
Apache Kafka 架构:初学者综合指南 [2022]
已发表: 2021-12-23在我们深入研究 Apache Kafka 架构的细节之前,有必要先弄清楚为什么 Kafka 会成为头条新闻。 首先,Apache Kafka 主要用于实时流数据架构,以提供实时分析。 Kafka 的发布-订阅消息系统持久、快速、可扩展和容错,具有跟踪 IoT 传感器数据或跟踪服务调用等用例。
LinkedIn、Netflix、Microsoft、Uber、Spotify、Goldman Sachs、Cisco、PayPal 等许多公司都使用 Apache Kafka 来处理实时流数据。 例如,Kafka 的起源地 LinkedIn 使用它来跟踪运营指标和活动数据。 同样,对于 Netflix,Apache Kafka 是其消息传递、事件和流处理需求的事实标准。
从世界顶级大学学习在线软件开发培训。 获得行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。
通过了解 Apache Kafka 架构及其底层组件,可以更好地了解 Apache Kafka 的实用性。 那么,让我们来探索一下 Kafka 架构的细节。
目录
基本的 Kafka 架构概念
以下概念是理解 Apache Kafka 架构的基础:
一、话题
Kafka 主题定义了数据流式传输的通道。 因此,生产者向主题发布消息,消费者从他们订阅的主题中读取消息。 Kafka 集群中创建的主题数量没有限制,每个主题都有一个唯一的名称标识。

2. 经纪人
Brokers 是 Kafka 集群中的服务器,它们作为容器工作并保存具有不同分区的多个主题。 唯一的整数 ID 标识 Kafka 集群中的代理,与这些代理中的任何一个连接意味着与整个集群连接。
3. 分区
Kafka 主题分为许多称为分区的部分。 分区按顺序分开,允许多个消费者并行读取特定主题的数据。 一个主题的分区分布在 Kafka 集群中的多个服务器上,每个服务器管理其大量分区的数据和请求。 消息到达代理和密钥,密钥确定特定消息将到达的分区。 因此,具有相同键的消息会进入同一个分区。 如果未指定密钥,则按照循环方法确定分区。
4. 复制品
在 Kafka 中,副本就像分区备份,以确保在计划关闭或故障的情况下不会丢失数据。 换句话说,副本是分区的副本。
5. 分区偏移
由于 Kafka 中的消息或记录被分配给分区,因此每个记录都提供了一个偏移量来指定其在分区中的位置。 因此,与记录关联的偏移值有助于在分区内轻松识别它。 分区偏移量仅在该特定分区内有意义,并且由于将记录添加到分区末端,因此较旧的记录将具有较低的偏移量值。
6. 生产者
Kafka 生产者向一个或多个主题发布消息,并将数据发送到 Kafka 集群。 一旦生产者向 Kafka 主题发布消息,代理就会收到消息并将其添加到特定分区。 然后,生产者可以选择他们想要发布消息的分区。
7. 消费者和消费者群体
消费者从 Kafka 集群中读取消息。 当消费者准备好接收消息时,将从代理中提取数据。 消费者属于一个消费者组,特定组中的每个消费者负责读取其订阅的每个主题的分区子集。
8. 领导者和追随者
每个 Kafka 分区都有一台服务器扮演领导者的角色。 领导者执行该特定分区的所有读写任务。 另一方面,追随者的工作是复制领导者的数据。 当特定分区中的领导者出现故障时,其中一个跟随者节点将承担领导者的角色。 一个分区可以没有或有很多追随者。
下图是上述 Apache Kafka 架构组件之间相互关系的简化表示。
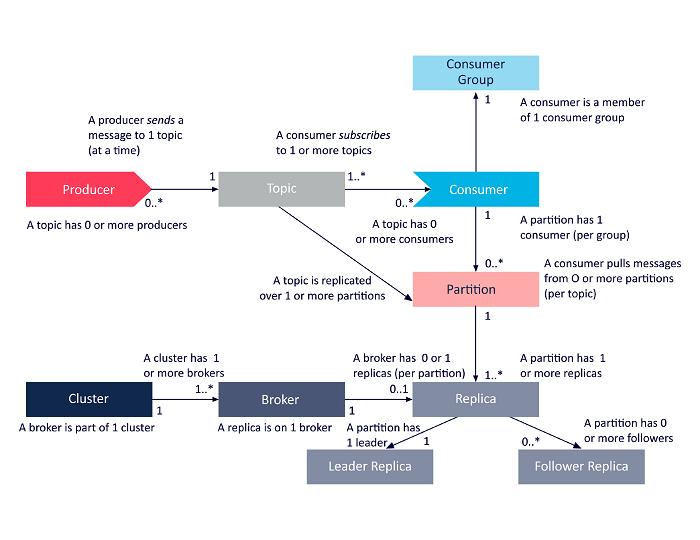

