
Makine Öğrenimi Kullanarak Hisse Senedi Piyasası Tahmini [Adım Adım Uygulama]
Yayınlanan: 2021-02-26İçindekiler
Tanıtım
Hisse senedi piyasasının tahmini ve analizi, yapılması en karmaşık görevlerden bazılarıdır. Bunun, piyasa oynaklığı ve piyasada belirli bir hisse senedinin değerine karar vermek için diğer birçok bağımlı ve bağımsız faktör gibi birkaç nedeni vardır. Bu faktörler, herhangi bir borsa analistinin yükselişi ve düşüşü yüksek doğruluk dereceleriyle tahmin etmesini çok zorlaştırıyor.
Ancak, Makine Öğreniminin ve sağlam algoritmalarının ortaya çıkmasıyla, en son piyasa analizi ve Borsa Tahmini gelişmeleri, borsa verilerini anlamada bu teknikleri birleştirmeye başladı.
Kısacası, Makine Öğrenimi Algoritmaları birçok kuruluş tarafından stok değerlerinin analizinde ve tahmin edilmesinde yaygın olarak kullanılmaktadır. Bu makale, Python'da birkaç Makine Öğrenimi Algoritması kullanarak Dünya Çapında Popüler Çevrimiçi Perakende Mağazasının stok değerlerini analiz etmenin ve tahmin etmenin basit bir Uygulamasından geçecektir.
Sorun bildirimi
Borsa değerlerini tahmin etmek için programın uygulamasına geçmeden önce, üzerinde çalışacağımız verileri görselleştirelim. Burada, National Association of Securities Dealers Automated Quotation'dan (NASDAQ) Microsoft Corporation'ın (MSFT) hisse senedi değerini analiz edeceğiz. Hisse senedi değeri verileri, Excel veya Elektronik Tablo kullanılarak açılıp görüntülenebilen Virgülle Ayrılmış Dosya (.csv) biçiminde sunulacaktır.
MSFT, NASDAQ'a kayıtlı hisse senetlerine sahiptir ve borsanın her iş günü içinde değerlerini güncelleştirmektedir. Pazarın cumartesi ve pazar günleri alım satım yapılmasına izin vermediğini unutmayın; dolayısıyla iki tarih arasında bir boşluk vardır. Her tarih için gün sonundaki Kapanış Değeri ile birlikte hisse senedinin Açılış Değeri, o hisse senedinin aynı günlerdeki En Yüksek ve En Düşük değerleri not edilir.
Düzeltilmiş Kapanış Değeri, hisse senedinin temettüler gönderildikten sonraki değerini gösterir (Çok teknik!). Ek olarak, piyasadaki hisse senetlerinin toplam hacmi de verilmiştir, Bu verilerle, verileri incelemek ve Microsoft Corporation hisse senedinin geçmişinden kalıpları çıkarabilen çeşitli algoritmaları uygulamak bir Makine Öğrenimi/Veri Bilimcisi'nin çalışmasına bağlıdır. veri.

Uzun Kısa Süreli Bellek
Microsoft Corporation'ın hisse senedi fiyatlarını tahmin etmek üzere bir Makine Öğrenimi modeli geliştirmek için Uzun Kısa Süreli Bellek (LSTM) tekniğini kullanacağız. Çarpma ve toplama yoluyla bilgilerde küçük değişiklikler yapmak için kullanılırlar. Tanım olarak, uzun süreli bellek (LSTM), derin öğrenmede kullanılan yapay bir tekrarlayan sinir ağı (RNN) mimarisidir.
Standart ileri beslemeli sinir ağlarının aksine, LSTM geri besleme bağlantılarına sahiptir. Tek veri noktalarını (görüntüler gibi) ve tüm veri dizilerini (konuşma veya video gibi) işleyebilir. LSTM'nin arkasındaki konsepti anlamak için, bir Cep Telefonunun çevrimiçi müşteri incelemesinden basit bir örnek alalım.
Diyelim ki Cep Telefonu satın almak istiyoruz, genellikle sertifikalı kullanıcılar tarafından yapılan net incelemelere başvuruyoruz. Onların düşünce ve girdilerine bağlı olarak, cep telefonunun iyi mi yoksa kötü mü olduğuna karar verir ve ardından satın alırız. İncelemeleri okumaya devam ederken, "muhteşem", "iyi kamera", "en iyi pil yedeği" gibi anahtar sözcükleri ve cep telefonuyla ilgili diğer birçok terimi arıyoruz.
