
Bileşen Tabanlı API ile Tanışın
Yayınlanan: 2022-03-10Bu makale, okuyucuların geri bildirimlerine yanıt vermek için 31 Ocak 2019'da güncellendi. Yazar, bileşen tabanlı API'ye özel sorgulama yetenekleri ekledi ve nasıl çalıştığını açıklıyor .
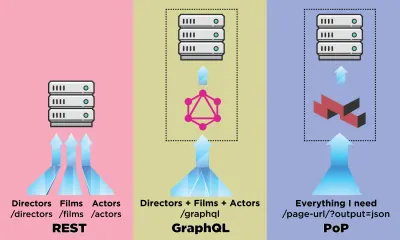
API, bir uygulamanın sunucudan veri yüklemesi için iletişim kanalıdır. API'ler dünyasında, REST daha yerleşik bir metodoloji olmuştur, ancak son zamanlarda REST'e göre önemli avantajlar sunan GraphQL tarafından gölgede bırakılmıştır. REST, bir bileşeni oluşturmak için bir dizi veriyi getirmek için birden çok HTTP isteği gerektirirken, GraphQL bu tür verileri tek bir istekte sorgulayabilir ve alabilir ve yanıt, tipik olarak olduğu gibi fazla veya eksik veri getirmeden tam olarak gereken şey olacaktır. DİNLENMEK.
Bu makalede, GraphQL tarafından sunulan tek bir istekte birkaç varlık için veri getirme fikrini genişleten ve "PoP" olarak adlandırdığım (ve burada açık kaynaklı) veri almanın başka bir yolunu anlatacağım. bir adım daha ileri, yani REST bir kaynak için verileri getirirken ve GraphQL tüm kaynaklar için verileri tek bir bileşende alırken, bileşen tabanlı API tüm bileşenlerden tüm kaynaklar için verileri tek bir sayfada getirebilir.
Bileşen tabanlı bir API kullanmak, web sitesinin kendisi bileşenler kullanılarak oluşturulduğunda, yani web sayfası yinelemeli olarak diğer bileşenleri saran bileşenlerden oluştuğunda, en üstte sayfayı temsil eden tek bir bileşen elde edene kadar anlamlıdır. Örneğin, aşağıdaki resimde gösterilen web sayfası, karelerle özetlenen bileşenlerle oluşturulmuştur:
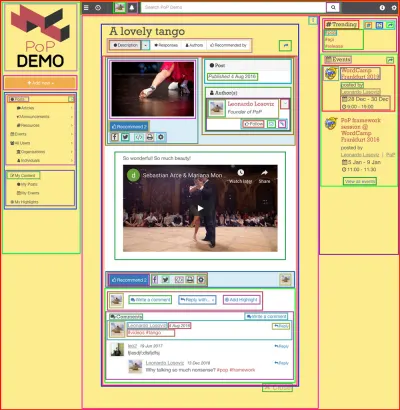
Bileşen tabanlı bir API, her bileşendeki (aynı zamanda sayfadaki tüm bileşenlerin yanı sıra) tüm kaynaklar için verileri talep ederek sunucuya tek bir istekte bulunabilir; bu, bileşenler arasındaki ilişkileri içinde tutarak gerçekleştirilir. API yapısının kendisi.
Diğerlerinin yanı sıra, bu yapı aşağıdaki çeşitli faydaları sunar:
- Pek çok bileşeni olan bir sayfa, pek çok yerine yalnızca bir isteği tetikler;
- Bileşenler arasında paylaşılan veriler, DB'den yalnızca bir kez alınabilir ve yanıtta yalnızca bir kez yazdırılabilir;
- Bir veri deposu ihtiyacını büyük ölçüde azaltabilir hatta tamamen ortadan kaldırabilir.
Bunları makale boyunca ayrıntılı olarak inceleyeceğiz, ancak önce bileşenlerin gerçekte ne olduğunu ve bu tür bileşenlere dayalı bir siteyi nasıl oluşturabileceğimizi ve son olarak bileşen tabanlı bir API'nin nasıl çalıştığını keşfedelim.
Önerilen okuma : Bir GraphQL Primer: Neden Yeni Bir API Türüne İhtiyacımız Var?
Bileşenler Aracılığıyla Site Oluşturma
Bir bileşen, özerk bir varlık oluşturmak için bir araya getirilen bir dizi HTML, JavaScript ve CSS kodudur. Bu daha sonra daha karmaşık yapılar oluşturmak için diğer bileşenleri sarabilir ve kendisi de diğer bileşenler tarafından sarılabilir. Bir bileşenin, çok temel bir şeyden (bir bağlantı veya bir düğme gibi) çok ayrıntılı bir şeye (bir atlıkarınca veya bir sürükle ve bırak görüntü yükleyicisi gibi) kadar değişebilen bir amacı vardır. Bileşenler, genel olduklarında ve enjekte edilen özellikler (veya "sahneler") aracılığıyla özelleştirmeyi mümkün kıldıklarında çok kullanışlıdır, böylece çok çeşitli kullanım durumlarına hizmet edebilirler. En yüksek durumda, sitenin kendisi bir bileşen haline gelir.
“Bileşen” terimi genellikle hem işlevselliğe hem de tasarıma atıfta bulunmak için kullanılır. Örneğin, işlevsellik ile ilgili olarak, React veya Vue gibi JavaScript çerçeveleri, kendi kendine oluşturabilen (örneğin, API gerekli verileri aldıktan sonra) istemci tarafı bileşenleri oluşturmaya ve yapılandırma değerlerini ayarlamak için sahne öğelerini kullanmaya izin verir. sarılmış bileşenler, kodun yeniden kullanılabilirliğini sağlar. Tasarımla ilgili olarak, Bootstrap, ön uç bileşen kitaplığı aracılığıyla web sitelerinin nasıl göründüğünü ve hissedildiğini standartlaştırdı ve ekiplerin web sitelerini korumak için tasarım sistemleri oluşturması sağlıklı bir trend haline geldi; bu, farklı ekip üyelerinin (tasarımcılar ve geliştiriciler, aynı zamanda pazarlamacılar ve satıcılar) birleşik bir dil konuşmak ve tutarlı bir kimlik ifade etmek.
Bir siteyi bileşen haline getirmek, web sitesini daha sürdürülebilir hale getirmenin çok mantıklı bir yoludur. React ve Vue gibi JavaScript çerçevelerini kullanan siteler zaten bileşen tabanlıdır (en azından istemci tarafında). Bootstrap gibi bir bileşen kitaplığı kullanmak, siteyi mutlaka bileşen tabanlı yapmaz (büyük bir HTML bloğu olabilir), ancak kullanıcı arabirimi için yeniden kullanılabilir öğeler kavramını içerir.
Site büyük bir HTML bloğuysa, onu bileşenleştirmemiz için düzeni bir dizi yinelenen desene bölmemiz gerekir; bunun için sayfadaki bölümleri işlevsellik ve stil benzerliklerine göre tanımlamalı ve kataloglamalı ve bunları kırmalıyız. her katmanın tek bir hedefe veya eyleme odaklanmasını sağlamaya çalışmak ve aynı zamanda farklı bölümler arasında ortak katmanları eşleştirmeye çalışmak.
Not : Brad Frost'un “Atomik Tasarımı”, bu ortak kalıpları belirlemek ve yeniden kullanılabilir bir tasarım sistemi oluşturmak için harika bir metodolojidir.
