
Java ile Makine Öğrenimi Nedir? Nasıl Uygulanır?
Yayınlanan: 2021-03-10İçindekiler
Makine Öğrenimi Nedir?
Makine öğrenimi, insan davranışını ve zekasını taklit etmek için mevcut verilerden, örneklerden ve deneyimlerden öğrenen Yapay Zekanın bir bölümüdür. Makine öğrenimi kullanılarak oluşturulan bir program, bir insanın kodu manuel olarak yazması gerekmeden kendi başına mantık oluşturabilir.
Her şey 1950'lerin başında Alan Turning'in bir bilgisayarın gerçek zekaya sahip olması için bir insanı manipüle etmesi veya onun da insan olduğuna ikna etmesi gerektiği sonucuna vardığında Turing Testi ile başladı. Makine öğrenimi nispeten eski bir kavramdır ancak bilgisayarlar artık karmaşık algoritmaları işleyebildiğinden, ortaya çıkan bu alan ancak bugün gerçekleştirilebilmektedir. Makine öğrenimi algoritmaları, son on yılda karmaşık hesaplama becerilerini içerecek şekilde gelişti ve bu da taklit yeteneklerinde bir gelişmeye yol açtı.
Makine öğrenimi uygulamaları da endişe verici bir oranda arttı. Sağlık, finans, analitik ve eğitimden üretim, pazarlama ve devlet operasyonlarına kadar her sektör, makine öğrenimi teknolojilerini uyguladıktan sonra kalite ve verimlilikte önemli bir artış gördü. Tüm dünyada yaygın niteliksel gelişmeler oldu, bu nedenle makine öğrenimi uzmanlarına olan talebi artırdı.
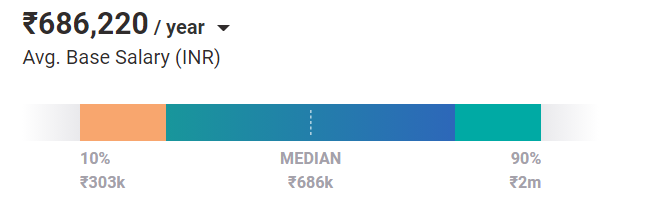
Ortalama olarak, Makine Öğrenimi Mühendisleri bugün 686.220 Yen/yıl maaş değerindedir. Ve bu, giriş seviyesi bir pozisyon için geçerlidir. Tecrübe ve becerilerle, Hindistan'da ₹2m / yıl'a kadar kazanabilirler.
Makine Öğrenimi Algoritmaları Türleri
Makine öğrenimi algoritmaları üç türdendir:
1. Denetimli Öğrenme : Bu tür öğrenmede, eğitim veri setleri, doğru tahminler veya analitik kararlar vermek için bir algoritmaya rehberlik eder. Yeni verileri işlemek için geçmiş eğitim veri kümelerinden öğrenmeyi kullanır. Denetimli öğrenme makine öğrenimi modellerine birkaç örnek:

- Doğrusal regresyon
- Lojistik regresyon
- Karar ağacı
2. Denetimsiz Öğrenme : Bu tür öğrenmede, bir makine öğrenme modeli etiketlenmemiş bilgi parçalarından öğrenir. Nesneleri gruplayarak veya aralarındaki ilişkiyi anlayarak veya analiz yapmak için istatistiksel özelliklerinden yararlanarak veri kümelemeyi kullanır. Denetimsiz öğrenme algoritmalarına örnekler:
- K-kümeleme anlamına gelir
- Hiyerarşik kümeleme
3. Pekiştirmeli Öğrenme : Bu süreç, isabet ve denemeye dayalıdır. Uzay veya bir çevre ile etkileşime girerek öğreniyor. Bir RL algoritması, çevre ile etkileşime girerek ve en iyi hareket tarzını belirleyerek geçmiş deneyimlerinden öğrenir.
Java ile Makine Öğrenimi Nasıl Uygulanır?
Java, makine öğrenimi algoritmalarını uygulamak için kullanılan en iyi programlama dilleri arasındadır. Kitaplıklarının çoğu açık kaynaklıdır ve kapsamlı belge desteği, kolay bakım, pazarlanabilirlik ve kolay okunabilirlik sağlar.
Popülerliğe bağlı olarak, Java'da makine öğrenimini uygulamak için kullanılan en iyi 10 makine öğrenimi kitaplığı burada.
