
Makine Öğrenimi İçin KNN Sınıflandırıcısı: Bilmeniz Gereken Her Şey
Yayınlanan: 2021-09-28Yapay zekanın (AI) yalnızca bilim kurgu romanları ve filmleriyle sınırlı bir kavram olduğu zamanı hatırlıyor musunuz? Teknolojik ilerleme sayesinde, AI artık her gün birlikte yaşadığımız bir şey. Alexa ve Siri'nin yanımızda olması ve OTT platformlarına izlemek istediğimiz filmleri “seçmesi” çağrısından, AI neredeyse günün sırası haline geldi ve öngörülebilir gelecek için burada söylemek için burada.
Tüm bunlar, gelişmiş ML algoritmaları sayesinde mümkündür. Bugün, böyle kullanışlı bir ML algoritmasından, K-NN Sınıflandırıcısından bahsedeceğiz.
Yapay zeka ve bilgisayar biliminin bir dalı olan makine öğrenimi, algoritmaların doğruluğunu kademeli olarak geliştirirken insan anlayışını taklit etmek için veri ve algoritmalar kullanır. Makine öğrenimi, tahminler veya sınıflandırmalar yapmak için algoritmaları eğitmeyi ve işletmeler ve uygulamalarda stratejik karar vermeyi yönlendiren temel bilgileri ortaya çıkarmayı içerir.
KNN (k-en yakın komşu) algoritması, regresyon ve sınıflandırma problem ifadelerini çözmek için kullanılan temel bir denetimli makine öğrenme algoritmasıdır. Öyleyse, K-NN Sınıflandırıcısı hakkında daha fazla bilgi edinmek için dalış yapalım.
İçindekiler
Denetimli ve Denetimsiz Makine Öğrenimi
Denetimli ve denetimsiz öğrenme, iki temel veri bilimi yaklaşımıdır ve KNN'nin ayrıntılarına girmeden önce farkı bilmek önemlidir.
Denetimli öğrenme , sonuçları tahmin etmeye yardımcı olmak için etiketli veri kümelerini kullanan bir makine öğrenimi yaklaşımıdır. Bu tür veri kümeleri, sonuçları tahmin etmek veya verileri doğru bir şekilde sınıflandırmak için algoritmaları "denetlemek" veya eğitmek için tasarlanmıştır. Bu nedenle, etiketlenmiş girdiler ve çıktılar, modelin doğruluğunu artırırken zaman içinde öğrenmesini sağlar.

Denetimli öğrenme iki tür problem içerir – sınıflandırma ve regresyon. Sınıflandırma problemlerinde , algoritmalar test verilerini kedileri köpeklerden ayırmak gibi ayrı kategorilere ayırır.
Gerçek hayattan önemli bir örnek, istenmeyen postaları gelen kutunuzdan ayrı bir klasörde sınıflandırmak olabilir. Öte yandan, denetimli öğrenmenin regresyon yöntemi, bağımsız ve bağımlı değişkenler arasındaki ilişkiyi anlamak için algoritmaları eğitir. Bir işletme için satış gelirini tahmin etmek gibi sayısal değerleri tahmin etmek için farklı veri noktalarını kullanır.
Denetimsiz öğrenme , aksine, etiketlenmemiş veri kümelerinin analizi ve kümelenmesi için makine öğrenme algoritmalarını kullanır. Bu nedenle, algoritmaların verilerdeki gizli kalıpları tanımlaması için insan müdahalesine (“denetimsiz”) gerek yoktur.
Denetimsiz öğrenme modellerinin üç ana uygulaması vardır - ilişkilendirme, kümeleme ve boyutluluk azaltma. Ancak konumuzun dışında kaldığı için ayrıntılara girmeyeceğiz.
K-En Yakın Komşu (KNN)
K-Nearest Neighbor veya KNN algoritması, denetimli öğrenme modeline dayalı bir makine öğrenme algoritmasıdır. K-NN algoritması, benzer şeylerin birbirine yakın olduğunu varsayarak çalışır. Bu nedenle, K-NN algoritması, yeni veri noktalarının değerlerini tahmin etmek için yeni veri noktaları ile eğitim kümesindeki (mevcut durumlar) noktalar arasındaki özellik benzerliğini kullanır. Özünde, K-NN algoritması, eğitim kümesindeki noktalara ne kadar benzediğine bağlı olarak en son veri noktasına bir değer atar. K-NN algoritması hem sınıflandırma hem de regresyon problemlerinde uygulama bulur ancak esas olarak sınıflandırma problemlerinde kullanılır.
İşte K-NN Sınıflandırıcısını anlamak için bir örnek.

