
Scrapy ile Ölçeklenebilir Web Kazıyıcıları Oluşturmak İçin En İyi Kılavuz
Yayınlanan: 2022-03-10Web kazıma, API'lere veya web sitesinin veritabanına erişmeye gerek kalmadan web sitelerinden veri almanın bir yoludur. Yalnızca sitenin verilerine erişmeniz gerekir - tarayıcınız verilere erişebildiği sürece, bunları kazıyabilirsiniz.
Gerçekçi olarak, çoğu zaman bir web sitesini manuel olarak inceleyebilir ve verileri kopyala ve yapıştır kullanarak 'elle' alabilirsiniz, ancak çoğu durumda bu saatlerce süren manuel çalışmanızı gerektirebilir ve bu da size bir maliyete mal olabilir. özellikle sizin için görevi yapması için birini işe aldıysanız, verilerden çok daha fazlası değerlidir. Her birkaç saniyede bir otomatik olarak bir sorgu gerçekleştirecek bir programa sahipken, neden birisini sorgu başına 1-2 dakikada çalışacak şekilde işe almalısınız?
Örneğin, en iyi film için Oscar kazananların bir listesini, yönetmenleri, başrol oyuncuları, çıkış tarihi ve çalışma süresi ile birlikte derlemek istediğinizi varsayalım. Google'ı kullanarak, bu filmleri adlarına ve belki de bazı ek bilgilere göre listeleyen birkaç site olduğunu görebilirsiniz, ancak genellikle istediğiniz tüm bilgileri yakalamak için bağlantıları takip etmeniz gerekir.
Açıktır ki, 1927'den günümüze kadar her bağlantıyı incelemek ve her sayfadan bilgiyi manuel olarak bulmaya çalışmak pratik ve zaman alıcı olmayacaktır. Web kazıma ile, tüm bu bilgileri içeren sayfalara sahip bir web sitesi bulmamız ve ardından programımızı doğru talimatlarla doğru yöne yönlendirmemiz gerekiyor.
Bu eğitimde, ihtiyacımız olan tüm bilgileri içerdiği için web sitemiz olarak Wikipedia'yı kullanacağız ve ardından bilgilerimizi sıyırmak için bir araç olarak Python'da Scrapy kullanacağız.
Başlamadan önce birkaç uyarı:
Veri kazıma, kazıdığınız site için sunucu yükünü artırmayı içerir; bu, siteyi barındıran şirketler için daha yüksek maliyet ve o sitenin diğer kullanıcıları için daha düşük kaliteli bir deneyim anlamına gelir. Web sitesini çalıştıran sunucunun kalitesi, elde etmeye çalıştığınız veri miktarı ve sunucuya istek gönderme hızınız, sunucu üzerindeki etkinizi azaltacaktır. Bunu akılda tutarak, birkaç kurala bağlı kaldığımızdan emin olmamız gerekir.
Çoğu sitenin ana dizininde robots.txt adlı bir dosya da bulunur. Bu dosya, sitelerin sıyırıcıların erişmesini istemediği dizinlere ilişkin kuralları belirler. Bir web sitesinin Şartlar ve Koşullar sayfası, genellikle veri kazıma konusundaki politikalarının ne olduğunu size bildirir. Örneğin, IMDB'nin koşullar sayfasında aşağıdaki madde bulunur:
Robotlar ve Ekran Kazıma: Aşağıda belirtilen açık yazılı iznimiz dışında, bu sitede veri madenciliği, robotlar, ekran kazıma veya benzeri veri toplama ve çıkarma araçlarını kullanamazsınız.
Bir web sitesinin verilerini elde etmeye çalışmadan önce, yasal veriler aldığımızdan emin olmak için her zaman web sitesinin şartlarını ve robots.txt kontrol etmeliyiz. Sıyırıcılarımızı oluştururken, bir sunucuyu işleyemeyeceği isteklerle boğmadığımızdan da emin olmamız gerekir.
