
Python 中的数据框:Python 深入教程 2022
已发表: 2021-01-09如果您是使用 Python 编程语言工作的开发人员或编码人员,那么您必须熟悉最令人惊叹的数据管理库之一——Pandas,它是最顶级的 Python 库之一。 多年来,Pandas 已成为使用 Python 进行数据分析和管理的标准工具。 阅读其他重要的 Python 工具。
Pandas 无疑是用于数据科学的最通用的 Python 包,这是正确的。 它提供了强大、富有表现力和灵活的数据结构,便于数据操作和分析,Python 中的 Data Frames 就是这些结构之一。
这正是我们在这篇文章中讨论的主题——我们将向您介绍 Pandas 的基本数据格式,即 Pandas Data Frame。
目录
什么是数据框?
根据Pandas 库文档,数据框是“带有标记轴(行和列)的二维、大小可变、潜在异构的表格数据结构”。 简而言之,数据框是一种数据结构,其中数据以表格方式排列,即按行和列排列。
一个数据框通常具有以下特征:
- 它可能有多个行和列。
- 虽然每一行代表一个数据样本,但每一列都包含一个描述样本(行)的不同变量。
- 每列中的数据通常是相同类型的数据(例如,数字、字符串、日期等)。
- 与 excel 数据集不同,它避免了缺失值,因此行或列之间没有间隙或空值。
在 Pandas 数据框中,您还可以为数据框指定索引和列名。 索引表示行中的差异,而列名显示列中的差异。
如何在 Python 中创建数据框(使用 Pandas)
创建数据框是 Python 中数据处理的第一步。 您可以使用以下输入创建 Pandas 数据框:
- 字典
- 列表
- 系列
- 麻木的“ndarray”
- 另一个数据框
- CS等外部文件
- 创建一个空数据框
创建一个基本的数据框,也就是一个空数据框是很容易的。 这是一个例子:
输入 -

输出 -

- 从列表创建数据框
您可以使用单个列表或多个列表创建数据框。
输入 -

输出 -

- 从“ndarrays”或列表的字典创建数据框
要从 ndarrays 的字典创建数据框,所有 ndarrays 必须具有相同的长度。 此外,如果它被索引,索引的长度应该等于数组的长度。 但是,如果它没有被索引,默认情况下索引将是 range(n),其中 'n' 表示数组长度。
输入 -

输出 -

这里的值 0,1,2,3 是使用函数 range(n) 分配给每一行的默认索引。
什么是基本的数据框操作?
现在我们已经了解了在 Python 中创建数据框的三种方法,是时候了解数据框内的不同操作了。
- 从 Pandas 数据框中选择索引或列
在开始添加、删除和重命名 DataFrame 中的组件之前,了解如何选择索引或列非常重要。 假设这是您的数据框:

您想访问“A”列中索引 0 下的值——该值为 1。访问该值的方法有很多,但其中最重要的两种是 .loc[] 和 .iloc[]。
输入 -
输出 -
因此,如您所见,您可以通过按标签调用值或通过声明它们在索引或列中的位置来访问值。 虽然这是从数据框中选择一个值,但如何从中选择行和列?
这是如何:
输入 -
输出-
- 如何向 Pandas DataFrame 添加索引、行或列
一旦您学习了如何从数据框中访问值和选择列,您就可以学习在 Pandas 数据框中添加索引、行或列。
添加索引:
创建数据框时,您可以选择将输入添加到“索引”参数。 这确保您可以轻松访问所需的索引。 如果不指定索引,默认情况下会添加一个从 0 开始并一直持续到 DataFrame 的最后一行的数值索引。 虽然,即使在默认情况下指定了索引后,您也可以通过调用 Data Frame 中的 set_index() 函数来使用列并将其转换为索引。
添加一行:
您可以使用 append 函数将行添加到 DataFrame。

