
什么是 Python 中的探索性数据分析? 从头开始学习
已发表: 2021-03-04简而言之,探索性数据分析或 EDA 占数据科学项目的近 70%。 EDA 是通过使用各种分析工具从数据中获取推断统计数据来探索数据的过程。 这些探索要么通过查看普通数字,要么通过绘制不同类型的图形和图表来完成。
每个图表或图表描绘了不同的故事和对相同数据的角度。 对于大部分数据分析和清洗部分,Pandas 是最常用的工具。 对于可视化和绘制图形/图表,使用了 Matplotlib、Seaborn 和 Plotly 等绘图库。
EDA是非常有必要进行的,因为它让数据向你坦白。 一个做得很好 EDA 的数据科学家对数据有很多了解,因此他们将建立的模型将自动比没有做好 EDA 的数据科学家更好。
在本教程结束时,您将了解以下内容:
- 检查数据的基本概述
- 检查数据的描述性统计
- 操作列名和数据类型
- 处理缺失值和重复行
- 双变量分析
目录
数据基本概述
我们将在本教程中使用汽车数据集,该数据集可以从 Kaggle下载。 几乎所有数据集的第一步都是导入它并检查它的基本概述——它的形状、列、列类型、前 5 行等。这一步让您快速了解您将使用的数据。 让我们看看如何在 Python 中做到这一点。