Kaynak
Yukarıdaki görüntüde, girdi değeri hem kedi hem de köpeğe benzerlik gösteren bir yaratıktır. Ancak biz onu kedi ya da köpek olarak sınıflandırmak istiyoruz. Dolayısıyla bu sınıflandırma için K-NN algoritmasını kullanabiliriz. K-NN modeli, yeni veri seti (girdi) ile mevcut kedi ve köpek görüntüleri (eğitim veri seti) arasında benzerlikler bulacaktır. Daha sonra model, yeni veri noktasını en benzer özelliklere dayalı olarak kedi veya köpek kategorisine yerleştirecektir.
Benzer şekilde, kategori A (yeşil noktalar) ve kategori B (turuncu noktalar) yukarıdaki grafik örneğe sahiptir. Ayrıca, kategorilerden birine girecek yeni bir veri noktamız (mavi nokta) var. Bu sınıflandırma problemini bir K-NN algoritması kullanarak çözebilir ve yeni veri noktası kategorisini belirleyebiliriz.
K-NN Algoritmasının Tanımlayıcı Özellikleri
Aşağıdaki iki özellik K-NN algoritmasını en iyi şekilde tanımlar:
- Tembel bir öğrenme algoritmasıdır çünkü K-NN algoritması eğitim setinden anında öğrenmek yerine veri setini depolar ve sınıflandırma anında veri setinden trenler yapar.
- K-NN aynı zamanda parametrik olmayan bir algoritmadır , yani temel alınan veriler hakkında herhangi bir varsayımda bulunmaz.
K-NN Algoritmasının Çalışması
Şimdi K-NN algoritmasının nasıl çalıştığını anlamak için aşağıdaki adımlara bir göz atalım.
Adım 1: Eğitim ve test verilerini yükleyin.
Adım 2: En yakın veri noktalarını, yani K değerini seçin.
Adım 3: K sayıda komşunun mesafesini hesaplayın (her bir eğitim verisi ve test verisi satırı arasındaki mesafe). Öklid yöntemi en yaygın olarak mesafeyi hesaplamak için kullanılır.
Adım 4: Hesaplanan Öklid mesafesine göre K en yakın komşuyu alın.
Adım 5: En yakın K komşuları arasında, her kategorideki veri noktalarının sayısını sayın.
Adım 6: Yeni veri noktalarını, komşu sayısının maksimum olduğu kategoriye tahsis edin.
Adım 7: Bitirin. Model artık hazır.
Kariyerinizi hızlandırmak için Dünyanın en iyi Üniversiteleri - Yüksek Lisanslar, Yönetici Yüksek Lisans Programları ve Makine Öğrenimi ve Yapay Zeka alanında İleri Düzey Sertifika Programı'ndan çevrimiçi Yapay Zeka kurslarına katılın .
K değerini seçme
K, K-NN algoritmasında kritik bir parametredir. Bu nedenle, K değerine karar vermeden önce bazı noktaları aklımızda tutmamız gerekir.
Hata eğrilerini kullanmak , K değerini belirlemek için yaygın bir yöntemdir. Aşağıdaki resim, test ve eğitim verileri için farklı K değerleri için hata eğrilerini göstermektedir.


