
React ve Tesseract.js (OCR) ile Görüntüyü Metne Dönüştürme
Yayınlanan: 2022-03-10Veri, her yazılım uygulamasının bel kemiğidir, çünkü bir uygulamanın temel amacı insan sorunlarını çözmektir. İnsan problemlerini çözmek için, onlar hakkında bazı bilgilere sahip olmak gerekir.
Bu tür bilgiler, özellikle hesaplama yoluyla veri olarak temsil edilir. Web'de veriler çoğunlukla metinler, resimler, videolar ve daha pek çok biçimde toplanır. Bazen görüntüler, belirli bir amaca ulaşmak için işlenmesi gereken temel metinleri içerir. Bu görüntüler çoğunlukla manuel olarak işlendi çünkü onları programlı olarak işlemenin bir yolu yoktu.
Görüntülerden metin çıkaramama, son şirketimde ilk elden yaşadığım bir veri işleme sınırlamasıydı. Taranan hediye kartlarını işlememiz gerekiyordu ve resimlerden metin çıkaramadığımız için bunu manuel olarak yapmak zorunda kaldık.
Şirket içinde, hediye kartlarının manuel olarak onaylanmasından ve kullanıcı hesaplarının kredilendirilmesinden sorumlu olan “Operasyonlar” adlı bir departman vardı. Kullanıcıların bizimle bağlantı kurduğu bir web sitemiz olmasına rağmen, hediye kartlarının işlenmesi perde arkasında manuel olarak gerçekleştirildi.
O zamanlar web sitemiz esas olarak arka uç için PHP (Laravel) ve ön uç için JavaScript (jQuery ve Vue) ile inşa edildi. Teknik yığınımız, konunun yönetim tarafından önemli görülmesi koşuluyla Tesseract.js ile çalışacak kadar iyiydi.
Sorunu çözmeye istekliydim, ancak işin veya yönetimin bakış açısına göre sorunu çözmek gerekli değildi. Şirketten ayrıldıktan sonra biraz araştırma yapmaya ve olası çözümler bulmaya karar verdim . Sonunda, OCR'yi keşfettim.
OCR Nedir?
OCR, “Optik Karakter Tanıma” veya “Optik Karakter Okuyucu” anlamına gelir. Resimlerden metin çıkarmak için kullanılır.
OCR'nin Evrimi birkaç buluşa kadar takip edilebilir, ancak Optophone, "Gismo" , CCD düz yataklı tarayıcı, Newton MesssagePad ve Tesseract, karakter tanımayı başka bir kullanışlılık düzeyine taşıyan başlıca icatlardır.
Peki, neden OCR kullanıyorsunuz? Optik Karakter Tanıma birçok sorunu çözüyor, bunlardan biri beni bu makaleyi yazmaya itti. Bir görüntüden metin çıkarma yeteneğinin aşağıdakiler gibi birçok olanak sağladığını fark ettim:
- Düzenleme
Her kuruluşun, bazı nedenlerden dolayı kullanıcıların faaliyetlerini düzenlemesi gerekir. Düzenleme, kullanıcıların haklarını korumak ve onları tehditlerden veya dolandırıcılıklardan korumak için kullanılabilir.
Bir görüntüden metin çıkarmak, bir kuruluşun, özellikle görüntüler bazı kullanıcılar tarafından sağlandığında, düzenleme için bir görüntü üzerindeki metinsel bilgileri işlemesine olanak tanır.
Örneğin, OCR ile reklamlar için kullanılan görsellerdeki metinlerin sayısının Facebook benzeri bir şekilde düzenlenmesi sağlanabilir. Ayrıca, Twitter'da hassas içeriğin gizlenmesi de OCR ile mümkün olmaktadır. - aranabilirlik
Arama, özellikle internette en yaygın etkinliklerden biridir. Arama algoritmaları çoğunlukla metinleri manipüle etmeye dayanır. Optik Karakter Tanıma ile görsellerdeki karakterleri tanımak ve bunları kullanıcılara ilgili görsel sonuçları sağlamak için kullanmak mümkündür. Kısacası, resimler ve videolar artık OCR yardımıyla aranabilir. - Ulaşılabilirlik
Görüntüler üzerinde metin bulundurmak, erişilebilirlik için her zaman bir zorluk olmuştur ve bir görüntü üzerinde az sayıda metin olması temel kuraldır. OCR ile ekran okuyucular, kullanıcılarına gerekli bazı deneyimi sağlamak için resimlerdeki metinlere erişebilir. - Veri İşleme Otomasyonu Verilerin işlenmesi çoğunlukla ölçek için otomatikleştirilir. Görüntüler üzerinde metin bulunması, veri işleme için bir sınırlamadır, çünkü metinler manuel olarak işlenemez. Optik Karakter Tanıma (OCR), görüntüler üzerindeki metinlerin programlı olarak çıkarılmasını mümkün kılar ve bu sayede özellikle görüntüler üzerindeki metinlerin işlenmesi ile ilgili olduğunda veri işleme otomasyonu sağlar.