| # 导入需要的库 将熊猫导入为pd 将numpy导入为np 将seaborn导入为sns #visualisation 将matplotlib.pyplot导入为plt #visualisation %matplotlib 内联 sns.set(color_codes=真) |
数据头尾
| 数据 = pd.read_csv( “路径/数据集.csv” ) # 检查数据框的前 5 行 数据头() |
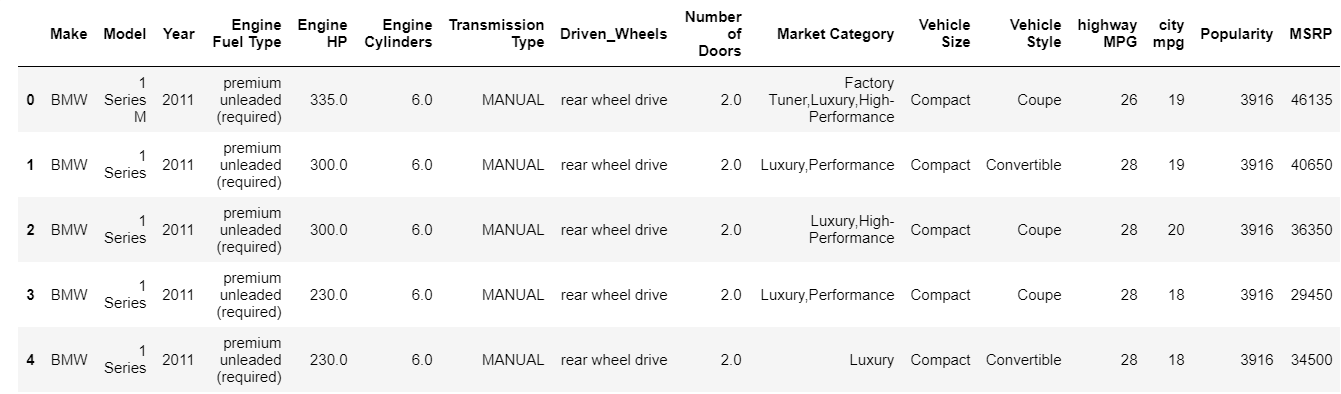
head 函数默认打印数据帧的前 5 个索引。 您还可以指定绕过该值到头部需要查看多少个顶级索引。 立即打印头部可以让我们快速查看我们拥有的数据类型、存在的特征类型以及它们包含的值。 当然,这并不能说明数据的全部内容,但它确实让您快速浏览了数据。 您可以使用 tail 函数类似地打印数据框的底部。
| # 打印数据框的最后 10 行 数据尾( 10 ) |
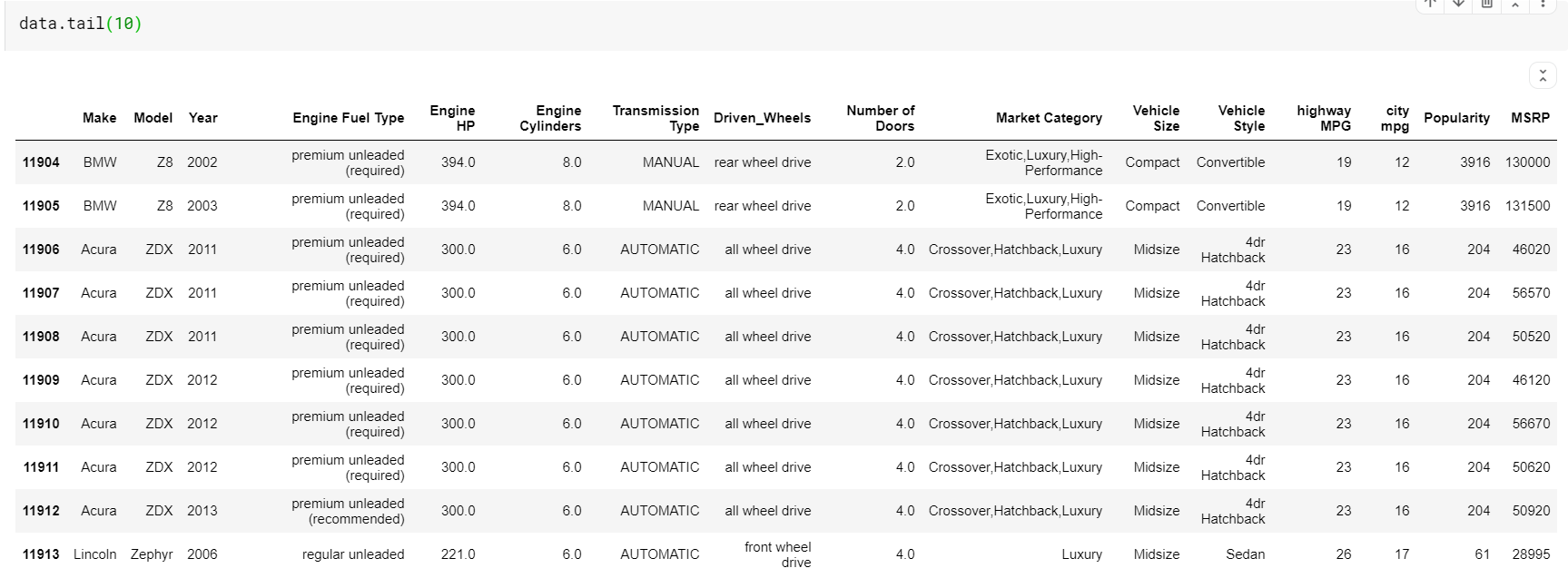
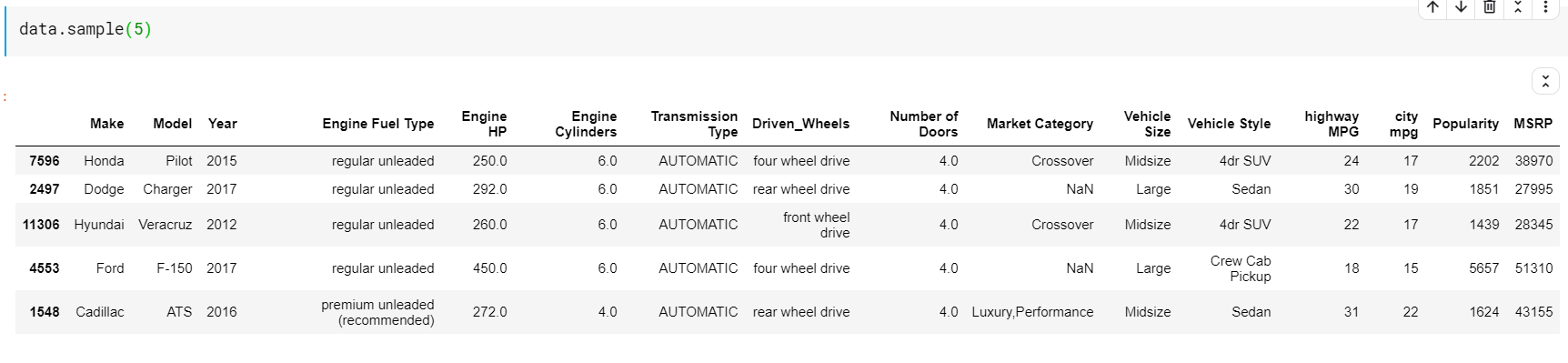
这里要注意的一件事是函数头和尾都为我们提供了顶部或底部索引。 但顶行或底行并不总是数据的良好预览。 因此,您还可以使用 sample() 函数打印从数据集中随机采样的任意数量的行。
| # 随机打印 5 行 数据样本( 5 ) |
描述性统计