输入 -

输出 -

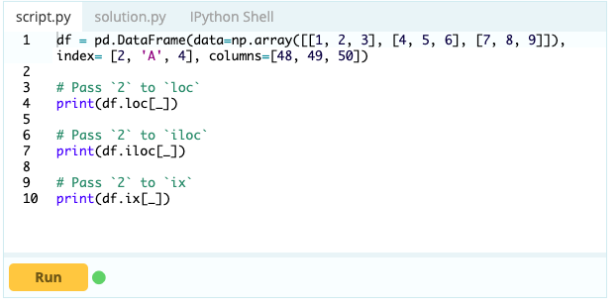
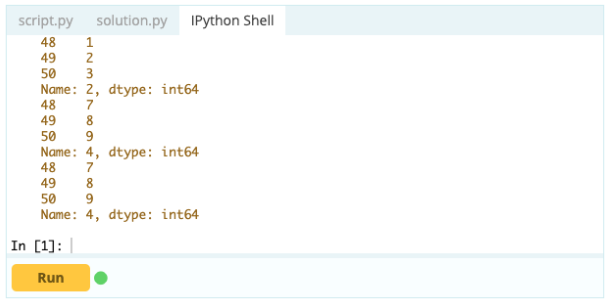
您还可以使用 .loc 在 DataFrame 中插入行,如下所示:
输入 -
输出 -
添加列
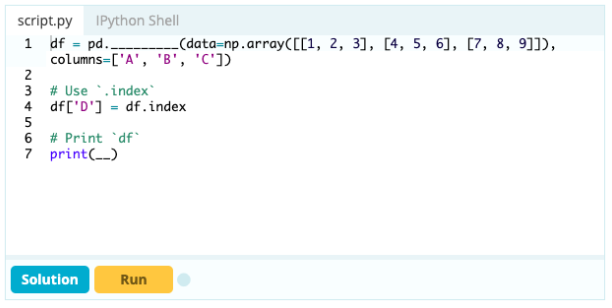
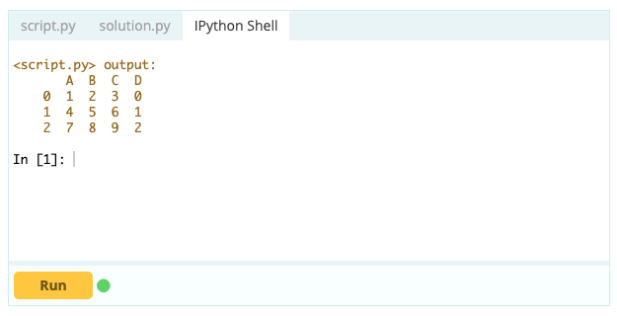
如果您想将索引作为数据框的一部分,您可以从数据框中获取一列或引用尚未创建的列,并将其分配给 .index 属性,如下所示:
输入 -
输出 -
要向数据框添加列,您还可以使用向数据框添加索引的相同方法,即可以使用 .loc[ ] 或 .iloc[ ] 函数。 例如:
输入 -
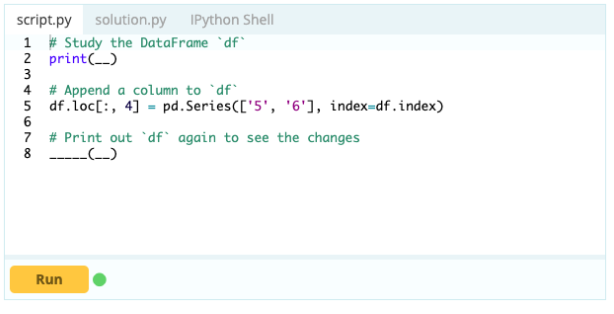
输出
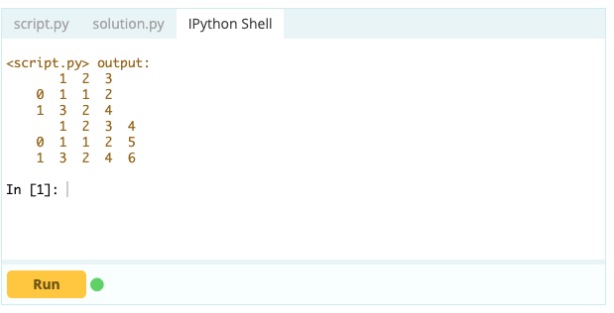
使用 .loc[ ],您可以将 Series 添加到现有 DataFrame。 由于 Series 对象与 Data Frame 的列非常相似,因此很容易将 Series 添加到现有 Data Frame 中。
- 如何重置数据框的索引?
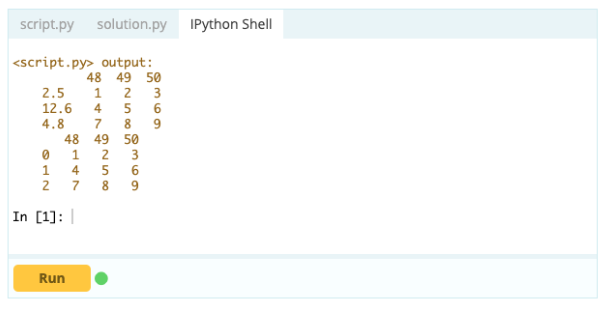
如果数据框的形状不符合您的要求,您可以重置它的索引。 您可以使用 .reset_index() 函数来执行此操作。
输入 -
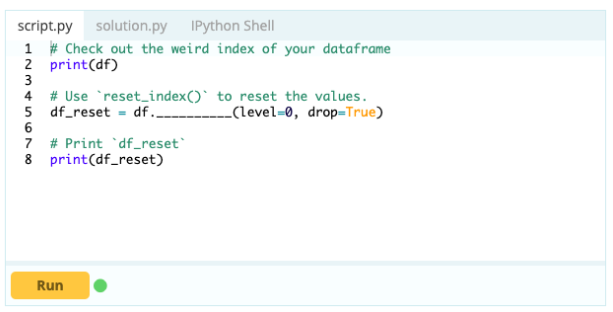
输出 -
- 如何删除 Pandas DataFrame 的索引、行或列
删除索引
- 重置数据框的索引。
- 使用 del df.index.name 函数删除索引名称(如果有)。
- 删除一个索引和一行。
- 通过重置索引删除所有重复的索引值,删除已添加到数据框中的索引列的重复项,并再次将新列(没有重复索引)恢复为索引。
删除列
要从数据框中删除列,您可以使用 drop() 函数。
输入 -
输出 -
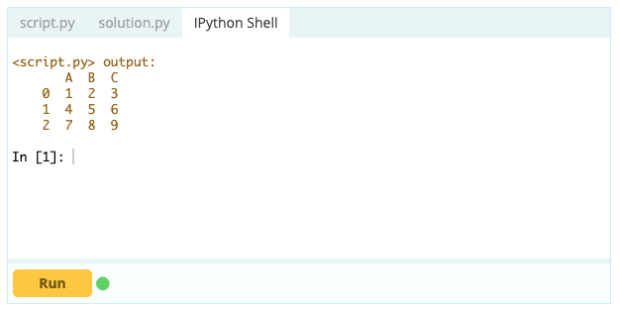
删除一行
要从 DataFrame 中删除一行,可以使用 drop() 函数,通过 index 属性指定要从 DataFrame 中删除的行的索引。
