
UX Tasarımcıları için Nicel Veri Araçları
Yayınlanan: 2022-03-10Birçok UX tasarımcısı, derin istatistik ve matematik bilgisi gerektirdiğine inanarak verilerden biraz korkar. Bu, gelişmiş veri bilimi için doğru olsa da, çoğu UX tasarımcısının ihtiyaç duyduğu temel araştırma veri analizi için doğru değildir. Giderek daha fazla veri odaklı bir dünyada yaşadığımızdan, temel veri okuryazarlığı, yalnızca UX tasarımcıları için değil, neredeyse tüm profesyoneller için yararlıdır.
Google'da etkileşim tasarımcısı Aaron Gitlin, birçok tasarımcının henüz veri odaklı olmadığını savunuyor:
"Birçok işletme kendilerini veri odaklı olarak tanıtırken, çoğu tasarımcı içgüdü, işbirliği ve nitel araştırma yöntemleriyle hareket ediyor."
— Aaron Gitlin, “Veriye Duyarlı Bir Tasarımcı Olmak”
Bu makaleyle, UX tasarımcılarına verileri günlük rutinlerine dahil edecek bilgi ve araçları vermek istiyorum.
Ama Önce, Bazı Veri Kavramları
Bu yazıda, satırlar ve sütunlar ile bir tabloda temsil edilebilecek veriler anlamına gelen yapılandırılmış verilerden bahsedeceğim. Kendi içinde bir konu olan yapılandırılmamış verileri analiz etmek daha zordur, çünkü Devin Pickell (G2 Crowd'da içerik pazarlama uzmanı, veri ve analitik hakkında yazıyor) “Yapılandırılmış ve Yapılandırılmamış Veri – Fark Nedir?” makalesinde işaret etti. Yapılandırılmış veriler bir tablo biçiminde gösterilebiliyorsa, ana kavramlar şunlardır:
veri kümesi
Analiz etmeyi düşündüğümüz tüm veri seti. Bu, örneğin bir Excel tablosu olabilir. Veri kümelerini depolamak için bir başka popüler format, virgülle ayrılmış değer dosyasıdır (CSV). CSV dosyaları, tablo benzeri bilgileri depolamak için kullanılan basit metin dosyalarıdır. Her CSV satırı, tablodaki bir satıra karşılık gelir ve her CSV satırı, tablo hücrelerine karşılık gelen virgülle (doğal olarak) ayrılmış değerlere sahiptir.
Veri noktası
Bir veri kümesi tablosundaki tek bir satır, bir veri noktasıdır. Bu şekilde, bir veri kümesi bir veri noktaları topluluğudur.
Veri Değişkeni
Bir veri noktası satırındaki tek bir değer, bir veri değişkenini temsil eder - basitçe söylemek gerekirse, bir tablo hücresi. İki tür veri değişkenimiz olabilir: nitel değişkenler ve nicel değişkenler. Niteliksel değişkenler (kategorik değişkenler olarak da bilinir), color = red/green/blue gibi ayrı bir değerler kümesine sahiptir. Nicel değişkenler, height = 167 gibi sayısal değerlere sahiptir. Nicel değişken, nitel değişkenden farklı olarak herhangi bir değer alabilir.
Veri Projemizi Oluşturma
Artık temelleri biliyoruz, ellerimizi kirletme ve ilk veri projemizi yaratma zamanı. Projenin kapsamı, verilerin içe aktarılması, işlenmesi ve çizilmesinden oluşan tüm veri akışından geçerek bir veri kümesini analiz etmektir. İlk önce veri setimizi seçeceğiz, ardından verileri analiz etmek için araçları indirip kuracağız.
Otomobil Veri Kümesi
Bu makalenin amacı için, basit ve sezgisel olduğu için bir araba veri seti seçtim. Veri analizi, arabalar hakkında zaten bildiklerimizi doğrulayacak - ki bu, veri akışına ve araçlara odaklandığımız için sorun değil.