Bu nedenle, bileşenler aracılığıyla bir site oluşturmak LEGO ile oynamaya benzer. Her bileşen ya bir atomik işlevsellik, diğer bileşenlerin bir bileşimi ya da ikisinin birleşimidir.
Aşağıda gösterildiği gibi, temel bir bileşen (bir avatar), en üstteki web sayfasını elde edene kadar diğer bileşenler tarafından iteratif olarak oluşturulur:

Bileşen Tabanlı API Spesifikasyonu
Tasarladığım bileşen tabanlı API için bir bileşene "modül" adı verildi, bu nedenle bundan böyle "bileşen" ve "modül" terimleri birbirinin yerine kullanılmaktadır.
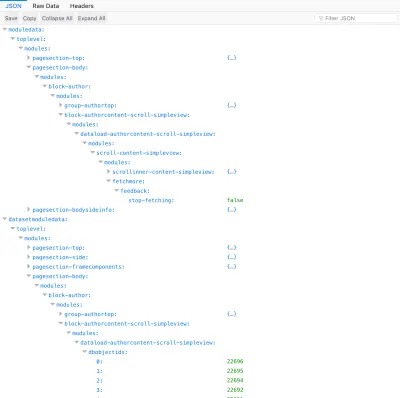
En üstteki modülden son seviyeye kadar birbirini saran tüm modüllerin ilişkisine “bileşen hiyerarşisi” denir. Bu ilişki, sunucu tarafında her modülün adını key niteliği olarak ve iç modüllerinin özellik modules altında belirttiği bir ilişkisel dizi (anahtar => özelliği dizisi) aracılığıyla ifade edilebilir. API daha sonra bu diziyi tüketim için bir JSON nesnesi olarak kodlar:
// Component hierarchy on server-side, eg through PHP: [ "top-module" => [ "modules" => [ "module-level1" => [ "modules" => [ "module-level11" => [ "modules" => [...] ], "module-level12" => [ "modules" => [ "module-level121" => [ "modules" => [...] ] ] ] ] ], "module-level2" => [ "modules" => [ "module-level21" => [ "modules" => [...] ] ] ] ] ] ] // Component hierarchy encoded as JSON: { "top-module": { modules: { "module-level1": { modules: { "module-level11": { ... }, "module-level12": { modules: { "module-level121": { ... } } } } }, "module-level2": { modules: { "module-level21": { ... } } } } } }Modüller arasındaki ilişki kesinlikle yukarıdan aşağıya bir tarzda tanımlanır: bir modül diğer modülleri sarar ve kim olduklarını bilir, ancak hangi modüllerin onu sardığını bilmez - ve umursamaz -.
Örneğin, yukarıdaki JSON kodunda, modül module-level1 -düzey1, modül module-level11 ve module-level12 modüllerini sardığını ve geçişli olarak, module-level121 sardığını da bilir; ancak modül module-level11 kimin sardığını umursamıyor, dolayısıyla module-level1 -düzey1'den habersiz.
Bileşen tabanlı yapıya sahip olarak, artık her bir modülün ihtiyaç duyduğu, ayarlar (konfigürasyon değerleri ve diğer özellikler gibi) ve veriler (sorgulanan veritabanı nesnelerinin kimlikleri ve diğer özellikler gibi) olarak sınıflandırılan gerçek bilgileri ekleyebiliriz. , ve buna göre modül ayarları ve modulesettings verileri girişleri altına moduledata :
{ modulesettings: { "top-module": { configuration: {...}, ..., modules: { "module-level1": { configuration: {...}, ..., modules: { "module-level11": { repeat... }, "module-level12": { configuration: {...}, ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { configuration: {...}, ..., modules: { "module-level21": { repeat... } } } } } }, moduledata: { "top-module": { dbobjectids: [...], ..., modules: { "module-level1": { dbobjectids: [...], ..., modules: { "module-level11": { repeat... }, "module-level12": { dbobjectids: [...], ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { dbobjectids: [...], ..., modules: { "module-level21": { repeat... } } } } } } } Ardından API, veritabanı nesne verilerini ekleyecektir. Bu bilgiler her modülün altına değil, iki veya daha fazla farklı modül aynı nesneleri veritabanından getirdiğinde bilgilerin tekrarlanmasını önlemek için databases adı verilen paylaşılan bir bölümün altına yerleştirilir.
Ek olarak, iki veya daha fazla farklı veritabanı nesnesi ortak bir nesneyle ilişkili olduğunda (aynı yazara sahip iki gönderi gibi) bilgilerin kopyalanmasını önlemek için API, veritabanı nesnesi verilerini ilişkisel bir şekilde temsil eder. Başka bir deyişle, veritabanı nesne verileri normalleştirilir.
Önerilen okuma : Statik Siteniz İçin Sunucusuz Bir İletişim Formu Oluşturma
Yapı, nesne özelliklerini elde edebileceğimiz, ilk olarak her nesne türü ve ikinci nesne kimliği altında düzenlenen bir sözlüktür:
{ databases: { primary: { dbobject_type: { dbobject_id: { property: ..., ... }, ... }, ... } } }Bu JSON nesnesi zaten bileşen tabanlı API'den gelen yanıttır. Biçimi başlı başına bir belirtimdir: Sunucu, JSON yanıtını gerekli biçimde döndürdüğü sürece, istemci, nasıl uygulandığından bağımsız olarak API'yi tüketebilir. Bu nedenle, API herhangi bir dilde uygulanabilir (ki bu GraphQL'nin güzelliklerinden biridir: gerçek bir uygulama olmayıp bir spesifikasyon olması, onun sayısız dilde kullanılabilir olmasını sağlamıştır.)
Not : Gelecek bir makalede, bileşen tabanlı API'yi PHP'de (repoda mevcut olan) uygulamamı anlatacağım.
API yanıtı örneği
Örneğin, aşağıdaki API yanıtı iki modüllü bir bileşen hiyerarşisi içerir, page => post-feed , burada modül post-feed blog gönderilerini getirir. Lütfen aşağıdakilere dikkat edin:
- Her modül,
dbobjectidsözelliğinden sorgulanan nesnelerinin hangileri olduğunu bilir (blog gönderileri için ID4ve9) - Her modül,
dbkeysözelliğinden sorgulanan nesneleri için nesne türünü bilir (her gönderinin verileri,postsaltında bulunur ve gönderinin yazar verileri, gönderinin özelliği altında verilen kimliğe sahipauthorkarşılık gelir,usersaltında bulunur) - Veritabanı nesne verileri ilişkisel olduğundan, özellik
author, yazar verilerini doğrudan yazdırmak yerine yazar nesnesinin kimliğini içerir.
{ moduledata: { "page": { modules: { "post-feed": { dbobjectids: [4, 9] } } } }, modulesettings: { "page": { modules: { "post-feed": { dbkeys: { id: "posts", author: "users" } } } } }, databases: { primary: { posts: { 4: { title: "Hello World!", author: 7 }, 9: { title: "Everything fine?", author: 7 } }, users: { 7: { name: "Leo" } } } } }Kaynak Tabanlı, Şema Tabanlı ve Bileşen Tabanlı API'lerden Veri Alma Farkları
PoP gibi bileşen tabanlı bir API'nin veri getirirken REST gibi kaynak tabanlı bir API ve GraphQL gibi şema tabanlı bir API ile nasıl karşılaştırıldığını görelim.
