
使用 Node.js 和 Puppeteer 对动态网站进行道德抓取的指南
已发表: 2022-03-10让我们从关于网络抓取实际含义的一小部分开始。 我们所有人都在日常生活中使用网络抓取。 它仅描述了从网站中提取信息的过程。 因此,如果您将您最喜欢的面条菜谱从互联网上复制并粘贴到您的个人笔记本上,您就是在执行网络抓取。
在软件行业中使用这个术语时,我们通常指的是通过使用一个软件来自动化这个手动任务。 以我们之前的“面条”为例,这个过程通常包括两个步骤:
- 获取页面
我们首先必须下载整个页面。 这一步就像手动抓取时在网络浏览器中打开页面一样。 - 解析数据
现在,我们必须在网站的 HTML 中提取配方,并将其转换为机器可读的格式,如 JSON 或 XML。
过去,我曾在多家公司担任数据顾问。 我很惊讶地看到有多少数据提取、聚合和丰富任务仍然是手动完成的,尽管它们可以很容易地通过几行代码实现自动化。 这正是网络抓取对我而言的全部意义:从网站中提取和规范有价值的信息,以推动另一个价值驱动的业务流程。
在此期间,我看到公司使用网络抓取来处理各种用例。 投资公司主要专注于收集替代数据,如产品评论、价格信息或社交媒体帖子,以支持他们的金融投资。
这是一个例子。 一位客户找到我,从多个电子商务网站上抓取产品评论数据,以获取大量产品列表,包括评级、评论者的位置以及每条提交评论的评论文本。 结果数据使客户能够识别产品在不同市场的流行趋势。 这是一个很好的例子,说明与大量信息相比,看似“无用”的单条信息如何变得有价值。
其他公司通过使用网络抓取来产生潜在客户来加速他们的销售过程。 此过程通常涉及为给定的网站列表提取联系信息,例如电话号码、电子邮件地址和联系人姓名。 自动执行此任务使销售团队有更多时间接近潜在客户。 因此,销售过程的效率提高了。
遵守规则
一般来说,网络抓取公开可用数据是合法的,正如 Linkedin 与 HiQ 案件的管辖权所证实的那样。 但是,我为自己设定了一套道德规则,我喜欢在开始一个新的网络抓取项目时遵守这些规则。 这包括:
- 检查 robots.txt 文件。
它通常包含有关页面所有者可以被机器人和抓取工具访问的网站的哪些部分的明确信息,并突出显示不应访问的部分。 - 阅读条款和条件。
与 robots.txt 相比,这条信息的可用频率并不低,但通常会说明他们如何处理数据抓取工具。 - 以中等速度刮擦。
抓取会在目标站点的基础架构上创建服务器负载。 根据您抓取的内容以及您的抓取工具运行的并发级别,流量可能会导致目标站点的服务器基础架构出现问题。 当然,服务器容量在这个等式中起着重要作用。 因此,我的抓取工具的速度始终是我旨在抓取的数据量和目标网站的受欢迎程度之间的平衡。 找到这种平衡可以通过回答一个问题来实现:“计划的速度会显着改变网站的自然流量吗?”。 如果我不确定网站的自然流量,我会使用 ahrefs 之类的工具来大致了解一下。
选择正确的技术
事实上,使用无头浏览器进行抓取是您可以使用的性能最低的技术之一,因为它会严重影响您的基础架构。 您机器处理器的一个内核大约可以处理一个 Chrome 实例。
让我们做一个快速的示例计算,看看这对现实世界的网络抓取项目意味着什么。
设想
- 你想抓取 20,000 个 URL。
- 目标站点的平均响应时间为 6 秒。
- 您的服务器有 2 个 CPU 内核。
该项目将需要16个小时才能完成。
因此,在对动态网站进行抓取可行性测试时,我总是尽量避免使用浏览器。
这是我经常检查的一个小清单:
- 我可以通过 URL 中的 GET 参数强制要求的页面状态吗? 如果是,我们可以简单地运行带有附加参数的 HTTP 请求。
- 页面源的动态信息部分是否可以通过 DOM 中某处的 JavaScript 对象获得? 如果是,我们可以再次使用正常的 HTTP 请求并从字符串化对象中解析数据。
- 数据是通过 XHR 请求获取的吗? 如果是这样,我可以使用 HTTP 客户端直接访问端点吗? 如果是,我们可以直接向端点发送 HTTP 请求。 很多时候,响应甚至被格式化为 JSON,这让我们的生活变得更加轻松。
如果所有问题都以明确的“否”回答,我们正式用完了使用 HTTP 客户端的可行选项。 当然,我们可以尝试更多特定于站点的调整,但通常情况下,与无头浏览器的较慢性能相比,找出它们所需的时间太长了。 使用浏览器抓取的美妙之处在于,您可以抓取符合以下基本规则的任何内容:
如果您可以使用浏览器访问它,则可以抓取它。
让我们以以下站点为例,我们的爬虫:https://quotes.toscrape.com/search.aspx。 它包含来自给定作者列表的主题列表的引用。 所有数据都是通过 XHR 获取的。
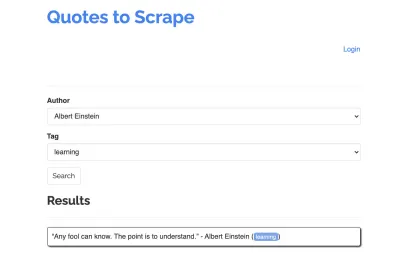
无论谁仔细查看了网站的功能并查看了上面的清单,都可能意识到实际上可以使用 HTTP 客户端抓取报价,因为可以通过直接在报价端点上发出 POST 请求来检索报价。 但是由于本教程应该介绍如何使用 Puppeteer 抓取网站,我们将假装这是不可能的。
安装先决条件
由于我们将使用 Node.js 构建所有内容,因此我们首先创建并打开一个新文件夹,并在其中创建一个新的 Node 项目,运行以下命令:
mkdir js-webscraper cd js-webscraper npm init请确保您已经安装了 npm。 安装程序会问我们一些关于这个项目的元信息的问题,我们都可以跳过,点击Enter 。
