
HTTP/3: Performans İyileştirmeleri (Bölüm 2)
Yayınlanan: 2022-03-10Yeni HTTP/3 protokolüyle ilgili bu seriye tekrar hoş geldiniz. 1. bölümde, tam olarak neden HTTP/3'e ve temeldeki QUIC protokolüne ihtiyacımız olduğuna ve bunların ana yeni özelliklerinin neler olduğuna baktık.
Bu ikinci bölümde, QUIC ve HTTP/3'ün web sayfası yükleme için tabloya getirdiği performans iyileştirmelerini yakınlaştıracağız. Bununla birlikte, pratikte bu yeni özelliklerden bekleyebileceğimiz etki konusunda biraz şüpheci olacağız.
Göreceğimiz gibi, QUIC ve HTTP/3 gerçekten büyük web performans potansiyeline sahiptir, ancak esas olarak yavaş ağlardaki kullanıcılar için . Ortalama bir ziyaretçiniz hızlı kablolu veya hücresel bir ağdaysa, muhtemelen yeni protokollerden o kadar fazla yararlanamayacaklardır. Bununla birlikte, tipik olarak hızlı yukarı bağlantılara sahip ülkelerde ve bölgelerde bile, hedef kitlenizin en yavaş %1 ila %10'unun ( 99. veya 90. yüzdelik dilimler olarak adlandırılır) hala potansiyel olarak çok şey kazanmaya devam ettiğini unutmayın. Bunun nedeni, HTTP/3 ve QUIC'in temel olarak, günümüzün İnternet'inde ortaya çıkabilecek biraz yaygın olmayan ancak potansiyel olarak yüksek etkili sorunların üstesinden gelmeye yardımcı olmasıdır.
Bu kısım, ilkinden biraz daha tekniktir , ancak gerçekten derin şeylerin çoğunu dış kaynaklara aktarır ve bunların ortalama web geliştiricisi için neden önemli olduğunu açıklamaya odaklanır.
- Bölüm 1: HTTP/3 Tarihçesi ve Temel Kavramlar
Bu makale, genel olarak HTTP/3 ve protokollerde yeni olan kişilere yöneliktir ve temel olarak temelleri tartışır. - Bölüm 2: HTTP/3 Performans Özellikleri
Bu daha ayrıntılı ve teknik. Temel bilgileri zaten bilenler buradan başlayabilir. - Bölüm 3: Pratik HTTP/3 Dağıtım Seçenekleri
Dizideki bu üçüncü makale, HTTP/3'ü kendiniz dağıtmanın ve test etmenin zorluklarını açıklıyor. Web sayfalarınızı ve kaynaklarınızı nasıl ve değiştirmeniz gerekip gerekmediğini ayrıntılarıyla anlatır.
Hız Üzerine Bir Astar
Performansı ve "hızı" tartışmak hızla karmaşıklaşabilir, çünkü birçok temel unsur bir web sayfasının "yavaş" yüklenmesine katkıda bulunur. Burada ağ protokolleri ile ilgilendiğimiz için, esas olarak, ikisi en önemli olan ağ yönlerine bakacağız: gecikme ve bant genişliği.
Gecikme, kabaca A noktasından (örneğin istemci) B noktasına (sunucu) bir paket göndermek için geçen süre olarak tanımlanabilir. Fiziksel olarak ışığın hızıyla veya pratikte sinyallerin kablolarda veya açık havada ne kadar hızlı hareket edebileceğiyle sınırlıdır. Bu, gecikmenin genellikle A ve B arasındaki fiziksel, gerçek dünya mesafesine bağlı olduğu anlamına gelir.
Dünyada bu, tipik gecikmelerin kavramsal olarak küçük olduğu, kabaca 10 ile 200 milisaniye arasında olduğu anlamına gelir. Ancak bu sadece bir yoldur: Paketlere verilen yanıtların da geri gelmesi gerekir. İki yönlü gecikmeye genellikle gidiş-dönüş süresi (RTT) denir.
Tıkanıklık kontrolü (aşağıya bakın) gibi özellikler nedeniyle, tek bir dosyayı bile yüklemek için genellikle birkaç gidiş-dönüş yolculuğuna ihtiyacımız olacaktır. Bu nedenle, 50 milisaniyenin altındaki düşük gecikme süreleri bile önemli gecikmelere neden olabilir. Bu, içerik dağıtım ağlarının (CDN'ler) var olmasının ana nedenlerinden biridir: Gecikmeyi ve dolayısıyla gecikmeyi mümkün olduğunca azaltmak için sunucuları fiziksel olarak son kullanıcıya daha yakın yerleştirirler.
Bant genişliği, kabaca aynı anda gönderilebilecek paket sayısı olarak söylenebilir. Bunu açıklamak biraz daha zordur, çünkü ortamın fiziksel özelliklerine (örneğin, radyo dalgalarının kullanılan frekansı), ağdaki kullanıcı sayısına ve ayrıca farklı alt ağları birbirine bağlayan cihazlara (çünkü bunlar tipik olarak saniyede yalnızca belirli sayıda paketi işleyebilir).
Sık kullanılan bir metafor, suyu taşımak için kullanılan bir boru metaforudur. Borunun uzunluğu gecikme, borunun genişliği ise bant genişliğidir. Bununla birlikte, İnternette, tipik olarak, bazıları diğerlerinden daha geniş olabilen (en dar bağlantılarda darboğazlara yol açan) uzun bir dizi bağlantılı boruya sahibiz. Bu nedenle, A ve B noktaları arasındaki uçtan uca bant genişliği genellikle en yavaş alt bölümlerle sınırlıdır.
Bu yazının geri kalanı için bu kavramların mükemmel bir şekilde anlaşılması gerekmese de, ortak bir üst düzey tanıma sahip olmak iyi olur. Daha fazla bilgi için Ilya Grigorik'in High Performance Browser Networking adlı kitabında gecikme ve bant genişliği hakkındaki mükemmel bölümüne göz atmanızı tavsiye ederim.
Tıkanıklık Kontrolü
Performansın bir yönü, bir taşıma protokolünün bir ağın tam (fiziksel) bant genişliğini ne kadar verimli kullanabildiğiyle ilgilidir (yani kabaca saniyede kaç paket gönderilebilir veya alınabilir). Bu da bir sayfanın kaynaklarının ne kadar hızlı indirilebileceğini etkiler. Bazıları QUIC'in bir şekilde bunu TCP'den çok daha iyi yaptığını iddia ediyor, ancak bu doğru değil.
Biliyor musun?
Örneğin, bir TCP bağlantısı tam bant genişliğinde veri göndermeye başlamaz çünkü bu, ağın aşırı yüklenmesine (veya tıkanmasına) neden olabilir. Bunun nedeni, dediğimiz gibi, her ağ bağlantısının her saniye (fiziksel olarak) işleyebileceği yalnızca belirli bir miktarda veriye sahip olmasıdır. Daha fazlasını verin ve aşırı paketleri bırakmaktan başka seçenek yok, bu da paket kaybına neden oluyor.
Bölüm 1'de tartışıldığı gibi, TCP gibi güvenilir bir protokol için, paket kaybından kurtulmanın tek yolu, bir gidiş-dönüş süren verilerin yeni bir kopyasını yeniden iletmektir. Özellikle yüksek gecikmeli ağlarda (örneğin, 50 milisaniyenin üzerinde bir RTT ile), paket kaybı performansı ciddi şekilde etkileyebilir.
Diğer bir problem ise maksimum bant genişliğinin ne kadar olacağını önceden bilmememizdir. Genellikle uçtan uca bağlantıda bir yerde bir darboğaza bağlıdır, ancak bunun nerede olacağını tahmin edemeyiz veya bilemeyiz. İnternet ayrıca bağlantı kapasitelerini uç noktalara geri gönderecek mekanizmalara (henüz) sahip değildir.
Ek olarak, mevcut fiziksel bant genişliğini bilsek bile, bu, hepsini kendimiz kullanabileceğimiz anlamına gelmez. Tipik olarak, her biri mevcut bant genişliğinden adil bir paya ihtiyaç duyan birkaç kullanıcı bir ağda aynı anda aktiftir.
Bu nedenle, bir bağlantı ne kadar bant genişliğini güvenli veya adil bir şekilde kullanabileceğini önceden bilemez ve bu bant genişliği kullanıcılar ağa katılırken, ağdan ayrılırken ve onu kullanırken değişebilir. Bu sorunu çözmek için TCP, tıkanıklık kontrolü adı verilen bir mekanizma kullanarak sürekli olarak kullanılabilir bant genişliğini zaman içinde keşfetmeye çalışacaktır.
Bağlantının başlangıcında, yalnızca birkaç paket gönderir (pratikte, 10 ila 100 paket arasında veya yaklaşık 14 ila 140 KB veri arasında değişir) ve alıcı bu paketlerin onaylarını geri gönderene kadar bir gidiş-dönüş bekler. Hepsi onaylanırsa, bu, ağın bu gönderme hızını işleyebileceği anlamına gelir ve işlemi daha fazla veriyle tekrarlamayı deneyebiliriz (pratikte, gönderme hızı genellikle her yinelemede ikiye katlanır).
Bu şekilde, bazı paketler onaylanmayana kadar gönderme hızı artmaya devam eder (bu, paket kaybını ve ağ tıkanıklığını gösterir). Bu ilk aşamaya genellikle "yavaş başlangıç" denir. Paket kaybının algılanması üzerine, TCP gönderme hızını düşürür ve (bir süre sonra) gönderme hızını (çok) daha küçük artışlarla da olsa tekrar artırmaya başlar. Bu azalt-sonra-büyüt mantığı, sonrasındaki her paket kaybı için tekrarlanır. Sonunda bu, TCP'nin sürekli olarak ideal, adil bant genişliği payına ulaşmaya çalışacağı anlamına gelir. Bu mekanizma şekil 1'de gösterilmektedir.
