
机器学习中的数据预处理:7 个简单的步骤
已发表: 2021-07-15机器学习中的数据预处理是有助于提高数据质量以促进从数据中提取有意义的见解的关键步骤。 机器学习中的数据预处理是指准备(清理和组织)原始数据以使其适合构建和训练机器学习模型的技术。 简而言之,机器学习中的数据预处理是一种数据挖掘技术,可将原始数据转换为可理解和可读的格式。
目录
为什么要在机器学习中进行数据预处理?
在创建机器学习模型时,数据预处理是标志着该过程开始的第一步。 通常,现实世界的数据不完整、不一致、不准确(包含错误或异常值),并且通常缺乏特定的属性值/趋势。 这是数据预处理进入场景的地方——它有助于清理、格式化和组织原始数据,从而使其为机器学习模型做好准备。 让我们探索机器学习中数据预处理的各个步骤。
加入来自世界顶级大学的在线人工智能课程——硕士、高级管理人员研究生课程和 ML 和 AI 高级证书课程,以加快您的职业生涯。
机器学习中数据预处理的步骤
机器学习中的数据预处理有七个重要步骤:
1.获取数据集
获取数据集是机器学习中数据预处理的第一步。 要构建和开发机器学习模型,您必须首先获取相关数据集。 该数据集将由从多个不同来源收集的数据组成,然后以适当的格式组合形成数据集。 数据集格式因用例而异。 例如,商业数据集将与医疗数据集完全不同。 虽然业务数据集将包含相关的行业和业务数据,但医疗数据集将包含与医疗保健相关的数据。
有几个在线资源可以下载数据集,例如https://www.kaggle.com/uciml/datasets和https://archive.ics.uci.edu/ml/index.php 。 您还可以通过不同的 Python API 收集数据来创建数据集。 数据集准备好后,您必须将其放入 CSV、HTML 或 XLSX 文件格式。

2. 导入所有关键库
由于 Python 是世界各地数据科学家使用最广泛且最喜欢的库,因此我们将向您展示如何导入 Python 库以在机器学习中进行数据预处理。 在此处阅读有关用于数据科学的 Python 库的更多信息。 预定义的 Python 库可以执行特定的数据预处理作业。 导入所有关键库是机器学习中数据预处理的第二步。 机器学习中用于数据预处理的三个核心 Python 库是:
- NumPy – NumPy 是 Python 中科学计算的基础包。 因此,它用于在代码中插入任何类型的数学运算。 使用 NumPy,您还可以在代码中添加大型多维数组和矩阵。
- Pandas ——Pandas 是一个优秀的开源 Python 库,用于数据操作和分析。 它广泛用于导入和管理数据集。 它包含用于 Python 的高性能、易于使用的数据结构和数据分析工具。
