
使用 Next.js 创建多作者博客
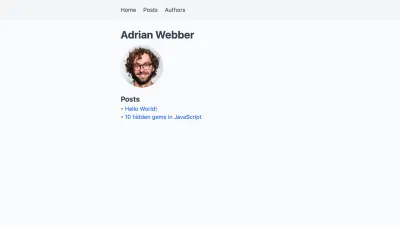
已发表: 2022-03-10在本文中,我们将使用 Next.js 构建一个支持两个或多个作者的博客。 我们会将每个帖子归于作者,并在帖子中显示他们的姓名和图片。 每个作者还会获得一个个人资料页面,其中列出了他们贡献的所有帖子。 它看起来像这样:

我们将把所有信息保存在本地文件系统的文件中。 两种类型的内容,帖子和作者,将使用不同类型的文件。 文字较多的帖子将使用 Markdown,从而简化编辑过程。 因为作者的信息比较少,我们将把它保存在 JSON 文件中。 辅助函数将使读取不同的文件类型和组合它们的内容更容易。
Next.js 让我们可以毫不费力地读取来自不同来源和不同类型的数据。 由于其动态路由和next/link ,我们可以快速构建和导航到我们网站的各个页面。 我们还通过next/image包免费获得图像优化。
通过选择“包含的电池”Next.js,我们可以专注于我们的应用程序本身。 我们不必在新项目经常出现的重复性基础工作上花费任何时间。 我们可以依赖经过测试和验证的框架,而不是手动构建所有内容。 Next.js 背后庞大而活跃的社区让我们在遇到问题时很容易获得帮助。
阅读本文后,您将能够将多种内容添加到单个 Next.js 项目中。 您还可以在它们之间建立关系。 这允许您链接作者和帖子、课程和课程或演员和电影等内容。
本文假设您基本熟悉 Next.js。 如果您以前没有使用过它,您可能想先了解它如何处理页面并为它们获取数据。
我们不会在本文中介绍样式,而是专注于使其全部工作。 你可以在 GitHub 上获得结果。 如果您想继续阅读本文,还可以将样式表放入您的项目中。 要获得相同的框架,包括导航,请将您的pages/_app.js替换为此文件。
设置
我们首先使用create-next-app设置一个新项目并切换到它的目录:
$ npx create-next-app multiauthor-blog $ cd multiauthor-blog稍后我们将需要阅读 Markdown 文件。 为了使这更容易,我们还在开始之前添加了更多的依赖项。
multiauthor-blog$ yarn add gray-matter remark remark-html 安装完成后,我们可以运行dev脚本来启动我们的项目:
multiauthor-blog$ yarn dev我们现在可以浏览我们的网站。 在浏览器中,打开 https://localhost:3000。 您应该会看到 create-next-app 添加的默认页面。
稍后,我们将需要一个导航来访问我们的页面。 我们甚至可以在页面存在之前将它们添加到pages/_app.js中。
import Link from 'next/link' import '../styles/globals.css' export default function App({ Component, pageProps }) { return ( <> <header> <nav> <ul> <li> <Link href="/"> <a>Home</a> </Link> </li> <li> <Link href="/posts"> <a>Posts</a> </Link> </li> <li> <Link href="/authors"> <a>Authors</a> </Link> </li> </ul> </nav> </header> <main> <Component {...pageProps} /> </main> </> ) }在本文中,我们将添加导航指向的这些缺失页面。 让我们首先添加一些帖子,这样我们就可以在博客概述页面上使用一些东西。
创建帖子
为了使我们的内容与代码分开,我们将把我们的帖子放在一个名为_posts/的目录中。 为了使编写和编辑更容易,我们将每个帖子创建为 Markdown 文件。 每个帖子的文件名将在以后作为我们路线中的 slug。 例如,文件_posts/hello-world.md可以在/posts/hello-world下访问。
一些信息,如完整的标题和简短的摘录,放在文件开头的 frontmatter 中。
--- title: "Hello World!" excerpt: "This is my first blog post." createdAt: "2021-05-03" --- Hey, how are you doing? Welcome to my blog. In this post, …添加更多这样的文件,这样博客就不会开始为空:
multi-author-blog/ ├─ _posts/ │ ├─ hello-world.md │ ├─ multi-author-blog-in-nextjs.md │ ├─ styling-react-with-tailwind.md │ └─ ten-hidden-gems-in-javascript.md └─ pages/ └─ …您可以添加自己的帖子或从 GitHub 存储库中获取这些示例帖子。
列出所有帖子
现在我们有一些帖子,我们需要一种方法将它们放到我们的博客上。 让我们首先添加一个列出所有内容的页面,作为我们博客的索引。
在 Next.js 中,在pages/posts/index.js下创建的文件将在我们的网站上以/posts的形式访问。 该文件必须导出一个用作该页面正文的函数。 它的第一个版本看起来像这样:
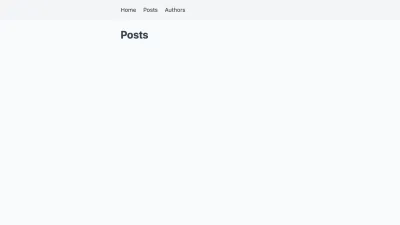
export default function Posts() { return ( <div className="posts"> <h1>Posts</h1> {/* TODO: render posts */} </div> ) }我们没有走得太远,因为我们还没有办法读取 Markdown 文件。 我们已经可以导航到 https://localhost:3000/posts,但我们只能看到标题。
