
使用 FaunaDB、Netlify 和 11ty 创建书签应用程序
已发表: 2022-03-10JAMstack(JavaScript、API 和标记)革命正在如火如荼地进行。 静态站点是安全、快速、可靠且有趣的。 JAMstack 的核心是将数据存储为平面文件的静态站点生成器 (SSG):Markdown、YAML、JSON、HTML 等。 有时,以这种方式管理数据可能过于复杂。 有时,我们仍然需要一个数据库。
考虑到这一点,Netlify(静态站点主机)和 FaunaDB(无服务器云数据库)合作使这两个系统的组合更容易。
为什么是书签网站?
JAMstack 非常适合许多专业用途,但我最喜欢这套技术的一个方面是它对个人工具和项目的进入门槛低。
对于我能想到的大多数应用程序,市场上有很多好的产品,但没有一个适合我。 没有人能让我完全控制我的内容。 没有成本(金钱或信息)。
考虑到这一点,我们可以使用 JAMstack 方法创建自己的迷你服务。 在这种情况下,我们将创建一个站点来存储和发布我在日常技术阅读中遇到的任何有趣的文章。
我花了很多时间阅读在 Twitter 上分享的文章。 当我喜欢一个时,我会点击“心”图标。 然后,在几天之内,随着新宠的涌入,几乎不可能找到。 我想建立一些接近“心”的轻松,但我拥有和控制的东西。
我们将如何做到这一点? 我很高兴你问。
有兴趣获取代码吗? 您可以在 Github 上获取它,或者直接从该存储库部署到 Netlify! 在这里看看成品。
我们的技术
托管和无服务器功能:Netlify
对于托管和无服务器功能,我们将使用 Netlify。 作为额外的奖励,通过上述新的合作,Netlify 的 CLI——“Netlify Dev”——将自动连接到 FaunaDB 并将我们的 API 密钥存储为环境变量。
数据库:动物数据库
FaunaDB 是一个“无服务器”NoSQL 数据库。 我们将使用它来存储我们的书签数据。
静态站点生成器:11ty
我是 HTML 的忠实信徒。 因此,本教程不会使用前端 JavaScript 来呈现我们的书签。 相反,我们将使用 11ty 作为静态站点生成器。 11ty 具有内置的数据功能,使从 API 获取数据就像编写几个简短的 JavaScript 函数一样简单。
iOS 快捷方式
我们需要一种简单的方法将数据发布到我们的数据库中。 在这种情况下,我们将使用 iOS 的快捷方式应用程序。 这也可以转换为 Android 或桌面 JavaScript 书签。
通过 Netlify Dev 设置 FaunaDB
无论您已经注册了 FaunaDB 还是需要创建一个新帐户,在 FaunaDB 和 Netlify 之间建立链接的最简单方法是通过 Netlify 的 CLI:Netlify Dev。 您可以在此处找到来自 FaunaDB 的完整说明或按照以下说明进行操作。
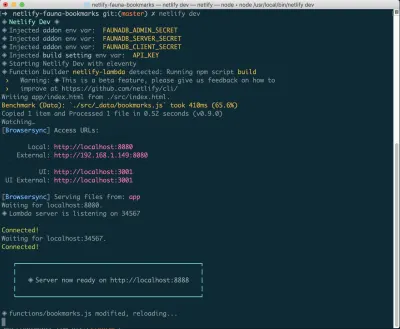
如果您还没有安装它,您可以在终端中运行以下命令:
npm install netlify-cli -g在您的项目目录中,运行以下命令:
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account 一旦这一切都连接起来,你可以在你的项目中运行netlify dev 。 这将运行我们设置的任何构建脚本,但也会连接到 Netlify 和 FaunaDB 服务并获取任何必要的环境变量。 便利!
