
2022'de En İyi 15 Hadoop Mülakat Sorusu ve Yanıtı
Yayınlanan: 2021-01-09Veri analitiğinin ivme kazanmasıyla birlikte, Büyük Veriyi iyi idare eden insanların talebinde bir artış oldu. Veri analistlerinden veri bilimcilerine kadar, Büyük Veri bugün bir dizi iş profili oluşturuyor. Uygulamalı olmanız beklenen ilk ve en önemli şey Hadoop.
Hangi iş rolü/profili olursa olsun, muhtemelen bir şekilde Hadoop üzerinde çalışıyor olacaksınız. Bu nedenle, görüşmecilerin her zaman yolunuza birkaç Hadoop sorusu çekmesini bekleyebilirsiniz.
Bunun için ve daha fazlası için, oturduğunuz herhangi bir röportajda bekleyebileceğiniz en iyi 15 Hadoop mülakat sorusuna bakalım.
Hadoop nedir? Hadoop'un birincil bileşenleri nelerdir?
Hadoop, Büyük Veriyi işlemek ve depolamak için gerekli olan ilgili araç ve hizmetlerle donatılmış bir altyapıdır. Kesin olmak gerekirse, Hadoop, tüm Büyük Veri zorluklarının 'çözümüdür'. Ayrıca Hadoop çerçevesi, kuruluşların Büyük Verileri analiz etmesine ve daha iyi iş kararları almasına da yardımcı olur.
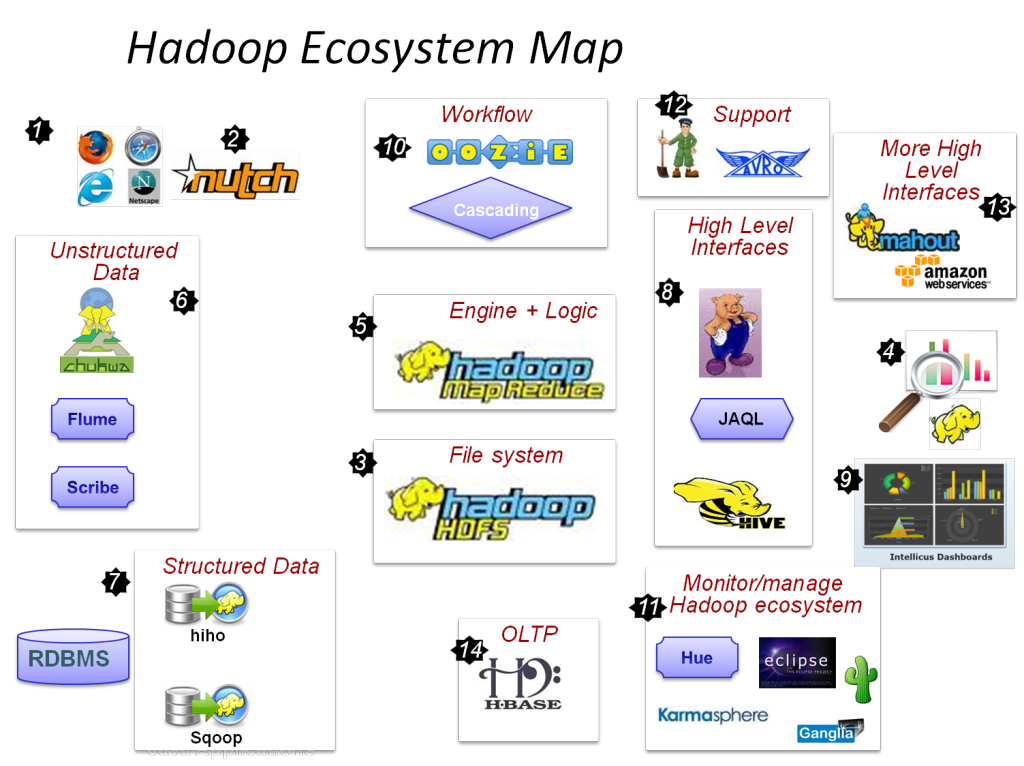
Hadoop'un birincil bileşenleri şunlardır:
- HDFS
- Hadoop HaritasıKüçült
- Hadoop Ortak
- İPLİK
- PIG ve HIVE – Veri Erişim Bileşenleri.
- HBase – Veri Depolama için
- Ambari, Oozie ve ZooKeeper – Veri Yönetimi ve İzleme Bileşeni
- Thrift ve Avro – Veri Serileştirme bileşenleri
- Apache Flume, Sqoop, Chukwa – Veri Entegrasyon Bileşenleri
- Apache Mahout ve Drill – Veri Zekası Bileşenleri
Hadoop çerçevesinin temel kavramları nelerdir?