我们现在需要一种方法来发布我们的帖子。 Next.js 使用一个名为getStaticProps()的函数将数据传递给页面组件。 该函数将返回对象中的props作为道具传递给组件。
从getStaticProps()中,我们将把帖子作为名为posts的道具传递给组件。 在第一步中,我们将硬编码两个占位符帖子。 通过这种方式,我们定义了以后想要接收真实帖子的格式。如果辅助函数以这种格式返回它们,我们可以在不更改组件的情况下切换到它。
帖子概述不会显示帖子的全文。 对于这个页面,每个帖子的标题、摘录、永久链接和日期就足够了。
export default function Posts() { … } +export function getStaticProps() { + return { + props: { + posts: [ + { + title: "My first post", + createdAt: "2021-05-01", + excerpt: "A short excerpt summarizing the post.", + permalink: "/posts/my-first-post", + slug: "my-first-post", + }, { + title: "My second post", + createdAt: "2021-05-04", + excerpt: "Another summary that is short.", + permalink: "/posts/my-second-post", + slug: "my-second-post", + } + ] + } + } +} 要检查连接,我们可以从 props 中获取帖子并将它们显示在Posts组件中。 我们将包括标题、创建日期、摘录和帖子的链接。 目前,该链接还不会通向任何地方。
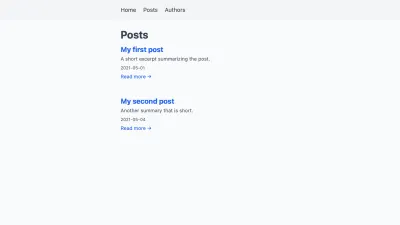
+import Link from 'next/link' -export default function Posts() { +export default function Posts({ posts }) { return ( <div className="posts"> <h1>Posts</h1> - {/* TODO: render posts */} + {posts.map(post => { + const prettyDate = new Date(post.createdAt).toLocaleString('en-US', { + month: 'short', + day: '2-digit', + year: 'numeric', + }) + + return ( + <article key={post.slug}> + <h2> + <Link href={post.permalink}> + <a>{post.title}</a> + </Link> + </h2> + + <time dateTime={post.createdAt}>{prettyDate}</time> + + <p>{post.excerpt}</p> + + <Link href={post.permalink}> + <a>Read more →</a> + </Link> + </article> + ) + })} </div> ) } export function getStaticProps() { … }在浏览器中重新加载页面后,它现在显示以下两个帖子:
我们不想永远在getStaticProps()中硬编码我们所有的博客文章。 毕竟,这就是我们之前在_posts/目录中创建所有这些文件的原因。 我们现在需要一种方法来读取这些文件并将它们的内容传递给页面组件。
我们有几种方法可以做到这一点。 我们可以直接在getStaticProps()中读取文件。 因为这个函数在服务器而不是客户端上运行,所以我们可以访问其中的原生 Node.js 模块,比如fs 。 我们可以在保存页面组件的同一个文件中读取、转换甚至操作本地文件。
为了使文件简短并专注于一项任务,我们将把该功能移到一个单独的文件中。 这样, Posts组件只需要显示数据,而不必自己读取数据。 这为我们的项目增加了一些分离和组织。
按照惯例,我们将把读取数据的函数放在一个名为lib/api.js的文件中。 该文件将包含所有为显示它的组件获取我们内容的函数。
对于帖子概览页面,我们需要一个读取、处理和返回所有帖子的函数。 我们称之为getAllPosts() 。 在其中,我们首先使用path.join()来构建_posts/目录的路径。 然后我们使用fs.readdirSync()来读取该目录,它为我们提供了其中所有文件的名称。 映射这些名称,然后我们依次读取每个文件。
import fs from 'fs' import path from 'path' export function getAllPosts() { const postsDirectory = path.join(process.cwd(), '_posts') const filenames = fs.readdirSync(postsDirectory) return filenames.map(filename => { const file = fs.readFileSync(path.join(process.cwd(), '_posts', filename), 'utf8') // TODO: transform and return file }) } 读取文件后,我们将其内容作为长字符串获取。 为了将 frontmatter 与帖子的文本分开,我们通过gray-matter运行该字符串。 我们还将通过从文件名末尾删除.md来获取每个帖子的 slug。 我们需要那个 slug 来构建稍后可以访问帖子的 URL。 由于我们不需要该功能的帖子的 Markdown 正文,因此我们可以忽略剩余的内容。
