectanddns-prefetch, the browser has a limit on the number of hosts it will look up/connect to in parallel, so it's a safe bet to order them based on priority ( thanks Philip Tellis! ).Since fonts usually are important assets on a page, sometimes it's a good idea to request the browser to download critical fonts with
preload. However, double check if it actually helps performance as there is a puzzle of priorities when preloading fonts: aspreloadis seen as high importance, it can leapfrog even more critical resources like critical CSS. ( thanks, Barry! )<!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /><!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" />Since
<link rel="preload">accepts amediaattribute, you could choose to selectively download resources based on@mediaquery rules, as shown above.Furthermore, we can use
imagesrcsetandimagesizesattributes to preload late-discovered hero images faster, or any images that are loaded via JavaScript, eg movie posters:<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image><!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image>We can also preload the JSON as fetch , so it's discovered before JavaScript gets to request it:
<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="fetch" href="foo.com/api/movies.json" crossorigin>We could also load JavaScript dynamically, effectively for lazy execution of the script.
/* Adding a preload hint to the head */ var preload = document.createElement("link"); link.href = "myscript.js"; link.rel = "preload"; link.as = "script"; document.head.appendChild(link); /* Injecting a script when we want it to execute */ var script = document.createElement("script"); script.src = "myscript.js"; document.body.appendChild(script);A few gotchas to keep in mind:
preloadis good for moving the start download time of an asset closer to the initial request, but preloaded assets land in the memory cache which is tied to the page making the request.preloadplays well with the HTTP cache: a network request is never sent if the item is already there in the HTTP cache.Hence, it's useful for late-discovered resources, hero images loaded via
background-image, inlining critical CSS (or JavaScript) and pre-loading the rest of the CSS (or JavaScript).
Preload important images early; no need to wait on JavaScript to discover them. (Image credit: “Preload Late-Discovered Hero Images Faster” by Addy Osmani) (Large preview) A
preloadtag can initiate a preload only after the browser has received the HTML from the server and the lookahead parser has found thepreloadtag. Preloading via the HTTP header could be a bit faster since we don't to wait for the browser to parse the HTML to start the request (it's debated though).Early Hints will help even further, enabling preload to kick in even before the response headers for the HTML are sent (on the roadmap in Chromium, Firefox). Plus, Priority Hints will help us indicate loading priorities for scripts.
Beware : if you're using
preload,asmust be defined or nothing loads, plus preloaded fonts without thecrossoriginattribute will double fetch. If you're usingprefetch, beware of theAgeheader issues in Firefox.
- Use service workers for caching and network fallbacks.
No performance optimization over a network can be faster than a locally stored cache on a user's machine (there are exceptions though). If your website is running over HTTPS, we can cache static assets in a service worker cache and store offline fallbacks (or even offline pages) and retrieve them from the user's machine, rather than going to the network.As suggested by Phil Walton, with service workers, we can send smaller HTML payloads by programmatically generating our responses. A service worker can request just the bare minimum of data it needs from the server (eg an HTML content partial, a Markdown file, JSON data, etc.), and then it can programmatically transform that data into a full HTML document. So once a user visits a site and the service worker is installed, the user will never request a full HTML page again. The performance impact can be quite impressive.
Browser support? Service workers are widely supported and the fallback is the network anyway. Does it help boost performance ? Oh yes, it does. And it's getting better, eg with Background Fetch allowing background uploads/downloads via a service worker as well.
There are a number of use cases for a service worker. For example, you could implement "Save for offline" feature, handle broken images, introduce messaging between tabs or provide different caching strategies based on request types. In general, a common reliable strategy is to store the app shell in the service worker's cache along with a few critical pages, such as offline page, frontpage and anything else that might be important in your case.
There are a few gotchas to keep in mind though. With a service worker in place, we need to beware range requests in Safari (if you are using Workbox for a service worker it has a range request module). If you ever stumbled upon
DOMException: Quota exceeded.error in the browser console, then look into Gerardo's article When 7KB equals 7MB.正如 Gerardo 所写,“如果您正在构建一个渐进式 Web 应用程序,并且当您的 Service Worker 缓存从 CDN 提供的静态资产时,您遇到了膨胀的缓存存储,请确保跨域资源存在正确的 CORS 响应标头,您不要缓存不透明的响应与您的服务人员无意中,您通过将
crossorigin属性添加到<img>标记来选择跨域图像资产进入 CORS 模式。”有很多很棒的资源可以帮助您开始使用服务人员:
- Service Worker Mindset,它可以帮助您了解 Service Worker 如何在幕后工作以及在构建服务人员时要了解的内容。
- Chris Ferdinandi 提供了一系列关于服务工作者的精彩文章,解释了如何创建离线应用程序并涵盖了各种场景,从离线保存最近查看的页面到为服务工作者缓存中的项目设置过期日期。
- Service Worker 陷阱和最佳实践,包括一些关于范围、延迟注册 Service Worker 和 Service Worker 缓存的提示。
- Ire Aderinokun 与 Service Worker 的“离线优先”系列,其中包含预缓存应用程序外壳的策略。
- Service Worker:介绍如何使用 Service Worker 获得丰富的离线体验、定期后台同步和推送通知的实用技巧。
- 总是值得参考优秀的 ol' Jake Archibald 的离线食谱,其中包含许多关于如何烘焙自己的服务人员的食谱。
- Workbox 是一组专门为构建渐进式 Web 应用程序而构建的服务工作者库。
- 您是否在 CDN/Edge 上运行服务器工作者,例如用于 A/B 测试?
