
2022 İçin 15 Makine Öğrenimi Mülakat Sorusu ve Yanıtı
Yayınlanan: 2021-01-08Makine Öğreniminde başarılı bir kariyer yapmak isteyen biri misiniz? Eğer öyleyse, sizin için harika!
Ancak önce, kendinizi buz kırıcı olan ML röportajına hazırlamanız gerekir.
Bir röportaja hazırlanma süreci bunaltıcı olabileceğinden, adım atmaya karar verdik - burada Makine Öğrenimi röportajlarında en sık sorulan 15 sorudan oluşan derlenmiş bir liste!
- Derin Öğrenme ile Makine Öğrenimi arasındaki fark nedir?
Makine Öğrenimi, verileri ayrıştırmak, verilerdeki gizli kalıpları ortaya çıkarmak ve ondan öğrenmek için gelişmiş algoritmaların uygulanmasını ve kullanılmasını içerir ve son olarak, bilinçli iş kararları vermek için öğrenilen içgörüleri uygular. Derin Öğrenmeye gelince, insan beyninin sinir ağı yapısından ilham alan Yapay Sinir Ağlarının kullanımını içeren Makine Öğreniminin bir alt kümesidir. Derin Öğrenme, özellik tespitinde yaygın olarak kullanılmaktadır.
- Tanımla – Hassasiyet ve Geri Çağırma.
Kesinlik veya Pozitif Öngörü Değeri ölçer veya daha kesin olarak, bir model tarafından iddia edilen gerçek pozitiflerin sayısını, gerçekte iddia ettiği pozitiflerin sayısına kıyasla tahmin eder.
Geri Çağırma veya Gerçek Pozitif Oranı, bir model tarafından talep edilen pozitiflerin sayısını, veriler boyunca mevcut pozitiflerin gerçek sayısına kıyasla ifade eder.

Kariyerinizi hızlandırmak için Makine Öğrenimi Kursuna , Makine Öğrenimi ve Yapay Zeka alanında Dünyanın en iyi Üniversiteleri - Yüksek Lisanslar, Yönetici Yüksek Lisans Programları ve İleri Düzey Sertifika Programından çevrimiçi katılın .
- 'Önyargı' ve 'varyans' terimlerini açıklayın. '
Eğitim süreci sırasında, bir öğrenme algoritmasının beklenen hatası genellikle iki kısma sınıflandırılır veya ayrıştırılır - önyargı ve varyans. Önyargı, öğrenme algoritmasında basit varsayımların kullanılmasından kaynaklanan bir hata durumu iken, varyans, veri analizinde o öğrenme algoritmasının karmaşıklığından kaynaklanan bir hatayı ifade eder. Bias, öğrenme algoritması tarafından oluşturulan ortalama sınıflandırıcının hedef fonksiyona yakınlığını ölçer ve varyans, farklı eğitim veri kümeleri için öğrenme algoritmasının tahmininin ne kadar değiştiğine göre ölçer.
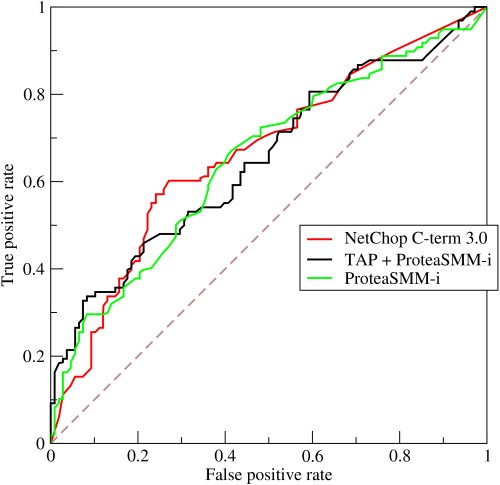
- ROC eğrisi nasıl çalışır?
ROC veya Alıcı Çalışma Karakteristiği eğrisi, değişen eşiklerde gerçek pozitif oranlar ile yanlış pozitif oranlar arasındaki değişimin grafiksel bir temsilidir. Teşhis testi değerlendirmesi için temel bir araçtır ve genellikle modelin duyarlılığı (gerçek pozitifler) ile yanlış alarmları tetikleme olasılığı (yanlış pozitifler) arasındaki dengenin bir temsili olarak kullanılır.
Kaynak
- Eğri, duyarlılık ve özgüllük arasındaki dengeyi gösterir - duyarlılık artarsa özgüllük azalacaktır.
- Eğri daha çok sol eksene ve ROC uzayının tepesine yakınsa, test genellikle daha doğrudur. Bununla birlikte, eğri ROC uzayının 45 derecelik köşegenine yaklaşırsa, test daha az doğru veya güvenilirdir.
- Bir kesme noktasındaki teğet doğrunun eğimi, testin o belirli değeri için Olabilirlik Oranını (LR) belirtir.
- Eğrinin altındaki alan test doğruluğunu ölçer.