import fs from 'fs' import path from 'path' +import matter from 'gray-matter' export function getAllPosts() { const postsDirectory = path.join(process.cwd(), '_posts') const filenames = fs.readdirSync(postsDirectory) return filenames.map(filename => { const file = fs.readFileSync(path.join(process.cwd(), '_posts', filename), 'utf8') - // TODO: transform and return file + // get frontmatter + const { data } = matter(file) + + // get slug from filename + const slug = filename.replace(/\.md$/, '') + + // return combined frontmatter and slug; build permalink + return { + ...data, + slug, + permalink: `/posts/${slug}`, + } }) } 请注意我们如何将...data传播到此处返回的对象中。 这让我们可以从它的 frontmatter 中以{post.title}而不是{post.data.title}的形式访问值。
回到我们的帖子概览页面,我们现在可以用这个新功能替换占位符帖子。
+import { getAllPosts } from '../../lib/api' export default function Posts({ posts }) { … } export function getStaticProps() { return { props: { - posts: [ - { - title: "My first post", - createdAt: "2021-05-01", - excerpt: "A short excerpt summarizing the post.", - permalink: "/posts/my-first-post", - slug: "my-first-post", - }, { - title: "My second post", - createdAt: "2021-05-04", - excerpt: "Another summary that is short.", - permalink: "/posts/my-second-post", - slug: "my-second-post", - } - ] + posts: getAllPosts(), } } }重新加载浏览器后,我们现在看到的是我们的真实帖子,而不是我们之前的占位符。
添加单个帖子页面
我们添加到每个帖子的链接还没有指向任何地方。 还没有响应/posts/hello-world类的 URL 的页面。 使用动态路由,我们可以像这样添加一个匹配所有路径的页面。
创建为pages/posts/[slug].js的文件将匹配所有看起来像/posts/abc的 URL。 URL 中出现的值而不是[slug]将作为查询参数提供给页面。 我们可以在相应页面的getStaticProps()中使用它作为params.slug来调用辅助函数。
作为getAllPosts()的对应物,我们将调用该辅助函数getPostBySlug(slug) 。 它将返回与我们传递的 slug 匹配的单个帖子,而不是所有帖子。 在帖子的页面上,我们还需要显示底层文件的 Markdown 内容。
单个帖子的页面看起来像帖子概述的页面。 我们只传递一个post ,而不是在getStaticProps()中将posts传递到页面。 在我们了解如何将帖子的 Markdown 正文转换为可用的 HTML 之前,让我们先进行一般设置。 我们将跳过此处的占位符帖子,使用我们将在下一步中立即添加的辅助函数。
import { getPostBySlug } from '../../lib/api' export default function Post({ post }) { const prettyDate = new Date(post.createdAt).toLocaleString('en-US', { month: 'short', day: '2-digit', year: 'numeric', }) return ( <div className="post"> <h1>{post.title}</h1> <time dateTime={post.createdAt}>{prettyDate}</time> {/* TODO: render body */} </div> ) } export function getStaticProps({ params }) { return { props: { post: getPostBySlug(params.slug), }, } } 我们现在必须将函数getPostBySlug(slug)添加到我们的帮助文件lib/api.js中。 它就像getAllPosts() ,但有一些显着差异。 因为我们可以从 slug 中获取帖子的文件名,所以我们不需要先读取整个目录。 如果 slug 是'hello-world' ,我们将读取一个名为_posts/hello-world.md的文件。 如果该文件不存在,Next.js 将显示 404 错误页面。