Diyelim ki IMDB, veri getirmesi gereken iki bileşenli bir sayfaya sahip: "Öne çıkan yönetmen" (George Lucas'ın bir açıklamasını ve filmlerinin bir listesini gösterir) ve "Sizin için önerilen filmler" ( Yıldız Savaşları: Bölüm I gibi filmleri gösterir) - Phantom Menace ve Terminatör ). Şuna benzeyebilir:
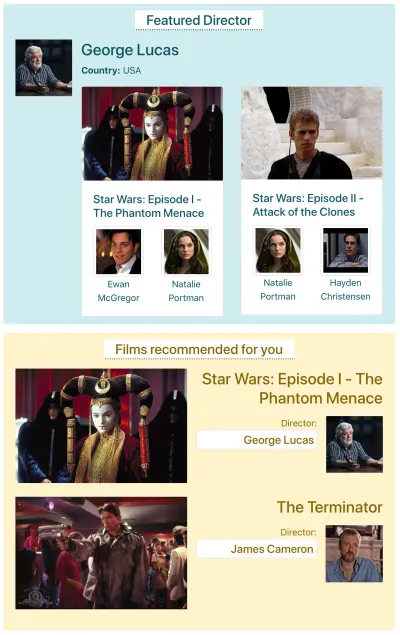
Her bir API yöntemi aracılığıyla verileri getirmek için kaç istek gerektiğini görelim. Bu örnek için, "Öne Çıkan yönetmen" bileşeni, iki filmi ( Yıldız Savaşları: Bölüm I — Hayalet Tehlike ve Yıldız Savaşları: Bölüm II — Klonların Saldırısı ) aldığı bir sonuç ("George Lucas") getirir ve her film için iki oyuncu (ilk film için “Ewan McGregor” ve “Natalie Portman” ve ikinci film için “Natalie Portman” ve “Hayden Christensen”). “Sizin için önerilen filmler” bileşeni iki sonuç getirir ( Yıldız Savaşları: Bölüm I - Hayalet Tehlike ve Terminatör ) ve ardından yönetmenlerini getirir (sırasıyla “George Lucas” ve “James Cameron”).
Featured featured-director bileşenini oluşturmak için REST kullanarak, aşağıdaki 7 isteğe ihtiyacımız olabilir (bu sayı, her bir uç nokta tarafından sağlanan veriye, yani ne kadar aşırı getirmenin uygulandığına bağlı olarak değişebilir):
GET - /featured-director GET - /directors/george-lucas GET - /films/the-phantom-menace GET - /films/attack-of-the-clones GET - /actors/ewan-mcgregor GET - /actors/natalie-portman GET - /actors/hayden-christensen GraphQL, kesin olarak belirlenmiş şemalar aracılığıyla, gerekli tüm verileri bileşen başına tek bir istekte getirmeyi sağlar. FeaturedDirector bileşeni için featuredDirector aracılığıyla veri getirme sorgusu şöyle görünür (ilgili şemayı uyguladıktan sonra):
query { featuredDirector { name country avatar films { title thumbnail actors { name avatar } } } }Ve aşağıdaki yanıtı üretir:
{ data: { featuredDirector: { name: "George Lucas", country: "USA", avatar: "...", films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", actors: [ { name: "Ewan McGregor", avatar: "...", }, { name: "Natalie Portman", avatar: "...", } ] }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "...", actors: [ { name: "Natalie Portman", avatar: "...", }, { name: "Hayden Christensen", avatar: "...", } ] } ] } } }Ve "Sizin için önerilen filmler" bileşenini sorgulamak aşağıdaki yanıtı verir:
{ data: { films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", director: { name: "George Lucas", avatar: "...", } }, { title: "The Terminator", thumbnail: "...", director: { name: "James Cameron", avatar: "...", } } ] } } PoP, sayfadaki tüm bileşenler için tüm verileri almak ve sonuçları normalleştirmek için yalnızca bir istek gönderir. Çağrılacak uç nokta, verileri almamız gereken URL ile aynıdır, verileri HTML olarak yazdırmak yerine JSON biçiminde getirmeyi belirtmek için ek bir output=json parametresi eklemeniz yeterlidir:
GET - /url-of-the-page/?output=json Modül yapısının, featured-director ve films-recommended-for-you modülleri içeren page adında bir üst modüle sahip olduğunu ve bunların da aşağıdaki gibi alt modüllere sahip olduğunu varsayarsak:
"page" modules "featured-director" modules "director-films" modules "film-actors" "films-recommended-for-you" modules "film-director"Döndürülen tek JSON yanıtı şöyle görünecektir:
{ modulesettings: { "page": { modules: { "featured-director": { dbkeys: { id: "people", }, modules: { "director-films": { dbkeys: { films: "films" }, modules: { "film-actors": { dbkeys: { actors: "people" }, } } } } }, "films-recommended-for-you": { dbkeys: { id: "films", }, modules: { "film-director": { dbkeys: { director: "people" }, } } } } } }, moduledata: { "page": { modules: { "featured-director": { dbobjectids: [1] }, "films-recommended-for-you": { dbobjectids: [1, 3] } } } }, databases: { primary: { people { 1: { name: "George Lucas", country: "USA", avatar: "..." films: [1, 2] }, 2: { name: "Ewan McGregor", avatar: "..." }, 3: { name: "Natalie Portman", avatar: "..." }, 4: { name: "Hayden Christensen", avatar: "..." }, 5: { name: "James Cameron", avatar: "..." }, }, films: { 1: { title: "Star Wars: Episode I - The Phantom Menace", actors: [2, 3], director: 1, thumbnail: "..." }, 2: { title: "Star Wars: Episode II - Attack of the Clones", actors: [3, 4], thumbnail: "..." }, 3: { title: "The Terminator", director: 5, thumbnail: "..." }, } } } }Bu üç yöntemin hız ve alınan veri miktarı açısından birbiriyle nasıl karşılaştırıldığını inceleyelim.
Hız
REST aracılığıyla, yalnızca bir bileşeni oluşturmak için 7 istek almak zorunda kalmak, çoğunlukla mobil ve titrek veri bağlantılarında çok yavaş olabilir. Bu nedenle, REST'ten GraphQL'ye geçiş, hız için çok önemlidir, çünkü bir bileşeni yalnızca bir istekle oluşturabiliyoruz.
PoP, birçok bileşen için tüm verileri tek bir istekte getirebildiği için, birçok bileşeni aynı anda işlemek için daha hızlı olacaktır; ancak, büyük olasılıkla buna gerek yoktur. Bileşenlerin (sayfada göründükleri gibi) sırayla işlenmesi zaten iyi bir uygulamadır ve ekranın altında görünen bileşenler için onları oluşturmak için kesinlikle acele yoktur. Bu nedenle, hem şema tabanlı hem de bileşen tabanlı API'ler zaten oldukça iyidir ve kaynak tabanlı bir API'den açıkça üstündür.
Data miktarı
Her istek üzerine, GraphQL yanıtındaki veriler çoğaltılabilir: aktris “Natalie Portman” ilk bileşenden gelen yanıtta iki kez getirilir ve iki bileşen için ortak çıktı düşünüldüğünde, film gibi paylaşılan verileri de bulabiliriz. Yıldız Savaşları: Bölüm I — Phantom Menace .
PoP ise veritabanı verilerini normalleştirir ve yalnızca bir kez yazdırır, ancak modül yapısını yazdırmanın ek yükünü taşır. Bu nedenle, yinelenen verilere sahip olan veya olmayan belirli isteğe bağlı olarak, şema tabanlı API veya bileşen tabanlı API daha küçük bir boyuta sahip olacaktır.