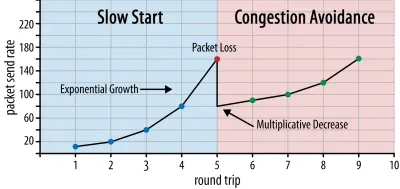
Bu, tıkanıklık kontrolünün son derece basitleştirilmiş bir açıklamasıdır. Uygulamada, arabellek şişkinliği, tıkanıklık nedeniyle RTT'lerin dalgalanması ve birden fazla eşzamanlı göndericinin bant genişliğinden adil pay alması gerektiği gerçeği gibi birçok başka faktör rol oynamaktadır. Bu nedenle, birçok farklı tıkanıklık kontrol algoritması mevcuttur ve hiçbiri her durumda en iyi şekilde performans göstermeden bugün hala pek çok şey icat edilmektedir.
TCP'nin tıkanıklık kontrolü onu sağlam kılarken, aynı zamanda RTT'ye ve mevcut mevcut bant genişliğine bağlı olarak optimum gönderme hızlarına ulaşmanın biraz zaman alacağı anlamına gelir. Web sayfası yükleme için, bu yavaş başlangıç yaklaşımı, ilk içerikli boyama gibi ölçümleri de etkileyebilir, çünkü ilk birkaç gidiş dönüşte yalnızca küçük miktarda veri (onlarca ila birkaç yüz KB) aktarılabilir. (Kritik verilerinizi 14 KB'den küçük tutma önerisini duymuş olabilirsiniz.)
Bu nedenle, daha agresif bir yaklaşım seçmek, özellikle ara sıra paket kaybını umursamıyorsanız, yüksek bant genişliğine ve yüksek gecikmeye sahip ağlarda daha iyi sonuçlara yol açabilir. QUIC'in nasıl çalıştığına dair birçok yanlış yorumlamayı yine burada gördüm.
Bölüm 1'de tartışıldığı gibi, QUIC teorik olarak paket kaybından (ve ilgili hat başı (HOL) engellemesinden) daha az muzdariptir çünkü her kaynağın bayt akışındaki paket kaybını bağımsız olarak ele alır. Ek olarak, QUIC, TCP'nin aksine yerleşik bir tıkanıklık denetimi özelliği bulunmayan Kullanıcı Datagram Protokolü (UDP) üzerinden çalışır; istediğiniz hızda göndermeyi denemenize izin verir ve kaybolan verileri yeniden iletmez.
Bu, QUIC'in tıkanıklık kontrolü kullanmadığını, QUIC'in bunun yerine UDP'ye göre çok daha yüksek bir hızda veri göndermeye başlayabileceğini (paket kaybıyla başa çıkmak için HOL engellemesinin kaldırılmasına dayanarak) iddia eden birçok makaleye yol açtı. QUIC, TCP'den çok daha hızlıdır.
Gerçekte, hiçbir şey gerçeğin ötesinde olamaz: QUIC aslında TCP ile çok benzer bant genişliği yönetimi teknikleri kullanır . O da daha düşük bir gönderme hızıyla başlar ve onayları ağ kapasitesini ölçmek için anahtar bir mekanizma olarak kullanarak zamanla büyütür. Bu (diğer nedenlerin yanı sıra) çünkü QUIC'in HTTP gibi bir şey için yararlı olması için güvenilir olması gerekiyor, çünkü diğer QUIC (ve TCP!) bağlantılarına karşı adil olması gerekiyor ve HOL engellemesini kaldırmadığı için aslında paket kaybına karşı o kadar iyi yardımcı olur (aşağıda göreceğimiz gibi).
Ancak bu, QUIC'in bant genişliğini yönetme konusunda TCP'den (biraz) daha akıllı olamayacağı anlamına gelmez. Bunun temel nedeni , QUIC'in TCP'den daha esnek ve geliştirilmesi daha kolay olmasıdır . Söylediğimiz gibi, tıkanıklık kontrol algoritmaları bugün hala yoğun bir şekilde gelişiyor ve örneğin 5G'den en iyi şekilde yararlanmak için muhtemelen bazı şeyleri değiştirmemiz gerekecek.
Bununla birlikte, TCP tipik olarak, çoğu işletim sistemi için açık kaynak bile olmayan güvenli ve daha kısıtlı bir ortam olan işletim sisteminin (OS') çekirdeğinde uygulanır. Bu nedenle, tıkanıklık mantığının ayarlanması genellikle yalnızca birkaç seçkin geliştirici tarafından yapılır ve evrim yavaştır.
Buna karşılık, çoğu QUIC uygulaması şu anda "kullanıcı alanında" (genellikle yerel uygulamaları çalıştırdığımız yerde) yapılıyor ve çok daha geniş bir geliştirici havuzunun (önceden gösterildiği gibi, örneğin Facebook tarafından gösterildiği gibi) denemeyi açıkça teşvik etmek için açık kaynak haline getiriliyor. ).
Başka bir somut örnek, QUIC için gecikmeli alındı bildirimi frekans uzantısı önerisidir. Varsayılan olarak, QUIC alınan her 2 paket için bir alındı bilgisi gönderirken, bu uzantı uç noktaların örneğin her 10 pakette bir onay vermesine izin verir. Bunun uydu ve çok yüksek bant genişliğine sahip ağlarda büyük hız avantajları sağladığı gösterilmiştir, çünkü alındı paketlerini iletme ek yükü azaltılmıştır. TCP için böyle bir uzantı eklemenin benimsenmesi uzun zaman alırken, QUIC için dağıtılması çok daha kolay.
Bu nedenle, QUIC'in esnekliğinin zaman içinde daha fazla denemeye ve daha iyi tıkanıklık kontrol algoritmalarına yol açmasını bekleyebiliriz ve bu da onu geliştirmek için TCP'ye geri aktarılabilir.
Biliyor musun?
Resmi QUIC Recovery RFC 9002, NewReno tıkanıklık kontrol algoritmasının kullanımını belirtir. Bu yaklaşım sağlam olmakla birlikte, aynı zamanda biraz eskidir ve artık pratikte yaygın olarak kullanılmamaktadır. Peki neden QUIC RFC'de? İlk neden, QUIC başlatıldığında, NewReno'nun kendisi standartlaştırılmış en yeni tıkanıklık kontrol algoritması olmasıydı. BBR ve CUBIC gibi daha gelişmiş algoritmalar ya hala standartlaştırılmamıştır ya da yakın zamanda RFC'ler haline gelmiştir.
İkinci neden, NewReno'nun nispeten basit bir kurulum olmasıdır. Algoritmalar, QUIC'in TCP'den farklarıyla başa çıkmak için birkaç ince ayar gerektirdiğinden, bu değişiklikleri daha basit bir algoritma üzerinde açıklamak daha kolaydır. Bu nedenle, RFC 9002, "QUIC için kullanmanız gereken şey budur" yerine "bir tıkanıklık kontrol algoritmasını QUIC'ye nasıl uyarlanır" olarak okunmalıdır. Gerçekten de, üretim düzeyindeki QUIC uygulamalarının çoğu, hem Cubic hem de BBR için özel uygulamalar yapmıştır.
Tıkanıklık kontrol algoritmalarının TCP veya QUIC'e özgü olmadığını tekrar etmekte fayda var; her iki protokol tarafından da kullanılabilirler ve umut, QUIC'deki ilerlemelerin sonunda TCP yığınlarına da ulaşacağıdır.
Biliyor musun?
Tıkanıklık kontrolünün yanında akış kontrolü adı verilen ilgili bir kavram olduğunu unutmayın. Bu iki özellik genellikle TCP'de karıştırılır, çünkü aslında iki pencere olmasına rağmen her ikisinin de "TCP penceresini" kullandığı söylenir: tıkanıklık penceresi ve TCP alma penceresi. Bununla birlikte, ilgilendiğimiz web sayfası yükleme kullanım durumu için akış kontrolü çok daha az devreye giriyor, bu yüzden burada atlayacağız. Daha ayrıntılı bilgi mevcuttur.
Tüm bunların anlamı ne?
QUIC hala fizik yasalarına ve İnternet'teki diğer göndericilere karşı nazik olma ihtiyacına bağlıdır. Bu, web sitesi kaynaklarınızı sihirli bir şekilde TCP'den çok daha hızlı indirmeyeceği anlamına gelir. Bununla birlikte, QUIC'in esnekliği, yeni tıkanıklık kontrol algoritmaları ile denemelerin daha kolay olacağı anlamına gelir; bu, gelecekte hem TCP hem de QUIC için işleri iyileştirecektir.
0-RTT Bağlantı Kurulumu
İkinci bir performans yönü, yeni bir bağlantıda faydalı HTTP verilerini (örneğin, sayfa kaynakları) gönderebilmeniz için önce kaç gidiş -dönüş yapılması gerektiğidir. Bazıları QUIC'in TCP + TLS'den iki hatta üç daha hızlı olduğunu iddia ediyor, ancak bunun gerçekten sadece bir tane olduğunu göreceğiz.
Biliyor musun?
Bölüm 1'de söylediğimiz gibi, bir bağlantı genellikle HTTP istekleri ve yanıtları değiş tokuş edilmeden önce bir (TCP) veya iki (TCP + TLS) el sıkışması gerçekleştirir. Bu el sıkışmaları, örneğin verileri şifrelemek için hem istemcinin hem de sunucunun bilmesi gereken ilk parametreleri değiştirir.