Neyse ki, birçok web sitesi, kullanıcıların veri edinme ihtiyacını kabul eder ve verileri API'ler aracılığıyla kullanılabilir hale getirir. Bunlar mevcutsa, API aracılığıyla veri elde etmek genellikle kazıma yoluyla elde etmekten çok daha kolay bir deneyimdir.
Wikipedia, robots.txt belirtildiği gibi, botlar 'çok hızlı' gitmediği sürece verilerin kazınmasına izin verir. Ayrıca, insanların verileri kendi makinelerinde işleyebilmeleri için indirilebilir veri kümeleri sağlarlar. Çok hızlı gidersek, sunucular IP'mizi otomatik olarak engeller, bu yüzden onların kurallarına uymak için zamanlayıcılar uygularız.
Başlarken, Pip Kullanarak İlgili Kitaplıkları Kurma
Her şeyden önce, başlamak için, Scrapy'yi yükleyelim.
pencereler
https://www.python.org/downloads/windows/ adresinden Python'un en son sürümünü yükleyin.
Not: Windows kullanıcıları ayrıca, buradaki “Microsoft Visual C++ Yapı Araçları”ndan alabileceğiniz Microsoft Visual C++ 14.0'a da ihtiyaç duyacaktır.
Ayrıca pip'in en son sürümüne sahip olduğunuzdan emin olmak isteyeceksiniz.
cmd.exe'de şunu yazın:
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapyBu, Scrapy'yi ve tüm bağımlılıkları otomatik olarak kuracaktır.
Linux
İlk önce tüm bağımlılıkları yüklemek isteyeceksiniz:
Terminal'de şunu girin:
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-devHepsi yüklendikten sonra, şunu yazın:
pip install --upgrade pipPip'in güncellendiğinden emin olmak için ve ardından:
pip install scrapyVe hepsi bitti.
Mac
Öncelikle sisteminizde bir c-derleyici olduğundan emin olmanız gerekir. Terminal'de şunu girin:
xcode-select --installBundan sonra, https://brew.sh/ adresinden homebrew yükleyin.
PATH değişkeninizi, homebrew paketlerinin sistem paketlerinden önce kullanılması için güncelleyin:
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrcPython'u yükleyin:
brew install pythonVe sonra her şeyin güncellendiğinden emin olun:
brew update; brew upgrade pythonBu yapıldıktan sonra, pip kullanarak Scrapy'yi kurmanız yeterlidir:
pip install Scrapy > ## Scrapy'ye Genel Bakış, Parçaların Bir Araya Nasıl Geldiği, Ayrıştırıcılar, Örümcekler vb.Scrapy'nin çalışması için 'Örümcek' adında bir senaryo yazacaksınız, ama merak etmeyin, Scrapy örümcekleri isimlerine rağmen hiç de korkutucu değiller. Scrapy örümcekleri ile gerçek örümceklerin sahip oldukları tek benzerlik, internette gezinmeyi sevmeleridir.
Örümceğin içinde, sizin tanımladığınız ve Scrapy'ye ne yapacağını söyleyen bir class bulunur. Örneğin, taramaya nereden başlayacağınız, yaptığı istek türleri, sayfalardaki bağlantıları nasıl takip edeceğiniz ve verileri nasıl ayrıştıracağı. Bir dosyaya geri dönmeden önce verileri işlemek için özel işlevler bile ekleyebilirsiniz.
İlk örümcekimizi başlatmak için önce bir Scrapy projesi oluşturmamız gerekiyor. Bunu yapmak için komut satırınıza şunu girin:
scrapy startproject oscarsBu, projenizle birlikte bir klasör oluşturacaktır.
Temel bir örümcekle başlayacağız. Aşağıdaki kod bir python betiğine girilecektir. /oscars/spiders içinde yeni bir python betiği açın ve oscars_spider.py olarak adlandırın
Scrapy'yi içe aktaracağız.
import scrapyArdından Spider sınıfımızı tanımlamaya başlıyoruz. İlk önce adı ve ardından örümceğin sıyırmasına izin verilen etki alanlarını belirledik. Son olarak, örümceğe nereden kazımaya başlayacağını söyleriz.