Sonuç olarak, GraphQL gibi şema tabanlı bir API ve PoP gibi bileşen tabanlı bir API, performans açısından benzer şekilde iyidir ve REST gibi kaynak tabanlı bir API'den daha üstündür.
Önerilen okuma : REST API'lerini Anlamak ve Kullanmak
Bileşen Tabanlı API'nin Belirli Özellikleri
Bileşen tabanlı bir API, performans açısından şema tabanlı bir API'den mutlaka daha iyi değilse, merak ediyor olabilirsiniz, o zaman bu makaleyle neyi başarmaya çalışıyorum?
Bu bölümde, böyle bir API'nin inanılmaz bir potansiyele sahip olduğuna, çok arzu edilen çeşitli özellikler sağladığına ve onu API dünyasında ciddi bir rakip haline getirdiğine sizi ikna etmeye çalışacağım. Aşağıda benzersiz harika özelliklerinin her birini açıklıyor ve gösteriyorum.
Veritabanından Alınacak Veriler Bileşen Hiyerarşisinden Çıkarılabilir
Bir modül bir DB nesnesinden bir özellik görüntülediğinde, modül bunun hangi nesne olduğunu bilmeyebilir veya umursamayabilir; tek umursadığı şey, yüklenen nesneden hangi özelliklerin gerekli olduğunu tanımlamaktır.
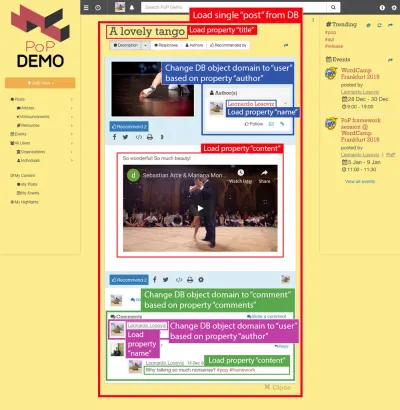
Örneğin, aşağıdaki resmi düşünün. Bir modül, veritabanından bir nesne yükler (bu durumda, tek bir gönderi) ve ardından onun alt modülleri, title ve content gibi nesneden belirli özellikleri gösterir:
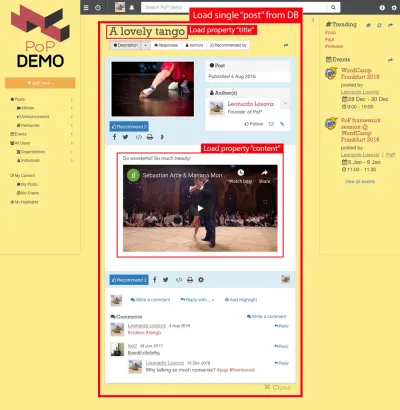
Bu nedenle, bileşen hiyerarşisi boyunca, "veri yükleme" modülleri, sorgulanan nesneleri yüklemekten sorumlu olacak (bu durumda tek gönderiyi yükleyen modül) ve onun alt modülleri, DB nesnesinden hangi özelliklerin gerekli olduğunu tanımlayacaktır ( title ve content , bu durumda).
DB nesnesi için gerekli tüm özelliklerin alınması, bileşen hiyerarşisini geçerek otomatik olarak yapılabilir: veri yükleme modülünden başlayarak, tüm alt modüllerini yeni bir veri yükleme modülüne ulaşana veya ağacın sonuna kadar baştan aşağı yineleriz; her seviyede gerekli tüm özellikleri elde ediyoruz ve ardından tüm özellikleri bir araya getiriyoruz ve hepsini bir kez veri tabanından sorguluyoruz.
Aşağıdaki yapıda, modül single-post , DB'den (ID 37'ye sahip gönderi) sonuçları getirir ve alt modüller post-title ve post-content , sorgulanan DB nesnesi için yüklenecek özellikleri tanımlar (sırasıyla title ve content ); alt modüller post-layout ve fetch-next-post-button herhangi bir veri alanı gerektirmez.
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "fetch-next-post-button"Yürütülecek sorgu, tüm modüller ve alt modülleri tarafından ihtiyaç duyulan tüm özellikleri içeren bileşen hiyerarşisinden ve gerekli veri alanlarından otomatik olarak hesaplanır:
SELECT title, content FROM posts WHERE id = 37 Doğrudan modüllerden alınacak özellikleri getirerek, bileşen hiyerarşisi değiştiğinde sorgu otomatik olarak güncellenecektir. Örneğin, veri alanı thumbnail gerektiren post-thumbnail alt modülü eklersek:
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-thumbnail" => Load property "thumbnail" "fetch-next-post-button"Ardından, ek özelliği getirmek için sorgu otomatik olarak güncellenir:
SELECT title, content, thumbnail FROM posts WHERE id = 37Alınacak veritabanı nesnesi verilerini ilişkisel bir şekilde kurduğumuz için, bu stratejiyi veritabanı nesneleri arasındaki ilişkiler arasında da uygulayabiliriz.
Aşağıdaki resmi inceleyin: post nesne türünden başlayarak ve bileşen hiyerarşisinde aşağı inerek, DB nesne türünü sırasıyla gönderinin yazarına ve gönderinin yorumlarının her birine karşılık gelen user ve comment olarak değiştirmemiz gerekecek ve ardından her biri için yorum, nesne türünü bir kez daha yorumun yazarına karşılık gelen user olarak değiştirmelidir.
Bir veritabanı nesnesinden ilişkisel bir nesneye geçiş (muhtemelen nesne tipini değiştirmek, post => author post to user gidiyor ya da değil, author => Follower's to user to user 'da olduğu gibi) "anahtar alanlarını değiştirmek" dediğim şeydir. ”.
Yeni bir etki alanına geçtikten sonra, bileşen hiyerarşisindeki o seviyeden aşağıya doğru, gerekli tüm özellikler yeni etki alanına tabi olacaktır:
-
name,usernesnesinden alınır (gönderinin yazarını temsil eder), -
content,commentnesnesinden alınır (gönderinin yorumlarının her birini temsil eder), -
name,usernesnesinden alınır (her yorumun yazarını temsil eder).
API, bileşen hiyerarşisini geçerek yeni bir etki alanına ne zaman geçildiğini bilir ve uygun şekilde, ilişkisel nesneyi getirmek için sorguyu günceller.
Örneğin, gönderinin yazarından gelen verileri göstermemiz gerekirse, post post-author writer alt modülünü yığınlamak, o seviyedeki etki alanını post'tan ilgili user değiştirecektir ve bu seviyeden aşağıya doğru, bağlama yüklenen DB nesnesi modüle aktarılır. Kullanıcı. Ardından, post-author writer altındaki user-name ve user-avatar alt modülleri, user nesnesi altında özelliklerin name ve avatar yükler:
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-author" => Switch domain from "post" to "user", based on property "author" modules "user-layout" modules "user-name" => Load property "name" "user-avatar" => Load property "avatar" "fetch-next-post-button"Aşağıdaki sorgu ile sonuçlanan:
SELECT p.title, p.content, p.author, u.name, u.avatar FROM posts p INNER JOIN users u WHERE p.id = 37 AND p.author = u.idÖzetle, her modülü uygun şekilde yapılandırarak, bileşen tabanlı bir API için veri getirmek için sorguyu yazmaya gerek yoktur. Sorgu, veri yükleme modülleri tarafından hangi nesnelerin yüklenmesi gerektiğini, her bir alt modülde tanımlanan yüklenen her nesne için alınacak alanları ve her bir alt modülde tanımlanan etki alanı anahtarını elde ederek, bileşen hiyerarşisinin yapısından otomatik olarak üretilir.
