
Python 中的数据可视化:基本图解释 [带图解]
已发表: 2021-02-08目录
基本设计原则
对于任何有抱负或成功的数据科学家来说,能够解释你的研究和分析是一项非常重要且有用的技能。 这就是数据可视化出现的地方。 诚实地使用这个工具至关重要,因为观众很容易被错误的设计选择误导或欺骗。
作为数据科学家,我们在维护真实数据方面都有一定的义务。
首先是我们在清理和汇总数据时应该对自己完全诚实。 数据预处理对于任何机器学习算法来说都是一个非常关键的步骤,因此数据中的任何不诚实都会导致截然不同的结果。
另一个义务是对我们的目标受众。 数据可视化中有多种技术可用于突出数据的特定部分并使其他一些数据不那么突出。 因此,如果我们不够仔细,读者将无法正确地探索和判断分析,从而导致怀疑和缺乏信任。
对于数据科学家来说,总是质疑自己是一个很好的特质。 我们应该始终考虑如何以一种易于理解且美观的方式展示真正重要的内容,同时记住上下文很重要。
这正是阿尔贝托·开罗在他的教义中试图描绘的。 他提到了大观的五种品质:美丽、开悟、功能、洞察力和真实,值得牢记。
一些基本情节
现在我们对设计原则有了基本的了解,让我们深入了解一些使用 python 中的matplotlib库的基本可视化技术。
下面的所有代码都可以在 Jupyter 笔记本中执行。
%matplotlib 笔记本
# 这提供了一个交互环境并设置了后端。 ( %matplotlib inline也可以使用,但它不是交互式的。这意味着对绘图函数的任何进一步调用都不会自动更新我们的原始可视化。)
import matplotlib.pyplot as plt # 导入需要的库模块
点图
绘制点的最简单的matplotlib函数是plot() 。 参数表示 X 和 Y 坐标,然后是描述数据输出应如何显示的字符串值。
plt.figure()
plt.plot( 5, 6, '+' ) # + 号作为标记
散点图
散点图是二维图。 scatter()函数还将 X 值作为第一个参数,将 Y 值作为第二个参数。 下图是一条对角线, matplotlib会自动调整两个轴的大小。 在这里,散点图不会将项目视为一个系列。 因此,我们还可以给出与每个点对应的所需颜色的列表。
将 numpy 导入为 np
x = np.array( [1, 2, 3, 4, 5, 6, 7, 8] )
y = x
plt.figure()
plt.scatter( x, y )
线图
线图是使用plot()函数创建的,并绘制了许多不同系列的数据点,如散点图,但它将每个点系列与一条线连接起来。
将 numpy 导入为 np
