
为语义网开发
已发表: 2022-03-107 月,维基媒体基金会宣布了抽象维基百科,这是一种对与语言无关的知识进行标记的尝试。 在许多方面,这是几十年积累的高潮,在此期间,语义网的梦想从未完全起飞,但也从未完全消失。
事实上,语义网正在发展,随着它更新其使命,我们都将从将语义标记纳入我们的网站中获益,无论是个人博客还是社交媒体巨头。 无论您关心复杂的网络体验、搜索引擎优化,还是抵御网络垄断的暴政,语义网都值得我们关注。
为语义网开发的好处并不总是立竿见影或可见的,但每一个确实加强了开放、透明、去中心化互联网的基础的网站。
语义网
语义网到底是什么? 它是一个机器可读的网络,通过元数据提供“一个允许数据在应用程序、企业和社区边界之间共享和重用的通用框架”。
这个想法与万维网本身一样古老。 年纪大了,其实。 这是蒂姆·伯纳斯-李 1989 年提案的重点。 正如他概述的那样,不仅文档应该形成网络,而且其中的数据也应该:
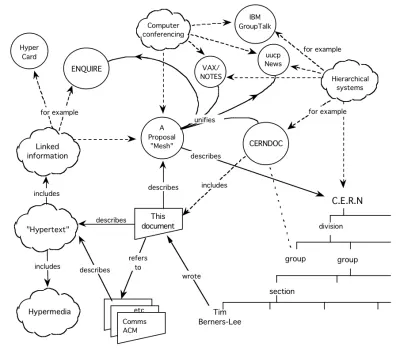
从那以后的几十年里,语义网的道路崎岖不平。 自千年之交以来,它已经演变成多个概念——开放数据、知识图谱——所有这些实际上都意味着同一个东西:数据网络。
正如 W3C 总结的那样,它是“当前网络的扩展,其中信息被赋予了明确定义的含义,使计算机和人们能够更好地合作工作。”

这个想法得到了相当多的拥护者。 互联网黑客活动家 Aaron Swartz 写了一本关于语义 Web 的书手稿,名为A Programmable Web 。 他在其中写道:
“文档无法真正实现合并、整合和查询; 它们主要用作要查看和审查的孤立实例。 但数据是多变的,能够转变为最适合您需求的任何形式。”
由于各种原因,语义网虽然正在迎头赶上,但并没有像 Web 那样起飞。 多年来,一些标记试图占据主导地位——RDFa、OWL 和 Schema 仅举几例——尽管没有一个标记成为标准,例如 HTML 或 CSS。 进入门槛太高了。
然而,语义网的梦想一直在持续,随着越来越多的网站将它融入他们的设计中,加入这个派对的理由也越来越多。 加入的网站越多,语义网就越强大。
延伸阅读
- 数据智能
- 语义网,2001 年由 Tim Berners-Lee、James Hensley 和 Ora Lassila 撰写的文章
- W3C 的可信网络社区组
知识无国界
在深入了解如何为语义 Web 进行设计之前,有必要深入挖掘一下为什么。 数据是否连接有什么关系? 连接的文档还不够吗?
语义网继续受到那些关心免费和开放互联网的人的推动有几个原因。 了解这些原因对于实施过程至关重要。 这不应该是“吃你的蔬菜,使用语义标记”的情况。 语义网是值得信赖和参与的。
语义网的好处包括:
- 更丰富、更复杂的网络体验
- 绕过内容孤岛和互联网垄断
- 提高搜索引擎的可读性和排名
- 信息民主化
其中大部分可以追溯到语义网的核心原则:数据的通用语言。 尽管互联网已经为国际交流创造了奇迹,但无法回避的事实是,有些国家的互联网比其他国家好得多。 以网络上使用的语言与现实世界中使用的语言为例。 你们中的鹰眼也许能够在下面的数据中发现轻微的不平衡……
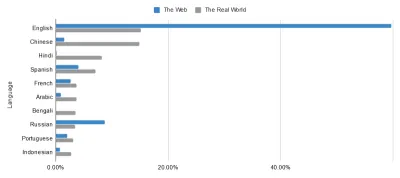
网络的无边界乌托邦并不像我们这些处于英语泡沫中的人所想的那样接近。 这是为了惩罚任何人吗? 不一定,但这是要面对的事情。 这样做突出了弥合这些差距的标记的重要性。 通过丰富网络数据,我们减轻了其语言的压力。
这是最近宣布的抽象维基百科的症结所在,它将试图将文章与它们所使用的语言分离。维基媒体执行董事凯瑟琳马赫写道:“使用代码,志愿者将能够将这些抽象的‘文章’翻译成他们自己的语言。 如果成功,这最终可以让每个人都以自己的语言阅读维基数据中的任何主题。”
摘要 Wikipedia 的创建者 Denny Vrandecic 多年来一直是语义网的倡导者,他认识到它具有释放在线未开发潜力的潜力。 打破国家壁垒对于这一进程至关重要。