İngilizcede yaygın olarak kullanılan “it”, “verdi”, “bu” gibi kelimeleri göz ardı etme eğilimindeyiz. Bu nedenle cep telefonu alıp almamaya karar verdiğimizde sadece yukarıda tanımlanan bu anahtar kelimeleri hatırlıyoruz. Büyük olasılıkla, diğer kelimeleri unutuyoruz.
Bu, Uzun Kısa Süreli Bellek Algoritmasının çalıştığı yöntemle aynıdır. Yalnızca ilgili bilgileri hatırlar ve alakasız verileri yok sayarak tahminler yapmak için kullanır. Bu şekilde, esasen sadece o hisse senedi hakkındaki temel verileri tanıyan ve aykırı değerleri dışarıda bırakan bir LSTM modeli oluşturmamız gerekiyor.
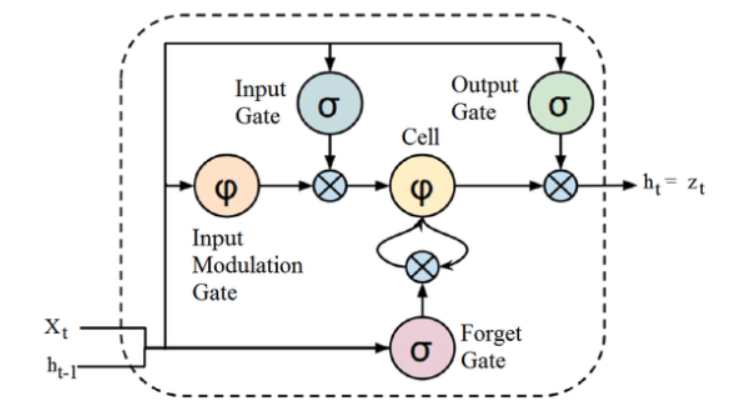
Kaynak
Bir LSTM mimarisinin yukarıda verilen yapısı ilk bakışta ilgi çekici görünse de, LSTM'nin, veri dizilerini işlemek için Belleği tutan Tekrarlayan Sinir Ağlarının gelişmiş bir versiyonu olduğunu hatırlamak yeterlidir. Kapı adı verilen yapılar tarafından dikkatlice düzenlenerek hücre durumuna bilgi ekleyebilir veya kaldırabilir.
LSTM birimi bir hücre, bir giriş kapısı, bir çıkış kapısı ve bir unutma kapısı içerir. Hücre keyfi zaman aralıklarında değerleri hatırlar ve üç kapı hücreye giren ve çıkan bilgi akışını düzenler.
Program Uygulaması
Python'da Machine Learning kullanarak stok değerini tahmin etmede LSTM'yi kullandığımız kısma geçeceğiz.
Adım 1 – Kitaplıkları İçe Aktarma
Hepimizin bildiği gibi, ilk adım, Microsoft Corporation'ın stok verilerini önceden işlemek için gerekli olan kitaplıkları ve LSTM modelinin çıktılarını oluşturmak ve görselleştirmek için gerekli diğer kitaplıkları içe aktarmaktır. Bunun için TensorFlow çerçevesi altındaki Keras kütüphanesini kullanacağız. Gerekli modüller Keras kitaplığından ayrı ayrı içe aktarılır.