创建我们的第一个数据
从这里,我们将登录 FaunaDB 并创建我们的第一个数据集。 我们将从创建一个名为“书签”的新数据库开始。 在数据库中,我们有集合、文档和索引。
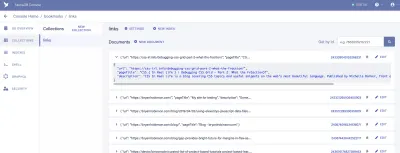
集合是分类的数据组。 每条数据都采用文档的形式。 根据 Fauna 的文档,文档是“FaunaDB 数据库中的单个、可更改的记录”。 您可以将 Collections 视为传统的数据库表,将 Document 视为一行。
对于我们的应用程序,我们需要一个集合,我们将其称为“链接”。 “链接”集合中的每个文档都是一个简单的 JSON 对象,具有三个属性。 首先,我们将添加一个新文档,我们将使用它来构建我们的第一个数据获取。
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }这为我们需要从书签中提取的信息奠定了基础,并为我们提供了第一组数据以提取到我们的模板中。
如果你和我一样,你想马上看到你的劳动成果。 让我们在页面上获取一些东西!
安装 11ty 并将数据拉入模板
由于我们希望书签以 HTML 格式呈现,而不是由浏览器获取,因此我们需要一些东西来进行呈现。 有很多很棒的方法,但为了方便和强大,我喜欢使用 11ty 静态站点生成器。
由于 11ty 是一个 JavaScript 静态站点生成器,我们可以通过 NPM 安装它。
npm install --save @11ty/eleventy 从那个安装开始,我们可以在我们的项目中运行 11 或eleventy --serve eleventy启动和运行。
Netlify Dev 通常会检测到 11ty 作为需求并为我们运行命令。 为了完成这项工作 - 并确保我们已准备好部署,我们还可以在package.json中创建“serve”和“build”命令。
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }11ty的数据文件
大多数静态站点生成器都有内置“数据文件”的想法。 通常,这些文件是 JSON 或 YAML 文件,允许您向站点添加额外信息。
在 11ty 中,您可以使用 JSON 数据文件或 JavaScript 数据文件。 通过使用 JavaScript 文件,我们实际上可以进行 API 调用并将数据直接返回到模板中。
默认情况下,11ty 希望数据文件存储在_data目录中。 然后,您可以通过将文件名用作模板中的变量来访问数据。 在我们的例子中,我们将在_data/bookmarks.js创建一个文件,并通过{{ bookmarks }}变量名访问它。
如果您想更深入地研究数据文件配置,可以阅读 11ty 文档中的示例或查看本教程,了解如何使用 Meetup API 使用 11ty 数据文件。
该文件将是一个 JavaScript 模块。 因此,为了让任何事情发挥作用,我们需要导出我们的数据或函数。 在我们的例子中,我们将导出一个函数。
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } 让我们分解一下。 我们有两个函数在这里做我们的主要工作: mapBookmarks()和getBookmarks() 。
getBookmarks()函数将从我们的 FaunaDB 数据库中获取我们的数据,而mapBookmarks()将获取一组书签并对其进行重组以更好地为我们的模板工作。
让我们深入研究getBookmarks() 。
getBookmarks()
首先,我们需要安装并初始化 FaunaDB JavaScript 驱动程序的一个实例。
npm install --save faunadb现在我们已经安装了它,让我们将它添加到数据文件的顶部。 此代码直接来自 Fauna 的文档。
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); 之后,我们就可以创建我们的函数了。 我们将从使用驱动程序的内置方法构建第一个查询开始。 第一段代码将返回数据库引用,我们可以使用它来获取所有带书签的链接的完整数据。 如果我们决定在将数据交给 11ty 之前对数据进行分页,我们使用Paginate方法作为管理游标状态的助手。 在我们的例子中,我们将只返回所有引用。
在此示例中,我假设您通过 Netlify Dev CLI 安装并连接了 FaunaDB。 使用此过程,您可以获得 FaunaDB 机密的本地环境变量。 如果您没有以这种方式安装它或者没有在您的项目中运行netlify dev ,您将需要一个像dotenv这样的包来创建环境变量。 您还需要将环境变量添加到您的 Netlify 站点配置中,以便稍后进行部署。
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })此代码将以引用形式返回我们所有链接的数组。 我们现在可以构建一个查询列表以发送到我们的数据库。
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) 从这里,我们只需要清理返回的数据。 这就是mapBookmarks()的用武之地!
