
AWS S3 Üzerinden Birden Çok Sunucu Arasında Veri Paylaşımı
Yayınlanan: 2022-03-10Kullanıcı tarafından yüklenen bir dosyanın işlenmesi için bazı işlevler sağlanırken, dosyanın yürütme boyunca süreç için erişilebilir olması gerekir. Basit bir yükleme ve kaydetme işlemi sorun yaratmaz. Ancak, ek olarak, dosya kaydedilmeden önce manipüle edilmesi gerekiyorsa ve uygulama bir yük dengeleyicinin arkasındaki birkaç sunucuda çalışıyorsa, dosyanın her seferinde işlemi hangi sunucuda çalıştırıyorsa o sunucuda kullanılabilir olduğundan emin olmamız gerekir.
Örneğin, çok adımlı bir "Kullanıcı avatarınızı yükleyin" işlevi, kullanıcının 1. adımda bir avatar yüklemesini, 2. adımda kırpmasını ve son olarak da 3. adımda kaydetmesini gerektirebilir. 1, dosya, 2. ve 3. adımlar için isteği hangi sunucu tarafından işlenirse işlesin, dosyanın erişilebilir olması gerekir; bu, 1. adım için aynı olabilir veya olmayabilir.
Naif bir yaklaşım, 1. adımda yüklenen dosyayı diğer tüm sunuculara kopyalamak olacaktır, böylece dosya hepsinde kullanılabilir olacaktır. Bununla birlikte, bu yaklaşım sadece son derece karmaşık değil, aynı zamanda uygulanabilir değildir: örneğin, site birkaç bölgeden yüzlerce sunucuda çalışıyorsa, bu gerçekleştirilemez.
Olası bir çözüm, belirli bir oturum için her zaman aynı sunucuyu atayacak olan yük dengeleyicide "yapışkan oturumları" etkinleştirmektir. Ardından, 1., 2. ve 3. adımlar aynı sunucu tarafından işlenecek ve 1. adımda bu sunucuya yüklenen dosya 2. ve 3. adımlar için hala orada olacaktır. Ancak, yapışkan oturumlar tam olarak güvenilir değildir: 1. adımlar arasındaysa. ve 2 bu sunucu çöktü, ardından yük dengeleyicinin farklı bir sunucu ataması gerekecek, bu da işlevselliği ve kullanıcı deneyimini bozacaktır. Benzer şekilde, bir oturum için her zaman aynı sunucunun atanması, özel durumlarda, aşırı yüklenmiş bir sunucudan daha yavaş yanıt sürelerine neden olabilir.
Daha uygun bir çözüm, dosyanın bir kopyasını tüm sunucuların erişebileceği bir havuzda tutmaktır. Ardından, dosya 1. adımda sunucuya yüklendikten sonra, bu sunucu dosyayı depoya yükleyecektir (veya alternatif olarak dosya sunucuyu atlayarak doğrudan istemciden depoya yüklenebilir); sunucu işleme adımı 2, dosyayı depodan indirecek, değiştirecek ve oraya tekrar yükleyecektir; ve son olarak, sunucu işleme adımı 3, onu depodan indirecek ve kaydedecektir.
Bu makalede, AWS SDK üzerinden çalışan Amazon Web Services (AWS) Simple Storage Service (S3) (veri depolamak ve almak için bir bulut nesnesi depolama çözümü) üzerinde dosya depolayan bir WordPress uygulamasına dayanan bu ikinci çözümü anlatacağım.
Not 1: Avatarları kırpmak gibi basit bir işlev için, başka bir çözüm, sunucuyu tamamen atlamak ve onu Lambda işlevleri aracılığıyla doğrudan bulutta uygulamak olabilir. Ancak bu yazı sunucuda çalışan bir uygulamayı AWS S3 ile bağlamakla ilgili olduğu için bu çözümü düşünmüyoruz.