1. ADAMLAR
Gelişmiş Veri Madenciliği ve Makine Öğrenimi Sistemi veya ADAMS, özgün ve esnek bir iş akışı sistemleri oluşturmak ve karmaşık gerçek dünya süreçlerini yönetmekle ilgilenir. ADAMS, manuel giriş-çıkış bağlantıları yapmak yerine veri akışını yönetmek için ağaç benzeri bir mimari kullanır.
Açık bağlantılara olan ihtiyacı ortadan kaldırır. “Az çoktur” ilkesine dayanır ve alma, görselleştirme ve veriye dayalı görselleştirmeler gerçekleştirir. ADAMS, veri işleme, veri akışı, veritabanlarını yönetme, komut dosyası oluşturma ve dokümantasyon konularında uzmandır.
2. JavaML
JavaML, yazılım mühendislerini, programcıları, veri bilimcilerini ve araştırmacıları desteklemek için Java için yazılmış çeşitli ML ve veri madenciliği algoritmaları sunar. Her algoritma, GUI olmamasına rağmen kullanımı kolay ve kapsamlı dokümantasyon desteğine sahip ortak bir arayüze sahiptir.
Diğer kümeleme algoritmalarına kıyasla uygulanması oldukça basit ve kolaydır. Temel özellikleri arasında veri işleme, dokümantasyon, veritabanı yönetimi, veri sınıflandırması, kümeleme, özellik seçimi vb. bulunur.
Kariyerinizi hızlandırmak için Makine Öğrenimi Kursuna , Makine Öğrenimi ve Yapay Zeka alanında Dünyanın en iyi Üniversiteleri - Yüksek Lisanslar, Yönetici Yüksek Lisans Programları ve İleri Düzey Sertifika Programından çevrimiçi katılın .
3. WEKA
Weka ayrıca Java için yazılmış, derin öğrenmeyi destekleyen açık kaynaklı bir makine öğrenimi kitaplığıdır. Bir dizi makine öğrenimi algoritması sağlar ve diğer veri işlemlerinin yanı sıra veri madenciliği, veri hazırlama, veri kümeleme, veri görselleştirme ve regresyonda geniş kullanım alanı bulur.
Örnek: Bunu küçük bir diyabet veri seti kullanarak göstereceğiz.
Adım 1 : Weka kullanarak verileri yükleyin
| weka.core.Instance'ları içe aktar; içe aktarma weka.core.converters.ConverterUtils.DataSource; genel sınıf Ana { public static void main(String[] args) İstisna {'yi atar // Veri kaynağının belirtilmesi DataSource dataSource = new DataSource(“data.arff”); // Veri seti yükleniyor Örnekler dataInstances = dataSource.getDataSet(); // Örnek sayısını görüntüleme log.info(“Yüklenen örnek sayısı: ” + dataInstances.numInstances()); log.info(“veri:” + dataInstances.toString()); } } |
Adım 2: Veri kümesinde 768 örnek bulunur. Öznitelik sayısına erişmemiz gerekiyor, yani 9.
| log.info(“Veri kümesindeki özniteliklerin (özelliklerin) sayısı: ” + dataInstances.numAttributes()); |
Adım 3 : Bir model oluşturmadan ve sınıf sayısını bulmadan önce hedef sütunu belirlememiz gerekiyor.
| // Etiket indeksini tanımlama dataInstances.setClassIndex(dataInstances.numAttributes() – 1); // sayısını almak log.info(“Sınıf sayısı: ” + dataInstances.numClasses()); |
Adım 4 : Şimdi modeli basit bir ağaç sınıflandırıcısı olan J48 kullanarak oluşturacağız.
| // Bir karar ağacı sınıflandırıcısı oluşturma J48 treeClassifier = yeni J48(); treeClassifier.setOptions(yeni Dize[] { “-U” }); treeClassifier.buildClassifier(dataInstances); |
Yukarıdaki kod, model eğitimi için gerekli veri örneklerinden oluşan budanmamış bir ağacın nasıl oluşturulacağını vurgulamaktadır. Model eğitiminden sonra ağaç yapısı yazdırıldıktan sonra, kuralların dahili olarak nasıl oluşturulduğunu belirleyebiliriz.