Aşağıdaki şekil 2'de görebileceğiniz gibi, her bir el sıkışmanın tamamlanması en az bir gidiş-dönüş (TCP + TLS 1.3, (b)) ve bazen iki (TLS 1.2 ve önceki (a)) sürer. Bu verimsizdir, çünkü ilk HTTP isteğimizi gönderebilmemiz için en az iki el sıkışma bekleme süresine (üstten) ihtiyacımız vardır, bu da ilk HTTP yanıt verilerinin (dönen kırmızı ok) gelmesi için en az üç gidiş dönüş beklemek anlamına gelir. yavaş ağlarda, bu 100 ila 200 milisaniyelik bir ek yük anlamına gelebilir.
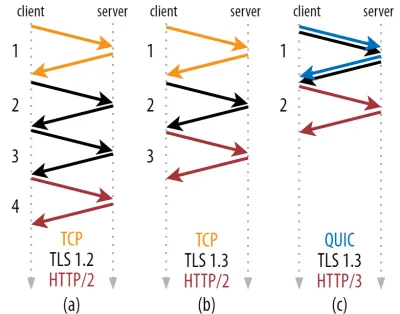
TCP + TLS anlaşmasının neden aynı gidiş-dönüşte basitçe birleştirilemediğini merak ediyor olabilirsiniz. Bu kavramsal olarak mümkün olsa da (QUIC tam olarak bunu yapıyor), başlangıçta işler böyle tasarlanmamıştı, çünkü TCP'yi TLS ile ve TLS olmadan kullanabilmemiz gerekiyor. Başka bir deyişle, TCP, el sıkışma sırasında TCP olmayan öğelerin gönderilmesini desteklemez . Bunu TCP Fast Open uzantısıyla eklemek için çabalar olmuştur; ancak, 1. bölümde tartışıldığı gibi, bunun geniş ölçekte dağıtılmasının zor olduğu ortaya çıktı.
Neyse ki, QUIC başından beri TLS düşünülerek tasarlandı ve bu nedenle hem taşıma hem de kriptografik el sıkışmalarını tek bir mekanizmada birleştiriyor. Bu, QUIC anlaşmasının tamamlanması için toplamda yalnızca bir gidiş-dönüş olacağı anlamına gelir, bu da TCP + TLS 1.3'ten bir gidiş-dönüş daha azdır (yukarıdaki şekil 2c'ye bakın).
Kafanız karışmış olabilir, çünkü muhtemelen QUIC'in TCP'den iki hatta üç gidiş dönüş daha hızlı olduğunu okumuşsunuzdur, sadece bir değil. Bunun nedeni, çoğu makalenin yalnızca en kötü durumu dikkate almasıdır (TCP + TLS 1.2, (a))), modern TCP + TLS 1.3'ün de "yalnızca" iki gidiş dönüş yaptığından ((b) nadiren gösterilmektedir). Bir gidiş-dönüş hız artışı güzel olsa da, şaşırtıcı değil. Özellikle hızlı ağlarda (örneğin, 50 milisaniyeden daha kısa bir RTT'den daha az), yavaş ağlar ve uzak sunuculara bağlantılar biraz daha fazla fayda sağlasa da, bu zorlukla fark edilecektir.
Ardından, el sıkışma(lar)ını neden beklememiz gerektiğini merak ediyor olabilirsiniz. İlk gidiş dönüşte neden bir HTTP isteği gönderemiyoruz? Bunun başlıca nedeni, eğer yapsaydık, o zaman ilk isteğin şifrelenmemiş olarak gönderilmesi ve kablodaki herhangi bir dinleyici tarafından okunabilmesidir, bu açıkça gizlilik ve güvenlik için pek iyi değildir. Bu nedenle, ilk HTTP isteğini göndermeden önce kriptografik el sıkışmanın tamamlanmasını beklememiz gerekir. Yoksa biz mi?
Pratikte akıllıca bir numaranın kullanıldığı yer burasıdır. Kullanıcıların genellikle ilk ziyaretlerinden kısa bir süre sonra web sayfalarını tekrar ziyaret ettiklerini biliyoruz. Bu nedenle, gelecekte ikinci bir bağlantıyı önyüklemek için ilk şifreli bağlantıyı kullanabiliriz. Basitçe söylemek gerekirse, kullanım ömrü boyunca ilk bağlantı, istemci ve sunucu arasında yeni kriptografik parametreleri güvenli bir şekilde iletmek için kullanılır. Bu parametreler daha sonra, tam TLS anlaşmasının tamamlanmasını beklemek zorunda kalmadan ikinci bağlantıyı en baştan şifrelemek için kullanılabilir. Bu yaklaşıma “oturum yeniden başlatma” denir.
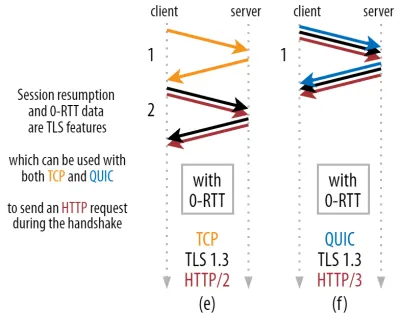
Güçlü bir optimizasyona izin verir: Artık ilk HTTP isteğimizi QUIC/TLS anlaşmasıyla birlikte güvenle gönderebiliriz, bu da başka bir gidiş-dönüşten tasarruf sağlar! TLS 1.3'e gelince, bu TLS anlaşmasının bekleme süresini etkili bir şekilde ortadan kaldırır. Bu yöntem genellikle 0-RTT olarak adlandırılır (tabii ki, HTTP yanıt verilerinin gelmeye başlaması yine de bir gidiş-dönüş sürer).
Hem oturumu sürdürme hem de 0-RTT, yine, QUIC'e özgü özellikler olarak yanlış bir şekilde açıklandığını gördüğüm şeylerdir. Gerçekte, bunlar aslında bir şekilde TLS 1.2'de mevcut olan ve şimdi TLS 1.3'te tam olarak teşekkül eden TLS özellikleridir .
Başka bir deyişle, aşağıdaki şekil 3'te görebileceğiniz gibi, bu özelliklerin performans avantajlarını TCP (ve dolayısıyla HTTP/2 ve hatta HTTP/1.1) üzerinden de elde edebiliriz! 0-RTT ile bile QUIC'in optimal olarak çalışan bir TCP + TLS 1.3 yığınından yalnızca bir gidiş dönüş daha hızlı olduğunu görüyoruz. QUIC'in üç gidiş-dönüş daha hızlı olduğu iddiası, şekil 2'nin (a) ile şekil 3'ün (f) karşılaştırılmasından kaynaklanmaktadır, ki bu gördüğümüz gibi gerçekten adil değildir.
En kötü yanı, 0-RTT kullanırken, QUIC'in güvenlik nedeniyle bu kazanılan gidiş dönüşünü o kadar iyi kullanamamasıdır. Bunu anlamak için TCP anlaşmasının var olmasının nedenlerinden birini anlamamız gerekiyor. İlk olarak, istemcinin herhangi bir üst katman verisini göndermeden önce sunucunun verilen IP adresinde gerçekten kullanılabilir olduğundan emin olmasını sağlar.
İkincisi ve burada en önemlisi, sunucunun, bağlantıyı açan istemcinin, verileri göndermeden önce gerçekte kim ve nerede olduğunu söylediğinden emin olmasını sağlar. Bölüm 1'de 4 demet ile nasıl bir bağlantı tanımladığımızı hatırlarsanız, istemcinin esas olarak IP adresiyle tanımlandığını bilirsiniz. Sorun da şu: IP adresleri sahte olabilir !
Bir saldırganın QUIC 0-RTT üzerinden HTTP aracılığıyla çok büyük bir dosya istediğini varsayalım. Ancak, IP adreslerini taklit ederek 0-RTT isteği kurbanlarının bilgisayarından gelmiş gibi görünürler. Bu, aşağıdaki şekil 4'te gösterilmiştir. QUIC sunucusunun IP'nin sahte olup olmadığını algılamasının hiçbir yolu yoktur, çünkü bu, o istemciden gördüğü ilk paket(ler)dir.

Sunucu daha sonra büyük dosyayı sahte IP'ye geri göndermeye başlarsa , kurbanın ağ bant genişliğinin aşırı yüklenmesine neden olabilir (özellikle saldırgan bu sahte isteklerin çoğunu paralel olarak yapacaksa). QUIC yanıtının kurban tarafından bırakılacağını unutmayın, çünkü gelen verileri beklemez, ancak bunun bir önemi yoktur: Ağlarının hala paketleri işlemesi gerekiyor!
Buna yansıma veya büyütme saldırısı denir ve bilgisayar korsanlarının dağıtılmış hizmet reddi (DDoS) saldırıları gerçekleştirmesinin önemli bir yoludur. Bunun TCP + TLS üzerinden 0-RTT kullanıldığında gerçekleşmediğini unutmayın, çünkü tam olarak TCP anlaşmasının, TLS anlaşmasıyla birlikte 0-RTT isteği gönderilmeden önce tamamlanması gerekir.
Bu nedenle, QUIC, 0-RTT isteklerine yanıt vermede ihtiyatlı olmalı ve müşterinin kurban değil gerçek bir müşteri olduğu doğrulanana kadar yanıt olarak ne kadar veri göndereceğini sınırlandırmalıdır. QUIC için bu veri miktarı, müşteriden alınan miktarın üç katına ayarlanmıştır.
Başka bir deyişle, QUIC, performans kullanışlılığı ve güvenlik riski arasında kabul edilebilir bir ödünleşim olduğu belirlenen maksimum "yükseltme faktörüne" sahiptir (özellikle 51.000 katın üzerinde bir yükseltme faktörüne sahip bazı olaylarla karşılaştırıldığında). İstemci tipik olarak önce yalnızca bir ila iki paket gönderdiğinden, QUIC sunucusunun 0-RTT yanıtı yalnızca 4 ila 6 KB (diğer QUIC ve TLS ek yükleri dahil!) ile sınırlandırılacaktır , bu etkileyici olmaktan biraz daha azdır.