Kaynak
Yukarıdaki grafik örnekte, eğitim verilerinde K=1'de tren hatası sıfırdır çünkü noktaya en yakın komşu o noktanın kendisidir. Ancak, K'nin düşük değerlerinde bile test hatası yüksektir. Buna yüksek varyans veya verilerin fazla uyması denir. K değerini artırdıkça test hatası azalır, ancak belirli bir K değerinden sonra yanlılık veya eksik uydurma olarak adlandırılan test hatasının tekrar arttığını görüyoruz. Böylece, varyans nedeniyle test verisi hatası başlangıçta yüksektir, daha sonra düşer ve sabitlenir ve K değerinde daha fazla artışla, test hatası yanlılıktan dolayı tekrar fırlar.
Bu nedenle, test hatasının stabilize olduğu ve düşük olduğu K değeri, K'nin optimal değeri olarak alınır. Yukarıdaki hata eğrisi göz önüne alındığında, K=8 optimal değerdir.
K-NN Algoritmasının Çalışmasını Anlamak İçin Bir Örnek
Aşağıdaki gibi çizilmiş bir veri kümesi düşünün:

Kaynak
(60,60) noktasında mor veya kırmızı sınıfa ayırmamız gereken yeni bir veri noktası (siyah nokta) olduğunu varsayalım. K=3 kullanacağız, yani yeni veri noktası, ikisi kırmızı sınıfta ve biri mor sınıfta olmak üzere en yakın üç veri noktasını bulacaktır.
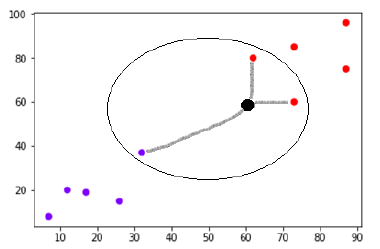
Kaynak
En yakın komşular, iki nokta arasındaki Öklid mesafesi hesaplanarak belirlenir. İşte hesaplamanın nasıl yapıldığını gösteren bir örnek.

Kaynak
Şimdi, yeni veri noktasının (siyah nokta) en yakın komşularından ikisi (üçten ikisi) kırmızı sınıfta yer aldığından, yeni veri noktası da kırmızı sınıfa atanacaktır.
Kariyerinizi hızlandırmak için Makine Öğrenimi Kursuna, Makine Öğrenimi ve Yapay Zeka alanında Dünyanın en iyi Üniversiteleri - Yüksek Lisanslar, Yönetici Yüksek Lisans Programları ve İleri Düzey Sertifika Programından çevrimiçi katılın.
Sınıflandırıcı olarak K-NN (Python'da Uygulama)
Artık K-NN algoritmasının basitleştirilmiş bir açıklamasına sahip olduğumuza göre, Python'da K-NN algoritmasını uygulamaya geçelim. Sadece K-NN Sınıflandırıcısına odaklanacağız.
Adım 1: Gerekli Python paketlerini içe aktarın.

Kaynak
Adım 2: UCI Machine Learning Repository'den iris veri setini indirin. Web bağlantısı “https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data” şeklindedir.
Adım 3: Veri kümesine sütun adları atayın.

Kaynak
Adım 4: Veri kümesini Pandas DataFrame'e okuyun.

Kaynak
Adım 5: Veri ön işleme, aşağıdaki kod satırları kullanılarak yapılır.

Kaynak
Adım 6: Veri kümesini test ve eğitim bölünmesine bölün. Aşağıdaki kod, veri kümesini %40 test verisi ve %60 eğitim verisine bölecektir.

Kaynak
Adım 7: Veri ölçekleme şu şekilde yapılır:

Kaynak
Adım 8: KNeighborsClassifier sklearn sınıfını kullanarak modeli eğitin.

Kaynak
9. Adım: Aşağıdaki komut dosyasını kullanarak bir tahmin yapın:

Kaynak
Adım 10: Sonuçları yazdırın.