En büyük ücretsiz veri kümelerinden biri olan Kaggle'dan kullanılmış araba veri kümesi indirebiliriz. Önce kayıt olmanız gerekecek.
Dosyayı indirdikten sonra açın ve bir göz atın. Bu gerçekten büyük bir CSV dosyası, ancak ana fikri anlamalısınız. Bu dosyadaki bir satır şöyle görünecektir:
19500,2015,2965,Miami,FL,WBA3B1G54FNT02351,BMW,3Gördüğünüz gibi, bu veri noktası virgülle ayrılmış birkaç değişkene sahiptir. Artık veri setimiz olduğuna göre, biraz araçlardan bahsedelim.
Ticaret Araçları
Veri setini analiz etmek için R dilini ve RStudio'yu kullanacağız. R, sadece veri bilimcileri tarafından değil, aynı zamanda finans piyasalarında, tıpta ve diğer birçok alanda insanlar tarafından kullanılan çok popüler ve öğrenmesi kolay bir dildir. RStudio, R projelerinin geliştirildiği ortamdır ve UX tasarımcıları olarak ihtiyaçlarımızı fazlasıyla karşılayan ücretsiz bir sürümü vardır.
Bazı UX tasarımcılarının veri iş akışları için Excel kullanması muhtemeldir. Bu sizin için uygunsa, R'yi deneyin - öğrenmesi kolay ve Excel'den daha esnek ve güçlü olduğu için büyük bir ihtimalle beğeneceksiniz. Araç kitinize R eklemek bir fark yaratacaktır.
Araçları Yükleme
Öncelikle R ve RStudio'yu indirip kurmamız gerekiyor. Önce R'yi, ardından RStudio'yu kurmalısınız. Hem R hem de RStudio için kurulum işlemleri basit ve anlaşılırdır.
Proje Kurulumu
Kurulum tamamlandıktan sonra bir proje klasörü oluşturun - buna kullanılmış-cars-prj adını verdim . Bu klasörde data adlı bir alt klasör oluşturun ve ardından veri kümesi dosyasını (Kaggle'dan indirilen) bu klasöre kopyalayın ve bunu kullanılmış-cars.csv olarak yeniden adlandırın. Şimdi proje klasörümüze geri dönün ( kullanılmış-cars-prj ) ve kullanılmış-cars.r adında bir düz metin dosyası oluşturun. Aşağıdaki ekran görüntüsündekiyle aynı yapıya sahip olmalısınız.
Artık klasör yapısını yerine getirdik, RStudio'yu açıp yeni bir R projesi oluşturabiliriz. Dosya menüsünden Yeni Proje… 'yi seçin ve ikinci seçenek olan Mevcut Dizin'i seçin. Ardından proje dizinini seçin ( kullanılmış-cars-prj ). Son olarak, Proje Oluştur düğmesine basın ve bitirdiniz. Proje oluşturulduktan sonra, RStudio'da kullanılmış-cars.r'yi açın - bu, tüm R kodlarımızı ekleyeceğimiz dosyadır.
Verileri İçe Aktarma
Kullanılmış-cars.csv dosyasındaki verileri okumak için ikinci satırımızı kullanılmış -cars.r dosyasına ekleyeceğiz. CSV dosyalarının yalnızca veri depolamak için kullanılan düz metin dosyaları olduğunu unutmayın. İlk R kodu satırımız şöyle görünecek:
cars <- read.csv("./data/used-cars.csv", stringsAsFactors = FALSE, sep=",") Biraz ürkütücü görünebilir, ama gerçekten değil - bu arada, bu, tüm makaledeki en karmaşık satırdır. Burada sahip olduğumuz şey, üç parametre alan read.csv işlevidir.
İlk parametre, veri klasöründe bulunan, bizim durumumuzda kullanılmış-cars.csv , okunacak dosyadır. İkinci parametre, stringsAsFactors=FALSE , "BMW" veya "Audi" gibi dizelerin faktörlere dönüştürülmemesini sağlamak için ayarlanmıştır (kategorik veriler için R jargonu) - hatırladığınız gibi, nitel veya kategorik değişkenler yalnızca aşağıdaki gibi ayrık değerlere sahip olabilir: red/green/blue . Son olarak, üçüncü parametre olan sep="," CSV dosyasındaki değerleri ayırmak için kullanılan ayırıcı türünü belirtir: virgül.