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']Ardından, istediğimiz bilgiyi yakalayacak bir fonksiyona ihtiyacımız var. Şimdilik, sadece sayfa başlığını alacağız. Başlık metnini taşıyan etiketi bulmak için CSS kullanıyoruz ve sonra onu çıkarıyoruz. Son olarak, bilgileri günlüğe kaydedilmek veya bir dosyaya yazılmak üzere Scrapy'ye geri döndürürüz.
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data Şimdi kodu /oscars/spiders/oscars_spider.py içine kaydedin
Bu örümceği çalıştırmak için komut satırınıza gidin ve şunu yazın:
scrapy crawl oscarsBunun gibi bir çıktı görmelisiniz:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
Tebrikler, ilk temel Scrapy kazıyıcınızı yaptınız!

Tam kod:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield dataAçıkçası, biraz daha fazlasını yapmasını istiyoruz, bu yüzden verileri ayrıştırmak için Scrapy'nin nasıl kullanılacağına bakalım.
İlk olarak, Scrapy kabuğunu tanıyalım. Scrapy kabuğu, Scrapy'nin istediğiniz verileri aldığından emin olmak için kodunuzu test etmenize yardımcı olabilir.
Kabuğa erişmek için bunu komut satırınıza girin:
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”Bu, temelde onu yönlendirdiğiniz sayfayı açar ve tek satır kod çalıştırmanıza izin verir. Örneğin, şunu yazarak sayfanın ham HTML'sini görüntüleyebilirsiniz:
print(response.text)Veya şunu yazarak sayfayı varsayılan tarayıcınızda açın:
view(response)Buradaki amacımız, istediğimiz bilgileri içeren kodu bulmaktır. Şimdilik sadece film isimlerini almaya çalışalım.
İhtiyacımız olan kodu bulmanın en kolay yolu, sayfayı tarayıcımızda açıp kodu incelemektir. Bu örnekte, Chrome DevTools kullanıyorum. Herhangi bir film başlığına sağ tıklayın ve 'incele'yi seçin:
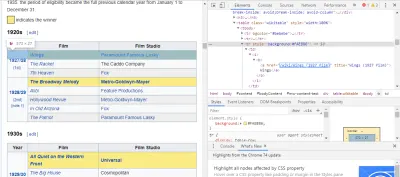
Gördüğünüz gibi, Oscar kazananlar sarı bir arka plana sahipken, adaylar sade bir arka plana sahip. Ayrıca film başlığıyla ilgili makaleye bir bağlantı var ve filmlerin bağlantıları filmde bitiyor film) . Artık bunu bildiğimize göre, verileri almak için bir CSS seçici kullanabiliriz. Scrapy kabuğuna şunu yazın:
response.css(r"tr[] a[href*='film)']").extract()Gördüğünüz gibi, artık tüm Oscar En İyi Film Kazananlarının bir listesi var!
> response.css(r"tr[] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']Ana hedefimize dönersek, yönetmenleri, başrol oyuncuları, çıkış tarihi ve çalışma süresi ile birlikte en iyi film için Oscar kazananların bir listesini istiyoruz. Bunu yapmak için, bu film sayfalarının her birinden veri almak için Scrapy'ye ihtiyacımız var.
Birkaç şeyi yeniden yazmamız ve yeni bir işlev eklememiz gerekecek, ancak endişelenmeyin, oldukça basit.
Kazıyıcıyı daha önce olduğu gibi başlatarak başlayacağız.
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] Ama bu sefer iki şey değişecek. İlk olarak, scrapy ile birlikte time içe aktaracağız çünkü botun ne kadar hızlı sıyırdığını kısıtlamak için bir zamanlayıcı oluşturmak istiyoruz. Ayrıca, sayfaları ilk kez ayrıştırdığımızda, yalnızca her bir başlığın bağlantılarının bir listesini almak istiyoruz, böylece bunun yerine bu sayfalardan bilgi alabiliriz.
def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req Burada, sayfadaki sarı arka plana sahip her bağlantıyı aramak için bir döngü yaparız ve sonra bu bağlantıları bir URL listesi halinde birleştiririz ve daha ileri parse_titles film) göndeririz. Ayrıca, yalnızca her 5 saniyede bir sayfa istemesi için bir zamanlayıcı ekledik. Doğru verileri aldığımızdan emin olmak için answer.css alanlarımızı test etmek için Scrapy kabuğunu kullanabileceğimizi unutmayın!
