
开始使用 Express 和 ES6+ JavaScript 堆栈
已发表: 2022-03-10本文是系列文章的第二部分,第一部分位于此处,它提供了对 Node.js、ES6+ JavaScript、回调函数、箭头函数、API、HTTP 协议、JSON、MongoDB 和更多的。
在本文中,我们将在前一篇文章中获得的技能的基础上,学习如何实现和部署 MongoDB 数据库以存储用户书单信息,使用 Node.js 和 Express Web 应用程序框架构建 API 以公开该数据库并对其执行 CRUD 操作等。 在此过程中,我们将讨论 ES6 对象解构、ES6 对象简写、Async/Await 语法、扩展运算符,我们将简要介绍 CORS、同源策略等。
在后面的文章中,我们将重构我们的代码库,通过利用三层架构和通过依赖注入实现控制反转来分离关注点,我们将执行基于 JSON Web Token 和 Firebase 身份验证的安全性和访问控制,学习如何安全地存储密码,并使用 AWS Simple Storage Service 使用 Node.js 缓冲区和流存储用户头像 — 同时使用 PostgreSQL 进行数据持久性。 在此过程中,我们将在 TypeScript 中从头开始重写我们的代码库,以检查经典的 OOP 概念(例如多态、继承、组合等),甚至像工厂和适配器这样的设计模式。
一个警告
今天大多数讨论 Node.js 的文章都存在问题。 他们中的大多数,而不是全部,只是描述了如何设置快速路由、集成 Mongoose 以及可能利用 JSON Web 令牌身份验证。 问题是他们不谈论架构,或安全最佳实践,或干净的编码原则,或 ACID 合规性、关系数据库、第五范式、CAP 定理或事务。 要么假设你知道所有这些进来,要么你不会构建足够大或受欢迎的项目来保证上述知识。
似乎有几种不同类型的 Node 开发人员——其中一些是一般编程的新手,而另一些则来自使用 C# 和 .NET Framework 或 Java Spring Framework 进行企业开发的悠久历史。 大多数文章迎合前一组。
在本文中,我将完全按照我刚才所说的那样做,但在后续文章中,我们将完全重构我们的代码库,允许我解释诸如依赖注入、三-层架构(控制器/服务/存储库)、数据映射和活动记录、设计模式、单元、集成和变异测试、SOLID 原则、工作单元、针对接口的编码、HSTS、CSRF、NoSQL 和 SQL 注入等安全最佳实践预防等等。 我们还将使用简单的查询构建器 Knex 而不是 ORM 从 MongoDB 迁移到 PostgreSQL——允许我们构建自己的数据访问基础设施,并近距离接触结构化查询语言,以及不同类型的关系(One-一对一、多对多等)等等。 那么,这篇文章应该会吸引初学者,但接下来的几篇应该会迎合更多希望改进其架构的中级开发人员。
在这一节中,我们只需要担心持久化书籍数据。 我们不会处理用户身份验证、密码散列、架构或任何类似的复杂事物。 所有这些都将出现在下一篇和未来的文章中。 现在,基本上,我们将构建一种方法,允许客户端通过 HTTP 协议与我们的 Web 服务器通信,以便将书籍信息保存在数据库中。
注意:我故意让它变得非常简单,也许在这里并不那么实用,因为这篇文章本身非常长,因为我冒昧地偏离讨论补充主题。 因此,我们将在本系列中逐步提高 API 的质量和复杂性,但同样,因为我认为这是您对 Express 的第一次介绍,所以我有意让事情变得非常简单。
- ES6 对象解构
- ES6 对象速记
- ES6 扩展运算符 (...)
- 接下来...
ES6 对象解构
ES6 对象解构或解构赋值语法是一种从数组或对象中提取或解压缩值到它们自己的变量中的方法。 我们将从对象属性开始,然后讨论数组元素。
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; // Log properties: console.log('Name:', person.name); console.log('Occupation:', person.occupation); 这样的操作非常原始,但考虑到我们必须在任何地方继续引用person.something ,它可能有点麻烦。 假设在我们的代码中还有 10 个其他地方我们必须这样做——很快就会变得相当艰巨。 一种简洁的方法是将这些值分配给它们自己的变量。
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; const personName = person.name; const personOccupation = person.occupation; // Log properties: console.log('Name:', personName); console.log('Occupation:', personOccupation); 也许这看起来很合理,但是如果我们在person对象上也嵌套了 10 个其他属性呢? 这将是许多不必要的行,只是为了给变量赋值——此时我们处于危险之中,因为如果对象属性发生了变异,我们的变量将不会反映这种变化(请记住,只有对对象的引用是通过const赋值不可变的,不是对象的属性),所以基本上,我们不能再保持“状态”(我用的是松散的词)同步。 按引用传递与按值传递可能会在这里发挥作用,但我不想偏离本节的范围太远。
ES6 Object Destructing 基本上让我们这样做:
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; // This is new. It's called Object Destructuring. const { name, occupation } = person; // Log properties: console.log('Name:', name); console.log('Occupation:', occupation); 我们不是在创建新的对象/对象字面量,而是从原始对象中解压缩name和occupation属性,并将它们放入它们自己的同名变量中。 我们使用的名称必须与我们希望提取的属性名称相匹配。
同样,语法const { a, b } = someObject; 特别是说我们希望某些属性a和某些属性b存在于someObject中(例如, someObject可能是{ a: 'dataA', b: 'dataB' } )并且我们希望放置任何值这些键/属性在同名的const变量中。 这就是为什么上面的语法会为我们提供两个变量const a = someObject.a和const b = someObject.b 。
这意味着对象解构有两个方面。 “模板”端和“源”端,其中const { a, b }端(左侧)是模板,而someObject端(右侧)是源端——这是有道理的— 我们在左侧定义了一个结构或“模板”,以反映“源”端的数据。
同样,为了清楚起见,这里有几个例子:
// ----- Destructure from Object Variable with const ----- // const objOne = { a: 'dataA', b: 'dataB' }; // Destructure const { a, b } = objOne; console.log(a); // dataA console.log(b); // dataB // ----- Destructure from Object Variable with let ----- // let objTwo = { c: 'dataC', d: 'dataD' }; // Destructure let { c, d } = objTwo; console.log(c); // dataC console.log(d); // dataD // Destructure from Object Literal with const ----- // const { e, f } = { e: 'dataE', f: 'dataF' }; // <-- Destructure console.log(e); // dataE console.log(f); // dataF // Destructure from Object Literal with let ----- // let { g, h } = { g: 'dataG', h: 'dataH' }; // <-- Destructure console.log(g); // dataG console.log(h); // dataH在嵌套属性的情况下,在破坏赋值中镜像相同的结构:
const person = { name: 'Richard P. Feynman', occupation: { type: 'Theoretical Physicist', location: { lat: 1, lng: 2 } } }; // Attempt one: const { name, occupation } = person; console.log(name); // Richard P. Feynman console.log(occupation); // The entire `occupation` object. // Attempt two: const { occupation: { type, location } } = person; console.log(type); // Theoretical Physicist console.log(location) // The entire `location` object. // Attempt three: const { occupation: { location: { lat, lng } } } = person; console.log(lat); // 1 console.log(lng); // 2如您所见,您决定提取的属性是可选的,要解压缩嵌套属性,只需在解构语法的模板端镜像原始对象(源)的结构。 如果您尝试解构原始对象上不存在的属性,则该值将是未定义的。
我们还可以在不首先声明变量的情况下解构一个变量——不声明的赋值——使用以下语法:
let name, occupation; const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; ;({ name, occupation } = person); console.log(name); // Richard P. Feynman console.log(occupation); // Theoretical Physicist我们在表达式前面加上一个分号,以确保我们不会意外地在前一行创建一个带有函数的 IIFE(立即调用函数表达式)(如果存在这样的函数),并且赋值语句周围的括号是必需的阻止 JavaScript 将您的左侧(模板)视为一个块。
函数参数中存在一个非常常见的解构用例:
const config = { baseUrl: '<baseURL>', awsBucket: '<bucket>', secret: '<secret-key>' // <- Make this an env var. }; // Destructures `baseUrl` and `awsBucket` off `config`. const performOperation = ({ baseUrl, awsBucket }) => { fetch(baseUrl).then(() => console.log('Done')); console.log(awsBucket); // <bucket> }; performOperation(config);如您所见,我们可以在函数内部使用我们现在习惯的正常解构语法,如下所示:
const config = { baseUrl: '<baseURL>', awsBucket: '<bucket>', secret: '<secret-key>' // <- Make this an env var. }; const performOperation = someConfig => { const { baseUrl, awsBucket } = someConfig; fetch(baseUrl).then(() => console.log('Done')); console.log(awsBucket); // <bucket> }; performOperation(config);但是将所述语法放在函数签名中会自动执行解构并为我们节省一行。
一个真实的用例是在 React Functional Components for props中:
import React from 'react'; // Destructure `titleText` and `secondaryText` from `props`. export default ({ titleText, secondaryText }) => ( <div> <h1>{titleText}</h1> <h3>{secondaryText}</h3> </div> );相对于:
import React from 'react'; export default props => ( <div> <h1>{props.titleText}</h1> <h3>{props.secondaryText}</h3> </div> );在这两种情况下,我们也可以为属性设置默认值:
const personOne = { name: 'User One', password: 'BCrypt Hash' }; const personTwo = { password: 'BCrypt Hash' }; const createUser = ({ name = 'Anonymous', password }) => { if (!password) throw new Error('InvalidArgumentException'); console.log(name); console.log(password); return { id: Math.random().toString(36) // <--- Should follow RFC 4122 Spec in real app. .substring(2, 15) + Math.random() .toString(36).substring(2, 15), name: name, // <-- We'll discuss this next. password: password // <-- We'll discuss this next. }; } createUser(personOne); // User One, BCrypt Hash createUser(personTwo); // Anonymous, BCrypt Hash 如您所见,如果name在解构时不存在,我们会为其提供默认值。 我们也可以使用前面的语法来做到这一点:
const { a, b, c = 'Default' } = { a: 'dataA', b: 'dataB' }; console.log(a); // dataA console.log(b); // dataB console.log(c); // Default数组也可以被解构:
const myArr = [4, 3]; // Destructuring happens here. const [valOne, valTwo] = myArr; console.log(valOne); // 4 console.log(valTwo); // 3 // ----- Destructuring without assignment: ----- // let a, b; // Destructuring happens here. ;([a, b] = [10, 2]); console.log(a + b); // 12数组解构的一个实际原因是 React Hooks。 (还有很多其他原因,我只是以 React 为例)。
import React, { useState } from "react"; export default () => { const [buttonText, setButtonText] = useState("Default"); return ( <button onClick={() => setButtonText("Toggled")}> {buttonText} </button> ); } 注意useState正在从导出中解构,并且数组函数/值正在从useState挂钩中解构。 同样,如果以上内容没有意义,请不要担心——你必须了解 React——我只是将其用作示例。
虽然 ES6 对象解构还有更多内容,但我将在这里再讨论一个主题:解构重命名,这对于防止范围冲突或变量阴影等很有用。假设我们想从一个名为person的对象中解构一个名为name的属性,但是范围内已经有一个名为name的变量。 我们可以用冒号即时重命名:
// JS Destructuring Naming Collision Example: const name = 'Jamie Corkhill'; const person = { name: 'Alan Turing' }; // Rename `name` from `person` to `personName` after destructuring. const { name: personName } = person; console.log(name); // Jamie Corkhill <-- As expected. console.log(personName); // Alan Turing <-- Variable was renamed.最后,我们也可以通过重命名来设置默认值:
const name = 'Jamie Corkhill'; const person = { location: 'New York City, United States' }; const { name: personName = 'Anonymous', location } = person; console.log(name); // Jamie Corkhill console.log(personName); // Anonymous console.log(location); // New York City, United States 如您所见,在这种情况下,来自person ( person.name ) 的name将重命名为personName ,如果不存在则设置为Anonymous的默认值。
当然,同样可以在函数签名中执行:
const personOne = { name: 'User One', password: 'BCrypt Hash' }; const personTwo = { password: 'BCrypt Hash' }; const createUser = ({ name: personName = 'Anonymous', password }) => { if (!password) throw new Error('InvalidArgumentException'); console.log(personName); console.log(password); return { id: Math.random().toString(36).substring(2, 15) + Math.random().toString(36).substring(2, 15), name: personName, password: password // <-- We'll discuss this next. }; } createUser(personOne); // User One, BCrypt Hash createUser(personTwo); // Anonymous, BCrypt HashES6 对象速记