Ek olarak, diğer güvenlik sorunları, örneğin yapabileceğiniz HTTP isteğinin türünü sınırlayan "tekrarlama saldırılarına" yol açabilir. Örneğin, Cloudflare, 0-RTT'de sorgu parametreleri olmadan yalnızca HTTP GET isteklerine izin verir. Bunlar, 0-RTT'nin kullanışlılığını daha da sınırlar.
Neyse ki, QUIC bunu biraz daha iyi hale getirmek için seçeneklere sahip. Örneğin, sunucu 0-RTT'nin daha önce geçerli bir bağlantısı olan bir IP'den gelip gelmediğini kontrol edebilir. Ancak, bu yalnızca istemci aynı ağda kalırsa çalışır (QUIC'in bağlantı geçiş özelliğini bir şekilde sınırlar). Ve işe yarasa bile, QUIC'in yanıtı yine de tıkanıklık denetleyicisinin yukarıda tartıştığımız yavaş başlangıç mantığıyla sınırlıdır; bu nedenle, kaydedilen bir gidiş dönüş dışında ekstra büyük bir hız artışı yoktur .
Biliyor musun?
QUIC'in üç kat amplifikasyon sınırının, şekil 2c'deki normal 0-RTT olmayan el sıkışma süreci için de geçerli olduğunu belirtmek ilginçtir. Örneğin, sunucunun TLS sertifikası 4 ila 6 KB'ye sığmayacak kadar büyükse bu bir sorun olabilir. Bu durumda, ikinci parçanın ikinci gidiş dönüşünün gönderilmesini beklemek zorunda kalacak şekilde bölünmesi gerekir (ilk birkaç paketin onayları geldikten sonra, bu da müşterinin IP'sinin sahte olmadığını gösterir). Bu durumda, QUIC'in anlaşması yine de TCP + TLS'ye eşit iki gidiş-dönüşle sonuçlanabilir ! Bu nedenle QUIC için sertifika sıkıştırma gibi teknikler ekstra önemli olacaktır.
Biliyor musun?
Bazı gelişmiş kurulumların, 0-RTT'yi daha kullanışlı hale getirmek için bu sorunları yeterince azaltabilmesi olabilir. Örneğin, sunucu, bir istemcinin en son görüldüğünde ne kadar bant genişliğine sahip olduğunu hatırlayabilir ve bu, tıkanıklık kontrolünün istemcileri yeniden bağlamak için yavaş başlamasıyla (dolandırıcılık yapılmamış) daha az sınırlı hale getirebilir. Bu, akademide araştırılmıştır ve bunu yapmak için QUIC'de önerilen bir uzantı bile vardır. Birkaç şirket zaten TCP'yi hızlandırmak için bu tür şeyler yapıyor.
Başka bir seçenek, istemcilerin bir veya ikiden fazla paket göndermesini sağlamak olabilir (örneğin, dolgulu 7 paket daha gönderme), bu nedenle üç kat sınırı, bağlantı geçişinden sonra bile 12 ila 14 KB arasında daha ilginç bir yanıta dönüşür. Bunu gazetelerimden birinde yazmıştım.
Son olarak, (yanlış davranan) QUIC sunucuları, bunu yapmanın bir şekilde güvenli olduğunu düşünürlerse veya olası güvenlik sorunlarını umursamazlarsa (sonuçta, bunu önleyen bir protokol polisi yoktur) kasıtlı olarak üç kat sınırını artırabilirler.
Tüm bunların anlamı ne?
QUIC'in 0-RTT ile daha hızlı bağlantı kurulumu, devrim niteliğindeki yeni bir özellikten çok bir mikro optimizasyondur . Son teknoloji ürünü bir TCP + TLS 1.3 kurulumuyla karşılaştırıldığında, maksimum bir gidiş-dönüş tasarrufu sağlar. İlk gidiş-dönüşte gerçekten gönderilebilecek veri miktarı, ek olarak bir takım güvenlik hususları ile sınırlıdır.
Bu nedenle, bu özellik çoğunlukla, kullanıcılarınız çok yüksek gecikme süresine sahip ağlardaysa (örneğin, 200 milisaniyeden fazla RTT'ye sahip uydu ağlarında) veya genellikle fazla veri göndermiyorsanız öne çıkacaktır. İkincisinin bazı örnekleri, yoğun şekilde önbelleğe alınmış web siteleri ve API'ler ve DNS-over-QUIC gibi diğer protokoller aracılığıyla periyodik olarak küçük güncellemeler getiren tek sayfalı uygulamalardır. Google'ın QUIC için çok iyi 0-RTT sonuçları görmesinin nedenlerinden biri, onu, sorgu yanıtlarının oldukça küçük olduğu, zaten yoğun şekilde optimize edilmiş arama sayfasında test etmesiydi.
Diğer durumlarda, en iyi ihtimalle yalnızca birkaç düzine milisaniye kazanırsınız, zaten bir CDN kullanıyorsanız daha da az kazanırsınız (performansa önem veriyorsanız bunu yapmalısınız!).
Bağlantı Taşıma
Üçüncü bir performans özelliği, mevcut bağlantıları olduğu gibi koruyarak ağlar arasında aktarım yaparken QUIC'i daha hızlı hale getirir. Bu gerçekten işe yarıyor olsa da, bu tür ağ değişikliği o kadar sık olmaz ve bağlantıların yine de gönderme oranlarını sıfırlaması gerekir.
Bölüm 1'de tartışıldığı gibi, QUIC'in bağlantı kimlikleri (CID'ler), ağlar arasında geçiş yaparken bağlantı geçişi gerçekleştirmesine izin verir. Bunu, büyük bir dosya indirme işlemi yaparken bir Wi-Fi ağından 4G'ye geçen bir istemciyle gösterdik. TCP'de bu indirmenin durdurulması gerekebilirken QUIC için devam edebilir.
Ancak önce, bu tür bir senaryonun gerçekte ne sıklıkta gerçekleştiğini düşünün. Bunun, bir bina içindeki Wi-Fi erişim noktaları arasında veya yoldayken hücresel kuleler arasında hareket ederken de meydana geldiğini düşünebilirsiniz. Ancak bu kurulumlarda (doğru yapılırsa), kablosuz baz istasyonları arasındaki geçiş daha düşük bir protokol katmanında yapıldığından, cihazınız IP'sini genellikle olduğu gibi tutacaktır. Bu nedenle, yalnızca tamamen farklı ağlar arasında geçiş yaptığınızda ortaya çıkar, ki bunun o kadar sık olmadığını söyleyebilirim.
İkinci olarak, bunun büyük dosya indirmeleri ve canlı video konferans ve akışın yanı sıra diğer kullanım durumları için de işe yarayıp yaramadığını sorabiliriz. Tam ağ değiştirme anında bir web sayfası yüklüyorsanız, (daha sonra) kaynakların bir kısmını gerçekten yeniden istemeniz gerekebilir.
Bununla birlikte, bir sayfanın yüklenmesi genellikle birkaç saniye sürer, bu nedenle bir ağ anahtarına denk gelmek de çok yaygın olmayacaktır. Ek olarak, bunun acil bir sorun olduğu kullanım durumları için, diğer azaltıcı önlemler genellikle zaten mevcuttur . Örneğin, büyük dosya indirmeleri sunan sunucular, devam ettirilebilir indirmelere izin vermek için HTTP aralığı isteklerini destekleyebilir.
Ağ 1'in devre dışı bırakılması ile ağ 2'nin kullanılabilir hale gelmesi arasında genellikle bir miktar çakışma süresi olduğundan, video uygulamaları birden fazla bağlantı (ağ başına 1) açarak eski ağ tamamen kaybolmadan önce bunları senkronize edebilir. Kullanıcı yine de geçişi fark edecek, ancak video akışını tamamen bırakmayacak.
Üçüncüsü, yeni ağın eskisi kadar kullanılabilir bant genişliğine sahip olacağının garantisi yoktur. Bu nedenle, kavramsal bağlantı bozulmadan tutulsa bile, QUIC sunucusu yalnızca yüksek hızlarda veri göndermeye devam edemez. Bunun yerine, yeni ağın aşırı yüklenmesini önlemek için , gönderme hızını sıfırlaması (veya en azından düşürmesi) ve tıkanıklık denetleyicisinin yavaş başlatma aşamasında yeniden başlaması gerekir.
Bu ilk gönderme hızı, video akışı gibi şeyleri gerçekten desteklemek için genellikle çok düşük olduğundan, QUIC'de bile bazı kalite kayıpları veya hıçkırıklar göreceksiniz. Bir bakıma, bağlantı geçişi, performansı artırmaktan çok, sunucuda bağlantı bağlamındaki karışıklığı ve ek yükü önlemekle ilgilidir.
Biliyor musun?
Yukarıda 0-RTT için tartışıldığı gibi, bağlantı geçişini iyileştirmek için bazı gelişmiş teknikler geliştirebileceğimizi unutmayın. Örneğin, geçen sefer belirli bir ağda ne kadar bant genişliğinin mevcut olduğunu tekrar hatırlamaya çalışabilir ve yeni bir geçiş için bu seviyeye daha hızlı yükselmeye çalışabiliriz. Ek olarak, sadece ağlar arasında geçiş yapmayı değil, her ikisini de aynı anda kullanmayı düşünebiliriz. Bu kavram multipath olarak adlandırılır ve aşağıda daha ayrıntılı olarak tartışacağız.
Şimdiye kadar, ağırlıklı olarak, kullanıcıların farklı ağlar arasında hareket ettiği aktif bağlantı geçişinden bahsettik. Bununla birlikte, belirli bir ağın kendisinin parametreleri değiştirdiği pasif bağlantı geçişi durumları da vardır. Buna iyi bir örnek, ağ adresi çevirisi (NAT) yeniden bağlamadır. NAT hakkında tam bir tartışma bu makalenin kapsamı dışında olsa da, esas olarak bağlantının bağlantı noktası numaralarının herhangi bir zamanda herhangi bir uyarı olmaksızın değişebileceği anlamına gelir. Bu aynı zamanda UDP için çoğu yönlendiricide TCP'den çok daha sık gerçekleşir.