- Basılı Malzemelerin Dijitalleştirilmesi
Her şey dijitalleşiyor ve hala dijitalleştirilmesi gereken çok sayıda belge var. Çekler, sertifikalar ve diğer fiziksel belgeler artık Optik Karakter Tanıma kullanılarak dijitalleştirilebilir.
Yukarıdaki tüm kullanımları öğrenmek ilgimi derinleştirdi, bu yüzden bir soru sorarak daha ileri gitmeye karar verdim:
"OCR'yi web'de, özellikle bir React uygulamasında nasıl kullanabilirim?"
Bu soru beni Tesseract.js'ye yönlendirdi.
Tesseract.js Nedir?
Tesseract.js, orijinal Tesseract'ı C'den JavaScript WebAssembly'ye derleyen ve böylece OCR'yi tarayıcıda erişilebilir hale getiren bir JavaScript kitaplığıdır. Tesseract.js motoru orijinal olarak ASM.js'de yazılmıştır ve daha sonra WebAssembly'ye taşınmıştır, ancak ASM.js, WebAssembly'nin desteklenmediği bazı durumlarda hala yedek olarak hizmet vermektedir.
Tesseract.js web sitesinde belirtildiği gibi, 100'den fazla dili, otomatik metin yönlendirmeyi ve komut dosyası algılamayı, paragrafları okumak için basit bir arayüzü, kelimeleri ve karakter sınırlama kutularını destekler .
Tesseract, çeşitli işletim sistemleri için bir optik karakter tanıma motorudur. Apache Lisansı altında yayınlanan ücretsiz bir yazılımdır. Hewlett-Packard, Tesseract'ı 1980'lerde tescilli yazılım olarak geliştirdi. 2005 yılında açık kaynak olarak piyasaya sürüldü ve geliştirmesi 2006'dan beri Google tarafından destekleniyor.
Tesseract'ın en son sürümü olan 4. sürümü Ekim 2018'de piyasaya sürüldü ve Uzun Kısa Süreli Belleğe (LSTM) dayalı bir sinir ağı sistemi kullanan ve daha doğru sonuçlar üretmesi amaçlanan yeni bir OCR motoru içeriyor.
Tesseract API'lerini Anlama
Tesseract'ın nasıl çalıştığını gerçekten anlamak için bazı API'lerini ve bileşenlerini parçalamamız gerekiyor. Tesseract.js belgelerine göre, onu kullanmanın iki yolu vardır. Aşağıda ilk yaklaşım ve dökümü verilmiştir:
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } recognize yöntemi ilk argümanı olarak imajı, ikinci argümanı olarak dili (birden fazla olabilir) ve son argümanı olarak { logger: m => console.log(me) } 'yi alır. Tesseract tarafından desteklenen görüntü formatı, yalnızca öğeler (img, video veya tuval), dosya nesnesi ( <input> ), blob nesnesi, bir görüntünün yolu veya URL'si ve base64 kodlu görüntü olarak sağlanabilen jpg, png, bmp ve pbm'dir. . (Tesseract'ın işleyebileceği tüm görüntü formatları hakkında daha fazla bilgi için burayı okuyun.)
Dil, eng gibi bir dize olarak sağlanır. + işareti, eng+chi_tra gibi birkaç dili birleştirmek için kullanılabilir. Dil argümanı, görüntülerin işlenmesinde kullanılacak eğitilmiş dil verilerini belirlemek için kullanılır.
Not : Mevcut tüm dilleri ve kodlarını burada bulabilirsiniz.