接下来,让我们看看数据集的描述性统计数据。 描述性统计数据包含“描述”数据集的所有内容。 我们检查数据框的形状,所有列都存在,所有数字和分类特征都有哪些。 我们还将看到如何在简单的函数中完成所有这些工作。
形状
| # 检查数据框形状 (mxn) # m=行数 # n=列数 数据形状 |

如我们所见,这个数据框包含 11914 行和 16 列。
列
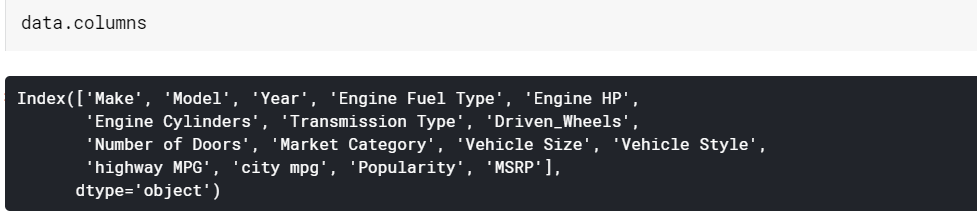
| # 打印列名 数据列 |
数据框信息
| # 打印列数据类型和非缺失值个数 数据信息() |
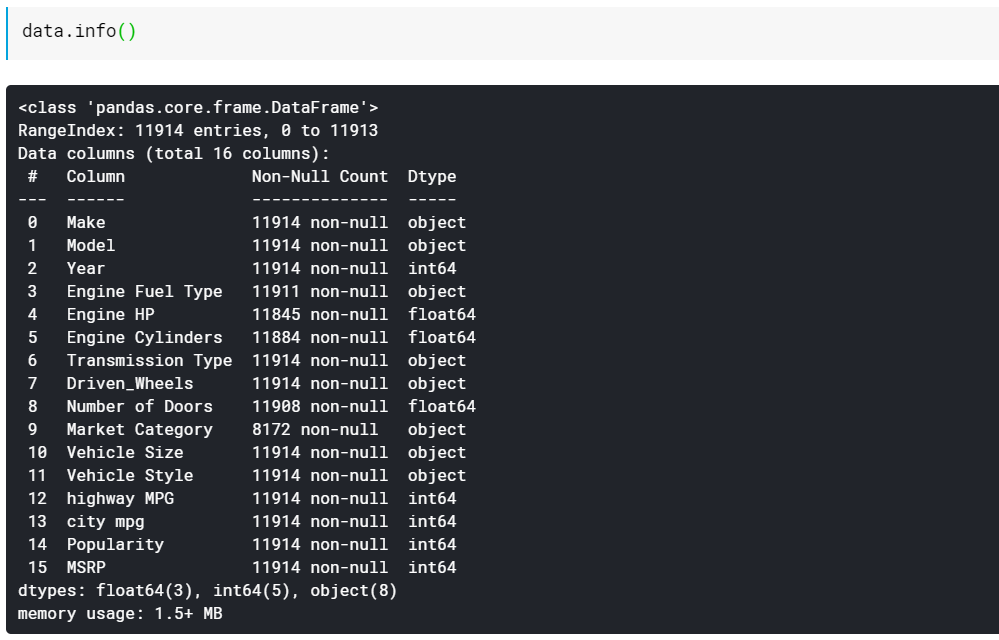
如您所见,info() 函数为我们提供了所有列,这些列中有多少非空或非缺失值,最后是这些列的数据类型。 这是查看所有特征都是数字的以及所有特征都是基于分类/文本的一种很好的快速方法。 此外,我们现在有关于所有列有哪些缺失值的信息。 稍后我们将研究如何处理缺失值。
操作列名和数据类型
仔细检查和操作每一列在 EDA 中非常重要。 我们需要查看列/特征包含的所有类型的内容以及 pandas 读取其数据类型的内容。 数值数据类型主要是 int64 或 float64。 基于文本或分类的特征被分配了“对象”数据类型。
