我们如何改进我们的核心 Web Vitals(案例研究)
已发表: 2022-03-10去年,Google 开始强调 Core Web Vitals 的重要性,以及它们如何反映一个人在访问网络站点时的真实体验。 性能是我们公司 Instant Domain Search 的核心功能——它就在名称中。 想象一下,当我们发现我们的生命体征分数对很多人来说都不是很好时,我们会感到惊讶。 我们快速的计算机和光纤互联网掩盖了真实人们在我们网站上的体验。 不久之后,我们的 Google Search Console 中大量的红色“差”和黄色“需要改进”通知需要我们关注。 Entropy 赢了,我们必须想办法清理垃圾——让我们的网站更快。
我在 2005 年创立了 Instant Domain Search,并在我在一家 Y Combinator 公司(Snipshot,W06)工作期间将其作为副业,然后在 Facebook 担任软件工程师。 我们最近成长为一个主要位于加拿大维多利亚的小型团队,我们正在处理长期积压的新功能和性能改进。 我们糟糕的网络生命体征得分和迫在眉睫的 Google 更新使我们专注于发现和解决这些问题。
当该站点的第一个版本发布时,我使用 PHP、MySQL 和 XMLHttpRequest 构建了它。 Internet Explorer 6 得到完全支持,Firefox 的份额越来越大,而 Chrome 距离发布还有几年的时间。 随着时间的推移,我们通过各种静态站点生成器、JavaScript 框架和服务器技术不断发展。 我们当前的前端堆栈是使用 Next.js 提供的 React 和内置 Rust 的后端服务来回答我们的域名搜索。 我们尝试遵循最佳实践,通过 CDN 提供尽可能多的服务,尽可能避免使用第三方脚本,并使用简单的 SVG 图形而不是位图 PNG。 这还不够。
Next.js 让我们可以在 React 和 TypeScript 中构建我们的页面和组件。 与 VS Code 搭配使用时,开发体验非常棒。 Next.js 通常通过将 React 组件转换为静态 HTML 和 CSS 来工作。 这样,可以从 CDN 提供初始内容,然后 Next 可以“水合”页面以使元素动态化。 一旦页面被水合,我们的网站就会变成一个单页应用程序,人们可以在其中搜索和生成域名。 我们不依赖 Next.js 做很多服务器端工作,我们的大部分内容都静态导出为 HTML、CSS 和 JavaScript,以便从 CDN 提供服务。
当有人开始搜索域名时,我们将页面内容替换为搜索结果。 为了使搜索尽可能快,前端直接查询我们的 Rust 后端,该后端针对域查找和建议进行了高度优化。 我们可以立即回答许多查询,但对于某些 TLD,我们需要执行较慢的 DNS 查询,这可能需要一两秒才能解决。 当其中一些较慢的查询得到解决时,我们将使用任何新信息更新 UI。每个人的结果页面都不同,我们很难准确预测每个人对网站的体验。
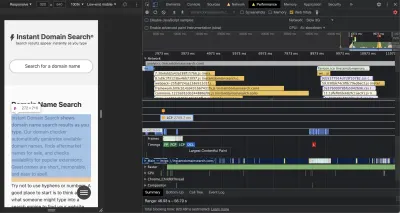
Chrome DevTools 非常出色,是解决性能问题时的好起点。 性能视图准确地显示 HTTP 请求何时发出、浏览器在何处花费时间评估 JavaScript 等等:
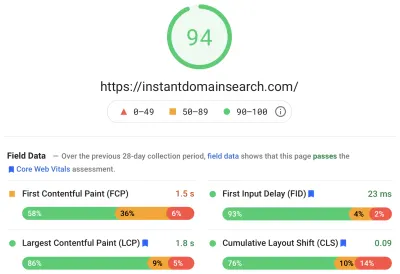
Google 将使用三个核心 Web Vitals 指标来帮助在即将到来的搜索算法更新中对网站进行排名。 Google 根据真实用户在网站上的 LCP、FID 和 CLS 分数将体验分为“好”、“需要改进”和“差”:
- LCP或最大内容绘制定义了最大内容元素变为可见所需的时间。
- FID或 First Input Delay 与站点对交互的响应有关——界面中的轻击、单击或按键与页面响应之间的时间。
- CLS或 Cumulative Layout Shift 跟踪元素在没有键盘或单击事件等操作的情况下如何在页面上移动或移动。

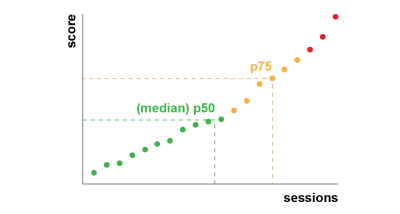