假设您有以下工厂:(我们稍后会介绍工厂)
const createPersonFactory = (name, location, position) => ({ name: name, location: location, position: position }); 可以使用这个工厂来创建一个person对象,如下所示。 另外,请注意,工厂隐式返回一个对象,箭头函数括号周围的括号很明显。
const person = createPersonFactory('Jamie', 'Texas', 'Developer'); console.log(person); // { ... } 这就是我们从 ES5 Object Literal Syntax 中已经知道的。 但是请注意,在工厂函数中,每个属性的值与属性标识符(键)本身同名。 即 — location: location或name: name 。 事实证明,这在 JS 开发人员中很常见。
使用 ES6 的简写语法,我们可以通过如下方式重写工厂来获得相同的结果:
const createPersonFactory = (name, location, position) => ({ name, location, position }); const person = createPersonFactory('Jamie', 'Texas', 'Developer'); console.log(person);产生输出:
{ name: 'Jamie', location: 'Texas', position: 'Developer' }重要的是要意识到,当我们希望创建的对象是基于变量动态创建时,我们只能使用这种简写,其中变量名称与我们希望分配变量的属性的名称相同。
同样的语法适用于对象值:
const createPersonFactory = (name, location, position, extra) => ({ name, location, position, extra // <- right here. }); const extra = { interests: [ 'Mathematics', 'Quantum Mechanics', 'Spacecraft Launch Systems' ], favoriteLanguages: [ 'JavaScript', 'C#' ] }; const person = createPersonFactory('Jamie', 'Texas', 'Developer', extra); console.log(person);产生输出:
{ name: 'Jamie', location: 'Texas', position: 'Developer', extra: { interests: [ 'Mathematics', 'Quantum Mechanics', 'Spacecraft Launch Systems' ], favoriteLanguages: [ 'JavaScript', 'C#' ] } }作为最后一个示例,这也适用于对象文字:
const id = '314159265358979'; const name = 'Archimedes of Syracuse'; const location = 'Syracuse'; const greatMathematician = { id, name, location };ES6 扩展运算符 (…)
扩展运算符允许我们做各种各样的事情,我们将在这里讨论其中的一些。
首先,我们可以将属性从一个对象分散到另一个对象:
const myObjOne = { a: 'a', b: 'b' }; const myObjTwo = { ...myObjOne }: 这具有将 myObjOne 上的所有属性放到myObjOne上的myObjTwo ,这样myObjTwo现在是{ a: 'a', b: 'b' } 。 我们可以使用此方法覆盖以前的属性。 假设用户想要更新他们的帐户:
const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */
可以对数组执行相同的操作:
const apollo13Astronauts = ['Jim', 'Jack', 'Fred']; const apollo11Astronauts = ['Neil', 'Buz', 'Michael']; const unionOfAstronauts = [...apollo13Astronauts, ...apollo11Astronauts]; console.log(unionOfAstronauts); // ['Jim', 'Jack', 'Fred', 'Neil', 'Buz, 'Michael'];请注意,我们通过将数组分散到一个新数组中来创建两个集合(数组)的并集。
Rest/Spread 运算符还有很多其他内容,但超出了本文的范围。 例如,它可用于获得函数的多个参数。 如果您想了解更多信息,请在此处查看 MDN 文档。
ES6 异步/等待
Async/Await 是一种用于减轻 Promise 链接痛苦的语法。
await保留关键字允许您“等待”promise 的结算,但它只能用于标有async关键字的函数中。 假设我有一个返回承诺的函数。 在一个新的async函数中,我可以await该承诺的结果,而不是使用.then和.catch 。
// Returns a promise. const myFunctionThatReturnsAPromise = () => { return new Promise((resolve, reject) => { setTimeout(() => resolve('Hello'), 3000); }); } const myAsyncFunction = async () => { const promiseResolutionResult = await myFunctionThatReturnsAPromise(); console.log(promiseResolutionResult); }; // Writes the log statement after three seconds. myAsyncFunction(); 这里有几点需要注意。 当我们在async函数中使用await时,只有解析的值进入左侧的变量。 如果函数拒绝,那是我们必须捕获的错误,稍后我们会看到。 此外,默认情况下,任何标记为async的函数都将返回一个 Promise。
假设我需要进行两次 API 调用,一次调用来自前者的响应。 使用 Promise 和 Promise 链,你可以这样做:
const makeAPICall = route => new Promise((resolve, reject) => { console.log(route) resolve(route); }); const main = () => { makeAPICall('/whatever') .then(response => makeAPICall(response + ' second call')) .then(response => console.log(response + ' logged')) .catch(err => console.error(err)) }; main(); // Result: /* /whatever /whatever second call /whatever second call logged */ 这里发生的是我们首先调用makeAPICall传递给它/whatever ,它第一次被记录。 承诺以该值解决。 然后我们再次调用makeAPICall ,将/whatever second call传递给它,它会被记录下来,再次,promise 会用那个新值解析。 最后,我们将新值/whatever second call与 promise 解决,并将其自己logged在最终日志中,并在最后附加 log。 如果这没有意义,您应该研究 Promise 链接。
使用async / await ,我们可以重构如下:
const main = async () => { const resultOne = await makeAPICall('/whatever'); const resultTwo = await makeAPICall(resultOne + ' second call'); console.log(resultTwo + ' logged'); }; 这是将会发生的事情。 整个函数将在第一个await语句处停止执行,直到第一次调用makeAPICall的 Promise 解析完成,解析后,解析的值将放置在resultOne中。 发生这种情况时,该函数将移动到第二个await语句,在 Promise 结算期间再次暂停。 当 Promise 解析时,解析结果将放在resultTwo中。 如果关于函数执行的想法听起来是阻塞的,不要害怕,它仍然是异步的,我将在一分钟内讨论原因。
这只描绘了“幸福”的道路。 如果其中一个 Promise 被拒绝,我们可以使用 try/catch 来捕获它,因为如果 Promise 被拒绝,就会抛出一个错误——这将是 Promise 被拒绝的任何错误。
const main = async () => { try { const resultOne = await makeAPICall('/whatever'); const resultTwo = await makeAPICall(resultOne + ' second call'); console.log(resultTwo + ' logged'); } catch (e) { console.log(e) } }; 正如我之前所说,任何声明为async的函数都会返回一个 Promise。 因此,如果你想从另一个函数调用异步函数,你可以使用普通的 Promise,或者如果你声明调用函数async则await 。 但是,如果您想从顶级代码调用async函数并等待其结果,那么您必须使用.then和.catch 。
例如:
const returnNumberOne = async () => 1; returnNumberOne().then(value => console.log(value)); // 1或者,您可以使用立即调用函数表达式 (IIFE):
(async () => { const value = await returnNumberOne(); console.log(value); // 1 })(); 当您在async函数中使用await时,函数的执行将在该 await 语句处停止,直到 promise 完成。 但是,所有其他函数都可以自由执行,因此不会分配额外的 CPU 资源,也不会阻塞线程。 我再说一遍——那个特定时间的特定函数中的操作将停止,直到承诺解决,但所有其他函数都可以自由触发。 考虑一个 HTTP Web 服务器——在每个请求的基础上,所有函数都可以在发出请求时同时为所有用户自由触发,只是 async/await 语法会提供一个操作是同步和阻塞的错觉。承诺更容易使用,但同样,一切都将保持良好和异步。
这不是async / await的全部内容,但它应该可以帮助您掌握基本原则。
经典的 OOP 工厂
我们现在要离开JavaScript世界,进入Java世界。 有时,对象的创建过程(在这种情况下,是一个类的实例——同样是 Java)相当复杂,或者我们希望根据一系列参数生成不同的对象。 一个示例可能是创建不同错误对象的函数。 工厂是面向对象编程中的一种常见设计模式,基本上是一个创建对象的函数。 为了探索这一点,让我们从 JavaScript 转移到 Java 世界。 这对于来自经典 OOP(即非原型)、静态类型语言背景的开发人员来说是有意义的。 如果您不是这样的开发人员,请随意跳过本节。 这是一个小的偏差,因此如果按照此处操作会中断您的 JavaScript 流程,那么请再次跳过本节。
一种常见的创建模式,工厂模式允许我们创建对象而不暴露执行所述创建所需的业务逻辑。
假设我们正在编写一个程序,允许我们在 n 维中可视化原始形状。 例如,如果我们提供一个立方体,我们会看到一个 2D 立方体(正方形)、一个 3D 立方体(一个立方体)和一个 4D 立方体(一个 Tesseract,或 Hypercube)。 以下是在 Java 中可以做到这一点的简单方法,并且除了实际的绘图部分之外。
// Main.java // Defining an interface for the shape (can be used as a base type) interface IShape { void draw(); } // Implementing the interface for 2-dimensions: class TwoDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 2D."); } } // Implementing the interface for 3-dimensions: class ThreeDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 3D."); } } // Implementing the interface for 4-dimensions: class FourDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 4D."); } } // Handles object creation class ShapeFactory { // Factory method (notice return type is the base interface) public IShape createShape(int dimensions) { switch(dimensions) { case 2: return new TwoDimensions(); case 3: return new ThreeDimensions(); case 4: return new FourDimensions(); default: throw new IllegalArgumentException("Invalid dimension."); } } } // Main class and entry point. public class Main { public static void main(String[] args) throws Exception { ShapeFactory shapeFactory = new ShapeFactory(); IShape fourDimensions = shapeFactory.createShape(4); fourDimensions.draw(); // Drawing a shape in 4D. } } 如您所见,我们定义了一个接口,该接口指定了绘制形状的方法。 通过让不同的类实现接口,我们可以保证可以绘制所有形状(因为它们都必须具有根据接口定义的可覆盖的draw方法)。 考虑到这个形状的绘制取决于它被查看的维度,我们定义了实现接口的帮助类,以执行模拟 n 维渲染的 GPU 密集型工作。 ShapeFactory负责实例化正确的类createShape方法是一个工厂,和上面的定义一样,它是一个返回类对象的方法。 IShape的返回类型是createShape接口,因为IShape接口是所有形状的基本类型(因为它们具有draw方法)。
这个 Java 示例相当简单,但您可以很容易地看到它在创建对象的设置可能不那么简单的大型应用程序中变得多么有用。 这方面的一个例子是视频游戏。 假设用户必须在不同的敌人中生存。 抽象类和接口可用于定义可供所有敌人使用的核心功能(以及可以被覆盖的方法),可能使用委托模式(正如四人组所建议的那样,优先组合而不是继承,这样您就不会陷入扩展单个基类并使测试/模拟/DI更容易)。 对于以不同方式实例化的敌人对象,该接口将允许创建工厂对象,同时依赖于通用接口类型。 如果敌人是动态创建的,这将非常重要。
另一个例子是构建器函数。 假设我们利用委托模式让一个类将工作委托给其他尊重接口的类。 我们可以在类上放置一个静态build方法,让它构建自己的实例(假设您没有使用依赖注入容器/框架)。 不必调用每个 setter,您可以这样做:
public class User { private IMessagingService msgService; private String name; private int age; public User(String name, int age, IMessagingService msgService) { this.name = name; this.age = age; this.msgService = msgService; } public static User build(String name, int age) { return new User(name, age, new SomeMessageService()); } } 如果您不熟悉委托模式,我将在后面的文章中解释它——基本上,通过组合和对象建模,它创建了一个“has-a”关系而不是“is-a”与继承的关系。 如果你有一个Mammal类和一个Dog类,并且Dog扩展Mammal ,那么Dog is-a Mammal 。 然而,如果你有一个Bark类,并且你只是将Bark的实例传递给Dog的构造函数,那么Dog就有一个Bark 。 正如您可能想象的那样,这尤其使单元测试更容易,因为您可以注入模拟并断言有关模拟的事实,只要模拟在测试环境中遵守接口契约。
上面的static “构建”工厂方法只是创建了一个新的User对象并传入一个具体的MessageService 。注意这是如何从上面的定义中得出的——没有暴露业务逻辑来创建一个类的对象,或者,在这种情况下,不将消息服务的创建暴露给工厂的调用者。
同样,这不一定是您在现实世界中做事的方式,但它很好地展示了工厂函数/方法的想法。 例如,我们可能会改用依赖注入容器。 现在回到 JavaScript。
从快递开始
Express 是一个用于 Node 的 Web 应用程序框架(可通过 NPM 模块获得),它允许创建 HTTP Web 服务器。 需要注意的是,Express 并不是唯一可以做到这一点的框架(还有 Koa、Fastify 等),并且如上一篇文章中所见,Node 可以在没有 Express 的情况下作为独立实体运行。 (Express 只是为 Node 设计的一个模块——Node 可以在没有它的情况下做很多事情,尽管 Express 在 Web 服务器中很流行)。
再次,让我做一个非常重要的区分。 Node/JavaScript 和 Express 之间存在二分法。 Node,你运行 JavaScript 的运行时/环境,可以做很多事情——比如允许你构建 React Native 应用程序、桌面应用程序、命令行工具等。 Express 只是一个轻量级框架,允许你使用Node/JS 用于构建 Web 服务器,而不是处理 Node 的低级网络和 HTTP API。 您不需要 Express 来构建 Web 服务器。
在开始本节之前,如果您不熟悉 HTTP 和 HTTP 请求(GET、POST 等),那么我鼓励您阅读我之前文章的相应部分,该部分链接在上面。
使用 Express,我们将设置可以向其发出 HTTP 请求的不同路由,以及在对该路由发出请求时将触发的相关端点(它们是回调函数)。 如果路由和端点当前没有意义,请不要担心——我稍后会解释它们。
