
Gatsby 网站中的高级 GraphQL 使用
已发表: 2022-03-10在 2015 年 GraphQL 发布之前,表示状态传输 (REST) 是与 API 交互的主要方式。 因此,GraphQL 的引入是软件开发的一个重大变化。
作为现代静态站点生成器,Gatsby 利用 GraphQL 提供了一种简洁的方法来将数据引入和操作到框架中。 在本文中,我们将仔细研究 GraphQL 以及如何通过在 Gatsby 中构建和实施高级数据源和转换将其集成到 Gatsby 网站中。 结果是任何出版公司都可以使用出版商的博客来分享其作者的内容。
什么是 GraphQL?
顾名思义, GraphQL是一种查询语言,它结合了一组工具,旨在为我们从源中提取数据的方式提供灵活性和效率。 使用 GraphQL,客户端/消费者可以准确地请求它需要的数据。 服务器/提供者使用与查询中指定的要求匹配的 JSON 响应签名进行响应。 它允许我们以声明的方式表达我们的数据需求。
为什么使用 GraphQL?
作为静态站点生成器,Gatsby 存储静态文件,这使得查询数据几乎是不可能的。 通常有页面组件必须像单个博客文章页面一样是动态的,因此需要从源中提取数据并将其转换为所需的格式,就像将博客文章存储在降价文件中一样。 一些插件提供来自各种来源的数据,这使您可以从某个来源查询和转换所需的数据。
根据 gatsby.org 上的列表,GraphQL 在 Gatsby 中很有用:
- 消除样板
- 将前端复杂性推送到查询中
- 为现代应用程序中始终复杂的数据提供完美的解决方案
- 最后,消除代码膨胀,从而提高性能。
GraphQL 概念
Gatsby 保持与广泛使用的 GraphQL 相同的思想; 其中一些概念是:
模式定义语言
GraphQL SDL 是一个集成到 GraphQL 中的类型系统,您可以使用它为您的数据创建新类型。
我们可以为一个国家声明一个类型,它的属性可以包括名称、大陆、人口、gdp 和州数。
作为下面的示例,我们创建了一个名为Aleem的新类型。 它的hobbies是一系列字符串,不是必需的,但由于! 它们包括,还帖子引用另一种类型, Post 。
type Author { name: String!, hobbies: [String] country: String! married: Boolean! posts: [Post!] } type Post { title: String! body: String! } type Query { author: Author } schema { query: Query }查询
我们可以使用查询从 GraphQL 源中提取数据。
考虑如下数据集
{ data: { author: [ { hobbies: ["travelling", "reading"], married: false, country: "Nigeria", name: "Aleem Isiaka", posts: [ { title: "Learn more about how to improve your Gatsby website", }, { title: "The ultimate guide to GatsbyJS", }, { title: "How to start a blog with only GatsbyJS", }, ], }, ], }, };我们可以有一个查询来从数据中获取国家和帖子:
query { authors { country, posts { title } } }我们将获得的响应应该包含博客文章的 JSON 数据,仅包含标题,仅此而已:
[ { country: “Nigeria”, posts: [{...}, {...}, {...}] }, { country: “Tunisia”, posts: [] }, { title: “Ghana”, posts: []}, ]我们还可以使用参数作为查询的条件:
query { authors (country: “Nigeria”) { country, posts { title } } }哪个应该返回
[ { country: “Nigeria”, posts: [{...}, {...}, {...}] } ]也可以查询嵌套字段,比如 Post 类型的帖子,你可以只要求标题:
query { authors(country: 'Nigeria') { country, posts { title } } }它应该返回任何与尼日利亚匹配的作者类型,返回国家和帖子数组,其中包含仅包含标题字段的对象。
使用 GraphQL 的盖茨比
为了避免使用服务于 GraphQL 可以转换的数据的服务器/服务的开销,Gatsby 在构建时执行 GraphQL 查询。 在构建过程中向组件提供数据,使它们无需服务器即可在浏览器中轻松使用。
尽管如此,Gatsby 仍然可以作为服务器运行,该服务器可以被其他 GraphQL 客户端(如 GraphiQL)在浏览器中查询。
Gatsby 与 GraphQL 的交互方式
Gatsby 可以在两个地方与 GraphQL 交互,通过 gatsby-node.js API 文件和通过页面组件。
gatsby-node.js
createPage API 可以配置为一个函数,它将接收一个graphql助手作为传递给函数的第一个参数中的项目的一部分。
// gatsby-node.js source: https://www.gatsbyjs.org/docs/node-apis/#createPages exports.createPages = async ({ graphql, actions }) => { const result = await graphql(` query loadPagesQuery ($limit: Int!) { allMarkdownRemark(limit: $limit) { edges { node { frontmatter { slug } } } } }`) }在上面的代码中,我们使用了 GraphQL 助手从 Gatsby 的数据层获取 markdown 文件。 我们可以注入它来创建一个页面并修改 Gatsby 数据层中的现有数据。
页面组件