分配基于日期时间的特征 有时 Pandas 不理解特征的数据类型。 在这种情况下,它只是懒惰地为其分配“对象”数据类型。 我们可以在使用 read_csv 读取数据时明确指定列数据类型。
选择分类和数值列
| # 将所有分类和数字列添加到单独的列表中 分类 = data.select_dtypes( 'object' ).columns 数值 = data.select_dtypes( 'number' ).columns |


在这里,我们作为“数字”传递的类型选择所有具有任何数字类型的数据类型的列 - 无论是 int64 还是 float64。
重命名列
| # 重命名列名 data = data.rename(columns={ “引擎 HP” : “HP” , “发动机气缸” : “气缸” , “传输类型” : “传输” , “Driven_Wheels” : “驱动模式” , “高速公路 MPG” : “MPG-H” , “厂商建议零售价” : “价格” }) 数据头( 5 ) |

rename 函数只接受一个字典,其中包含要重命名的列名及其新名称。
处理缺失值和重复行
缺失值是任何现实生活数据集中最常见的问题/差异之一。 处理缺失值本身就是一个很大的话题,因为有多种方法可以做到这一点。 有些方法是更通用的方法,有些方法更具体到一个可能正在处理的数据集。
检查缺失值
| # 检查缺失值 data.isnull().sum() |