与其他文章不同的是,我将采用逐行编写源代码的方法,而不是将整个代码库转储到一个片段中,然后再进行解释。 让我们从打开一个终端开始(我在 Windows 上的 Git Bash 上使用 Terminus——对于想要一个 Bash Shell 而无需设置 Linux 子系统的 Windows 用户来说,这是一个不错的选择),设置我们项目的样板,然后打开它在 Visual Studio 代码中。
mkdir server && cd server touch server.js npm init -y npm install express code . 在server.js文件中,我将首先使用require()函数请求express 。
const express = require('express'); require('express')告诉 Node 去获取我们之前安装的 Express 模块,该模块当前位于node_modules文件夹中(这就是npm install所做的——创建一个node_modules文件夹并将模块及其依赖项放入其中)。 按照惯例,在处理 Express 时,我们将保存require('express')返回结果的变量称为express ,尽管它可以被称为任何东西。
这个返回的结果,我们称之为express ,实际上是一个函数——我们必须调用这个函数来创建我们的 Express 应用程序并设置我们的路线。 Again, by convention, we call this app — app being the return result of express() — that is, the return result of calling the function that has the name express as express() .
const express = require('express'); const app = express(); // Note that the above variable names are the convention, but not required. // An example such as that below could also be used. const foo = require('express'); const bar = foo(); // Note also that the node module we installed is called express. The line const app = express(); simply puts a new Express Application inside of the app variable. It calls a function named express (the return result of require('express') ) and stores its return result in a constant named app . If you come from an object-oriented programming background, consider this equivalent to instantiating a new object of a class, where app would be the object and where express() would call the constructor function of the express class. Remember, JavaScript allows us to store functions in variables — functions are first-class citizens. The express variable, then, is nothing more than a mere function. It's provided to us by the developers of Express.
I apologize in advance if I'm taking a very long time to discuss what is actually very basic, but the above, although primitive, confused me quite a lot when I was first learning back-end development with Node.
Inside the Express source code, which is open-source on GitHub, the variable we called express is a function entitled createApplication , which, when invoked, performs the work necessary to create an Express Application:
A snippet of Express source code:
exports = module.exports = createApplication; /* * Create an express application */ // This is the function we are storing in the express variable. (- Jamie) function createApplication() { // This is what I mean by "Express App" (- Jamie) var app = function(req, res, next) { app.handle(req, res, next); }; mixin(app, EventEmitter.prototype, false); mixin(app, proto, false); // expose the prototype that will get set on requests app.request = Object.create(req, { app: { configurable: true, enumerable: true, writable: true, value: app } }) // expose the prototype that will get set on responses app.response = Object.create(res, { app: { configurable: true, enumerable: true, writable: true, value: app } }) app.init(); // See - `app` gets returned. (- Jamie) return app; }GitHub: https://github.com/expressjs/express/blob/master/lib/express.js
With that short deviation complete, let's continue setting up Express. Thus far, we have required the module and set up our app variable.
const express = require('express'); const app = express(); From here, we have to tell Express to listen on a port. Any HTTP Requests made to the URL and Port upon which our application is listening will be handled by Express. We do that by calling app.listen(...) , passing to it the port and a callback function which gets called when the server starts running:
const PORT = 3000; app.listen(PORT, () => console.log(`Server is up on port {PORT}.`)); We notate the PORT variable in capital by convention, for it is a constant variable that will never change. You could do that with all variables that you declare const , but that would look messy. It's up to the developer or development team to decide on notation, so we'll use the above sparsely. I use const everywhere as a method of “defensive coding” — that is, if I know that a variable is never going to change then I might as well just declare it const . Since I define everything const , I make the distinction between what variables should remain the same on a per-request basis and what variables are true actual global constants.
Here is what we have thus far:
const express = require('express'); const app = express(); const PORT = 3000; // We will build our API here. // ... // Binding our application to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`); });Let's test this to see if the server starts running on port 3000.
I'll open a terminal and navigate to our project's root directory. I'll then run node server/server.js . Note that this assumes you have Node already installed on your system (You can check with node -v ).
If everything works, you should see the following in the terminal:
Server is up on port 3000.
Go ahead and hit Ctrl + C to bring the server back down.
If this doesn't work for you, or if you see an error such as EADDRINUSE , then it means you may have a service already running on port 3000. Pick another port number, like 3001, 3002, 5000, 8000, etc. Be aware, lower number ports are reserved and there is an upper bound of 65535.
At this point, it's worth taking another small deviation as to understand servers and ports in the context of computer networking. We'll return to Express in a moment. I take this approach, rather than introducing servers and ports first, for the purpose of relevance. That is, it is difficult to learn a concept if you fail to see its applicability. In this way, you are already aware of the use case for ports and servers with Express, so the learning experience will be more pleasurable.
A Brief Look At Servers And Ports
A server is simply a computer or computer program that provides some sort of “functionality” to the clients that talk to it. More generally, it's a device, usually connected to the Internet, that handles connections in a pre-defined manner. In our case, that “pre-defined manner” will be HTTP or the HyperText Transfer Protocol. Servers that use the HTTP Protocol are called Web Servers.
When building an application, the server is a critical component of the “client-server model”, for it permits the sharing and syncing of data (generally via databases or file systems) across devices. It's a cross-platform approach, in a way, for the SDKs of platforms against which you may want to code — be they web, mobile, or desktop — all provide methods (APIs) to interact with a server over HTTP or TCP/UDP Sockets. It's important to make a distinction here — by APIs, I mean programming language constructs to talk to a server, like XMLHttpRequest or the Fetch API in JavaScript, or HttpUrlConnection in Java, or even HttpClient in C#/.NET. This is different from the kind of REST API we'll be building in this article to perform CRUD Operations on a database.
To talk about ports, it's important to understand how clients connect to a server. A client requires the IP Address of the server and the Port Number of our specific service on that server. An IP Address, or Internet Protocol Address, is just an address that uniquely identifies a device on a network. Public and private IPs exist, with private addresses commonly used behind a router or Network Address Translator on a local network. You might see private IP Addresses of the form 192.168.XXX.XXX or 10.0.XXX.XXX . When articulating an IP Address, decimals are called “dots”. So 192.168.0.1 (a common router IP Addr.) might be pronounced, “one nine two dot one six eight dot zero dot one”. (By the way, if you're ever in a hotel and your phone/laptop won't direct you to the AP captive portal, try typing 192.168.0.1 or 192.168.1.1 or similar directly into Chrome).
For simplicity, and since this is not an article about the complexities of computer networking, assume that an IP Address is equivalent to a house address, allowing you to uniquely identify a house (where a house is analogous to a server, client, or network device) in a neighborhood. One neighborhood is one network. Put together all of the neighborhoods in the United States, and you have the public Internet. (This is a basic view, and there are many more complexities — firewalls, NATs, ISP Tiers (Tier One, Tier Two, and Tier Three), fiber optics and fiber optic backbones, packet switches, hops, hubs, etc., subnet masks, etc., to name just a few — in the real networking world.) The traceroute Unix command can provide more insight into the above, displaying the path (and associated latency) that packets take through a network as a series of “hops”.