Not 2: AWS S3'ü (veya AWS hizmetlerinden herhangi birini) kullanmak için bir kullanıcı hesabımız olması gerekir. Amazon, hizmetlerini denemek için yeterince iyi olan 1 yıllık ücretsiz bir katman sunuyor.
Not 3: WordPress'ten S3'e dosya yüklemek için 3. taraf eklentiler vardır. Bu tür bir eklenti, harika bir özellik sağlayan WP Media Offload'dır (lite sürümü burada mevcuttur): Medya Kitaplığına yüklenen dosyaları sorunsuz bir şekilde bir S3 kovasına aktarır ve bu, sitenin içeriğini ayırmaya izin verir (her şey gibi). /wp-content/uploads) uygulama kodundan. İçeriği ve kodu ayırarak, WordPress uygulamamızı Git kullanarak dağıtabiliriz (aksi takdirde kullanıcı tarafından yüklenen içerik Git deposunda barındırılmadığından yapamayız) ve uygulamayı birden fazla sunucuda barındırabiliriz (aksi takdirde, her sunucunun saklaması gerekir). kullanıcı tarafından yüklenen tüm içeriğin bir kopyası.)
Kovayı Oluşturma
Kovayı oluştururken, kova adını dikkate almamız gerekir: Her bir kova adı, AWS ağında global olarak benzersiz olmalıdır, bu nedenle kovamıza "avatarlar" gibi basit bir şey demek istesek bile, bu ad zaten alınmış olabilir. , sonra "şirketimin-adı-avatarları" gibi daha belirgin bir şey seçebiliriz.
Ayrıca paketin bulunduğu bölgeyi de seçmemiz gerekecek (bölge, dünyanın her yerindeki konumlarla birlikte veri merkezinin bulunduğu fiziksel konumdur.)
İşlem yürütme sırasında S3'e erişimin hızlı olması için bölge, uygulamamızın dağıtıldığı bölgeyle aynı olmalıdır. Aksi takdirde, kullanıcının uzak bir yere/bir yerden bir görüntü yüklemesi/indirmesi için fazladan saniye beklemesi gerekebilir.
Not: S3'ü bulut nesnesi depolama çözümü olarak kullanmak, yalnızca uygulamayı çalıştırmak için Amazon'un buluttaki sanal sunucular için hizmeti olan EC2'yi de kullanırsak mantıklıdır. Bunun yerine, uygulamayı barındırmak için Microsoft Azure veya DigitalOcean gibi başka bir şirkete güveniyorsak, o zaman onların bulut nesne depolama hizmetlerini de kullanmalıyız. Aksi takdirde, sitemiz farklı şirketlerin ağları arasında dolaşan verilerden dolayı ek yüke maruz kalacaktır.
Aşağıdaki ekran görüntülerinde, kırpma için kullanıcı avatarlarının yükleneceği kovanın nasıl oluşturulacağını göreceğiz. Önce S3 panosuna gidiyoruz ve "Kepçe oluştur" u tıklıyoruz:
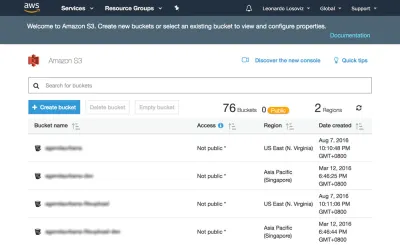
Ardından kova adını yazıyoruz (bu durumda “avatarları parçalayan”) ve bölgeyi seçiyoruz (“AB (Frankfurt)”):
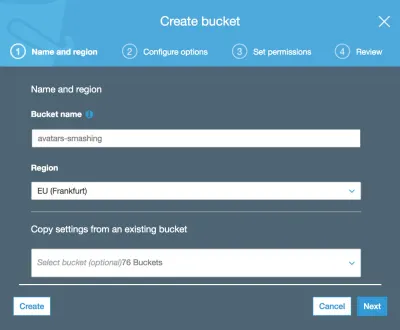
Yalnızca paket adı ve bölge zorunludur. Aşağıdaki adımlar için varsayılan seçenekleri tutabiliriz, bu nedenle son olarak “Kepçe oluştur” seçeneğine tıklayana kadar “İleri” ye tıklıyoruz ve bununla birlikte kovayı oluşturmuş olacağız.
