
Python中的探索性数据分析:你需要知道什么?
已发表: 2021-03-12探索性数据分析 (EDA) 是所有数据科学家都遵循的一种非常普遍且重要的实践。 这是从不同角度查看表格和数据表以完全理解它的过程。 对数据有很好的理解有助于我们对数据进行清理和总结,从而带来原本不清楚的见解和趋势。
例如,EDA 没有像“数据分析”那样需要遵循的核心规则集。 刚接触该领域的人总是容易混淆这两个术语,这两个术语大多相似,但目的不同。 与 EDA 不同,数据分析更倾向于使用概率和统计方法来揭示不同变体之间的事实和关系。
回过头来,执行 EDA 的方式没有对错之分。 它因人而异,但是,下面列出了一些通常遵循的主要准则。
- 处理缺失值:当收集期间所有数据可能不可用或未记录时,可以看到空值。
- 删除重复数据:重要的是要防止在使用重复数据记录训练机器学习算法期间产生任何过度拟合或偏差
- 处理异常值:异常值是与其余数据截然不同且不遵循趋势的记录。 它可能由于数据收集过程中的某些异常或不准确而出现
- 缩放和标准化:这仅适用于数值数据变量。 大多数情况下,变量的范围和规模差异很大,这使得很难比较它们并找到相关性。
- 单变量和双变量分析:单变量分析通常通过查看一个变量如何影响目标变量来完成。 双变量分析是在任何两个变量之间进行的,它可以是数值的或分类的或两者兼而有之。
我们将看看其中一些是如何使用 Kaggle 上非常著名的“Home Credit Default Risk”数据集实现的。 该数据包含有关贷款申请人在申请贷款时的信息。 它包含两种类型的场景:
- 付款困难的客户:他/她逾期付款超过X天
在我们样本中的前 Y 期贷款中的至少一个,
- 所有其他情况:按时付款的所有其他情况。
为了本文的目的,我们将只处理应用程序数据文件。
相关:面向初学者的 Python 项目理念和主题
目录
看数据
app_data = pd.read_csv('application_data.csv')
app_data.info()
读取应用程序数据后,我们使用 info() 函数来简要了解我们将要处理的数据。 下面的输出告诉我们,我们有大约 300000 条贷款记录,包含 122 个变量。 其中,有 16 个分类变量,其余为数字变量。
<class 'pandas.core.frame.DataFrame'>
RangeIndex:307511 个条目,0 到 307510
列:122 个条目,SK_ID_CURR 到 AMT_REQ_CREDIT_BUREAU_YEAR
数据类型:float64(65)、int64(41)、object(16)
内存使用量:286.2+ MB
分开处理和分析数值数据和分类数据始终是一种很好的做法。
分类 = app_data.select_dtypes(include = object).columns