端口号标识服务器上运行的特定服务。 SSH 或 Secure Shell,它允许远程 shell 访问设备,通常在端口 22 上运行。FTP 或文件传输协议(例如,可能与 FTP 客户端一起使用以将静态资产传输到服务器)通常运行在端口 21。那么,我们可以说,在我们上面的类比中,端口是每个房屋内的特定房间,因为房屋中的房间是为不同的东西而设计的——卧室用于睡觉,厨房用于准备食物,餐厅用于消费。食物等,就像端口对应于执行特定服务的程序一样。 对我们来说,Web 服务器通常在端口 80 上运行,尽管您可以自由指定您希望的任何端口号,只要它们不被其他服务使用(它们不会冲突)。
为了访问网站,您需要该网站的 IP 地址。 尽管如此,我们通常通过 URL 访问网站。 在幕后,DNS 或域名服务器将该 URL 转换为 IP 地址,允许浏览器向服务器发出 GET 请求,获取HTML,并将其呈现到屏幕上。 8.8.8.8是 Google 的公共 DNS 服务器之一的地址。 您可能会想象需要通过远程 DNS 服务器将主机名解析为 IP 地址需要时间,您是对的。 为了减少延迟,操作系统有一个 DNS 缓存——一个存储 DNS 查找信息的临时数据库,从而降低了必须发生所述查找的频率。 可以在 Windows 上使用ipconfig /displaydns CMD 命令查看 DNS 解析器缓存,并通过ipconfig /flushdns命令清除。
在 Unix 服务器上,更常见的较低编号端口,如 80,需要root级别(如果您来自 Windows 背景,则升级)权限。 出于这个原因,我们将使用端口 3000 进行开发工作,但在我们部署到生产环境时将允许服务器选择端口号(无论可用)。
最后请注意,我们可以直接在谷歌浏览器的搜索栏中输入 IP 地址,从而绕过 DNS 解析机制。 例如,键入216.58.194.36会将您带到 Google.com。 在我们的开发环境中,当使用我们自己的计算机作为开发服务器时,我们将使用localhost和端口 3000。地址格式为hostname:port ,因此我们的服务器将在localhost:3000上运行。 本地主机或127.0.0.1是环回地址,表示“这台计算机”的地址。 它是一个主机名,其 IPv4 地址解析为127.0.0.1 。 立即尝试在您的机器上 ping localhost。 您可能会得到::1 - 这是 IPv6 环回地址,或127.0.0.1 - 这是 IPv4 环回地址。 IPv4 和 IPv6 是与不同标准相关的两种不同的 IP 地址格式——一些 IPv6 地址可以转换为 IPv4,但不是全部。
返回快递
我在之前的文章《Node 入门:API、HTTP 和 ES6+ JavaScript 简介》中提到了 HTTP 请求、动词和状态码。 如果您对协议没有大致的了解,请随意跳到该文章的“HTTP 和 HTTP 请求”部分。
为了了解 Express,我们将简单地为我们将在数据库上执行的四个基本操作设置端点——创建、读取、更新和删除,统称为 CRUD。
请记住,我们通过 URL 中的路由访问端点。 也就是说,虽然“路由”和“端点”这两个词通常可以互换使用,但端点在技术上是一种执行某些服务器端操作的编程语言函数(如 ES6 箭头函数),而路由是端点位于后面的。 我们将这些端点指定为回调函数,当客户端向端点所在的路由发出适当的请求时,Express 将触发这些函数。 您可以通过意识到执行功能的是端点并且路由是用于访问端点的名称来记住上述内容。 正如我们将看到的,相同的路由可以通过使用不同的 HTTP 动词与多个端点相关联(如果您来自具有多态性的经典 OOP 背景,则类似于方法重载)。
请记住,我们通过允许客户端向我们的服务器发出请求来遵循 REST(表示状态传输)架构。 毕竟,这是一个 REST 或 RESTful API。 对特定路由的特定请求将触发特定端点,这些端点将执行特定操作。 端点可能做的这种“事情”的一个例子是向数据库添加新数据、删除数据、更新数据等。
Express 知道要触发哪个端点,因为我们明确地告诉它请求方法(GET、POST 等)和路由——我们定义了针对上述特定组合触发的函数,客户端发出请求,指定路线和方法。 更简单地说,使用 Node,我们会告诉 Express——“嘿,如果有人向这个路由发出 GET 请求,那么继续并触发这个函数(使用这个端点)”。 事情可能会变得更复杂:“表达,如果有人向这条路由发出 GET 请求,但他们没有在请求的标头中发送有效的 Authorization Bearer Token,那么请用HTTP 401 Unauthorized响应。 如果他们确实拥有一个有效的承载令牌,那么请通过触发端点发送他们正在寻找的任何受保护资源。 非常感谢,祝您有美好的一天。” 确实,如果编程语言能够达到如此高的水平而不会泄露歧义,那就太好了,但它仍然展示了基本概念。
请记住,在某种程度上,端点存在于路线后面。 因此,客户端必须在请求的标头中提供它想要使用的方法,以便 Express 能够弄清楚要做什么。 请求将发送到特定路由,客户端将在联系服务器时指定(连同请求类型),允许 Express 做它需要做的事情,当 Express 触发我们的回调时我们做我们需要做的事情. 这就是一切。
在前面的代码示例中,我们调用了app上可用的listen函数,向它传递了一个端口和回调。 app本身,如果你还记得的话,就是将express变量作为函数调用的返回结果(即express() ),而express变量就是我们从node_modules文件夹中调用'express'的返回结果。 就像在app上调用listen一样,我们通过在app上调用它们来指定 HTTP 请求端点。 让我们看一下GET:
app.get('/my-test-route', () => { // ... }); 第一个参数是一个string ,它是端点所在的路由。 回调函数是端点。 我再说一遍:回调函数——第二个参数——是当对我们指定为第一个参数的任何路由(在本例中为/my-test-route )发出 HTTP GET 请求时将触发的端点。
现在,在我们对 Express 做更多工作之前,我们需要知道路由是如何工作的。 我们指定为字符串的路由将通过向www.domain.com/the-route-we-chose-earlier-as-a-string发出请求来调用。 在我们的例子中,域是localhost:3000 ,这意味着,为了触发上面的回调函数,我们必须向localhost:3000/my-test-route发出 GET 请求。 如果我们使用不同的字符串作为上面的第一个参数,则 URL 必须不同才能匹配我们在 JavaScript 中指定的内容。
在谈论这些事情时,您可能会听说 Glob Patterns。 我们可以说我们所有 API 的路由都位于localhost:3000/** Glob 模式,其中**是通配符,表示 root 是父目录的任何目录或子目录(注意路由不是目录)——也就是说,一切。
让我们继续在该回调函数中添加一条日志语句,这样我们就拥有了:
// Getting the module from node_modules. const express = require('express'); // Creating our Express Application. const app = express(); // Defining the port we'll bind to. const PORT = 3000; // Defining a new endpoint behind the "/my-test-route" route. app.get('/my-test-route', () => { console.log('A GET Request was made to /my-test-route.'); }); // Binding the server to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`) }); 我们将通过在项目的根目录中执行node server/server.js (在我们的系统上安装 Node 并且可以从系统环境变量全局访问)来启动并运行我们的服务器。 和之前一样,您应该在控制台中看到服务器已启动的消息。 现在服务器正在运行,打开浏览器,在 URL 栏中访问localhost:3000 。
您应该会看到一条错误消息,指出Cannot GET / 。 在 Chrome 中的 Windows 上按 Ctrl + Shift + I 以查看开发者控制台。 在那里,您应该看到我们有一个404 (找不到资源)。 这是有道理的——我们只告诉服务器当有人访问localhost:3000/my-test-route时该做什么。 浏览器在localhost:3000 (相当于localhost:3000/带有斜线)处没有要呈现的内容。
如果您查看运行服务器的终端窗口,应该没有新数据。 现在,在浏览器的 URL 栏中访问localhost:3000/my-test-route 。 您可能会在 Chrome 的控制台中看到相同的错误(因为浏览器正在缓存内容并且仍然没有要呈现的 HTML),但是如果您查看正在运行服务器进程的终端,您会看到回调函数确实触发了并且确实记录了日志消息。
使用 Ctrl + C 关闭服务器。
现在,让我们在向该路由发出 GET 请求时为浏览器提供一些要呈现的内容,这样我们就可以丢失Cannot GET /消息。 我将使用之前的app.get() ,在回调函数中,我将添加两个参数。 请记住,我们传入的回调函数在幕后被 Express 调用,Express 可以添加它想要的任何参数。 它实际上增加了两个(嗯,技术上是三个,但我们稍后会看到),虽然它们都非常重要,但我们现在不关心第一个。 第二个参数称为res ,是response的缩写,我将通过将undefined设置为第一个参数来访问它:
app.get('/my-test-route', (undefined, res) => { console.log('A GET Request was made to /my-test-route.'); }); 同样,我们可以随意调用res参数,但res是处理 Express 时的约定。 res实际上是一个对象,在它上面存在不同的方法将数据发送回客户端。 在这种情况下,我将访问res上可用的send(...)函数以发送回浏览器将呈现的 HTML。 但是,我们不仅限于发回 HTML,还可以选择发回文本、JavaScript 对象、流(流特别漂亮)或其他任何东西。
app.get('/my-test-route', (undefined, res) => { console.log('A GET Request was made to /my-test-route.'); res.send('<h1>Hello, World!</h1>'); }); 如果您关闭服务器然后将其重新启动,然后在/my-test-route路由处刷新您的浏览器,您将看到 HTML 被渲染。
Chrome 开发人员工具的网络选项卡将允许您更详细地查看此 GET 请求,因为它与标头有关。
在这一点上,开始学习 Express Middleware 对我们很有帮助——这些函数可以在客户端发出请求后全局触发。
快速中间件
Express 提供了为您的应用程序定义自定义中间件的方法。 确实,Express Middleware 的含义最好在 Express Docs 中定义,这里)
中间件函数是可以访问请求对象 (
req)、响应对象 (res) 和应用程序请求-响应周期中的下一个中间件函数的函数。 next 中间件函数通常由名为next的变量表示。
中间件函数可以执行以下任务:
- 执行任何代码。
- 更改请求和响应对象。
- 结束请求-响应周期。
- 调用堆栈中的下一个中间件函数。
换句话说,中间件函数是我们(开发人员)可以定义的自定义函数,它将充当 Express 接收请求和触发适当的回调函数之间的中介。 例如,我们可能会创建一个log函数,它会在每次发出请求时进行记录。 请注意,我们还可以选择在端点触发后触发这些中间件函数,具体取决于您将其放置在堆栈中的位置——我们稍后会看到。
为了指定自定义中间件,我们必须将其定义为一个函数并将其传递给app.use(...) 。
const myMiddleware = (req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); } app.use(myMiddleware); // This is the app variable returned from express().总之,我们现在有:
// Getting the module from node_modules. const express = require('express'); // Creating our Express Application. const app = express(); // Our middleware function. const myMiddleware = (req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); } // Tell Express to use the middleware. app.use(myMiddleware); // Defining the port we'll bind to. const PORT = 3000; // Defining a new endpoint behind the "/my-test-route" route. app.get('/my-test-route', () => { console.log('A GET Request was made to /my-test-route.'); }); // Binding the server to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`) }); 如果您再次通过浏览器发出请求,您现在应该看到您的中间件函数正在触发并记录时间戳。 为了促进实验,尝试删除对next函数的调用,看看会发生什么。
使用三个参数req 、 res和next调用中间件回调函数。 req是我们之前构建 GET 处理程序时跳过的参数,它是一个包含有关请求的信息的对象,例如标头、自定义标头、参数以及可能从客户端发送的任何主体(例如您使用 POST 请求)。 我知道我们在这里谈论的是中间件,但是端点和中间件函数都被req和res调用。 在来自客户端的单个请求的范围内,中间件和端点中的req和res将是相同的(除非其中一个或另一个对其进行了变异)。 这意味着,例如,您可以使用中间件函数通过剥离任何可能旨在执行 SQL 或 NoSQL 注入的字符来清理数据,然后将安全req交给端点。
res ,如前所述,允许您以几种不同的方式将数据发送回客户端。
next是一个回调函数,您必须在中间件完成其工作时执行该函数,以便调用堆栈或端点中的下一个中间件函数。 请务必注意,您必须在中间件中触发的任何异步函数的then块中调用它。 根据您的异步操作,您可能希望也可能不想在catch块中调用它。 也就是说, myMiddleware函数在客户端发出请求之后但在请求的端点函数被触发之前触发。 当我们执行此代码并发出请求时,您应该会在控制台中看到Middleware has fired...消息之前A GET Request was made to...消息。 如果您不调用next() ,则后一部分将永远不会运行 - 您的请求端点函数将不会触发。
另请注意,我可以匿名定义此函数(我将坚持的约定):
app.use((req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); }); 对于 JavaScript 和 ES6 的新手来说,如果上述工作方式没有立即意义,下面的示例应该会有所帮助。 我们只是定义了一个回调函数(匿名函数),它接受另一个回调函数( next )作为参数。 我们将接受函数参数的函数称为高阶函数。 请看下面的方式——它描述了 Express 源代码如何在幕后工作的基本示例:
console.log('Suppose a request has just been made from the client.\n'); // This is what (it's not exactly) the code behind app.use() might look like. const use = callback => { // Simple log statement to see where we are. console.log('Inside use() - the "use" function has been called.'); // This depicts the termination of the middleware. const next = () => console.log('Terminating Middleware!\n'); // Suppose req and res are defined above (Express provides them). const req = res = null; // "callback" is the "middleware" function that is passed into "use". // "next" is the above function that pretends to stop the middleware. callback(req, res, next); }; // This is analogous to the middleware function we defined earlier. // It gets passed in as "callback" in the "use" function above. const myMiddleware = (req, res, next) => { console.log('Inside the myMiddleware function!'); next(); } // Here, we are actually calling "use()" to see everything work. use(myMiddleware); console.log('Moving on to actually handle the HTTP Request or the next middleware function.'); 我们首先调用use myMiddleware作为参数的 use。 myMiddleware本身就是一个函数,它接受三个参数—— req 、 res和next 。 在use中, myMiddlware ,并传入了这三个参数。 next是在use中定义的函数。 myMiddleware在use方法中定义为callback 。 如果我在本例中将use放在名为app的对象上,我们可以完全模仿 Express 的设置,尽管没有任何套接字或网络连接。
