
2022 年 Apache Spark 的 6 个改变游戏规则的特性 [你应该如何使用]
已发表: 2021-01-07自从大数据席卷科技和商业世界以来,大数据工具和平台出现了巨大的热潮,尤其是 Apache Hadoop 和 Apache Spark。 今天,我们将只关注 Apache Spark,并详细讨论其业务优势和应用程序。
Apache Spark 于 2009 年成为众人瞩目的焦点,从那时起,它逐渐在行业中为自己开辟了一片天地。 根据 Apache org.,Spark 是一个“闪电般快速的统一分析引擎”,专为处理海量大数据而设计。 得益于活跃的社区,今天,Spark 是世界上最大的开源大数据平台之一。
目录
什么是 Apache Spark?
Spark 最初由加州大学(伯克利)AMPLab 开发,被设计为强大的 Hadoop 数据处理引擎,特别注重速度和易用性。 它是 Hadoop 的 MapReduce 的开源替代品。 从本质上讲,Spark 是一个并行数据处理框架,可以与 Apache Hadoop 协作,以促进在 Hadoop 上顺利快速地开发复杂的大数据应用程序。
Spark 包含大量用于机器学习 (ML) 算法和图形算法的库。 不仅如此,它还分别通过 Spark Streaming 和 Shark 支持实时流和 SQL 应用程序。 使用 Spark 的最佳之处在于,您可以使用 Java、Scala 甚至 Python 编写 Spark 应用程序,这些应用程序的运行速度(在磁盘上)和在内存中的速度比 MapReduce 应用程序快近 10 倍(在内存中)。
Apache Spark 非常通用,因为它可以以多种方式部署,并且它还为 Java、Scala、Python 和 R 编程语言提供本机绑定。 它支持 SQL、图形处理、数据流和机器学习。 这就是为什么 Spark 被广泛应用于行业各个部门的原因,包括银行、电信公司、游戏开发公司、政府机构,当然还有科技界的所有顶级公司——苹果、Facebook、IBM 和微软。
Apache Spark 的 6 个最佳特性
使 Spark 成为使用最广泛的大数据平台之一的特性是:

1. 闪电般的处理速度
大数据处理就是处理大量复杂数据。 因此,在大数据处理方面,组织和企业需要这样的框架,可以高速处理大量数据。 正如我们之前提到的,在 Hadoop 集群中,Spark 应用程序在内存中的运行速度可以提高 100 倍,在磁盘上的运行速度可以提高 10 倍。
它依赖于弹性分布式数据集 (RDD),它允许 Spark 透明地将数据存储在内存上,并仅在需要时将其读/写到磁盘。 这有助于减少数据处理过程中的大部分磁盘读写时间。
2. 易用性
Spark 允许您使用 Java、Scala、Python 和 R 编写可扩展的应用程序。因此,开发人员可以使用他们喜欢的编程语言创建和运行 Spark 应用程序。 此外,Spark 内置了 80 多个高级算子。 您可以交互式地使用 Spark 从 Scala、Python、R 和 SQL shell 中查询数据。
3. 它为复杂的分析提供支持
Spark 不仅支持简单的“map”和“reduce”操作,还支持 SQL 查询、流数据和高级分析,包括 ML 和图形算法。 它带有强大的库堆栈,例如 SQL & DataFrames 和 MLlib(用于 ML)、GraphX 和 Spark Streaming。 令人着迷的是,Spark 允许您在单个工作流/应用程序中组合所有这些库的功能。
4.实时流处理
Spark 旨在处理实时数据流。 虽然 MapReduce 是为处理和处理已经存储在 Hadoop 集群中的数据而构建的,但 Spark 可以同时执行这两项操作,还可以通过 Spark Streaming 实时处理数据。
与其他流解决方案不同,Spark Streaming 可以恢复丢失的工作并提供开箱即用的确切语义,而无需额外的代码或配置。 此外,它还允许您重用相同的代码进行批处理和流处理,甚至将流数据连接到历史数据。
5.灵活
Spark可以在集群模式下独立运行,也可以在Hadoop YARN、Apache Mesos、Kubernetes甚至云端运行。 此外,它可以访问各种数据源。 例如,Spark 可以在 YARN 集群管理器上运行并读取任何现有的 Hadoop 数据。 它可以从任何 Hadoop 数据源中读取数据,例如 HBase、HDFS、Hive 和 Cassandra。 Spark 的这一方面使其成为迁移纯 Hadoop 应用程序的理想工具,前提是应用程序的用例对 Spark 友好。
6. 活跃和扩大的社区
来自300 多家公司的开发人员为设计和构建 Apache Spark 做出了贡献。 自 2009 年以来,已有超过 1200 名开发人员为使 Spark 成为今天的样子做出了积极贡献! 自然,Spark 得到了一个活跃的开发人员社区的支持,他们致力于不断改进其功能和性能。 要联系 Spark 社区,您可以使用邮件列表进行任何查询,还可以参加 Spark 聚会小组和会议。