#Kütüphaneleri İçe Aktarma
pandaları PD olarak içe aktar
NumPy'yi np olarak içe aktar
%matplotlib satır içi
matplotlib'i içe aktarın. plt olarak pyplot
matplotlib'i içe aktar
sklearn'den. Ön işleme içe aktarma MinMaxScaler
Keras'tan. katmanlar içe aktarılır LSTM, Yoğun, Bırakma
sklearn.model_selection'dan TimeSeriesSplit'i içe aktarın
sklearn.metrics'den ortalama_squared_error, r2_score'u içe aktarın
matplotlib'i içe aktarın. görev olarak tarihler
sklearn'den. Ön işleme içe aktarma MinMaxScaler
sklearn'den içe aktarma linear_model
Keras'tan. Modeller sıralı içe aktarma
Keras'tan. Katmanlar Yoğun içe aktarılıyor
Keras'ı içe aktarın. K olarak arka uç
Keras'tan. Geri aramalar EarlyStopping'i içe aktarır
Keras'tan. Optimize ediciler Adam'ı içe aktarır
Keras'tan. Modeller yük_modelini içe aktarır
Keras'tan. Katmanlar LSTM'yi içe aktarır
Keras'tan. utils.vis_utils import plot_model
Adım 2 – Verileri Görselleştirme
Pandas Data okuyucu kitaplığını kullanarak, yerel sistemin stok verilerini Virgülle Ayrılmış Değer (.csv) dosyası olarak yükleyeceğiz ve bir pandas DataFrame'e kaydedeceğiz. Son olarak, verileri de görüntüleyeceğiz.
#Veri Kümesini Alın
df = pd.read_csv(“MicrosoftStockData.csv”,na_values=['null'],index_col='Date',parse_dates=True,infer_datetime_format=Doğru)
df.head()
Kariyerinizi hızlandırmak için Dünyanın en iyi Üniversiteleri - Yüksek Lisanslar, Yönetici Yüksek Lisans Programları ve Makine Öğrenimi ve Yapay Zeka alanında İleri Düzey Sertifika Programından çevrimiçi olarak AI sertifikası alın .
Adım 3 – DataFrame Şeklini yazdırın ve Boş Değerleri Kontrol Edin.
Bu bir diğer önemli adımda, önce veri kümesinin şeklini yazdırıyoruz. Veri çerçevesinde boş değer olmadığından emin olmak için bunları kontrol ederiz. Veri kümesindeki boş değerlerin varlığı, eğitim sürecinde geniş bir varyansa neden olan aykırı değerler olarak hareket ettikleri için eğitim sırasında sorunlara neden olma eğilimindedir.
#Veri çerçevesi şeklini yazdır ve Boş Değerleri Kontrol Et
print(“Veri çerçevesi Şekli: “, df. şekil)
print(“Boş Değer Mevcut: “, df.IsNull().values.any())
>> Veri Çerçevesi Şekli: (7334, 6)
>>Null Value Present: False
| Tarih | Açık | Yüksek | Düşük | Kapat | Ayar Kapat | Hacim |
| 1990-01-02 | 0.605903 | 0.616319 | 0.598090 | 0.616319 | 0,447268 | 53033600 |
| 1990-01-03 | 0.621528 | 0.626736 | 0.614583 | 0,619792 | 0.449788 | 113772800 |
| 1990-01-04 | 0,619792 | 0.638889 | 0.616319 | 0.638021 | 0.463017 | 125740800 |
| 1990-01-05 | 0.635417 | 0.638889 | 0.621528 | 0.622396 | 0.451678 | 69564800 |
| 1990-01-08 | 0.621528 | 0.631944 | 0.614583 | 0.631944 | 0.458607 | 58982400 |
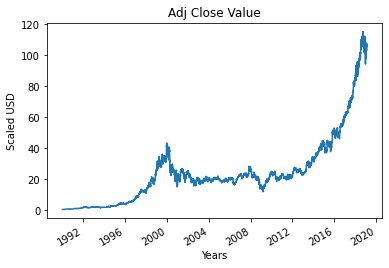
Adım 4 – Gerçek Düzeltilmiş Kapanış Değerini Çizmek
Machine Learning modeli kullanılarak tahmin edilecek nihai çıktı değeri, Düzeltilmiş Kapanış Değeridir. Bu değer, hisse senedi piyasasının o belirli gününde hisse senedinin kapanış değerini temsil eder.