安装 Puppeteer
我们之前一直在谈论使用浏览器进行抓取。 Puppeteer 是一个 Node.js API,它允许我们以编程方式与无头 Chrome 实例对话。
让我们使用 npm 安装它:
npm install puppeteer建造我们的刮刀
现在,让我们通过创建一个名为scraper.js的新文件来开始构建我们的爬虫。
首先,我们导入之前安装的库 Puppeteer:
const puppeteer = require('puppeteer');下一步,我们告诉 Puppeteer 在异步和自执行函数中打开一个新的浏览器实例:
(async function scrape() { const browser = await puppeteer.launch({ headless: false }); // scraping logic comes here… })();注意:默认情况下,无头模式是关闭的,因为这会提高性能。 但是,在构建新的爬虫时,我喜欢关闭无头模式。 这使我们能够跟踪浏览器正在经历的过程并查看所有呈现的内容。 这将帮助我们稍后调试我们的脚本。
在我们打开的浏览器实例中,我们现在打开一个新页面并指向我们的目标 URL:
const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); 作为异步函数的一部分,我们将使用await语句等待执行以下命令,然后再继续执行下一行代码。
现在我们已经成功打开浏览器窗口并导航到页面,我们必须创建网站的状态,以便可以看到所需的信息片段以供抓取。
可用主题是为选定的作者动态生成的。 因此,我们将首先选择“Albert Einstein”并等待生成的主题列表。 列表完全生成后,我们选择“学习”作为主题,并将其作为第二个表单参数。 然后我们单击提交并从保存结果的容器中提取检索到的报价。
由于我们现在将其转换为 JavaScript 逻辑,因此我们首先列出我们在上一段中讨论过的所有元素选择器:
| 作者选择字段 | #author |
| 标记选择字段 | #tag |
| 提交按钮 | input[type="submit"] |
| 报价容器 | .quote |
在我们开始与页面交互之前,我们将确保我们将访问的所有元素都是可见的,方法是在我们的脚本中添加以下行:
await page.waitForSelector('#author'); await page.waitForSelector('#tag');接下来,我们将为我们的两个选择字段选择值:
await page.select('select#author', 'Albert Einstein'); await page.select('select#tag', 'learning');我们现在准备好通过点击页面上的“搜索”按钮进行搜索,然后等待报价出现:
await page.click('.btn'); await page.waitForSelector('.quote'); 因为我们现在要访问页面的 HTML DOM 结构,所以我们调用提供的page.evaluate()函数,选择包含引号的容器(在这种情况下只有一个)。 然后我们构建一个对象并将 null 定义为每个object参数的后备值:
let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, }; }); return quotes; });我们可以通过记录它们使所有结果在我们的控制台中可见:

console.log(quotes);最后,让我们关闭浏览器并添加一条 catch 语句:
await browser.close();完整的刮板如下所示:
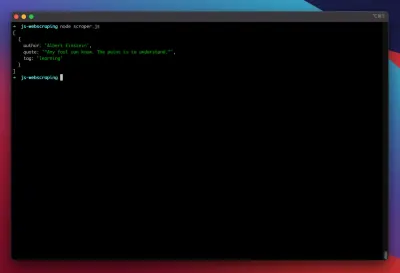
const puppeteer = require('puppeteer'); (async function scrape() { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('#author'); await page.select('#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); // logging results console.log(quotes); await browser.close(); })();让我们尝试运行我们的爬虫:
node scraper.js我们去吧! 刮板按预期返回我们的报价对象:
高级优化
我们的基本刮板现在正在工作。 让我们添加一些改进,为一些更严重的抓取任务做好准备。
设置用户代理
默认情况下,Puppeteer 使用包含字符串HeadlessChrome的用户代理。 相当多的网站会寻找这种签名并阻止带有类似签名的传入请求。 为了避免这种情况成为刮板失败的潜在原因,我总是通过在我们的代码中添加以下行来设置自定义用户代理:
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');这可以通过从前 5 个最常见的用户代理的数组中为每个请求选择一个随机的用户代理来进一步改进。 最常见的用户代理列表可以在最常见的用户代理中找到。
实现代理