Bu gerçekleşirse, QUIC CID değişmez ve çoğu uygulama, kullanıcının hala aynı fiziksel ağda olduğunu varsayar ve bu nedenle tıkanıklık penceresini veya diğer parametreleri sıfırlamaz. QUIC, bunun olmasını önlemek için PING'ler ve zaman aşımı göstergeleri gibi bazı özellikler de içerir, çünkü bu genellikle uzun süre boşta kalan bağlantılar için gerçekleşir.
QUIC'in güvenlik nedenleriyle yalnızca tek bir CID kullanmadığını 1. bölümde tartışmıştık. Bunun yerine, etkin geçiş gerçekleştirirken CID'leri değiştirir. Uygulamada, daha da karmaşıktır, çünkü hem istemci hem de sunucu ayrı CID listelerine sahiptir (QUIC RFC'de kaynak ve hedef CID'ler olarak adlandırılır). Bu, aşağıdaki şekil 5'te gösterilmektedir.
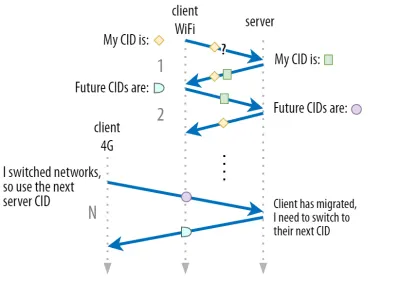
Bu, her uç noktanın kendi CID biçimini ve içeriğini seçmesine izin vermek için yapılır ve bu da gelişmiş yönlendirme ve yük dengeleme mantığına izin vermek için çok önemlidir. Bağlantı geçişiyle, yük dengeleyiciler artık bir bağlantıyı belirlemek ve doğru arka uç sunucusuna göndermek için 4 demete bakamaz. Ancak, tüm QUIC bağlantıları rastgele CID'ler kullanacak olsaydı, bu, CID'lerin arka uç sunucularına eşlemelerini depolaması gerekeceğinden, yük dengeleyicideki bellek gereksinimlerini büyük ölçüde artırırdı. Ayrıca, CID'ler yeni rastgele değerlere dönüştüğü için bu, bağlantı geçişi ile yine de çalışmaz.
Bu nedenle, bir yük dengeleyicinin arkasında dağıtılan QUIC arka uç sunucularının, CID'lerinin öngörülebilir bir biçimine sahip olması önemlidir, böylece yük dengeleyici, geçişten sonra bile CID'den doğru arka uç sunucusunu türetebilir. Bunu yapmak için bazı seçenekler, IETF'nin önerilen belgesinde açıklanmıştır. Tüm bunları mümkün kılmak için, sunucuların kendi CID'lerini seçebilmeleri gerekir; bu, bağlantı başlatıcısı (QUIC için her zaman istemcidir) CID'yi seçerse bu mümkün olmaz. Bu nedenle QUIC'de istemci ve sunucu CID'leri arasında bir ayrım vardır.

Tüm bunların anlamı ne?
Bu nedenle, bağlantı geçişi durumsal bir özelliktir. Örneğin, Google tarafından yapılan ilk testler, kullanım durumları için düşük yüzdeli iyileştirmeler gösteriyor. Birçok QUIC uygulaması bu özelliği henüz uygulamamaktadır. Bunu yapanlar bile, genellikle onu masaüstü eşdeğerleriyle değil, mobil istemciler ve uygulamalarla sınırlayacaktır. Hatta bazı kişiler, 0-RTT ile yeni bir bağlantı açmanın çoğu durumda benzer performans özelliklerine sahip olması gerektiğinden, özelliğin gerekli olmadığı görüşündedir.
Yine de, kullanım durumunuza veya kullanıcı profilinize bağlı olarak büyük bir etkisi olabilir. Web siteniz veya uygulamanız en sık hareket halindeyken kullanılıyorsa (örneğin, Uber veya Google Haritalar gibi bir şey), kullanıcılarınızın genellikle bir masanın arkasında oturmasından çok daha fazla fayda sağlarsınız. Similarly, if you're focusing on constant interaction (be it video chat, collaborative editing, or gaming), then your worst-case scenarios should improve more than if you have a news website.
Head-of-Line Blocking Removal
The fourth performance feature is intended to make QUIC faster on networks with a high amount of packet loss by mitigating the head-of-line (HoL) blocking problem. While this is true in theory, we will see that in practice this will probably only provide minor benefits for web-page loading performance.
To understand this, though, we first need to take a detour and talk about stream prioritization and multiplexing.
Stream Prioritization
As discussed in part 1, a single TCP packet loss can delay data for multiple in-transit resources because TCP's bytestream abstraction considers all data to be part of a single file. QUIC, on the other hand, is intimately aware that there are multiple concurrent bytestreams and can handle loss on a per-stream basis. However, as we've also seen, these streams are not truly transmitting data in parallel: Rather, the stream data is multiplexed onto a single connection. This multiplexing can happen in many different ways.
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC , where we change the active stream in each packet (let's call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC , where each stream is completed in full before starting the next one (let's call this sequential). Of course, many other options are possible in between these extremes ( AAAABBCAAAAABBC… , AABBCCAABBCC… , ABABABCCCC… , etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I've written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.
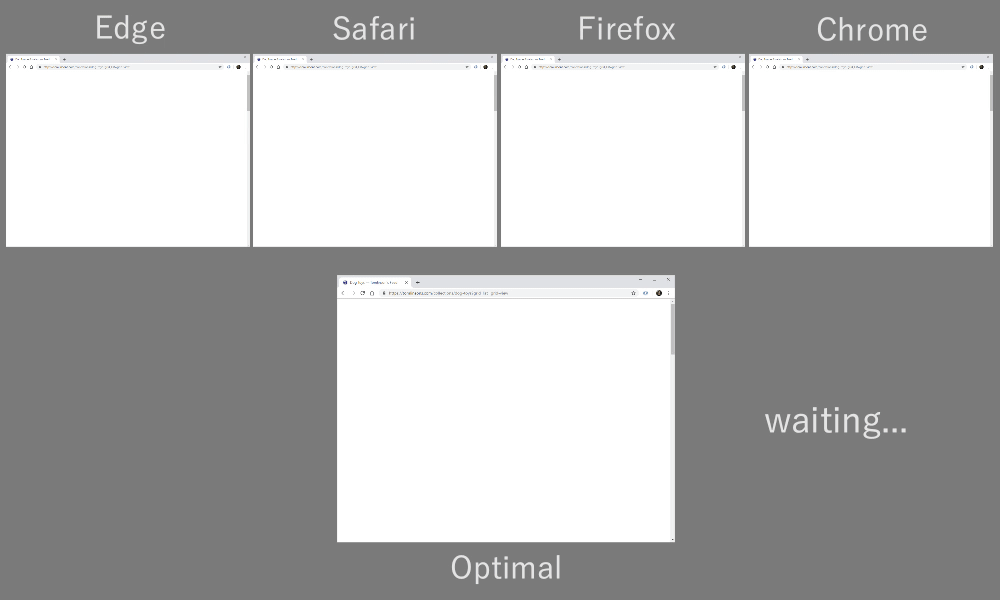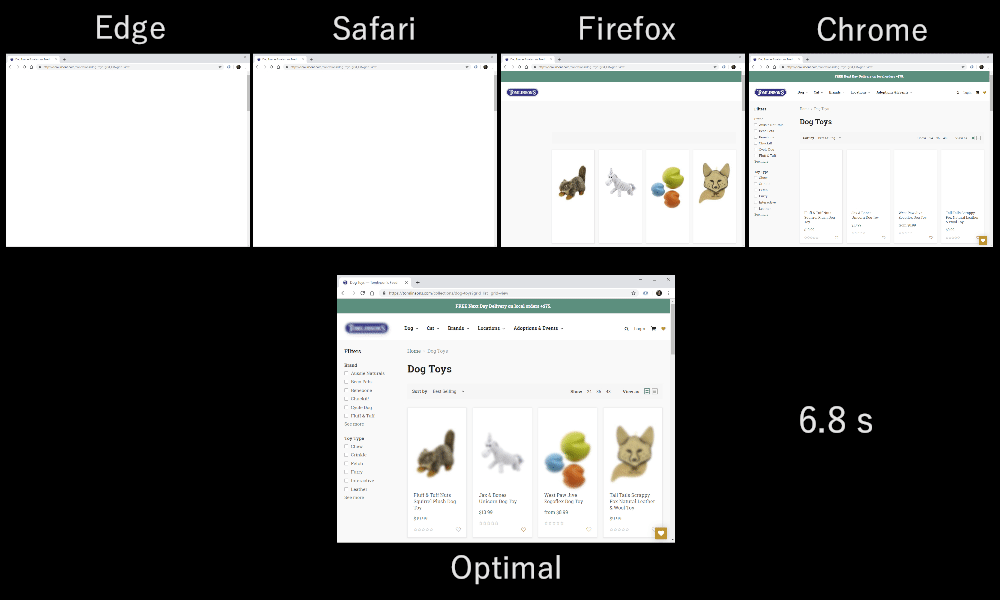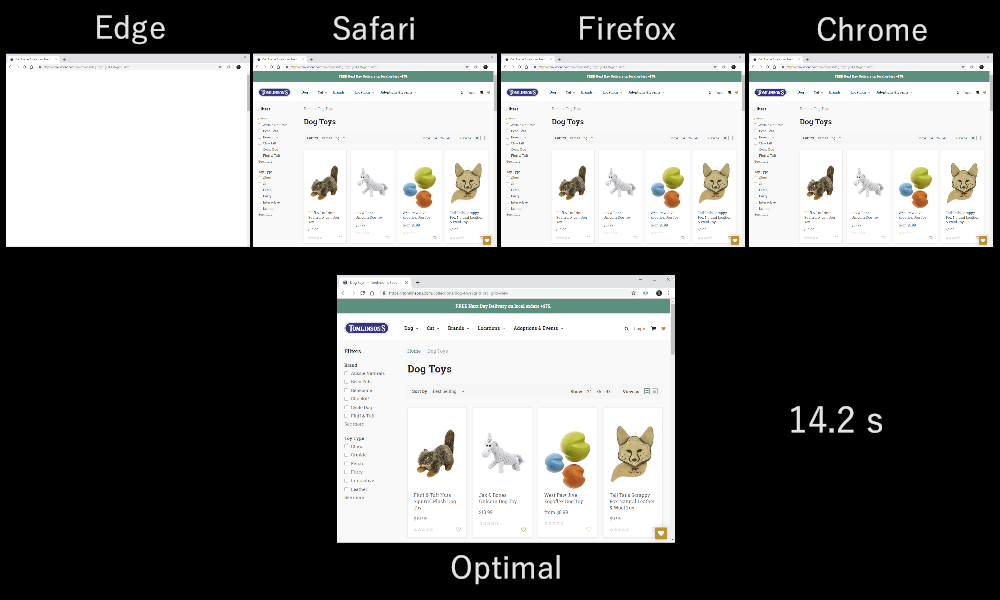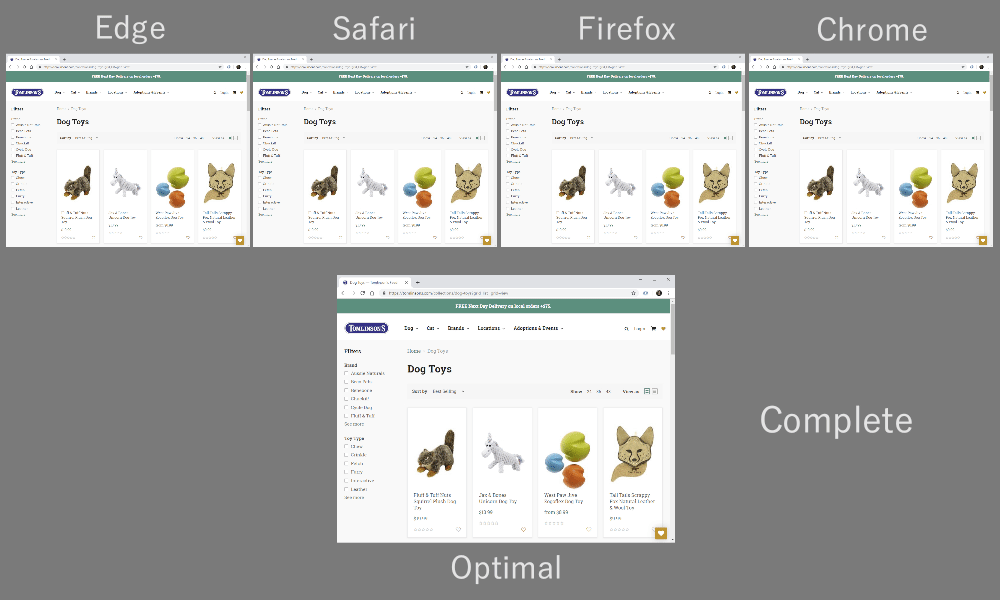
Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).
What's more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let's contemplate what would happen if A, B, and C were all render-blocking resources.
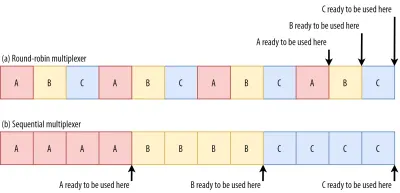
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource's total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C's completion time.