getAllPosts()的另一个区别是,这一次,我们还需要读取帖子的 Markdown 内容。 我们可以通过首先使用remark处理它,将它作为渲染就绪的 HTML 而不是原始的 Markdown 返回。
import fs from 'fs' import path from 'path' import matter from 'gray-matter' +import remark from 'remark' +import html from 'remark-html' export function getAllPosts() { … } +export function getPostBySlug(slug) { + const file = fs.readFileSync(path.join(process.cwd(), '_posts', `${slug}.md`), 'utf8') + + const { + content, + data, + } = matter(file) + + const body = remark().use(html).processSync(content).toString() + + return { + ...data, + body, + } +} 理论上,我们可以在getPostBySlug(slug)中使用getAllPosts()函数。 我们首先使用它获取所有帖子,然后我们可以搜索与给定 slug 匹配的帖子。 这意味着我们总是需要阅读所有帖子才能获得一篇文章,这是不必要的工作。 getAllPosts()也不会返回帖子的 Markdown 内容。 我们可以更新它来做到这一点,在这种情况下,它会做比目前需要的更多的工作。
因为这两个辅助函数做不同的事情,所以我们将它们分开。 这样,我们就可以准确地将功能集中在我们需要它们完成的工作上。
使用动态路由的页面可以在其getStaticPaths() getStaticProps() 。 这个函数告诉 Next.js 构建页面的动态路径段的值。 我们可以通过使用getAllPosts()并返回定义每个帖子的slug的对象列表来提供这些。
-import { getPostBySlug } from '../../lib/api' +import { getAllPosts, getPostBySlug } from '../../lib/api' export default function Post({ post }) { … } export function getStaticProps({ params }) { … } +export function getStaticPaths() { + return { + fallback: false, + paths: getAllPosts().map(post => ({ + params: { + slug: post.slug, + }, + })), + } +} 由于我们在getPostBySlug(slug)中解析了 Markdown 内容,我们现在可以在页面上呈现它。 我们需要在此步骤中使用dangerouslySetInnerHTML ,以便 Next.js 可以呈现post.body后面的 HTML。 尽管它的名字,在这种情况下使用该属性是安全的。 因为我们可以完全控制我们的帖子,所以他们不太可能会注入不安全的脚本。
import { getAllPosts, getPostBySlug } from '../../lib/api' export default function Post({ post }) { const prettyDate = new Date(post.createdAt).toLocaleString('en-US', { month: 'short', day: '2-digit', year: 'numeric', }) return ( <div className="post"> <h1>{post.title}</h1> <time dateTime={post.createdAt}>{prettyDate}</time> - {/* TODO: render body */} + <div dangerouslySetInnerHTML={{ __html: post.body }} /> </div> ) } export function getStaticProps({ params }) { … } export function getStaticPaths() { … }如果我们按照帖子概述中的链接之一,我们现在可以访问该帖子自己的页面。
添加作者
既然我们已经连接了帖子,我们需要为我们的作者重复相同的步骤。 这一次,我们将使用 JSON 而不是 Markdown 来描述它们。 只要有意义,我们就可以像这样在同一个项目中混合不同类型的文件。 我们用来读取文件的辅助函数会为我们处理任何差异。 页面可以在不知道我们存储内容的格式的情况下使用这些功能。

首先,创建一个名为_authors/的目录并向其中添加一些作者文件。 正如我们对帖子所做的那样,按每个作者的 slug 命名文件。 稍后我们将使用它来查找作者。 在每个文件中,我们在 JSON 对象中指定作者的全名。
{ "name": "Adrian Webber" }目前,在我们的项目中有两个作者就足够了。
为了给他们更多个性,我们还为每位作者添加个人资料图片。 我们将把这些静态文件放在public/目录中。 通过用相同的 slug 命名文件,我们可以单独使用隐含的约定来连接它们。 我们可以将图片的路径添加到每个作者的 JSON 文件中,以链接两者。 通过以 slug 命名所有文件,我们可以管理此连接而无需将其写出。 JSON 对象只需要保存我们无法用代码构建的信息。