“无论你用什么语言发布你的内容,你都会错过包括世界上绝大多数人的机会。 网络为我们提供了一个获得全球影响力的绝好机会——但依靠一种语言或一小部分语言,我们正在浪费这个机会。 虽然最重要的目标是首先创建好的内容,但您可以通过独立于语言来邀请更多的人参与到更好的内容的开发中。 它可以帮助您降低贡献和消费的门槛,并让更多的人从这项努力中受益。”
— Denny Vrandecic,抽象维基百科创建者
COVID-19 大流行期间的数据可视化就是一个及时的例子。 该病毒在全球范围内造成了难以形容的破坏,但它也是开放数据网络的一个闪光时刻,它允许出色的网络应用程序、报告等在网络上普遍存在。
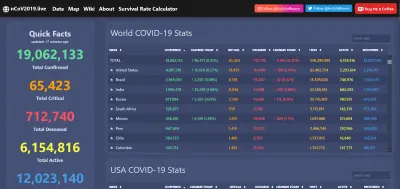
当然,当数据透明且易于访问时,就更容易识别异常……或直接欺骗。 即使在 20 年前,公众对上述信息的广泛访问也是不可想象的。 现在我们期待它,并在它拒绝我们时闻到老鼠的味道。 数据是强大的,如果我们愿意,可以永远使用它。
同样,将自己排除在内容孤岛之外——现代网络体验的一个标志——会从谷歌、Facebook 和 Twitter 等网络垄断企业手中夺走权力。 我们已经习惯了第三方平台解密和呈现信息,以至于我们忘记了它们并不是绝对必要的。
“如果我们有共享格式、共享协议,我们最终可能仍会让某些提供商在某些市场发挥重要作用——想想 Gmail 的电子邮件——但每个人都可以自由转移到另一个提供商,市场仍然具有竞争力。”
— Denny Vrandecic,抽象维基百科创建者
语义网是无孤岛的; 它是免费的、开放的和抽象的,可以实现不同语言和平台之间的通信,否则会更加困难。
数据化在线内容
语义网设计归结为数据化在线内容——查看您的内容并了解可以(并且应该)抽象的内容。 除了模糊地同意这是一件值得做的事情之外,这实际上意味着什么? 这取决于:
- 如果从头开始一个项目,请将语义 Web 考虑因素纳入您的工作中。 随着网站的形成,将语义标记编织到其 DNA 中。
- 如果更新或重建一个项目,请评估可以融入语义网但目前还没有的东西,然后实施。
这两种情况基本上都相当于数据内容。 在本节中,我们将介绍一些数据抽象的示例,以及它如何使内容更好、更智能和更广泛地可用。
抽象信息
为语义网设计和开发意味着带着你的数据查看在线内容。 我们大多数人将网络视为一系列相互连接的文档或页面。 你想用语义网做的是连接信息。 这意味着评估您的数据点内容,然后根据您的发现调整设计。
语义网倡导者 James Hendler 用他的 DIVE 精神很好地概述了这个过程。 (深入研究数据,嗯?嗯?)。 它分解如下:
- 发现
查找数据集和/或内容(包括在您自己的组织之外)。 - 整合
使用有意义的标签链接关系。 - 证实
为建模和仿真系统提供输入。 - 探索
开发将数据转化为可操作知识的方法。
为语义网开发主要是要对您所做的事物进行鸟瞰,以及它如何潜在地为无限丰富的网络体验提供服务。 正如 Hendler 所说,可操作的知识是目标。
这实际上可以应用于几乎任何类型的网络内容,但让我们从一个常见的例子开始:食谱。 假设您经营一个烹饪博客,每周四都有新食谱。 如果您是法国人,并且在您的个人博客上以纯文本的形式发布了一个非常棒的蛋奶酥食谱,那么它只对那些能够阅读法语的人有用。
但是,通过实现语义标记,可以将博客转换为机器可读的食谱数据集。 存在用于抽象烹饪术语的语法。 例如,Schema 可以与 Microdata、RDFa 或 JSON-LD 一起使用,其标记包括:
- 准备时间
- 烹饪时间
- 配方产量
- 食谱成分
- 估计成本
- 营养,分解成卡路里和脂肪含量
- 适合饮食。
我可以继续。 可以在 Schema.org 上阅读所有选项以及示例。 将它们添加到帖子格式中,配方的格式根本不需要改变——您只需将信息放在计算机可以理解的术语中。
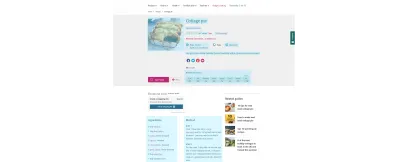