However, that doesn't mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally . In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best . This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren't always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we've just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We'd rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC's HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it's high priority and render-blocking — think main.js ), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A : All of the data is for A , and so everything would still have to wait (we don't have B or C data to process), similar to TCP.

We see that we have a kind of contradiction: Sequential multiplexing ( AAAABBBBCCCC ) is typically better for web performance, but it doesn't allow us to take much advantage of QUIC's HoL blocking removal. Round-robin multiplexing ( ABCABCABCABC ) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another .
And it gets worse. Up until now, we've sort of assumed that individual packets get lost one at a time. However, this isn't always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time .
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that's intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don't lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let's say we are using a per-packet round-robin multiplexer ( ABCABCABCABCABCABCABCABC… ) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC's HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions .
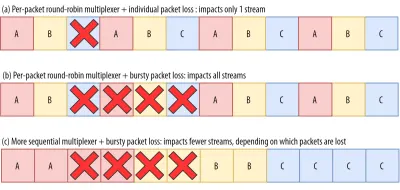
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC's HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don't send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don't keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don't necessarily lower its burstiness.
Tüm bunların anlamı ne?
While QUIC's HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users . However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
UDP ve TLS Performansı
QUIC ve HTTP/3'ün beşinci performans yönü, ağ üzerinde gerçekte ne kadar verimli ve performanslı paket oluşturup gönderebilecekleri ile ilgilidir. QUIC'in UDP ve ağır şifreleme kullanımının, onu TCP'den biraz daha yavaş hale getirebileceğini göreceğiz (ancak işler gelişiyor).
İlk olarak, QUIC'in UDP kullanımının performanstan çok esneklik ve konuşlandırılabilirlik ile ilgili olduğunu zaten tartışmıştık. Bu, yakın zamana kadar UDP üzerinden QUIC paketleri göndermenin TCP paketleri göndermekten çok daha yavaş olması gerçeğiyle daha da fazla kanıtlanmıştır. Bunun nedeni kısmen bu protokollerin tipik olarak nerede ve nasıl uygulandığıdır (aşağıdaki şekil 9'a bakın).
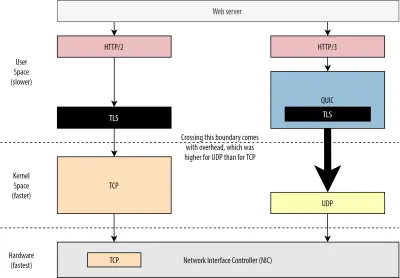
Yukarıda tartışıldığı gibi, TCP ve UDP tipik olarak doğrudan işletim sisteminin hızlı çekirdeğinde uygulanır. Buna karşılık, TLS ve QUIC uygulamaları çoğunlukla daha yavaş kullanıcı alanındadır (bunun QUIC için gerçekten gerekli olmadığını unutmayın - çoğunlukla yapılır çünkü çok daha esnektir). Bu, QUIC'i zaten TCP'den biraz daha yavaş yapar.
Ek olarak, kullanıcı alanı yazılımımızdan (örneğin tarayıcılar ve web sunucuları) veri gönderirken, bu verileri işletim sistemi çekirdeğine geçirmemiz gerekir, bu da daha sonra ağa yerleştirmek için TCP veya UDP kullanır. Bu verilerin iletilmesi, API çağrısı başına belirli bir miktarda ek yük içeren çekirdek API'leri (sistem çağrıları) kullanılarak yapılır. TCP için bu genel giderler UDP'den çok daha düşüktü.
Bunun nedeni, tarihsel olarak TCP'nin UDP'den çok daha fazla kullanılmış olmasıdır. Bu nedenle, zaman içinde, paket gönderme ve alma genel giderlerini en aza indirmek için TCP uygulamalarına ve çekirdek API'lerine birçok optimizasyon eklendi. Çoğu ağ arabirim denetleyicisi (NIC), TCP için yerleşik donanım boşaltma özelliklerine bile sahiptir. Ancak UDP o kadar şanslı değildi çünkü daha sınırlı kullanımı ek optimizasyonlara yapılan yatırımı haklı çıkarmadı. Son beş yılda bu durum şans eseri değişti ve çoğu işletim sistemi o zamandan beri UDP için optimize edilmiş seçenekler ekledi .
İkincisi, QUIC'in çok fazla ek yükü vardır çünkü her paketi ayrı ayrı şifreler . Bu, TCP üzerinden TLS kullanmaktan daha yavaştır, çünkü orada paketleri parçalar halinde şifreleyebilirsiniz (bir seferde yaklaşık 16 KB veya 11 pakete kadar), bu da daha verimlidir. Bu, QUIC'de yapılan bilinçli bir takastı çünkü toplu şifreleme, kendi HoL engelleme biçimlerine yol açabilir.
UDP'yi (ve dolayısıyla QUIC'yi) daha hızlı hale getirmek için ekstra API'ler ekleyebildiğimiz ilk noktadan farklı olarak, burada QUIC, TCP + TLS'ye karşı her zaman doğal bir dezavantaja sahip olacaktır. Bununla birlikte, örneğin optimize edilmiş şifreleme kitaplıkları ve QUIC paket başlıklarının toplu olarak şifrelenmesine izin veren akıllı yöntemlerle pratikte bu da oldukça yönetilebilir.
Sonuç olarak, Google'ın en eski QUIC sürümleri hala TCP + TLS'den iki kat daha yavaş olsa da, o zamandan beri işler kesinlikle iyileşti. Örneğin, son testlerde, Microsoft'un yoğun şekilde optimize edilmiş QUIC yığını, aynı sistemdeki TCP + TLS için 11.85 Gbps ile karşılaştırıldığında 7.85 Gbps elde edebildi (yani burada, QUIC, TCP + TLS kadar hızlıdır).