线性数据 = np.array( [1, 2, 3, 4, 5, 6, 7, 8] )
平方数据 = 线性数据**2
plt.figure()
plt.plot(线性数据,“-o”,平方数据,“-o”)
为了使图表更具可读性,我们还可以添加一个图例,它会告诉我们每条线代表什么。 图表和两个轴的合适标题很重要。 此外,可以使用fill_between()函数对图形的任何部分进行着色以突出显示相关区域。
plt.xlabel('X 值')

plt.ylabel('Y 值')
plt.title('线图')
plt.legend(['线性','平方'])
plt.gca().fill_between( range ( len ( linear_data ) ), linear_data, squared_data, facecolor = 'blue', alpha = 0.25)
这就是修改后的图表的样子——
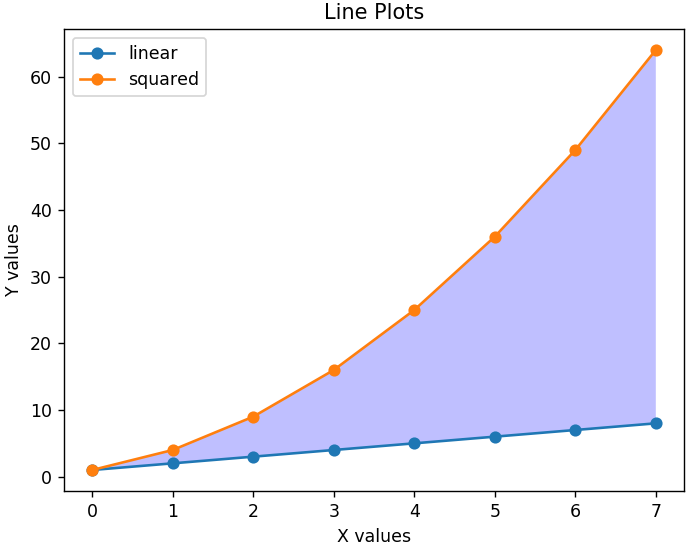
条形图
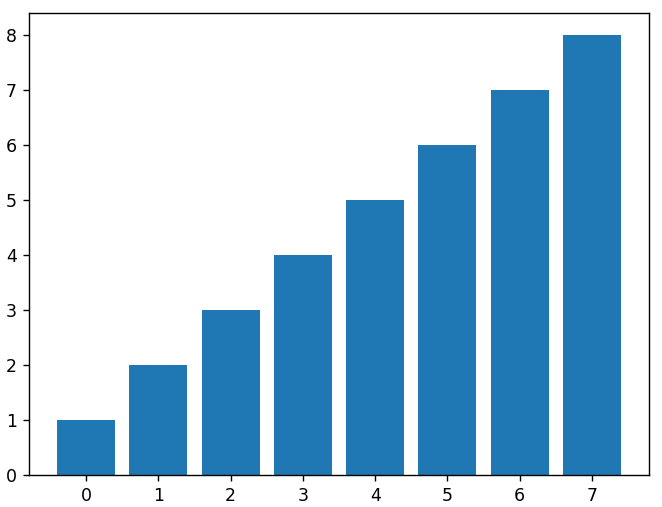
我们可以通过将 X 值和每个条的高度的参数发送到bar()函数来绘制条形图。 下面是我们上面使用的相同线性数据数组的条形图。
plt.figure()
x = 范围(长度(线性数据))
plt.bar(x,线性数据)
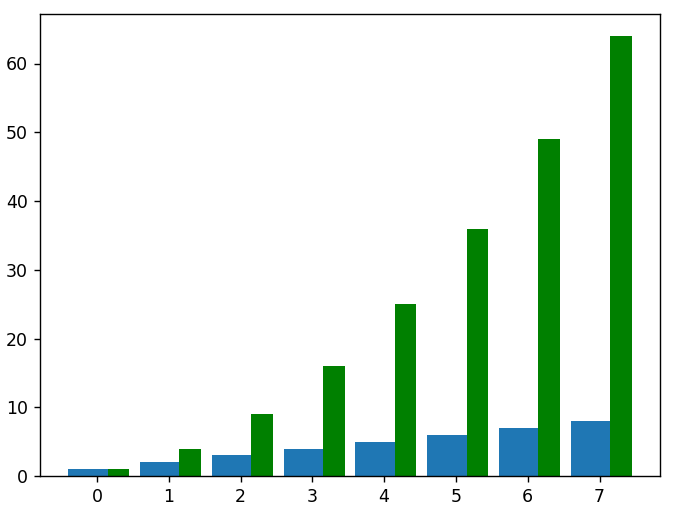
# 为了将平方数据绘制为同一图表上的另一组条形图,我们必须调整新的 x 值以弥补第一组条形图
新_x = []
对于 x 中的数据:
new_x.append(数据+0.3)
plt.bar(new_x, squared_data, width = 0.3, color = 'green')
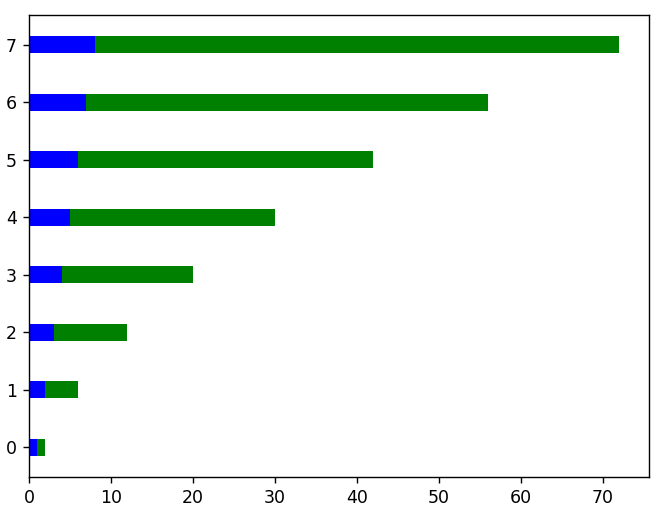
# 对于水平方向的图,我们使用barh()函数
plt.figure()
x = 范围(长度(线性数据))
plt.barh(x,线性数据,高度 = 0.3,颜色 = 'b')
plt.barh(x, squared_data, height = 0.3, left = linear_data, color = 'g')
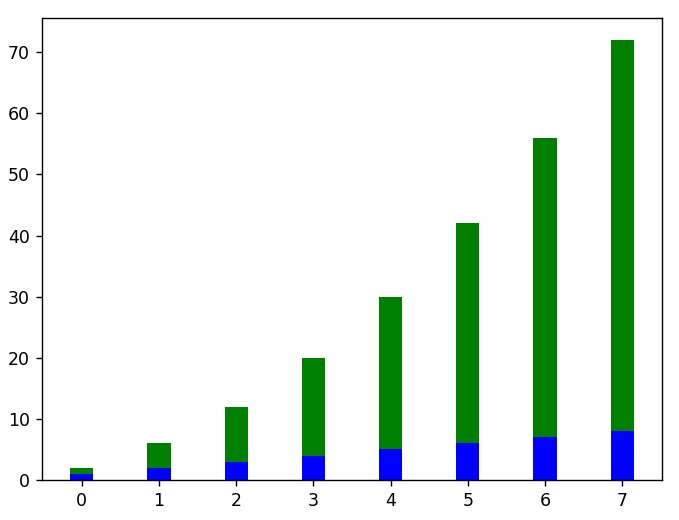
#这里是一个垂直堆叠条形图的例子
plt.figure()
x = 范围(长度(线性数据))
plt.bar(x,线性数据,宽度 = 0.3,颜色 = 'b')