Herhangi bir modülün eklenmesi, çıkarılması, değiştirilmesi veya değiştirilmesi sorguyu otomatik olarak güncelleyecektir. Sorguyu yürüttükten sonra, alınan veriler tam olarak gerekli olan şey olacaktır - ne eksik ne fazla.
Verilerin Gözlenmesi ve Ek Özelliklerin Hesaplanması
Bileşen hiyerarşisinde veri yükleme modülünden başlayarak, herhangi bir modül döndürülen sonuçları gözlemleyebilir ve bunlara dayalı olarak ekstra veri öğelerini veya giriş modülü verileri altına yerleştirilen feedback değerlerini moduledata .
Örneğin, fetch-next-post-button modülü, getirilecek daha fazla sonuç olup olmadığını belirten bir özellik ekleyebilir (bu geri bildirim değerine göre, daha fazla sonuç yoksa, düğme devre dışı bırakılır veya gizlenir):
{ moduledata: { "page": { modules: { "single-post": { modules: { "fetch-next-post-button": { feedback: { hasMoreResults: true } } } } } } } }Gerekli Verilerin Örtülü Bilgisi Karmaşıklığı Azaltır ve “Son Nokta” Kavramını Eski Haline Getirir
Yukarıda gösterildiği gibi, bileşen tabanlı API, sunucudaki tüm bileşenlerin modeline ve her bir bileşen için hangi veri alanlarının gerekli olduğuna sahip olduğundan, tam olarak gerekli verileri getirebilir. Ardından, gerekli veri alanlarının bilgisini örtük hale getirebilir.

Avantajı, bileşen tarafından gerekli olan verilerin tanımlanmasının JavaScript dosyalarını yeniden dağıtmak zorunda kalmadan yalnızca sunucu tarafında güncellenebilmesi ve istemcinin, sunucudan ihtiyaç duyduğu verileri sağlamasını isteyerek aptallaştırılabilmesidir. , böylece istemci tarafı uygulamanın karmaşıklığını azaltır.
Ek olarak, belirli bir URL için tüm bileşenlerin verilerini almak üzere API'yi çağırmak, yalnızca bu URL'yi sorgulayarak ve sayfayı yazdırmak yerine API verilerinin döndürüldüğünü belirtmek için ekstra parametre output=json eklenerek gerçekleştirilebilir. Bu nedenle, URL kendi bitiş noktası haline gelir veya farklı bir şekilde düşünüldüğünde, "bitiş noktası" kavramının modası geçmiş olur.
Verilerin Alt Kümelerini Alma: Bileşen Hiyerarşisinin Herhangi Bir Düzeyinde Bulunan Belirli Modüller İçin Veri Getirilebilir
Bir sayfadaki tüm modüller için verileri almamız gerekmiyorsa, sadece bileşen hiyerarşisinin herhangi bir seviyesinden başlayan belirli bir modülün verilerini almamız gerekiyorsa ne olur? Örneğin, bir modül sonsuz kaydırma uygularsa, aşağı kaydırırken sayfadaki diğer modüller için değil, yalnızca bu modül için yeni veriler getirmeliyiz.
Bu, yalnızca belirtilen modülden başlayan özellikleri dahil etmek ve bu seviyenin üzerindeki her şeyi yok saymak için yanıta dahil edilecek bileşen hiyerarşisinin dallarını filtreleyerek gerçekleştirilebilir. Uygulamamda (ki bunu bir sonraki makalede anlatacağım), URL'ye modulefilter=modulepaths parametresi eklenerek filtreleme etkinleştirilir ve seçilen modül (veya modüller) bir modulepaths[] parametresi aracılığıyla belirtilir, burada bir "modül yolu ”, en üstteki modülden belirli modüle kadar olan modüllerin listesidir (örneğin, module1 => module2 => module3 , [ module1 , module2 , module3 ] modül yoluna sahiptir ve bir URL parametresi olarak module1.module2.module3 olarak geçirilir) .
Örneğin, aşağıdaki bileşen hiyerarşisinde her modülün bir dbobjectids girişi vardır:
"module1" dbobjectids: [...] modules "module2" dbobjectids: [...] modules "module3" dbobjectids: [...] "module4" dbobjectids: [...] "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] Ardından, modulefilter=modulepaths ve modulepaths[]=module1.module2.module5 parametrelerini ekleyerek web sayfası URL'sini istemek, aşağıdaki yanıtı üretecektir:
"module1" modules "module2" modules "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] Özünde, API, module1 => module2 => module5 öğesinden başlayarak verileri yüklemeye başlar. Bu nedenle module6 altında gelen module5 , module3 ve module4 gelmezken verilerini de getirir.
Ek olarak, önceden düzenlenmiş modül setini dahil etmek için özel modül filtreleri oluşturabiliriz. Örneğin, modulefilter=userstate ile bir sayfanın çağrılması, yalnızca modülleri module3 ve module6 gibi istemcide oluşturmak için kullanıcı durumu gerektiren modülleri yazdırabilir:
"module1" modules "module2" modules "module3" dbobjectids: [...] "module5" modules "module6" dbobjectids: [...] Başlangıç modülleri olan bilgiler, requestmeta bölümü altında, filteredmodules girişi altında, bir dizi modül yolu olarak gelir:
requestmeta: { filteredmodules: [ ["module1", "module2", "module3"], ["module1", "module2", "module5", "module6"] ] }Bu özellik, site çerçevesinin ilk istek üzerine yüklendiği karmaşık olmayan Tek Sayfalı bir Uygulamanın uygulanmasına izin verir:
"page" modules "navigation-top" dbobjectids: [...] "navigation-side" dbobjectids: [...] "page-content" dbobjectids: [...] Ancak onlardan sonra, istenen tüm URL'lere modulefilter=page parametresini ekleyebilir, çerçeveyi filtreleyebilir ve yalnızca sayfa içeriğini getirebiliriz:
"page" modules "navigation-top" "navigation-side" "page-content" dbobjectids: [...] Modül filtreleri userstate ve yukarıda açıklanan page benzer şekilde, herhangi bir özel modül filtresi uygulayabilir ve zengin kullanıcı deneyimleri oluşturabiliriz.
Modül Kendi API'sidir
Yukarıda gösterildiği gibi, herhangi bir modülden başlayarak verileri almak için API yanıtını filtreleyebiliriz. Sonuç olarak, her modül, modül yolunu dahil edildiği web sayfası URL'sine ekleyerek istemciden sunucuya kendisiyle etkileşime girebilir.
Umarım aşırı heyecanımı mazur görürsünüz ama bu özelliğin ne kadar harika olduğunu gerçekten ne kadar vurgulasam azdır. Bir bileşen oluştururken, verileri (REST, GraphQL veya herhangi bir şey) almak için onunla birlikte gitmek için bir API oluşturmamız gerekmez, çünkü bileşen zaten sunucuda kendisiyle konuşabilir ve kendi kendisini yükleyebilir. data — tamamen özerktir ve kendi kendine hizmet eder .
Her veri yükleme modülü, dataloadsource bölümündeki datasetmodulemeta girişi altında kendisiyle etkileşim kurmak için URL'yi dışa aktarır:
{ datasetmodulemeta: { "module1": { modules: { "module2": { modules: { "module5": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5" }, modules: { "module6": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5.module6" } } } } } } } } } }Veri Alma Modüller Arasında Ayrılır ve KURU
Bileşen tabanlı bir API'de veri getirmenin yüksek oranda ayrıştırılmış ve KURU ( D on't Repeat Yourself Yourself) olduğunu belirtmek için önce GraphQL gibi şema tabanlı bir API'de bunun nasıl daha az ayrıştırıldığını ve kuru değil.