mapBookmarks()
在这个函数中,我们处理数据的两个方面。
首先,我们在 FaunaDB 中获得了一个免费的 dateTime。 对于创建的任何数据,都有一个时间戳 ( ts ) 属性。 它的格式没有让 Liquid 的默认日期过滤器满意,所以让我们修复它。
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } 有了这个,我们可以为我们的数据构建一个新对象。 在这种情况下,它将有一个time属性,我们将使用 Spread 运算符来解构我们的data对象,以使它们都生活在一个层次上。
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }这是我们函数之前的数据:
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }这是我们函数后的数据:
{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }现在,我们已经为我们的模板准备了格式良好的数据!
让我们写一个简单的模板。 我们将遍历我们的书签并验证每个书签都有一个pageTitle和一个url ,这样我们就不会看起来很傻。

<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>我们现在正在摄取和显示来自 FaunaDB 的数据。 让我们花点时间想一想,这渲染出纯 HTML 并且无需在客户端获取数据是多么美妙!
但这还不足以使它成为对我们有用的应用程序。 让我们找出比在 FaunaDB 控制台中添加书签更好的方法。
输入 Netlify 函数
Netlify 的 Functions 插件是部署 AWS lambda 函数的更简单方法之一。 由于没有配置步骤,因此非常适合您只想编写代码的 DIY 项目。
该函数将位于您项目中的 URL 中,如下所示: https://myproject.com/.netlify/functions/bookmarks ://myproject.com/.netlify/functions/bookmarks 假设我们在函数文件夹中创建的文件是bookmarks.js 。
基本流程
- 将 URL 作为查询参数传递给我们的函数 URL。
- 使用该函数加载 URL 并抓取页面的标题和描述(如果可用)。
- 格式化 FaunaDB 的详细信息。
- 将详细信息推送到我们的 FaunaDB 集合。
- 重建网站。
要求
在构建它时,我们需要一些包。 我们将使用 netlify-lambda CLI 在本地构建我们的函数。 request-promise是我们将用于发出请求的包。 Cheerio.js 是我们用来从我们请求的页面中抓取特定项目的包(想想 jQuery for Node)。 最后,我们需要 FaunaDb(应该已经安装好了。
npm install --save netlify-lambda request-promise cheerio安装完成后,让我们配置我们的项目以在本地构建和提供功能。
我们将在package.json中修改“build”和“serve”脚本,如下所示:
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } 警告:当使用 Netlify 的 Functions 构建的 Webpack 编译时,Fauna 的 NodeJS 驱动程序出错。 为了解决这个问题,我们需要为 Webpack 定义一个配置文件。 您可以将以下代码保存到新的或现有的webpack.config.js中。
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; 一旦这个文件存在,当我们使用netlify-lambda命令时,我们需要告诉它从这个配置运行。 这就是我们的“服务”和“构建脚本”使用该命令的--config值的原因。
功能管家
为了使我们的主函数文件尽可能干净,我们将在一个单独的bookmarks目录中创建我们的函数并将它们导入到我们的主函数文件中。
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
getDetails()函数将获取一个 URL,从我们导出的处理程序传入。 从那里,我们将通过该 URL 访问该站点并获取页面的相关部分以存储为我们书签的数据。
我们首先需要我们需要的 NPM 包:
const rp = require('request-promise'); const cheerio = require('cheerio'); 然后,我们将使用request-promise模块为所请求的页面返回一个 HTML 字符串,并将其传递给cheerio ,从而为我们提供一个非常 jQuery 式的界面。
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }从这里,我们需要获取页面标题和元描述。 为此,我们将像在 jQuery 中一样使用选择器。
注意:在这段代码中,我们使用'head > title'作为选择器来获取页面的标题。 如果您不指定这一点,您最终可能会在页面上的所有 SVG 中获得<title>标签,这不太理想。
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }有了数据,是时候将我们的书签发送到我们在 FaunaDB 中的集合了!
saveBookmark(details)
对于我们的保存函数,我们希望将从getDetails获取的详细信息以及 URL 作为单个对象传递。 Spread 运算符再次来袭!