/pages 目录中的页面组件或由createPage API 操作呈现的模板可以从gatsby模块导入graphql并导出pageQuery 。 反过来,Gatsby 会将新的 prop data注入到包含已解析数据的页面组件的 props 中。
import React from "react"; import { graphql } from "gatsby"; const Page = props => { return{JSON.stringify(props.data)}; }; 导出 const pageQuery = graphql` 询问 { ... } `; 导出默认页面;
在其他组件中
其他组件可以从gatsby模块导入graphql和StaticQuery组件,渲染<StaticQuery/>传递实现 Graphql 帮助器的查询道具并渲染以获取返回的数据。
import React from "react"; import { StaticQuery, graphql } from "gatsby"; const Brand = props => { return ( <div> <h1>{data.site.siteMetadata.title}</h1> </div> ); }; const Navbar = props => { return ( <StaticQuery query={graphql` query { site { siteMetadata { title } } } `} render={data => <Brand data={data} {...props} />} /> ); }; export default Navbar;建立一个现代和先进的 Gatsby 出版博客
在本节中,我们将介绍创建支持按作者标记、分类、分页和分组文章的博客的过程。 我们将使用 Gatsby 生态系统的插件来引入一些功能,并使用 GraphQL 查询中的逻辑来制作发布者的博客,以便为多个作者发布做好准备。
我们将构建的博客的最终版本可以在这里找到,代码也托管在 Github 上。
初始化项目
像任何 Gatsby 网站一样,我们从启动器进行初始化,在这里我们将使用高级启动器,但经过修改以适应我们的用例。
首先克隆这个 Github 存储库,将工作分支更改为 dev-init,然后从项目文件夹运行npm run develop以启动开发服务器,使站点在 https://localhost:8000 可用。
git clone [email protected]:limistah/modern-gatsby-starter.git cd modern-gatsby-starter git checkout dev-init npm install npm run develop访问 https://localhost:8000 将显示该分支的默认主页。
创建博客文章内容
项目存储库中包含的一些帖子内容可以在 dev-blog-content 分支中访问。 内容目录的组织类似于/content/YYYY_MM/DD.md ,它按一年中创建的月份对帖子进行分组。
博文内容有title 、 date 、 author 、 category 、 tags作为frontmatter,我们将用它们来区分一篇博文并做一些进一步的处理,而其余的内容是博文的正文。
title: "Bold Mage" date: "2020-07-12" author: "Tunde Isiaka" category: "tech" tags: - programming - stuff - Ice cream - other --- # Donut I love macaroon chocolate bar Oat cake marshmallow lollipop fruitcake I love jelly-o. Gummi bears cake wafer chocolate bar pie. Marshmallow pastry powder chocolate cake candy chupa chups. Jelly beans powder souffle biscuit pie macaroon chocolate cake. Marzipan lemon drops chupa chups sweet cookie sesame snaps jelly halvah.显示帖子内容
在我们可以用 HTML 渲染我们的 Markdown 帖子之前,我们必须做一些处理。 首先,将文件加载到 Gatsby 存储中,将 MD 解析为 HTML,链接图像依赖项和点赞。 为了缓解这种情况,我们将使用 Gatsby 生态系统的大量插件。
我们可以通过更新项目根目录下的 gatsby-config.js 来使用这些插件,如下所示:
module.exports = { siteMetadata: {}, plugins: [ { resolve: "gatsby-source-filesystem", options: { name: "assets", path: `${__dirname}/static/`, }, }, { resolve: "gatsby-source-filesystem", options: { name: "posts", path: `${__dirname}/content/`, }, }, { resolve: "gatsby-transformer-remark", options: { plugins: [ { resolve: `gatsby-remark-relative-images`, }, { resolve: "gatsby-remark-images", options: { maxWidth: 690, }, }, { resolve: "gatsby-remark-responsive-iframe", }, "gatsby-remark-copy-linked-files", "gatsby-remark-autolink-headers", "gatsby-remark-prismjs", ], }, }, ], };我们已指示 gatsby 包含插件以帮助我们执行一些操作,特别是从 /static 文件夹中提取静态文件和 /content 中的文件用于我们的博客文章。 此外,我们还包含了一个备注转换器插件,用于将所有以 .md 或 .markdown 结尾的文件转换为具有所有备注字段的节点,以将 Markdown 呈现为 HTML。
