
使用 Scikit 进行线性回归的指南 [附示例]
已发表: 2021-06-18监督学习算法通常有两种类型:回归和分类,预测连续和离散输出。
下面的文章将讨论线性回归及其使用最流行的 Python 机器学习库之一 Scikit-learn 库的实现。 Python 库中提供了机器学习和统计模型工具,用于分类、回归、聚类和降维。 该库以 Python 编程语言编写,建立在 NumPy、SciPy 和 Matplotlib Python 库之上。
目录
线性回归
线性回归在监督学习方法下执行回归任务。 基于自变量,预测目标值。 该方法主要用于预测和识别变量之间的关系。
在代数中,术语线性是指变量之间的线性关系。 在二维空间中的变量之间推导出一条直线。
如果一条线是 X 轴上的自变量和 Y 轴上的因变量之间的图,则通过最适合数据点的线性回归获得一条直线。
直线方程的形式为

Y = mx + b
其中,b = 截距
m = 线的斜率
因此,通过线性回归,
- 截距和斜率的最佳值是在二维中确定的。
- x 和 y 变量没有变化,因为它们是数据特征,因此保持不变。
- 只能控制截距和斜率值。
- 可能存在基于斜率和截距值的多条直线,但是通过线性回归算法在数据点上拟合多条直线,并返回误差最小的直线。
使用 Python 进行线性回归
为了在 python 中实现线性回归,需要应用适当的包以及它的函数和类。 Python 中的 NumPy 包是开源的,允许对数组进行多项操作,包括单维数组和多维数组。
python中另一个广泛使用的库是用于机器学习问题的Scikit-learn。
Scikit-learn
Scikit-learn 库为开发人员提供了基于监督和无监督学习的算法。 python的开源库专为机器学习任务而设计。
数据科学家可以通过使用 scikit-learn 导入数据、对其进行预处理、绘制和预测数据。
David Cournapeau 于 2007 年首次开发 scikit-learn,该库几十年来一直在增长。
scikit-learn 提供的工具有:
- 回归:包括逻辑回归和线性回归
- 分类:包括 K-Nearest Neighbors 方法
- 型号选择
- 聚类:包括 K-Means++ 和 K-Means
- 预处理
图书馆的优点是:
- 图书馆的学习和实施很容易。
- 它是一个开源库,因此是免费的。
- 机器学习方面可以被掩盖,包括深度学习。
- 它是一个功能强大且用途广泛的软件包。
- 该库有详细的文档。
- 机器学习最常用的工具包之一。
导入 scikit-learn
scikit-learn 必须首先通过 pip 或 conda 安装。
- 要求:python 3 的 64 位版本,已安装库 NumPy 和 Scipy。 同样对于数据图的可视化,matplotlib 是必需的。
