
向 JAMstack 站点添加动态和异步功能
已发表: 2022-03-10这是否意味着 JAMstack 站点无法处理动态交互? 当然不!
JAMstack 站点非常适合创建高度动态的异步交互。 通过对我们对代码的思考方式进行一些小的调整,我们可以仅使用静态资产创建有趣的、身临其境的交互!
使用 JAMstack 构建的网站越来越常见,即可以作为静态 HTML 文件提供服务的网站,这些文件由 JavaScript、标记和 API 构建而成。 公司喜欢 JAMstack,因为它降低了基础设施成本、加快交付速度并降低了性能和安全性改进的障碍,因为交付静态资产消除了扩展服务器或保持数据库高可用性的需要(这也意味着没有服务器或数据库可以被黑客攻击)。 开发人员喜欢 JAMstack,因为它降低了在 Internet 上运行网站的复杂性:无需管理或部署服务器; 我们可以编写前端代码,它就像魔术一样上线。
(在这种情况下,“魔术”是自动静态部署,许多公司都可以免费使用,包括我工作的 Netlify。)
但是如果你花很多时间与开发人员谈论 JAMstack,那么 JAMstack 是否可以处理严重的 Web 应用程序的问题就会出现。 毕竟,JAMstack 站点是静态站点,对吧? 静态网站的功能不是超级有限吗?
这是一个非常普遍的误解,在本文中,我们将深入探讨误解的来源,查看 JAMstack 的功能,并通过几个使用 JAMstack 构建严重 Web 应用程序的示例。
JAMstack 基础知识
Phil Hawksworth 解释了 JAMStack 的实际含义,何时在您的项目中使用它有意义,以及它如何影响工具和前端架构。 阅读相关文章 →
是什么让 JAMstack 网站“静态”?
今天的 Web 浏览器加载 HTML、CSS 和 JavaScript 文件,就像它们在 90 年代所做的一样。
JAMstack 站点的核心是一个包含 HTML、CSS 和 JavaScript 文件的文件夹。
这些是“静态资产”,这意味着我们不需要中间步骤来生成它们(例如,像 WordPress 这样的 PHP 项目需要一个服务器来为每个请求生成HTML)。
这就是 JAMstack 的真正威力:它不需要任何专门的基础架构即可工作。 您可以在本地计算机上运行 JAMstack 站点,将其放在您首选的内容交付网络 (CDN) 上,使用 GitHub Pages 等服务托管它——您甚至可以将文件夹拖放到您最喜欢的 FTP 客户端中以上传它共享主机。
静态资产不一定意味着静态体验
因为 JAMstack 站点是由静态文件组成的,所以很容易假设这些站点上的体验是静态的。 但事实并非如此!
JavaScript 能够做很多动态的事情。 毕竟,在我们完成构建步骤之后,现代 JavaScript 框架是静态文件——并且有数百个由它们提供支持的令人难以置信的动态网站体验示例。
有一个普遍的误解,认为“静态”意味着不灵活或固定。 但是,在“静态站点”的上下文中,“静态”的真正含义是浏览器不需要任何帮助来传递它们的内容——它们可以在本地使用它们,而无需服务器首先处理处理步骤。
或者,换一种说法:
“静态资产”不代表静态应用; 这意味着不需要服务器。
“
JAMstack 能做到吗?
如果有人询问有关构建新应用程序的问题,通常会看到有关 JAMstack 方法的建议,例如 Gatsby、Eleventy、Nuxt 和其他类似工具。 同样常见的反对意见是:“静态站点生成器不能做 _______”,其中 _______ 是动态的。
但是——正如我们在上一节中提到的——JAMstack 站点可以处理动态内容和交互!