CSV dosyasını okuduktan sonra, veriler cars veri çerçevesi nesnesine kaydedilir. Veri çerçevesi , verileri işlemek için R'de çok yararlı olan iki boyutlu bir veri yapısıdır (bir Excel tablosu gibi). Hattı tanıtıp çalıştırdıktan sonra sizin için bir cars veri çerçevesi oluşturulacaktır. RStudio'da sağ üst çeyreğe bakarsanız, Ortam sekmesinin altındaki Veri bölümünde cars veri çerçevesini fark edeceksiniz. Arabalara çift tıklarsanız, RStudio'nun sol üst çeyreğinde yeni bir sekme açılır ve cars veri çerçevesini sunar. Tahmin edebileceğiniz gibi, bir Excel tablosuna benziyor.
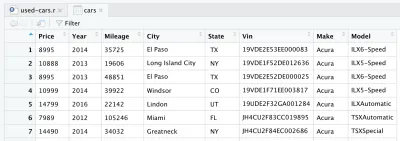
Bu aslında Kaggle'dan indirdiğimiz ham veriler. Fakat veri analizi yapmak istediğimiz için öncelikle veri setimizi işlememiz gerekiyor.
Veri işleme
İşleme ile, gerçekleştirmek istediğimiz analiz türüne hazırlanmak için veri kümemize bilgi eklemeyi, dönüştürmeyi veya çıkarmayı kastediyoruz. Veriler bir veri çerçevesi nesnesinde var, bu yüzden şimdi verileri işlemek için güçlü bir kitaplık olan dplyr kitaplığını kurmamız gerekiyor. Kütüphaneyi R ortamımıza kurmak için R dosyamızın en üstüne aşağıdaki satırı yazmamız gerekiyor.
install.packages("dplyr")Ardından, mevcut projemize kütüphaneyi eklemek için sonraki satırı kullanacağız:
library(dplyr) dplyr kitaplığı projemize eklendikten sonra veri işlemeye başlayabiliriz. Gerçekten büyük bir veri kümemiz var ve bunu fiyatla ilişkilendirmek için yalnızca aynı otomobil üreticisini ve modelini temsil eden verilere ihtiyacımız var. Yalnızca BMW 3 Serisi ile ilgili verileri tutmak için aşağıdaki R kodunu kullanacağız ve gerisini kaldıracağız. Elbette, veri kümesinden başka bir üretici ve model seçebilir ve aynı veri özelliklerine sahip olmayı bekleyebilirsiniz.
cars <- cars %>% filter(Make == "BMW", Model == "3")Artık 11.000'den fazla veri noktası içermesine rağmen daha yönetilebilir bir veri setimiz var ve bu bizim amaçlanan amacımıza uyuyor: arabaların fiyatını, yaşını ve kilometre dağılımlarını ve ayrıca bunlar arasındaki korelasyonları analiz etmek. Bunun için sadece "Fiyat", "Yıl" ve "Kilometre" sütunlarını tutmamız ve gerisini kaldırmamız gerekiyor - bu, aşağıdaki satırla yapılır.
cars <- cars %>% select(Price, Year, Mileage)Diğer sütunları çıkardıktan sonra veri çerçevemiz şöyle görünecektir:

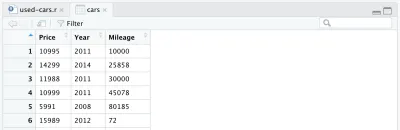
Veri kümemizde yapmak istediğimiz bir değişiklik daha var: üretim yılını otomobilin yaşıyla değiştirmek. Aşağıdaki iki satırı ekleyebiliriz, ilki yaşı hesaplamak için, ikincisi sütun adını değiştirmek için.
cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Son olarak, tam işlenmiş veri çerçevemiz şöyle görünür:
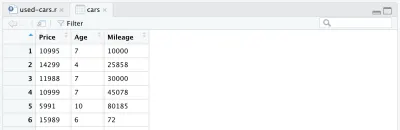
Bu noktada, R kodumuz aşağıdaki gibi görünecek ve hepsi veri işleme için. Artık R dilinin ne kadar kolay ve güçlü olduğunu görebiliriz. İlk veri kümesini yalnızca birkaç satır kodla oldukça çarpıcı biçimde işledik.
install.packages("dplyr") library(dplyr) cars = read.csv("./data/cars.csv", stringsAsFactors = FALSE, sep=",") cars <- cars %>% filter(Make == "BMW", Model == "3") cars <- cars %>% select(Price, Year, Mileage) cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Veri analizi
Verilerimiz artık doğru durumda, bu yüzden bazı çizimler yapmaya gidebiliriz. Daha önce de belirtildiği gibi, iki yöne odaklanacağız: bireysel değişkenlerin dağılımı ve aralarındaki korelasyonlar. Değişken dağılım, kullanılmış bir araba için neyin orta veya yüksek fiyat olarak kabul edildiğini veya belirli bir fiyatın üzerindeki araba yüzdesini anlamamıza yardımcı olur. Aynısı araçların yaşı ve kilometresi için de geçerlidir. Öte yandan korelasyonlar, yaş ve kilometre gibi değişkenlerin birbirleriyle nasıl ilişkili olduğunu anlamada yardımcı olur.
Bununla birlikte, iki tür veri görselleştirme kullanacağız: değişken dağılım için histogramlar ve korelasyonlar için dağılım grafikleri.
Fiyat Dağılımı
Araba fiyatı histogramını R dilinde çizmek şu kadar kolay:
hist(cars$Price)Küçük bir ipucu: RStudio'daysanız, kodu satır satır çalıştırabilirsiniz; örneğin, bizim durumumuzda, histogramı görüntülemek için yalnızca yukarıdaki satırı çalıştırmanız gerekir. Zaten bir kez çalıştırdığınız için tüm kodu yeniden çalıştırmanız gerekmez. Histogram şöyle görünmelidir:
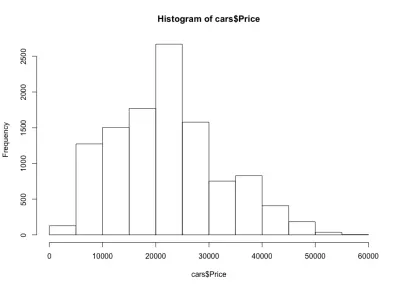
Histograma bakarsak, araba fiyatlarının beklediğimiz gibi çan benzeri bir dağılımını fark ederiz. Arabaların çoğu orta menzile düşüyor ve her iki tarafa geçtikçe daha az arabamız var. Arabaların neredeyse %80'i 10.000 ila 30.000 ABD Doları arasında ve 20.000 ila 25.000 ABD Doları arasında maksimum 2.500'den fazla arabamız var. Sol tarafta muhtemelen 5.000 USD'nin altında yaklaşık 150 arabamız var ve sağ tarafta daha da az. Bu tür grafiklerin verilere ilişkin içgörüler elde etmek için ne kadar yararlı olduğunu kolayca görebiliriz.
Yaş dağılımı
Arabaların fiyatlarında olduğu gibi, arabaların yaş histogramını çizmek için benzer bir çizgi kullanacağız.
