
如何使用 Node.js 构建亚马逊产品爬虫
已发表: 2022-03-10您是否曾经处于需要深入了解特定产品市场的位置? 也许您正在推出一些软件并且需要知道如何定价。 或者,您可能已经在市场上拥有自己的产品,并希望了解添加哪些功能以获得竞争优势。 或者,也许您只是想为自己买点东西,并希望确保您物有所值。
所有这些情况都有一个共同点:您需要准确的数据才能做出正确的决定。 实际上,他们还分享了另一件事。 所有场景都可以从使用网络爬虫中受益。
网络抓取是通过使用软件提取大量网络数据的做法。 因此,从本质上讲,这是一种将点击“复制”然后“粘贴”200 次的繁琐过程自动化的方法。 当然,机器人可以在你读完这句话的时候做到这一点,所以它不仅不那么无聊,而且速度也快了很多。
但迫切的问题是:为什么有人要抓取亚马逊页面?
你即将发现! 但首先,我现在想澄清一点——虽然抓取公开数据的行为是合法的,但亚马逊有一些措施来防止它出现在他们的页面上。 因此,我敦促您在抓取时始终注意网站,注意不要损坏它,并遵守道德准则。
推荐阅读: Andreas Altheimer 的“使用 Node.js 和 Puppeteer 对动态网站进行道德抓取的指南”
为什么要提取亚马逊产品数据
作为地球上最大的在线零售商,可以肯定地说,如果你想买东西,你可以在亚马逊上买到。 因此,不言而喻,该网站有多大的数据宝库。
抓取网络时,您的主要问题应该是如何处理所有这些数据。 虽然有许多个人原因,但它归结为两个突出的用例:优化您的产品和寻找最优惠的价格。
“
让我们从第一个场景开始。 除非您设计了一款真正创新的新产品,否则您很有可能已经在亚马逊上找到了至少类似的产品。 抓取这些产品页面可以为您提供宝贵的数据,例如:
- 竞争对手的定价策略
因此,您可以调整价格以具有竞争力并了解其他人如何处理促销交易; - 客户意见
了解您未来的客户群最关心什么以及如何改善他们的体验; - 最常见的功能
查看您的竞争对手提供什么,以了解哪些功能至关重要,哪些可以留待以后使用。
从本质上讲,亚马逊拥有深入市场和产品分析所需的一切。 您将更好地准备好利用这些数据设计、发布和扩展您的产品系列。
第二种情况适用于企业和普通人。 这个想法与我之前提到的非常相似。 您可以抓取所有可以选择的产品的价格、功能和评论,因此,您将能够选择以最低价格提供最大利益的产品。 毕竟,谁不喜欢好交易呢?
并非所有产品都值得如此关注细节,但它可以与昂贵的购买产生巨大的差异。 不幸的是,虽然好处是显而易见的,但在爬取亚马逊的过程中也会遇到许多困难。
抓取亚马逊产品数据的挑战
并非所有网站都相同。 根据经验,一个网站越复杂和广泛,就越难抓取它。 还记得我说过亚马逊是最著名的电子商务网站吗? 好吧,这使得它既非常流行又相当复杂。
首先,亚马逊知道抓取机器人的行为方式,因此该网站制定了相应的对策。 也就是说,如果爬虫遵循可预测的模式,以固定的间隔发送请求,比人类更快或使用几乎相同的参数,亚马逊将注意到并阻止 IP。 代理可以解决这个问题,但我不需要它们,因为我们不会在示例中抓取太多页面。
接下来,亚马逊故意为其产品使用不同的页面结构。 也就是说,如果您检查不同产品的页面,您很有可能会发现它们的结构和属性存在显着差异。 这背后的原因很简单。 您需要针对特定系统调整您的爬虫代码,如果您在新类型的页面上使用相同的脚本,则必须重写其中的一部分。 因此,它们本质上是让您为数据工作更多。
最后,亚马逊是一个庞大的网站。 如果您想收集大量数据,在您的计算机上运行抓取软件可能会花费太多时间来满足您的需求。 过快会使您的刮板被阻塞,这一事实进一步巩固了这个问题。 因此,如果您想要快速加载数据,您将需要一个真正强大的抓取工具。
好了,问题说够了,让我们专注于解决方案!
如何为亚马逊构建 Web Scraper
为简单起见,我们将逐步编写代码。 随意与指南并行工作。
寻找我们需要的数据
所以,这里有一个场景:几个月后我要搬到一个新地方,我需要几个新书架来存放书籍和杂志。 我想知道我所有的选择,并尽可能地达成交易。 所以,让我们去亚马逊市场,搜索“货架”,看看我们得到了什么。
此搜索的 URL 和我们将要抓取的页面在这里。
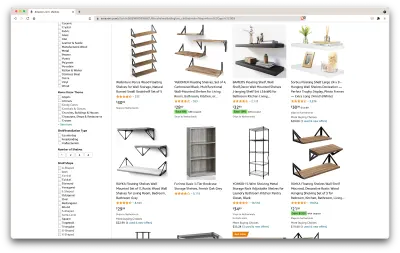
好的,让我们盘点一下我们这里有什么。 只需浏览一下页面,我们就可以很好地了解以下内容:
- 货架的外观;
- 包裹包括什么;
- 客户如何评价他们;
- 他们的价格;
- 产品链接;
- 为某些物品提供更便宜的替代品的建议。
这超出了我们的要求!