这是我反复听到人们声称 JAMstack 无法处理它绝对可以处理的事情的不完整列表:
- 异步加载数据
- 处理处理文件,例如处理图像
- 读取和写入数据库
- 处理用户身份验证并保护登录后的内容
在以下部分中,我们将了解如何在 JAMstack 站点上实现这些工作流中的每一个。
如果您迫不及待地想看看动态 JAMstack 的运行情况,您可以先查看演示,然后再回来了解它们的工作原理。
关于演示的说明:
这些演示是在没有任何框架的情况下编写的。 它们只是 HTML、CSS 和标准 JavaScript。 它们在构建时考虑了现代浏览器(例如 Chrome、Firefox、Safari、Edge),并利用了 JavaScript 模块、HTML 模板和 Fetch API 等新功能。 没有添加任何 polyfill,因此如果您使用的是不受支持的浏览器,演示可能会失败。
从第三方 API 异步加载数据
“如果我在构建静态文件后需要获取新数据怎么办?”
在 JAMstack 中,我们可以利用众多异步请求库,包括内置的 Fetch API,随时使用 JavaScript 加载数据。
演示:从 JAMstack 站点搜索第三方 API
需要异步加载的常见场景是当我们需要的内容取决于用户输入时。 例如,如果我们为Rick & Morty API构建一个搜索页面,在有人输入搜索词之前我们不知道要显示什么内容。
为了解决这个问题,我们需要:
- 创建一个表单,人们可以在其中输入搜索词,
- 收听表单提交,
- 从表单提交中获取搜索词,
- 使用搜索词向 Rick & Morty API 发送异步请求,
- 在页面上显示请求结果。
首先,我们需要创建一个表单和一个包含搜索结果的空元素,如下所示:
<form> <label for="name">Find characters by name</label> <input type="text" name="name" required /> <button type="submit">Search</button> </form> <ul></ul>接下来,我们需要编写一个处理表单提交的函数。 该功能将:
- 防止默认的表单提交行为
- 从表单输入中获取搜索词
- 使用 Fetch API 通过搜索词向 Rick & Morty API 发送请求
- 调用在页面上显示搜索结果的辅助函数
我们还需要在表单上为调用我们的处理函数的提交事件添加一个事件监听器。
下面是这段代码的样子:
<script type="module"> import showResults from './show-results.js'; const form = document.querySelector('form'); const handleSubmit = async event => { event.preventDefault(); // get the search term from the form input const name = form.elements['name'].value; // send a request to the Rick & Morty API based on the user input const characters = await fetch( `https://rickandmortyapi.com/api/character/?name=${name}`, ) .then(response => response.json()) .catch(error => console.error(error)); // add the search results to the DOM showResults(characters.results); }; form.addEventListener('submit', handleSubmit); </script>注意:为了专注于动态 JAMstack 行为,我们不会讨论如何编写 showResults 等实用函数。 不过,该代码已被彻底注释,因此请查看源代码以了解其工作原理!
有了这段代码,我们可以在浏览器中加载我们的网站,我们将看到没有结果显示的空表单:
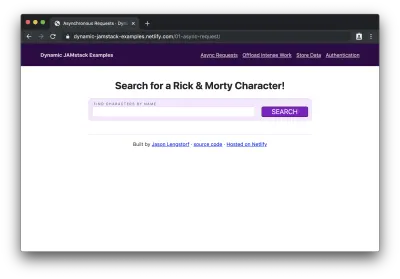
如果我们输入一个角色名称(例如“rick”)并单击“search”,我们会看到名称中包含“rick”的角色列表:
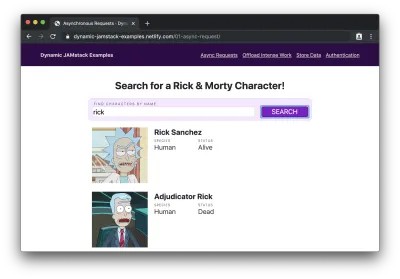
嘿! 那个静态站点只是动态加载数据吗? 圣水桶!