最后,我们在gatsby-transformer-remark生成的节点上包含了插件。
实现gatsby-config.js API 文件
展望未来,在项目根目录的 gatsby-node.js 中,我们可以导出一个名为createPage的函数,并拥有该函数的内容,以使用 graphQL 助手从 GatsbyJS 的内容层中提取节点。
此页面的第一个更新将包括确保我们在 MarkDown 备注节点上设置了一个 slug。 我们将监听 onCreateNode API 并获取创建的节点以确定它是否是 MarkdownRemark 类型,然后我们更新节点以包含相应的 slug 和日期。
const path = require("path"); const _ = require("lodash"); const moment = require("moment"); const config = require("./config"); // Called each time a new node is created exports.onCreateNode = ({ node, actions, getNode }) => { // A Gatsby API action to add a new field to a node const { createNodeField } = actions; // The field that would be included let slug; // The currently created node is a MarkdownRemark type if (node.internal.type === "MarkdownRemark") { // Recall, we are using gatsby-source-filesystem? // This pulls the parent(File) node, // instead of the current MarkdownRemark node const fileNode = getNode(node.parent); const parsedFilePath = path.parse(fileNode.relativePath); if ( Object.prototype.hasOwnProperty.call(node, "frontmatter") && Object.prototype.hasOwnProperty.call(node.frontmatter, "title") ) { // The node is a valid remark type and has a title, // Use the title as the slug for the node. slug = `/${_.kebabCase(node.frontmatter.title)}`; } else if (parsedFilePath.name !== "index" && parsedFilePath.dir !== "") { // File is in a directory and the name is not index // eg content/2020_02/learner/post.md slug = `/${parsedFilePath.dir}/${parsedFilePath.name}/`; } else if (parsedFilePath.dir === "") { // File is not in a subdirectory slug = `/${parsedFilePath.name}/`; } else { // File is in a subdirectory, and name of the file is index // eg content/2020_02/learner/index.md slug = `/${parsedFilePath.dir}/`; } if (Object.prototype.hasOwnProperty.call(node, "frontmatter")) { if (Object.prototype.hasOwnProperty.call(node.frontmatter, "slug")) slug = `/${_.kebabCase(node.frontmatter.slug)}`; if (Object.prototype.hasOwnProperty.call(node.frontmatter, "date")) { const date = moment(new Date(node.frontmatter.date), "DD/MM/YYYY"); if (!date.isValid) console.warn(`WARNING: Invalid date.`, node.frontmatter); // MarkdownRemark does not include date by default createNodeField({ node, name: "date", value: date.toISOString() }); } } createNodeField({ node, name: "slug", value: slug }); } };帖子列表
此时,我们可以实现createPages API 来查询所有降价,并创建一个页面,其路径为我们在上面创建的 slug。 在 Github 上查看。