| pla <= 127 | kütle <= 26.4 | | preg <= 7: test edilmiş_negatif (117.0/1.0) | | gebelik > 7 | | | kütle <= 0: test edilmiş_pozitif (2.0) | | | kütle > 0: test edilmiş_negatif (13.0) | kütle > 26,4 | | yaş <= 28: test edilmiş_negatif (180.0/22.0) | | yaş > 28 | | | plas <= 99: test edilmiş_negatif (55.0/10.0) | | | ortalama > 99 | | | | pedi <= 0.56: test edilmiş_negatif (84.0/34.0) | | | | pedi > 0,56 | | | | | hamile <= 6 | | | | | | yaş <= 30: test edilmiş_pozitif (4.0) | | | | | | yaş > 30 | | | | | | | yaş <= 34: test edilmiş_negatif (7.0/1.0) | | | | | | | yaş > 34 | | | | | | | | kütle <= 33.1: test edilmiş_pozitif (6.0) | | | | | | | | kütle > 33.1: test edilmiş_negatif (4.0/1.0) | | | | | gebelik > 6: test edilmiş_pozitif (13.0) ortalama > 127 | kütle <= 29.9 | | plas <= 145: test edilmiş_negatif (41.0/6.0) | | ortalama > 145 | | | yaş <= 25: test edilmiş_negatif (4.0) | | | yaş > 25 | | | | yaş <= 61 | | | | | kütle <= 27.1: test edilmiş_pozitif (12.0/1.0) | | | | | kütle > 27,1 | | | | | | pres <= 82 | | | | | | | pedi <= 0.396: test edilmiş_pozitif (8.0/1.0) | | | | | | | pedi > 0.396: test edilmiş_negatif (3.0)  | | | | | | pres > 82: test edilmiş_negatif (4.0) | | | | yaş > 61: test edilmiş_negatif (4.0) | kütle > 29.9 | | plas <= 157 | | | pres <= 61: test edilmiş_pozitif (15.0/1.0) | | | pres > 61 | | | | yaş <= 30: test edilmiş_negatif (40.0/13.0) | | | | yaş > 30: test edilmiş_pozitif (60.0/17.0) | | plas > 157: test edilmiş_pozitif (92.0/12.0) Yaprak Sayısı : 22 Ağacın büyüklüğü : 43 |
4. Apaçi Mahaut
Mahaut, Java kullanarak makine öğrenimini uygulamaya yardımcı olan bir algoritmalar koleksiyonudur. Geliştiricilerin matematik, istatistikçi analitiği gerçekleştirebilecekleri ölçeklenebilir bir lineer cebir çerçevesidir. Genellikle veri bilimcileri, araştırma mühendisleri ve analitik uzmanları tarafından kurumsal kullanıma hazır uygulamalar oluşturmak için kullanılır. Ölçeklenebilirliği ve esnekliği, kullanıcıların veri kümeleme, öneri sistemleri uygulamasına ve hızlı ve kolay bir şekilde yüksek performanslı Makine öğrenimi uygulamaları oluşturmasına olanak tanır.
5. Derin Öğrenme4j
Deeplearning4j, Java ile yazılmış ve derin öğrenme için kapsamlı destek sunan bir programlama kitaplığıdır. İş operasyonlarına hizmet etmek için derin sinir ağlarını ve derin pekiştirici öğrenmeyi birleştiren açık kaynaklı bir çerçevedir. Scala, Kotlin, Apache Spark, Hadoop ve diğer JVM dilleri ve büyük veri hesaplama çerçeveleriyle uyumludur.
Genellikle ses, konuşma ve yazılı metinlerdeki kalıpları ve duyguları tespit etmek için kullanılır. İşlemlerdeki tutarsızlıkları keşfedebilen ve birden fazla görevi yerine getirebilen bir Kendin Yap aracı olarak hizmet eder. Açık kaynaklı yapısı nedeniyle ayrıntılı API belgelerine sahip ticari düzeyde, dağıtılmış bir kitaplıktır.
Deeplearning4j kullanarak makine öğrenimini nasıl uygulayabileceğinize dair bir örnek.
Örnek : Deeplearning4j kullanarak, MNIST kitaplığı yardımıyla el yazısı rakamları sınıflandırmak için bir Evrişim Sinir Ağı (CNN) modeli oluşturacağız.