您可以在现场演示中亲自尝试,或查看完整的源代码以获取更多详细信息。
在用户设备外处理昂贵的计算任务
在许多应用程序中,我们需要做一些资源密集型的事情,例如处理图像。 虽然其中一些类型的操作仅使用客户端 JavaScript 是可能的,但让用户的设备完成所有这些工作并不一定是个好主意。 如果他们使用的是低功率设备或试图延长最后 5% 的电池寿命,那么让他们的设备完成大量工作可能会让他们感到沮丧。
那么这是否意味着 JAMstack 应用程序不走运? 一点也不!
JAMstack 中的“A”代表 API。 这意味着我们可以将这项工作发送到 API,并避免将用户的计算机风扇旋转到“悬停”设置。
“但是等等,”你可能会说。 “如果我们的应用程序需要进行自定义工作,而这项工作需要 API,那不就意味着我们正在构建一个服务器吗?”
由于无服务器功能的强大功能,我们不必这样做!
无服务器函数(也称为“lambda 函数”)是一种不需要任何服务器样板的 API。 我们开始编写一个普通的旧 JavaScript 函数,所有部署、扩展、路由等工作都卸载到我们选择的无服务器提供商。
使用无服务器功能并不意味着没有服务器。 它只是意味着我们不需要考虑服务器。
“
无服务器函数是我们 JAMstack 的花生酱:它们无需我们处理服务器代码或 devops 就可以解锁整个世界的高性能、动态功能。
演示:将图像转换为灰度
假设我们有一个应用程序需要:
- 从 URL 下载图像
- 将该图像转换为灰度
- 将转换后的图像上传到 GitHub 存储库
据我所知,没有办法完全在浏览器中进行这样的图像转换——即使有,这也是一项相当耗费资源的事情,所以我们可能不想把这种负载放在我们的用户身上' 设备。
相反,我们可以将要转换的 URL 提交到无服务器函数,这将为我们完成繁重的工作并将 URL 发送回转换后的图像。
对于我们的无服务器函数,我们将使用 Netlify 函数。 在我们网站的代码中,我们在根级别添加一个名为“functions”的文件夹,并在其中创建一个名为“convert-image.js”的新文件。 然后我们编写所谓的处理程序,它接收并 - 正如您可能已经猜到的那样 -处理对我们的无服务器函数的请求。
要转换图像,它看起来像这样:
exports.handler = async event => { // only try to handle POST requests if (event.httpMethod !== 'POST') { return { statusCode: 404, body: '404 Not Found' }; } try { // get the image URL from the POST submission const { imageURL } = JSON.parse(event.body); // use a temporary directory to avoid intermediate file cruft // see https://www.npmjs.com/package/tmp const tmpDir = tmp.dirSync(); const convertedPath = await convertToGrayscale(imageURL, tmpDir); // upload the processed image to GitHub const response = await uploadToGitHub(convertedPath, tmpDir.name); return { statusCode: 200, body: JSON.stringify({ url: response.data.content.download_url, }), }; } catch (error) { return { statusCode: 500, body: JSON.stringify(error.message), }; } };此函数执行以下操作:
- 检查以确保请求是使用 HTTP POST 方法发送的
- 从 POST 正文中获取图像 URL
- 创建一个临时目录用于存储将在函数执行完成后清理的文件
- 调用将图像转换为灰度的辅助函数
- 调用帮助函数将转换后的图像上传到 GitHub
- 返回带有 HTTP 200 状态代码和新上传图片 URL 的响应对象
注意:我们不会讨论用于图像转换或上传到 GitHub 的辅助函数是如何工作的,但源代码有很好的注释,因此您可以看到它是如何工作的。
接下来,我们需要添加一个表单,用于提交 URL 进行处理,以及一个显示前后的位置:
<form action="/.netlify/functions/convert-image" method="POST" > <label for="imageURL">URL of an image to convert</label> <input type="url" name="imageURL" required /> <button type="submit">Convert</button> </form> <div></div>最后,我们需要在表单中添加一个事件监听器,以便我们可以将 URL 发送到我们的无服务器函数进行处理:
<script type="module"> import showResults from './show-results.js'; const form = document.querySelector('form'); form.addEventListener('submit', event => { event.preventDefault(); // get the image URL from the form const imageURL = form.elements['imageURL'].value; // send the image off for processing const promise = fetch('/.netlify/functions/convert-image', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ imageURL }), }) .then(result => result.json()) .catch(error => console.error(error)); // do the work to show the result on the page showResults(imageURL, promise); }); </script>在将站点(连同其新的“functions”文件夹)部署到 Netlify 和/或在 CLI 中启动 Netlify Dev 后,我们可以在浏览器中看到表单:
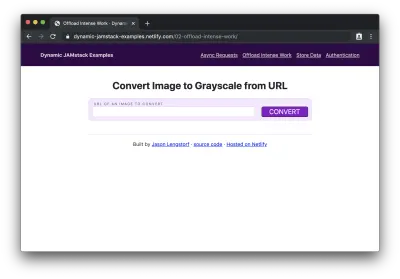
如果我们在表单中添加一个图像 URL 并单击“转换”,我们将在转换过程中看到“正在处理...”片刻,然后我们将看到原始图像及其新创建的灰度副本:
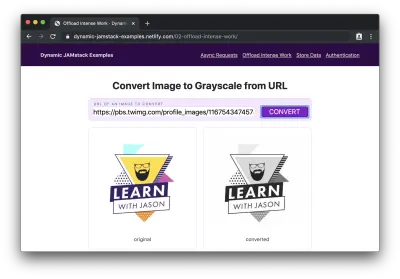
天哪! 我们的 JAMstack 站点刚刚处理了一些非常重要的业务,我们不必考虑服务器一次或耗尽用户的电池!

使用数据库存储和检索条目
在许多应用程序中,我们不可避免地需要保存用户输入的能力。 这意味着我们需要一个数据库。
你可能会想,“就是这样,对吧? 夹具起来了? 当然,JAMstack 站点——你告诉我们的只是文件夹中的文件集合——无法连接到数据库!”
相反。
正如我们在上一节中看到的,无服务器功能使我们能够做各种强大的事情,而无需创建自己的服务器。
同样,我们可以使用数据库即服务 (DBaaS) 工具(例如 Fauna)来读取和写入数据库,而无需自己设置或托管它。
DBaaS 工具极大地简化了为网站设置数据库的过程:创建新数据库就像定义我们要存储的数据类型一样简单。 这些工具会自动生成所有代码来管理创建、读取、更新和删除 (CRUD) 操作,并通过 API 供我们使用,因此我们不必实际管理数据库; 我们只是使用它。
演示:创建请愿页面
如果我们想创建一个小应用程序来收集请愿书的数字签名,我们需要建立一个数据库来存储这些签名并允许页面读取它们以进行显示。
对于这个演示,我们将使用 Fauna 作为我们的 DBaaS 提供者。 我们不会深入探讨 Fauna 是如何工作的,但为了演示设置数据库所需的少量工作,让我们列出每个步骤并单击以获取现成的数据库:
- 在 https://fauna.com 创建一个 Fauna 帐户
- 点击“新建数据库”
- 为数据库命名(例如“dynamic-jamstack-demos”)
- 点击“创建”
- 在下一页的左侧菜单中单击“安全”
- 点击“新密钥”
- 将角色下拉菜单更改为“服务器”
- 为密钥添加名称(例如“Dynamic JAMstack Demos”)
- 将密钥存储在安全的地方以供应用程序使用
- 点击“保存”
- 点击左侧菜单中的“GraphQL”
- 点击“导入架构”
- 上传一个名为
db-schema.gql的文件,其中包含以下代码:
type Signature { name: String! } type Query { signatures: [Signature!]! }一旦我们上传了模式,我们的数据库就可以使用了。 (严重地。)
十三个步骤很多,但是通过这十三个步骤,我们只得到了一个数据库、一个 GraphQL API、容量自动管理、扩展、部署、安全性等等——所有这些都由数据库专家处理。 免费。 什么时候活着!