//gatsby-node.js // previous code // Create Pages Programatically! exports.createPages = async ({ graphql, actions }) => { // Pulls the createPage action from the Actions API const { createPage } = actions; // Template to use to render the post converted HTML const postPage = path.resolve("./src/templates/singlePost/index.js"); // Get all the markdown parsed through the help of gatsby-source-filesystem and gatsby-transformer-remark const allMarkdownResult = await graphql(` { allMarkdownRemark { edges { node { fields { slug } frontmatter { title tags category date author } } } } } `); // Throws if any error occur while fetching the markdown files if (allMarkdownResult.errors) { console.error(allMarkdownResult.errors); throw allMarkdownResult.errors; } // Items/Details are stored inside of edges const postsEdges = allMarkdownResult.data.allMarkdownRemark.edges; // Sort posts postsEdges.sort((postA, postB) => { const dateA = moment( postA.node.frontmatter.date, siteConfig.dateFromFormat ); const dateB = moment( postB.node.frontmatter.date, siteConfig.dateFromFormat ); if (dateA.isBefore(dateB)) return 1; if (dateB.isBefore(dateA)) return -1; return 0; }); // Pagination Support for posts const paginatedListingTemplate = path.resolve( "./src/templates/paginatedListing/index.js" ); const { postsPerPage } = config; if (postsPerPage) { // Get the number of pages that can be accommodated const pageCount = Math.ceil(postsEdges.length / postsPerPage); // Creates an empty array Array.from({ length: pageCount }).forEach((__value__, index) => { const pageNumber = index + 1; createPage({ path: index === 0 ? `/posts` : `/posts/${pageNumber}/`, component: paginatedListingTemplate, context: { limit: postsPerPage, skip: index * postsPerPage, pageCount, currentPageNumber: pageNumber, }, }); }); } else { // Load the landing page instead createPage({ path: `/`, component: landingPage, }); } }; 在createPages函数中,我们使用 Gatsby 提供的graphql helper 从内容层查询数据。 我们使用标准的 Graphql 查询来执行此操作,并通过查询从allMarkdownRemark类型中获取内容。 然后继续按创建日期对帖子进行排序。
然后,我们从导入的配置对象中提取了一个postPerPage属性,该属性用于将帖子总数分块为单个页面的指定帖子数。
要创建支持分页的列表页面,我们需要传入限制、pageNumber 和要跳转到将呈现列表的组件的页数。 我们使用createPage配置对象的 context 属性来实现这一点。 我们将从页面访问这些属性以进行另一个 graphql 查询以获取限制内的帖子。
我们还可以注意到,我们在列表中使用了相同的模板组件,并且只有路径在使用我们之前定义的块数组的索引进行更改。 Gatsby 将传递与/{chunkIndex}匹配的给定 URL 的必要数据,因此我们可以将/用于前十个帖子,将/2用于接下来的十个帖子。
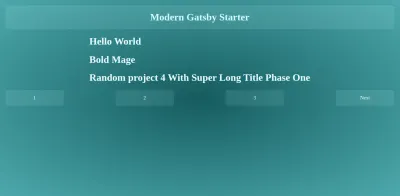
渲染帖子列表
渲染这些页面的组件可以在项目文件夹的src/templates/singlePost/index.js中找到。 它还导出了一个graphql帮助程序,该帮助程序提取从 createPages 进程接收到的限制和页面查询参数,以查询 gatsby 以获取当前页面范围内的帖子。

import React from "react"; import { graphql, Link } from "gatsby"; import Layout from "../../layout"; import PostListing from "../../components/PostListing"; import "./index.css"; const Pagination = ({ currentPageNum, pageCount }) => { const prevPage = currentPageNum - 1 === 1 ? "/" : `/${currentPageNum - 1}/`; const nextPage = `/${currentPageNum + 1}/`; const isFirstPage = currentPageNum === 1; const isLastPage = currentPageNum === pageCount; return ( <div className="paging-container"> {!isFirstPage && <Link to={prevPage}>Previous</Link>} {[...Array(pageCount)].map((_val, index) => { const