Chrome 设置为跟踪所有登录 Chrome 用户的这些指标,并将总结客户在网站上的体验的匿名统计数据发送回谷歌进行评估。 这些分数可通过 Chrome 用户体验报告访问,并在您使用 PageSpeed Insights 工具检查 URL 时显示。 这些分数代表在过去 28 天内访问该 URL 的人的第 75 个百分位体验。 这是他们将用来帮助对更新中的站点进行排名的数字。
第 75 个百分位 (p75) 指标在性能目标方面取得了合理的平衡。 例如,取平均值会隐藏人们的许多不良经历。 中位数或第 50 个百分位数 (p50) 意味着使用我们产品的人中有一半的体验更差。 另一方面,第 95 个百分位 (p95) 很难构建,因为它在连接不完整的旧设备上捕获了太多极端异常值。 我们认为基于 75% 的评分是一个公平的标准。
为了控制我们的分数,我们首先求助于 Lighthouse,以获取 Chrome 中内置的一些优秀工具,并托管在 web.dev/measure/ 和 PageSpeed Insights 上。 这些工具帮助我们找到了我们网站的一些广泛的技术问题。 我们看到 Next.js 捆绑我们的 CSS 并减慢了我们的初始渲染时间,这影响了我们的 FID。 第一个轻松的胜利来自一个实验性的 Next.js 功能,optimizeCss,它有助于显着提高我们的总体性能得分。
Lighthouse 还发现了一个缓存错误配置,导致我们的一些静态资产无法从我们的 CDN 提供服务。 我们托管在 Google Cloud Platform 上,Google Cloud CDN 要求 Cache-Control 标头包含“public”。 Next.js 不允许您配置它发出的所有标头,因此我们必须通过将 Next.js 服务器放置在 Caddy 后面来覆盖它们,Caddy 是一个用 Go 实现的轻量级 HTTP 代理服务器。 我们还借此机会通过现代浏览器中相对较新的 stale-while-revalidate 支持确保我们能够提供我们所能提供的服务,这允许 CDN 在后台异步从源(我们的 Next.js 服务器)获取内容。
从 npm 向产品中添加几乎所有需要的东西很容易——也许太容易了。 捆绑大小的增长不需要很长时间。 大包在慢速网络上下载需要更长的时间,而且 75% 的手机会花费大量时间阻塞主 UI 线程,同时它会尝试理解它刚刚下载的所有代码。 我们喜欢 BundlePhobia,它是一个免费工具,可以显示一个 npm 包将添加到你的包中的依赖项和字节数。 这导致我们用更简单的 CSS 过渡消除或替换了许多由 react-spring 驱动的动画:
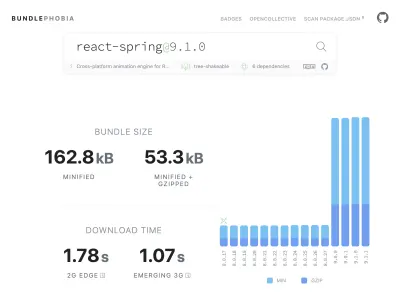
通过使用 BundlePhobia 和 Lighthouse,我们发现第三方错误记录和分析软件对我们的包大小和加载时间有很大贡献。 我们删除了这些工具,并用我们自己的客户端日志记录替换了这些工具,这些日志记录利用了现代浏览器 API,如 sendBeacon 和 ping。 我们将日志记录和分析发送到我们自己的 Google BigQuery 基础架构,在那里我们可以比任何现成的工具提供的更详细地回答我们关心的问题。 这也消除了许多第三方 cookie,使我们能够更好地控制从客户端发送日志数据的方式和时间。
我们的 CLS 分数仍有最大的提升空间。 谷歌计算 CLS 的方式很复杂——给你一个最大的“会话窗口”,间隔 1 秒,从初始页面加载或键盘或点击交互开始的 5 秒,以完成在网站上的移动. 如果您有兴趣更深入地阅读该主题,这里有关于该主题的精彩指南。 这会惩罚在您登陆网站后出现的许多类型的覆盖和弹出窗口。 例如,当您开始滚动过去的广告以到达内容时,可能会出现转移内容或追加销售的广告。 本文很好地解释了 CLS 分数的计算方式及其背后的原因。
我们从根本上反对这种数字混乱,所以我们很惊讶地看到谷歌坚持我们有多大的改进空间。 Chrome 有一个内置的 Web Vitals 覆盖,您可以使用命令菜单“显示核心 Web Vitals 覆盖”来访问它。 为了准确了解 Chrome 在其 CLS 计算中考虑了哪些元素,我们发现 Chrome Web Vitals 扩展在设置中的“控制台日志记录”选项更有帮助。 启用后,此插件会显示您当前页面的 LCP、FID 和 CLS 分数。 从控制台中,您可以准确地看到页面上的哪些元素与这些分数相关联。 我们的 CLS 分数有最大的提升空间。