plt.bar(x,squared_data,宽度 = 0.3,底部 = 线性数据,颜色 = 'g')
学习世界顶尖大学的数据科学课程。 获得行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。
结论
可视化类型不仅仅止于此。 Python 还有一个很棒的名为seaborn的库,绝对值得探索。 适当的信息可视化极大地有助于增加我们数据的价值。 数据可视化将始终是获得洞察力和识别各种趋势和模式的更好选择,而不是查看包含数百万条记录的无聊表格。
如果您想了解数据科学,请查看 IIIT-B 和 upGrad 的数据科学 PG 文凭,该文凭专为在职专业人士而设,提供 10 多个案例研究和项目、实用的实践研讨会、与行业专家的指导、1-与行业导师面对面交流,400 多个小时的学习和顶级公司的工作协助。
有哪些有用的 Python 数据可视化包?
Python 有一些用于数据可视化的惊人而有用的包。 下面提到了其中一些软件包:
1. Matplotlib - Matplotlib 是一个流行的 Python 库,用于以散点图、条形图、饼图和折线图等各种形式进行数据可视化。 它使用 Numpy 进行数学运算。
2. Seaborn - Seaborn 库用于 Python 中的统计表示。 它是在 Matplotlib 之上开发的,并与 Pandas 数据结构集成。
3. Altair - Altair 是另一个流行的用于数据可视化的 Python 库。 它是一个声明性统计库,可让您以最少的编码创建视觉效果。
4. Plotly - Plotly 是 Python 的交互式开源数据可视化库。 这个基于浏览器的库创建的视觉效果受到许多平台的支持,例如 Jupyter Notebook 和独立的 HTML 文件。
你对点图和散点图了解多少?
点图是数据可视化中最基本、最简单的图。 点图以笛卡尔平面上的点的形式显示数据。 “+”表示值的增加,而“-”表示值随时间的减少。
另一方面,散点图是优化的图,其中数据在二维平面上可视化。 它是使用 scatter() 函数定义的,该函数将 x 轴值作为第一个参数,将 y 轴值作为第二个参数。
数据可视化有哪些优势?
以下优势展示了数据可视化如何成为组织发展的真正英雄:
1. 数据可视化使解释原始数据和理解它以进行进一步分析变得更加容易。
2. 研究和分析数据后,可以使用有意义的可视化显示结果。 这使得与观众联系和解释结果变得更容易。
3. 该技术最重要的应用之一是分析模式和趋势,以推断预测和潜在的增长领域。
4. 它还允许您根据客户偏好隔离数据。 您还可以确定需要更多关注的区域。