输入 -
输出 -
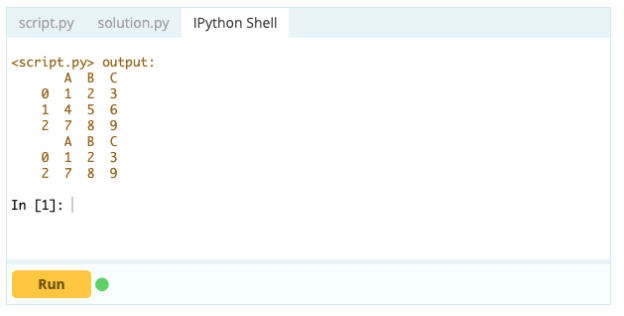
但是,要删除重复行,您可以使用 df.drop_duplicates() 函数。
输入 -
输出 -
资料来源:教程点数据营
结论
因此,这里有您使用 Pandas 在 Python 中使用 Data Frame 的基本教程。
如果您有兴趣学习 Python、数据科学,请查看 IIIT-B 和 upGrad 的数据科学 PG 文凭,该文凭专为在职专业人士而设,提供 10 多个案例研究和项目、实用的实践研讨会、与行业专家的指导,与行业导师一对一,400 多个小时的学习和顶级公司的工作协助。
为什么 Pandas 是在 Python 中创建数据帧的首选库之一?
Pandas 库被认为最适合创建数据框,因为它提供了各种功能,可以高效地创建数据框。 其中一些特性如下: Pandas 为我们提供了各种数据帧,这些数据帧不仅允许有效的数据表示,而且使我们能够对其进行操作。 它提供有效的对齐和索引功能,提供标记和组织数据的智能方式。 Pandas 的一些特性使代码更简洁,增加了可读性,从而提高了效率。 它还可以读取多种文件格式。 JSON、CSV、HDF5 和 Excel 是 Pandas 支持的一些文件格式。 对于许多程序员来说,合并多个数据集是一个真正的挑战。 Pandas 也克服了这一点,并且非常有效地合并了多个数据集。
补充 Pandas 库的其他库和工具是什么?
Pandas 不仅可以作为创建数据框的中央库,还可以与 Python 的其他库和工具一起使用以提高效率。 Pandas 是基于 NumPy Python 包构建的,这表明大部分 Pandas 库结构都是从 NumPy 包复制而来的。 Pandas 库中数据的统计分析由 SciPy 操作,Matplotlib 上的绘图函数和 Scikit-learn 中的机器学习算法。 Jupyter Notebook 是一个基于 Web 的交互式环境,可用作 IDE,并为 Pandas 提供良好的环境。
什么是基本的数据帧操作?
在开始任何操作(如添加或删除)之前选择索引或列很重要。 一旦你学会了如何从数据框中访问值和选择列,你就可以学习在 Pandas 数据框中添加索引、行或列。 如果数据框中的索引不符合您的要求,您可以重置它。 要重置索引,您可以使用“reset_index()”函数。