- Tip 1 ve Tip 2 hatalar arasındaki farkı açıklayın?
Tip 1 hata, aslında hiçbir şey olmadığı halde bir olayın meydana geldiğini 'iddia eden' yanlış bir pozitif hatadır. Yanlış pozitif hataya en iyi örnek yanlış yangın alarmıdır - yangın olmadığında alarm çalmaya başlar. Bunun aksine, Tip 2 hata, kesinlikle bir şey olduğunda hiçbir şeyin olmadığını 'iddia eden' yanlış bir negatif hatadır. Hamile bir kadına bebek taşımadığını söylemek 2. Tip hata olur.
- Bayes neden “Naive Bayes” olarak anılır?
Naive Bayes, birçok pratik uygulamaya sahip olmasına rağmen, gerçek hayattaki verilerde bulunmanın imkansız olduğu varsayımına dayandığı için “naif” olarak adlandırılır - bir veri setindeki tüm özellikler çok önemli, bağımsız ve eşittir. Naive Bayes yaklaşımında, koşullu olasılık, bireysel bileşenlerin olasılıklarının saf ürünü olarak hesaplanır, böylece özelliklerin tam bağımsızlığını ima eder. Ne yazık ki, bu varsayım gerçek dünya senaryosunda asla yerine getirilemez.
- 'Aşırı takma' terimi ile ne kastedilmektedir? Bundan kaçınabilir misin? Öyleyse nasıl?
Genellikle, eğitim süreci sırasında bir modele büyük miktarda veri beslenir. İşlem sırasında, örnek veri setinde bulunan yanlış bilgi ve gürültüden bile veriler öğrenmeye başlar. Bu, modelin yeni veriler üzerindeki performansı üzerinde olumsuz bir etki yaratır, yani model, eğitim kümesindekilerden ayrı olarak yeni örnekleri/verileri doğru bir şekilde sınıflandıramaz. Bu, Aşırı Takma olarak bilinir.
Evet, Overfitting'den kaçınmak mümkündür. İşte nasıl:
- Modeli farklı örneklerle eğitmek için (farklı kaynaklardan) daha fazla veri toplayın.
- Veri kümesinin farklı birimlerinde birden çok Karar ağacının sonuçlarını yan yana getirerek tahminlerdeki varyasyonu en aza indirmek için torbalama yaklaşımını kullanan birleştirme yöntemlerini (örneğin, Rastgele Orman) uygulayın.
- Çapraz doğrulama tekniklerini kullandığınızdan emin olun.
- Denetimli Öğrenmede kalibrasyon için kullanılan iki yöntemi adlandırın.
Denetimli Öğrenmede iki kalibrasyon yöntemi vardır – Platt Kalibrasyonu ve İzotonik Regresyon. Bu yöntemlerin her ikisi de özellikle ikili sınıflandırma için tasarlanmıştır.
- Neden bir Karar Ağacı budamak?
Öngörü yeteneği zayıf olan dallardan kurtulmak için Karar Ağaçlarının budanması gerekir. Bu, Karar Ağacı modelinin karmaşıklık oranını en aza indirmeye ve tahmin doğruluğunu optimize etmeye yardımcı olur. Budama yukarıdan aşağıya veya aşağıdan yukarıya yapılabilir. Azaltılmış hata budama, maliyet-karmaşıklık budama, hata karmaşıklığı budama ve minimum hata budama, en çok kullanılan Karar Ağacı budama yöntemlerinden bazılarıdır.

- F1 puanı ne anlama geliyor?
Basit bir ifadeyle, F1 puanı bir modelin performansının bir ölçüsüdür – bir modelin Hassasiyet ve Geri Çağırma ortalamasının ortalamasıdır ve 1'e yakın sonuçlar en iyisidir ve 0'a yakın olanlar en kötüdür. F1 puanı, gerçek negatiflere önem vermeyen sınıflandırma testlerinde kullanılabilir.
- Üretken ve Ayrımcı algoritma arasında ayrım yapın.
Üretken bir algoritma veri kategorilerini öğrenirken, Ayrımcı bir algoritma farklı veri kategorileri arasındaki ayrımı öğrenir. Sınıflandırma görevleri söz konusu olduğunda, ayırt edici modeller tipik olarak üretken modelleri geride bırakır.
- Topluluk Öğrenmesi Nedir?
Ensemble Learning, modellerin tahmine dayalı performansını optimize etmek için öğrenme algoritmalarının bir kombinasyonunu kullanır. Bu yöntemde, sınıflandırıcılar veya uzmanlar gibi birden çok model hem stratejik olarak oluşturulur hem de modellerde Aşırı Uyum'u önlemek için birleştirilir. Çoğunlukla bir modelin tahminini, sınıflandırmasını, fonksiyon yaklaşımını, performansını vb. geliştirmek için kullanılır.
- 'Çekirdek Hilesini' tanımlayın.