Puppeteer 使连接到代理非常容易,因为代理地址可以在启动时传递给 Puppeteer,如下所示:
const browser = await puppeteer.launch({ headless: false, args: [ '--proxy-server=<PROXY-ADDRESS>' ] });sslproxies 提供了大量免费代理供您使用。 或者,可以使用轮换代理服务。 由于代理通常在许多客户(或本例中的免费用户)之间共享,因此连接变得比正常情况下更加不可靠。 这是讨论错误处理和重试管理的最佳时机。
错误和重试管理
很多因素都会导致您的刮刀失败。 因此,重要的是要处理错误并决定在发生故障时应该发生什么。 由于我们已将爬虫连接到代理,并且预计连接会不稳定(尤其是因为我们使用的是免费代理),因此我们希望在放弃之前重试四次。
此外,如果以前失败了,再次重试具有相同 IP 地址的请求是没有意义的。 因此,我们将构建一个小型代理旋转系统。
首先,我们创建两个新变量:
let retry = 0; let maxRetries = 5; 每次我们运行我们的函数scrape()时,我们都会将我们的重试变量增加 1。然后我们用 try 和 catch 语句包装我们完整的抓取逻辑,以便我们可以处理错误。 重试管理发生在我们的catch函数中:
之前的浏览器实例将被关闭,如果我们的 retry 变量小于我们的maxRetries变量,则递归调用 scrape 函数。
我们的刮板现在看起来像这样:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); … // our scraping logic } catch(e) { console.log(e); await browser.close(); if (retry < maxRetries) { scrape(); } };现在,让我们添加前面提到的代理旋转器。
让我们首先创建一个包含代理列表的数组:
let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ];现在,从数组中选择一个随机值:
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];我们现在可以将动态生成的代理与我们的 Puppeteer 实例一起运行:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] });当然,这个代理轮换器可以进一步优化以标记死代理等等,但这肯定超出了本教程的范围。
这是我们刮板的代码(包括所有改进):
const puppeteer = require('puppeteer'); // starting Puppeteer let retry = 0; let maxRetries = 5; (async function scrape() { retry++; let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ]; var proxy = proxyList[Math.floor(Math.random() * proxyList.length)]; console.log('proxy: ' + proxy); const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36'); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('select#author'); await page.select('select#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('select#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); console.log(quotes); await browser.close(); } catch (e) { await browser.close(); if (retry < maxRetries) { scrape(); } } })();瞧! 在我们的终端中运行我们的爬虫将返回引号。
剧作家作为木偶戏的替代品
Puppeteer 是由 Google 开发的。 2020 年初,微软发布了一款名为 Playwright 的替代品。 微软从 Puppeteer-Team 挖了很多工程师。 因此,Playwright 是由许多已经在 Puppeteer 上工作的工程师开发的。 除了作为博客上的新手之外,Playwright 最大的不同之处在于跨浏览器支持,因为它支持 Chromium、Firefox 和 WebKit (Safari)。
性能测试(例如 Checkly 进行的测试)表明,与 Playwright 相比,Puppeteer 的性能通常提高了 30%,这与我自己的经验相符——至少在撰写本文时是这样。
其他差异,例如您可以使用一个浏览器实例运行多个设备这一事实,对于网络抓取的上下文而言并不真正有价值。
资源和附加链接
- Puppeteer 文档
- 学习木偶剧作家
- Zenscrape 使用 Javascript 进行网页抓取
- 最常见的用户代理
- 木偶师与剧作家