Kullanıcı İzinlerini Ayarlama
AWS'ye SDK aracılığıyla bağlanırken, istenen hizmetlere ve nesnelere erişimimiz olduğunu doğrulamak için kullanıcı kimlik bilgilerimizi (bir çift erişim anahtarı kimliği ve gizli erişim anahtarı) girmemiz gerekecektir. Kullanıcı izinleri çok genel ("yönetici" rolü her şeyi yapabilir) veya çok ayrıntılı olabilir, yalnızca gereken belirli işlemlere izin verir ve başka bir şey yapmaz.
Genel bir kural olarak, verilen izinlerimiz ne kadar spesifik olursa, güvenlik sorunlarından kaçınmak için o kadar iyidir . Yeni kullanıcıyı oluştururken, kullanıcıya verilecek izinleri listeleyen basit bir JSON belgesi olan bir politika oluşturmamız gerekecek. Bizim durumumuzda, kullanıcı izinlerimiz “avatar-smashing” kovası için, “Put” (bir nesneyi yüklemek için), “Get” (bir nesneyi indirmek için) ve “Liste” işlemleri için S3'e erişim verecektir ( kovadaki tüm nesneleri listelemek için), aşağıdaki politikayla sonuçlanır:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:Put*", "s3:Get*", "s3:List*" ], "Resource": [ "arn:aws:s3:::avatars-smashing", "arn:aws:s3:::avatars-smashing/*" ] } ] }Aşağıdaki ekran görüntülerinde kullanıcı izinlerinin nasıl ekleneceğini görebiliriz. Kimlik ve Erişim Yönetimi (IAM) panosuna gitmeliyiz:
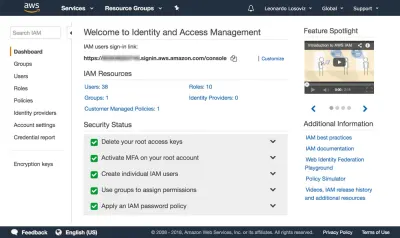
Kontrol panelinde “Kullanıcılar”a ve hemen ardından “Kullanıcı Ekle”ye tıklıyoruz. Kullanıcı Ekle sayfasında, bir kullanıcı adı ("kırpma-avatarlar") seçiyoruz ve Erişim türü olarak, SDK üzerinden bağlanmak için erişim anahtarı kimliğini ve gizli erişim anahtarını sağlayacak olan "Programatik erişim"i işaretliyoruz:
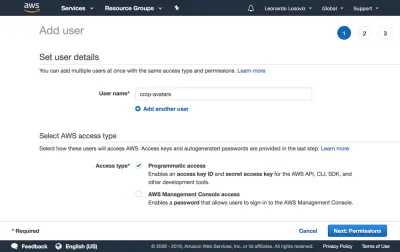
Ardından “İleri: İzinler” butonuna tıklıyoruz, “Mevcut politikaları doğrudan ekle” seçeneğine tıklıyoruz ve “Politika oluştur” seçeneğine tıklıyoruz. Bu, tarayıcıda İlke oluştur sayfasıyla yeni bir sekme açar. JSON sekmesine tıklıyoruz ve yukarıda tanımlanan politika için JSON kodunu giriyoruz:
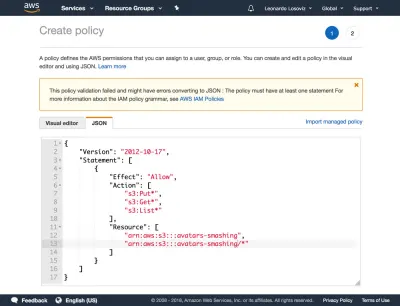
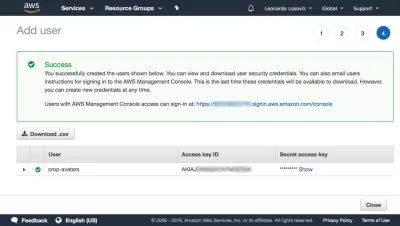
Ardından Politikayı gözden geçir'e tıklıyoruz, ona bir ad veriyoruz (“KırpAvatarlar”) ve son olarak Politika oluştur'a tıklıyoruz. Politikayı oluşturduktan sonra bir önceki sekmeye dönüyoruz, CropAvatars politikasını seçiyoruz (bunu görmek için politika listesini yenilememiz gerekebilir), İleri: Gözden Geçir'e ve son olarak Kullanıcı oluştur'a tıklayın. Bu yapıldıktan sonra, nihayet erişim anahtarı kimliğini ve gizli erişim anahtarını indirebiliriz (lütfen bu kimlik bilgilerinin bu benzersiz an için mevcut olduğunu unutmayın; bunları şimdi kopyalamaz veya indirmezsek, yeni bir çift oluşturmamız gerekecek ):

SDK Üzerinden AWS'ye Bağlanma
SDK, sayısız dil aracılığıyla kullanılabilir. Bir WordPress uygulaması için, buradan indirilebilen PHP için SDK'ya ihtiyacımız var ve nasıl kurulacağına dair talimatlar burada.
Paket oluşturulduktan, kullanıcı kimlik bilgileri hazırlandıktan ve SDK yüklendikten sonra dosyaları S3'e yüklemeye başlayabiliriz.
Dosyaları Yükleme ve İndirme
Kolaylık sağlamak için, wp-config.php dosyasında kullanıcı kimlik bilgilerini ve bölgeyi sabitler olarak tanımlarız:
define ('AWS_ACCESS_KEY_ID', '...'); // Your access key id define ('AWS_SECRET_ACCESS_KEY', '...'); // Your secret access key define ('AWS_REGION', 'eu-central-1'); // Region where the bucket is located. This is the region id for "EU (Frankfurt)" Bizim durumumuzda, avatarların "avatarları parçalayan" kovada saklanacağı kırpma avatarı işlevini uyguluyoruz. Bununla birlikte, uygulamamızda, aynı dosya yükleme, indirme ve listeleme işlemlerini gerçekleştirmeyi gerektiren diğer işlevler için birkaç başka kovamız olabilir. Bu nedenle, ortak yöntemleri AWS_S3 soyut bir sınıf üzerinde uygularız ve uygulama alt sınıflarında get_bucket işlevi aracılığıyla tanımlanan kova adı gibi girdileri elde ederiz.