{ logger: m => console.log(m) } , işlenmekte olan bir görüntünün ilerlemesi hakkında bilgi almak için çok kullanışlıdır. Kaydedici özelliği, Tesseract bir görüntüyü işlerken birden çok kez çağrılacak bir işlev alır. Kaydedici işlevinin parametresi, özellikleri olarak workerId , jobId , status ve progress olan bir nesne olmalıdır:
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progress , 0 ile 1 arasında bir sayıdır ve bir görüntü tanıma işleminin ilerlemesini göstermek için yüzde cinsindendir.
Tesseract, nesneyi kaydedici işlevine bir parametre olarak otomatik olarak oluşturur, ancak manuel olarak da sağlanabilir. Bir tanıma işlemi gerçekleşirken, işlev her çağrıldığında logger nesnesi özellikleri güncellenir. Bu nedenle, bir dönüştürme ilerleme çubuğu göstermek, bir uygulamanın bir bölümünü değiştirmek veya istenen herhangi bir sonucu elde etmek için kullanılabilir.
Yukarıdaki koddaki result , görüntü tanıma işleminin sonucudur. result özelliklerinin her biri, sınırlayıcı kutularının x/y koordinatları olarak bbox özelliğine sahiptir.
result nesnesinin özellikleri, anlamları veya kullanımları şunlardır:
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text: Tanınan metnin tamamı bir dize olarak. -
lines: Metin satırına göre tanınan her satırın bir dizisi. -
words: Tanınan her kelimenin bir dizisi. -
symbols: Tanınan karakterlerin her birinin dizisi. -
paragraphs: Tanınan her paragrafın bir dizisi. Bu yazıda daha sonra “güven” konusunu tartışacağız.
Tesseract ayrıca şu şekilde daha zorunlu olarak kullanılabilir:
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();Bu yaklaşım, ilk yaklaşımla ilgilidir ancak farklı uygulamalarla.
createWorker(options) , bir Tesseract çalışanı oluşturan bir web çalışanı veya düğüm alt süreci oluşturur. Çalışan, Tesseract OCR motorunun kurulmasına yardımcı olur. load() yöntemi, Tesseract çekirdek komut dosyalarını yükler, loadLanguage() kendisine sağlanan herhangi bir dili bir dize olarak yükler, initialize() , Tesseract'ın tamamen kullanıma hazır olduğundan emin olur ve ardından sağlanan görüntüyü işlemek için tanıma yöntemi kullanılır. sonlandır() yöntemi, çalışanı durdurur ve her şeyi temizler.
Not : Daha fazla bilgi için lütfen Tesseract API belgelerine bakın.
Şimdi, Tesseract.js'nin gerçekten ne kadar etkili olduğunu görmek için bir şeyler inşa etmeliyiz.
Ne İnşa Edeceğiz?
Bir hediye kartı PIN çıkarıcı yapacağız çünkü bir hediye kartından PIN çıkarmak, bu yazma macerasına ilk etapta yol açan sorundu.
Taranmış bir hediye kartından PIN'i çıkaran basit bir uygulama oluşturacağız . Basit bir hediye kartı pin çıkarıcısı yapmaya başladığımda, size yol boyunca karşılaştığım bazı zorluklar, sağladığım çözümler ve deneyimlerime dayanarak vardığım sonuçlar hakkında rehberlik edeceğim.
- Kaynak koduna git →
Aşağıda, gerçek dünyada mümkün olan bazı gerçekçi özelliklere sahip olduğu için test için kullanacağımız görüntü bulunmaktadır.

AQUX-QWMB6L-R6JAU'yu karttan çıkaracağız . Öyleyse başlayalım.
React ve Tesseract Kurulumu
React ve Tesseract.js'yi yüklemeden önce katılmanız gereken bir soru var ve soru şu ki, React'i Tesseract ile neden kullanıyorsunuz? Pratik olarak Tesseract'ı Vanilla JavaScript, herhangi bir JavaScript kitaplığı veya React, Vue ve Angular gibi çerçeveler ile kullanabiliriz.
Bu durumda React kullanmak kişisel bir tercihtir. Başlangıçta Vue kullanmak istedim ama React ile gitmeye karar verdim çünkü React'e Vue'dan daha aşinayım.
Şimdi kurulumlara devam edelim.
