
Python 中的数据结构——完整指南
已发表: 2021-06-14目录
什么是数据结构?
数据结构是指数据的计算存储以便有效使用。 它以易于修改和访问的方式存储数据。 它统指数据的值、它们之间的关系以及可以对数据进行的操作。 数据结构的重要性在于它在开发计算机程序中的应用。 由于计算机程序严重依赖数据,因此为方便访问而正确安排数据对于任何程序或软件来说都是最重要的。
数据结构的四个主要功能是
- 输入信息
- 处理信息
- 维护信息
- 检索信息
Python中的数据结构类型
Python 支持多种数据结构,以便于访问和存储数据。 Python 数据结构类型可以分为原始数据类型和非原始数据类型。 前一种数据类型包括整数、浮点数、字符串和布尔值,而后一种数据类型是数组、列表、元组、字典、集合和文件。 因此, python中的数据结构既是内置的数据结构,也是用户自定义的数据结构。 内置数据结构称为非原始数据结构。
内置数据结构
Python 有几种数据结构,它们充当存储其他数据的容器。 这些Python 数据结构是 List、Dictionaries、Tuple 和 Sets。
用户定义的数据结构
这些数据结构可以编程为与python中内置数据结构相同的功能。 用户定义的数据结构有:Linked List、Stack、Queue、Tree、Graph 和 Hashmap。
内置数据结构列表和解释
1. 列表
存储在列表中的数据是按顺序排列的,具有不同的数据类型。 对于每个数据,都会分配一个地址,它被称为索引。 索引值从 0 开始,一直持续到最后一个元素。 这称为正指数。 如果元素被反向访问,也存在负索引。 这称为负索引。
列表创建
该列表创建为方括号。 然后可以相应地添加元素。 可以将其添加到方括号中以创建列表。 如果没有添加任何元素,则会创建一个空列表。 否则将创建列表中的元素。
| 输入 my_list = [] #创建空列表 打印(我的列表) my_list = [1, 2, 3, 'example', 3.132] #用数据创建列表 打印(我的列表) | 输出 [] [1, 2, 3, '例子', 3.132] |
在列表中添加元素
三个函数用于在列表中添加元素。 这些函数是 append()、extend() 和 insert()。
- 使用 append() 函数将所有元素添加为单个元素。
- 为了在列表中一个一个地添加元素,使用了 extend() 函数。
- 为了通过索引值添加元素,使用 insert() 函数。
| 输入 my_list = [1, 2, 3] 打印(我的列表) my_list.append([555, 12]) #添加为单个元素 打印(我的列表) my_list.extend([234, 'more_example']) #添加为不同的元素 打印(我的列表) my_list.insert(1, 'insert_example') #添加元素 i 打印(我的列表) | 输出: [1、2、3] [1, 2, 3, [555, 12]] [1, 2, 3, [555, 12], 234, 'more_example'] [1, 'insert_example', 2, 3, [555, 12], 234, 'more_example'] |
删除列表中的元素
python中的内置关键字“del”用于从列表中删除元素。 但是,此函数不会返回已删除的元素。
- 要返回已删除的元素,使用 pop() 函数。 它使用要删除的元素的索引值。
- remove() 函数用于按元素的值删除元素。
输出:
[1, 2, 3, '例子', 3.132, 30]
[1、2、3、3.132、30]
弹出元素:2 剩余列表:[1, 3, 3.132, 30]
[]
评估列表中的元素
- 评估列表中的元素很简单。 打印列表将直接显示元素。
- 可以通过传递索引值来评估特定元素。
输出:
1
2
3
例子
3.132
10
30
[1, 2, 3, '例子', 3.132, 10, 30]
例子
[1, 2]
[30, 10, 3.132, '例子', 3, 2, 1]
除了上述操作之外,python 中还提供了其他几个用于处理列表的内置函数。
- len():该函数用于返回列表的长度。
- index():此函数允许用户知道传递的值的索引值。
- count() 函数用于查找传递给它的值的计数。
- sort() 对列表中的值进行排序并修改列表。
- sorted() 对列表中的值进行排序并返回列表。
输出
6
3
2
[1、2、3、10、10、30]
[30、10、10、3、2、1]
2.字典
字典是一种存储键值对而不是单个元素的数据结构。 可以用一个电话簿的例子来解释它,其中包含所有个人号码及其电话号码。 这里的姓名和电话号码定义了作为“键”的常量值,以及所有个人的号码和姓名作为该键的值。 评估一个键将允许访问存储在该键中的所有值。 这种在 Python 上定义的键值结构被称为字典。
字典的创建
- 花括号闲置的dict()函数可用于创建字典。
- 创建字典时要添加键值对。
键值对中的修改
字典中的任何修改都只能通过键来完成。 因此,应首先访问密钥,然后进行修改。
| 输入 my_dict = {'First': 'Python', 'Second': 'Java'} print(my_dict) my_dict['Second'] = 'C++' #更改元素 print(my_dict) my_dict['Third'] = 'Ruby' #添加键值对打印(my_dict) | 输出: {'第一':'Python','第二':'Java'} {'第一':'Python','第二':'C++'} {'First':'Python','Second':'C++','Third':'Ruby'} |
删除字典
clear() 函数用于删除整个字典。 可以使用 get() 函数或传递键值通过键来评估字典。
| 输入 dict = {'月份':'一月','季节':'冬天'} 打印(字典['第一']) 打印(dict.get('第二') | 输出 一月 冬天 |
与字典相关的其他函数是keys()、values() 和items()。
3. 元组
与列表类似,元组是数据存储列表,但唯一的区别是元组中存储的数据不能被修改。 如果元组中的数据是可变的,那么只有这样才能更改数据。
- 元组可以通过 tuple() 函数创建。
输入
新元组 = (10, 20, 30, 40)
打印(新元组)
输出
(10, 20, 30, 40)
- 可以以与评估列表中的元素相同的方式评估元组中的元素。
输入
new_tuple2 = (10, 20, 30, '年龄')
对于 new_tuple2 中的 x:
打印(x)
打印(新元组2)
打印(new_tuple2[0])
输出
10
20
30
年龄
(10, 20, 30, '年龄')
10
- '+' 运算符用于附加另一个元组
输入
元组 = (1, 2, 3)
元组 = 元组 + (4, 5, 6
打印(元组)
输出
(1, 2, 3, 4, 5, 6)