在这种情况下, myMiddleware和callback都是高阶函数,因为它们都将函数作为参数。
如果执行此代码,您将看到以下响应:
Suppose a request has just been made from the client. Inside use() - the "use" function has been called. Inside the middleware function! Terminating Middleware! Moving on to actually handle the HTTP Request or the next middleware function.请注意,我也可以使用匿名函数来实现相同的结果:

console.log('Suppose a request has just been made from the client.'); // This is what (it's not exactly) the code behind app.use() might look like. const use = callback => { // Simple log statement to see where we are. console.log('Inside use() - the "use" function has been called.'); // This depicts the termination of the middlewear. const next = () => console.log('Terminating Middlewear!'); // Suppose req and res are defined above (Express provides them). const req = res = null; // "callback" is the function which is passed into "use". // "next" is the above function that pretends to stop the middlewear. callback(req, res, () => { console.log('Terminating Middlewear!'); }); }; // Here, we are actually calling "use()" to see everything work. use((req, res, next) => { console.log('Inside the middlewear function!'); next(); }); console.log('Moving on to actually handle the HTTP Request.');有了希望解决的问题,我们现在可以回到手头的实际任务——设置我们的中间件。
事实是,您通常必须通过 HTTP 请求向上发送数据。 这样做有几个不同的选项——发送 URL 查询参数,发送可以在我们之前了解的req对象上访问的数据,等等。该对象不仅在调用app.use() ,但也可以到任何端点。 我们之前使用undefined作为填充符,因此我们可以专注于res将 HTML 发送回客户端,但现在,我们需要访问它。
app.use('/my-test-route', (req, res) => { // The req object contains client-defined data that is sent up. // The res object allows the server to send data back down. });HTTP POST 请求可能要求我们向服务器发送一个主体对象。 如果您在客户端上有一个表单,并且您获取了用户的姓名和电子邮件,您可能会将该数据发送到请求正文中的服务器。
让我们看一下客户端的情况:
<!DOCTYPE html> <html> <body> <form action="https://localhost:3000/email-list" method="POST" > <input type="text" name="nameInput"> <input type="email" name="emailInput"> <input type="submit"> </form> </body> </html>在服务器端:
app.post('/email-list', (req, res) => { // What do we now? // How do we access the values for the user's name and email? }); 要访问用户的姓名和电子邮件,我们必须使用特定类型的中间件。 这会将数据放在req上一个名为body的对象上。 Body Parser 是一种流行的方法,Express 开发人员可以将其作为独立的 NPM 模块使用。 现在,Express 预先打包了自己的中间件来执行此操作,我们将这样称呼它:
app.use(express.urlencoded({ extended: true }));现在我们可以这样做:
app.post('/email-list', (req, res) => { console.log('User Name: ', req.body.nameInput); console.log('User Email: ', req.body.emailInput); }); 所有这一切都是从客户端发送的任何用户定义的输入,并使它们在req的body对象上可用。 请注意,在req.body上,我们现在有nameInput和emailInput ,它们是 HTML 中input标签的名称。 现在,这个客户端定义的数据应该被认为是危险的(永远,永远不要相信客户端),并且需要进行清理,但我们稍后会介绍。
express 提供的另一种中间件是express.json() 。 express.json用于将来自客户端的请求中发送的任何 JSON 有效负载打包到req.body上,而express.urlencoded将使用字符串、数组或其他 URL 编码数据的任何传入请求打包到req.body上。 简而言之,两者都操作req.body ,但 .json .json()用于 JSON 有效负载, .urlencoded()用于 POST 查询参数等。
另一种说法是,带有Content-Type: application/json标头的传入请求(例如使用fetch API 指定 POST 正文)将由express.json()处理,而带有标头Content-Type: application/x-www-form-urlencoded请求Content-Type: application/x-www-form-urlencoded (例如 HTML 表单)将使用express.urlencoded()处理。 希望这现在是有道理的。
为 MongoDB 启动我们的 CRUD 路由
注意:在本文中执行 PATCH 请求时,我们不会遵循 JSONPatch RFC 规范——我们将在本系列的下一篇文章中纠正这个问题。
考虑到我们知道我们通过调用app上的相关函数来指定每个端点,将路由和包含请求和响应对象的回调函数传递给它,我们可以开始为 Bookshelf API 定义我们的 CRUD 路由。 事实上,考虑到这是一篇介绍性文章,我不会注意完全遵循 HTTP 和 REST 规范,也不会尝试使用最简洁的架构。 这将在以后的文章中介绍。
我将打开迄今为止我们一直在使用的server.js文件,并清空所有内容,以便从以下干净的状态开始:
// Getting the module from node_modules. const express = require('express'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true )); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // ... // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); 考虑以下所有代码来占用上面文件的// ...部分。
为了定义我们的端点,并且因为我们正在构建一个 REST API,我们应该讨论命名路由的正确方法。 同样,您应该查看我之前文章的 HTTP 部分以获取更多信息。 我们正在处理书籍,因此所有路由都将位于/books后面(复数命名约定是标准的)。
| 要求 | 路线 |
|---|---|
| 邮政 | /books |
| 得到 | /books/id |
| 修补 | /books/id |
| 删除 | /books/id |
如您所见,发布书籍时不需要指定 ID,因为我们(或者更确切地说,MongoDB)将在服务器端自动为我们生成它。 GETting、PATCHing 和 DELETing 书籍都需要我们将该 ID 传递到我们的端点,我们将在稍后讨论。 现在,让我们简单地创建端点:
// HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); :id语法告诉 Express id是一个动态参数,将在 URL 中向上传递。 我们可以在req上可用的params对象上访问它。 我知道“我们可以在req上访问它”听起来像是魔术,而且魔术(不存在)在编程中是危险的,但你必须记住 Express 不是黑匣子。 这是一个开源项目,可在 GitHub 上获得 MIT 许可证。 如果您想了解如何将动态查询参数放到req对象上,您可以轻松查看它的源代码。
总之,我们现在在server.js文件中有以下内容:
// Getting the module from node_modules. const express = require('express'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); 继续并启动服务器,从终端或命令行运行node server.js ,然后访问您的浏览器。 打开 Chrome 开发控制台,在 URL(统一资源定位器)栏中,访问localhost:3000/books 。 您应该已经在操作系统终端中看到服务器已启动的指示器以及 GET 的日志语句。
到目前为止,我们一直在使用 Web 浏览器来执行 GET 请求。 这对刚开始很有用,但我们很快就会发现存在更好的工具来测试 API 路由。 事实上,我们可以将fetch调用直接粘贴到控制台或使用一些在线服务。 在我们的例子中,为了节省时间,我们将使用cURL和 Postman。 我在本文中使用了这两种方法(尽管您可以使用其中一种或),因此如果您还没有使用它们,我可以介绍它们。 cURL是一个库(一个非常非常重要的库)和命令行工具,旨在使用各种协议传输数据。 Postman 是一个基于 GUI 的 API 测试工具。 在您的操作系统上按照这两个工具的相关安装说明进行操作后,确保您的服务器仍在运行,然后在新终端中执行以下命令(一个接一个)。 键入它们并单独执行它们很重要,然后在与服务器不同的终端中查看日志消息。 另外,请注意标准编程语言注释符号//在 Bash 或 MS-DOS 中不是有效符号。 您必须省略这些行,我在这里只使用它们来描述每个cURL命令块。
// HTTP POST Request (Localhost, IPv4, IPv6) curl -X POST https://localhost:3000/books curl -X POST https://127.0.0.1:3000/books curl -X POST https://[::1]:3000/books // HTTP GET Request (Localhost, IPv4, IPv6) curl -X GET https://localhost:3000/books/123abc curl -X GET https://127.0.0.1:3000/books/book-id-123 curl -X GET https://[::1]:3000/books/book-abc123 // HTTP PATCH Request (Localhost, IPv4, IPv6) curl -X PATCH https://localhost:3000/books/456 curl -X PATCH https://127.0.0.1:3000/books/218 curl -X PATCH https://[::1]:3000/books/some-id // HTTP DELETE Request (Localhost, IPv4, IPv6) curl -X DELETE https://localhost:3000/books/abc curl -X DELETE https://127.0.0.1:3000/books/314 curl -X DELETE https://[::1]:3000/books/217 如您所见,作为 URL 参数传入的 ID 可以是任何值。 -X标志指定 HTTP 请求的类型(对于 GET 可以省略),我们提供此后将向其发出请求的 URL。 我将每个请求重复了三次,让您可以看到无论您使用localhost主机名、 localhost解析到的 IPv4 地址 ( 127.0.0.1 ) 还是localhost解析到的 IPv6 地址 ( ::1 ),一切仍然有效. 请注意, cURL需要将 IPv6 地址包装在方括号中。
我们现在处于一个不错的位置——我们设置了简单的路由结构和端点。 服务器正常运行并按照我们的预期接受 HTTP 请求。 与您可能期望的相反,此时距离不远了——我们只需要设置我们的数据库,托管它(使用数据库即服务——MongoDB Atlas),并将数据持久保存到它(以及执行验证并创建错误响应)。
设置生产 MongoDB 数据库
要设置生产数据库,我们将前往 MongoDB Atlas 主页并注册一个免费帐户。 此后,创建一个新集群。 您可以保持默认设置,选择适用区域的费用等级。 然后点击“创建集群”按钮。 集群将需要一些时间来创建,然后您将能够获得您的数据库 URL 和密码。 当你看到它们时,请注意它们。 我们现在将对它们进行硬编码,然后出于安全目的将它们存储在环境变量中。 有关创建和连接集群的帮助,我将向您推荐 MongoDB 文档,特别是此页面和此页面,或者您可以在下面留下评论,我会尽力提供帮助。
创建 Mongoose 模型
建议您了解 NoSQL(Not Only SQL — Structured Query Language)上下文中 Documents 和 Collections 的含义。 作为参考,您可能需要同时阅读 Mongoose 快速入门指南和我之前文章的 MongoDB 部分。
我们现在有一个准备好接受 CRUD 操作的数据库。 Mongoose 是一个 Node 模块(或 ODM — 对象文档映射器),它将允许我们执行这些操作(抽象出一些复杂性)以及设置数据库集合的模式或结构。
作为一个重要的免责声明,围绕 ORM 和 Active Record 或 Data Mapper 等模式存在很多争议。 一些开发人员对 ORM 发誓,而另一些开发人员则对他们发誓(认为他们妨碍了他们)。 同样重要的是要注意,ORM 抽象了很多,例如连接池、套接字连接和处理等。您可以轻松地使用 MongoDB 原生驱动程序(另一个 NPM 模块),但它会涉及更多工作。 虽然建议您在使用 ORM 之前先使用 Native Driver,但为了简洁起见,我在这里省略了 Native Driver。 对于关系数据库上的复杂 SQL 操作,并非所有 ORM 都会针对查询速度进行优化,您最终可能会编写自己的原始 SQL。 ORM 可以在领域驱动设计和 CQRS 等方面发挥很大作用。 它们是 .NET 世界中的一个既定概念,Node.js 社区还没有完全赶上——TypeORM 更好,但它不是 NHibernate 或实体框架。
为了创建我们的模型,我将在server目录中创建一个名为models的新文件夹,我将在其中创建一个名为book.js的文件。 Thus far, our project's directory structure is as follows:
- server - node_modules - models - book.js - package.json - server.js Indeed, this directory structure is not required, but I use it here because it's simple. Allow me to note that this is not at all the kind of architecture you want to use for larger applications (and you might not even want to use JavaScript — TypeScript could be a better option), which I discuss in this article's closing. The next step will be to install mongoose , which is performed via, as you might expect, npm i mongoose .