Spark 应用剖析
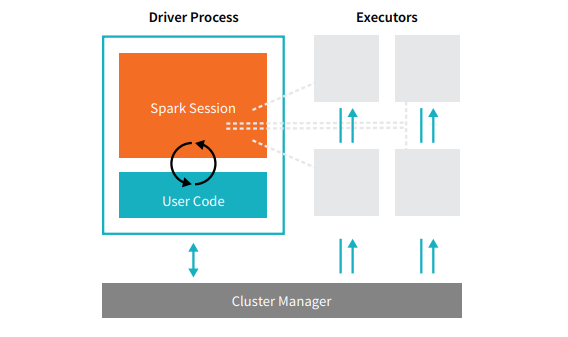
每个 Spark 应用程序都包含两个核心进程——一个主驱动进程和一组执行进程。
资源
位于集群中节点上的驱动程序进程负责运行 main() 函数。 它还处理其他三项任务——维护有关 Spark 应用程序的信息、响应用户的代码或输入,以及跨执行程序分析、分发和调度工作。 驱动程序进程构成了 Spark 应用程序的核心——它包含并维护了涵盖 Spark 应用程序生命周期的所有关键信息。
执行者或执行者进程是次要项,必须执行驱动程序分配给它们的任务。 基本上,每个执行程序执行两个关键功能——运行驱动程序分配给它的代码,并将计算状态(在该执行程序上)报告给驱动程序节点。 用户可以决定和配置每个节点应该有多少个执行器。
在 Spark 应用程序中,集群管理器控制所有机器并将资源分配给应用程序。 在这里,集群管理器可以是 Spark 的任何核心集群管理器,包括 YARN(Spark 的独立集群管理器)或 Mesos。 这意味着一个集群可以同时运行多个 Spark 应用程序。
真实世界的 Apache Spark 应用程序
Spark 是现代行业中评价最高且应用广泛的 Big Dara 平台。 Apache Spark 应用程序的一些最受好评的真实世界示例是:
机器学习 Spark
Apache Spark 拥有一个可扩展的机器学习库——MLlib。 该库明确设计用于简单性、可扩展性和促进与其他工具的无缝集成。 MLlib 不仅具有 Spark 的可扩展性、语言兼容性和速度,而且还可以执行许多高级分析任务,如分类、聚类、降维。 多亏了 MLlib,Spark 可用于预测分析、情绪分析、客户细分和预测智能。
Apache Spark 另一个令人印象深刻的特性在于网络安全领域。 Spark Streaming 允许用户在将数据包推送到存储之前对其进行实时监控。 在此过程中,它可以成功识别已知威胁源产生的任何可疑或恶意活动。 即使在数据包被发送到存储之后,Spark 也会使用 MLlib 进一步分析数据并识别网络的潜在风险。 此功能还可用于欺诈和事件检测。
用于雾计算的 Spark
Apache Spark 是用于雾计算的出色工具,尤其是在涉及物联网 (IoT) 时。 物联网严重依赖大规模并行处理的概念。 由于物联网网络是由成千上万的连接设备组成的,这个网络每秒产生的数据是无法理解的。
自然,要处理物联网设备产生的如此大量数据,您需要一个支持并行处理的可扩展平台。 还有什么比 Spark 强大的架构和雾计算能力更能处理如此大量的数据!
雾计算将数据和存储分散,而不是使用云处理,而是在网络边缘(主要嵌入物联网设备)执行数据处理功能。
为此,雾计算需要三种能力,即低延迟、ML 的并行处理和复杂的图形分析算法——每一种都存在于 Spark 中。 此外,Spark Streaming、Shark(一种可以实时运行的交互式查询工具)、MLlib 和 GraphX(一种图分析引擎)的存在进一步增强了 Spark 的雾计算能力。
交互式分析 Spark
与处理速度相对较低的 MapReduce、Hive 或 Pig 不同,Spark 可以拥有高速交互式分析。 它能够处理探索性查询,而无需对数据进行采样。 此外,Spark 兼容几乎所有流行的开发语言,包括 R、Python、SQL、Java 和 Scala。
最新版本的 Spark – Spark 2.0 – 具有称为结构化流的新功能。 借助此功能,用户可以实时对流数据运行结构化和交互式查询。
Spark的用户
既然您已经对 Spark 的特性和能力了如指掌,那么让我们来谈谈 Spark 的四个杰出用户吧!
1.雅虎
雅虎在其两个项目中使用 Spark,一个用于为访问者个性化新闻页面,另一个用于运行广告分析。 为了定制新闻页面,雅虎利用在 Spark 上运行的高级 ML 算法来了解个人用户的兴趣、偏好和需求,并相应地对故事进行分类。
对于第二个用例,Yahoo 利用 Hive on Spark 的交互功能(与任何插入 Hive 的工具集成)来查看和查询 Yahoo 在 Hadoop 上收集的广告分析数据。
2.优步
Uber 使用 Spark Streaming 与 Kafka 和 HDFS 相结合,将离散事件的大量实时数据 ETL(提取、转换和加载)转化为结构化和可用数据,以供进一步分析。 这些数据帮助优步为客户设计改进的解决方案。

3. 康维瓦
作为一家视频流媒体公司,Conviva 每月平均获得超过 400 万条视频源,这导致了巨大的客户流失。 管理实时视频流量的问题进一步加剧了这一挑战。 为了有效应对这些挑战,Conviva 使用 Spark Streaming 实时了解网络状况并相应地优化其视频流量。 这使 Conviva 能够为用户提供一致且高质量的观看体验。
4.品脱
在 Pinterest 上,用户可以在浏览网络和社交媒体时随心所欲地固定他们最喜欢的主题。 为了提供个性化和增强的客户体验,Pinterest 利用 Spark 的 ETL 功能来识别个人用户的独特需求和兴趣,并在 Pinterest 上向他们提供相关建议。
结论
总而言之,Spark 是一个极其通用的大数据平台,具有令人印象深刻的功能。 由于它是一个开源框架,因此它不断改进和发展,并添加了新的特性和功能。 随着大数据的应用变得更加多样化和广泛,Apache Spark 的用例也将如此。
如果您有兴趣了解有关大数据的更多信息,请查看我们的 PG 大数据软件开发专业文凭课程,该课程专为在职专业人士设计,提供 7 多个案例研究和项目,涵盖 14 种编程语言和工具,实用的动手操作研讨会,超过 400 小时的严格学习和顶级公司的就业帮助。
在 upGrad 查看我们的其他软件工程课程。