React'i create-react-app ile kurmak için aşağıdaki kodu çalıştırmanız gerekir:
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.jsveya
npm install tesseract.jsTesseract.js'yi kurmak için iplik kullanmaya karar verdim çünkü Tesseract'ı npm ile kuramadım ama iplik işi stres olmadan halletti. Npm kullanabilirsiniz, ancak deneyimlerime dayanarak Tesseract'ı iplikle kurmanızı öneririm.
Şimdi aşağıdaki kodu çalıştırarak geliştirme sunucumuzu başlatalım:
yarn startveya
npm startthread start veya npm start'ı çalıştırdıktan sonra, varsayılan tarayıcınız aşağıdakine benzer bir web sayfası açmalıdır:

Sayfanın otomatik olarak başlatılmaması koşuluyla tarayıcıda localhost:3000 de gidebilirsiniz.
React ve Tesseract.js'yi kurduktan sonra sırada ne var?
Yükleme Formu Oluşturma
Bu durumda, tarayıcıda az önce görüntülediğimiz ana sayfayı (App.js) ihtiyacımız olan formu içerecek şekilde ayarlayacağız:
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App Yukarıdaki kodun bu noktada dikkatimizi çekmesi gereken kısmı, handleChange .
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } İşlevde, URL.createObjectURL , event.target.files[0] aracılığıyla seçilen bir dosyayı alır ve img, audio ve video gibi HTML etiketleriyle kullanılabilecek bir referans URL oluşturur. URL'yi duruma eklemek için setImagePath kullandık. Artık URL'ye imagePath ile erişilebilir.
<img src={imagePath} className="App-logo" alt="image"/> Görüntüyü işlemeden önce tarayıcıda önizlemek için görüntünün src niteliğini {imagePath} olarak ayarladık.
Seçilmiş Resimleri Metinlere Dönüştürme
Seçilen görüntünün yolunu yakaladığımız için, metinleri çıkarmak için görüntünün yolunu Tesseract.js'ye geçirebiliriz.
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default App“App.js” dosyasına “handleClick” fonksiyonunu ekliyoruz ve seçilen görüntünün yolunu tutan Tesseract.js API'sini içeriyor. Tesseract.js “imagePath”, “dil”, “ayar nesnesi” alır.
Aşağıdaki düğme, düğmeye her tıklandığında görüntüden metne dönüştürmeyi tetikleyen “handClick”i çağırmak için forma eklenir.
<button onClick={handleClick} style={{height:50}}> convert to text</button>İşlem başarılı olduğunda sonuçtan hem “güven”e hem de “metne” erişiriz. Ardından “setText(text)” ile duruma “text” ekliyoruz.
<p> {text} </p> 'e ekleyerek, ayıklanan metni görüntülüyoruz.
Görüntüden “metnin” çıkarıldığı açık ama güven nedir?
Güven, dönüşümün ne kadar doğru olduğunu gösterir. Güven düzeyi 1 ile 100 arasındadır. Doğruluk açısından 1 en kötü, 100 en iyi anlamına gelir. Ayıklanan bir metnin doğru olarak kabul edilip edilmeyeceğini belirlemek için de kullanılabilir.
O halde soru şudur: Güven puanını veya tüm dönüşümün doğruluğunu hangi faktörler etkileyebilir? Çoğunlukla üç ana faktörden etkilenir - kullanılan belgenin kalitesi ve doğası, belgeden oluşturulan taramanın kalitesi ve Tesseract motorunun işleme yetenekleri.
Şimdi uygulamaya biraz stil vermek için aşağıdaki kodu “App.css” içerisine ekleyelim.
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }İşte ilk testimin sonucu:
Firefox'ta Sonuç
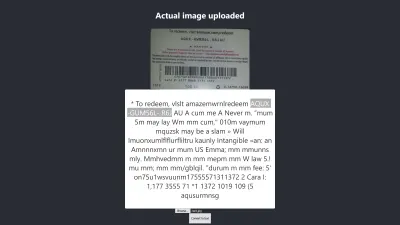
Yukarıdaki sonucun güven seviyesi 64'tür. Hediye kartı görselinin koyu renkli olduğunu ve aldığımız sonucu kesinlikle etkilediğini belirtmekte fayda var.
Yukarıdaki resme daha yakından bakarsanız, çıkarılan metinde karttan iğnenin neredeyse doğru olduğunu göreceksiniz. Hediye kartı gerçekten net olmadığı için doğru değil.

Bekle! Chrome'da nasıl görünecek?
