
机器学习中的假新闻检测[用编码示例解释]
已发表: 2021-02-08假新闻是当前互联网和社交媒体时代的最大问题之一。 虽然新闻在几个小时内从世界的一个角落传到另一个角落是一件幸事,但看到许多人和团体散布假新闻也很痛苦。
使用自然语言处理和深度学习的机器学习技术可以在一定程度上解决这个问题。 在本教程中,我们将使用机器学习构建一个假新闻检测模型。
在本文结束时,您将了解以下内容:
- 处理文本数据
- NLP处理技术
- 计数向量化和 TF-IDF
- 进行预测和分类新闻文本
加入来自世界顶级大学的AI 和 ML在线课程 - 硕士、高级管理人员研究生课程和 ML 和 AI 高级证书课程,以加快您的职业生涯。
目录
数据与问题
我们将使用 Kaggle 假新闻挑战数据来制作分类器。 数据集由 4 个特征和 1 个二进制目标组成。 4个特点如下:
- id :新闻文章的唯一 ID
- title :新闻文章的标题
- author : 新闻文章的作者
- text :文章的正文; 可能不完整
目标是包含二进制值 0 和 1 的“标签”。 其中 0 表示它是可靠的新闻来源,或者换句话说,Not Fake。 1 表示它是一条潜在的假新闻并且不可靠。 我们的数据集由 20800 个实例组成。 让我们潜入水中。

数据预处理和清洗
| 将熊猫导入为pd df=pd.read_csv( 'fake-news/train.csv' ) df.head() |
| X=df.drop( 'label' ,axis= 1 ) # 特征 y=df[ 'label' ] # 目标 |
我们现在需要删除缺少数据的实例。
| df=df.dropna() |
![]()
正如我们所看到的,它删除了所有缺少数据的实例。
| 消息=df.copy() messages.reset_index(就地=真) 消息头( 10 ) |
让我们看一次数据。
| 消息['文本'][6] |

如我们所见,需要执行以下步骤:
- 删除停用词:无论数据如何,有很多词对任何文本都没有任何价值。 例如,“I”、“a”、“am”等。这些词没有信息价值,因此可以删除以减少我们的语料库的大小,这样我们就可以只关注具有实际价值的词/标记.
- 词干提取:词干提取和词形还原是将词还原为词干或词根的技术。 这一步的主要优点是减少了词汇量。 例如,Play、Playing、Played 等词将简化为“Play”。 词干只是将单词截断为最短的单词,而不考虑文本的语法方面。 另一方面,词形还原也考虑了语法,因此产生了更好的结果。 然而,词根化通常比词干化要慢,因为它需要参考字典并考虑语法方面。
- 删除除字母值之外的所有内容:非字母值在这里没有多大用处,因此可以删除它们。 但是,您可以进一步探索以查看数字或其他类型数据的存在是否对目标有任何影响。
- 小写单词:小写单词以减少词汇量。
- 标记句子:从句子生成标记。
| 从 sklearn.feature_extraction.text 导入 CountVectorizer、TfidfVectorizer、HashingVectorizer 从 nltk.corpus 导入停用词 从 nltk.stem.porter 导入 PorterStemmer 重新进口 ps = PorterStemmer() corpus = [] for i in range(0, len(messages)): review = re.sub('[^a-zA-Z]', ' ', messages['text'][i]) 评论 = 评论.lower() 评论 = 评论.split() review = [ps.stem(word) for the word in review if not in stopwords.words('english')] review = ' '.join(review) corpus.append(评论) |