完成后,您的项目目录应如下所示。
multi-author-blog/ ├─ _authors/ │ ├─ adrian-webber.json │ └─ megan-carter.json ├─ _posts/ │ └─ … ├─ pages/ │ └─ … └─ public/ ├─ adrian-webber.jpg └─ megan-carter.jpg 与帖子一样,我们现在需要帮助函数来读取所有作者并获取单个作者。 新函数getAllAuthors()和getAuthorBySlug(slug)也在lib/api.js中。 他们的工作几乎与他们的岗位同行完全相同。 因为我们使用 JSON 来描述作者,所以这里不需要解析任何带有remark的 Markdown。 我们也不需要gray-matter来解析frontmatter。 相反,我们可以使用 JavaScript 的内置JSON.parse()将文件的文本内容读入对象。
const contents = fs.readFileSync(somePath, 'utf8') // ⇒ looks like an object, but is a string // eg '{ "name": "John Doe" }' const json = JSON.parse(contents) // ⇒ a real JavaScript object we can do things with // eg { name: "John Doe" }有了这些知识,我们的辅助函数如下所示:
export function getAllPosts() { … } export function getPostBySlug(slug) { … } +export function getAllAuthors() { + const authorsDirectory = path.join(process.cwd(), '_authors') + const filenames = fs.readdirSync(authorsDirectory) + + return filenames.map(filename => { + const file = fs.readFileSync(path.join(process.cwd(), '_authors', filename), 'utf8') + + // get data + const data = JSON.parse(file) + + // get slug from filename + const slug = filename.replace(/\.json/, '') + + // return combined frontmatter and slug; build permalink + return { + ...data, + slug, + permalink: `/authors/${slug}`, + profilePictureUrl: `${slug}.jpg`, + } + }) +} + +export function getAuthorBySlug(slug) { + const file = fs.readFileSync(path.join(process.cwd(), '_authors', `${slug}.json`), 'utf8') + + const data = JSON.parse(file) + + return { + ...data, + permalink: `/authors/${slug}`, + profilePictureUrl: `/${slug}.jpg`, + slug, + } +} 通过将作者读入我们的应用程序的方法,我们现在可以添加一个列出所有作者的页面。 在pages/authors/index.js下创建一个新页面会在我们的网站上为我们提供一个/authors页面。
辅助函数负责为我们读取文件。 这个页面组件不需要知道作者是文件系统中的 JSON 文件。 它可以在不知道从何处或如何获取数据的情况下使用getAllAuthors() 。 只要我们的辅助函数以我们可以使用的格式返回它们的数据,格式就无关紧要了。 像这样的抽象让我们可以在我们的应用程序中混合不同类型的内容。
作者的索引页面看起来很像帖子的索引页面。 我们在getStaticProps()中获取所有作者,然后将它们传递给Authors组件。 该组件映射每个作者并列出有关他们的一些信息。 我们不需要从 slug 构建任何其他链接或 URL。 辅助函数已经以可用格式返回作者。
import Image from 'next/image' import Link from 'next/link' import { getAllAuthors } from '../../lib/api/authors' export default function Authors({ authors }) { return ( <div className="authors"> <h1>Authors</h1> {authors.map(author => ( <div key={author.slug}> <h2> <Link href={author.permalink}> <a>{author.name}</a> </Link> </h2> <Image alt={author.name} src={author.profilePictureUrl} height="40" width="40" /> <Link href={author.permalink}> <a>Go to profile →</a> </Link> </div> ))} </div> ) } export function getStaticProps() { return { props: { authors: getAllAuthors(), }, } } 如果我们在我们的网站上访问/authors ,我们会看到所有作者的列表以及他们的姓名和照片。