Adım 1 : Boyutunu görüntülemek için veri kümesini yükleyin.
| DataSetIterator MNISTTrain = new MnistDataSetIterator(batchSize,true,seed); DataSetIterator MNISTTest = new MnistDataSetIterator(batchSize,false,seed); |
Adım 2 : Veri kümesinin bize on benzersiz etiket verdiğinden emin olun.
| log.info(“Eğitim veri setinde bulunan toplam etiket sayısı ” + MNISTTrain.totalOutcomes()); log.info(“Test veri setinde bulunan toplam etiket sayısı ” + MNISTTest.totalOutcomes()); |
Adım 3 : Şimdi, çıktıyı görüntülemek için düzleştirilmiş bir katmanla birlikte iki evrişim katmanı kullanarak model mimarisini yapılandıracağız.
Deeplearning4j'de ağırlık şemasını başlatmanıza izin veren seçenekler vardır.
| // CNN modelini oluşturma MultiLayerConfiguration conf = yeni NeuralNetConfiguration.Builder() .seed(tohum) // rastgele tohum .l2(0.0005) // düzenlileştirme .weightInit(WeightInit.XAVIER) // ağırlık şemasının başlatılması .updater(new Adam(1e-3)) // Optimizasyon algoritmasını ayarlama .liste() .layer(yeni ConvolutionLayer.Builder(5, 5) //Adım, çekirdek boyutu ve etkinleştirme işlevinin ayarlanması. .nIn(nKanallar) .adım(1,1) .nÇıkış(20) .aktivasyon(Etkinleştirme.KİMLİK) .yapı()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // evrişimin altörneklenmesi .kernelSize(2,2) .adım(2,2) .yapı()) .layer(yeni ConvolutionLayer.Builder(5, 5) // Adım, çekirdek boyutu ve etkinleştirme işlevinin ayarlanması. .adım(1,1) .nÇıkış(50) .aktivasyon(Etkinleştirme.KİMLİK) .yapı()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // evrişimin altörneklenmesi .kernelSize(2,2) .adım(2,2) .yapı()) .layer(yeni DenseLayer.Builder().activation(Activation.RELU) .nOut(500).build()) .layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELİHOOD) .nOut(çıktıNum) .aktivasyon(Activation.SOFTMAX) .yapı()) // son çıktı katmanı 1 derinliğinde 28×28'dir. .setInputType(InputType.convolutionalFlat(28,28,1)) .yapı(); |
Adım 4 : Mimariyi yapılandırdıktan sonra, kipi ve eğitim veri setini başlatacağız ve model eğitimine başlayacağız.
| MultiLayerNetwork modeli = yeni MultiLayerNetwork(conf); // model ağırlıklarını başlat. model.init(); log.info(“Adım2: modeli eğitmeye başlayın”); // Her 10 yinelemede bir dinleyici ayarlama ve her çağda test setinde değerlendirme model.setListeners(new ScoreIterationListener(10), new EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); // Modeli eğitmek model.fit(MNISTTrain, nEpochs); |
Model eğitimi başladığında, sınıflandırma doğruluğunun karışıklık matrisine sahip olacaksınız.
İşte on eğitim döneminden sonra modelin doğruluğu:
| ======================== Karışıklık Matrisi======================= == 0 1 2 3 4 5 6 7 8 9 ————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. ELKİ
İndeks yapısı veya ELKI tarafından desteklenen KDD-Uygulamaları Geliştirme Ortamı, veri madenciliği için kullanılan yerleşik algoritmalar ve programlar topluluğudur. Java ile yazılmış, algoritmalarda yüksek düzeyde yapılandırılabilir parametreler içeren açık kaynaklı bir kitaplıktır. Genellikle araştırmacı bilim adamları ve öğrenciler tarafından veri kümeleri hakkında bilgi edinmek için kullanılır. Adından da anlaşılacağı gibi, bir dizin yapısı kullanarak karmaşık veri madenciliği programları ve veritabanları geliştirmek için bir ortam sağlar.
7. JSAT
Java İstatistiksel Analiz Aracı veya JSAT, kullanıcıların Java ile makine öğrenimini uygulamalarına yardımcı olmak için nesne yönelimli bir çerçeve kullanan bir GPL3 kitaplığıdır. Genellikle öğrenciler ve geliştiriciler tarafından kendi kendine eğitim amacıyla kullanılır. Diğer AI uygulama kitaplıklarıyla karşılaştırıldığında, JSAT en fazla makine öğrenimi algoritmasına sahiptir ve tüm çerçeveler arasında en hızlısıdır. Sıfır dış bağımlılık ile son derece esnek ve verimlidir ve yüksek performans sunar.