4.设置
集合数据结构类似于算术集合。 它基本上是独特元素的集合。 如果数据不断重复,则集合只考虑添加该元素一次。
- 只需在花括号中将值传递给它,就可以创建一个集合。
输入
设置 = {10, 20, 30, 40, 40, 40}
打印(设置)
输出
{10、20、30、40}
- add() 函数可用于将元素添加到集合中。
- 要合并来自两个集合的数据,可以使用 union() 函数。
- 为了识别这两个集合中存在的数据,使用了intersection() 函数。
- difference() 函数只输出集合中唯一的数据,去除公共数据。
- symmetric_difference() 函数输出两组唯一的数据。
用户自定义数据结构列表及说明
1. 堆栈
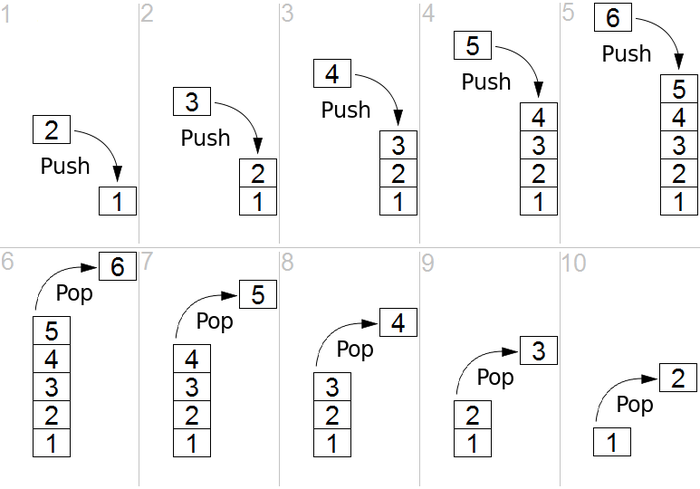
堆栈是一种线性结构,可以是后进先出 (LIFO) 或先进后出 (FIFO) 结构。 堆栈中存在两个主要操作,即 push 和 pop。 Push 意味着在列表顶部添加一个元素,而 pop 意味着从堆栈底部删除一个元素。 图 1很好地描述了该过程。
堆栈的用处
- 以前的元素可以通过回溯进行评估。
- 递归元素的匹配。
资源
图 1:堆栈的图形表示
例子