为了尝试一下,左侧菜单中的“GraphQL”选项为我们提供了一个 GraphQL 浏览器,其中包含有关可用查询和突变的文档,这些查询和突变允许我们执行 CRUD 操作。
注意:我们不会在这篇文章中详细介绍 GraphQL 查询和突变,但是如果你想了解它的工作原理,Eve Porcello 写了一篇关于发送 GraphQL 查询和突变的精彩介绍。
准备好数据库后,我们可以创建一个在数据库中存储新签名的无服务器函数:
const qs = require('querystring'); const graphql = require('./util/graphql'); exports.handler = async event => { try { // get the signature from the POST data const { signature } = qs.parse(event.body); const ADD_SIGNATURE = ` mutation($signature: String!) { createSignature(data: { name: $signature }) { _id } } `; // store the signature in the database await graphql(ADD_SIGNATURE, { signature }); // send people back to the petition page return { statusCode: 302, headers: { Location: '/03-store-data/', }, // body is unused in 3xx codes, but required in all function responses body: 'redirecting...', }; } catch (error) { return { statusCode: 500, body: JSON.stringify(error.message), }; } };此函数执行以下操作:
- 从表单
POST数据中获取签名值 - 调用将签名存储在数据库中的辅助函数
- 定义要写入数据库的 GraphQL 突变
- 使用 GraphQL 辅助函数发送突变
- 重定向回提交数据的页面
接下来,我们需要一个无服务器函数来读取数据库中的所有签名,这样我们就可以显示有多少人支持我们的请愿:
const graphql = require('./util/graphql'); exports.handler = async () => { const { signatures } = await graphql(` query { signatures { data { name } } } `); return { statusCode: 200, body: JSON.stringify(signatures.data), }; };这个函数发送一个查询并返回它。
关于敏感密钥和 JAMstack 应用程序的重要说明:
关于这个应用程序需要注意的一点是,我们使用无服务器函数来进行这些调用,因为我们需要将私有服务器密钥传递给 Fauna,以证明我们具有对该数据库的读写访问权限。 我们不能将此密钥放入客户端代码中,因为这意味着任何人都可以在源代码中找到它并使用它对我们的数据库执行 CRUD 操作。 无服务器功能对于在 JAMstack 应用程序中保持私钥私有至关重要。
设置好无服务器函数后,我们可以添加一个表单,该表单提交给添加签名的函数,一个显示现有签名的元素,以及一些 JS 来调用该函数以获取签名并将它们放入我们的显示中元素:
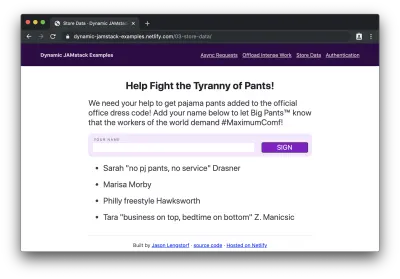
<form action="/.netlify/functions/add-signature" method="POST"> <label for="signature">Your name</label> <input type="text" name="signature" required /> <button type="submit">Sign</button> </form> <ul class="signatures"></ul> <script> fetch('/.netlify/functions/get-signatures') .then(res => res.json()) .then(names => { const signatures = document.querySelector('.signatures'); names.forEach(({ name }) => { const li = document.createElement('li'); li.innerText = name; signatures.appendChild(li); }); }); </script>如果我们在浏览器中加载它,我们会看到我们的请愿书下面有签名:
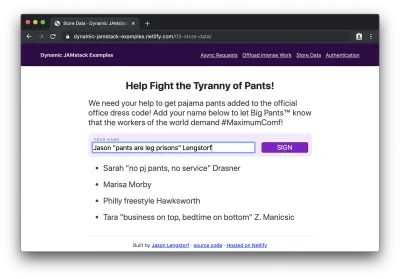
然后,如果我们添加我们的签名......