8. Encog Makine Öğrenimi Çerçevesi
Encog, Java ve C# ile yazılmıştır ve makine öğrenimi algoritmalarının uygulanmasına yardımcı olan kitaplıkları içerir. Genetik algoritmalar, Bayes Ağları, Gizli Markov Modeli gibi istatistiksel modeller ve daha fazlasını oluşturmak için kullanılır.
9. çekiç
Dil Araç Seti veya Mallet için Makine Öğrenimi, Doğal Dil İşleme'de (NLP) kullanılır. Diğer birçok ML uygulama çerçevesi gibi, Mallet de veri modelleme, veri kümeleme, belge işleme, belge sınıflandırma vb. için destek sağlar.
10. Kıvılcım MLlib
Spark MLlib, iş akışı yönetiminin verimliliğini ve ölçeklenebilirliğini artırmak için işletmeler tarafından kullanılır. Bol miktarda veriyi işler ve ağır yüklü ML algoritmalarını destekler.
Ödeme: Makine Öğrenimi Proje Fikirleri
Çözüm
Bu da bizi makalenin sonuna getiriyor. Makine Öğrenimi kavramları hakkında daha fazla bilgi için, upGrad'ın Makine Öğrenimi ve Yapay Zeka Yüksek Lisans programı aracılığıyla IIIT Bangalore ve Liverpool John Moores Üniversitesi'nin en iyi öğretim üyeleriyle iletişime geçin.
Java'yı neden Makine Öğrenimi ile birlikte kullanmalıyız?
Makine Öğrenimi uzmanları, projeleri için programlama dili olarak Java'yı seçerlerse, mevcut kod havuzlarıyla arayüz oluşturmayı daha kolay bulacaktır. Kullanım kolaylığı, paket servisler, daha iyi kullanıcı etkileşimi, hızlı hata ayıklama ve verilerin grafiksel gösterimi gibi özellikleri nedeniyle tercih edilen bir Makine Öğrenimi dilidir. Java, Makine Öğrenimi geliştiricilerinin sistemlerini ölçeklendirmesini kolaylaştırarak, sıfırdan büyük, karmaşık Makine Öğrenimi uygulamaları oluşturmak için mükemmel bir seçimdir. Java Sanal Makinesi (JVM), makine öğrenenlerin yeni araçları hızla tasarlamasına olanak tanıyan bir dizi tümleşik geliştirme ortamını (IDE) destekler.
Java öğrenmek kolay mı?
Java üst düzey bir dil olduğu için kavraması kolaydır. Bir öğrenci olarak, acemilerin anlayabileceği kadar basit, iyi yapılandırılmış, nesne yönelimli bir dil olduğu için çok fazla ayrıntıya girmek zorunda kalmayacaksınız. Otomatik olarak çalışan çok sayıda prosedür olduğundan, bunlara hızlı bir şekilde hakim olabilirsiniz. Orada işlerin nasıl yürüdüğüne dair çok fazla ayrıntıya girmenize gerek yok. Java, platformdan bağımsız bir programlama dilidir. Bir programcının herhangi bir cihazda kullanılabilecek bir mobil uygulama oluşturmasını sağlar. Nesnelerin İnterneti'nin tercih ettiği dil olmasının yanı sıra kurumsal düzeyde uygulamalar geliştirmek için en iyi araçtır.
ADAMS nedir ve Makine Öğreniminde nasıl yardımcı olur?
Gelişmiş Veri Madenciliği ve Makine Öğrenimi Sistemi (ADAMS), iş süreçlerine kolayca dahil edilebilecek veri odaklı, reaktif iş akışlarını hızlı bir şekilde oluşturmak ve yönetmek için GPLv3 lisanslı bir iş akışı motorudur. ADAMS'ın kalbinde, az çoktur ilkesini izleyen iş akışı motoru yatmaktadır. ADAMS, kullanıcının operatörleri (veya ADAMS jargonunda aktörleri) bir tuval üzerinde düzenlemesine ve ardından girdileri ve çıktıları manuel olarak bağlamasına izin vermek yerine ağaç benzeri bir yapı kullanır. Bu yapı ve kontrol aktörleri, süreçte verilerin nasıl aktığını belirlediğinden, açık bağlantılara gerek yoktur. Operatör işleyicileri içindeki dahili nesne gösterimi ve alt operatör yerleştirme, ağaç benzeri bir yapıyla sonuçlanır. ADAMS, veri alma, işleme, madencilik ve görüntüleme için çok çeşitli aracılar sağlar.