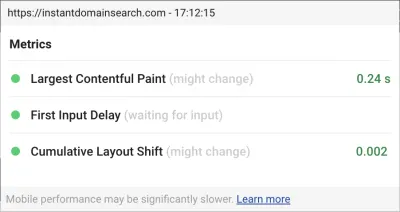
在这三个指标中,CLS 是唯一一个在您与页面交互时累积的指标。 Web Vitals 扩展有一个日志记录选项,可以在您与产品交互时准确显示导致 CLS 的元素。 当我们在 Smashing Magazine 的主页上滚动时,观察 CLS 指标是如何增加的:

随着时间的推移,Google 将继续调整其计算 CLS 的方式,因此请务必关注 Google 的 Web 开发博客了解最新情况。 使用 Chrome Web Vitals 扩展等工具时,启用 CPU 和网络节流以获得更真实的体验非常重要。 您可以使用开发人员工具通过模拟移动 CPU 来做到这一点。
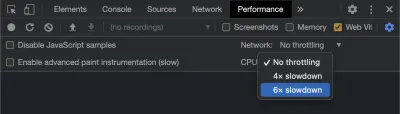
跟踪从一次部署到下一次部署进度的最佳方法是像 Google 一样衡量页面体验。 如果您设置了 Google Analytics,一个简单的方法是安装 Google 的 web-vitals 模块并将其连接到 Google Analytics。 这可以粗略衡量您的进度,并使其在 Google Analytics(分析)仪表板中可见。
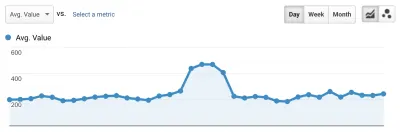
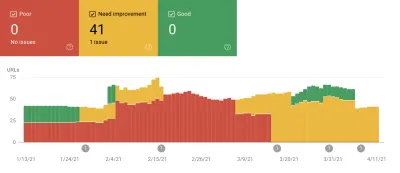
这是我们碰壁的地方。 我们可以看到我们的 CLS 分数,虽然我们已经显着提高了它,但我们还有工作要做。 我们的 CLS 分数大约为 0.23,我们需要将其降低到 0.1 以下,最好降到 0。不过,此时,我们无法找到确切的信息来告诉我们哪些页面上的哪些组件仍然影响分数。 我们可以看到 Chrome 在他们的 Core Web Vitals 工具中暴露了很多细节,但是日志聚合器抛弃了最重要的部分:究竟是哪个页面元素导致了问题。
为了捕获我们需要的所有细节,我们构建了一个无服务器函数来从浏览器中捕获 Web Vitals 数据。 由于我们不需要对数据运行实时查询,我们将其流式传输到 Google BigQuery 的流式 API 中进行存储。 这种架构意味着我们可以廉价地捕获我们可以生成的尽可能多的数据点。
在使用 Web Vitals 和 BigQuery 学习了一些经验之后,我们决定捆绑此功能并将这些工具作为开源工具发布在 vitals.dev。
使用 Instant Vitals 是一种快速开始在 BigQuery 中跟踪您的 Web Vitals 分数的方法。 以下是我们创建的 BigQuery 表架构示例:
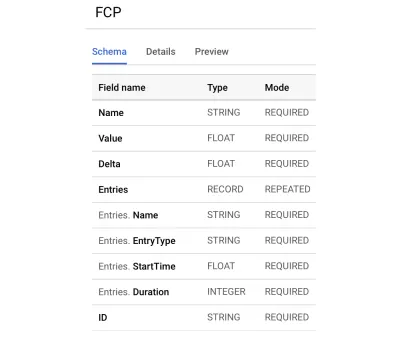
与 Instant Vitals 集成很容易。 您可以通过与客户端库集成来开始将数据发送到您的后端或无服务器功能:
import { init } from "@instantdomain/vitals-client"; init({ endpoint: "/api/web-vitals" });然后,在您的服务器上,您可以与服务器库集成以完成电路:
import fs from "fs"; import { init, streamVitals } from "@instantdomain/vitals-server"; // Google libraries require service key as path to file const GOOGLE_SERVICE_KEY = process.env.GOOGLE_SERVICE_KEY; process.env.GOOGLE_APPLICATION_CREDENTIALS = "/tmp/goog_creds"; fs.writeFileSync( process.env.GOOGLE_APPLICATION_CREDENTIALS, GOOGLE_SERVICE_KEY ); const DATASET_; init({ datasetId: DATASET_ID }).then().catch(console.error); // Request handler export default async (req, res) => { const body = JSON.parse(req.body); await streamVitals(body, body.name); res.status(200).end(); }; 只需使用请求正文和指标名称调用streamVitals即可将指标发送到 BigQuery。 该库将为您处理创建数据集和表。