- Matplotlib – Matplotlib 是一个 Python 2D 绘图库,用于在 Python 中绘制任何类型的图表。 它可以跨平台(IPython shell、Jupyter notebook、Web 应用程序服务器等)以多种硬拷贝格式和交互式环境提供出版质量的图形。
阅读:面向初学者的机器学习项目创意
3. 导入数据集
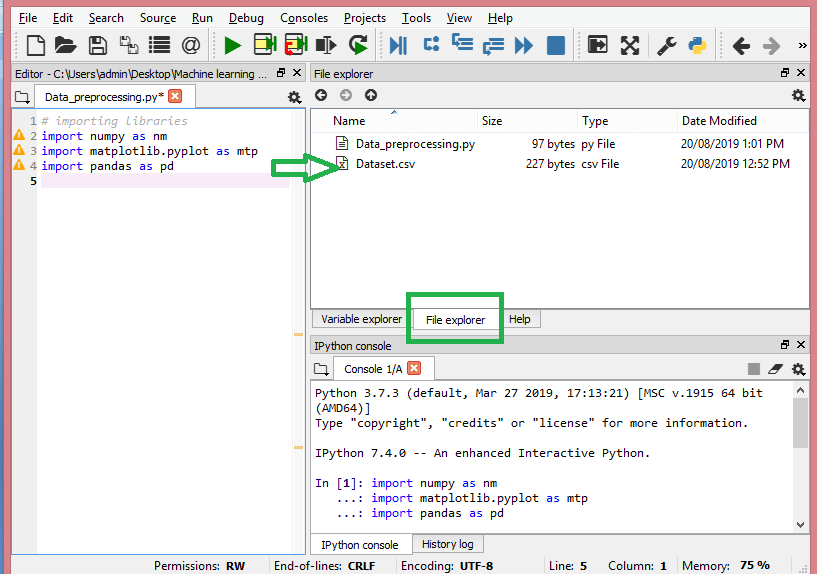
在此步骤中,您需要导入为手头的 ML 项目收集的数据集。 导入数据集是机器学习中数据预处理的重要步骤之一。 但是,在导入 dataset/s 之前,您必须将当前目录设置为工作目录。 您可以通过三个简单的步骤在 Spyder IDE 中设置工作目录:
- 将 Python 文件保存在包含数据集的目录中。
- 转到 Spyder IDE 中的文件资源管理器选项并选择所需的目录。
- 现在,单击 F5 按钮或运行选项来执行文件。
资源
这就是工作目录的外观。
设置包含相关数据集的工作目录后,您可以使用 Pandas 库的“read_csv()”函数导入数据集。 此函数可以读取 CSV 文件(本地或通过 URL)并对其执行各种操作。 read_csv() 写为:
data_set= pd.read_csv('Dataset.csv')
在这行代码中,“data_set”表示存储数据集的变量的名称。 该函数还包含数据集的名称。 执行此代码后,数据集将成功导入。
在数据集导入过程中,您必须做另一件重要的事情——提取因变量和自变量。 对于每个机器学习模型,有必要将数据集中的自变量(特征矩阵)和因变量分开。
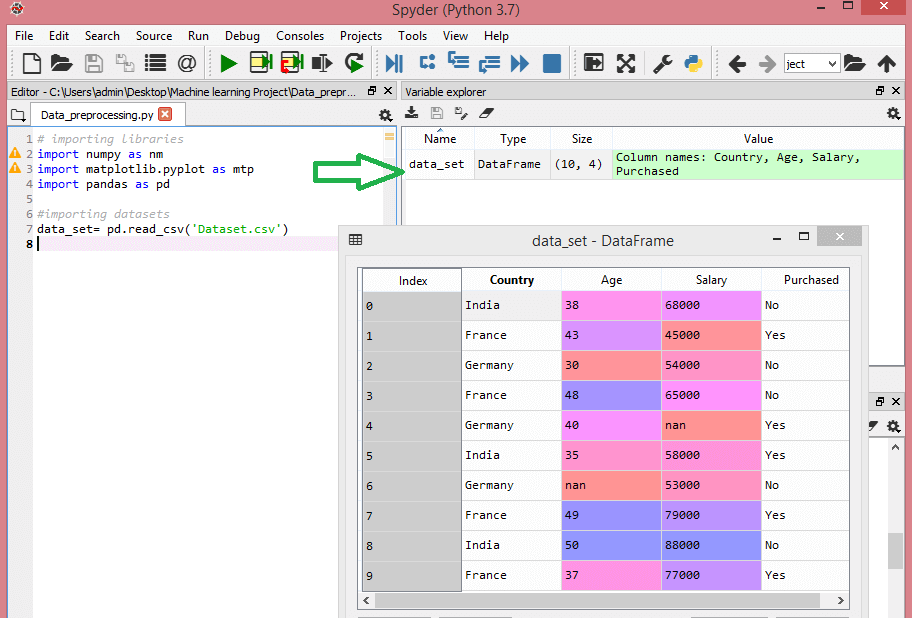
考虑这个数据集:
资源
该数据集包含三个自变量——国家、年龄和薪水,以及一个因变量——购买。
如何提取自变量?
要提取自变量,可以使用 Pandas 库的“iloc[]”函数。 此函数可以从数据集中提取选定的行和列。
x= data_set.iloc[:,:-1].values
在上面的代码行中,第一个冒号(:) 考虑所有行,第二个冒号(:) 考虑所有列。 该代码包含“:-1”,因为您必须省略包含因变量的最后一列。 通过执行此代码,您将获得特征矩阵,如下所示 -
[['印度'38.0 68000.0]
['法国' 43.0 45000.0]
['德国'30.0 54000.0]
['法国' 48.0 65000.0]
['德国' 40.0 nan]
['印度' 35.0 58000.0]
['德国'南 53000.0]
['法国' 49.0 79000.0]
['印度' 50.0 88000.0]
['法国' 37.0 77000.0]]
如何提取因变量?