Chrome'da Sonuç
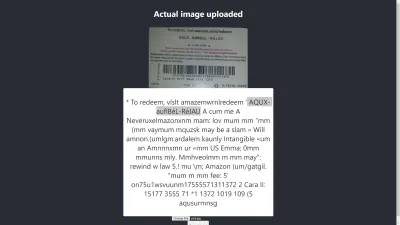
Ah! Sonuç Chrome'da daha da kötü. Ancak Chrome'daki sonuç neden Mozilla Firefox'tan farklı? Farklı tarayıcılar, görüntüleri ve renk profillerini farklı şekilde işler. Bu, bir görüntünün tarayıcıya bağlı olarak farklı şekilde oluşturulabileceği anlamına gelir. Tesseract'a önceden oluşturulmuş image.data sağlayarak, kullanılan tarayıcıya bağlı olarak Tesseract'a farklı image.data sağlandığı için farklı tarayıcılarda farklı bir sonuç üretmesi muhtemeldir. Bu makalenin ilerleyen kısımlarında göreceğimiz gibi, bir görüntünün ön işlenmesi, tutarlı bir sonuç elde edilmesine yardımcı olacaktır.
Doğru bilgiyi aldığımızdan veya verdiğimizden emin olabilmemiz için daha doğru olmamız gerekir. O yüzden biraz daha ileriye götürmemiz gerekiyor.
Sonunda amaca ulaşıp ulaşamayacağımızı görmek için daha fazla deneyelim.
Doğruluk Testi
Tesseract.js ile bir resimden metne dönüştürmeyi etkileyen birçok faktör vardır. Bu faktörlerin çoğu, işlemek istediğimiz görüntünün doğası etrafında döner ve geri kalanı Tesseract motorunun dönüştürmeyi nasıl ele aldığına bağlıdır.
Dahili olarak Tesseract, görüntüleri gerçek OCR dönüşümünden önce işler ancak her zaman doğru sonuçlar vermez.
Çözüm olarak, doğru dönüşümler elde etmek için görüntüleri önceden işleyebiliriz. Bir görüntüyü Tesseract.js için ön işleme tabi tutmak üzere ikili hale getirebilir, ters çevirebilir, genişletebilir, eğriliğini düzeltebilir veya yeniden ölçeklendirebiliriz.
Görüntü ön işleme , başlı başına çok fazla iş veya kapsamlı bir alandır. Neyse ki P5.js, kullanmak istediğimiz tüm görüntü ön işleme tekniklerini sağladı. Tekerleği yeniden icat etmek ya da sadece küçük bir bölümünü kullanmak istediğimiz için kitaplığın tamamını kullanmak yerine, ihtiyacımız olanları kopyaladım. Tüm görüntü ön işleme teknikleri preprocess.js'ye dahildir.
Binarizasyon Nedir?
Binarizasyon, bir görüntünün piksellerinin siyah veya beyaza dönüştürülmesidir. Doğruluğunun daha iyi olup olmayacağını kontrol etmek için önceki hediye kartını ikili hale getirmek istiyoruz.
Daha önce bir hediye kartından bazı metinler çıkardık ancak hedef PIN istediğimiz kadar doğru değildi. Bu nedenle, doğru bir sonuç elde etmek için başka bir yol bulmaya ihtiyaç vardır.
Şimdi, hediye kartını ikili hale getirmek istiyoruz, yani daha iyi bir doğruluk seviyesinin elde edilip edilemeyeceğini görebilmek için piksellerini siyah beyaza dönüştürmek istiyoruz.
Aşağıdaki işlevler ikilileştirme için kullanılacaktır ve preprocess.js adlı ayrı bir dosyaya dahil edilmiştir.
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImageYukarıdaki kod ne işe yarar?
Bazı filtreler uygulamak için bir görüntü verisini tutmak, görüntüyü dönüştürmek için Tesseract'a geçirmeden önce ön işlemek için tuvali tanıtıyoruz.
İlk preprocessImage işlevi preprocess.js'de bulunur ve tuvali piksellerini alarak kullanıma hazırlar. thresholdFilter işlevi , piksellerini siyah veya beyaza dönüştürerek görüntüyü ikili hale getirir.
Önceki hediye kartından çıkarılan metnin daha doğru olup olmadığını görmek için preprocessImage çağıralım.