#Gerçek Adj Kapanış Değerini Çiz
df['Adj Kapat'].plot()
Adım 5 – Hedef Değişkenin Ayarlanması ve Özelliklerin Seçilmesi
Bir sonraki adımda çıktı sütununu hedef değişkene atadık. Bu durumda, Microsoft Hisse Senedi'nin ayarlanmış göreli değeridir. Ek olarak, hedef değişkene (bağımlı değişken) bağımsız değişken olarak hareket eden özellikleri de seçiyoruz. Eğitim amacını hesaba katmak için dört özellik seçiyoruz:

- Açık
- Yüksek
- Düşük
- Hacim
#Hedef Değişkeni Ayarla
output_var = PD.DataFrame(df['Adj Close'])
#Özellikleri Seçme
özellikler = ['Açık', 'Yüksek', 'Düşük', 'Ses Düzeyi']
Adım 6 – Ölçekleme
Tablodaki verilerin hesaplama maliyetini azaltmak için stok değerlerini 0 ile 1 arasındaki değerlere indireceğiz. Bu şekilde büyük sayılardaki tüm veriler azaltılarak bellek kullanımı azaltılır. Ayrıca, veriler çok büyük değerlere yayılmadığı için ölçeği küçülterek daha fazla doğruluk elde edebiliriz. Bu, sci-kit-learn kitaplığının MinMaxScaler sınıfı tarafından gerçekleştirilir.
#Ölçeklendirme
ölçekleyici = MinMaxScaler()
feature_transform = scaler.fit_transform(df[özellikler])
feature_transform= pd.DataFrame(columns=features, data=feature_transform, index=df.index)
feature_transform.head()
| Tarih | Açık | Yüksek | Düşük | Hacim |
| 1990-01-02 | 0.000129 | 0.000105 | 0.000129 | 0.064837 |
| 1990-01-03 | 0.000265 | 0.000195 | 0,000273 | 0.144673 |
| 1990-01-04 | 0.000249 | 0.000300 | 0.000288 | 0.160404 |
| 1990-01-05 | 0.000386 | 0.000300 | 0.000334 | 0,086566 |
| 1990-01-08 | 0.000265 | 0.000240 | 0,000273 | 0.072656 |
Yukarıda bahsedildiği gibi, öznitelik değişkenlerinin değerlerinin yukarıda verilen gerçek değerlere göre daha küçük değerlere ölçeklendiğini görüyoruz.
Adım 7 – Bir Eğitim Seti ve Test Setine Bölme.
Verileri eğitim modeline beslemeden önce, tüm veri setini eğitim ve test seti olarak ayırmamız gerekiyor. Machine Learning LSTM modeli, eğitim setinde bulunan veriler üzerinde eğitilecek ve doğruluk ve geri yayılım için test setinde test edilecektir.
Bunun için sci-kit-learn kütüphanesinin TimeSeriesSplit sınıfını kullanacağız. Bölme sayısını 10 olarak belirledik, bu da verilerin %10'unun test seti olarak kullanılacağını ve verilerin %90'ının LSTM modelini eğitmek için kullanılacağını ifade ediyor. Bu Zaman Serisi bölünmesini kullanmanın avantajı, bölünmüş zaman serisi veri örneklerinin sabit zaman aralıklarında gözlemlenmesidir.
#Eğitim setine ve Test setine bölme
timeplit= TimeSeriesSplit(n_splits=10)
train_index için, timesplit.split(feature_transform) içindeki test_index:
X_train, X_test = feature_transform[:len(train_index)], feature_transform[len(train_index): (len(train_index)+len(test_index))]
y_train, y_test = output_var[:len(train_index)].values.ravel(), output_var[len(train_index): (len(train_index)+len(test_index))].values.ravel()
Adım 8 – LSTM İçin Verilerin İşlenmesi
Eğitim ve test setleri hazır olduğunda, oluşturulduktan sonra verileri LSTM modeline besleyebiliriz. Bunun öncesinde eğitim ve test seti verilerini LSTM modelinin kabul edeceği bir veri tipine dönüştürmemiz gerekiyor. Önce eğitim verilerini ve test verilerini NumPy dizilerine dönüştürüyoruz ve ardından LSTM'nin verilerin 3D biçimde beslenmesini gerektirdiği için bunları biçime (Örnek Sayısı, 1, Özellik Sayısı) yeniden şekillendiriyoruz. Bildiğimiz gibi eğitim setindeki örnek sayısı 7334 olan 6667'nin %90'ı ve öznitelik sayısı 4'tür ve eğitim seti (6667, 1, 4) olarak yeniden şekillendirilir. Benzer şekilde test seti de yeniden şekillendirilir.