在这一点上,我们已经习惯了在客户端运行服务工作者,但是通过在服务器上实现它们的 CDN,我们也可以使用它们来调整边缘的性能。例如,在 A/B 测试中,当 HTML 需要为不同的用户改变其内容时,我们可以使用 CDN 服务器上的 Service Worker 来处理逻辑。 我们还可以流式传输 HTML 重写以加速使用 Google 字体的网站。
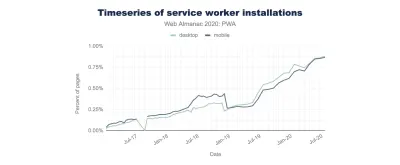
- 优化渲染性能。
每当应用程序运行缓慢时,都会立即引起注意。 因此,我们需要确保在滚动页面或动画元素时没有延迟,并且您始终保持每秒 60 帧的速度。 如果这不可能,那么至少使每秒帧数保持一致比 60 到 15 的混合范围更可取。使用 CSS 的will-change通知浏览器哪些元素和属性将发生变化。每当您遇到时,请在 DevTools 中调试不必要的重绘:
- 测量运行时渲染性能。 查看一些有关如何理解它的有用提示。
- 要开始使用,请查看 Paul Lewis 关于浏览器渲染优化的免费 Udacity 课程和 Georgy Marchuk 关于浏览器绘画和 Web 性能考虑的文章。
- 在 Firefox DevTools 的“更多工具 → 渲染 → 画图闪烁”中启用画图闪烁。
- 在 React DevTools 中,选中“突出显示更新”并启用“记录每个组件呈现的原因”,
- 您还可以使用Why Did You Render,因此当重新渲染组件时,Flash 会通知您更改。
您使用的是砌体布局吗? 请记住,很快就可以单独使用 CSS 网格构建 Masonry 布局。
如果您想深入探讨该主题,Nolan Lawson 在他的文章中分享了准确测量布局性能的技巧,Jason Miller 也提出了替代技术。 我们还有一篇 Sergey Chikuyonok 撰写的关于如何正确设置 GPU 动画的文章。

浏览器可以廉价地为变换和不透明度设置动画。 CSS 触发器对于检查 CSS 是否触发重新布局或重排很有用。 (图片来源:Addy Osmani)(大预览) 注意:对 GPU 合成层的更改是最便宜的,因此如果您可以通过
opacity和transform仅触发合成来摆脱困境,那么您将走在正确的轨道上。 Anna Migas 在她关于调试 UI 渲染性能的演讲中也提供了很多实用的建议。 要了解如何在 DevTools 中调试绘制性能,请查看 Umar 的绘制性能审核视频。 - 您是否针对感知性能进行了优化?
虽然组件出现在页面上的顺序,以及我们如何为浏览器提供资源的策略很重要,但我们也不应该低估感知性能的作用。 这个概念涉及等待的心理方面,基本上是让客户在其他事情发生时保持忙碌或参与。 这就是感知管理、抢先开始、提前完成和容忍管理发挥作用的地方。这是什么意思呢? 在加载资产时,我们可以尝试始终领先于客户一步,因此在后台发生很多事情的同时,体验感觉很快。 为了保持客户的参与度,我们可以测试骨架屏幕(实现演示)而不是加载指示器,添加过渡/动画,并且基本上在没有什么可以优化的情况下欺骗用户体验。
在他们关于 UI 骨架艺术的案例研究中,Kumar McMillan 分享了一些关于如何模拟动态列表、文本和最终屏幕的想法和技术,以及如何使用 React 考虑骨架思维。
但请注意:在部署之前应该测试骨架屏幕,因为一些测试表明骨架屏幕在所有指标上都表现最差。
- 您是否防止布局变化和重绘?