安装命令:pip install -U scikit-learn
然后验证是否安装完成
安装 Numpy、Scipy 和 matplotlib
可以通过以下方式确认安装:
资源
通过 Scikit-learn 进行线性回归
通过 scikit-learn 包实现线性回归涉及以下步骤。
- 需要导入包和类。
- 需要使用数据并进行适当的转换。
- 将创建一个回归模型并与现有数据进行拟合。
- 检查模型拟合数据以分析创建的模型是否令人满意。
- 将通过应用模型进行预测。
NumPy 包和 LinearRegression 类将从 sklearn.linear_model 导入。

资源
sklearn 线性回归所需的功能都存在于最终实现线性回归。 sklearn.linear_model.LinearRegression 类用于执行回归分析(线性和多项式)并进行预测。
对于任何机器学习算法和scikit 学习线性回归,都必须先导入数据集。 Scikit-learn 提供了三个选项来获取数据:

- 虹膜分类或波士顿房价回归集等数据集。
- 现实世界的数据集可以通过 Scikit-learn 预定义函数直接从互联网上下载。
- 可以通过 Scikit-learn 数据生成器随机生成数据集以匹配特定模式。
无论选择什么选项,都必须导入模块数据集。
将 sklearn.datasets导入为数据集
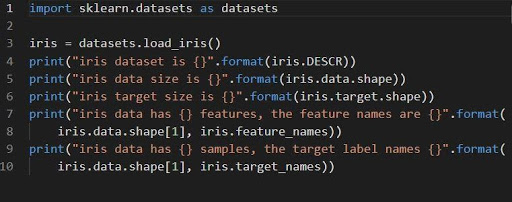
1. 鸢尾花的分类集
iris = datasets.load_iris()
数据集 iris 存储为 n_samples * n_features 的二维数组数据字段。 它的输入是作为字典的对象执行的。 它包含所有必要的数据以及元数据。
函数 DESCR、shape 和 _names 可用于获取数据的描述和格式。 打印函数结果将显示在处理 iris 数据集时可能需要的数据集信息。
以下代码将加载 iris 数据集的信息。
资源
2. 回归数据的生成
如果不需要内置数据,则可以通过可以选择的分布生成数据。
使用一组 1 个信息特征和 1 个特征生成回归数据。
X , Y = datasets.make_regression(n_features=1, n_informative=1)
生成的数据保存在具有对象 x 和 y 的 2D 数据集中。 生成数据的特征可以通过改变函数make_regression的参数来改变。
在此示例中,信息特征和特征的参数从默认值 10 更改为 1。
考虑的其他参数是样本和目标,其中控制了跟踪的目标和样本变量的数量。
- 为机器学习算法提供有用信息的特征被称为信息特征,而那些无用的特征被称为信息特征。
3. 绘制数据
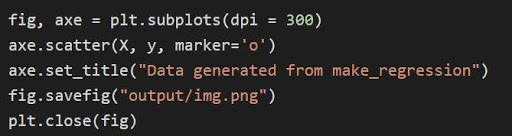
使用 matplotlib 库绘制数据。 首先,必须导入 matplotlib。