作者个人资料的链接还没有指向任何地方。 要添加个人资料页面,我们在pages/authors/[slug].js下创建一个文件。 因为作者没有任何文字内容,我们现在只能添加他们的姓名和头像。 我们还需要另一个getStaticPaths()来告诉 Next.js 为哪些 slug 构建页面。
import Image from 'next/image' import { getAllAuthors, getAuthorBySlug } from '../../lib/api' export default function Author({ author }) { return ( <div className="author"> <h1>{author.name}</h1> <Image alt={author.name} src={author.profilePictureUrl} height="80" width="80" /> </div> ) } export function getStaticProps({ params }) { return { props: { author: getAuthorBySlug(params.slug), }, } } export function getStaticPaths() { return { fallback: false, paths: getAllAuthors().map(author => ({ params: { slug: author.slug, }, })), } }有了这个,我们现在有一个基本的作者简介页面,信息非常简单。
此时,作者和帖子尚未连接。 接下来我们将搭建这个桥梁,以便我们可以将每个作者的帖子列表添加到他们的个人资料页面。
连接帖子和作者
要连接两段内容,我们需要在另一段中引用。 由于我们已经通过它们的 slug 识别帖子和作者,因此我们将引用它们。 我们可以将作者添加到帖子和帖子到作者,但是一个方向就足以将它们链接起来。 由于我们想将帖子归因于作者,我们将把作者的 slug 添加到每个帖子的 frontmatter 中。
--- title: "Hello World!" excerpt: "This is my first blog post." createdAt: "2021-05-03" +author: adrian-webber --- Hey, how are you doing? Welcome to my blog. In this post, … 如果我们保留它,通过gray-matter运行帖子会将作者字段作为字符串添加到帖子中:
const post = getPostBySlug("hello-world") const author = post.author console.log(author) // "adrian-webber" 要获取代表作者的对象,我们可以使用该 slug 并使用它调用getAuthorBySlug(slug) 。
const post = getPostBySlug("hello-world") -const author = post.author +const author = getAuthorBySlug(post.author) console.log(author) // { // name: "Adrian Webber", // slug: "adrian-webber", // profilePictureUrl: "/adrian-webber.jpg", // permalink: "/authors/adrian-webber" // } 要将作者添加到单个帖子的页面,我们需要在getStaticProps()中调用一次getAuthorBySlug(slug) ) 。
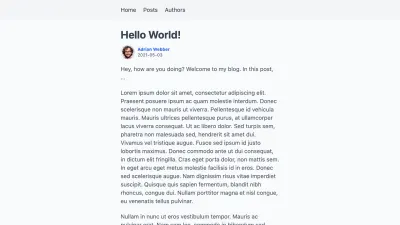
+import Image from 'next/image' +import Link from 'next/link' -import { getPostBySlug } from '../../lib/api' +import { getAuthorBySlug, getPostBySlug } from '../../lib/api' export default function Post({ post }) { const prettyDate = new Date(post.createdAt).toLocaleString('en-US', { month: 'short', day: '2-digit', year: 'numeric', }) return ( <div className="post"> <h1>{post.title}</h1> <time dateTime={post.createdAt}>{prettyDate}</time> + <div> + <Image alt={post.author.name} src={post.author.profilePictureUrl} height="40" width="40" /> + + <Link href={post.author.permalink}> + <a> + {post.author.name} + </a> + </Link> + </div> <div dangerouslySetInnerHTML={{ __html: post.body }}> </div> ) } export function getStaticProps({ params }) { + const post = getPostBySlug(params.slug) return { props: { - post: getPostBySlug(params.slug), + post: { + ...post, + author: getAuthorBySlug(post.author), + }, }, } } 请注意我们如何将...post传播到getStaticProps()中也称为post的对象中。 通过将author放在该行之后,我们最终将 author 的字符串版本替换为其完整对象。 这让我们可以通过Post组件中的post.author.name访问作者的属性。