输出
['第一第二第三']
['第一第二第三第四第五']
第五
['第一第二第三第四']
2.排队
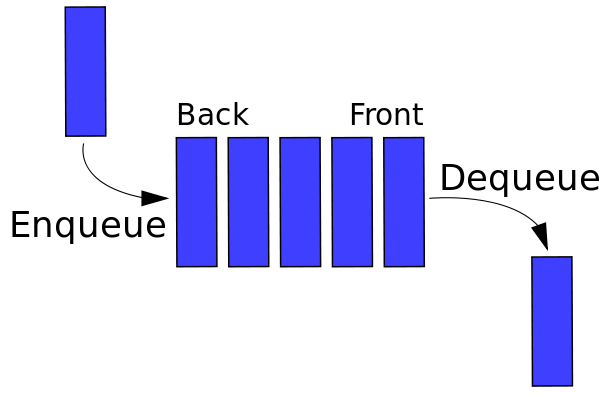
与堆栈类似,队列是一种线性结构,允许在一端插入元素并从另一端删除元素。 这两个操作称为入队和出队。 最近添加的元素像堆栈一样首先被删除。 队列的图形表示如图 2所示。队列的主要用途之一是在事物进入后立即对其进行处理。
资源
图 2 :队列的图形表示
例子

输出
['第一第二第三']
['第一第二第三第四第五']
第一的
第五
['第二','第三','第四','第五']
3. 树
树是由通过边链接的节点组成的非线性和分层数据结构。 python树数据结构有根节点、父节点和子节点。 根是数据结构的最顶层元素。 二叉树是一种结构,其中元素的子节点不超过两个。
树的用处
- 显示数据元素的结构关系。
- 高效遍历每个节点
- 用户可以插入、搜索、检索和删除数据。
- 灵活的数据结构
图 3:树的图形表示
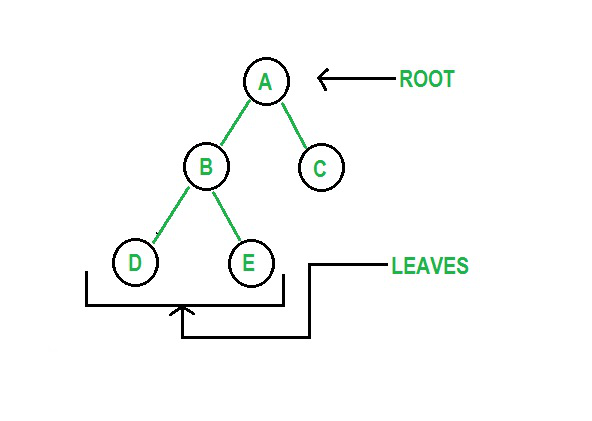
资源
例子:

输出
第一的
第二
第三
4. 图表
python中的另一种非线性数据结构是由节点和边组成的图。 它以图形方式显示一组对象,其中一些对象通过链接连接。 顶点是相互连接的对象,而链接称为边。 图的表示可以通过python的字典数据结构来完成,其中键代表顶点,值代表边。
可以对图执行的基本操作
- 显示图形顶点和边。
- 添加一个顶点。
- 添加边缘。
- 创建图表
图表的用处
- 图的表示很容易理解和遵循。
- 这是一个很好的结构来表示链接关系,即 Facebook 朋友。
图 4:图形的图形表示
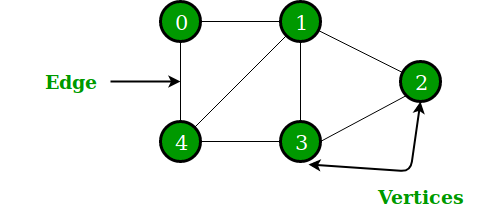
资源
例子

g = 图(4)
g.edge(0, 2)
g.edge(1, 3)
g.edge(3, 2)
g.edge(0, 3)
g.__repr__()
输出
顶点0的邻接表
头 -> 3 -> 2
顶点1的邻接表
头-> 3
顶点2的邻接表
头 -> 3 -> 0
顶点3的邻接表
头 -> 0 -> 2 -> 1
5.哈希图
哈希图是用于存储键值对的索引python 数据结构。 存储在散列图中的数据是通过在散列函数的帮助下计算的键来检索的。 这些类型的数据结构对于存储学生数据、客户详细信息等很有用。python 中的字典是 hashmap 的一个示例。
例子