hist(cars$Age)Ve işte histogram:
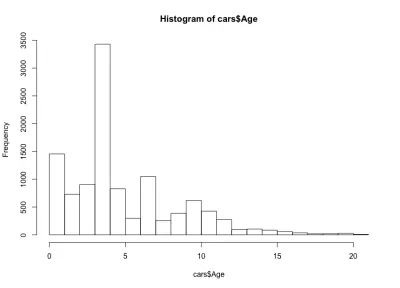
Bu sefer histogram mantıksız görünüyor - basit bir çan şekli yerine burada dört çan var. Temel olarak, dağılımın beklenmedik bir şekilde üç yerel ve bir küresel maksimumu vardır. Arabaların yaşlarının bu garip dağılımının başka bir araba üreticisi ve modeli için geçerli olup olmadığını görmek ilginç olurdu. Bu makalenin amacı doğrultusunda BMW 3 Serisi veri seti üzerinde kalacağız, ancak merak ediyorsanız verilerin daha derinlerine inebilirsiniz. Araba yaş dağılımımızla ilgili olarak, arabaların %90'ından fazlasının 10 yaşından küçük ve %80'den fazlasının 7 yaşından küçük olduğunu görüyoruz. Ayrıca, arabaların çoğunun 5 yaşından küçük olduğunu fark ediyoruz.
Kilometre Dağılımı
Şimdi, kilometre hakkında ne söyleyebiliriz? Tabii ki, fiyat için sahip olduğumuz aynı çan şekline sahip olmayı umuyoruz. İşte R kodu ve histogram:
hist(cars$Mileage) 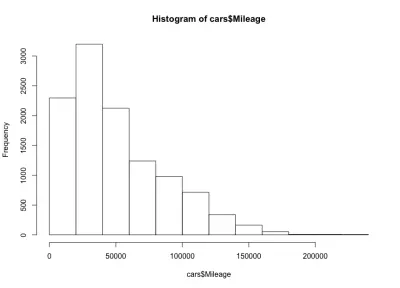
Burada sola eğik bir çan şeklimiz var, bu da piyasada daha az kilometre yapan daha fazla araba olduğu anlamına geliyor. Ayrıca, arabaların çoğunun 60.000 milden daha az olduğunu ve maksimum 20.000 ila 40.000 mil civarında olduğunu fark ettik.
Yaş-Fiyat Korelasyonu
Korelasyonlarla ilgili olarak, arabaların yaş-fiyat korelasyonuna daha yakından bakalım. Fiyatın yaşla negatif korelasyon göstermesini bekleyebiliriz - bir arabanın yaşı arttıkça fiyatı düşecektir. Fiyat-yaş korelasyonunu aşağıdaki gibi görüntülemek için R plot işlevini kullanacağız:
plot(cars$Age, cars$Price)Ve arsa şöyle görünüyor:
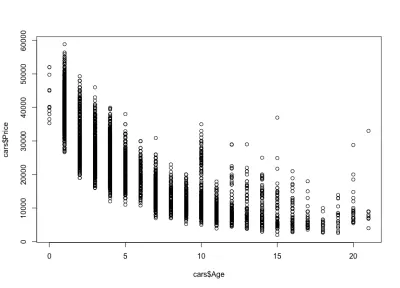
Araba fiyatlarının yaşla birlikte nasıl düştüğünü fark ediyoruz: pahalı yeni arabalar ve daha ucuz eski arabalar var. Ayrıca herhangi bir belirli yaş için fiyat değişim aralığını görebiliriz, bu bir arabanın yaşıyla birlikte azalan bir değişikliktir. Bu varyasyon büyük ölçüde aracın kilometresi, konfigürasyonu ve genel durumu tarafından yönlendirilir. Örneğin, 4 yaşında bir araba söz konusu olduğunda, fiyat 10.000 ila 40.000 ABD Doları arasında değişmektedir.
Kilometre-Yaş Korelasyonu
Kilometre-yaş korelasyonu göz önüne alındığında, kilometrenin yaşla birlikte artmasını bekleriz, bu da pozitif bir korelasyon anlamına gelir. İşte kod:
plot(cars$Mileage, cars$Age)Ve işte arsa:
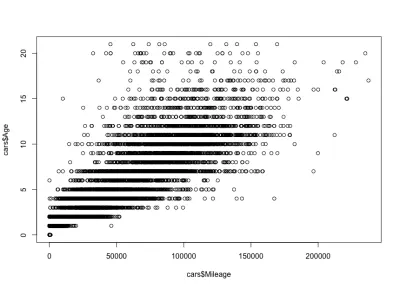
Gördüğünüz gibi, bir arabanın yaşı ve kilometresi, bir arabanın fiyatı ve yaşının aksine, negatif olarak ilişkili olan pozitif bir korelasyona sahiptir. Ayrıca belirli bir yaş için beklenen bir kilometre varyasyonumuz var; yani, aynı yaştaki arabaların değişen kilometreleri vardır. Örneğin, 4 yaşındaki arabaların çoğu 10.000 ila 80.000 mil arasında bir kilometreye sahiptir. Ancak daha fazla kilometre ile aykırı değerler de var.