Kernel Trick yöntemi, bu boyut içindeki noktaların koordinatlarını açıkça hesaplamak zorunda kalmadan daha yüksek boyutlu ve örtük bir özellik uzayında çalışabilen çekirdek fonksiyonlarının kullanımını içerir. Çekirdek işlevleri, bir özellik alanında bulunan tüm veri çiftlerinin görüntüleri arasındaki iç çarpımları hesaplar. Bu prosedür, koordinatların açık bir şekilde hesaplanmasına kıyasla hesaplama açısından daha ucuzdur ve Çekirdek Numarası olarak bilinir.
- Bir veri kümesindeki eksik veya bozuk verileri nasıl ele almalısınız?
Bir veri kümesindeki eksik/bozuk verileri bulmak için satırları ve sütunları bırakmanız veya başka değerlerle değiştirmeniz gerekir. Pandas kitaplığının eksik/bozuk verileri bulmak için iki harika yöntemi vardır – isnull() ve dropna(). Bu işlevlerin her ikisi de, eksik/bozuk veri içeren veri satırlarını/sütunlarını bulmanıza ve bu değerleri bırakmanıza yardımcı olmak için özel olarak tasarlanmıştır.
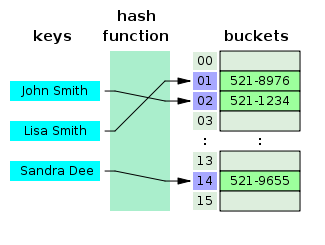
- Hash Tablosu Nedir?
Karma Tablosu, bir anahtarın bir karma işlevi kullanılarak belirli değerlere eşlendiği bir ilişkisel dizi oluşturan bir veri yapısıdır. Hash tabloları çoğunlukla veritabanı indekslemede kullanılır.
Kaynak
Bu soru listesi, yalnızca Makine Öğreniminin temellerini size tanıtmayı amaçlamaktadır ve açıkçası, bu yirmi soru denizde bir damladır. Makine Öğrenimi biz konuşurken ilerliyor ve bu nedenle zamanla yeni kavramlar ortaya çıkacak. Bu nedenle, makine öğrenimi görüşmelerinizi tamamlamanın anahtarı, sürekli bir öğrenme ve beceri kazanma dürtüsünü barındırmakta yatar. Öyleyse başlayın ve İnternet'i belaya sokun, dergileri okuyun, çevrimiçi topluluklara katılın, ML konferanslarına ve seminerlerine katılın - öğrenmenin pek çok yolu var.
Büyük bir organizasyona girmek için tanınmış bir kurumdan alınan sertifika şarttır. IIIT-B'nin Makine Öğrenimi ve Yapay Zeka alanında Yönetici PG Programına göz atın ve en iyi ML ve AI firmalarından iş yardımı alın.
Topluluk Öğrenmenin sınırlamaları nelerdir?
Topluluk yaklaşımları, varyansın azaltılmasına ve daha sağlam modellerin geliştirilmesine yardımcı olabilir. Bununla birlikte, açıklanabilirlik ve performans eksikliği gibi topluluk tekniklerini kullanmanın bazı sakıncaları vardır. Ayrıca, toplulukların etkinliğinin, konunun farklı yönlerine odaklanan birden fazla modeli bir araya getirme yeteneklerinden kaynaklandığını unutmayın. Bununla birlikte, yüzlerce modelden tahminlere ihtiyacınız olabileceğinden, daha uzun bir tahmin periyoduna sahiptirler. Daha iyi projeksiyonlara sahip olsalar bile, doğruluktaki kazanç buna değmeyebilir.
Makine Öğrenimi öğrenmek için ne kadar zamana ihtiyaç var?
Makine Öğrenimi söz konusu olduğunda, bunun için kullanılan karmaşık teknolojiler insanları kolayca korkutabilir. Ancak, parça parça anlamak zor değil. İstatistik, ileri matematik vb. alanlardaki önceki deneyimler, kuşkusuz tüm kavramları hızlı bir şekilde kavramanıza yardımcı olacaktır. Bununla birlikte, eğitim geçmişi ve becerileri kişiden kişiye değiştiğinden, bir kişi makine öğrenimini üç haftada öğrenirken diğerinin bir yıla ihtiyacı olabilir.
Makine Öğrenimi günlük hayatımızda nasıl kullanılıyor?
Gmail, e-postaları Makine Öğrenimi kullanarak Birincil, Promosyonlar, Sosyal ve Güncelleme olarak sıralayarak gerekli olarak sınıflandırır. Şirketler, en son işlem sıklığı, işlem miktarı ve satıcı türü gibi verilere dayalı olarak sahte işlemleri tespit etmek için sinir ağlarını kullanıyor. İntihal dedektörleri de makine öğreniminden yararlanır. Makine öğrenimi mühendisliği söz konusu olduğunda, tamamlanması yaklaşık altı ay sürer.