Bu, UDP'yi daha hızlı hale getiren en son Windows güncellemeleriyle ilgilidir (tam bir karşılaştırma için, bu sistemdeki UDP verimi 19,5 Gb/sn idi). Google'ın QUIC yığınının en optimize edilmiş sürümü şu anda TCP + TLS'den yaklaşık %20 daha yavaştır. Fastly'nin daha az gelişmiş bir sistemde ve birkaç hileyle daha önceki testleri, kullanım durumuna bağlı olarak QUIC'in kesinlikle TCP ile rekabet edebileceğini göstererek eşit performans (yaklaşık 450 Mbps) iddia ediyor.
Ancak, QUIC, TCP + TLS'den iki kat daha yavaş olsa bile, o kadar da kötü değil. İlk olarak, QUIC ve TCP + TLS işleme genellikle bir sunucuda gerçekleşen en ağır şey değildir, çünkü diğer mantığın da (örneğin, HTTP, önbelleğe alma, proxy oluşturma, vb.) yürütülmesi gerekir. Bu nedenle, QUIC'i çalıştırmak için aslında iki kat daha fazla sunucuya ihtiyacınız olmayacak (gerçek bir veri merkezinde ne kadar etkisi olacağı biraz belirsiz, çünkü büyük şirketlerin hiçbiri bu konuda veri yayınlamadı).
İkincisi, gelecekte QUIC uygulamalarını optimize etmek için hala birçok fırsat var. Örneğin, zamanla, bazı QUIC uygulamaları (kısmen) işletim sistemi çekirdeğine (tıpkı TCP gibi) geçer veya onu atlar (bazıları MsQuic ve Quant gibi zaten yapar). QUIC'e özel donanımın da kullanıma sunulmasını bekleyebiliriz.
Yine de, TCP + TLS'nin tercih edilen seçenek olarak kalacağı bazı kullanım durumları olacaktır. Örneğin, Netflix, videolarını TCP + TLS üzerinden yayınlamak için özel FreeBSD kurulumlarına yoğun bir şekilde yatırım yaptığından, muhtemelen yakın zamanda QUIC'e geçmeyeceğini belirtti.
Benzer şekilde, Facebook, QUIC'in büyük olasılıkla daha büyük ek yükü nedeniyle veri merkezleri veya uç düğümler ve kaynak sunucular arasında değil, son kullanıcılar ve CDN'nin kenarı arasında kullanılacağını söyledi. Genel olarak, çok yüksek bant genişliğine sahip senaryolar, özellikle önümüzdeki birkaç yıl içinde muhtemelen TCP + TLS'yi desteklemeye devam edecek.
Biliyor musun?
Ağ yığınlarını optimize etmek, yukarıdakilerin yalnızca yüzeyi çizdiği (ve birçok nüansı kaçırdığı) derin ve teknik bir tavşan deliğidir. Yeterince cesursanız veyaGRO/GSO,SO_TXTIME, kernel bypass vesendmmsg()verecvmmsg()gibi terimlerin ne anlama geldiğini bilmek istiyorsanız, Cloudflare ve Fastly ile QUIC'i optimize etme konusunda bazı mükemmel makaleler önerebilirim. Microsoft tarafından kapsamlı bir kod kılavuzu ve Cisco'dan derinlemesine bir konuşma olarak. Son olarak, bir Google mühendisi, QUIC uygulamalarını zaman içinde optimize etme konusunda çok ilginç bir açılış konuşması yaptı.
Tüm bunların anlamı ne?
QUIC'in UDP ve TLS protokollerini özel kullanımı, geçmişte onu TCP + TLS'den çok daha yavaş hale getirdi. Bununla birlikte, zaman içinde, aradaki farkı bir şekilde kapatan çeşitli iyileştirmeler yapıldı (ve uygulanmaya devam edecek). Yine de, web sayfası yüklemenin tipik kullanım durumlarında bu tutarsızlıkları muhtemelen fark etmeyeceksiniz, ancak büyük sunucu çiftlikleri kullanıyorsanız, bunlar size baş ağrısına neden olabilir.
HTTP/3 Özellikleri
Şimdiye kadar, ağırlıklı olarak QUIC ve TCP'deki yeni performans özelliklerinden bahsettik. Ancak, HTTP/3'e karşı HTTP/2'ye ne dersiniz? Bölüm 1'de tartışıldığı gibi, HTTP/3 gerçekten HTTP/2-over-QUIC'dir ve bu nedenle, yeni sürümde gerçek, büyük yeni özellikler sunulmamıştır. Bu, HTTP/1.1'den çok daha büyük olan ve başlık sıkıştırma, akış önceliklendirme ve sunucu gönderme gibi yeni özellikler sunan HTTP/2'ye geçişten farklıdır. Bu özelliklerin tümü hala HTTP/3'te, ancak kaputun altında nasıl uygulandıkları konusunda bazı önemli farklılıklar var.
Bunun nedeni çoğunlukla QUIC'in HoL engellemesini kaldırmasının nasıl çalıştığıdır. Tartıştığımız gibi, B akışındaki bir kayıp, artık A ve C akışlarının TCP üzerinden yaptıkları gibi B'nin yeniden iletimlerini beklemek zorunda kalacağı anlamına gelmez. Bu nedenle, A, B ve C'nin her biri bu sırayla bir QUIC paketi gönderdiyse, verileri tarayıcıya A, C, B olarak teslim edilebilir (ve işlenebilir)! Başka bir deyişle, TCP'nin aksine, QUIC artık farklı akışlarda tam olarak sıralanmamaktadır !
Bu, veri parçalarıyla serpiştirilmiş özel kontrol mesajlarını kullanan birçok özelliğinin tasarımında gerçekten TCP'nin katı sıralamasına dayanan HTTP/2 için bir sorundur. QUIC'de, bu kontrol mesajları herhangi bir sırada gelebilir (ve uygulanabilir), hatta özelliklerin amaçlananın tersini yapmasını bile sağlayabilir! Teknik ayrıntılar yine bu makale için gereksizdir, ancak bu makalenin ilk yarısı size bunun ne kadar aptalca karmaşık olabileceği konusunda bir fikir verecektir.
Bu nedenle, özelliklerin iç mekaniği ve uygulamaları HTTP/3 için değişmek zorunda kaldı. Somut bir örnek, tekrarlanan büyük HTTP başlıklarının (örneğin, tanımlama bilgileri ve kullanıcı aracısı dizeleri) ek yükünü azaltan HTTP başlık sıkıştırmasıdır . HTTP/2'de bu, HPACK kurulumu kullanılarak yapılırken, HTTP/3 için bu, daha karmaşık QPACK'e yeniden çalışıldı. Her iki sistem de aynı özelliği sunar (yani başlık sıkıştırması), ancak oldukça farklı şekillerde. Bu konuyla ilgili bazı mükemmel derin teknik tartışmalar ve diyagramlar Litespeed blogunda bulunabilir.
Akış çoğullama mantığını çalıştıran ve yukarıda kısaca tartıştığımız önceliklendirme özelliği için de benzer bir şey geçerlidir. HTTP/2'de bu, tüm sayfa kaynaklarını ve aralarındaki ilişkileri açıkça modellemeye çalışan karmaşık bir "bağımlılık ağacı" kurulumu kullanılarak uygulandı (daha fazla bilgi "HTTP Kaynak Önceliklendirmesi için Nihai Kılavuz" konuşmasındadır). Bu sistemi doğrudan QUIC üzerinden kullanmak bazı potansiyel olarak çok yanlış ağaç yerleşimlerine yol açacaktır, çünkü her bir kaynağın ağaca eklenmesi ayrı bir kontrol mesajı olacaktır.
Ek olarak, bu yaklaşımın gereksiz yere karmaşık olduğu ortaya çıktı ve birçok sunucuda birçok uygulama hatasına ve verimsizliğe ve düşük performansa yol açtı. Her iki sorun da önceliklendirme sisteminin HTTP/3 için çok daha basit bir şekilde yeniden tasarlanmasına yol açmıştır. Bu daha basit kurulum, bazı gelişmiş senaryoların uygulanmasını zor veya imkansız hale getirir (örneğin, tek bir bağlantıda birden çok istemciden gelen trafiği proxy'ye almak), ancak yine de web sayfası yükleme optimizasyonu için çok çeşitli seçenekler sağlar.
Yine, iki yaklaşım aynı temel özelliği sunarken (akım çoğullamasına rehberlik ediyor), HTTP/3'ün daha kolay kurulumunun daha az uygulama hatasına yol açacağı umulmaktadır.
Son olarak, server push var. Bu özellik, sunucunun önce onlar için açık bir istek beklemeden HTTP yanıtları göndermesini sağlar. Teorik olarak, bu mükemmel performans kazanımları sağlayabilir. Ancak pratikte, doğru ve tutarsız bir şekilde uygulanmasının zor olduğu ortaya çıktı. Sonuç olarak, muhtemelen Google Chrome'dan bile kaldırılacak.
Tüm bunlara rağmen , hala HTTP/3'te bir özellik olarak tanımlanmaktadır (birkaç uygulama bunu desteklemesine rağmen). Dahili işleyişi önceki iki özellik kadar değişmemiş olsa da, QUIC'in deterministik olmayan sıralamasında çalışmak üzere uyarlanmıştır. Ne yazık ki, bu uzun süredir devam eden bazı sorunları çözmek için çok az şey yapacak.
Tüm bunların anlamı ne?
Daha önce de söylediğimiz gibi, HTTP/3'ün potansiyelinin çoğu, HTTP/3'ün kendisinden değil, temeldeki QUIC'den gelir. Protokolün dahili uygulaması HTTP/2'lerden çok farklı olsa da, üst düzey performans özellikleri ve bunların nasıl kullanılabileceği ve kullanılması gerektiği aynı kaldı.