在感知性能领域,可能更具破坏性的体验之一是布局转换或重排,这是由重新缩放的图像和视频、网络字体、注入的广告或用实际内容填充组件的后期发现的脚本引起的。 结果,客户可能开始阅读一篇文章,只是被阅读区域上方的布局跳转打断。 这种体验通常是突然的并且非常令人迷惑:这可能是加载需要重新考虑的优先级的情况。社区已经开发了一些技术和解决方法来避免回流。 一般来说,避免在现有内容之上插入新内容是个好主意,除非它是为了响应用户交互而发生的。 始终在图像上设置宽度和高度属性,因此现代浏览器默认分配框并保留空间(Firefox、Chrome)。
对于图像或视频,我们可以使用 SVG 占位符来保留媒体将出现的显示框。这意味着当您需要保持其纵横比时,该区域将被正确保留。 我们还可以为广告和动态内容使用占位符或后备图像,以及预分配布局插槽。
仅在不支持本地延迟加载时才加载外部脚本时,考虑使用本地延迟加载或混合延迟加载,而不是使用外部脚本延迟加载图像。
如上所述,始终将 Web 字体重绘和从所有后备字体转换为所有Web 字体一次进行分组——只需确保该切换不会太突然,通过使用 font-style-matcher 调整字体之间的行高和间距.
要覆盖备用字体的字体指标以模拟 Web 字体,我们可以使用 @font-face 描述符来覆盖字体指标(演示,在 Chrome 87 中启用)。 (请注意,调整会因复杂的字体堆栈而变得复杂。)
对于后期 CSS,我们可以确保布局关键的 CSS 内联在每个模板的标题中。 更进一步:对于长页面,当添加垂直滚动条时,它会将主要内容向左移动 16px。 为了尽早显示滚动条,我们可以在
html上添加overflow-y: scroll以在第一次绘制时强制滚动条。 后者有帮助,因为当宽度改变时,由于折叠内容重排,滚动条会导致非平凡的布局变化。 不过,应该主要发生在具有非覆盖滚动条的平台上,例如 Windows。 但是:中断position: sticky,因为这些元素永远不会滚动出容器。如果您处理在滚动时固定或粘在页面顶部的页眉,请在页眉松动时为页眉保留空间,例如在内容上使用占位符元素或
margin-top。 一个例外应该是不应该对 CLS 产生影响的 cookie 同意横幅,但有时他们会这样做:这取决于实施。 在这个 Twitter 线程中有一些有趣的策略和要点。对于可能包含大量文本的选项卡组件,您可以使用 CSS 网格堆栈来防止布局变化。 通过将每个选项卡的内容放在同一个网格区域,并一次隐藏其中一个,我们可以确保容器始终采用较大元素的高度,因此不会发生布局偏移。
啊,当然,如果列表下方有内容(例如页脚),无限滚动和“加载更多”也会导致布局变化。 要改进 CLS,请在用户滚动到页面的该部分之前为将要加载的内容保留足够的空间,删除页脚或页面底部可能因内容加载而被压下的任何 DOM 元素。此外,为首屏内容预取数据和图像,这样当用户滚动到那么远时,它就已经存在了。 您也可以使用 react-window 之类的列表虚拟化库来优化长列表(感谢 Addy Osmani! )。
为确保包含回流的影响,请使用 Layout Instability API 测量布局稳定性。 有了它,您可以计算 Cumulative Layout Shift ( CLS ) 分数并将其作为测试要求包含在内,因此每当出现回归时,您都可以对其进行跟踪和修复。
为了计算布局偏移分数,浏览器查看视口大小和两个渲染帧之间的视口中不稳定元素的移动。 理想情况下,分数将接近
0。 Milica Mihajlija 和 Philip Walton 就 CLS 是什么以及如何测量它提供了一个很棒的指南。 这是衡量和维护感知性能并避免中断的良好起点,尤其是对于关键业务任务。快速提示:要了解导致 DevTools 中布局变化的原因,您可以在性能面板的“体验”下探索布局变化。
奖励:如果您想减少重排和重绘,请查看 Charis Theodoulou 的《最小化 DOM 重排/布局抖动指南》和 Paul Irish 的强制布局/重排的列表以及 CSSTriggers.com,这是一个关于触发布局、绘制的 CSS 属性的参考表和合成。
网络和 HTTP/2
- 是否启用了 OCSP 装订?
通过在您的服务器上启用 OCSP 装订,您可以加快 TLS 握手。 在线证书状态协议 (OCSP) 是作为证书撤销列表 (CRL) 协议的替代方案而创建的。 这两种协议都用于检查 SSL 证书是否已被吊销。但是,OCSP 协议不需要浏览器花时间下载然后搜索证书信息列表,因此减少了握手所需的时间。
- 您是否减少了 SSL 证书吊销的影响?