The meaning of a Model is best ascertained from the Mongoose documentation:
Models are fancy constructors compiled from
Schemadefinitions. An instance of a model is called a document. Models are responsible for creating and reading documents from the underlying MongoDB database.
Before creating the Model, we'll define its Schema. A Schema will, among others, make certain expectations about the value of the properties provided. MongoDB is schemaless, and thus this functionality is provided by the Mongoose ODM. 让我们从一个简单的例子开始。 Suppose I want my database to store a user's name, email address, and password. Traditionally, as a plain old JavaScript Object (POJO), such a structure might look like this:
const userDocument = { name: 'Jamie Corkhill', email: '[email protected]', password: 'Bcrypt Hash' };If that above object was how we expected our user's object to look, then we would need to define a schema for it, like this:
const schema = { name: { type: String, trim: true, required: true }, email: { type: String, trim: true, required: true }, password: { type: String, required: true } }; Notice that when creating our schema, we define what properties will be available on each document in the collection as an object in the schema. In our case, that's name , email , and password . The fields type , trim , required tell Mongoose what data to expect. If we try to set the name field to a number, for example, or if we don't provide a field, Mongoose will throw an error (because we are expecting a type of String ), and we can send back a 400 Bad Request to the client. This might not make sense right now because we have defined an arbitrary schema object. However, the fields of type , trim , and required (among others) are special validators that Mongoose understands. trim , for example, will remove any whitespace from the beginning and end of the string. We'll pass the above schema to mongoose.Schema() in the future and that function will know what to do with the validators.
Understanding how Schemas work, we'll create the model for our Books Collection of the Bookshelf API. Let's define what data we require:
标题
国际标准书号
作者
名
姓
Publishing Date
Finished Reading (Boolean)
I'm going to create this in the book.js file we created earlier in /models . Like the example above, we'll be performing validation:
const mongoose = require('mongoose'); // Define the schema: const mySchema = { title: { type: String, required: true, trim: true, }, isbn: { type: String, required: true, trim: true, }, author: { firstName:{ type: String, required: true, trim: true }, lastName: { type: String, required: true, trim: true } }, publishingDate: { type: String }, finishedReading: { type: Boolean, required: true, default: false } } default will set a default value for the property if none is provided — finishedReading for example, although a required field, will be set automatically to false if the client does not send one up.
Mongoose also provides the ability to perform custom validation on our fields, which is done by supplying the validate() method, which attains the value that was attempted to be set as its one and only parameter. In this function, we can throw an error if the validation fails. 这是一个例子:
// ... isbn: { type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } } // ... Now, if anyone supplies an invalid ISBN to our model, Mongoose will throw an error when trying to save that document to the collection. I've already installed the NPM module validator via npm i validator and required it. validator contains a bunch of helper functions for common validation requirements, and I use it here instead of RegEx because ISBNs can't be validated with RegEx alone due to a tailing checksum. Remember, users will be sending a JSON body to one of our POST routes. That endpoint will catch any errors (such as an invalid ISBN) when attempting to save, and if one is thrown, it'll return a blank response with an HTTP 400 Bad Request status — we haven't yet added that functionality.
Finally, we have to define our schema of earlier as the schema for our model, so I'll make a call to mongoose.Schema() passing in that schema:
const bookSchema = mongoose.Schema(mySchema); To make things more precise and clean, I'll replace the mySchema variable with the actual object all on one line:
const bookSchema = mongoose.Schema({ title:{ type: String, required: true, trim: true, }, isbn:{ type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } }, author:{ firstName: { type: String required: true, trim: true }, lastName:{ type: String, required: true, trim: true } }, publishingDate:{ type: String }, finishedReading:{ type: Boolean, required: true, default: false } });Let's take a final moment to discuss this schema. We are saying that each of our documents will consist of a title, an ISBN, an author with a first and last name, a publishing date, and a finishedReading boolean.
-
titlewill be of typeString, it's a required field, and we'll trim any whitespace. -
isbnwill be of typeString, it's a required field, it must match the validator, and we'll trim any whitespace. -
authoris of typeobjectcontaining a required, trimmed,stringfirstName and a required, trimmed,stringlastName. -
publishingDateis of type String (although we could make it of typeDateorNumberfor a Unix timestamp. -
finishedReadingis a requiredbooleanthat will default tofalseif not provided.
With our bookSchema defined, Mongoose knows what data and what fields to expect within each document to the collection that stores books. However, how do we tell it what collection that specific schema defines? We could have hundreds of collections, so how do we correlate, or tie, bookSchema to the Book collection?
The answer, as seen earlier, is with the use of models. We'll use bookSchema to create a model, and that model will model the data to be stored in the Book collection, which will be created by Mongoose automatically.
Append the following lines to the end of the file:
const Book = mongoose.model('Book', bookSchema); module.exports = Book; As you can see, we have created a model, the name of which is Book (— the first parameter to mongoose.model() ), and also provided the ruleset, or schema, to which all data is saved in the Book collection will have to abide. We export this model as a default export, allowing us to require the file for our endpoints to access. Book is the object upon which we'll call all of the required functions to Create, Read, Update, and Delete data which are provided by Mongoose.
Altogether, our book.js file should look as follows:
const mongoose = require('mongoose'); const validator = require('validator'); // Define the schema. const bookSchema = mongoose.Schema({ title:{ type: String, required: true, trim: true, }, isbn:{ type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } }, author:{ firstName: { type: String, required: true, trim: true }, lastName:{ type: String, required: true, trim: true } }, publishingDate:{ type: String }, finishedReading:{ type: Boolean, required: true, default: false } }); // Create the "Book" model of name Book with schema bookSchema. const Book = mongoose.model('Book', bookSchema); // Provide the model as a default export. module.exports = Book;Connecting To MongoDB (Basics)
Don't worry about copying down this code. I'll provide a better version in the next section. To connect to our database, we'll have to provide the database URL and password. We'll call the connect method available on mongoose to do so, passing to it the required data. For now, we are going hardcode the URL and password — an extremely frowned upon technique for many reasons: namely the accidental committing of sensitive data to a public (or private made public) GitHub Repository. Realize also that commit history is saved, and that if you accidentally commit a piece of sensitive data, removing it in a future commit will not prevent people from seeing it (or bots from harvesting it), because it's still available in the commit history. CLI tools exist to mitigate this issue and remove history.
As stated, for now, we'll hard code the URL and password, and then save them to environment variables later. At this point, let's look at simply how to do this, and then I'll mention a way to optimize it.
const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: false, useUnifiedTopology: true });这将连接到数据库。 我们提供了从 MongoDB Atlas 仪表板获得的 URL,并且作为第二个参数传入的对象指定了要使用的功能,其中包括防止弃用警告。
Mongoose 在幕后使用核心 MongoDB Native Driver,必须尝试跟上对驱动程序所做的重大更改。 在新版本的驱动程序中,用于解析连接 URL 的机制发生了变化,因此我们通过useNewUrlParser: true标志来指定我们要使用官方驱动程序提供的最新版本。
默认情况下,如果您为数据库中的数据设置索引(它们被称为“索引”而不是“索引”)(我们不会在本文中介绍),Mongoose 会使用 Native Driver 提供的ensureIndex()函数。 MongoDB 弃用了该函数以支持createIndex() ,因此将标志useCreateIndex设置为 true 将告诉 Mongoose 使用驱动程序中的createIndex()方法,这是未弃用的函数。
Mongoose 的findOneAndUpdate原始版本(这是一种在数据库中查找文档并更新它的方法)早于 Native Driver 版本。 也就是说, findOneAndUpdate()原本并不是 Native Driver 的函数,而是 Mongoose 提供的函数,所以 Mongoose 不得不使用驱动在后台提供的findAndModify来创建findOneAndUpdate功能。 现在更新了驱动程序,它包含自己的此类功能,因此我们不必使用findAndModify 。 这可能没有意义,但这没关系——它不是关于事物规模的重要信息。
最后,MongoDB 弃用了旧的服务器和引擎监控系统。 我们将新方法与useUnifiedTopology: true一起使用。
到目前为止,我们拥有的是一种连接数据库的方法。 但事情就是这样——它不是可扩展的或高效的。 当我们为此 API 编写单元测试时,单元测试将在他们自己的测试数据库上使用他们自己的测试数据(或夹具)。 因此,我们想要一种能够为不同目的创建连接的方法——一些用于测试环境(我们可以随意启动和拆除),另一些用于开发环境,还有一些用于生产环境。 为此,我们将建立一个工厂。 (还记得之前的那个吗?)