Hadoop temel olarak iki temel kavram üzerine kuruludur. Onlar:
- HDFS: HDFS veya Hadoop Dağıtılmış Dosya Sistemi, büyük veri kümelerini blok biçiminde depolamak için kullanılan Java tabanlı güvenilir bir dosya sistemidir. Master-Slave Mimarisi ona güç veriyor.
- MapReduce: MapReduce, büyük veri kümelerinin işlenmesine yardımcı olan bir programlama yapısıdır. Bu işlev ayrıca iki kısma ayrılır - 'harita' veri kümelerini kümelere ayırırken, 'azaltma' harita kümelerini kullanır ve daha küçük küme kümelerinin bir kombinasyonunu oluşturur.
Hadoop'taki en yaygın giriş biçimlerini adlandırın?
Hadoop'ta üç yaygın giriş biçimi vardır:
- Metin Giriş Biçimi: Bu, Hadoop'taki varsayılan giriş biçimidir.
- Sıra Dosya Giriş Formatı: Bu giriş formatı, dosyaları sırayla okumak için kullanılır.
- Anahtar Değer Giriş Formatı: Bu, düz metin dosyalarını okumak için kullanılır.
İPLİK nedir?
YARN, Yet Another Resource Negotiator'ın kısaltmasıdır. Veri kaynaklarını yöneten ve başarılı işleme için bir ortam yaratan, Hadoop'un veri işleme çerçevesidir. 
“Raf Farkındalığı” nedir?
"Rack Awareness", NameNode'un veri bloklarının ve bunların kopyalarının Hadoop kümesi içinde depolandığı modeli belirlemek için kullandığı bir algoritmadır. Bu, aynı rafta bulunan veri düğümleri arasındaki tıkanıklığı azaltan raf tanımlarının yardımıyla elde edilir.

Aktif ve Pasif NameNode nedir?
Yüksek kullanılabilirliğe sahip bir Hadoop sistemi genellikle iki NameNode içerir – Active NameNode ve Passive NameNode.
Hadoop kümesini çalıştıran NameNode, Active NameNode olarak adlandırılır ve Active NameNode'un verilerini depolayan beklemedeki NameNode, Pasif NameNode'dur.
İki NameNode'a sahip olmanın amacı, Aktif NameNode'un çökmesi durumunda Pasif NameNode'un liderliği alabilmesidir. Böylece NameNode her zaman kümede çalışır ve sistem asla başarısız olmaz.
Hadoop çerçevesindeki farklı zamanlayıcılar nelerdir?
Hadoop çerçevesinde üç farklı zamanlayıcı vardır:
- COSHH – COSHH, kümeyi ve heterojenlikle birleştirilmiş iş yükünü gözden geçirerek kararların programlanmasına yardımcı olur.
- FIFO Zamanlayıcı – FIFO, heterojenlik kullanmadan varış zamanlarına göre işleri bir kuyruğa yerleştirir.
- Adil Paylaşım – Adil Paylaşım, bireysel kullanıcılar için birden fazla harita içeren bir havuz oluşturur ve belirli işleri yürütmek için kullanabilecekleri bir kaynaktaki yuvaları azaltır.
Spekülatif İcra Nedir?
Genellikle Hadoop çerçevesinde bazı düğümler diğerlerinden daha yavaş çalışabilir. Bu, tüm programı kısıtlama eğilimindedir. Bunun üstesinden gelmek için, Hadoop önce bir görevin normalden daha yavaş çalıştığını algılar veya "speküle eder" ve ardından bu görev için eşdeğer bir yedekleme başlatır. Yani bu süreçte, ana düğüm her iki görevi de aynı anda yürütür ve hangisi önce tamamlanırsa kabul edilir, diğeri öldürülür. Hadoop'un bu yedekleme özelliği, Spekülatif Yürütme olarak bilinir.

Apache HBase'in ana bileşenlerini adlandırın?
Apache HBase üç bileşenden oluşur:
- Bölge Sunucusu: Bir tablo birden çok bölgeye ayrıldıktan sonra, bu bölgelerin kümeleri, Bölge Sunucusu aracılığıyla istemcilere iletilir.
- HMaster: Bu, Bölge sunucusunu yönetmeye ve koordine etmeye yardımcı olan bir araçtır.
- ZooKeeper: ZooKeeper, HBase dağıtılmış ortamında bir koordinatördür. Oturumlarda iletişim yoluyla küme içinde bir sunucu durumunun korunmasına yardımcı olur.
"Kontrol noktası" nedir? Faydası nedir?