app_data[categorical].apply(pd.Series.nunique, 轴 = 0)
只看下面的分类特征,我们发现它们中的大多数只有几个类别,这使得它们更容易使用简单的图进行分析。
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
职业类型 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
紧急状态_模式 2
数据类型:int64
现在对于数值特征,describe() 方法为我们提供了数据的统计信息:
数字= app_data.describe()
数字=数字.列
号码
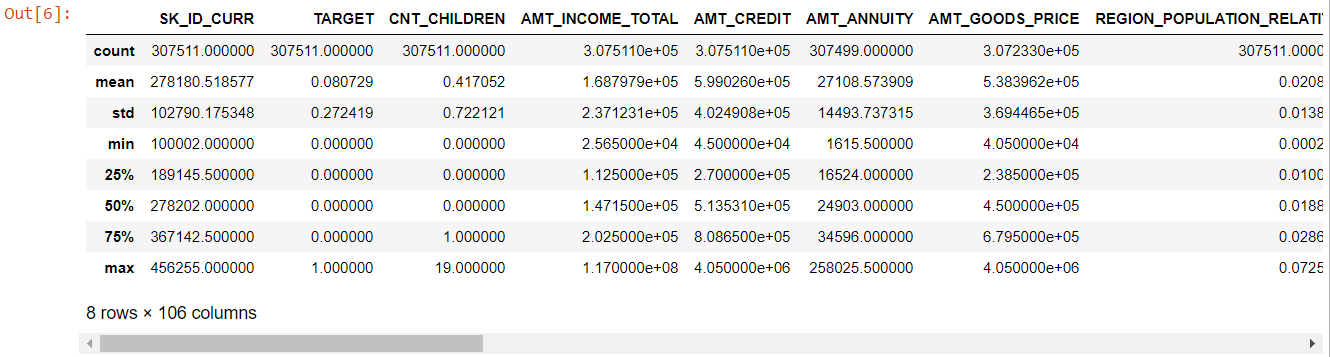
纵观整个表格,很明显:
- days_birth 为负数:申请人相对于申请日的年龄(以天为单位)
- days_employ 有异常值(最大值约为 100 年)(635243)
- amt_annuity- 均值远小于最大值
所以现在我们知道哪些特征需要进一步分析。
缺失数据
我们可以通过沿 Y 轴绘制缺失数据的百分比来绘制所有具有缺失值的特征的点图。

缺失 = pd.DataFrame((app_data.isnull().sum()) * 100 / app_data.shape[0]).reset_index()
plt.figure(figsize = (16,5))
ax = sns.pointplot('index', 0, data = missing)
plt.xticks(旋转 = 90,字体大小 = 7)
plt.title(“缺失值的百分比”)
plt.ylabel(“百分比”)
plt.show()
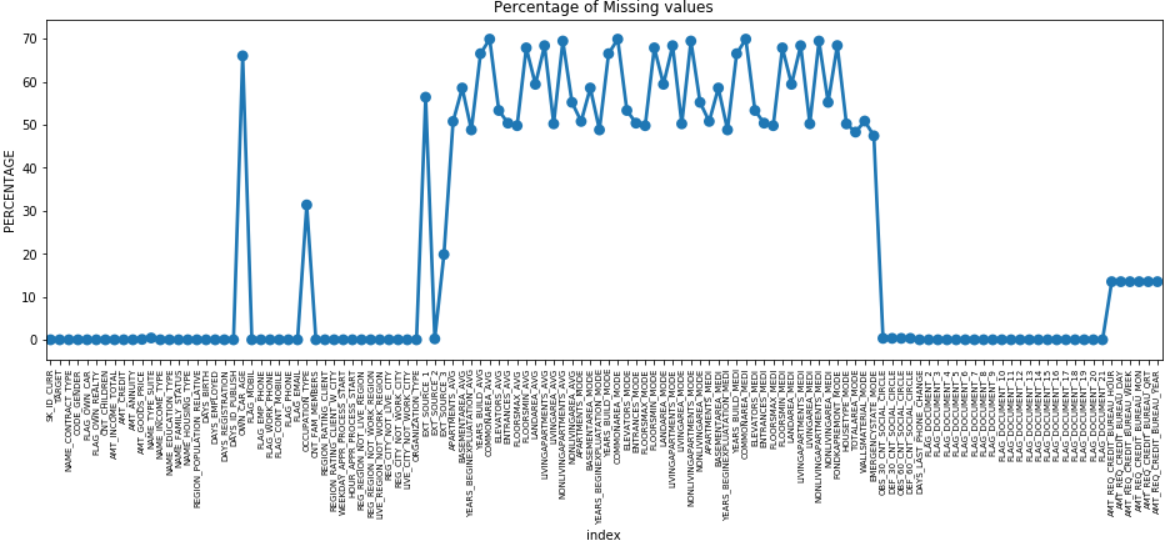
许多列有很多缺失数据 (30-70%),有些缺失数据很少 (13-19%),许多列也根本没有缺失数据。 当您只需要执行 EDA 时,实际上并不需要修改数据集。 但是,继续进行数据预处理,我们应该知道如何处理缺失值。
对于缺失值较少的特征,我们可以使用回归来预测缺失值或填充存在值的平均值,具体取决于特征。 对于具有大量缺失值的特征,最好删除这些列,因为它们对分析的洞察力非常少。
数据不平衡
在这个数据集中,贷款违约者是使用二进制变量“目标”来识别的。
100 * app_data['TARGET'].value_counts() / len(app_data['TARGET'])
0 91.927118
1 8.072882
名称:目标,数据类型:float64
我们看到数据高度不平衡,比例为 92:8。 大部分贷款按时偿还(目标 = 0)。 因此,每当出现如此巨大的不平衡时,最好将特征与目标变量进行比较(目标分析),以确定这些特征中的哪些类别比其他类别更容易拖欠贷款。