获取所需工具
在继续下一步之前,让我们确保我们已经安装和配置了以下所有工具。
- 铬合金
我们可以从这里下载。 - VSCode
按照此页面上的说明将其安装在您的特定设备上。 - 节点.js
在开始使用 Axios 或 Cheerio 之前,我们需要安装 Node.js 和 Node Package Manager。 安装 Node.js 和 NPM 的最简单方法是从 Node.Js 官方源获取安装程序之一并运行它。
现在,让我们创建一个新的 NPM 项目。 为项目创建一个新文件夹并运行以下命令:
npm init -y要创建网络爬虫,我们需要在项目中安装几个依赖项:
- 切里奥
一个开源库,通过解析标记和提供用于操作结果数据的 API 来帮助我们提取有用的信息。 Cheerio 允许我们使用选择器来选择 HTML 文档的标签:$("div")。 这个特定的选择器帮助我们选择页面上的所有<div>元素。 要安装 Cheerio,请在项目文件夹中运行以下命令:
npm install cheerio- 爱讯
用于从 Node.js 发出 HTTP 请求的 JavaScript 库。
npm install axios检查页面源
在以下步骤中,我们将详细了解信息在页面上的组织方式。 这个想法是为了更好地了解我们可以从源头中抓取什么。
开发人员工具帮助我们以交互方式探索网站的文档对象模型 (DOM)。 我们将使用 Chrome 中的开发人员工具,但您可以使用任何您喜欢的网络浏览器。
让我们通过右键单击页面上的任意位置并选择“检查”选项来打开它:
这将打开一个包含页面源代码的新窗口。 正如我们之前所说,我们正在寻找每个货架的信息。
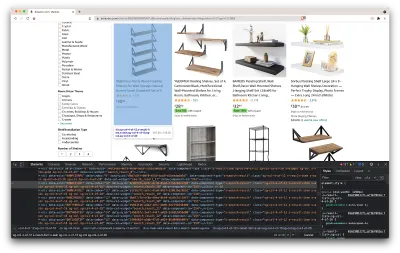
从上面的截图中我们可以看到,保存所有数据的容器具有以下类:
sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20在下一步中,我们将使用 Cheerio 选择包含我们需要的数据的所有元素。
获取数据
在我们安装了上面提供的所有依赖项之后,让我们创建一个新的index.js文件并键入以下代码行:
const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { try { const response = await axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = response.data; const $ = cheerio.load(html); const shelves = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20').each((_idx, el) => { const shelf = $(el) const title = shelf.find('span.a-size-base-plus.a-color-base.a-text-normal').text() shelves.push(title) }); return shelves; } catch (error) { throw error; } }; fetchShelves().then((shelves) => console.log(shelves)); 正如我们所看到的,我们在前两行导入了我们需要的依赖项,然后我们创建了一个fetchShelves()函数,使用 Cheerio 从页面中获取包含我们产品信息的所有元素。

它遍历它们中的每一个并将其推送到一个空数组以获得格式更好的结果。
fetchShelves()函数此时只会返回产品的标题,所以让我们获取我们需要的其余信息。 请在我们定义变量title的行之后添加以下代码行。
const image = shelf.find('img.s-image').attr('src') const link = shelf.find('aa-link-normal.a-text-normal').attr('href') const reviews = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last().attr('aria-label') const stars = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') const price = shelf.find('span.a-price > span.a-offscreen').text() let element = { title, image, link: `https://amazon.com${link}`, price, } if (reviews) { element.reviews = reviews } if (stars) { element.stars = stars } 并将shelves.push(title)替换为shelves.push(element) 。
我们现在选择我们需要的所有信息并将其添加到一个名为element的新对象中。 然后将每个元素推送到shelves数组以获取仅包含我们正在查找的数据的对象列表。
这是一个shelf对象在添加到我们的列表之前的样子:
{ title: 'SUPERJARE Wall Mounted Shelves, Set of 2, Display Ledge, Storage Rack for Room/Kitchen/Office - White', image: 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', link: 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating-Shelves-Display%2Fdp%2FB07H4NRT36%2Fref%3Dsr_1_59_sspa%3Fcrid%3D36QNR0DBY6M7J%26dchild%3D1%26keywords%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26psc%3D1&qualifier=1627970918&id=3373422987100422&widgetName=sp_btf', price: '$32.99', reviews: '6,171', stars: '4.7 out of 5 stars' }格式化数据
现在我们已经设法获取了我们需要的数据,最好将其保存为.CSV文件以提高可读性。 获取所有数据后,我们将使用 Node.js 提供的fs模块,并将一个名为saved-shelves.csv的新文件保存到项目的文件夹中。 导入文件顶部的fs模块并复制或写入以下代码行:
let csvContent = shelves.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("\n") fs.writeFile('saved-shelves.csv', "Title, Image, Link, Price, Reviews, Stars" + '\n' + csvContent, 'utf8', function (err) { if (err) { console.log('Some error occurred - file either not saved or corrupted.') } else{ console.log('File has been saved!') } }) 正如我们所看到的,在前三行中,我们通过使用逗号连接搁置对象的所有值来格式化我们之前收集的数据。 然后,使用fs模块,我们创建一个名为saved-shelves.csv的文件,添加一个包含列标题的新行,添加我们刚刚格式化的数据并创建一个处理错误的回调函数。
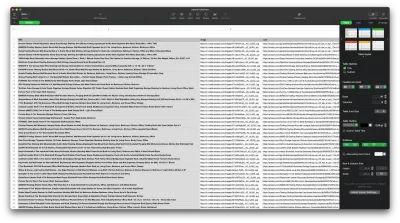
结果应如下所示:
奖金提示!