GraphQL'de, verileri getirecek sorgu, alt bileşenleri içerebilen bileşen için veri alanlarını belirtmelidir ve bunlar ayrıca alt bileşenleri vb. içerebilir. Ardından, en üstteki bileşenin, bu verileri getirmek için alt bileşenlerinin her biri için hangi verilerin gerekli olduğunu bilmesi gerekir.
Örneğin, <FeaturedDirector> bileşeninin oluşturulması aşağıdaki alt bileşenleri gerektirebilir:
Render <FeaturedDirector>: <div> Country: {country} {foreach films as film} <Film film={film} /> {/foreach} </div> Render <Film>: <div> Title: {title} Pic: {thumbnail} {foreach actors as actor} <Actor actor={actor} /> {/foreach} </div> Render <Actor>: <div> Name: {name} Photo: {avatar} </div> Bu senaryoda, GraphQL sorgusu <FeaturedDirector> düzeyinde uygulanır. Ardından, <Film> alt bileşeni güncellenirse, başlık yerine filmTitle özelliği aracılığıyla title istenirse, bu yeni bilgiyi yansıtmak için <FeaturedDirector> bileşeninden gelen sorgunun da güncellenmesi gerekir (GraphQL, bu sorunla, ancak er ya da geç bilgileri yine de güncellemeliyiz). Bu, iç bileşenler sıklıkla değiştiğinde veya üçüncü taraf geliştiriciler tarafından üretildiğinde ele alınması zor olabilecek bakım karmaşıklığı üretir. Bu nedenle, bileşenler birbirinden tamamen ayrılmamıştır.
Benzer şekilde, belirli bir film için doğrudan <Film> bileşenini oluşturmak isteyebiliriz, bu durumda film ve oyuncuları için verileri getirmek için bu düzeyde bir GraphQL sorgusu uygulamamız gerekir, bu da fazlalık kod ekler: aynı sorgu, bileşen yapısının farklı seviyelerinde yaşayacaktır. Yani GraphQL DRY değildir .
Bileşen tabanlı bir API, bileşenlerinin kendi yapısı içinde birbirini nasıl sardığını zaten bildiğinden, bu sorunlardan tamamen kaçınılır. Birincisi, müşteri, bu veriler hangisi olursa olsun, ihtiyaç duyduğu gerekli verileri kolayca talep edebilir; if a subcomponent data field changes, the overall model already knows and adapts immediately, without having to modify the query for the parent component in the client. Therefore, the modules are highly decoupled from each other.
For another, we can fetch data starting from any module path, and it will always return the exact required data starting from that level; there are no duplicated queries whatsoever, or even queries to start with. Hence, a component-based API is fully DRY . (This is another feature that really excites me and makes me get wet.)
(Yes, pun fully intended. Sorry about that.)
Retrieving Configuration Values In Addition To Database Data
Let's revisit the example of the featured-director component for the IMDB site described above, which was created — you guessed it! — with Bootstrap. Instead of hardcoding the Bootstrap classnames or other properties such as the title's HTML tag or the avatar max width inside of JavaScript files (whether they are fixed inside the component, or set through props by parent components), each module can set these as configuration values through the API, so that then these can be directly updated on the server and without the need to redeploy JavaScript files. Similarly, we can pass strings (such as the title Featured director ) which can be already translated/internationalized on the server-side, avoiding the need to deploy locale configuration files to the front-end.
Similar to fetching data, by traversing the component hierarchy, the API is able to deliver the required configuration values for each module and nothing more or less.
The configuration values for the featured-director component might look like this:
{ modulesettings: { "page": { modules: { "featured-director": { configuration: { class: "alert alert-info", title: "Featured director", titletag: "h3" }, modules: { "director-films": { configuration: { classes: { wrapper: "media", avatar: "mr-3", body: "media-body", films: "row", film: "col-sm-6" }, avatarmaxsize: "100px" }, modules: { "film-actors": { configuration: { classes: { wrapper: "card", image: "card-img-top", body: "card-body", title: "card-title", avatar: "img-thumbnail" } } } } } } } } } } } Please notice how — because the configuration properties for different modules are nested under each module's level — these will never collide with each other if having the same name (eg property classes from one module will not override property classes from another module), avoiding having to add namespaces for modules.
Higher Degree Of Modularity Achieved In The Application
According to Wikipedia, modularity means:
The degree to which a system's components may be separated and recombined, often with the benefit of flexibility and variety in use. The concept of modularity is used primarily to reduce complexity by breaking a system into varying degrees of interdependence and independence across and 'hide the complexity of each part behind an abstraction and interface'.
Being able to update a component just from the server-side, without the need to redeploy JavaScript files, has the consequence of better reusability and maintenance of components. I will demonstrate this by re-imagining how this example coded for React would fare in a component-based API.
Let's say that we have a <ShareOnSocialMedia> component, currently with two items: <FacebookShare> and <TwitterShare> , like this:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> </ul> But then Instagram got kind of cool, so we need to add an item <InstagramShare> to our <ShareOnSocialMedia> component, too:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> <li>Share on Instagram: <InstagramShare url={window.location.href} /></li> </ul> In the React implementation, as it can be seen in the linked code, adding a new component <InstagramShare> under component <ShareOnSocialMedia> forces to redeploy the JavaScript file for the latter one, so then these two modules are not as decoupled as they could be.
Ancak bileşen tabanlı API'de, modülleri bir araya getirmek için API'de zaten açıklanan modüller arasındaki ilişkileri kolayca kullanabiliriz. Başlangıçta şu yanıtı alacağız:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} } } } } }Instagram'ı ekledikten sonra yükseltilmiş yanıtı alacağız:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} }, "instagram-share": { configuration: {...} } } } } } Ve yalnızca modulesettings["share-on-social-media"].modules altındaki tüm değerleri yineleyerek, <ShareOnSocialMedia> bileşeni, herhangi bir JavaScript dosyasını yeniden dağıtmaya gerek kalmadan <InstagramShare> bileşenini gösterecek şekilde yükseltilebilir. Bu nedenle, API, diğer modüllerden koddan ödün vermeden modüllerin eklenmesini ve çıkarılmasını destekler ve daha yüksek bir modülerlik derecesi elde eder.
Yerel İstemci Tarafı Önbellek/Veri Deposu
Alınan veritabanı verileri bir sözlük yapısında normalleştirilir ve standartlaştırılır, böylece dbobjectids üzerindeki değerden başlayarak, databases altındaki herhangi bir veri parçasına, hangi şekilde yapılandırılmış olursa olsun, dbkeys girişlerinde belirtildiği gibi sadece yolu izleyerek ulaşılabilir. . Bu nedenle, verileri düzenleme mantığı zaten API'nin kendisine özgüdür.
Bu durumdan birkaç şekilde faydalanabiliriz. Örneğin, her istek için döndürülen veriler, oturum boyunca kullanıcı tarafından istenen tüm verileri içeren bir istemci tarafı önbelleğine eklenebilir. Bu nedenle, uygulamaya Redux gibi harici bir veri deposu eklemekten kaçınmak mümkündür (yani, verilerin işlenmesiyle ilgili, Geri Al/Yinele, işbirliği ortamı veya zaman yolculuğu hata ayıklaması gibi diğer özelliklerle ilgili değil).