const savedResponse = await saveBookmark({url, ...details}); 在我们的create.js文件中,我们还需要要求并设置我们的 FaunaDB 驱动程序。 这在我们的 11ty 数据文件中应该看起来很熟悉。
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });一旦我们解决了这个问题,我们就可以编码了。
首先,我们需要将我们的详细信息格式化为 Fauna 期望我们查询的数据结构。 Fauna 需要一个具有数据属性的对象,该属性包含我们希望存储的数据。
const saveBookmark = async function(details) { const data = { data: details }; ... }然后我们将打开一个新查询以添加到我们的集合中。 在这种情况下,我们将使用查询助手并使用 Create 方法。 Create() 接受两个参数。 第一个是我们要存储数据的集合,第二个是数据本身。
保存后,我们将成功或失败返回给我们的处理程序。
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }让我们看一下完整的函数文件。
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
明眼人会注意到我们在处理程序中又导入了一个函数: rebuildSite() 。 每次我们提交一个新的——成功的——书签保存时,这个函数将使用 Netlify 的 Deploy Hook 功能从新数据重建我们的站点。
在 Netlify 的站点设置中,您可以访问 Build & Deploy 设置并创建一个新的“Build Hook”。 Hooks 的名称显示在 Deploy 部分,如果您愿意,可以选择部署非 master 分支。 在我们的例子中,我们将其命名为“new_link”并部署我们的主分支。
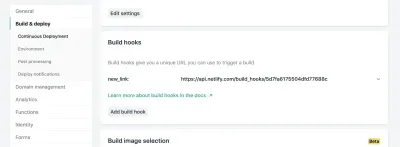
从那里,我们只需要向提供的 URL 发送一个 POST 请求。
我们需要一种发出请求的方式,并且由于我们已经安装了request-promise ,我们将通过在文件顶部要求它来继续使用该包。
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } 设置 iOS 快捷方式
所以,我们有一个数据库,一个显示数据的方法和一个添加数据的函数,但我们仍然不是很友好。
Netlify 为我们的 Lambda 函数提供 URL,但在移动设备中输入它们并不有趣。 我们还必须将 URL 作为查询参数传递给它。 这是一个很大的努力。 我们怎样才能尽可能少地做这件事呢?
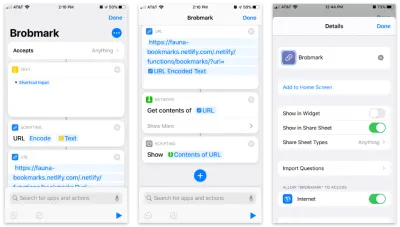
Apple 的 Shortcuts 应用程序允许将自定义项目构建到您的共享表中。 在这些快捷方式中,我们可以发送各种类型的共享过程中收集的数据请求。
这是一步一步的快捷方式:
- 接受任何项目并将该项目存储在“文本”块中。
- 将该文本传递到“脚本”块中以进行 URL 编码(以防万一)。
- 使用我们的 Netlify 函数的 URL 和
url的查询参数将该字符串传递到 URL 块中。 - 从“网络”使用“获取内容”块将 JSON POST 到我们的 URL。
- 可选:从“脚本”“显示”最后一步的内容(以确认我们发送的数据)。
要从共享菜单访问它,我们打开此快捷方式的设置并切换“在共享表中显示”选项。
从 iOS13 开始,这些共享“动作”可以被收藏并移动到对话框中的较高位置。
我们现在有了一个可以在多个平台上共享书签的工作“应用程序”!
多走一英里!
如果您受到启发自己尝试这个,还有很多其他的可能性来添加功能。 DIY 网络的乐趣在于您可以让这些类型的应用程序为您工作。 这里有一些想法:
- 使用虚假的“API 密钥”进行快速身份验证,这样其他用户就不会发布到您的网站(我的使用 API 密钥,所以不要尝试发布到它!)。
- 添加标签功能来组织书签。
- 为您的站点添加 RSS 提要,以便其他人可以订阅。
- 以编程方式为您添加的链接发送每周摘要电子邮件。
真的,天空是极限,所以开始尝试吧!