现在让我们看看我们的语料库。
| 语料库[ 3 ] |
![]()
正如我们所看到的,这些词现在被提取为词根。
TF-IDF 矢量化器
现在我们需要将单词向量化为数字数据,这也称为向量化。 最简单的矢量化方法是使用词袋。 但是词袋创建了一个稀疏矩阵,因此需要大量的处理内存。 此外,BoW 没有考虑词的频率,这使其成为一种糟糕的算法。
TF-IDF(词频 - 逆文档频率)是另一种考虑词频的词向量化方法。 例如,“我们”、“我们的”、“该”等常用词出现在每个文档/实例中,因此 BoW 值会太高,从而产生误导。 这将导致一个糟糕的模型。 TF-IDF 是词频和逆文档频率的乘积。
词频考虑了文档中单词的频率,而逆文档频率考虑了整个语料库中出现的单词。 出现在整个语料库中的单词的重要性降低了,因为 IDF 值要低得多。 特定出现在一个文档中的单词具有较高的 IDF 值,这使得总 TF-IDF 值很高。
| ## TFi df 矢量化器 从sklearn.feature_extraction.text导入TfidfVectorizer tfidf_v = TfidfVectorizer(max_features= 5000 ,ngram_range=( 1 , 3 )) X=tfidf_v.fit_transform(corpus).toarray() y=messages[ 'label' ] |
在上面的代码中,我们从 Sklearn 的特征提取模块中导入了 TF-IDF Vectorizer。 我们通过将 max_features 作为 5000 并将 ngram_range 作为 (1,3) 来制作它的对象。 参数 max_features 定义了我们想要创建的特征向量的最大数量,而 ngram_range 参数定义了我们想要包含的 ngram 组合。 在我们的例子中,我们将得到 1 个单词、2 个单词和 3 个单词的 3 种组合。 让我们看一下创建的一些功能。
| tfidf_v.get_feature_names()[: 20 ] |


正如我们所看到的,形成了多种类型的组合。 有 1 个标记、2 个标记和 3 个标记的特征名称。
制作数据框
| ##将数据集分为训练和测试 从sklearn.model_selection导入train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.33 , random_state= 0 ) count_df = pd.DataFrame(X_train, columns=tfidf_v.get_feature_names()) count_df.head() |
我们将数据集拆分为训练和测试,以便我们可以测试模型在未见数据上的性能。 然后我们创建一个新的 Dataframe,其中包含新的特征向量。
建模与调优
多项式NB算法
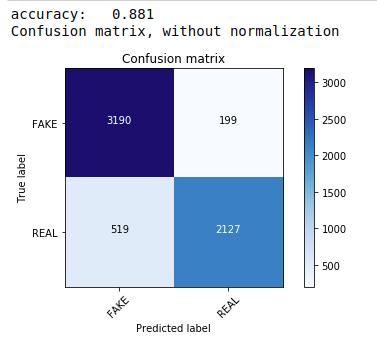
首先,我们使用多项朴素贝叶斯定理,这是文本数据分类中最常用和最简单的算法。 我们拟合训练数据并预测测试数据。 后来我们计算并绘制了混淆矩阵,得到了 88.1% 的准确率。
| 从sklearn.naive_bayes导入MultinomialNB 从sklearn导入指标 将numpy导入为np 导入迭代工具 从sklearn.metrics导入plot_confusion_matrix 分类器=多项式NB() 分类器.fit(X_train, y_train) pred = classifier.predict(X_test) score = metrics.accuracy_score(y_test, pred) 打印( “准确度:%0.3f” % 分数) cm = metrics.confusion_matrix(y_test, pred) plot_confusion_matrix(cm,classes=[ 'FAKE' , 'REAL' ]) |