// Load the SDK and import the AWS objects require 'vendor/autoload.php'; use Aws\S3\S3Client; use Aws\Exception\AwsException; // Definition of an abstract class abstract class AWS_S3 { protected function get_bucket() { // The bucket name will be implemented by the child class return ''; } } S3Client sınıfı, S3 ile etkileşim için API'yi sunar. Bunu yalnızca gerektiğinde (tembel başlatma yoluyla) başlatırız ve aynı örneği kullanmaya devam etmek için $this->s3Client altına bir başvuru kaydederiz:
abstract class AWS_S3 { // Continued from above... protected $s3Client; protected function get_s3_client() { // Lazy initialization if (!$this->s3Client) { // Create an S3Client. Provide the credentials and region as defined through constants in wp-config.php $this->s3Client = new S3Client([ 'version' => '2006-03-01', 'region' => AWS_REGION, 'credentials' => [ 'key' => AWS_ACCESS_KEY_ID, 'secret' => AWS_SECRET_ACCESS_KEY, ], ]); } return $this->s3Client; } } Uygulamamızda $file ile uğraşırken, bu değişken diskteki dosyanın mutlak yolunu içerir (örneğin /var/app/current/wp-content/uploads/users/654/leo.jpg ), ancak dosyayı yüklerken Dosyayı S3'e kaydedersek, nesneyi aynı yol altında saklamamalıyız. Özellikle, güvenlik nedenleriyle sistem bilgileriyle ilgili ilk biti ( /var/app/current ) kaldırmalıyız ve isteğe bağlı olarak /wp-content bitini kaldırabiliriz (tüm dosyalar bu klasör altında saklandığından, bu gereksiz bir bilgidir. ), yalnızca dosyanın göreli yolunu koruyarak ( /uploads/users/654/leo.jpg ). Uygun bir şekilde, bu, WP_CONTENT_DIR sonraki her şeyi mutlak yoldan kaldırarak başarılabilir. Aşağıdaki get_file ve get_file_relative_path işlevleri, mutlak ve göreli dosya yolları arasında geçiş yapar:
abstract class AWS_S3 { // Continued from above... function get_file_relative_path($file) { return substr($file, strlen(WP_CONTENT_DIR)); } function get_file($file_relative_path) { return WP_CONTENT_DIR.$file_relative_path; } }S3'e bir nesne yüklerken, erişim kontrol listesi (ACL) izinleri aracılığıyla yapılan, nesneye kimlerin erişim izni verildiğini ve erişim türünü belirleyebiliriz. En yaygın seçenekler, dosyayı gizli tutmak (ACL => “özel”) ve internette okumak için erişilebilir kılmaktır (ACL => “genel okuma”). Dosyayı kullanıcıya göstermek için doğrudan S3'ten talep etmemiz gerekeceğinden, ACL => “public-read”e ihtiyacımız var:
abstract class AWS_S3 { // Continued from above... protected function get_acl() { return 'public-read'; } }Son olarak, bir nesneyi S3 kovasına yüklemek ve buradan bir nesne indirmek için yöntemleri uygularız:
abstract class AWS_S3 { // Continued from above... function upload($file) { $s3Client = $this->get_s3_client(); // Upload a file object to S3 $s3Client->putObject([ 'ACL' => $this->get_acl(), 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SourceFile' => $file, ]); } function download($file) { $s3Client = $this->get_s3_client(); // Download a file object from S3 $s3Client->getObject([ 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SaveAs' => $file, ]); } }Ardından, uygulama alt sınıfında kovanın adını tanımlarız:
class AvatarCropper_AWS_S3 extends AWS_S3 { protected function get_bucket() { return 'avatars-smashing'; } } Son olarak, avatarları S3'e yüklemek veya S3'ten indirmek için sınıfı somutlaştırıyoruz. Ek olarak, 1'den 2'ye ve 2'den 3'e kadar olan adımlardan geçiş yaparken, $file değerini iletmemiz gerekir. Bunu, bir POST işlemi aracılığıyla $file file'ın göreli yolunun değeriyle bir “file_relative_path” alanı göndererek yapabiliriz (güvenlik nedeniyle mutlak yolu geçmiyoruz: “/var/www/current” i eklemeye gerek yok ” dışarıdakilerin görmesi için bilgiler):
// Step 1: after the file was uploaded to the server, upload it to S3. Here, $file is known $avatarcropper = new AvatarCropper_AWS_S3(); $avatarcropper->upload($file); // Get the file path, and send it to the next step in the POST $file_relative_path = $avatarcropper->get_file_relative_path($file); // ... // -------------------------------------------------- // Step 2: get the $file from the request and download it, manipulate it, and upload it again $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_POST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Do manipulation of the file // ... // Upload the file again to S3 $avatarcropper->upload($file); // -------------------------------------------------- // Step 3: get the $file from the request and download it, and then save it $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_REQUEST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Save it, whatever that means // ...Dosyayı Doğrudan S3'ten Görüntüleme
Adım 2'deki manipülasyondan sonra dosyanın ara durumunu görüntülemek istiyorsak (örneğin, kırpıldıktan sonra kullanıcı avatarı), o zaman dosyaya doğrudan S3'ten başvurmalıyız; URL, sunucudaki dosyayı gösteremedi çünkü bir kez daha, hangi sunucunun bu isteği yerine getireceğini bilmiyoruz.