资源
Apache Kafka 集群架构
以下是 Kafka 主要架构组件的详细介绍:
1. 卡夫卡经纪人
Kafka 集群通常包含多个称为代理的节点。 代理保持负载平衡。 每个 Kafka 代理每秒可以处理成百上千的读写操作。 代理充当一个特定分区的领导者。 领导者有一个或多个追随者,领导者上的数据在该特定分区的追随者之间复制。
追随者需要随时了解领导者的数据。 反过来,领导者会跟踪与其同步的追随者。 如果追随者没有赶上领导者或不再活动,则将其从与特定领导者关联的同步副本列表中删除。 领导者死亡后,从追随者中选出新的领导者,并由 ZooKeeper 监督选举。 由于代理是无状态的,ZooKeeper 维护其集群状态。 集群中的节点向 ZooKeeper 发送心跳消息,通知后者它们还活着。
2. 卡夫卡生产者
Kafka 生产者直接将数据发送到充当特定分区领导者角色的代理。 Kafka 集群的代理或节点帮助生产者发送直接消息。 他们通过回答对哪些服务器处于活动状态的元数据请求以及主题的分区领导者的活动状态的请求来做到这一点,从而使生产者能够相应地指导其请求。 生产者决定它想要发布消息的分区。 Kafka 中的消息是分批发送的,称为记录批。 生产者在内存中收集消息,并在经过固定时间或累积一定数量的消息后分批发送。
3. 卡夫卡消费者
Kafka 消费者向代理发出请求,表示它想要使用的分区。 消费者在其请求中指定分区偏移量,并从代理接收一条日志(从偏移位置开始)。 日志包含可配置期间(称为保留期)的记录。
只要日志包含数据,消费者也可以重新消费数据。 Kafka 消费者采用基于拉取的方法,这意味着代理不会立即将数据推送给消费者。 相反,首先,消费者向代理发送请求,表明他们已准备好使用数据。 因此,基于拉取的系统确保消费者不会被消息淹没,并且在他们落后时能够赶上。
以下是简化的 Apache Kafka 架构图:
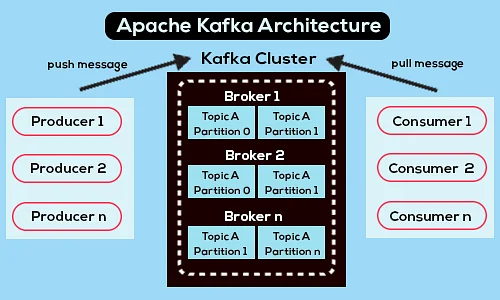
资源
了解有关 Apache Kafka 的更多信息。
Apache Kafka API 架构
Apache Kafka 有四个关键 API——Streams API、Connector API、Producer API 和 Consumer API。 让我们看看每个人在增强 Apache Kafka 的功能方面都扮演了什么角色:
1. 流 API
Kafka 的 Streams API 允许应用程序使用流处理算法来处理数据。 使用 Streams API,应用程序可以使用来自一个或多个主题的输入流,使用流操作处理它们,生成输出流,并最终将它们发送到一个或多个主题。 因此,Streams API 有助于将输入流转换为输出流。
2. 连接器 API
Kafka 的连接器 API 有助于构建、运行和管理将 Kafka 主题连接到现有数据系统或应用程序的可重用生产者和消费者。 例如,关系数据库的连接器可以捕获所有更新,并确保更改在 Kafka 主题中可用。

3.生产者API
Kafka 的 Producer API 允许应用程序将记录流发布到 Kafka 主题。
4.消费者API
Kafka 的 Consumer API 允许应用订阅 Kafka 主题。 它还使应用程序能够处理为这些 Kafka 主题生成的记录流。
前进之路
Apache Kafka 架构只是软件开发人员处理的大量工具和语言的一小部分。 假设您是一名初出茅庐的软件开发人员,倾向于大数据。 在这种情况下,您可以通过upGrad 的软件开发执行 PG 计划——大数据专业化迈出实现目标的第一步。
以下是该计划的概述,其中包含一些关键亮点:
- 来自 IIIT Bangalore 的执行 PGP,拥有数据科学和云基础设施方面的认证
- 内容超过 400 小时的在线课程和现场讲座
- 7+ 案例研究和项目
- 14+ 种编程语言和工具
- 360 度的职业支持
- 同行和行业网络
注册以获取更多详细信息 关于课程!
卡夫卡是干什么用的?
Apache Kafka 主要用于构建实时流数据管道和适应这些数据流的应用程序。 它允许通过消息传递、存储和流处理的组合来存储和分析实时和历史数据。
卡夫卡是一个框架吗?
Apache Kafka 是一个开源软件,它提供了一个用于存储、读取和分析流数据的框架。 由于它是开源的,因此许多开发人员和用户可以免费使用 Kafka,为新功能、更新和对新用户的支持做出贡献。
为什么我们需要 Kafka 流?
Kafka Streams 是一个客户端库,用于构建微服务和流应用程序,其中输入数据和输出数据存储在 Apache Kafka 集群中。 一方面,它提供了 Apache Kafka 的服务器端集群技术的优势。 另一方面,它简化了在客户端编写和部署标准 Scala 和 Java 应用程序。