Ayrıca, bileşen tabanlı yapı önbelleğe almayı destekler: bileşen hiyerarşisi URL'ye değil, o URL'de hangi bileşenlerin gerekli olduğuna bağlıdır. Bu şekilde, /events/1/ ve /events/2/ altındaki iki olay aynı bileşen hiyerarşisini paylaşacak ve hangi modüllerin gerekli olduğuna dair bilgiler bunlar arasında yeniden kullanılabilir. Sonuç olarak, tüm özellikler (veritabanı verileri dışında), ilk olay alındıktan sonra istemcide önbelleğe alınabilir ve o andan itibaren yeniden kullanılabilir, böylece sonraki her olay için yalnızca veritabanı verilerinin alınması gerekir ve başka bir şey olmamalıdır.
Genişletilebilirlik ve Yeniden Amaçlama
API'nin databases bölümü, bilgilerini özelleştirilmiş alt bölümlere ayırmayı sağlayarak genişletilebilir. Varsayılan olarak, tüm veritabanı nesnesi verileri primary girdi altına yerleştirilir, ancak belirli DB nesnesi özelliklerinin yerleştirileceği özel girdiler de oluşturabiliriz.
Örneğin, daha önce açıklanan “Sizin için önerilen filmler” bileşeni, film DB nesnesi üzerinde friendsWhoWatchedFilm özelliği altında oturum açmış kullanıcının bu filmi izlemiş olan arkadaşlarının bir listesini gösteriyorsa, bu değer oturum açmış olan kullanıcıya bağlı olarak değişecektir. kullanıcı daha sonra bu özelliği bir userstate girişi altında kaydederiz, bu nedenle kullanıcı oturumu kapattığında, bu dalı yalnızca istemcideki önbelleğe alınmış veritabanından sileriz, ancak tüm primary veriler hala kalır:
{ databases: { userstate: { films: { 5: { friendsWhoWatchedFilm: [22, 45] }, } }, primary: { films: { 5: { title: "The Terminator" }, } "people": { 22: { name: "Peter", }, 45: { name: "John", }, }, } } }Ek olarak, belirli bir noktaya kadar API yanıtının yapısı yeniden amaçlanabilir. Özellikle, veritabanı sonuçları, varsayılan sözlük yerine bir dizi gibi farklı bir veri yapısında yazdırılabilir.
Örneğin, nesne türü yalnızca bir ise (örneğin films ), doğrudan bir daktilo bileşenine beslenecek bir dizi olarak biçimlendirilebilir:
[ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "..." }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "..." }, { title: "The Terminator", thumbnail: "..." }, ]En-Boy Odaklı Programlama Desteği
Bileşen tabanlı API, veri getirmeye ek olarak, bir gönderi oluşturma veya yorum ekleme gibi verileri de gönderebilir ve kullanıcının oturum açma veya kapatma, e-posta gönderme, günlük kaydı, analiz gibi her türlü işlemi yürütebilir. ve bunun gibi. Herhangi bir kısıtlama yoktur: Temel CMS tarafından sağlanan herhangi bir işlevsellik, herhangi bir düzeyde bir modül aracılığıyla başlatılabilir.
Bileşen hiyerarşisi boyunca istediğimiz sayıda modül ekleyebiliriz ve her modül kendi operasyonunu yürütebilir. Bu nedenle, REST'te POST, PUT veya DELETE işlemi yaparken veya GraphQL'de bir mutasyon gönderirken olduğu gibi, tüm işlemlerin mutlaka isteğin beklenen eylemiyle ilgili olması gerekmez, ancak e-posta göndermek gibi ekstra işlevler sağlamak için eklenebilir. bir kullanıcı yeni bir gönderi oluşturduğunda yöneticiye.
Bu nedenle, bileşen hiyerarşisini bağımlılık enjeksiyonu veya yapılandırma dosyaları aracılığıyla tanımlayarak, API'nin Aspect odaklı programlamayı desteklediği söylenebilir, "birbiriyle kesişen endişelerin ayrılmasına izin vererek modülerliği artırmayı amaçlayan bir programlama paradigması".
Önerilen okuma : Sitenizi Özellik İlkesi ile Koruma
Arttırılmış güvenlik
Modüllerin adları çıktıda yazdırıldığında mutlaka sabit değildir, ancak kısaltılabilir, karıştırılabilir, rastgele değiştirilebilir veya (kısaca) istenilen şekilde değişken hale getirilebilir. Başlangıçta API çıktısını kısaltmak için düşünülse de (böylece modül adları carousel-featured-posts veya drag-and-drop-user-images , üretim ortamı için a1 , a2 ve benzeri gibi bir temel 64 gösterime kısaltılabilir. ), bu özellik, güvenlik nedenleriyle API'den gelen yanıtta modül adlarının sık sık değiştirilmesine olanak tanır.
Örneğin, giriş adları varsayılan olarak ilgili modülleri olarak adlandırılır; daha sonra, istemcide sırasıyla <input type="text" name="{input_name}"> ve <input type="password" name="{input_name}"> olarak işlenecek olan username ve password adlı modüller, girdi adları için değişen rastgele değerler (bugün zwH8DSeG ve QBG7m6EF ve yarın c3oMLBjo ve c46oVgN6 gibi) ayarlanabilir, bu da spam göndericilerin ve botların siteyi hedeflemesini zorlaştırır.
Alternatif Modellerle Çok Yönlülük
Modüllerin iç içe yerleştirilmesi, belirli bir ortam veya teknoloji için uyumluluk eklemek veya bazı stil veya işlevleri değiştirmek ve ardından orijinal şubeye geri dönmek için başka bir modüle dallanmaya izin verir.
Örneğin, web sayfasının aşağıdaki yapıya sahip olduğunu varsayalım:
"module1" modules "module2" modules "module3" "module4" modules "module5" modules "module6" Bu durumda, web sitesinin AMP için de çalışmasını istiyoruz, ancak modüller module2 , module4 ve module5 AMP uyumlu değil. Bu modülleri benzer, AMP uyumlu modüller module2AMP , module4AMP ve module5AMP olarak dallara ayırabiliriz, ardından orijinal bileşen hiyerarşisini yüklemeye devam ederiz, böylece yalnızca bu üç modül değiştirilir (ve başka bir şey değil):
"module1" modules "module2AMP" modules "module3" "module4AMP" modules "module5AMP" modules "module6"Bu, tek bir kod tabanından farklı çıktılar üretmeyi oldukça kolaylaştırır, çatalları yalnızca gerektiği kadar burada ve orada ekler ve her zaman bireysel modüllere göre kapsamlandırılır ve sınırlandırılır.
Gösteri Süresi
Bu makalede açıklandığı gibi API'yi uygulayan kod, bu açık kaynak deposunda mevcuttur.
PoP API'sini gösterim amacıyla https://nextapi.getpop.org altında dağıttım. Web sitesi WordPress üzerinde çalışır, bu nedenle URL kalıcı bağlantıları WordPress'e özgü olanlardır. Daha önce belirtildiği gibi, bunlara output=json parametresi eklenerek bu URL'ler kendi API uç noktaları haline gelir.
Site, PoP Demo web sitesindeki aynı veritabanı tarafından desteklenmektedir, bu nedenle bileşen hiyerarşisinin görselleştirilmesi ve alınan veriler bu diğer web sitesinde aynı URL'yi sorgulayarak yapılabilir (örn. https://demo.getpop.org/u/leo/ ziyaret edin). https://demo.getpop.org/u/leo/ , https://nextapi.getpop.org/u/leo/?output=json verileri açıklar).