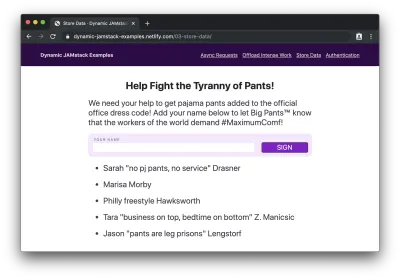
......并提交它,我们会看到我们的名字附加到列表的底部:
热狗! 我们刚刚编写了一个完整的数据库驱动的 JAMstack 应用程序,其中包含大约 75 行代码和 7 行数据库模式!
使用用户身份验证保护内容
“好吧,这次你肯定被卡住了,”你可能在想。 “JAMstack 站点无法处理用户身份验证。 这到底是怎么回事,甚至?!”
我会告诉你它是如何工作的,我的朋友:使用我们值得信赖的无服务器功能和 OAuth。
OAuth 是一种广泛采用的标准,允许人们为应用程序提供对其帐户信息的有限访问权限,而不是共享他们的密码。 如果您曾经使用其他服务登录过服务(例如,“使用您的 Google 帐户登录”),那么您之前使用过 OAuth。
注意:我们不会深入探讨 OAuth 的工作原理,但 Aaron Parecki 写了一篇详尽的 OAuth 概述,其中涵盖了细节和工作流程。
在 JAMstack 应用程序中,我们可以利用 OAuth 和它为我们提供的 JSON Web 令牌 (JWT) 来识别用户、保护内容并只允许登录用户查看它。
演示:需要登录才能查看受保护的内容
如果我们需要构建一个只向登录用户显示内容的站点,我们需要一些东西:
- 管理用户和登录流程的身份提供者
- 用于管理登录和注销的 UI 元素
- 一种无服务器函数,使用 JWT 检查登录用户并返回受保护的内容(如果提供)
对于本示例,我们将使用 Netlify Identity,它为我们提供了非常愉快的开发人员添加身份验证体验,并提供了一个用于管理登录和注销操作的插入式小部件。
要启用它:
- 访问您的 Netlify 仪表板
- 从您的站点列表中选择需要身份验证的站点
- 点击顶部导航中的“身份”
- 点击“启用身份”按钮
我们可以通过添加显示已注销内容的标记并添加一个元素以在登录后显示受保护的内容来将 Netlify Identity 添加到我们的站点:
<div class="content logged-out"> <h1>Super Secret Stuff!</h1> <p> only my bestest friends can see this content</p> <button class="login">log in / sign up to be my best friend</button> </div> <div class="content logged-in"> <div class="secret-stuff"></div> <button class="logout">log out</button> </div>这个标记依赖 CSS 来根据用户是否登录来显示内容。 但是,我们不能依靠它来实际保护内容——任何人都可以查看源代码并窃取我们的秘密!