将 matplotlib.pyplot 导入为 plt
上图是通过matplotlib通过代码绘制的
资源
在上面的代码中:
- 元组变量被解包并保存为代码第 1 行中的单独变量。 因此,可以操作和保存单独的属性。
- 数据集 x, y 用于通过第 2 行生成散点图。利用 matplotlib 中可用的标记参数,通过用点 (o) 标记数据点来增强视觉效果。
- 生成图的标题通过第 3 行设置。
- 可以将图形保存为 .png 图像文件,然后关闭当前图形。
通过上述代码生成的回归图为
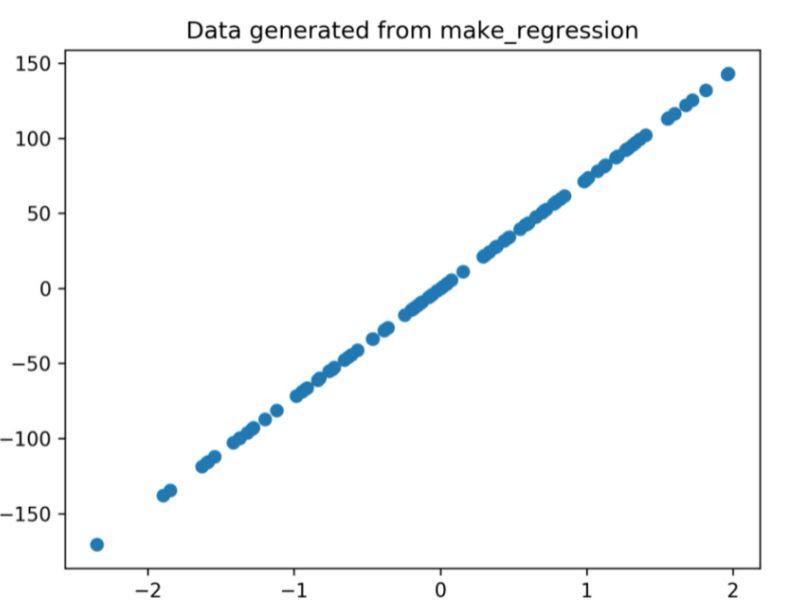
图 1:从上面的代码生成的回归图。
4. 线性回归的实现算法
使用波士顿房价的样本数据,在下面的例子中实现了Scikit-learn 线性回归的算法。 与其他 ML 算法一样,数据集被导入,然后使用以前的数据进行训练。
企业使用线性回归方法,因为它是一种预测模型,用于预测数值及其变量与输出值之间的关系,具有现实意义。
当存在早期数据的日志时,可以最好地应用该模型,因为如果该模式继续存在,它可以预测未来将发生的事情的未来结果。
在数学上,可以拟合数据以最小化数据点与预测值之间存在的所有残差之和。
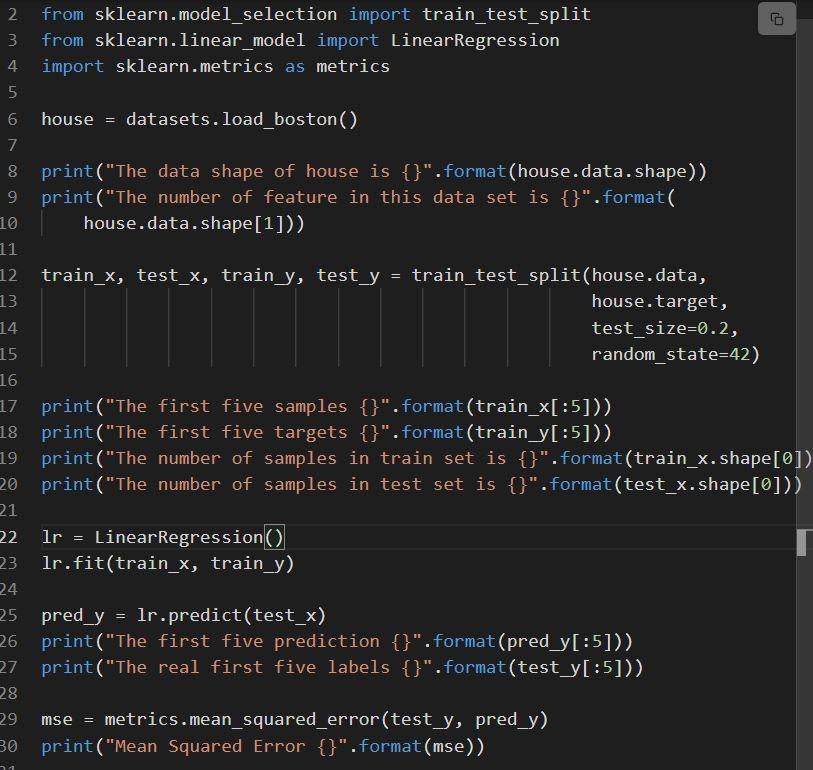
以下片段显示了sklearn 线性回归的实现。
资源
代码解释如下:
- 第 6 行加载名为 load_boston 的数据集。
- 数据集在第 12 行拆分,即 80% 数据的训练集和 20% 数据的测试集。
- 在第 23 行创建线性回归模型,然后在第 23 行进行训练。
- 通过调用 mean_squared_error 在亚麻 29 处评估模型的性能。
sklearn线性回归图如下所示:
波士顿房价样本数据的线性回归模型
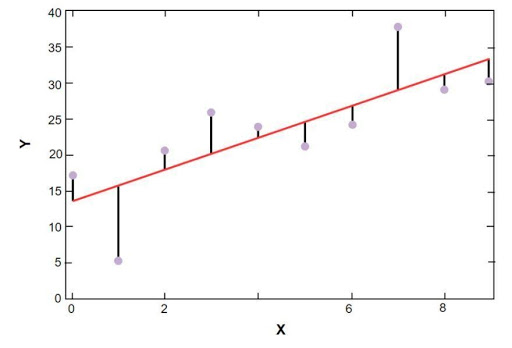
资源
上图中,红线代表波士顿房价样本数据已经求解的线性模型。 蓝点代表原始数据,红线和蓝点之间的距离代表残差之和。 scikit-learn 线性回归模型的目标是减少残差之和。
结论
本文讨论了线性回归及其通过使用名为 scikit-learn 的开源 python 包的实现。 至此,您已经可以通过这个包了解如何实现线性回归了。 值得学习如何使用该库进行数据分析。
如果您有兴趣进一步探索该主题,例如 Python 包在机器学习和 AI 相关问题中的实现,您可以查看upGrad提供的机器学习与 AI 科学硕士课程。 该课程针对 21 至 45 岁的入门级专业人士,旨在通过 650 多个小时的在线培训、25 多个案例研究和作业来培训学生的机器学习。 LJMU认证,课程提供完美的指导和就业帮助。 如果您有任何问题或疑问,请给我们留言,我们将很乐意与您联系。