具有超参数调整的多项分类器
MultinomialNB 有一个可以进一步调整的参数 alpha。 因此,我们运行一个循环来尝试多个具有不同 alpha 值的 MultinomialNB 分类器并检查它们的准确度分数。 我们检查当前分数是否高于之前的分数。 如果是,那么我们将分类器设置为当前分类器。
| 以前的分数= 0 对于np.arange( 0 , 1 , 0.1 )中的alpha : sub_classifier=多项式NB(alpha=alpha) sub_classifier.fit(X_train,y_train) y_pred=sub_classifier.predict(X_test) score = metrics.accuracy_score(y_test, y_pred) 如果分数>previous_score: 分类器=子分类器 打印( “阿尔法:{},分数:{}” .format(阿尔法,分数)) |
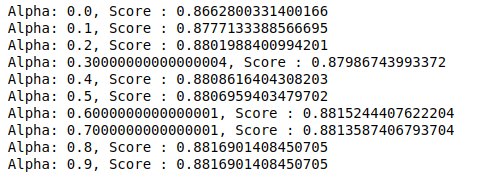
因此,我们可以看到 0.9 或 0.8 的 alpha 值给出了最高的准确度分数。
解释结果
现在让我们看看这些分类器系数值的含义。 我们首先将所有特征名称保存在另一个变量中。
| ## G et F特征名称 feature_names = cv.get_feature_names() |
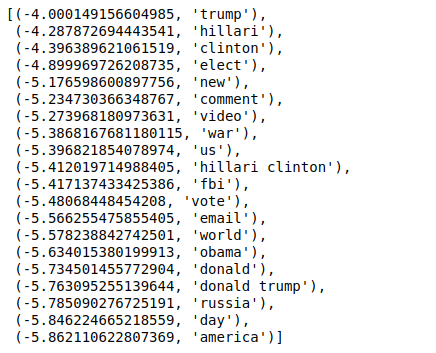
现在,当我们以相反的顺序对值进行排序时,我们得到最小值为 -4 的值。 这些表示最真实或最不假的词。
| ###最真实 排序(zip(分类器.coef_ [ 0 ],特征名称),反向=真)[: 20 ] |
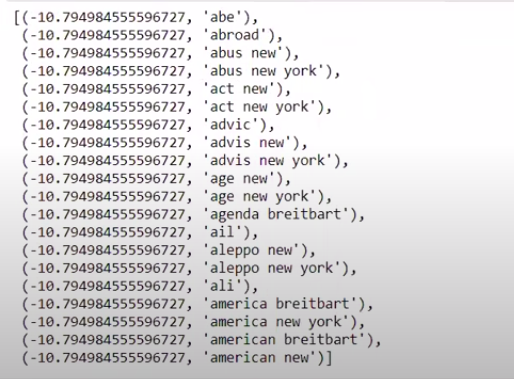
当我们以非逆序对值进行排序时,我们得到最小值为 -10 的值。 这些表示最不真实或最虚假的词。
| ###最真实 排序(zip(classifier.coef_[ 0 ],feature_names))[: 20 ] |
结论
在本教程中,我们仅使用了 ML 算法,但您也使用了其他神经网络方法。 此外,为了对文本数据进行矢量化,我们使用了 TF-IDF 矢量化器。 还有更多的矢量化器,如 Count Vectorizer、Hashing Vectorizer 等,它们可以更好地完成这项工作。 尝试并尝试其他算法和技术,看看是否可以产生更好的结果。
如果您有兴趣了解有关机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和 AI 执行 PG 计划,该计划专为工作专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和作业、IIIT -B 校友身份,5 个以上实用的实践顶点项目和顶级公司的工作协助。
为什么需要检测假新闻?
在目前的情况下,社交媒体平台非常强大和有价值,因为它们允许用户讨论和交流想法以及辩论民主、教育和健康等主题。 然而,某些实体严重利用此类平台,在某些情况下获取金钱利益,并产生偏见观点、改变思维方式以及在其他情况下传播讽刺或荒谬。 假新闻是这种现象的术语。 不符合现实的在线发布项目的激增导致了政治、体育、健康、科学和其他领域的一系列问题。
哪些公司主要使用假新闻检测?
假新闻检测用于社交媒体和新闻网站等平台。 Facebook、Instagram 和 Twitter 等社交媒体巨头很容易受到假新闻的影响,因为大多数用户都依赖它们作为日常新闻来源来获取最新信息。 媒体公司也使用虚假检测技术来确定他们所拥有信息的真实性。 电子邮件是个人可以接收新闻的另一种媒介,因此很难识别和验证其真实性。 恶作剧、垃圾邮件和垃圾邮件以通过电子邮件传输而闻名。 因此,大多数电子邮件平台采用虚假新闻检测来识别垃圾邮件和垃圾邮件。