
Apache Kafka:架构、概念、特性和应用
已发表: 2021-03-09Kafka 于 2011 年推出,这一切都归功于 LinkedIn。 从那时起,它见证了令人难以置信的增长,以至于现在大多数财富 500 强企业都在使用它。 它是一种高度可扩展、耐用和高吞吐量的产品,可以处理大量流数据。 但这就是它如此受欢迎的唯一原因吗? 嗯,不。 我们甚至还没有开始了解它的功能、它产生的质量以及它为用户提供的易用性。
我们稍后会深入探讨。 我们先来了解一下Kafka是什么,用在什么地方。
目录
什么是阿帕奇卡夫卡?
Apache Kafka 是一种开源流处理软件,旨在在管理实时数据的同时提供高吞吐量和低延迟。 Kafka 用 Java 和 Scala 编写,通过内存中的微服务提供持久性,并在维护复杂事件流服务(也称为 CEP 或自动化系统)的供应事件方面发挥着不可或缺的作用。
它是一个非常通用的、防故障的分布式系统,使优步等公司能够管理乘客和司机的匹配。 除了帮助 LinkedIn 跟踪多项实时服务外,它还为 British Gas 的智能家居产品提供实时数据和主动维护。
Kafka 经常用于实时流数据架构以提供实时分析,是一个快速、坚固、可扩展和发布-订阅的消息传递系统。 Apache Kafka 可以用作传统 MOM 的替代品,因为它具有出色的兼容性和灵活的架构,可以跟踪服务调用或 IoT 传感器数据。
Kafka 与 Apache Flume/Flafka、Apache Spark Streaming、Apache Storm、HBase、Apache Flink 和 Apache Spark 完美配合,用于实时摄取、研究、分析和处理流数据。 Kafka 中介还促进了 Hadoop 或 Spark 中的低延迟后续报告。 Kafka 还有一个名为 Kafka Stream 的子项目,它是一种有效的实时分析工具。

Kafka 架构和组件
Kafka 用于将实时数据流式传输到多个接收系统。 Kafka 作为解耦实时数据管道的中心层。 它在直接计算中没有多大用处。 它与基于实时或操作数据的快速通道进料系统最兼容,可以流式传输大量数据以进行批量数据分析。
Storm、Flink、Spark 和 CEP 框架是 Kafka 用来完成实时分析、创建备份、审计等的一些数据系统。 它还可以与大数据平台或数据库系统(如 RDBMS、Cassandra、Spark 等)集成,用于数据科学处理、报告等。
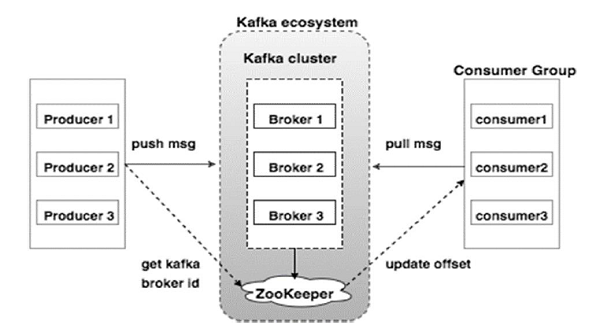
下图说明了 Kafka 生态系统:
资源
以下是 Kafka 生态系统的各种组件,如 Kafka 架构图所示:
1. 卡夫卡经纪人
Kafka 模拟一个包含多个服务器的集群,每个服务器都称为“代理”。 客户端和服务器之间的任何通信都遵循高性能 TCP 协议。 它包含一个以上的无状态代理来处理繁重的负载。 单个 Kafka 代理能够在不影响性能的情况下每秒管理数次读取和写入。 他们使用 ZooKeeper 来维护集群并选举代理领导者。
2. 卡夫卡动物园管理员
如上所述,ZooKeeper 负责管理 Kafka 代理。 Kafka 生态系统中代理的任何新添加或故障都会通过 ZooKeeper 通知生产者或消费者。

3. 卡夫卡生产者
他们负责向经纪人发送数据。 生产者不依赖代理来确认收到消息。 相反,他们确定代理可以相应地处理和发送多少消息。
4. 卡夫卡消费者
Kafka 消费者有责任记录分区偏移量消费的消息数量。 确认消息表示在消息被消费之前发送的消息。 为了确保代理有准备好发送给消费者的字节缓冲区,消费者发起一个异步拉取请求。 ZooKeeper 在维护跳过或倒带消息的偏移值方面发挥着作用。
Kafka 的机制涉及在分布式系统中的应用程序之间发送消息。 Kafka 使用提交日志,当订阅该日志时,它会将存在的数据发布到各种流应用程序。 发送者向 Kafka 发送消息,而接收者从 Kafka 分发的流中接收消息。
消息被组装成主题——Kafka 的有效审议。 给定的主题表示基于特定类型或分类的有组织的数据流。 生产者根据主题编写消息供消费者阅读。
每个主题都有一个唯一的名称。 发件人发送的来自给定主题的任何消息都会被所有正在收听该主题的用户接收。 一旦发布,主题中的数据将无法更新或修改。
卡夫卡的特点
- Kafka 包含一个永久提交日志,允许您订阅它,然后将数据发布到多个系统或实时应用程序。
- 它使应用程序能够在数据到来时对其进行控制。 Apache Kafka 中的 Streams API 是一个功能强大的轻量级库,可促进动态批处理数据处理。
- 它是一个 Java 应用程序,可让您调节工作流程并显着减少任何维护需求。
- Kafka 充当“事实存储”,通过支持通过多个数据系统进行数据部署,将数据分发到多个节点。
- Kafka 的提交日志使其成为可靠的存储系统。 Kafka 创建分区的副本/备份有助于防止数据丢失(正确的配置可以导致零数据丢失)。 这还可以防止服务器故障并增强 Kafka 的耐用性。
- Kafka 中的主题有数千个分区,使其能够处理任意数量的数据和繁重的负载。
- Kafka 依靠操作系统内核快速移动数据。 这些信息集群是端到端加密的,生产者到文件系统再到最终消费者。
- Kafka 中的批处理提高了数据压缩效率并降低了 I/O 延迟。
卡夫卡的应用
许多每天处理大量数据的公司都在使用 Kafka。

- LinkedIn 使用 Kafka 来跟踪用户活动和性能指标。 Twitter 将它与 Storm 相结合,以启用流处理框架。
- Square 使用 Kafka 来促进将所有系统事件转移到其他 Square 数据中心。 这包括日志、自定义事件和指标。
- 其他利用 Kafka 优势的流行公司包括 Netflix、Spotify、Uber、Tumblr、CloudFlare 和 PayPal。
为什么要学习 Apache Kafka?
Kafka 是一个出色的事件流平台,可以高效地处理、跟踪和监控实时数据。 其容错和可扩展架构允许低延迟数据集成,从而实现高吞吐量的流事件。 Kafka 显着缩短了数据的“价值实现时间”。
它通过消除围绕数据的“日志”作为向组织提供信息的基础系统。 这使数据科学家和专家可以随时轻松访问信息。
由于这些原因,它是许多顶级公司的首选流媒体平台,因此,具有 Apache Kafka 资格的候选人备受追捧。
如果您有兴趣了解有关 Kafka、大数据的更多信息,您应该查看 upGrad 的大数据软件开发专业化 PG 文凭,该文凭提供 7 多个案例研究和项目以及来自世界级教师和行业专家的指导。 这个为期 13 个月的课程涵盖 14 种编程语言,并教授数据处理、MapReduce、数据仓库、实时处理、云端大数据处理等技能。
在 upGrad 查看我们的其他软件工程课程。