相反,我们创建了一个包含受保护内容的空 div,但我们需要向无服务器函数发出请求才能实际获取该内容。 我们很快就会深入研究它是如何工作的。
接下来,我们需要添加代码以使我们的登录按钮工作,加载受保护的内容,并将其显示在屏幕上:
<script src="https://identity.netlify.com/v1/netlify-identity-widget.js"></script> <script> const login = document.querySelector('.login'); login.addEventListener('click', () => { netlifyIdentity.open(); }); const logout = document.querySelector('.logout'); logout.addEventListener('click', () => { netlifyIdentity.logout(); }); netlifyIdentity.on('logout', () => { document.querySelector('body').classList.remove('authenticated'); }); netlifyIdentity.on('login', async () => { document.querySelector('body').classList.add('authenticated'); const token = await netlifyIdentity.currentUser().jwt(); const response = await fetch('/.netlify/functions/get-secret-content', { headers: { Authorization: `Bearer ${token}`, }, }).then(res => res.text()); document.querySelector('.secret-stuff').innerHTML = response; }); </script>下面是这段代码的作用:
- 加载 Netlify Identity 小部件,这是一个帮助库,用于创建登录模式,使用 Netlify Identity 处理 OAuth 工作流程,并让我们的应用程序访问登录用户的信息
- 向登录按钮添加一个事件侦听器,触发 Netlify Identity 登录模式打开
- 向调用 Netlify Identity 注销方法的注销按钮添加事件侦听器
- 添加注销的事件处理程序以在注销时删除经过身份验证的类,该类隐藏已登录的内容并显示已注销的内容
- 添加用于登录的事件处理程序:
- 添加经过身份验证的类以显示已登录的内容并隐藏已注销的内容
- 获取登录用户的 JWT
- 调用无服务器函数来加载受保护的内容,在 Authorization 标头中发送 JWT
- 将秘密内容放在 secret-stuff div 中,以便登录用户可以看到它
现在我们在该代码中调用的无服务器函数不存在。 让我们使用以下代码创建它:
exports.handler = async (_event, context) => { try { const { user } = context.clientContext; if (!user) throw new Error('Not Authorized'); return { statusCode: 200, headers: { 'Content-Type': 'text/html', }, body: `你被邀请了,${user.user_metadata.full_name}!
如果你能读到这意味着我们是最好的朋友。
以下是我生日派对的秘密细节:
`, }; } 捕捉(错误){ 返回 { 状态码:401, 正文:'未授权', }; } };
jason.af/派对
此函数执行以下操作:
- 在无服务器函数的上下文参数中检查用户
- 如果找不到用户,则抛出错误
- 在确保登录用户请求后返回秘密内容
Netlify Functions 将检测授权标头中的 Netlify Identity JWT,并自动将该信息放入上下文中——这意味着我们可以检查有效的 JWT,而无需编写代码来验证 JWT!
当我们在浏览器中加载此页面时,我们将首先看到已注销的页面:
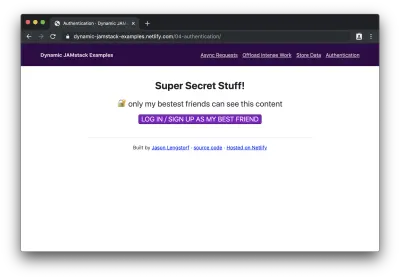
如果我们单击按钮登录,我们将看到 Netlify Identity 小部件:
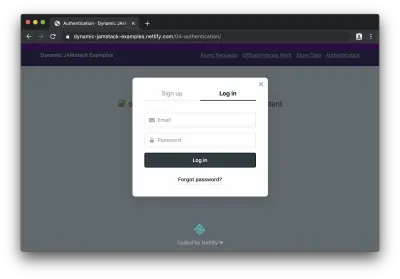
登录(或注册)后,我们可以看到受保护的内容:
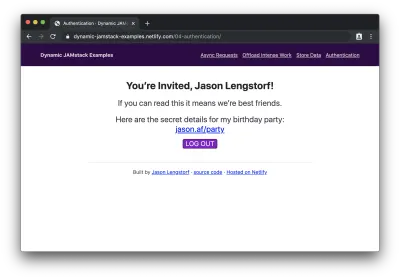
哇! 我们刚刚向 JAMstack 应用程序添加了用户登录和受保护的内容!
接下来做什么
JAMstack 不仅仅是“静态站点”——我们可以响应用户交互、存储数据、处理用户身份验证,以及我们想要在现代网站上做的任何其他事情。 所有这些都无需配置、配置或部署服务器!
你想用 JAMstack 构建什么? 有什么你仍然不相信 JAMstack 可以处理的吗? 我很想听听——在 Twitter 或评论中联系我!