pageNum = index + 1; return ( <Link key={`listing-page-${pageNum}`} to={pageNum === 1 ? "/" : `/${pageNum}/`} > {pageNum} </Link> ); })} {!isLastPage && <Link to={nextPage}>Next</Link>} </div> ); }; export default (props) => { const { data, pageContext } = props; const postEdges = data.allMarkdownRemark.edges; const { currentPageNum, pageCount } = pageContext; return ( <Layout> <div className="listing-container"> <div className="posts-container"> <PostListing postEdges={postEdges} /> </div> <Pagination pageCount={pageCount} currentPageNum={currentPageNum} /> </div> </Layout> ); }; /* eslint no-undef: "off" */ export const pageQuery = graphql` query ListingQuery($skip: Int!, $limit: Int!) { allMarkdownRemark( sort: { fields: [fields___date], order: DESC } limit: $limit skip: $skip ) { edges { node { fields { slug date } excerpt timeToRead frontmatter { title tags author category date } } } } } `;帖子页面
要查看页面的内容,我们需要在gatsby-node.js API 文件中以编程方式创建页面。 首先,我们必须定义一个新组件来渲染内容,为此,我们有src/templates/singlePost/index.jsx 。
import React from "react"; import { graphql, Link } from "gatsby"; import _ from "lodash"; import Layout from "../../layout"; import "./b16-tomorrow-dark.css"; import "./index.css"; import PostTags from "../../components/PostTags"; export default class PostTemplate extends React.Component { render() { const { data, pageContext } = this.props; const { slug } = pageContext; const postNode = data.markdownRemark; const post = postNode.frontmatter; if (!post.id) { post.id = slug; } return ( <Layout> <div> <div> <h1>{post.title}</h1> <div className="category"> Posted to{" "} <em> <Link key={post.category} style={{ textDecoration: "none" }} to={`/category/${_.kebabCase(post.category)}`} > <a>{post.category}</a> </Link> </em> </div> <PostTags tags={post.tags} /> <div dangerouslySetInnerHTML={{ __html: postNode.html }} /> </div> </div> </Layout> ); } } /* eslint no-undef: "off" */ export const pageQuery = graphql` query BlogPostBySlug($slug: String!) { markdownRemark(fields: { slug: { eq: $slug } }) { html timeToRead excerpt frontmatter { title date category tags } fields { slug date } } } `;同样,我们使用 graphQL 助手通过 slug 查询提取页面,该查询将通过 createPages API 发送到页面。
接下来,我们应该将以下代码添加到 gatsby-node.js 的createPages API 函数末尾。
// Template to use to render the post converted HTML const postPage = path.resolve("./src/templates/singlePost/index.jsx"); // Loops through all the post nodes postsEdges.forEach((edge, index) => { // Create post pages createPage({ path: edge.node.fields.slug, component: postPage, context: { slug: edge.node.fields.slug, }, }); }); 我们可以访问 '/{pageSlug}' 并让它将该页面的 markdown 文件的内容呈现为 HTML。 例如,https://localhost:8000/the-butterfly-of-the-edge 应该在content/2020_05/01.md加载转换后的 HTML,类似于所有有效的 slug。 伟大的!