输出
0 -> 第一个
1 -> 第二
2 -> 第三
0 -> 第一个
1 -> 第二
2 -> 第三
3 -> 第四
0 -> 第一个
1 -> 第二
2 -> 第三
用处
- 与其他数据结构相比,它是最灵活、最可靠的信息检索方法。
6.链表
它是一种线性数据结构。 基本上,它是通过 python 中的链接连接在一起的一系列数据元素。 链表中的元素通过指针连接。 该数据结构的第一个节点称为头部,最后一个节点称为尾部。 因此,链表由具有值的节点组成,每个节点由链接到另一个节点的指针组成。
链表的用处
- 与固定的数组相比,链表是一种动态的数据输入形式。 内存在分配节点内存时被保存。 在数组中,必须预先定义大小,这会导致内存浪费。
- 链表可以存储在内存中的任何位置。 链表节点可以更新并移动到不同的位置。
图 6:链表的图形表示
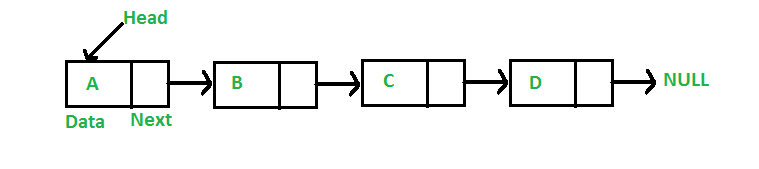
资源
例子

输出:
['第一第二第三']
['第一','第二','第三','第六','第四','第五']
['第一','第三','第六','第四','第五']
结论
已经探索了python中的各种类型的数据结构。 无论是新手还是专家,数据结构和算法都不容忽视。 在对数据执行任何形式的操作时,数据结构的概念起着至关重要的作用。 数据结构有助于以有组织的方式存储信息,而算法有助于指导整个数据分析。 因此, python 数据结构和算法都可以帮助计算机科学家或任何用户处理他们的数据。
如果您想了解数据结构,请查看 IIIT-B 和 upGrad 的数据科学执行 PG 计划,该计划是为在职专业人士创建的,提供 10 多个案例研究和项目、实用的实践研讨会、与行业专家的指导、1与行业导师一对一,400 多个小时的学习和顶级公司的工作协助。
Python中哪种数据结构更快?
在字典中,查找速度更快,因为 Python 使用哈希表来实现它们。 如果我们使用大 O 概念来说明区别,字典具有恒定的时间复杂度 O(1),而列表具有线性时间复杂度 O(n)。
在 Python 中,字典是频繁查找包含数千个条目的数据的最快方法。 字典经过高度优化,因为它们是 Python 中的内置映射类型。 然而,在字典和列表中,有一个常见的时空权衡。 这表明虽然我们可以减少我们的方法所需的时间,但我们将需要使用更多的内存空间。
在列表中,要获得所需的内容,您必须查看完整列表。 另一方面,字典将返回您要查找的值,而无需查看所有键。
Python列表或数组中哪个更快?
一般来说,Python 列表非常灵活,可以保存完全异构的随机数据,并且可以在近似恒定的时间内快速追加。 如果您需要快速、轻松地缩小和扩展列表,它们是您的最佳选择。 然而,它们比数组占用更多的空间,部分原因是列表中的每个项目都需要创建一个单独的 Python 对象。
另一方面,array.array 类型本质上是 C 数组的薄包装。 它只能携带同质数据(即相同类型的数据),因此内存限制为 sizeof(one object) * length 个字节。
NumPy 数组和列表有什么区别?
Numpy 是 Python 的科学计算核心包。 它使用大型多维数组对象以及用于操作它们的实用程序。 numpy 数组是由非负整数元组索引的相同类型值的网格。
列表包含在 Python 核心库中。 列表类似于 Python 中的数组,但它可以调整大小并包含各种类型的元素。 这里真正的区别是什么? 性能就是答案。 Numpy 数据结构在大小、性能和功能方面更有效。