App.js'yi güncellediğimiz zaman, kod şu şekilde görünmelidir:
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default AppÖncelikle “preprocessImage” dosyasını “preprocess.js” içinden aşağıdaki kod ile import etmemiz gerekiyor:
import preprocessImage from './preprocess'; Ardından, forma bir tuval etiketi ekliyoruz. Hem canvas hem de img etiketlerinin ref özniteliğini sırasıyla { canvasRef } ve { imageRef } imageRef } olarak ayarladık. Referanslar, tuvale ve Uygulama bileşeninden görüntüye erişmek için kullanılır. “useRef” ile hem tuvali hem de görüntüyü şu şekilde elde ederiz:
const canvasRef = useRef(null); const imageRef = useRef(null);Kodun bu bölümünde, JavaScript'te bir tuvali yalnızca ön işleme tabi tutabildiğimiz için görüntüyü tuvalle birleştiriyoruz. Daha sonra, resim formatı olarak "jpeg" olan bir veri URL'sine dönüştürüyoruz.
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");“dataUrl”, işlenecek görüntü olarak Tesseract'a iletilir.
Şimdi, çıkarılan metnin daha doğru olup olmayacağını kontrol edelim.
2. Test

Yukarıdaki resim Firefox'taki sonucu göstermektedir. Görüntünün karanlık kısmının beyaza dönüştürüldüğü aşikar ama görüntüyü ön işleme tabi tutmak daha doğru bir sonuca yol açmaz. Daha da kötü.
İlk dönüştürmede yalnızca iki yanlış karakter var ama bunda dört yanlış karakter var. Eşik seviyesini değiştirmeyi bile denedim ama boşuna. İkilileştirme kötü olduğu için değil, görüntünün ikilileştirilmesi görüntünün doğasını Tesseract motoruna uygun bir şekilde düzeltmediği için daha iyi bir sonuç alamıyoruz.
Chrome'da da nasıl göründüğünü kontrol edelim:

Aynı sonucu alıyoruz.
Görüntüyü ikilileştirerek daha kötü bir sonuç elde ettikten sonra, sorunu çözüp çözemeyeceğimizi görmek için diğer görüntü ön işleme tekniklerini kontrol etmeye ihtiyaç vardır. Şimdi, genişleme, ters çevirme ve bulanıklaştırmayı deneyeceğiz.
Bu makalede kullanılan tekniklerin her birinin kodunu P5.js'den alalım. Görüntü işleme tekniklerini preprocess.js'ye ekleyeceğiz ve bunları tek tek kullanacağız. Kullanmadan önce kullanmak istediğimiz görüntü ön işleme tekniklerinin her birini anlamak gerekir, bu yüzden önce bunları tartışacağız.
Dilatasyon Nedir?
Genişletme, daha geniş, daha büyük veya daha açık hale getirmek için bir görüntüdeki nesnelerin sınırlarına pikseller eklemektir. “dilate” tekniği, görüntülerdeki nesnelerin parlaklığını artırmak için görüntülerimizi önceden işlemek için kullanılır. JavaScript kullanarak görüntüleri genişletmek için bir işleve ihtiyacımız var, bu nedenle bir görüntüyü genişletmek için kod parçacığı preprocess.js'ye eklenir.
Bulanıklık Nedir?
Bulanıklaştırma, bir görüntünün renklerini keskinliğini azaltarak yumuşatmaktır. Bazen görüntülerde küçük noktalar/yamalar olabilir. Bu yamaları kaldırmak için görüntüleri bulanıklaştırabiliriz. Bir görüntüyü bulanıklaştırmaya yönelik kod parçacığı, preprocess.js'ye dahil edilmiştir.
İnversiyon Nedir?
Ters çevirme, bir görüntünün açık renk alanlarını koyu renge ve koyu alanları açık renge dönüştürmektir. Örneğin, bir görüntünün siyah arka planı ve beyaz ön planı varsa, arka planı beyaz ve ön planı siyah olacak şekilde onu tersine çevirebiliriz. Ayrıca bir görüntüyü preprocess.js'ye çevirmek için kod parçacığını da ekledik.