渲染类别和标签
单个帖子模板组件具有指向/categories/{categoryName}格式的页面的链接,以列出具有相似类别的帖子。
当我们在gatsby-node.js文件中构建单个帖子页面时,我们可以首先捕获所有类别和标签,然后为每个捕获的类别/标签创建页面,并传递类别/标签名称。
在 gatsby-node.js 中对创建单个帖子页面的部分进行了修改,如下所示:
const categorySet = new Set(); const tagSet = new Set(); const categoriesListing = path.resolve( "./src/templates/categoriesListing/index.jsx" ); // Template to use to render posts based on categories const tagsListingPage = path.resolve("./src/templates/tagsListing/index.jsx"); // Loops through all the post nodes postsEdges.forEach((edge, index) => { // Generate a list of categories if (edge.node.frontmatter.category) { categorySet.add(edge.node.frontmatter.category); } // Generate a list of tags if (edge.node.frontmatter.tags) { edge.node.frontmatter.tags.forEach((tag) => { tagSet.add(tag); }); } // Create post pages createPage({ path: edge.node.fields.slug, component: postPage, context: { slug: edge.node.fields.slug, }, }); }); 在按标签列出帖子的组件中,我们可以让pageQuery导出查询 graphql 的帖子,包括该标签在其标签列表中。 我们将使用 graphql 的filter功能和 $in 运算符来实现:
// src/templates/tagsListing/ import React from "react"; import { graphql } from "gatsby"; import Layout from "../../layout"; import PostListing from "../../components/PostListing"; export default ({ pageContext, data }) => { const { tag } = pageContext; const postEdges = data.allMarkdownRemark.edges; return ( <Layout> <div className="tag-container"> <div>Posts posted with {tag}</div> <PostListing postEdges={postEdges} /> </div> </Layout> ); }; /* eslint no-undef: "off" */ export const pageQuery = graphql` query TagPage($tag: String) { allMarkdownRemark( limit: 1000 sort: { fields: [fields___date], order: DESC } filter: { frontmatter: { tags: { in: [$tag] } } } ) { totalCount edges { node { fields { slug date } excerpt timeToRead frontmatter { title tags author date } } } } } `;我们在分类列表组件中也有相同的过程,不同的是我们只需要找到与我们传递给它的分类精确匹配的位置。
// src/templates/categoriesListing/index.jsx import React from "react"; import { graphql } from "gatsby"; import Layout from "../../layout"; import PostListing from "../../components/PostListing"; export default ({ pageContext, data }) => { const { category } = pageContext; const postEdges = data.allMarkdownRemark.edges; return ( <Layout> <div className="category-container"> <div>Posts posted to {category}</div> <PostListing postEdges={postEdges} /> </div> </Layout> ); }; /* eslint no-undef: "off" */ export const pageQuery = graphql` query CategoryPage($category: String) { allMarkdownRemark( limit: 1000 sort: { fields: [fields___date], order: DESC } filter: { frontmatter: { category: { eq: $category } } } ) { totalCount edges { node { fields { slug date } excerpt timeToRead frontmatter { title tags author date } } } } } `;值得注意的是,在标签和类别组件中,我们呈现指向单个帖子页面的链接,以便进一步阅读帖子的内容。
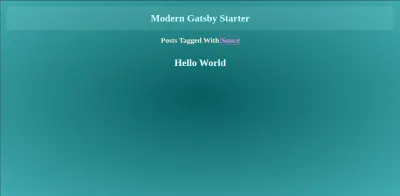
添加对作者的支持
为了支持多个作者,我们必须对我们的帖子内容进行一些修改并引入新概念。
加载 JSON 文件
首先,我们应该能够将作者的内容存储在 JSON 文件中,如下所示:
{ "mdField": "aleem", "name": "Aleem Isiaka", "email": "[email protected]", "location": "Lagos, Nigeria", "avatar": "https://api.adorable.io/avatars/55/[email protected]", "description": "Yeah, I like animals better than people sometimes... Especially dogs. Dogs are the best. Every time you come home, they act like they haven't seen you in a year. And the good thing about dogs... is they got different dogs for different people.", "userLinks": [ { "label": "GitHub", "url": "https://github.com/limistah/modern-gatsby-starter", "iconClassName": "fa fa-github" }, { "label": "Twitter", "url": "https://twitter.com/limistah", "iconClassName": "fa fa-twitter" }, { "label": "Email", "url": "mailto:[email protected]", "iconClassName": "fa fa-envelope" } ] } 我们会将它们作为/authors存储在项目根目录中的作者目录中。 请注意,作者 JSON 具有mdField ,它将是我们将介绍给降价博客内容的作者字段的唯一标识符; 这确保了作者可以拥有多个个人资料。
接下来,我们必须更新gatsby-config.js插件,指示gatsby-source-filesystem将内容从authors/目录加载到文件节点中。
// gatsby-config.js { resolve: `gatsby-source-filesystem`, options: { name: "authors", path: `${__dirname}/authors/`, }, } 最后,我们将安装gatsby-transform-json来转换创建的 JSON 文件,以便于处理和正确处理。
npm install gatsby-transformer-json --save 并将其包含在gatsby-config.js的插件中,
module.exports = { plugins: [ // ...other plugins `gatsby-transformer-json` ], };查询和创建作者页面
首先,我们需要在gatsby-config.js中的authors/目录中查询所有已加载到数据层的作者,我们应该将以下代码附加到createPages API 函数
const authorsListingPage = path.resolve( "./src/templates/authorsListing/index.jsx" ); const allAuthorsJson = await graphql(` { allAuthorsJson { edges { node { id avatar mdField location name email description userLinks { iconClassName label url } } } } } `); const authorsEdges = allAuthorsJson.data.allAuthorsJson.edges; authorsEdges.forEach((author) => { createPage({ path: `/authors/${_.kebabCase(author.node.mdField)}/`, component: authorsListingPage, context: { authorMdField: author.node.mdField, authorDetails: author.node, }, }); }); 在这个片段中,我们从 allAuthorsJson 类型中提取所有作者,然后在节点上调用 forEach 以创建一个页面,我们在其中传递mdField来区分作者和authorDetails以获取有关作者的完整信息。
渲染作者的帖子
在渲染页面的组件中,可以在src/templates/authorsListing/index.jsx找到,我们有以下文件内容
import React from "react"; import { graphql } from "gatsby"; import Layout from "../../layout"; import PostListing from "../../components/PostListing"; import AuthorInfo from "../../components/AuthorInfo"; export default ({ pageContext, data }) => { const { authorDetails } = pageContext; const postEdges = data.allMarkdownRemark.edges; return ( <Layout> <div> <h1 style={{ textAlign: "center" }}>Author Roll</h1> <div className="category-container"> <AuthorInfo author={authorDetails} /> <PostListing postEdges={postEdges} /> </div> </div> </Layout> ); }; /* eslint no-undef: "off" */ export const pageQuery = graphql` query AuthorPage($authorMdField: String) { allMarkdownRemark( limit: 1000 sort: { fields: [fields___date], order: DESC } filter: { frontmatter: { author: { eq: $authorMdField } } } ) { totalCount edges { node { fields { slug date } excerpt timeToRead frontmatter { title tags author date } } } } } `; 在上面的代码中,我们像我们一样导出了pageQuery ,以创建一个 GraphQL 查询来获取作者匹配的帖子,我们使用$eq运算符来实现这一点,即生成指向单个帖子页面的链接以供进一步阅读。

结论
在 Gatsby 中,我们可以使用 GraphQL 查询来查询存在于其数据访问层内部的任何数据,并使用 Gatsby 架构定义的一些构造传递变量。 我们已经了解了如何在各个地方使用graphql助手,并了解了在 GraphQL 的帮助下在 Gatsby 网站中查询数据的广泛使用模式。
GraphQL 非常强大,可以在服务器上做其他事情,比如数据突变。 Gatsby 不需要在运行时更新其数据,因此不支持 GraphQL 的变异特性。
GraphQL 是一项伟大的技术,Gatsby 让它在他们的框架中使用非常有趣。
参考
- Gatsby 对 GraphQL 的支持
- 为什么 Gatsby 使用 GraphQL
- Gatsby 中的 GraphQL 概念
- 如何 GraphQL:基本概念
- GraphQL 中的模式定义语言
- GraphQL 简介
- 盖茨比高级入门