Kaynak
Çıktı:

Kaynak
Sıradaki ne? IIT Madras ve upGrad'dan Makine Öğreniminde Gelişmiş Sertifika Programına Kaydolun
Yetenekli bir Veri Bilimcisi veya Makine Öğrenimi uzmanı olmayı hedeflediğinizi varsayalım. Bu durumda, IIT Madras ve upGrad'dan Makine Öğrenimi ve Bulutta Gelişmiş Sertifikasyon Kursu tam size göre!
12 aylık çevrimiçi program, Makine Öğrenimi, Büyük Veri İşleme, Veri Yönetimi, Veri Ambarı, Bulut ve Makine Öğrenimi modellerinin dağıtımında ana kavramlar arayan çalışan profesyoneller için özel olarak tasarlanmıştır.
Programın sunduğu şeyler hakkında size daha iyi bir fikir vermek için bazı önemli kurslar şunlardır:
- IIT Madras'tan dünya çapında kabul görmüş prestijli sertifika
- 500 saatten fazla öğrenme, 20'den fazla vaka çalışması ve proje, 25'ten fazla sektör danışmanlığı oturumu, 8'den fazla kodlama görevi
- 7 programlama dili ve aracının kapsamlı kapsamı
- 4 haftalık endüstri capstone projesi
- Pratik uygulamalı atölyeler
- Çevrimdışı eşler arası ağ iletişimi
Program hakkında daha fazla bilgi edinmek için bugün kaydolun!
Çözüm
Zamanla, Büyük Veri büyümeye devam ediyor ve yapay zeka giderek hayatımıza giriyor. Sonuç olarak, veri içgörüleri toplamak ve kritik iş süreçlerini ve genel olarak dünyamızı iyileştirmek için makine öğrenimi modellerinin gücünden yararlanabilen veri bilimi uzmanlarına yönelik talepte keskin bir artış var. Hiç şüphe yok ki, yapay zeka ve makine öğrenimi alanı gerçekten umut verici görünüyor. upGrad ile makine öğrenimi ve bulut alanındaki kariyerinizin ödüllendirici olduğundan emin olabilirsiniz!
K-NN neden iyi bir sınıflandırıcıdır?
K-NN'nin diğer makine öğrenimi algoritmalarına göre birincil avantajı, çok sınıflı sınıflandırma için K-NN'yi rahatlıkla kullanabilmemizdir. Bu nedenle, verileri ikiden fazla kategoriye ayırmamız gerekiyorsa veya veriler ikiden fazla etiket içeriyorsa, K-NN en iyi algoritmadır. Ayrıca, doğrusal olmayan veriler için idealdir ve nispeten yüksek doğruluğa sahiptir.
K-NN algoritmasının sınırlaması nedir?
K-NN algoritması, veri noktaları arasındaki mesafeyi hesaplayarak çalışır. Bu nedenle, nispeten daha fazla zaman alan bir algoritma olduğu ve bazı durumlarda sınıflandırmanın daha fazla zaman alacağı oldukça açıktır. Bu nedenle, çok sınıflı sınıflandırma için K-NN kullanırken çok fazla veri noktası kullanmamak en iyisidir. Diğer sınırlamalar arasında yüksek bellek depolaması ve alakasız özelliklere karşı hassasiyet sayılabilir.
K-NN'nin gerçek dünyadaki uygulamaları nelerdir?
K-NN, makine öğreniminde el yazısı algılama, konuşma tanıma, video tanıma ve görüntü tanıma gibi birçok gerçek yaşam kullanım örneğine sahiptir. Bankacılıkta, K-NN, bir kişinin temerrüde düşenlere benzer özelliklere sahip olup olmadığına bağlı olarak bir krediye uygun olup olmadığını tahmin etmek için kullanılır. Politikada, K-NN, potansiyel seçmenleri "X partisine oy verecek" veya "Y partisine oy verecek" gibi farklı sınıflara ayırmak için kullanılabilir.