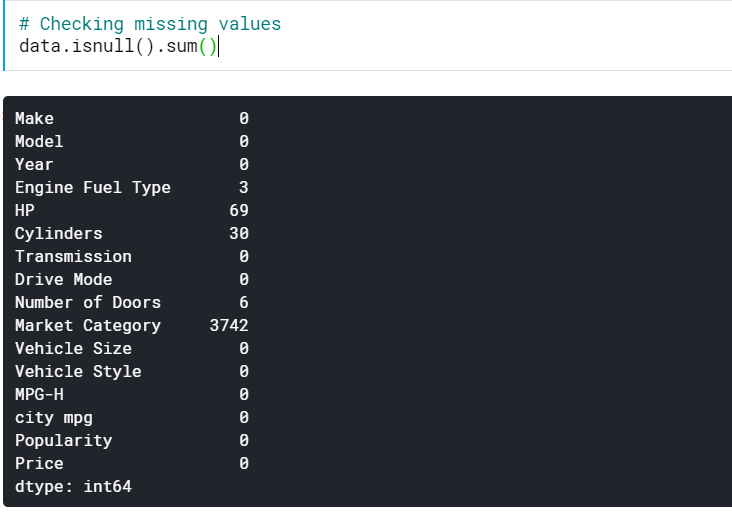
这为我们提供了所有列中缺少的值的数量。 我们还可以看到缺失值的百分比。
| # 缺失值的百分比 数据.isnull().mean()* 100 |
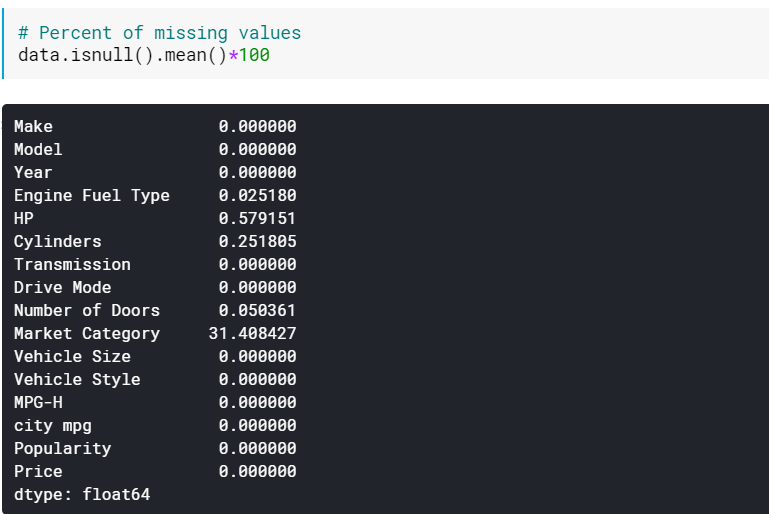
当有很多列缺失值时,检查百分比可能很有用。 在这种情况下,可以删除具有大量缺失值(例如,>60% 缺失)的列。
插补缺失值
| #按均值估算数值列的缺失值 数据[数值] = 数据[数值].fillna(数据[数值].mean().iloc[ 0 ]) #按模式估算分类列的缺失值 数据[分类] = 数据[分类].fillna(数据[分类].mode().iloc[ 0 ]) |
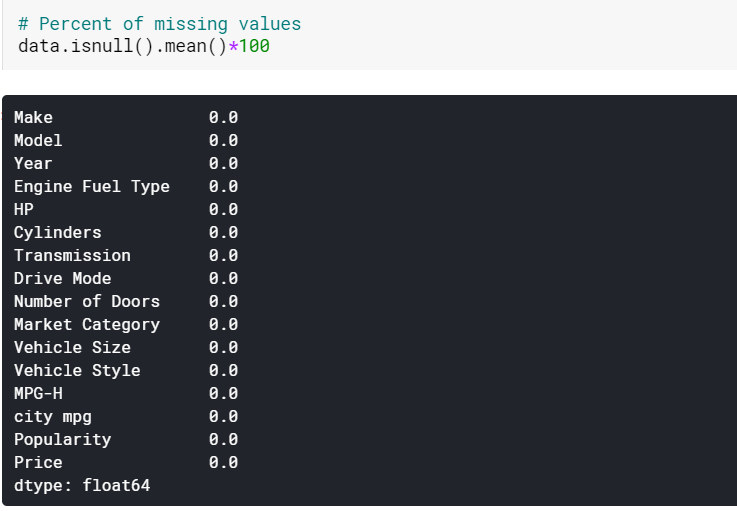
在这里,我们简单地通过它们各自的方式来估算数字列中的缺失值,并通过它们的模式来估算分类列中的缺失值。 正如我们所看到的,现在没有缺失值。
请注意,这是估算值的最原始方法,在开发更复杂方法(例如插值、KNN 等)的实际案例中不起作用。
处理重复行
| # 删除重复行 data.drop_duplicates(就地=真) |
这只会删除重复的行。
结帐: Python 项目的想法和主题
双变量分析