Aşağıda, S3'te o dosyanın URL'sini alan get_file_url($file) işlevini ekliyoruz. Bu işlevi kullanıyorsanız, lütfen yüklenen dosyaların ACL'sinin "herkese açık" olduğundan emin olun, aksi takdirde kullanıcı bunlara erişemez.
abstract class AWS_S3 { // Continue from above... protected function get_bucket_url() { $region = $this->get_region(); // North Virginia region is simply "s3", the others require the region explicitly $prefix = $region == 'us-east-1' ? 's3' : 's3-'.$region; // Use the same scheme as the current request $scheme = is_ssl() ? 'https' : 'http'; // Using the bucket name in path scheme return $scheme.'://'.$prefix.'.amazonaws.com/'.$this->get_bucket(); } function get_file_url($file) { return $this->get_bucket_url().$this->get_file_relative_path($file); } }Ardından, S3'teki dosyanın URL'sini alabilir ve resmi yazdırabiliriz:
printf( "<img src='%s'>", $avatarcropper->get_file_url($file) );Dosyaları Listeleme
Uygulamamızda, kullanıcının önceden yüklenmiş tüm avatarları görüntülemesine izin vermek istiyorsak, bunu yapabiliriz. Bunun için, belirli bir yol altında depolanan tüm dosyaların URL'sini listeleyen get_file_urls işlevini tanıtıyoruz (S3 terimlerinde buna önek denir):
abstract class AWS_S3 { // Continue from above... function get_file_urls($prefix) { $s3Client = $this->get_s3_client(); $result = $s3Client->listObjects(array( 'Bucket' => $this->get_bucket(), 'Prefix' => $prefix )); $file_urls = array(); if(isset($result['Contents']) && count($result['Contents']) > 0 ) { foreach ($result['Contents'] as $obj) { // Check that Key is a full file path and not just a "directory" if ($obj['Key'] != $prefix) { $file_urls[] = $this->get_bucket_url().$obj['Key']; } } } return $file_urls; } }Ardından, her avatarı "/users/${user_id}/" yolu altında saklıyorsak, bu öneki geçerek tüm dosyaların listesini elde edeceğiz:
$user_id = get_current_user_id(); $prefix = "/users/${user_id}/"; foreach ($avatarcropper->get_file_urls($prefix) as $file_url) { printf( "<img src='%s'>", $file_url ); }Çözüm
Bu makalede, birden çok sunucuya dağıtılan bir uygulama için dosyaları depolamak üzere ortak bir havuz görevi görecek bir bulut nesnesi depolama çözümünün nasıl kullanılacağını araştırdık. Çözüm için AWS S3'e odaklandık ve uygulamaya entegre edilmesi gereken adımları göstermeye başladık: kova oluşturma, kullanıcı izinlerini ayarlama ve SDK'yı indirme ve yükleme. Son olarak, uygulamadaki güvenlik tuzaklarından nasıl kaçınılacağını açıkladık ve S3'te en temel işlemlerin nasıl gerçekleştirileceğini gösteren kod örnekleri gördük: her biri yalnızca birkaç satır kod gerektiren dosyaları karşıya yükleme, indirme ve listeleme. Çözümün basitliği, bulut hizmetlerini uygulamaya entegre etmenin zor olmadığını ve bulut konusunda fazla deneyimli olmayan geliştiriciler tarafından da yapılabileceğini gösteriyor.