通过这一更改,我们现在在帖子页面上获得了指向作者个人资料页面的链接,并附有他们的姓名和照片。
将作者添加到帖子概述页面需要类似的更改。 我们不需要调用getAuthorBySlug(slug)一次,而是需要映射所有帖子并为每个帖子调用它。
+import Image from 'next/image' +import Link from 'next/link' -import { getAllPosts } from '../../lib/api' +import { getAllPosts, getAuthorBySlug } from '../../lib/api' export default function Posts({ posts }) { return ( <div className="posts"> <h1>Posts</h1> {posts.map(post => { const prettyDate = new Date(post.createdAt).toLocaleString('en-US', { month: 'short', day: '2-digit', year: 'numeric', }) return ( <article key={post.slug}> <h2> <Link href={post.permalink}> <a>{post.title}</a> </Link> </h2> <time dateTime={post.createdAt}>{prettyDate}</time> + <div> + <Image alt={post.author.name} src={post.author.profilePictureUrl} height="40" width="40" /> + + <span>{post.author.name}</span> + </div> <p>{post.excerpt}</p> <Link href={post.permalink}> <a>Read more →</a> </Link> </article> ) })} </div> ) } export function getStaticProps() { return { props: { - posts: getAllPosts(), + posts: getAllPosts().map(post => ({ + ...post, + author: getAuthorBySlug(post.author), + })), } } }这会将作者添加到帖子概述中的每个帖子中:
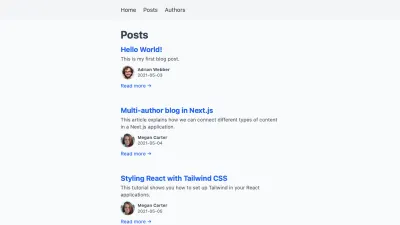
我们不需要将作者的帖子列表添加到他们的 JSON 文件中。 在他们的个人资料页面上,我们首先使用getAllPosts()获取所有帖子。 然后,我们可以过滤归因于该作者的完整列表。
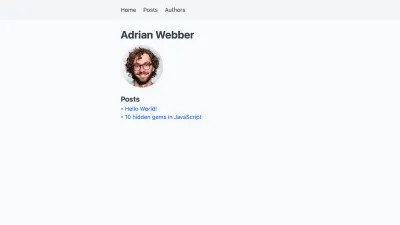
import Image from 'next/image' +import Link from 'next/link' -import { getAllAuthors, getAuthorBySlug } from '../../lib/api' +import { getAllAuthors, getAllPosts, getAuthorBySlug } from '../../lib/api' export default function Author({ author }) { return ( <div className="author"> <h1>{author.name}</h1> <Image alt={author.name} src={author.profilePictureUrl} height="40" width="40" /> + <h2>Posts</h2> + + <ul> + {author.posts.map(post => ( + <li> + <Link href={post.permalink}> + <a> + {post.title} + </a> + </Link> + </li> + ))} + </ul> </div> ) } export function getStaticProps({ params }) { const author = getAuthorBySlug(params.slug) return { props: { - author: getAuthorBySlug(params.slug), + author: { + ...author, + posts: getAllPosts().filter(post => post.author === author.slug), + }, }, } } export function getStaticPaths() { … }这为我们提供了每个作者个人资料页面上的文章列表。
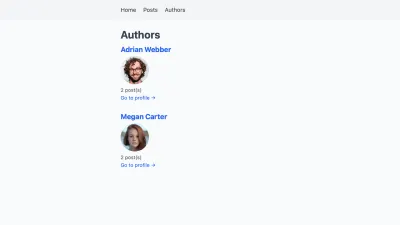
在作者概述页面上,我们只会添加他们写了多少帖子,以免使界面混乱。