现在让我们看看如何通过双变量分析获得更多见解。 双变量是指由 2 个变量或特征组成的分析。 有不同类型的绘图可用于不同类型的功能。
对于数值 - 数值
- 散点图
- 线图
- 相关性的热图
对于分类数值
- 条形图
- 小提琴情节
- 群体图
对于分类-分类
- 条形图
- 点图
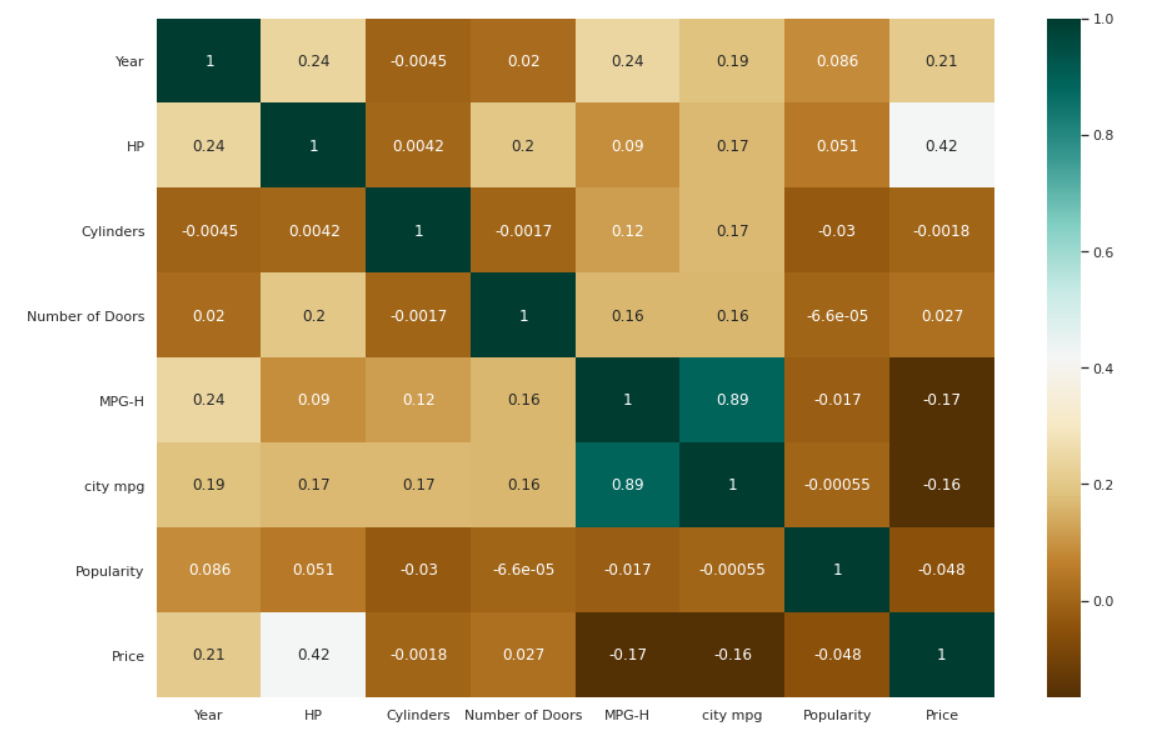
相关性的热图
| # 检查变量之间的相关性。 plt.figure(figsize=( 15 , 10 )) c=data.corr() sns.heatmap(c,cmap= “BrBG” ,annot= True ) |
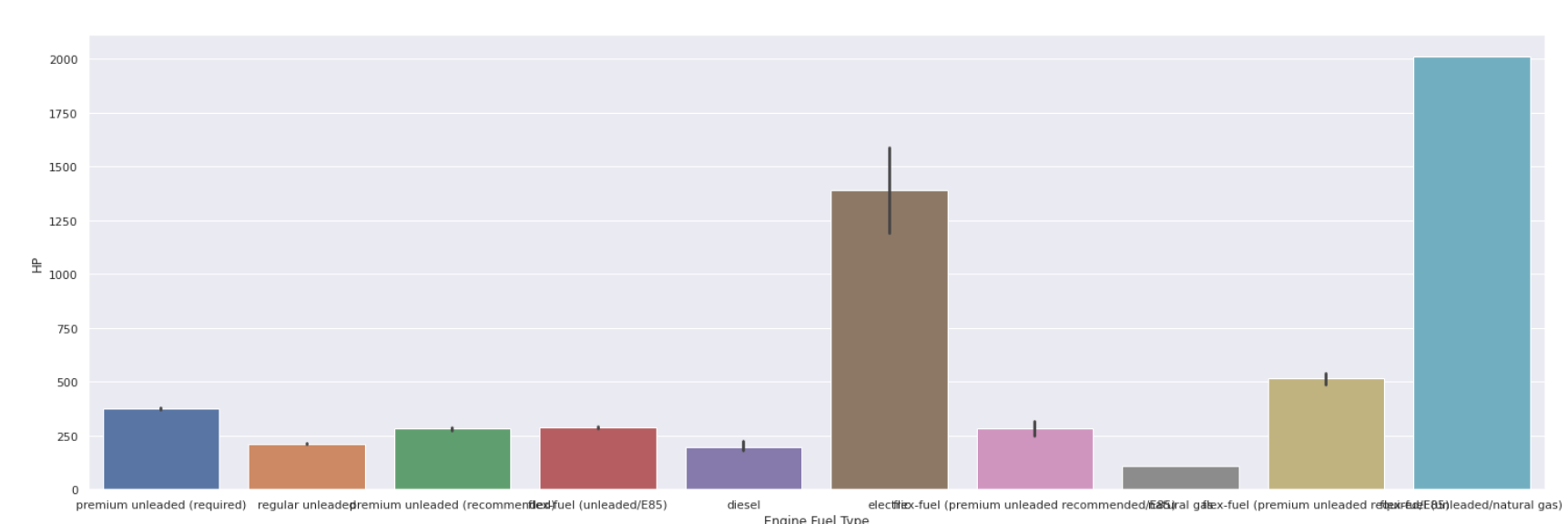
条形图
| sns.barplot(数据[ '发动机燃料类型' ],数据[ 'HP' ]) |
获得世界顶尖大学的数据科学认证。 学习行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。
结论
正如我们所看到的,在探索数据集时需要涵盖很多步骤。 我们在本教程中只介绍了少数几个方面,但这会给您提供的不仅仅是良好 EDA 的基本知识。
如果您想了解 Python 以及有关数据科学的所有知识,请查看 IIIT-B 和 upGrad 的数据科学 PG 文凭,该文凭专为在职专业人士而设,提供 10 多个案例研究和项目、实用的实践研讨会、行业指导专家,与行业导师一对一,400 多个小时的学习和顶级公司的工作协助。