在他关于“EV 证书的性能成本”的文章中,Simon Hearne 对常见证书进行了很好的概述,以及证书的选择可能对整体性能产生的影响。正如 Simon 所写,在 HTTPS 的世界中,有几种类型的证书验证级别用于保护流量:
- 域验证(DV) 验证证书请求者是否拥有该域,
- 组织验证(OV) 验证组织是否拥有该域,
- 扩展验证(EV) 通过严格的验证来验证组织是否拥有该域。
需要注意的是,所有这些证书在技术方面都是相同的。 它们仅在这些证书中提供的信息和属性上有所不同。
EV 证书既昂贵又耗时,因为它们需要人工审核证书并确保其有效性。 另一方面,DV 证书通常是免费提供的——例如由 Let's Encrypt——一个开放的、自动化的证书颁发机构,它很好地集成到许多托管服务提供商和 CDN 中。 事实上,在撰写本文时,它为超过 2.25 亿个网站 (PDF) 提供支持,尽管它仅占页面的 2.69%(在 Firefox 中打开)。
那么有什么问题呢? 问题是EV 证书不完全支持上面提到的 OCSP 装订。 虽然装订允许服务器与证书颁发机构检查证书是否已被吊销,然后将此信息添加(“装订”)到证书中,而无需装订客户端必须完成所有工作,从而导致在 TLS 协商期间产生不必要的请求. 在连接不佳的情况下,这可能会导致显着的性能成本(1000 毫秒以上)。
EV 证书对于 Web 性能来说并不是一个很好的选择,而且它们对性能的影响要比 DV 证书大得多。 为获得最佳 Web 性能,请始终提供 OCSP 装订的 DV 证书。 它们也比 EV 证书便宜得多,而且获得的麻烦更少。 好吧,至少在 CRLite 可用之前。
压缩很重要:40-43% 的未压缩证书链太大而无法容纳 3 个 UDP 数据报的单个 QUIC 飞行。 (图片来源:)快速)(大预览) 注意:使用 QUIC/HTTP/3,值得注意的是 TLS 证书链是一个可变大小的内容,它在 QUIC 握手中支配字节数。 大小在几百字节和超过 10 KB 之间变化。
因此,在 QUIC/HTTP/3 上保持 TLS 证书很小很重要,因为大型证书会导致多次握手。 此外,我们需要确保证书被压缩,否则证书链将太大而无法容纳在单个 QUIC 飞行中。
您可以在以下位置找到更多详细信息和指向问题和解决方案的方法:
- EV 证书使 Web 变得缓慢且不可靠 作者 Aaron Peters,
- SSL 证书吊销对 Web 性能的影响 by Matt Hobbs,
- Simon Hearne 的 EV 证书的性能成本,
- QUIC 握手是否需要快速压缩? 通过帕特里克麦克马纳斯。
- 您采用 IPv6 了吗?
因为我们的 IPv4 空间已经用完,而且主要移动网络正在迅速采用 IPv6(美国几乎达到了 50% 的 IPv6 采用阈值),所以最好将您的 DNS 更新为 IPv6,以防万一。 只需确保跨网络提供双栈支持——它允许 IPv6 和 IPv4 同时运行。 毕竟,IPv6 不是向后兼容的。 此外,研究表明,由于邻居发现 (NDP) 和路由优化,IPv6 使这些网站的速度提高了 10% 到 15%。 - 确保所有资产都通过 HTTP/2(或 HTTP/3)运行。
随着谷歌在过去几年中推动更安全的 HTTPS 网络,切换到 HTTP/2 环境绝对是一项不错的投资。 事实上,根据 Web Almanac,64% 的请求已经在 HTTP/2 上运行。重要的是要了解 HTTP/2 并不完美并且存在优先级问题,但它得到了很好的支持; 而且,在大多数情况下,你会更好。
提醒一句:HTTP/2 Server Push 正在从 Chrome 中删除,因此如果您的实现依赖于 Server Push,您可能需要重新访问它。 相反,我们可能正在研究 Early Hints,它已经作为实验集成在 Fastly 中。
如果您仍然在 HTTP 上运行,最耗时的任务将是首先迁移到 HTTPS,然后调整您的构建过程以适应 HTTP/2 多路复用和并行化。 将 HTTP/2 引入 Gov.uk 是一个非常棒的案例研究,可以在此过程中通过 CORS、SRI 和 WPT 找到方法。 对于本文的其余部分,我们假设您正在切换到或已经切换到 HTTP/2。
- 正确部署 HTTP/2。