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data Asıl iş, data adı verilen bir sözlük oluşturduğumuz ve ardından her anahtarı istediğimiz bilgiyle doldurduğumuz parse_data işlevimizde yapılır. Yine, tüm bu seçiciler, daha önce gösterildiği gibi Chrome DevTools kullanılarak bulundu ve ardından Scrapy kabuğuyla test edildi.
Son satır, veri sözlüğünü saklamak için Scrapy'ye geri döndürür.
Kodu tamamlayın:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield dataWeb siteleri kazıma girişimlerimizi engellemeye çalışacağından bazen proxy kullanmak isteyeceğiz.
Bunu yapmak için sadece birkaç şeyi değiştirmemiz gerekiyor. Örneğimizi kullanarak, def parse() içinde, onu aşağıdaki şekilde değiştirmemiz gerekiyor:
def parse(self, response): for href in (r"tr[] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "https://yourproxy.com:80" yield reqBu, istekleri proxy sunucunuz üzerinden yönlendirecektir.
Dağıtım ve Günlüğe Kaydetme, Üretimde Bir Örümceğin Gerçekte Nasıl Yönetileceğini Göster
Şimdi örümceğimizi çalıştırma zamanı. Scrapy'nin kazımaya başlamasını ve ardından bir CSV dosyasına çıktı almasını sağlamak için komut isteminize aşağıdakini girin:
scrapy crawl oscars -o oscars.csvBüyük bir çıktı göreceksiniz ve birkaç dakika sonra tamamlanacak ve proje klasörünüzde oturan bir CSV dosyanız olacak.
Sonuçları Derleme, Önceki Adımlarda Derlenen Sonuçların Nasıl Kullanılacağını Göster
CSV dosyasını açtığınızda, istediğimiz tüm bilgileri göreceksiniz (başlıklı sütunlara göre sıralanmış). Gerçekten bu kadar basit.
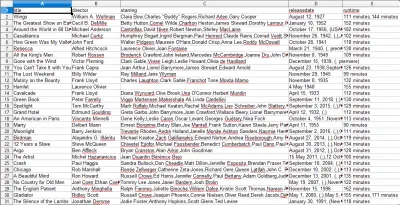
Veri kazıma ile, bilgiler herkese açık olduğu sürece, istediğimiz hemen hemen her özel veri kümesini elde edebiliriz. Bu verilerle ne yapmak istediğiniz size kalmış. Bu beceri, pazar araştırması yapmak, bir web sitesindeki bilgileri güncel tutmak ve diğer birçok şey için son derece yararlıdır.
Özel veri kümelerini kendi başınıza elde etmek için kendi web kazıyıcınızı kurmak oldukça kolaydır, ancak ihtiyacınız olan verileri elde etmenin başka yolları da olabileceğini her zaman unutmayın. İşletmeler, istediğiniz verileri sağlamaya çok yatırım yapar, bu nedenle onların hüküm ve koşullarına saygı göstermemiz adil olur.
Genel Olarak Scrapy ve Web Scraping Hakkında Daha Fazla Bilgi Edinmek İçin Ek Kaynaklar
- Resmi Scrapy Web Sitesi
- Scrapy'nin GitHub Sayfası
- “En İyi 10 Veri Kazıma Aracı ve Web Kazıma Aracı,” Scraper API
- “Engellenmeden veya Kara Listeye Alınmadan Web Kazıma İçin 5 İpucu,” Kazıyıcı API
- Parsel, HTML'den veri çıkarmak için normal ifadeleri kullanan bir Python kitaplığı.