您也可以使用“iloc[]”函数来提取因变量。 这是你写它的方式:
y= data_set.iloc[:,3].values
这行代码只考虑最后一列的所有行。 通过执行上述代码,您将获得因变量数组,如下所示 -
array(['No', 'Yes', 'No', 'No', 'Yes', 'Yes', 'No', 'Yes', 'No', 'Yes'],
数据类型=对象)
4. 识别和处理缺失值
在数据预处理中,识别和正确处理缺失值至关重要,如果不这样做,您可能会从数据中得出不准确和错误的结论和推论。 不用说,这会妨碍您的 ML 项目。
基本上,有两种方法可以处理丢失的数据:
- 删除特定行- 在此方法中,您删除具有空值的特定行,该行的特征或特定列缺失超过 75% 的值。 但是,这种方法并不是 100% 有效的,建议您仅在数据集有足够样本的情况下使用它。 您必须确保在删除数据后,不会再增加偏差。
- 计算平均值——此方法对于具有数字数据(如年龄、薪水、年份等)的特征很有用。在这里,您可以计算包含缺失值的特定特征或列或行的平均值、中位数或众数,并替换缺失值的结果。 这种方法可以为数据集增加方差,并且可以有效地否定任何数据丢失。 因此,与第一种方法(省略行/列)相比,它产生了更好的结果。 另一种近似方法是通过相邻值的偏差。 但是,这对线性数据最有效。
阅读:使用云的机器学习应用程序的应用程序
5. 对分类数据进行编码
分类数据是指在数据集中具有特定类别的信息。 在上面引用的数据集中,有两个分类变量——国家和购买。
机器学习模型主要基于数学方程。 因此,您可以直观地理解,将分类数据保留在方程式中会导致某些问题,因为您只需要方程式中的数字。
如何编码国家变量?
从我们的数据集示例中可以看出,国家列会导致问题,因此您必须将其转换为数值。 为此,您可以使用 sci-kit 学习库中的 LabelEncoder() 类。 代码如下——
#分类数据
#for 国家变量
从 sklearn.preprocessing 导入 LabelEncoder
label_encoder_x= 标签编码器()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
输出将是 -
出[15]:
数组([[2, 38.0, 68000.0],
[0, 43.0, 45000.0],
[1, 30.0, 54000.0],
[0, 48.0, 65000.0],
[1, 40.0, 65222.22222222222],
[2, 35.0, 58000.0],
[1, 41.111111111111114, 53000.0],
[0, 49.0, 79000.0],
[2, 50.0, 88000.0],
[0, 37.0, 77000.0]], dtype=object)
在这里我们可以看到 LabelEncoder 类已经成功地将变量编码为数字。 但是,在上面显示的输出中,有一些国家变量被编码为 0、1 和 2。 因此,ML 模型可能会假设三个变量之间存在某种相关性,从而产生错误的输出。 为了消除这个问题,我们现在将使用虚拟编码。
虚拟变量是那些取值 0 或 1 来表示不存在或存在可以改变结果的特定分类效应的变量。 在这种情况下,值 1 表示该变量存在于特定列中,而其他变量的值变为 0。在虚拟编码中,列数等于类别数。
由于我们的数据集具有三个类别,因此它将生成具有值 0 和 1 的三列。对于虚拟编码,我们将使用 scikit-learn 库的 OneHotEncoder 类。 输入代码如下——
#for 国家变量
从 sklearn.preprocessing 导入 LabelEncoder,OneHotEncoder
label_encoder_x= 标签编码器()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#虚拟变量的编码
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
执行此代码时,您将获得以下输出 -
数组([[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.80000000e+01,
6.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.30000000e+01,
4.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 3.00000000e+01,
5.40000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.80000000e+01,
6.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.00000000e+01,
6.52222222e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.50000000e+01,
5.80000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.11111111e+01,
5.30000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.90000000e+01,
7.90000000e+04],

[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 5.00000000e+01,
8.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.70000000e+01,
7.70000000e+04]])
在上面显示的输出中,所有变量都分为三列并编码为值 0 和 1。
如何编码购买的变量?