#LSTM için verileri işleyin
trenX =np.dizi(X_tren)
testX =np.dizi(X_test)
X_train = trainX.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test = testX.reshape(X_test.shape[0], 1, X_test.shape[1])
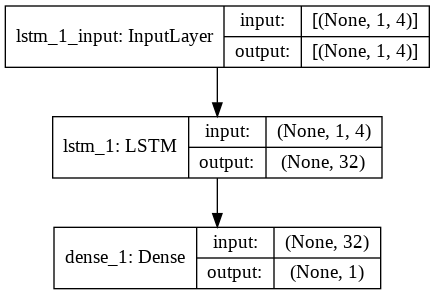
Adım 9 – LSTM Modelini Oluşturma
Son olarak LSTM Modelini kurduğumuz aşamaya geliyoruz. Burada, bir LSTM katmanı ile bir Sıralı Keras modeli oluşturuyoruz. LSTM katmanı 32 birime sahiptir ve bunu 1 nörondan oluşan bir Yoğun Katman izler.
Modeli derlemek için kayıp fonksiyonu olarak Adam Optimizer ve Mean Squared Error kullanıyoruz. Bu ikisi, bir LSTM modeli için en çok tercih edilen kombinasyondur. Ek olarak, model de çizilir ve aşağıda görüntülenir.
#LSTM Modelini Oluşturma
lstm = Sıralı()
lstm.add(LSTM(32, input_shape=(1, trainX.shape[1]), activation='relu', return_sequences=Yanlış))
lstm.add(Yoğun(1))
lstm.compile(loss='mean_squared_error', optimizer='adam')
plot_model(lstm, show_shapes=Doğru, show_layer_names=Doğru)
Adım 10 – Modelin Eğitimi
Son olarak, yukarıda tasarlanan LSTM modelini, uyum işlevini kullanarak 8 parti boyutuyla 100 dönem için eğitim verileri üzerinde eğitiyoruz.
#Model Eğitimi
geçmiş = lstm.fit(X_train, y_train, epochs=100, batch_size=8, ayrıntılı=1, shuffle=Yanlış)
Dönem 1/100
834/834 [=============================] – 3s 2ms/adım – kayıp: 67.1211
Dönem 2/100
834/834 [=============================] – 1s 2ms/adım – kayıp: 70.4911
Dönem 3/100
834/834 [=============================] – 1s 2ms/adım – kayıp: 48.8155
Dönem 4/100
834/834 [=============================] – 1s 2ms/adım – kayıp: 21.5447
Dönem 5/100
834/834 [=============================] – 1s 2ms/adım – kayıp: 6.1709
Dönem 6/100
834/834 [=============================] – 1s 2ms/adım – kayıp: 1.8726
Dönem 7/100
834/834 [=============================] – 1s 2ms/adım – kayıp: 0.9380
Dönem 8/100
834/834 [=============================] – 2s 2ms/adım – kayıp: 0.6566
Dönem 9/100
834/834 [=============================] – 1s 2ms/adım – kayıp: 0,5369
Dönem 10/100
834/834 [=============================] – 2s 2ms/adım – kayıp: 0,4761
.
.
.
.
Dönem 95/100
834/834 [=============================] – 1s 2ms/adım – kayıp: 0.4542
Dönem 96/100
834/834 [=============================] – 2s 2ms/adım – kayıp: 0.4553
Dönem 97/100
834/834 [=============================] – 1s 2ms/adım – kayıp: 0.4565
Dönem 98/100
834/834 [=============================] – 1s 2ms/adım – kayıp: 0.4576
Dönem 99/100
834/834 [=============================] – 1s 2ms/adım – kayıp: 0.4588
Dönem 100/100
834/834 [=============================] – 1s 2ms/adım – kayıp: 0.4599
Son olarak 100 epochluk eğitim sürecinde kayıp değerinin zaman içinde katlanarak azaldığını ve 0,4599 değerine ulaştığını görüyoruz.
Adım 11 – LSTM Tahmini
Modelimiz hazır olduğunda, LSTM ağı kullanılarak eğitilen modeli test setinde kullanma ve Microsoft hissesinin Bitişik Kapanış Değerini tahmin etme zamanı gelmiştir. Bu, oluşturulan lstm modelinde basit tahmin işlevi kullanılarak gerçekleştirilir.