“preprocess.js” dosyasına dilate , invertColors ve blurARGB ekledikten sonra, artık bunları görüntüleri ön işlemek için kullanabiliriz. Bunları kullanmak için, preprocess.js'deki ilk "preprocessImage" işlevini güncellememiz gerekiyor:
preprocessImage(...) şimdi şöyle görünür:
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } Yukarıdaki preprocessImage , bir görüntüye dört ön işleme tekniği uygularız: görüntüdeki noktaları kaldırmak için blurARGB() , görüntünün parlaklığını artırmak için dilate() , görüntünün ön plan ve arka plan rengini değiştirmek için invertColors() ve thresholdFilter() Tesseract dönüşümü için daha uygun olan görüntüyü siyah beyaza dönüştürmek için.
eşikFilter thresholdFilter() parametresi olarak image.data ve level alır. level , görüntünün ne kadar beyaz veya siyah olacağını ayarlamak için kullanılır. Tesseract'ın harika bir sonuç vermesi için görüntünün ne kadar beyaz, koyu veya pürüzsüz olması gerektiğinden emin olmadığımızdan, thresholdFilter seviyesini ve blurRGB yarıçapını deneme yanılma yoluyla belirledik.
3 numaralı test
İşte dört tekniği uyguladıktan sonraki yeni sonuç:

Yukarıdaki resim, hem Chrome'da hem de Firefox'ta elde ettiğimiz sonucu temsil ediyor.
Hata! Sonuç korkunç.
Dört tekniğin hepsini kullanmak yerine neden aynı anda sadece ikisini kullanmıyoruz?
Evet! Görüntüyü siyah beyaza dönüştürmek ve görüntünün ön planını ve arka planını değiştirmek için invertColors ve thresholdFilter tekniklerini kullanabiliriz. Fakat neyi ve hangi teknikleri birleştireceğimizi nasıl bileceğiz? Önceden işlemek istediğimiz görüntünün doğasına göre neyi birleştireceğimizi biliyoruz.
Örneğin, dijital bir görüntünün siyah beyaza dönüştürülmesi ve noktaların/yamaların kaldırılması için yamaları olan bir görüntünün bulanıklaştırılması gerekir. Gerçekten önemli olan, tekniklerin her birinin ne için kullanıldığını anlamaktır.
invertColors ve thresholdFilter kullanmak için, hem blurARGB hem de preprocessImage dilate yorumlamamız gerekir:
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }4 numaralı test
Şimdi, işte yeni sonuç:

Sonuç, herhangi bir ön işleme yapılmamış olandan hala daha kötü. Bu özel görüntü ve diğer bazı görüntüler için tekniklerin her birini ayarladıktan sonra, farklı doğaya sahip görüntülerin farklı ön işleme teknikleri gerektirdiği sonucuna vardım.
Kısacası, Tesseract.js'yi görüntü ön işleme olmadan kullanmak, yukarıdaki hediye kartı için en iyi sonucu verdi. Görüntü ön işleme ile yapılan diğer tüm deneyler daha az doğru sonuçlar verdi.
Konu
Başlangıçta, herhangi bir Amazon hediye kartından PIN'i çıkarmak istedim, ancak bunu başaramadım çünkü tutarlı bir sonuç elde etmek için tutarsız bir PIN'i eşleştirmenin bir anlamı yok. Doğru bir PIN elde etmek için bir görüntüyü işlemek mümkün olsa da, bu tür bir ön işleme, farklı nitelikte başka bir görüntü kullanıldığında tutarsız olacaktır.
Üretilen En İyi Sonuç
Aşağıdaki resim, deneyler tarafından üretilen en iyi sonucu göstermektedir.
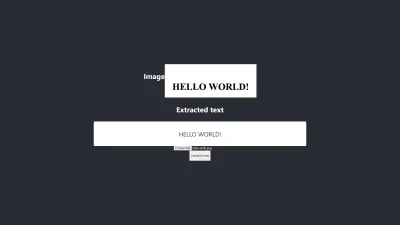
5 numaralı test

Görseldeki metinler ile çıkarılan metinler tamamen aynıdır. Dönüşüm %100 doğruluğa sahiptir. Sonucu yeniden oluşturmaya çalıştım ancak yalnızca benzer nitelikte görüntüler kullanırken yeniden oluşturabildim.
Gözlem ve Dersler
- Ön işleme tabi tutulmamış bazı resimler farklı tarayıcılarda farklı sonuçlar verebilir. Bu iddia ilk testte açıkça görülmektedir. Firefox'taki sonuç, Chrome'dakinden farklıdır. Ancak görüntülerin ön işlenmesi, diğer testlerde tutarlı bir sonuç elde edilmesine yardımcı olur.