Kilometre-Fiyat Korelasyonu
Beklendiği gibi, araçların kilometresi ile fiyatı arasında negatif bir ilişki olacaktır, bu da kilometrenin artmasının fiyatı düşürdüğü anlamına gelir.
plot(cars$Mileage, cars$Price)Ve işte arsa:
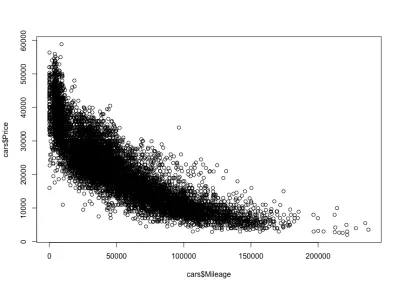
Beklediğimiz gibi, negatif bir korelasyon. Ayrıca brüt fiyat aralığını 3.000 ile 50.000 ABD Doları arasında ve kilometreyi 0 ile 150.000 ABD Doları arasında görebiliriz. Dağılım şekline daha yakından bakarsak, daha az kilometre yapan arabaların fiyatının, daha fazla kilometre yapan arabalara göre çok daha hızlı düştüğünü görürüz. Fiyatın önemli ölçüde düştüğü neredeyse sıfır kilometreli arabalar var. Ayrıca, 200.000 milin üzerinde - kilometre çok yüksek olduğu için - fiyat sabit kalır.
Sayılardan Veri Görselleştirmelerine
Bu makalede, iki tür görselleştirme kullandık: veri dağılımları için histogramlar ve veri bağıntıları için dağılım grafikleri. Histogramlar, bir veri değişkeninin (gerçek sayılar ) değerlerini alan ve bunların bir aralıkta nasıl dağıldığını gösteren görsel temsillerdir. Bir histogram çizmek için R hist() işlevini kullandık.
Dağılım grafikleri ise sayı çiftlerini alır ve onları iki eksende temsil eder. Dağılım grafikleri, plot() işlevini kullanır ve iki parametre sağlar: araştırmak istediğimiz korelasyonun birinci ve ikinci veri değişkenleri. Böylece, iki R işlevi, hist() ve plot() , anlamlı görsel temsillerde sayı kümelerini çevirmemize yardımcı olur.
Çözüm
Verileri içe aktarma, işleme ve çizmeye ilişkin tüm veri akışından geçerken ellerimizi kirlettikten sonra, işler şimdi çok daha net görünüyor. Aynı veri akışını, karşılaşacağınız herhangi bir parlak yeni veri kümesine uygulayabilirsiniz. Örneğin, kullanıcı araştırmasında, görev veya hata dağılımları üzerinde zaman grafiği oluşturabilir ve ayrıca göreve karşı hata korelasyonu üzerine bir zaman çizebilirsiniz.
R dili hakkında daha fazla bilgi edinmek için Quick-R başlamak için iyi bir yerdir, ancak R Blogger'ları da düşünebilirsiniz. dplyr gibi R paketleriyle ilgili belgeler için RDocumentation sayfasını ziyaret edebilirsiniz. Verilerle oynamak eğlenceli olabilir, ancak aynı zamanda veri odaklı bir dünyada herhangi bir UX tasarımcısı için son derece yararlıdır. İş kararlarını bildirmek için daha fazla veri toplanıp kullanıldıkça, tasarımcıların veri görselleştirmesi veya verinin doğasını anlamanın önemli olduğu veri ürünleri üzerinde çalışma şansı artar.