同样,通过 HTTP/2 提供资产可以受益于对迄今为止提供资产的方式进行部分改革。 您需要在打包模块和并行加载许多小模块之间找到一个很好的平衡点。 归根结底,最好的请求仍然是没有请求,但是,目标是在快速首次交付资产和缓存之间找到一个很好的平衡点。一方面,您可能希望避免完全连接资产,而不是将整个界面分解为许多小模块,将它们作为构建过程的一部分进行压缩并并行加载。 一个文件的更改不需要重新下载整个样式表或 JavaScript。 它还最大限度地减少了解析时间,并使各个页面的有效负载保持在较低水平。
另一方面,包装仍然很重要。 通过使用许多小脚本,整体压缩会受到影响,并且从缓存中检索对象的成本会增加。 大包的压缩将受益于字典重用,而单独的小包则不会。 有标准的工作来解决这个问题,但现在还很遥远。 其次,浏览器尚未针对此类工作流程进行优化。 例如,Chrome 会触发与资源数量成线性关系的进程间通信 (IPC),因此包含数百个资源将产生浏览器运行时成本。
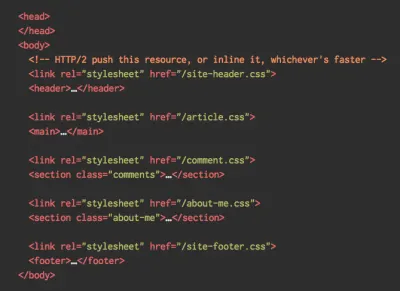
要使用 HTTP/2 获得最佳结果,请考虑逐步加载 CSS,正如 Chrome 的 Jake Archibald 所建议的那样。 不过,您可以尝试逐步加载 CSS。 事实上,in-body CSS 不再阻碍 Chrome 的渲染。 但是有一些优先级问题,所以它不是那么简单,但值得尝试。
您可以使用 HTTP/2 连接合并,它允许您在受益于 HTTP/2 的同时使用域分片,但在实践中实现这一点很困难,而且通常不被认为是好的做法。 此外,HTTP/2 和子资源完整性并不总是有效。
该怎么办? 好吧,如果你在 HTTP/2 上运行,发送大约6-10 个包似乎是一个不错的折衷方案(对于旧版浏览器来说还不错)。 试验和测量以找到适合您网站的平衡点。
- 我们是否通过单个 HTTP/2 连接发送所有资产?
HTTP/2 的主要优点之一是它允许我们通过单个连接将资产发送到线路上。 然而,有时我们可能做错了什么——例如有一个 CORS 问题,或者错误配置了crossorigin属性,所以浏览器将被迫打开一个新连接。要检查所有请求是否使用单个 HTTP/2 连接,或者是否配置错误,请启用 DevTools → Network 中的“Connection ID”列。 例如,在这里,所有请求共享相同的连接 (286) — 除了 manifest.json,它打开一个单独的连接 (451)。
- 您的服务器和 CDN 是否支持 HTTP/2?
不同的服务器和 CDN(仍然)以不同的方式支持 HTTP/2。 使用 CDN 比较来检查您的选项,或快速查看您的服务器的性能以及您期望支持的功能。请参阅 Pat Meenan 关于 HTTP/2 优先级(视频)的令人难以置信的研究,并测试服务器对 HTTP/2 优先级的支持。 根据 Pat 的说法,建议启用 BBR 拥塞控制并将
tcp_notsent_lowat设置为 16KB,以便 HTTP/2 优先级在 Linux 4.9 内核及更高版本上可靠地工作(感谢 Yoav! )。 Andy Davies 对跨浏览器、CDN 和云托管服务的 HTTP/2 优先级进行了类似的研究。使用它时,请仔细检查您的内核是否支持 TCP BBR,并在可能的情况下启用它。 它目前用于 Google Cloud Platform、Amazon Cloudfront、Linux(例如 Ubuntu)。
- 是否正在使用 HPACK 压缩?
如果您使用的是 HTTP/2,请仔细检查您的服务器是否为 HTTP 响应标头实施 HPACK 压缩,以减少不必要的开销。 一些 HTTP/2 服务器可能不完全支持该规范,HPACK 就是一个例子。 H2spec 是一个很棒的(如果技术上非常详细)工具来检查它。 HPACK 的压缩算法令人印象深刻,而且它确实有效。 - 确保服务器上的安全性是防弹的。
HTTP/2 的所有浏览器实现都通过 TLS 运行,因此您可能希望避免出现安全警告或页面上的某些元素不起作用。 仔细检查您的安全标头是否设置正确,消除已知漏洞,并检查您的 HTTPS 设置。此外,确保所有外部插件和跟踪脚本都是通过 HTTPS 加载的,跨站点脚本是不可能的,并且 HTTP 严格传输安全标头和内容安全策略标头都已正确设置。
- 您的服务器和 CDN 是否支持 HTTP/3?