- Beyaz zemin üzerine siyah renk, yönetilebilir sonuçlar verme eğilimindedir. Aşağıdaki resim, herhangi bir ön işleme gerektirmeyen doğru bir sonucun bir örneğidir. Ben de görüntüyü önceden işleyerek aynı düzeyde doğruluk elde edebildim ama bu benim için gereksiz olan çok fazla ayar gerektirdi.
Dönüşüm %100 doğrudur.
- Büyük yazı tipi boyutuna sahip bir metin daha doğru olma eğilimindedir.
- Eğri kenarlı yazı tipleri Tesseract'ı karıştırma eğilimindedir. En iyi sonucu Arial (font) kullandığımda elde ettim.
- OCR, şu anda, özellikle %80'den fazla doğruluk düzeyi gerektiğinde, resimden metne dönüştürmeyi otomatikleştirmek için yeterince iyi değil. Bununla birlikte, manuel düzeltme için metinleri ayıklayarak görüntülerdeki metinlerin manuel olarak işlenmesini daha az stresli hale getirmek için kullanılabilir.
- OCR şu anda erişilebilirlik için yararlı bilgileri ekran okuyuculara iletmek için yeterince iyi değil. Bir ekran okuyucuya yanlış bilgi sağlamak, kullanıcıları kolayca yanıltabilir veya dikkatlerini dağıtabilir.
- OCR, sinir ağları öğrenmeyi ve geliştirmeyi mümkün kıldığı için çok umut vericidir. Derin öğrenme, OCR'yi yakın gelecekte oyunun kurallarını değiştirecek hale getirecek .
- Kararları güvenle almak. Uygulamalarımızı büyük ölçüde etkileyebilecek kararlar almak için bir güven puanı kullanılabilir. Güven puanı, bir sonucun kabul edilip edilmeyeceğini belirlemek için kullanılabilir. Tecrübelerime ve deneylerime göre, 90'ın altındaki herhangi bir güven puanının gerçekten yararlı olmadığını anladım. Bir metinden yalnızca bazı pinleri çıkarmam gerekirse, 75 ile 100 arasında bir güven puanı beklerim ve 75'in altındaki her şey reddedilir .
Herhangi bir kısmını çıkarmaya gerek duymadan metinlerle uğraşıyorsam, kesinlikle 90 ile 100 arasında bir güven puanını kabul edeceğim, bunun altındaki puanları reddedeceğim. Örneğin, çek, tarihi bir taslak gibi belgeleri dijitalleştirmek istersem veya tam bir kopyası gerektiğinde 90 ve üzeri doğruluk beklenir. Ancak, bir hediye kartından PIN'i almak gibi tam bir kopyanın önemli olmadığı durumlarda 75 ile 90 arasında bir puan kabul edilebilir. Kısacası, bir güven puanı, uygulamalarımızı etkileyen kararlar almamıza yardımcı olur .
Çözüm
Görüntülerdeki metinlerin neden olduğu veri işleme sınırlaması ve bununla ilişkili dezavantajlar göz önüne alındığında, Optik Karakter Tanıma (OCR), benimsenmesi gereken yararlı bir teknolojidir. OCR'nin sınırlamaları olmasına rağmen, sinir ağlarını kullanması nedeniyle çok umut vericidir.
Zamanla, OCR, derin öğrenme yardımıyla sınırlamalarının çoğunun üstesinden gelecektir, ancak ondan önce, bu makalede vurgulanan yaklaşımlar, en azından, manuel ile ilgili zorlukları ve kayıpları azaltmak için görüntülerden metin çıkarma ile başa çıkmak için kullanılabilir. işleme - özellikle iş açısından.
Artık görüntülerden metin çıkarmak için OCR'yi deneme sırası sizde. İyi şanlar!
Daha fazla okuma
- P5.js
- OCR'de Ön İşleme
- Çıktının kalitesinin iyileştirilmesi
- Görüntüleri OCR için Ön İşleme Etmek İçin JavaScript'i Kullanma
- Tesseract.js ile tarayıcıda OCR
- Optik Karakter Tanımayla İlgili Hızlı Bir Tarihçe
- OCR'nin Geleceği Derin Öğrenmedir
- Optik Karakter Tanıma Zaman Çizelgesi