Kontrol noktası, yeni bir FsImage oluşturmak için bir FsImage ve Edit günlüğünün birleştirildiği prosedürü ifade eder. Böylece, düzenleme günlüğünü yeniden oynatmak yerine NameNode, FsImage'dan son bellek içi durumu doğrudan yükleyebilir. Bu işlemden ikincil NameNode sorumludur.
Checkpointing'in sunduğu avantaj, NameNode'un başlatma süresini en aza indirerek tüm süreci daha verimli hale getirmesidir.
Pop-Kültürde Büyük Veri Uygulamaları
Hadoop kodunda nasıl hata ayıklanır?
Bir Hadoop kodunda hata ayıklamak için önce, çalışmakta olan MapReduce görevlerinin listesini kontrol etmeniz gerekir. Ardından, artık herhangi bir görevin aynı anda çalışıp çalışmadığını kontrol etmeniz gerekir. Öyleyse, aşağıdaki basit adımları izleyerek Kaynak Yöneticisi günlüklerinin konumunu bulmanız gerekir:
“ps –ef | grep –I ResourceManager” ve görüntülenen sonuçta belirli bir iş kimliğiyle ilgili bir hata olup olmadığını bulmaya çalışın.
Şimdi, görevi yürütmek için kullanılan çalışan düğümü tanımlayın. Düğümde oturum açın ve “ps –ef | grep –iNodeManager."
Son olarak, Düğüm Yöneticisi günlüğünü inceleyin. Hataların çoğu, her eşleme azaltma işi için kullanıcı düzeyindeki günlüklerden oluşturulur.
Hadoop'ta RecordReader'ın amacı nedir?
Hadoop, verileri blok biçimlerine ayırır. RecordReader, bu veri bloklarını tek bir okunabilir kayda entegre etmeye yardımcı olur. Örneğin, giriş verileri iki bloğa bölünmüşse –
1. Sıra – Hoş Geldiniz
2. Sıra – UpGrad
RecordReader bunu "UpG rad'a Hoş Geldiniz" olarak okuyacaktır .
Hadoop'un çalışabileceği modlar nelerdir?
Hadoop'un çalışabileceği modlar şunlardır:
- Bağımsız mod – Bu, hata ayıklama amacıyla kullanılan varsayılan bir Hadoop modudur. HDFS'yi desteklemiyor.
- Sözde dağıtılmış mod – Bu mod, mapred-site.xml, core-site.xml ve hdfs-site.xml dosyalarının yapılandırılmasını gerektiriyordu. Hem Master hem de Slave Düğüm burada aynıdır.
- Tam dağıtılmış mod – Tam dağıtılmış mod, verilerin bir Hadoop kümesindeki çeşitli düğümler arasında dağıtıldığı Hadoop'un üretim aşamasıdır. Burada, Master ve Slave Düğümleri ayrı ayrı tahsis edilmiştir.
Hadoop'un bazı pratik uygulamalarını adlandırın.
Hadoop'un fark yarattığı gerçek hayattan bazı örnekler:
- Sokak trafiğini yönetme
- Dolandırıcılık tespiti ve önlenmesi
- Müşteri hizmetlerini iyileştirmek için müşteri verilerini gerçek zamanlı olarak analiz edin
- Sağlık hizmetlerini iyileştirmek için doktorlardan, HCP'lerden vb. yapılandırılmamış tıbbi verilere erişim.
Büyük Verinin performansını artırabilecek hayati Hadoop araçları nelerdir?
Büyük Veri performansını önemli ölçüde artıran Hadoop araçları şunlardır:

• Kovan
• HDFS
• HBase
• SQL
• NoSQL
• Oozie
• Bulutlar
• Avro
• Kanalizasyon
• Hayvan Bekçisi
Büyük Veri Mühendisleri: Mitler ve Gerçekler
Çözüm
Bu Hadoop mülakat soruları, bir sonraki mülakatınızda size çok yardımcı olacaktır. Bazen görüşmecilerin bazı Hadoop görüşme sorularını çarpıtma eğilimi olsa da, temel bilgilerinizi sıralarsanız bu sizin için bir sorun olmamalıdır.
Büyük Veri hakkında daha fazla bilgi edinmek istiyorsanız, çalışan profesyoneller için tasarlanmış ve 7+ vaka çalışması ve proje sağlayan, 14 programlama dili ve aracını kapsayan, pratik uygulamalı Büyük Veride Yazılım Geliştirme Uzmanlığı programında PG Diplomamıza göz atın çalıştaylar, en iyi firmalarla 400 saatten fazla titiz öğrenim ve işe yerleştirme yardımı.