虽然 HTTP/2 为 Web 带来了许多显着的性能改进,但它也留下了相当多的改进空间——尤其是 TCP 中的线头阻塞,这在具有严重数据包丢失的慢速网络上很明显。 HTTP/3 正在彻底解决这些问题(文章)。为了解决 HTTP/2 问题,IETF 与 Google、Akamai 和其他公司一起,一直在研究一种新协议,该协议最近被标准化为 HTTP/3。
Robin Marx 已经很好地解释了 HTTP/3,下面的解释是基于他的解释。 就其核心而言,HTTP/3 在功能方面与 HTTP/2 非常相似,但在底层它的工作方式却大不相同。 HTTP/3 提供了许多改进:更快的握手、更好的加密、更可靠的独立流、更好的加密和流控制。 一个显着的区别是 HTTP/3 使用 QUIC 作为传输层,QUIC 数据包封装在 UDP 图而不是 TCP 之上。
QUIC 将 TLS 1.3 完全集成到协议中,而在 TCP 中它是分层的。 在典型的 TCP 堆栈中,我们有一些往返时间的开销,因为 TCP 和 TLS 需要自己进行单独的握手,但是使用 QUIC 可以将它们组合在一起并在一次往返中完成。 由于 TLS 1.3 允许我们为后续连接设置加密密钥,从第二个连接开始,我们已经可以在第一次往返中发送和接收应用层数据,称为“0-RTT”。
此外,HTTP/2 的标头压缩算法及其优先级系统也被完全重写。 此外,QUIC 通过每个 QUIC 数据包标头中的连接 ID 支持从 Wi-Fi 到蜂窝网络的连接迁移。 大多数实现都是在用户空间完成的,而不是内核空间(就像 TCP 一样),所以我们应该期待协议在未来不断发展。
这一切都会有很大的不同吗? 可能是的,尤其是对移动设备的加载时间有影响,而且对我们如何向最终用户提供资产也有影响。 在 HTTP/2 中,多个请求共享一个连接,而在 HTTP/3 中,请求也共享一个连接但独立流式传输,因此丢弃的数据包不再影响所有请求,只会影响一个流。
这意味着,虽然使用一个大型 JavaScript 包,当一个流暂停时资产的处理速度会减慢,但当多个文件并行流 (HTTP/3) 时,影响将不那么显着。 所以包装仍然很重要。
HTTP/3 仍在进行中。 Chrome、Firefox 和 Safari 已经有了实现。 一些 CDN 已经支持 QUIC 和 HTTP/3。 2020 年底,Chrome 开始部署 HTTP/3 和 IETF QUIC,实际上所有 Google 服务(Google Analytics、YouTube 等)都已经在 HTTP/3 上运行。 LiteSpeed Web Server 支持 HTTP/3,但 Apache、nginx 或 IIS 都不支持它,但它很可能在 2021 年迅速改变。
底线:如果您可以选择在服务器和 CDN 上使用 HTTP/3,那么这样做可能是一个非常好的主意。 主要好处将来自同时获取多个对象,尤其是在高延迟连接上。 我们还不确定,因为在该领域没有太多研究,但初步结果非常有希望。
如果您想更深入地了解协议的细节和优势,这里有一些很好的起点来检查:
- HTTP/3 Explained,一个记录 HTTP/3 和 QUIC 协议的协作努力。 有多种语言版本,也有 PDF 格式。
- Daniel Stenberg 使用 HTTP/3 提升 Web 性能。
- 与 Robin Marx 合作的 QUIC 学术指南介绍了 QUIC 和 HTTP/3 协议的基本概念,解释了 HTTP/3 如何处理线头阻塞和连接迁移,以及 HTTP/3 如何被设计为常青树(感谢Simon !)。
- 您可以在 HTTP3Check.net 上检查您的服务器是否在 HTTP/3 上运行。
测试和监控
- 您是否优化了审计工作流程?
这听起来可能没什么大不了的,但是触手可及的正确设置可能会为您节省大量测试时间。 考虑使用 Tim Kadlec 的 Alfred Workflow for WebPageTest 向 WebPageTest 的公共实例提交测试。 事实上,WebPageTest 有许多晦涩难懂的功能,因此请花时间学习如何阅读 WebPageTest 瀑布视图图表以及如何阅读 WebPageTest 连接视图图表以更快地诊断和解决性能问题。您还可以从 Google 电子表格驱动 WebPageTest,并使用 Lighthouse CI 将可访问性、性能和 SEO 分数整合到您的 Travis 设置中,或者直接整合到 Webpack 中。
看看最近发布的 AutoWebPerf,这是一个模块化工具,可以自动收集来自多个来源的性能数据。 例如,我们可以在您的关键页面上设置每日测试,以捕获来自 CrUX API 的现场数据和来自 PageSpeed Insights 的 Lighthouse 报告的实验室数据。
如果你需要快速调试一些东西,但你的构建过程似乎非常慢,请记住“空白删除和符号修改占大多数 JavaScript 缩小代码大小减少的 95%——而不是复杂的代码转换。你可以只需禁用压缩即可将 Uglify 构建速度提高 3 到 4 倍。”
- 您是否在代理浏览器和旧版浏览器中进行了测试?