例如,上面 BBC 食谱中以蓝色突出显示的所有内容也都被赋予了语义标记——从烹饪时间到营养成分。 您可以通过将配方 URL 输入到 Google 的丰富结果测试中来查看幕后情况。 请注意“添加到购物清单”功能,这是通过语义 Web 实现实现的连接示例。 好的内容变成可用的数据。

我们大多数人都通过搜索结果遇到过这种复杂性的道路,但应用范围远不止于此。 食谱的语义标记使家庭助理更容易找到和使用网站。 所列食材可从当地超市订购。 食谱可以通过各种方式进行过滤——饮食、过敏、宗教、成本等等。 或者假设你家里的原料数量有限。 使用数据库,您可以输入这些成分并查看符合要求的食谱。
可能性的范围确实是无限的。 正如 Swartz 所说,数据是多变的。 一旦拥有它,您就可以以各种奇怪而奇妙的方式使用它。 这篇文章不是关于那些奇怪而美妙的方式,而是关于使它们成为可能。 为语义网设计使后续的设计无限丰富。
这是一个更个人的例子来说明我的意思。 我和几个朋友经营一个小小的音乐网络杂志作为一种爱好。 虽然我们发表了奇怪的文章或采访,但“主要事件”是我们每周的专辑评论,我们三个人每人都会分配一个分数,选择最喜欢的曲目,然后写总结。 我们已经进行了五年多,这意味着我们有接近 250 条评论,这意味着大量的潜在数据。 直到我们开始重新设计网站,我们才意识到有多少。
我在一篇关于将结构化数据烘焙到设计过程中的文章中谈到了这一点。 在剖析我们的评论时,我们意识到它们充满了可以给予语义标记的信息。 艺术家、专辑名称、艺术作品、发行日期、个人乐谱、总乐谱、发行类型等。 更重要的是——这才是真正令人兴奋的地方——我们意识到我们可以连接到现有的数据库:MusicBrainz。
这种双向方法是语义网的关键。 当我们的音乐网站重新启动时,它将成为拥有数千个独特数据点的自己的开放数据源。 连接到现有的音乐数据库将为我们自己的数据提供更多背景和潜力。 数千个数据点变成数万个数据点,甚至更多。
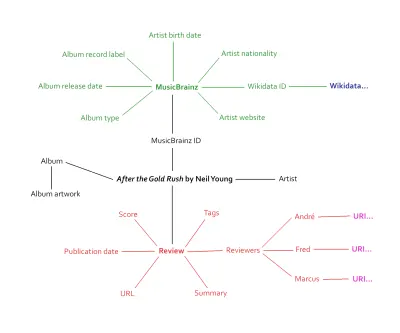
上图仅涉及将多少信息连接到评论页面的表面。 内容和以前一样,只是现在它被插入到元数据生态系统中——正如 Berners-Lee 曾经所说的 Giant Global Graph。
为语义网开发意味着识别您自己的数据,标记它,然后弄清楚它如何连接到其他数据。 因为确实如此。 它总是这样。 这个过程就是这样……
……时间变成了这个……
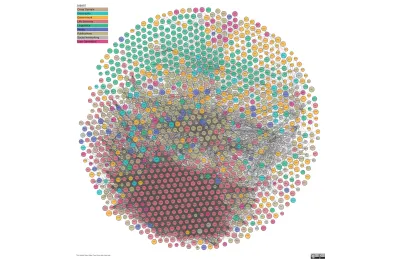
第二张图片是 The Linked Open Data Cloud,这是一个不断更新的网络连接数据的可视化。 那个红色的联系蜂巢是科学; 其余的还有一段路要走。 这就是我们进来的地方。
有用的语义网资源
- w3schools.com 上的 RDF
- W3C 的 RDF 验证器
- W3C 的“The Semantic Web Made Easy”
- “语义网发生了什么?” 通过两位历史
- JSON-LD 生成器
- Google 的结构化数据标记助手
插入
语义网的理想是连接。 制作数据、共享数据、需求数据。 成为信息生态系统的一部分。 当您创建原始数据时,非常棒。 分享它。 当数据已经存在并且您想使用它时,将其拉入。
这里只是一些数据资源:
- 百度百科
- 音乐脑
- 世界猫
- ISBN数据库
事实上,在存在这样的数据库的地方,我什至会说正确的做法是在它们缺乏信息的地方更新它们。 为什么要留给自己? 成为贡献者,语义网倡导者。
执行
就在您的网站中构建 Semantic Webness 而言,我当然不提倡手动、逐个文档标记。 谁有时间做这个? 解决方案通常是标准化格式并为其模板化的情况。
模板是这里的大好机会。 有多少人真正有时间手动标记所有这些信息? 但是,如果您有自定义输入,则可以两全其美。 内容可以充满对人友好的信息,并且信息作为数据存在,随时可以服务于想到的任何目的。
举个例子,像 Eleventy 这样的静态站点生成器,它最近受到了开发社区的喜爱。 你写了一篇文章,通过一个模板运行它,你就是金子。 那么为什么不将语义标记合并到模板本身呢?