#LSTM Tahmini
y_pred= lstm.predict(X_test)
Adım 12 – Doğru ve Öngörülen Adj Kapanış Değeri – LSTM
Son olarak, test setinin değerlerini tahmin ettiğimiz gibi, hem Adj Close'un gerçek değerlerini hem de Adj Close'un LSTM Machine Learning modeli tarafından tahmin edilen değerini karşılaştırmak için grafiği çizebiliriz.
#True ve Öngörülen Adj Kapanış Değeri – LSTM
plt.plot(y_test, label='Gerçek Değer')
plt.plot(y_pred, label='LSTM Değeri')
plt.title(“LSTM ile Tahmin”)
plt.xlabel('Zaman Ölçeği')
plt.ylabel('Ölçekli USD')
plt.legend()
plt.göster()
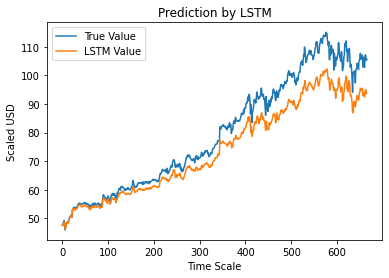
Yukarıdaki grafik, yukarıda oluşturulmuş çok temel tek LSTM ağ modeli tarafından bazı modellerin algılandığını göstermektedir. Birkaç parametreye ince ayar yaparak ve modele daha fazla LSTM katmanı ekleyerek, herhangi bir şirketin hisse senedi değerinin daha doğru bir temsilini elde edebiliriz.
Çözüm
Yapay zeka örnekleri, makine öğrenimi hakkında daha fazla bilgi edinmek istiyorsanız, IIIT-B & upGrad'ın çalışan profesyoneller için tasarlanmış ve 450+ saatlik zorlu eğitim, 30'dan fazla vaka çalışması sunan Makine Öğrenimi ve Yapay Zeka alanında Yönetici PG Programına göz atın. & ödevler, IIIT-B Mezun statüsü, 5'ten fazla pratik uygulamalı bitirme projesi ve en iyi firmalarla iş yardımı.
Makine öğrenimini kullanarak borsayı tahmin edebilir misiniz?
Bugün, piyasa eğilimlerini tahmin etmeye yardımcı olacak bir dizi göstergemiz var. Ancak borsa için en doğru göstergeleri bulmak için yüksek güçlü bir bilgisayardan başka bir yere bakmamıza gerek yok. Borsa açık bir sistemdir ve karmaşık bir ağ olarak görülebilir. Ağ, hisse senetleri, şirketler, yatırımcılar ve ticaret hacimleri arasındaki ilişkilerden oluşur. Destek vektör makinesi gibi bir veri madenciliği algoritması kullanarak, bu değişkenler arasındaki ilişkileri çıkarmak için bir matematiksel formül uygulayabilirsiniz. Borsa artık insan öngörülerinin ötesinde.
Borsa tahmini için en iyi algoritma hangisidir?
En iyi sonuçlar için Linear Regresyon kullanmalısınız. Doğrusal Regresyon, iki farklı değişken arasındaki ilişkiyi belirlemek için kullanılan istatistiksel bir yaklaşımdır. Bu örnekte, değişkenler fiyat ve zamandır. Borsa tahmininde fiyat bağımsız değişken, zaman ise bağımlı değişkendir. Bu iki değişken arasında doğrusal bir ilişki belirlenebilirse, gelecekte herhangi bir noktada hisse senedinin değerini doğru bir şekilde tahmin etmek mümkündür.
Borsa tahmini bir sınıflandırma mı yoksa regresyon sorunu mu?
Cevap vermeden önce borsa tahminlerinin ne anlama geldiğini anlamamız gerekiyor. İkili bir sınıflandırma problemi mi yoksa bir regresyon problemi mi? Bir hisse senedinin geleceğini tahmin etmek istediğimizi varsayalım, gelecek gün, hafta, ay veya yıl anlamına gelir. Hisse senedinin bir zaman noktasındaki geçmiş performansı girdiyse ve gelecek çıktıysa, bu bir regresyon problemidir. Bir hisse senedinin geçmiş performansı ve bir hisse senedinin geleceği bağımsız ise, bu bir sınıflandırma problemidir.