在 Chrome 和 Firefox 中进行测试是不够的。 查看您的网站在代理浏览器和旧版浏览器中的工作方式。 例如,UC 浏览器和 Opera Mini 在亚洲拥有重要的市场份额(在亚洲高达 35%)。 测量您感兴趣的国家/地区的平均互联网速度,以避免未来出现重大意外。 使用网络限制进行测试,并模拟高 DPI 设备。 BrowserStack 非常适合在远程真实设备上进行测试,并且还可以在您的办公室中至少使用一些真实设备来补充它——这是值得的。
- 您是否测试过 404 页面的性能?
通常,当涉及到 404 页时,我们不会三思而后行。 毕竟,当客户端请求服务器上不存在的页面时,服务器将响应 404 状态代码和相关的 404 页面。 它没有那么多,不是吗?404 响应的一个重要方面是发送到浏览器的实际响应正文大小。 根据 Matt Hobbs 对 404 页面的研究,绝大多数 404 响应来自丢失的网站图标、WordPress 上传请求、损坏的 JavaScript 请求、清单文件以及 CSS 和字体文件。 每次客户请求不存在的资产时,他们都会收到 404 响应——而且该响应通常是巨大的。
确保检查和优化 404 页面的缓存策略。 我们的目标是仅在浏览器需要 HTML 响应时才向浏览器提供 HTML,并为所有其他响应返回一个小的错误负载。 根据 Matt 的说法,“如果我们在源之前放置一个 CDN,我们就有机会在 CDN 上缓存 404 页面响应。这很有用,因为没有它,点击 404 页面可能会被用作 DoS 攻击向量,通过强制源服务器响应每个 404 请求,而不是让 CDN 以缓存版本响应。”
404 错误不仅会损害您的性能,而且还会影响流量,因此最好在您的 Lighthouse 测试套件中包含 404 错误页面,并随着时间的推移跟踪其分数。
- 您是否测试过 GDPR 同意提示的性能?
在 GDPR 和 CCPA 时代,依靠第三方为欧盟客户提供选择加入或退出跟踪的选项已变得很普遍。 但是,与任何其他第三方脚本一样,它们的性能可能会对整个性能工作产生相当大的破坏性影响。当然,实际同意可能会改变脚本对整体性能的影响,因此,正如 Boris Schapira 所指出的,我们可能想要研究一些不同的 Web 性能配置文件:
- 完全拒绝同意,
- 同意被部分拒绝,
- 完全同意。
- 用户尚未对同意提示采取行动(或提示被内容阻止程序阻止),
通常 cookie 同意提示不应该对 CLS 产生影响,但有时会产生影响,因此请考虑使用免费和开源选项 Osano 或 cookie-consent-box。
一般来说,值得研究弹出窗口的性能,因为您需要确定鼠标事件的水平或垂直偏移量,并正确定位弹出窗口相对于锚点的位置。 Noam Rosenthal 在文章 Web 性能案例研究:维基百科页面预览(也可作为视频和会议纪要)中分享了 Wikimedia 团队的学习成果。
- 您是否保留了性能诊断 CSS?
虽然我们可以包括各种检查以确保部署非性能代码,但通常快速了解一些可以轻松解决的容易实现的成果是有用的。 为此,我们可以使用 Tim Kadlec 出色的性能诊断 CSS(灵感来自 Harry Roberts 的片段,该片段突出显示延迟加载的图像、未调整大小的图像、旧格式图像和同步脚本。例如,您可能希望确保首屏上方的图像不会被延迟加载。 您可以根据需要自定义片段,例如突出显示未使用的网络字体,或检测图标字体。 一个很棒的小工具,可以确保在调试过程中可以看到错误,或者只是快速审核当前项目。
/* Performance Diagnostics CSS */ /* via Harry Roberts. https://twitter.com/csswizardry/status/1346477682544951296 */ img[loading=lazy] { outline: 10px solid red; }
- Have you tested the impact on accessibility?
When the browser starts to load a page, it builds a DOM, and if there is an assistive technology like a screen reader running, it also creates an accessibility tree. The screen reader then has to query the accessibility tree to retrieve the information and make it available to the user — sometimes by default, and sometimes on demand. And sometimes it takes time.When talking about fast Time to Interactive, usually we mean an indicator of how soon a user can interact with the page by clicking or tapping on links and buttons. The context is slightly different with screen readers. In that case, fast Time to Interactive means how much time passes by until the screen reader can announce navigation on a given page and a screen reader user can actually hit keyboard to interact.
Leonie Watson has given an eye-opening talk on accessibility performance and specifically the impact slow loading has on screen reader announcement delays. Screen readers are used to fast-paced announcements and quick navigation, and therefore might potentially be even less patient than sighted users.
Large pages and DOM manipulations with JavaScript will cause delays in screen reader announcements. A rather unexplored area that could use some attention and testing as screen readers are available on literally every platform (Jaws, NVDA, Voiceover, Narrator, Orca).
- Is continuous monitoring set up?