Aşağıdaki bağlantılar, daha önce açıklanan durumlar için API'yi göstermektedir:
- Ana sayfa, tek bir gönderi, bir yazar, bir gönderi listesi ve bir kullanıcı listesi.
- Belirli bir modülden filtreleme yapan bir olay.
- Tek Sayfa Uygulamasından yalnızca bir sayfa getirmek için kullanıcı durumu ve filtreleme gerektiren bir etiket, filtreleme modülleri.
- Bir daktiloya beslemek için bir dizi konum.
- “Biz Kimiz” sayfası için alternatif modeller: Normal, Yazdırılabilir, Katıştırılabilir.
- Modül adlarını değiştirme: orijinal vs karışık.
- Filtreleme bilgileri: yalnızca modül ayarları, modül verileri artı veritabanı verileri.
Çözüm
İyi bir API, güvenilir, bakımı kolay ve güçlü uygulamalar oluşturmak için bir basamak taşıdır. Bu yazıda, oldukça iyi bir API olduğuna inandığım bileşen tabanlı bir API'yi destekleyen kavramları anlattım ve umarım sizi de ikna edebilmişimdir.
Şimdiye kadar, API'nin tasarımı ve uygulanması birkaç yinelemeyi gerektirdi ve beş yıldan fazla sürdü - ve henüz tamamen hazır değil. Ancak oldukça iyi durumda, üretime hazır değil, kararlı bir alfa olarak. Bu günlerde hala üzerinde çalışıyorum; açık belirtimi tanımlama, ek katmanları uygulama (oluşturma gibi) ve belge yazma üzerinde çalışmak.
Gelecek bir makalede, API uygulamamın nasıl çalıştığını anlatacağım. O zamana kadar, olumlu ya da olumsuz herhangi bir düşünceniz varsa, aşağıdaki yorumlarınızı okumak isterim.
Güncelleme (31 Ocak): Özel Sorgulama Yetenekleri
Alain Schlesser, istemciden özel olarak sorgulanamayan bir API'nin değersiz olduğunu ve bizi SOAP'a geri götürdüğünü, çünkü REST veya GraphQL ile rekabet edemeyeceğini söyledi. Birkaç gün düşündükten sonra onun haklı olduğunu kabul etmek zorunda kaldım. Bununla birlikte, Bileşen tabanlı API'yi iyi niyetli, ancak henüz tam olarak orada olmayan bir çaba olarak reddetmek yerine, çok daha iyi bir şey yaptım: Bunun için özel sorgulama yeteneğini uygulamam gerekti. Ve bir cazibe gibi çalışıyor!
Aşağıdaki bağlantılarda, bir kaynağa veya kaynak koleksiyonuna ilişkin veriler, genellikle REST aracılığıyla yapıldığı gibi alınır. Bununla birlikte, parametre fields aracılığıyla, her bir kaynak için hangi belirli verilerin alınacağını da belirleyerek, verilerin fazla veya eksik alınmasından kaçınabiliriz:
- Tek bir gönderi ve parametre
fields=title,content,datetime -
fields=name,username,descriptionparametresini ekleyen bir kullanıcı ve bir kullanıcı topluluğu
Yukarıdaki bağlantılar, yalnızca sorgulanan kaynaklar için veri almayı göstermektedir. Peki ya ilişkileri? Örneğin, "title" ve "content" alanlarına sahip yayınların bir listesini, her bir yayının "content" ve "date" alanlı yorumlarını ve "name" ve "url" alanları olan her yorumun yazarını almak istediğimizi varsayalım. "url" . GraphQL'de bunu başarmak için aşağıdaki sorguyu uygularız:
query { post { title content comments { content date author { name url } } } } Bileşen tabanlı API'nin uygulanması için, sorguyu ilgili "nokta sözdizimi" ifadesine çevirdim ve bu ifade daha sonra parametre fields aracılığıyla sağlanabiliyor. Bir "post" kaynağında sorgulama yapıldığında bu değer:
fields=title,content,comments.content,comments.date,comments.author.name,comments.author.url Veya | kullanılarak basitleştirilebilir. aynı kaynağa uygulanan tüm alanları gruplamak için:
fields=title|content,comments.content|date,comments.author.name|urlBu sorguyu tek bir gönderide yürütürken, ilgili tüm kaynaklar için tam olarak gerekli verileri elde ederiz:
{ "datasetmodulesettings": { "dataload-dataquery-singlepost-fields": { "dbkeys": { "id": "posts", "comments": "comments", "comments.author": "users" } } }, "datasetmoduledata": { "dataload-dataquery-singlepost-fields": { "dbobjectids": [ 23691 ] } }, "databases": { "posts": { "23691": { "id": 23691, "title": "A lovely tango", "content": "<div class=\"responsiveembed-container\"><iframe loading="lazy" width=\"480\" height=\"270\" src=\"https:\\/\\/www.youtube.com\\/embed\\/sxm3Xyutc1s?feature=oembed\" frameborder=\"0\" allowfullscreen><\\/iframe><\\/div>\n", "comments": [ "25094", "25164" ] } }, "comments": { "25094": { "id": "25094", "content": "<p><a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/videos\\/\">#videos<\\/a>\\u00a0<a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/tango\\/\">#tango<\\/a><\\/p>\n", "date": "4 Aug 2016", "author": "851" }, "25164": { "id": "25164", "content": "<p>fjlasdjf;dlsfjdfsj<\\/p>\n", "date": "19 Jun 2017", "author": "1924" } }, "users": { "851": { "id": 851, "name": "Leonardo Losoviz", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo\\/" }, "1924": { "id": 1924, "name": "leo2", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo2\\/" } } } } Dolayısıyla kaynakları REST tarzında sorgulayabilir ve bir GraphQL tarzında şema tabanlı sorguları belirleyebiliriz ve fazla veya eksik veri getirmeden ve veri tabanındaki verileri normalleştirerek hiçbir verinin tekrarlanmaması için tam olarak gerekli olanı elde ederiz. Tercihen, sorgu, derinlerde iç içe geçmiş herhangi bir sayıda ilişki içerebilir ve bunlar doğrusal karmaşıklık süresiyle çözülür: en kötü durum O(n+m), burada n, etki alanını değiştiren düğümlerin sayısıdır (bu durumda 2: comments ve comments.author ) ve m, alınan sonuçların sayısıdır (bu durumda 5: 1 gönderi + 2 yorum + 2 kullanıcı) ve ortalama O(n) durumudur. (Bu, polinom karmaşıklık zamanı O(n^c) olan ve seviye derinliği arttıkça artan yürütme süresinden muzdarip GraphQL'den daha verimlidir).
Son olarak, bu API, verileri sorgularken, örneğin GraphQL aracılığıyla yapılabileceği gibi hangi kaynakların alındığını filtrelemek için değiştiriciler de uygulayabilir. Bunu başarmak için API, uygulamanın en üstünde yer alır ve işlevselliğini rahatlıkla kullanabilir, böylece tekerleği yeniden icat etmeye gerek kalmaz. Örneğin, filter=posts&searchfor=internet parametrelerinin eklenmesi, bir gönderi koleksiyonundan "internet" içeren tüm gönderileri filtreleyecektir.
Bu yeni özelliğin uygulanması, gelecek bir makalede anlatılacaktır.