对于第二个分类变量,即购买的,可以使用 LableEncoder 类的“labelencoder”对象。 我们没有使用 OneHotEncoder 类,因为购买的变量只有两个类别是或否,这两个类别都被编码为 0 和 1。
此变量的输入代码将是 -
labelencoder_y= 标签编码器()
y= labelencoder_y.fit_transform(y)
输出将是 -
出[17]:数组([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
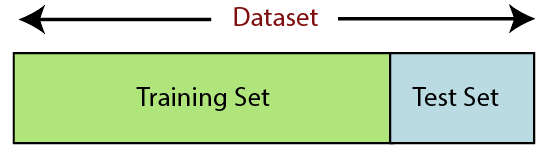
6. 分割数据集
拆分数据集是机器学习中数据预处理的下一步。 机器学习模型的每个数据集都必须分成两个独立的集合——训练集和测试集。
资源
训练集表示用于训练机器学习模型的数据集子集。 在这里,您已经知道输出。 另一方面,测试集是用于测试机器学习模型的数据集的子集。 ML 模型使用测试集来预测结果。
通常,数据集被分成 70:30 或 80:20 的比例。 这意味着您可以将 70% 或 80% 的数据用于训练模型,而忽略其余的 30% 或 20%。 拆分过程根据相关数据集的形状和大小而有所不同。
要拆分数据集,您必须编写以下代码行 -
从 sklearn.model_selection 导入 train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
在这里,第一行将数据集的数组拆分为随机训练和测试子集。 第二行代码包括四个变量:
- x_train – 训练数据的特征
- x_test – 测试数据的特征
- y_train – 训练数据的因变量
- y_test – 测试数据的自变量
因此,train_test_split() 函数包括四个参数,其中前两个用于数据数组。 test_size 函数指定测试集的大小。 test_size 可能是 .5、.3 或 .2——这指定了训练集和测试集之间的划分比率。 最后一个参数“random_state”为随机生成器设置种子,以便输出始终相同。
7. 特征缩放
特征缩放标志着机器学习中数据预处理的结束。 它是一种在特定范围内对数据集的自变量进行标准化的方法。 换句话说,特征缩放限制了变量的范围,以便您可以在共同的基础上比较它们。
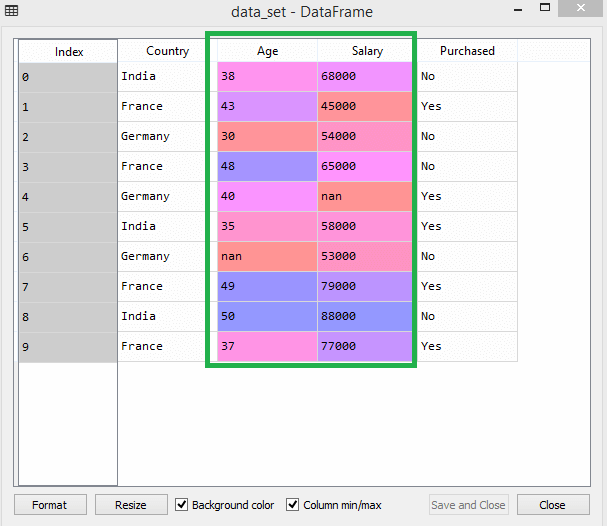
以这个数据集为例——
资源
在数据集中,您可以注意到年龄和薪水列的比例不同。 在这种情况下,如果您从年龄和薪水列中计算任意两个值,薪水值将支配年龄值并提供不正确的结果。 因此,您必须通过执行机器学习的特征缩放来消除此问题。
大多数 ML 模型基于欧几里德距离,表示为:
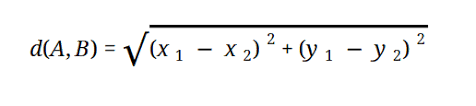
资源
您可以通过两种方式在机器学习中执行特征缩放:
标准化
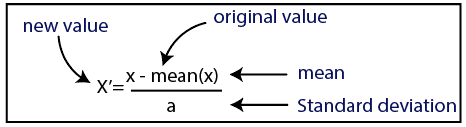
资源
正常化
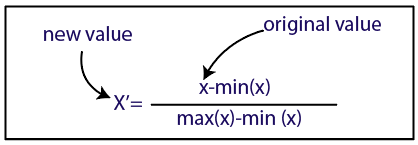
资源
对于我们的数据集,我们将使用标准化方法。 为此,我们将使用以下代码行导入 sci-kit-learn 库的 StandardScaler 类:
从 sklearn.preprocessing 导入 StandardScaler
下一步将是为自变量创建 StandardScaler 类的对象。 在此之后,您可以使用以下代码拟合和转换训练数据集:
st_x=标准缩放器()
x_train=st_x.fit_transform(x_train)
对于测试数据集,你可以直接应用 transform() 函数(你不需要使用 fit_transform() 函数,因为它已经在训练集中完成了)。 代码如下——
x_test=st_x.transform(x_test)
测试数据集的输出将显示 x_train 和 x_test 的缩放值:
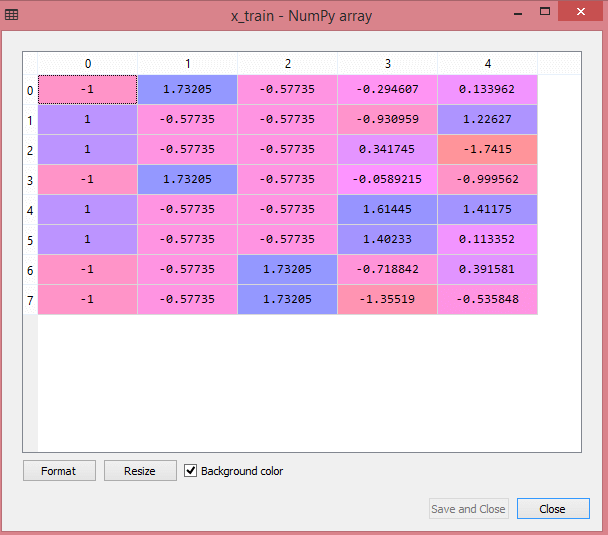
资源
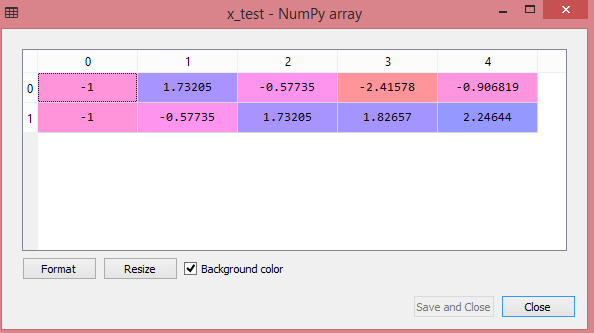
资源
输出中的所有变量都在值 -1 和 1 之间缩放。
现在,结合我们迄今为止执行的所有步骤,您将获得:
# 导入库
将 numpy 导入为 nm
将 matplotlib.pyplot 导入为 mtp
将熊猫导入为 pd
#导入数据集
data_set= pd.read_csv('Dataset.csv')
#提取自变量
x= data_set.iloc[:, :-1].values
#提取因变量
y= data_set.iloc[:, 3].values
#处理缺失数据(用平均值替换缺失数据)
从 sklearn.preprocessing 导入 Imputer
imputer= Imputer(missing_values ='NaN', strategy='mean', axis = 0)
#将 imputer 对象拟合到自变量 x。
imputerimputer= imputer.fit(x[:, 1:3])
#用计算的平均值替换缺失数据
x[:, 1:3]= imputer.transform(x[:, 1:3])
#for 国家变量
从 sklearn.preprocessing 导入 LabelEncoder,OneHotEncoder
label_encoder_x= 标签编码器()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#虚拟变量的编码
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
#encoding 购买变量
labelencoder_y= 标签编码器()
y= labelencoder_y.fit_transform(y)
# 将数据集拆分为训练集和测试集。
从 sklearn.model_selection 导入 train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
#数据集的特征缩放
从 sklearn.preprocessing 导入 StandardScaler
st_x=标准缩放器()
x_train=st_x.fit_transform(x_train)
x_test=st_x.transform(x_test)
简而言之,这就是机器学习中的数据处理!
您可以与upGrad一起查看IIT 德里的机器学习和人工智能执行 PG 计划。 IIT德里是印度最负盛名的机构之一。 拥有超过 500 多名在主题方面最优秀的内部教职员工。
数据预处理的重要性是什么?
由于错误、冗余、缺失值和不一致都会危及数据集的完整性,因此您必须解决所有这些问题以获得更准确的结果。 假设您使用有缺陷的数据集来训练机器学习系统来处理客户的购买。 系统很可能会产生偏差和偏差,从而导致糟糕的用户体验。 因此,在您将这些数据用于您的预期目的之前,它必须尽可能有条理且“干净”。 根据您要处理的困难类型,有多种选择。
什么是数据清洗?
您的数据集中几乎肯定会有缺失和嘈杂的数据。 由于数据收集过程并不理想,您将获得大量无用和缺失的信息。 数据清理是您应该采用的方式来处理这个问题。 这可以分为两类。 第一个讨论如何处理丢失的数据。 您可以选择忽略数据集合的这一部分(称为元组)中的缺失值。 第二种数据清洗方法是针对有噪声的数据。 如果您希望整个过程顺利运行,那么摆脱系统无法读取的无用数据至关重要。
数据转换和缩减是什么意思?
处理完问题后,数据预处理进入转换阶段。 您使用它将数据转换为相关构象以进行分析。 规范化、属性选择、离散化和概念层次生成是可用于实现此目的的一些方法。 即使对于自动化方法,筛选大型数据集也可能需要很长时间。 这就是数据缩减阶段如此重要的原因:它通过将数据集限制为最重要的信息来减少数据集的大小,提高存储效率,同时降低使用它们的财务和时间费用。