Having a private instance of WebPagetest is always beneficial for quick and unlimited tests. However, a continuous monitoring tool — like Sitespeed, Calibre and SpeedCurve — with automatic alerts will give you a more detailed picture of your performance. Set your own user-timing marks to measure and monitor business-specific metrics. Also, consider adding automated performance regression alerts to monitor changes over time.Look into using RUM-solutions to monitor changes in performance over time. For automated unit-test-alike load testing tools, you can use k6 with its scripting API. Also, look into SpeedTracker, Lighthouse and Calibre.
快速获胜
This list is quite comprehensive, and completing all of the optimizations might take quite a while. So, if you had just 1 hour to get significant improvements, what would you do? Let's boil it all down to 17 low-hanging fruits . Obviously, before you start and once you finish, measure results, including Largest Contentful Paint and Time To Interactive on a 3G and cable connection.
- Measure the real world experience and set appropriate goals. Aim to be at least 20% faster than your fastest competitor. Stay within Largest Contentful Paint < 2.5s, a First Input Delay < 100ms, Time to Interactive < 5s on slow 3G, for repeat visits, TTI < 2s. Optimize at least for First Contentful Paint and Time To Interactive.
- Optimize images with Squoosh, mozjpeg, guetzli, pingo and SVGOMG, and serve AVIF/WebP with an image CDN.
- Prepare critical CSS for your main templates, and inline them in the
<head>of each template. For CSS/JS, operate within a critical file size budget of max. 170KB gzipped (0.7MB decompressed). - Trim, optimize, defer and lazy-load scripts. Invest in the config of your bundler to remove redundancies and check lightweight alternatives.
- Always self-host your static assets and always prefer to self-host third-party assets. Limit the impact of third-party scripts. Use facades, load widgets on interaction and beware of anti-flicker snippets.
- Be selective when choosing a framework. For single-page-applications, identify critical pages and serve them statically, or at least prerender them, and use progressive hydration on component-level and import modules on interaction.
- Client-side rendering alone isn't a good choice for performance. Prerender if your pages don't change much, and defer the booting of frameworks if you can. If possible, use streaming server-side rendering.
- Serve legacy code only to legacy browsers with
<script type="module">and module/nomodule pattern. - Experiment with regrouping your CSS rules and test in-body CSS.
- Add resource hints to speed up delivery with faster
dns-lookup,preconnect,prefetch,preloadandprerender. - Subset web fonts and load them asynchronously, and utilize
font-displayin CSS for fast first rendering. - Check that HTTP cache headers and security headers are set properly.
- Enable Brotli compression on the server. (If that's not possible, at least make sure that Gzip compression is enabled.)
- Enable TCP BBR congestion as long as your server is running on the Linux kernel version 4.9+.
- Enable OCSP stapling and IPv6 if possible. Always serve an OCSP stapled DV certificate.
- Enable HPACK compression for HTTP/2 and move to HTTP/3 if it's available.
- Cache assets such as fonts, styles, JavaScript and images in a service worker cache.
Download The Checklist (PDF, Apple Pages)
With this checklist in mind, you should be prepared for any kind of front-end performance project. Feel free to download the print-ready PDF of the checklist as well as an editable Apple Pages document to customize the checklist for your needs:
- Download the checklist PDF (PDF, 166 KB)
- Download the checklist in Apple Pages (.pages, 275 KB)
- Download the checklist in MS Word (.docx, 151 KB)
If you need alternatives, you can also check the front-end checklist by Dan Rublic, the "Designer's Web Performance Checklist" by Jon Yablonski and the FrontendChecklist.
我们走吧!
Some of the optimizations might be beyond the scope of your work or budget or might just be overkill given the legacy code you have to deal with. That's fine! Use this checklist as a general (and hopefully comprehensive) guide, and create your own list of issues that apply to your context. But most importantly, test and measure your own projects to identify issues before optimizing. Happy performance results in 2021, everyone!
A huge thanks to Guy Podjarny, Yoav Weiss, Addy Osmani, Artem Denysov, Denys Mishunov, Ilya Pukhalski, Jeremy Wagner, Colin Bendell, Mark Zeman, Patrick Meenan, Leonardo Losoviz, Andy Davies, Rachel Andrew, Anselm Hannemann, Barry Pollard, Patrick Hamann, Gideon Pyzer, Andy Davies, Maria Prosvernina, Tim Kadlec, Rey Bango, Matthias Ott, Peter Bowyer, Phil Walton, Mariana Peralta, Pepijn Senders, Mark Nottingham, Jean Pierre Vincent, Philipp Tellis, Ryan Townsend, Ingrid Bergman, Mohamed Hussain SH, Jacob Groß, Tim Swalling, Bob Visser, Kev Adamson, Adir Amsalem, Aleksey Kulikov and Rodney Rehm for reviewing this article, as well as our fantastic community which has shared techniques and lessons learned from its work in performance optimization for everybody to use. 你真的很牛逼!