连接到 Mongo — 构建一个 JS 工厂的实现
事实上,Java 对象与 JavaScript 对象完全不同,因此,我们在上面从工厂设计模式中了解到的内容将不再适用。 我只是提供了一个例子来展示传统的模式。 要在 Java、C# 或 C++ 等中获得一个对象,我们必须实例化一个类。 这是通过new关键字完成的,它指示编译器为堆上的对象分配内存。 在 C++ 中,这为我们提供了一个指向我们必须自己清理的对象的指针,这样我们就没有悬挂指针或内存泄漏(C++ 没有垃圾收集器,这与基于 C++ 构建的 Node/V8 不同)在 JavaScript 中,上面不需要做——我们不需要实例化一个类来获得一个对象——一个对象只是{} 。 有人会说 JavaScript 中的一切都是对象,尽管这在技术上并不正确,因为原始类型不是对象。
由于上述原因,我们的 JS 工厂会更简单,坚持工厂的松散定义,即返回对象(JS 对象)的函数。 由于函数是一个对象( function通过原型继承从object继承),我们下面的示例将满足这个标准。 为了实现工厂,我将在server内部创建一个名为db的新文件夹。 在db中,我将创建一个名为mongoose.js的新文件。 该文件将连接到数据库。 在mongoose.js内部,我将创建一个名为connectionFactory的函数并默认导出它:
// Directory - server/db/mongoose.js const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; const connectionFactory = () => { return mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: false }); }; module.exports = connectionFactory; 使用 ES6 为箭头函数提供的简写,它在方法签名的同一行返回一个语句,我将通过删除connectionFactory定义并默认导出工厂来简化此文件:
// server/db/mongoose.js const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; module.exports = () => mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: true });现在,所要做的就是获取文件并调用导出的方法,如下所示:
const connectionFactory = require('./db/mongoose'); connectionFactory(); // OR require('./db/mongoose')();您可以通过将 MongoDB URL 作为参数提供给工厂函数来反转控制,但我们将根据环境将 URL 作为环境变量动态更改。
将连接作为函数的好处是,我们可以稍后在代码中调用该函数,以从针对生产的文件以及针对本地和远程集成测试的文件连接到数据库,包括设备上和远程 CI/CD 管道/建立服务器。
建立我们的端点
我们现在开始向端点添加非常简单的 CRUD 相关逻辑。 如前所述,需要简短的免责声明。 我们在这里实现业务逻辑的方法不是您应该为简单项目以外的任何东西镜像的方法。 连接到数据库并直接在端点内执行逻辑是(并且应该)不赞成的,因为您失去了交换服务或 DBMS 的能力,而无需执行应用程序范围的重构。 尽管如此,考虑到这是一篇初学者的文章,我在这里采用了这些不好的做法。 本系列未来的一篇文章将讨论我们如何提高架构的复杂性和质量。
现在,让我们回到我们的server.js文件并确保我们都有相同的起点。 请注意,我为我们的数据库连接工厂添加了require语句,并导入了我们从./models/book.js导出的模型。
const express = require('express'); // Database connection and model. require('./db/mongoose.js'); const Book = require('./models/book.js'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); 我将从app.post()开始。 我们可以访问Book模型,因为我们从创建它的文件中导出了它。 正如 Mongoose 文档中所述, Book是可构造的。 要创建一本新书,我们调用构造函数并传入书籍数据,如下所示:
const book = new Book(bookData); 在我们的例子中,我们将bookData作为请求中发送的对象,这将在req.body.book上可用。 请记住, express.json()中间件会将我们发送的任何 JSON 数据放到req.body上。 我们将以以下格式发送 JSON:
{ "book": { "title": "The Art of Computer Programming", "isbn": "ISBN-13: 978-0-201-89683-1", "author": { "firstName": "Donald", "lastName": "Knuth" }, "publishingDate": "July 17, 1997", "finishedReading": true } } 那么,这意味着我们传递的 JSON 将被解析,整个 JSON 对象(第一对大括号)将由express.json()中间件放在req.body上。 我们的 JSON 对象的唯一属性是book ,因此book对象将在req.body.book上可用。
此时,我们可以调用模型构造函数并传入我们的数据:
app.post('/books', async (req, res) => { // <- Notice 'async' const book = new Book(req.body.book); await book.save(); // <- Notice 'await' }); 注意这里的几件事。 当且仅当它符合我们在 Mongoose 模型中定义的模式时,在我们从调用构造函数返回的实例上调用save方法会将req.body.book对象持久保存到数据库中。 将数据保存到数据库的行为是一个异步操作,并且这个save()方法返回一个承诺——我们非常期待它的解决。 我没有链接.then()调用,而是使用 ES6 Async/Await 语法,这意味着我必须将回调函数设置为app.post async 。
如果客户端发送的对象不符合我们定义的模式,则book.save()将拒绝并返回ValidationError 。 我们当前的设置导致了一些非常不稳定和编写糟糕的代码,因为我们不希望我们的应用程序在验证失败的情况下崩溃。 为了解决这个问题,我将在try/catch子句中包含危险操作。 如果发生错误,我将返回 HTTP 400 错误请求或 HTTP 422 无法处理的实体。 关于使用哪个存在一些争论,所以我将在本文中坚持使用 400,因为它更通用。
app.post('/books', async (req, res) => { try { const book = new Book(req.body.book); await book.save(); return res.status(201).send({ book }); } catch (e) { return res.status(400).send({ error: 'ValidationError' }); } }); 请注意,我使用 ES6 Object Shorthand 在成功的情况下使用res.send({ book })将book对象直接返回给客户端——这相当于res.send({ book: book }) 。 我还返回表达式只是为了确保我的函数退出。 在catch块中,我将状态显式设置为 400,并在返回的对象的error属性上返回字符串“ValidationError”。 201 是成功路径状态代码,意思是“已创建”。
事实上,这也不是最好的解决方案,因为我们不能确定失败的原因是客户端的错误请求。 也许我们失去了与数据库的连接(假设是一个断开的套接字连接,因此是一个暂时的异常),在这种情况下,我们可能应该返回一个 500 Internal Server 错误。 检查这一点的一种方法是读取e错误对象并有选择地返回响应。 现在让我们这样做,但正如我多次说过的,后续文章将讨论路由器、控制器、服务、存储库、自定义错误类、自定义错误中间件、自定义错误响应、数据库模型/域实体数据方面的适当架构映射和命令查询分离 (CQS)。
app.post('/books', async (req, res) => { try { const book = new Book(req.body.book); await book.save(); return res.send({ book }); } catch (e) { if (e instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'ValidationError' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); 继续打开 Postman(假设你有它,否则,下载并安装它)并创建一个新请求。 我们将向localhost:3000/books发出 POST 请求。 在 Postman Request 部分的“Body”选项卡下,我将选择“raw”单选按钮并在最右侧的下拉按钮中选择“JSON”。 这将继续并自动将Content-Type: application/json标头添加到请求中。 然后,我会将之前的 Book JSON 对象复制并粘贴到正文文本区域中。 这就是我们所拥有的:
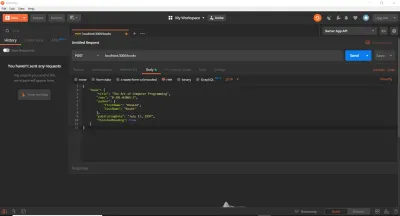
此后,我将点击发送按钮,您应该会在 Postman 的“响应”部分(底行)中看到 201 Created 响应。 我们看到这一点是因为我们特别要求 Express 响应 201 和 Book 对象——如果我们刚刚完成res.send()没有状态码, express会自动响应 200 OK。 如您所见,Book 对象现在已保存到数据库中,并已作为对 POST 请求的响应返回给客户端。
如果您通过 MongoDB Atlas 查看数据库 Book 集合,您会看到该书确实已保存。
您还可以看出 MongoDB 已插入__v和_id字段。 前者代表文档的版本,在本例中为 0,后者是文档的 ObjectID——由 MongoDB 自动生成,保证碰撞概率低。
迄今为止我们所涵盖内容的摘要
到目前为止,我们已经在文章中介绍了很多内容。 在返回完成 Express API 之前,让我们先回顾一下简短的摘要。
我们了解了 ES6 对象解构、ES6 对象简写语法以及 ES6 Rest/Spread 运算符。 所有这三个让我们执行以下操作(以及更多,如上所述):
// Destructuring Object Properties: const { a: newNameA = 'Default', b } = { a: 'someData', b: 'info' }; console.log(`newNameA: ${newNameA}, b: ${b}`); // newNameA: someData, b: info // Destructuring Array Elements const [elemOne, elemTwo] = [() => console.log('hi'), 'data']; console.log(`elemOne(): ${elemOne()}, elemTwo: ${elemTwo}`); // elemOne(): hi, elemTwo: data // Object Shorthand const makeObj = (name) => ({ name }); console.log(`makeObj('Tim'): ${JSON.stringify(makeObj('Tim'))}`); // makeObj('Tim'): { "name": "Tim" } // Rest, Spread const [c, d, ...rest] = [0, 1, 2, 3, 4]; console.log(`c: ${c}, d: ${d}, rest: ${rest}`) // c: 0, d: 1, rest: 2, 3, 4 我们还介绍了 Express、Expess 中间件、服务器、端口、IP 地址等。当我们了解到require('express')();的返回结果存在可用的方法时,事情变得有趣起来。 使用 HTTP 动词的名称,例如app.get和app.post 。
如果这require('express')()部分对您没有意义,这就是我要提出的观点:
const express = require('express'); const app = express(); app.someHTTPVerb它应该与我们之前为 Mongoose 启动连接工厂的方式相同。
每个路由处理程序,即端点函数(或回调函数),在幕后从 Express 传入一个req对象和一个res对象。 (他们在技术上也得到next ,我们马上就会看到)。 req包含特定于来自客户端的传入请求的数据,例如标头或发送的任何 JSON。 res允许我们向客户端返回响应。 next函数也传递给处理程序。
在 Mongoose 中,我们看到了如何使用两种方法连接到数据库——一种原始方式和一种借鉴工厂模式的更高级/实用的方式。 当我们讨论 Jest 的单元和集成测试(和突变测试)时,我们最终会使用它,因为它允许我们启动一个数据库的测试实例,其中填充了我们可以运行断言的种子数据。
之后,我们创建了一个 Mongoose 模式对象并使用它来创建模型,然后学习了如何调用该模型的构造函数来创建它的新实例。 实例上可用的是save方法(以及其他方法),它本质上是异步的,它将检查我们传入的对象结构是否符合模式,如果符合则解析 promise,如果符合则使用ValidationError拒绝 promise它不是。 在解决的情况下,新文档被保存到数据库中,我们以 HTTP 200 OK/201 CREATED 响应,否则,我们在端点中捕获抛出的错误,并向客户端返回 HTTP 400 错误请求。
随着我们继续构建我们的端点,您将了解有关模型和模型实例上可用的一些方法的更多信息。
完成我们的端点
完成 POST Endpoint 后,让我们处理 GET。 正如我之前提到的,路由中的:id语法让 Express 知道id是一个路由参数,可以从req.params访问。 您已经看到,当您为路径中的参数“通配符”匹配某个 ID 时,它会在早期示例中打印到屏幕上。 例如,如果您向“/books/test-id-123”发出 GET 请求,那么req.params.id将是字符串test-id-123 ,因为参数名称是通过将路由设置为HTTP GET /books/:id的id HTTP GET /books/:id 。
因此,我们需要做的就是从req对象中检索该 ID,并检查我们数据库中的任何文档是否具有相同的 ID——Mongoose(和本机驱动程序)使这变得非常容易。
app.get('/books/:id', async (req, res) => { const book = await Book.findById(req.params.id); console.log(book); res.send({ book }); }); 您可以看到,在我们的模型上可访问的是一个我们可以调用的函数,它将通过其 ID 查找文档。 在幕后,Mongoose 会将我们传递给findById的任何 ID 转换为文档上_id字段的类型,或者在本例中为ObjectId 。 如果找到一个匹配的 ID(并且对于ObjectId的冲突概率极低,只会找到一个),该文档将被放置在我们的book常量变量中。 如果不是,则book将为空——我们将在不久的将来使用这一事实。
现在,让我们重新启动服务器(除非您使用nodemon ,否则您必须重新启动服务器)并确保我们在Books Collection 中仍然拥有之前的一本书文档。 继续复制该文档的 ID,即下图中突出显示的部分:

并使用它通过 Postman 向/books/:id发出 GET 请求,如下所示(请注意,正文数据只是我之前的 POST 请求中遗留下来的。尽管它如下图所示,但实际上并没有被使用) :
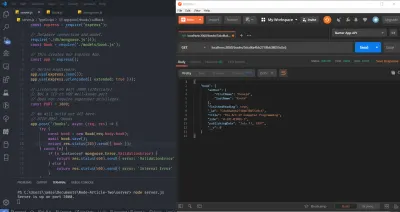
这样做后,您应该在 Postman 响应部分中获取具有指定 ID 的图书文档。 请注意,之前的 POST 路由旨在“POST”或“推送”新资源到服务器,我们以 201 Created 响应——因为创建了新资源(或文档)。 在 GET 的情况下,没有创建任何新内容——我们只是请求了一个具有特定 ID 的资源,因此我们得到了 200 OK 状态码,而不是 201 Created。
在软件开发领域很常见,必须考虑边缘情况——用户输入本质上是不安全和错误的,作为开发人员,我们的工作是灵活地处理我们可以提供的输入类型并做出响应因此。 如果用户(或 API 调用者)向我们传递了一些无法转换为 MongoDB ObjectID 的 ID,或者可以转换但不存在的 ID,我们该怎么办?