抓取单页应用程序
如今,动态内容正在成为标准,因为网站比以往任何时候都更加复杂。 为了尽可能提供最佳的用户体验,开发人员必须对动态内容采用不同的加载机制,这让我们的工作变得更加复杂。 如果您不知道这意味着什么,想象一下缺少图形用户界面的浏览器。 幸运的是,有 Puppeteer——一个神奇的 Node 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chrome 实例。 尽管如此,它仍提供与浏览器相同的功能,但必须通过键入几行代码以编程方式对其进行控制。 让我们看看它是如何工作的。
在之前创建的项目中,通过运行npm install puppeteer Puppeteer 库,创建一个新的puppeteer.js文件,然后复制或写入以下代码行:
const puppeteer = require('puppeteer') (async () => { try { const chrome = await puppeteer.launch() const page = await chrome.newPage() await page.goto('https://www.reddit.com/r/Kanye/hot/') await page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout: 2000 }) const body = await page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(body) await chrome.close() } catch (error) { console.log(error) } })() 在上面的示例中,我们创建了一个 Chrome 实例并打开了一个新的浏览器页面,该页面需要转到此链接。 在下一行中,我们告诉无头浏览器等到具有类rpBJOHq2PR60pnwJlUyP0的元素出现在页面上。 我们还指定了浏览器应该等待页面加载的时间(2000 毫秒)。
使用page变量的evaluate方法,我们指示 Puppeteer 在元素最终加载后立即在页面上下文中执行 Javascript 片段。 这将允许我们访问页面的 HTML 内容并将页面的正文作为输出返回。 然后我们通过调用chrome变量的close方法来关闭 Chrome 实例。 生成的工作应该包含所有动态生成的 HTML 代码。 这就是 Puppeteer 可以帮助我们加载动态 HTML 内容的方式。
如果您对使用 Puppeteer 感到不自在,请注意有几个替代方案,例如 NightwatchJS、NightmareJS 或 CasperJS。 它们略有不同,但最终,过程非常相似。
设置user-agent头
user-agent是一个请求标头,它告诉您正在访问的网站有关您自己的信息,即您的浏览器和操作系统。 这用于优化设置的内容,但网站也使用它来识别发送大量请求的机器人——即使它改变了 IPS。
这是user-agent标头的样子:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36为了不被检测和阻止,您应该定期更改此标头。 请特别注意不要发送空的或过时的标头,因为对于普通用户来说永远不会发生这种情况,您会脱颖而出。
速率限制
网络爬虫可以非常快速地收集内容,但您应该避免以最快的速度前进。 有两个原因:
- 短期内过多的请求会降低网站服务器的速度,甚至导致其瘫痪,从而给网站所有者和其他访问者带来麻烦。 它本质上可以成为 DoS 攻击。
- 如果没有轮换代理,这类似于大声宣布您正在使用机器人,因为没有人会每秒发送数百或数千个请求。
解决方案是在您的请求之间引入延迟,这种做法称为“速率限制”。 (实现起来也很简单! )
在上面提供的 Puppeteer 示例中,在创建body变量之前,我们可以使用 Puppeteer 提供的waitForTimeout方法等待几秒钟,然后再发出另一个请求:
await page.waitForTimeout(3000); 其中ms是您希望等待的秒数。
另外,如果我们想对 axios 示例做同样的事情,我们可以创建一个调用setTimeout()方法的 Promise,以帮助我们等待所需的毫秒数:
fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))通过这种方式,您可以避免对目标服务器施加太大压力,并为网络抓取带来更人性化的方法。
结束的想法
这就是你为亚马逊产品数据创建自己的网络爬虫的分步指南! 但请记住,这只是一种情况。 如果您想抓取不同的网站,则必须进行一些调整才能获得任何有意义的结果。
相关阅读
如果您仍然希望看到更多的网络抓取,这里有一些对您有用的阅读材料:
- “使用 JavaScript 和 Node.Js 进行 Web 抓取的终极指南”,Robert Sfichi
- “使用 Puppeteer 进行高级 Node.JS Web 抓取”,Gabriel Cioci
- “Python Web Scraping:构建 Scraper 的终极指南”,Raluca Penciuc