探索性数据分析的步骤是什么?
进行探索性数据分析所需执行的主要步骤是 -
必须识别变量和数据类型。
分析基本指标
单变量非图形分析
单变量图形分析
双变量数据分析
可变的变换
缺失值处理
异常值的处理
相关性分析
降维
探索性数据分析的目的是什么?
EDA 的主要目标是在做出任何假设之前协助分析数据。 它可以帮助检测明显的错误,更好地理解数据模式,检测异常值或异常事件,以及发现变量之间的有趣关系。
数据科学家可以使用探索性分析来保证他们创建的结果准确且适合任何有针对性的业务成果和目标。 EDA 还通过确保他们解决适当的问题来帮助利益相关者。 标准偏差、分类数据和置信区间都可以用 EDA 来回答。 在完成 EDA 并提取见解后,其功能可应用于更高级的数据分析或建模,包括机器学习。
探索性数据分析有哪些不同类型?
有两种 EDA 技术:图形和定量(非图形)。 另一方面,定量方法需要汇总统计数据,而图形方法需要以图表或可视方式收集数据。 单变量和多变量方法是这两种方法的子集。
为了研究关系,单变量方法一次查看一个变量(数据列),而多变量方法一次查看两个或多个变量。 单变量和多变量图形和非图形是 EDA 的四种形式。 定量程序更客观,而图像方法更主观。