在收集了一天的数据后,我们像这样运行这个查询:
SELECT `<project_name>.web_vitals.CLS`.Value, Node FROM `<project_name>.web_vitals.CLS` JOIN UNNEST(Entries) AS Entry JOIN UNNEST(Entry.Sources) WHERE Node != "" ORDER BY value LIMIT 10此查询产生如下结果:
| 价值 | 节点 |
|---|---|
4.6045324800736724E-4 | /html/body/div[1]/main/div/div/div[2]/div/div/blockquote |
7.183070668914928E-4 | /html/body/div[1]/header/div/div/header/div |
0.031002668277977697 | /html/body/div[1]/footer |
0.035830703317463526 | /html/body/div[1]/main/div/div/div[2] |
0.035830703317463526 | /html/body/div[1]/footer |
0.035830703317463526 | /html/body/div[1]/main/div/div/div[2] |
0.035830703317463526 | /html/body/div[1]/main/div/div/div[2] |
0.035830703317463526 | /html/body/div[1]/footer |
0.035830703317463526 | /html/body/div[1]/footer |
0.03988482067913317 | /html/body/div[1]/footer |
这向我们展示了哪些页面上的哪些元素对 CLS 影响最大。 它为我们的团队创建了一个清单来调查和修复。 在即时域搜索上,事实证明,缓慢或不良的移动连接将需要 500 多毫秒才能加载我们的一些搜索结果。 对于这些用户来说,CLS 最糟糕的贡献者之一实际上是我们的页脚。
布局移位分数是根据元素移动的大小以及移动的距离来计算的。 在我们的搜索结果视图中,如果设备花费超过一定时间来接收和呈现搜索结果,结果视图将折叠到zero-height ,从而将页脚显示在视图中。 当结果出现时,他们将页脚推回页面底部。 移动这么远的一个大 DOM 元素为我们的 CLS 分数增加了很多。 为了正确解决这个问题,我们需要重新构建搜索结果的收集和呈现方式。 我们决定只删除搜索结果视图中的页脚,作为一种快速破解方法,它可以阻止它在慢速连接上弹跳。
我们现在定期审查这份报告,以跟踪我们如何改进——并在我们前进的过程中利用它来对抗不断下降的结果。 我们见证了对我们网站上新推出的功能和产品的额外关注的价值,并实施了一致的检查,以确保核心生命体征有利于我们的排名。 我们希望通过分享 Instant Vitals,我们也可以帮助其他开发人员解决他们的 Core Web Vitals 分数。
Google 提供了内置于 Chrome 中的出色性能工具,我们使用它们来查找和修复许多性能问题。 我们了解到,谷歌提供的现场数据很好地总结了我们的 p75 进展,但没有可操作的细节。 我们需要准确找出导致布局偏移和输入延迟的 DOM 元素。 一旦我们开始收集我们自己的字段数据(使用 XPath 查询),我们就能够识别特定的机会来改善每个人在我们网站上的体验。 通过一些努力,我们将真实世界的 Core Web Vitals 字段分数降低到可接受的范围内,为 6 月的页面体验更新做准备。 我们很高兴看到这些数字向右下方下降!