与 Eleventy 一样,我们的音乐网站的新版本使用 Markdown 发布帖子。 虽然我们有与往常一样的旧文本帖子,但现在每条评论还包括以下元数据输入,然后将其拉入模板:
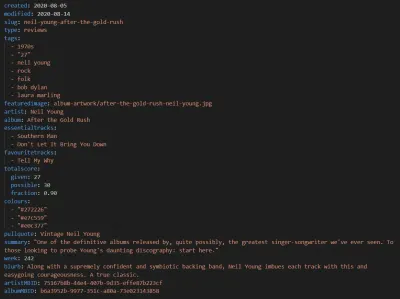
连同帖子正文中的作者详细信息和一些通用网站信息,这将转化为以下语义标记:
<script type="application/ld+json"> { "@context": "https://schema.org/", "@type": "Review", "reviewBody": "One of the definitive albums released by, quite possibly, the greatest singer-songwriter we've ever seen. To those looking to probe Young's daunting discography: start here.", "datePublished": "2020-08-14", "author": [{ "@type": "Person", "name": "Andre Dack" }, { "@type": "Person", "name": "Frederick O'Brien" }, { "@type": "Person", "name": "Marcus Lawrence" }], "itemReviewed": { "@type": "MusicAlbum", "name": "After the Gold Rush", "@id": "https://musicbrainz.org/release-group/b6a3952b-9977-351c-a80a-73e023143858", "image": "https://audioxide.com/images/album-artwork/after-the-gold-rush-neil-young.jpg", "albumProductionType": "https://schema.org/StudioAlbum", "albumReleaseType": "https://schema.org/AlbumRelease", "byArtist": { "@type": "MusicGroup", "name": "Neil Young", "@id": "https://musicbrainz.org/artist/75167b8b-44e4-407b-9d35-effe87b223cf" } }, "reviewRating": { "@type": "Rating", "ratingValue": 27, "worstRating": 0, "bestRating": 30 }, "publisher": { "@type": "Organization", "name": "Audioxide", "description": "Independent music webzine founded in 2015. Publishes reviews, articles, interviews, and other oddities.", "url": "https://audioxide.com", "logo": "https://audioxide.com/logo-location.jpg", "sameAs" : [ "https://facebook.com/audioxide", "https://twitter.com/audioxide", "https://instagram.com/audioxidecom" ] } } </script>以前只有文字,现在在每个评论页面上,读者在访问网站时看到的内容也将有机器可读的版本。 文字还在那里,内容几乎没有改变——只是被数据化了。 从丰富的搜索结果到交互式评论统计页面,这极大地增加了可能性。 前面的路是宽阔的。 它也让我们在 MusicBrainz 的未来中占有一席之地。 通过将他们的数据连接到我们自己的数据,我们反过来希望看到它做得好,并将尽我们所能确保它做得好。
适当的语义标记取决于网站的性质,但它存在的可能性很大。 从明显的输入(日期、作者、内容类型等)开始,然后逐步进入内容的杂草。 第一步可以像您个人网站的 hCard(一种数字身份证)一样简单。 打印页面截图并开始注释。 您会惊讶于有多少内容可以被数据化。
超乎想象
为语义网设计和开发是一种可以追溯到互联网创始理想的实践。 无论您看重美观、信息丰富的数据可视化,想要更复杂的搜索结果,希望消除网络垄断的力量,还是仅仅相信自由和开放的信息,语义网都是您的盟友。
Aaron Swartz 以希望的呼唤结束了他的手稿:
“语义网是基于赌注的,赌注是为世界提供轻松协作和交流的工具将带来如此美妙的可能性,我们现在几乎无法想象它们。”
摘要 Wikipedia Denny Vrandecic 今天回应了这些观点,他说:
“需要一个网络基础设施来促进服务之间的互操作性,这需要一套通用的数据表示标准和跨提供商的通用协议。”
语义网已经跛足了很长时间,以至于很明显银弹语言不太可能出现,但现在有足够的和平共处让伯纳斯-李的创始梦想成为大多数网络的现实。 我们每个人都可以成为我们自己社区的倡导者。
变得更好,要求更好
正如 Tim Berners-Lee 所说,语义 Web 既是一种文化,也是一种技术障碍。 在 2009 年的 TED 演讲中,他很好地总结了这一点:制作关联数据,需求关联数据。 现在比以往任何时候都更真实。 万维网只有我们强迫它成为开放、连接和良好的状态。 每当你在网上做某事时,问问自己,“这怎么能插入语义网?” 答案将为我们创造的事物增添新的维度,并在未来几年创造难以想象的美妙新可能性。