下面只是一些可以使用seaborn python 库和简单的用户定义函数制作的图形示例。
性别
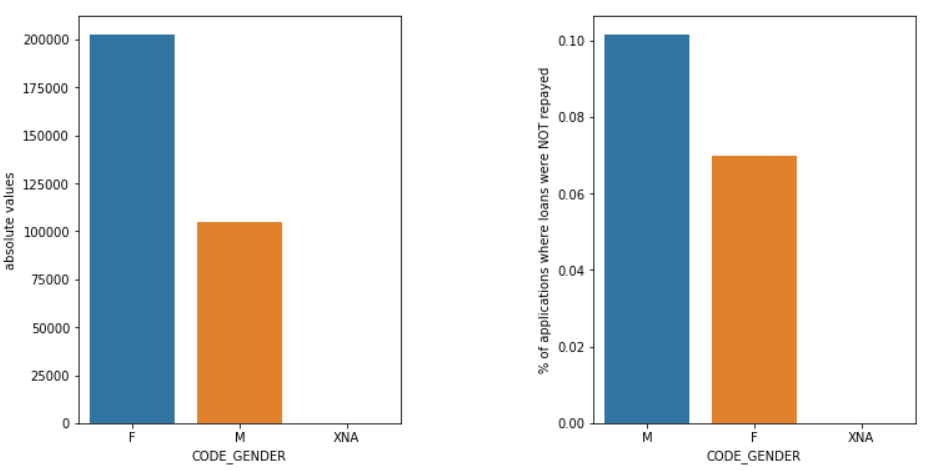
与女性 (F) 相比,男性 (M) 的违约几率更高,尽管女性申请人的数量几乎是其两倍。 所以女性在偿还贷款方面比男性更可靠。
教育类型
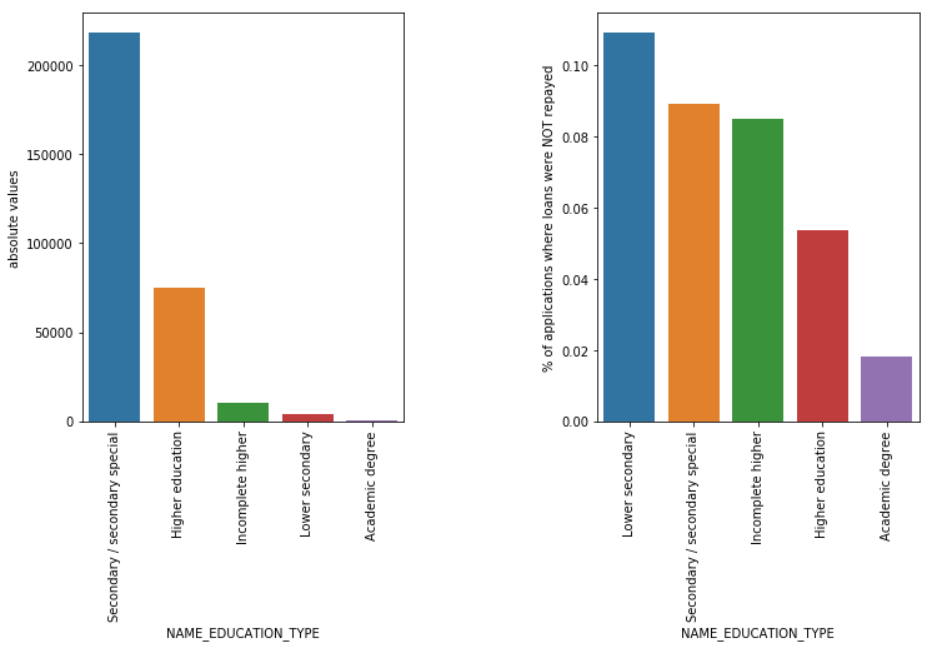
尽管大多数学生贷款用于他们的中学教育或高等教育,但对公司而言风险最大的是初中教育贷款,其次是中学。
另请阅读:数据科学职业
结论
上面看到的这种分析在银行和金融服务的风险分析中得到了广泛的应用。 通过这种方式,可以使用数据存档来最大程度地降低向客户提供贷款时的损失风险。 EDA 在所有其他领域的范围是无穷无尽的,应该广泛使用。
如果您想了解数据科学,请查看 IIIT-B 和 upGrad 的数据科学执行 PG,它是为在职专业人士创建的,提供 10 多个案例研究和项目、实用的实践研讨会、行业专家的指导、1-与行业导师面对面交流,400 多个小时的学习和顶级公司的工作协助。
当您开始对数据进行建模时,探索性数据分析被认为是初始级别。 这是一种非常有见地的技术,可以分析数据建模的最佳实践。 您将能够从数据中提取视觉图、图形和报告,以全面了解它。 异常值是指数据中的异常或细微差异。 它可能在数据收集期间发生。 有 4 种方法可以检测数据集中的异常值。 这些方法如下: 与数据分析不同,EDA 没有严格的规则和规定。 不能说这是执行 EDA 的正确方法或错误方法。 初学者经常被误解并混淆 EDA 和数据分析。为什么需要探索性数据分析 (EDA)?
EDA 涉及到完整分析数据的某些步骤,包括推导统计结果、查找缺失的数据值、处理错误的数据条目,最后推导出各种绘图和图形。
此分析的主要目的是确保您使用的数据集适合开始应用建模算法。 这就是为什么这是您在进入建模阶段之前应该对数据执行的第一步。 什么是异常值以及如何处理它们?
1. Boxplot - Boxplot 是一种检测异常值的方法,我们通过它们的四分位数分离数据。
2. 散点图 - 散点图以笛卡尔平面上标记的点集合的形式显示 2 个变量的数据。 一个变量的值代表水平轴(x-ais),另一个变量的值代表垂直轴(y 轴)。
3. Z-score - 在计算 Z-score 时,我们寻找远离中心的点并将它们视为异常值。
4. 四分位数间距 (IQR) - 四分位数间距或 IQR 是上四分位数和下四分位数或第 75 和第 25 个四分位数之间的差异,通常称为统计离散度。 执行 EDA 的准则是什么?
但是,有一些通常采用的准则:
1.处理缺失值
2.去除重复数据
3. 处理异常值
4. 缩放和规范化
5. 单变量和双变量分析