import Image from 'next/image' import Link from 'next/link' -import { getAllAuthors } from '../../lib/api' +import { getAllAuthors, getAllPosts } from '../../lib/api' export default function Authors({ authors }) { return ( <div className="authors"> <h1>Authors</h1> {authors.map(author => ( <div key={author.slug}> <h2> <Link href={author.permalink}> <a> {author.name} </a> </Link> </h2> <Image alt={author.name} src={author.profilePictureUrl} height="40" width="40" /> + <p>{author.posts.length} post(s)</p> <Link href={author.permalink}> <a>Go to profile →</a> </Link> </div> ))} </div> ) } export function getStaticProps() { return { props: { - authors: getAllAuthors(), + authors: getAllAuthors().map(author => ({ + ...author, + posts: getAllPosts().filter(post => post.author === author.slug), + })), } } }这样,作者概述页面会显示每个作者贡献了多少帖子。
就是这样! 帖子和作者现在完全联系起来了。 我们可以从一个帖子到作者的个人资料页面,然后从那里到他们的其他帖子。
总结与展望
在本文中,我们通过它们独特的 slug 连接了两种相关类型的内容。 定义从帖子到作者的关系启用了各种场景。 我们现在可以在每个帖子上显示作者,并在他们的个人资料页面上列出他们的帖子。
使用这种技术,我们可以添加许多其他类型的关系。 每个帖子都可能在作者之上有一个审稿人。 我们可以通过在帖子的前端添加reviewer字段来设置它。
--- title: "Hello World!" excerpt: "This is my first blog post." createdAt: "2021-05-03" author: adrian-webber +reviewer: megan-carter --- Hey, how are you doing? Welcome to my blog. In this post, … 在文件系统上,审阅者是_authors/目录中的另一位作者。 我们也可以使用getAuthorBySlug(slug)来获取他们的信息。
export function getStaticProps({ params }) { const post = getPostBySlug(params.slug) return { props: { post: { ...post, author: getAuthorBySlug(post.author), + reviewer: getAuthorBySlug(post.reviewer), }, }, } }我们甚至可以通过在一个帖子上命名两个或多个作者而不是一个人来支持共同作者。
--- title: "Hello World!" excerpt: "This is my first blog post." createdAt: "2021-05-03" -author: adrian-webber +authors: + - adrian-webber + - megan-carter --- Hey, how are you doing? Welcome to my blog. In this post, … 在这种情况下,我们无法再在帖子的getStaticProps()中查找单个作者。 相反,我们将映射这组作者以获取所有作者。
export function getStaticProps({ params }) { const post = getPostBySlug(params.slug) return { props: { post: { ...post, - author: getAuthorBySlug(post.author), + authors: post.authors.map(getAuthorBySlug), }, }, } }我们还可以使用这种技术生成其他类型的场景。 它支持任何类型的一对一、一对多甚至多对多关系。 如果您的项目还包含时事通讯和案例研究,您也可以为每个项目添加作者。
在一个关于漫威宇宙的网站上,我们可以连接角色和他们出现的电影。在体育运动中,我们可以连接球员和他们目前效力的球队。
因为辅助函数隐藏了数据源,所以内容可能来自不同的系统。 我们可以从文件系统中读取文章,从 API 中读取评论,并将它们合并到我们的代码中。 如果某些内容与另一种类型的内容相关,我们可以将它们与这种模式联系起来。
更多资源
Next.js 提供了有关我们在其数据获取页面中使用的功能的更多背景信息。 它包括从不同类型的来源获取数据的示例项目的链接。
如果您想进一步了解此入门项目,请查看以下文章:
- 使用 Strapi 和 Next.js 构建 CSS 技巧网站克隆
用 Strapi 驱动的后端替换本地文件系统上的文件。 - 比较 Next.js 中的样式方法
探索编写自定义 CSS 以更改此启动器样式的不同方法。 - 带有 Next.js 的 Markdown/MDX
将 MDX 添加到您的项目中,以便您可以在 Markdown 中使用 JSX 和 React 组件。