对于前一种情况,Mongoose 会抛出一个CastError ——这是可以理解的,因为如果我们提供一个类似math-is-fun的 ID,那么这显然不是可以转换为 ObjectID 的东西,而转换为 ObjectID 是具体的Mongoose 在幕后工作。
对于后一种情况,我们可以通过 Null Check 或 Guard Clause 轻松纠正问题。 无论哪种方式,我都会发回 HTTP 404 Not Found 响应。 我将向您展示我们可以做到这一点的几种方法,一种不好的方法,然后是一种更好的方法。
首先,我们可以做到以下几点:
app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) throw new Error(); return res.send({ book }); } catch (e) { return res.status(404).send({ error: 'Not Found' }); } }); 这很有效,我们可以很好地使用它。 如果 ID 字符串无法转换为 ObjectID,我希望语句await Book.findById()将引发 Mongoose CastError ,从而导致执行catch块。 如果可以强制转换但对应的 ObjectID 不存在,那么book将为null并且 Null Check 将抛出错误,再次触发catch块。 在catch中,我们只返回一个 404。这里有两个问题。 首先,即使找到了 Book 但发生了一些其他未知错误,当我们可能应该给客户端一个通用的 catch-all 500 时,我们发送回一个 404。其次,我们并没有真正区分发送的 ID 是否有效,而是不存在,或者它是否只是一个错误的 ID。
所以,这里有另一种方式:
const mongoose = require('mongoose'); app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) return res.status(404).send({ error: 'Not Found' }); return res.send({ book }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); 这样做的好处是我们可以处理 400、404 和通用 500 这三种情况。请注意,在book上的 Null Check 之后,我在响应中使用了return关键字。 这非常重要,因为我们要确保我们在那里退出路由处理程序。
其他一些选项可能是我们检查req.params上的id是否可以显式转换为 ObjectID,而不是允许 Mongoose 使用mongoose.Types.ObjectId.isValid('id); ,但是有一个 12 字节字符串的边缘情况会导致它有时会意外地工作。
例如,我们可以使用 HTTP 响应库Boom来减轻重复的痛苦,或者我们可以使用错误处理中间件。 我们还可以使用 Mongoose Hooks/Middleware 将 Mongoose 错误转换为更具可读性的内容,如此处所述。 另一个选项是定义自定义错误对象并使用全局 Express 错误处理中间件,但是,我将把它留到下一篇讨论更好的架构方法的文章中。
在PATCH /books/:id的端点中,我们希望传递一个更新对象,其中包含相关书籍的更新。 对于本文,我们将允许更新所有字段,但在未来,我将展示如何禁止更新特定字段。 此外,您会看到我们的 PATCH 端点中的错误处理逻辑将与我们的 GET 端点相同。 这表明我们违反了 DRY 原则,但我们稍后再谈。
我希望req.body的updates对象上的所有更新都可用(这意味着客户端将发送包含updates对象的 JSON)并将使用带有特殊标志的Book.findByAndUpdate函数来执行更新。
app.patch('/books/:id', async (req, res) => { const { id } = req.params; const { updates } = req.body; try { const updatedBook = await Book.findByIdAndUpdate(id, updates, { runValidators: true, new: true }); if (!updatedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: updatedBook }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); 注意这里的几件事。 我们首先从req.body中解构id并从req.params中updates 。
Book模型上可用的是一个名为findByIdAndUpdate的函数,它获取相关文档的 ID、要执行的更新和一个可选的选项对象。 通常,Mongoose 不会为更新操作重新执行验证,因此我们作为options对象传入的runValidators: true标志会强制它这样做。 此外,从 Mongoose 4 开始, Model.findByIdAndUpdate不再返回修改后的文档,而是返回原始文档。 new: true标志(默认为 false)会覆盖该行为。
最后,我们可以构建我们的 DELETE 端点,它与所有其他端点非常相似:
app.delete('/books/:id', async (req, res) => { try { const deletedBook = await Book.findByIdAndDelete(req.params.id); if (!deletedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: deletedBook }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } });这样,我们的原始 API 就完成了,您可以通过向所有端点发出 HTTP 请求来测试它。
关于架构的简短免责声明以及我们将如何纠正它
从架构的角度来看,我们这里的代码很糟糕,很乱,它不是 DRY,它不是 SOLID,事实上,你甚至可以称之为可恶。 这些所谓的“路由处理程序”不仅仅是“处理路由”——它们直接与我们的数据库交互。 这意味着绝对没有抽象。
让我们面对现实吧,大多数应用程序永远不会这么小,或者您可能会使用 Firebase 数据库摆脱无服务器架构。 也许,正如我们稍后将看到的,用户希望能够从他们的书中上传头像、报价和片段等。也许我们希望使用 WebSockets 在用户之间添加实时聊天功能,甚至可以说我们'将打开我们的应用程序,让用户以少量费用互相借书——此时我们需要考虑与 Stripe API 的支付集成以及与 Shippo API 的运输物流。
假设我们继续我们当前的架构并添加所有这些功能。 这些路由处理程序,也称为控制器动作,最终将变得非常非常大,具有很高的圈复杂度。 这种编码风格在早期可能很适合我们,但是如果我们认为我们的数据是参考的,因此 PostgreSQL 是比 MongoDB 更好的数据库选择怎么办? 我们现在必须重构整个应用程序,剥离 Mongoose,更改我们的控制器等,所有这些都可能导致其余业务逻辑中的潜在错误。 另一个这样的例子是决定 AWS S3 太贵,我们希望迁移到 GCP。 同样,这需要应用程序范围的重构。
虽然关于架构有很多意见,从领域驱动设计、命令查询职责分离和事件溯源,到测试驱动开发、SOILD、分层架构、洋葱架构等等,我们将专注于实现简单的分层架构未来的文章,包括控制器、服务和存储库,并采用组合、适配器/包装器和通过依赖注入实现控制反转等设计模式。 虽然在某种程度上,这可以通过 JavaScript 执行,但我们也将研究 TypeScript 选项来实现这种架构,允许我们使用函数式编程范式,例如 Either Monads 以及诸如泛型之类的 OOP 概念。
目前,我们可以做两个小改动。 因为我们的错误处理逻辑在所有端点的catch块中都非常相似,所以我们可以将其提取到堆栈最末端的自定义 Express 错误处理中间件函数中。
清理我们的架构
目前,我们正在所有端点上重复大量错误处理逻辑。 相反,我们可以构建一个 Express 错误处理中间件函数,它是一个被错误调用的 Express 中间件函数、req 和 res 对象以及下一个函数。
现在,让我们构建该中间件功能。 我要做的就是重复我们习惯的相同错误处理逻辑:
app.use((err, req, res, next) => { if (err instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'Validation Error' }); } else if (err instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { console.log(err); // Unexpected, so worth logging. return res.status(500).send({ error: 'Internal error' }); } }); 这似乎不适用于 Mongoose 错误,但通常,您可以切换错误的构造函数,而不是使用if/else if/else来确定错误实例。 不过,我会留下我们所拥有的。
在同步端点/路由处理程序中,如果您抛出错误,Express 将捕获并处理它,而无需您进行额外的工作。 不幸的是,我们并非如此。 我们正在处理异步代码。 为了使用异步路由处理程序将错误处理委托给 Express,我们自己捕获错误并将其传递给next() 。
因此,我只允许next成为端点的第三个参数,并且我将删除catch块中的错误处理逻辑,以便将错误实例传递给next ,如下所示:
app.post('/books', async (req, res, next) => { try { const book = new Book(req.body.book); await book.save(); return res.send({ book }); } catch (e) { next(e) } });如果你对所有路由处理程序都这样做,你应该得到以下代码:
const express = require('express'); const mongoose = require('mongoose'); // Database connection and model. require('./db/mongoose.js')(); const Book = require('./models/book.js'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', async (req, res, next) => { try { const book = new Book(req.body.book); await book.save(); return res.status(201).send({ book }); } catch (e) { next(e) } }); // HTTP GET /books/:id app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) return res.status(404).send({ error: 'Not Found' }); return res.send({ book }); } catch (e) { next(e); } }); // HTTP PATCH /books/:id app.patch('/books/:id', async (req, res, next) => { const { id } = req.params; const { updates } = req.body; try { const updatedBook = await Book.findByIdAndUpdate(id, updates, { runValidators: true, new: true }); if (!updatedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: updatedBook }); } catch (e) { next(e); } }); // HTTP DELETE /books/:id app.delete('/books/:id', async (req, res, next) => { try { const deletedBook = await Book.findByIdAndDelete(req.params.id); if (!deletedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: deletedBook }); } catch (e) { next(e); } }); // Notice - bottom of stack. app.use((err, req, res, next) => { if (err instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'Validation Error' }); } else if (err instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { console.log(err); // Unexpected, so worth logging. return res.status(500).send({ error: 'Internal error' }); } }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); 更进一步,将我们的错误处理中间件分离到另一个文件中是值得的,但这是微不足道的,我们将在本系列的未来文章中看到它。 此外,我们可以使用一个名为express-async-errors的 NPM 模块来允许我们不必在 catch 块中调用 next,但我再次尝试向您展示事情是如何正式完成的。
关于 CORS 和同源策略的一句话
假设您的网站是从域myWebsite.com提供的,但您的服务器位于myOtherDomain.com/api 。 CORS 代表 Cross-Origin Resource Sharing,是一种可以执行跨域请求的机制。 在上述情况下,由于服务器和前端 JS 代码位于不同的域中,因此您将跨两个不同的来源发出请求,出于安全原因,这通常受到浏览器的限制,并通过提供特定的 HTTP 标头来缓解。
同源策略是执行上述限制的原因——Web 浏览器只允许跨同源请求。
稍后当我们使用 React 为 Book API 构建 Webpack 捆绑前端时,我们将涉及 CORS 和 SOP。
结论和下一步是什么
我们在这篇文章中讨论了很多。 也许它并不完全实用,但希望它能让您更轻松地使用 Express 和 ES6 JavaScript 特性。 如果您是编程新手,而 Node 是您开始的第一条路径,希望对 Java、C++ 和 C# 等静态类型语言的引用有助于突出 JavaScript 与其静态对应语言之间的一些差异。
Next time, we'll finish building out our Book API by making some fixes to our current setup with regards to the Book Routes, as well as adding in User Authentication so that users can own books. We'll do all of this with a similar architecture to what I described here and with MongoDB for data persistence. Finally, we'll permit users to upload avatar images to AWS S3 via Buffers.
In the article thereafter, we'll be rebuilding our application from the ground up in TypeScript, still with Express. We'll also move to PostgreSQL with Knex instead of MongoDB with Mongoose as to depict better architectural practices. Finally, we'll update our avatar image uploading process to use Node Streams (we'll discuss Writable, Readable, Duplex, and Transform Streams). Along the way, we'll cover a great amount of design and architectural patterns and functional paradigms, including:
- Controllers/Controller Actions
- 服务
- 存储库
- 数据映射
- The Adapter Pattern
- The Factory Pattern
- The Delegation Pattern
- OOP Principles and Composition vs Inheritance
- Inversion of Control via Dependency Injection
- 坚实的原则
- Coding against interfaces
- 数据传输对象
- Domain Models and Domain Entities
- Either Monads
- 验证
- 装饰器
- Logging and Logging Levels
- Unit Tests, Integration Tests (E2E), and Mutation Tests
- The Structured Query Language
- 关系
- HTTP/Express Security Best Practices
- Node Best Practices
- OWASP Security Best Practices
- 和更多。
Using that new architecture, in the article after that, we'll write Unit, Integration, and Mutation tests, aiming for close to 100 percent testing coverage, and we'll finally discuss setting up a remote CI/CD pipeline with CircleCI, as well as Message Busses, Job/Task Scheduling, and load balancing/reverse proxying.
Hopefully, this article has been helpful, and if you have any queries or concerns, let me know in the comments below.