Dikkat Edilmesi Gereken Gelecekteki Gelişmeler
Bu seride, daha hızlı evrim ve daha yüksek esnekliğin QUIC'in (ve buna bağlı olarak HTTP/3) temel yönleri olduğunu düzenli olarak vurguladım. Bu nedenle, insanların halihazırda protokollerin yeni uzantıları ve uygulamaları üzerinde çalışıyor olmaları şaşırtıcı olmamalıdır. Aşağıda, muhtemelen ileride bir yerde karşılaşacağınız başlıca olanlar listelenmiştir:
İleri hata düzeltme
Bu tekniğin bu amacı, yine QUIC'in paket kaybına karşı direncini arttırmaktır . Bunu, verilerin yedek kopyalarını göndererek yapar (akıllıca kodlanmış ve o kadar büyük olmayacak şekilde sıkıştırılmış olsa da). Ardından, bir paket kaybolursa ancak fazla veri gelirse, artık yeniden iletime gerek yoktur.
Bu, başlangıçta Google QUIC'in bir parçasıydı (ve insanların QUIC'in paket kaybına karşı iyi olduğunu söylemelerinin nedenlerinden biri), ancak performans etkisi henüz kanıtlanmadığından standartlaştırılmış QUIC sürüm 1'e dahil edilmedi. Bununla birlikte, araştırmacılar şimdi onunla aktif deneyler yapıyorlar ve PQUIC-FEC İndirme Deneyleri uygulamasını kullanarak onlara yardımcı olabilirsiniz.Çok Yollu HIZLI
Daha önce bağlantı geçişini ve örneğin Wi-Fi'den hücresele geçerken nasıl yardımcı olabileceğini tartışmıştık. Ancak bu , aynı anda hem Wi-Fi hem de hücresel kullanabileceğimiz anlamına gelmiyor mu? Her iki ağı aynı anda kullanmak bize daha fazla kullanılabilir bant genişliği ve daha fazla sağlamlık sağlayacaktır! Çoklu yolun arkasındaki ana kavram budur.
Bu, yine, Google'ın denediği ancak doğal karmaşıklığı nedeniyle QUIC sürüm 1'e girmediği bir şeydir. Bununla birlikte, araştırmacılar o zamandan beri yüksek potansiyelini gösterdiler ve QUIC sürüm 2'ye dönüştürebilir. TCP çoklu yolunun da mevcut olduğunu, ancak pratik olarak kullanılabilir hale gelmesinin neredeyse on yıl sürdüğünü unutmayın.QUIC ve HTTP/3 üzerinden güvenilmez veriler
Gördüğümüz gibi, QUIC tamamen güvenilir bir protokoldür. Ancak, güvenilmez olan UDP üzerinden çalıştığı için, QUIC'e güvenilmez verileri de göndermek için bir özellik ekleyebiliriz. Bu, önerilen datagram uzantısında özetlenmiştir. Elbette bunu web sayfası kaynaklarını göndermek için kullanmak istemezsiniz, ancak oyun oynama ve canlı video akışı gibi şeyler için kullanışlı olabilir. Bu şekilde, kullanıcılar UDP'nin tüm avantajlarından ancak QUIC düzeyinde şifreleme ve (isteğe bağlı) tıkanıklık kontrolü elde edebilirler.WebTaşıma
Tarayıcılar, özellikle güvenlik endişeleri nedeniyle, TCP veya UDP'yi doğrudan JavaScript'e maruz bırakmaz. Bunun yerine, Fetch gibi HTTP düzeyinde API'lere ve biraz daha esnek WebSocket ve WebRTC protokollerine güvenmek zorundayız. Bu seçenekler serisindeki en yenisi, esas olarak HTTP/3'ü (ve buna bağlı olarak QUIC'i) daha düşük seviyeli bir şekilde kullanmanıza izin veren WebTransport'tur (gerçi gerekirse TCP ve HTTP/2'ye geri dönebilir). ).
En önemlisi, HTTP/3 üzerinden güvenilmez verileri kullanma yeteneğini içerecek (önceki noktaya bakın), bu da oyun oynama gibi şeylerin tarayıcıda uygulanmasını biraz daha kolaylaştırmalıdır. Normal (JSON) API çağrıları için, elbette, mümkün olduğunda otomatik olarak HTTP/3'ü de kullanacak olan Fetch'i kullanmaya devam edeceksiniz. WebTransport şu anda hala yoğun bir tartışma altında, bu nedenle sonunda neye benzeyeceği henüz belli değil. Tarayıcılardan yalnızca Chromium, şu anda herkese açık bir kavram kanıtı uygulaması üzerinde çalışıyor.DASH ve HLS video akışı
Canlı olmayan video için (YouTube ve Netflix'i düşünün), tarayıcılar genellikle HTTP üzerinden Dinamik Uyarlamalı Akış (DASH) veya HTTP Canlı Akış (HLS) protokollerini kullanır. Her ikisi de temel olarak videolarınızı daha küçük parçalara (2 ila 10 saniye) ve farklı kalite seviyelerine (720p, 1080p, 4K, vb.) kodlamanız anlamına gelir.
Çalışma zamanında, tarayıcı ağınızın kaldırabileceği en yüksek kaliteyi (veya belirli bir kullanım durumu için en uygun olanı) tahmin eder ve HTTP aracılığıyla sunucudan ilgili dosyaları ister. Tarayıcının TCP yığınına doğrudan erişimi olmadığından (genellikle çekirdekte uygulandığı gibi), bazen bu tahminlerde birkaç hata yapar veya değişen ağ koşullarına tepki vermesi biraz zaman alır (video duraklarına yol açar) .
QUIC tarayıcının bir parçası olarak uygulandığından, akış tahmincilerine düşük seviyeli protokol bilgilerine (kayıp oranları, bant genişliği tahminleri vb.) erişim verilerek bu biraz geliştirilebilir. Diğer araştırmacılar, bazı umut verici sonuçlarla birlikte video akışı için güvenilir ve güvenilmez verileri karıştırmayı deniyorlar.HTTP/3 dışındaki protokoller
QUIC genel amaçlı bir aktarım protokolü olduğundan, artık TCP üzerinden çalışan birçok uygulama katmanı protokolünün de QUIC'in üzerinde çalıştırılmasını bekleyebiliriz. Devam eden bazı çalışmalar arasında QUIC üzerinden DNS, QUIC üzerinden SMB ve hatta QUIC üzerinden SSH yer alıyor. Bu protokollerin tipik olarak HTTP ve web sayfası yüklemesinden çok farklı gereksinimleri olduğundan, QUIC'in tartıştığımız performans iyileştirmeleri bu protokoller için çok daha iyi sonuç verebilir.
Tüm bunların anlamı ne?
QUIC sürüm 1 sadece başlangıçtır . Google'ın daha önce denediği birçok gelişmiş performans odaklı özellik, bu ilk yinelemeye dahil olmadı. Ancak amaç, protokolü hızlı bir şekilde geliştirmek, yeni uzantıları ve özellikleri yüksek frekansta sunmaktır. Bu nedenle, zamanla QUIC (ve HTTP/3), TCP'den (ve HTTP/2) açıkça daha hızlı ve daha esnek hale gelmelidir.
Çözüm
Serinin bu ikinci bölümünde , HTTP/3'ün ve özellikle QUIC'in birçok farklı performans özelliğini ve yönünü tartıştık. Bu özelliklerin çoğu çok etkili görünse de, pratikte, düşündüğümüz web sayfası yükleme kullanım durumunda ortalama bir kullanıcı için o kadar fazla bir şey yapmayabileceğini gördük.
Örneğin, QUIC'in UDP kullanmasının, aniden TCP'den daha fazla bant genişliği kullanabileceği veya kaynaklarınızı daha hızlı indirebileceği anlamına gelmediğini gördük. Sıklıkla övülen 0-RTT özelliği, yaklaşık 5 KB (en kötü durumda) gönderebileceğiniz bir gidiş-dönüşten tasarruf etmenizi sağlayan gerçekten bir mikro optimizasyondur.
Ani paket kaybı varsa veya oluşturmayı engelleyen kaynakları yüklerken HoL engellemenin kaldırılması iyi çalışmaz. Bağlantı geçişi son derece durumsaldır ve HTTP/3, onu HTTP/2'den daha hızlı hale getirebilecek önemli yeni özelliklere sahip değildir.
Bu nedenle, HTTP/3 ve QUIC'i atlamanızı önermemi bekleyebilirsiniz. Neden rahatsız, değil mi? Ancak kesinlikle böyle bir şey yapmayacağım! Bu yeni protokoller, hızlı (kentsel) ağlardaki kullanıcılara pek yardımcı olmasa da, yeni özellikler kesinlikle son derece mobil kullanıcılar ve yavaş ağlardaki insanlar için oldukça etkili olma potansiyeline sahiptir.
Genellikle hızlı cihazlarımızın ve yüksek hızlı hücresel ağlara erişimimizin olduğu benim Belçika gibi Batı pazarlarında bile, bu durumlar ürününüze bağlı olarak kullanıcı tabanınızın %1 ila %10'unu etkileyebilir. Bir örnek, bir trende web sitenizdeki kritik bir bilgiyi umutsuzca aramaya çalışan, ancak yüklenmesi için 45 saniye beklemek zorunda kalan bir kişidir. Bu durumda olduğumu kesinlikle biliyorum, birinin beni bundan kurtarmak için QUIC'i kullanmasını diledim.
Ancak, işlerin hala çok daha kötü olduğu başka ülkeler ve bölgeler de var. Orada, ortalama bir kullanıcı Belçika'daki en yavaş %10 gibi görünebilir ve en yavaş %1 hiç bir zaman yüklü bir sayfa göremeyebilir. Dünyanın birçok yerinde web performansı bir erişilebilirlik ve kapsayıcılık sorunudur.
Bu nedenle, sayfalarımızı asla kendi donanımımızda test etmemeliyiz (aynı zamanda Webpagetest gibi bir hizmet kullanmamalıyız) ve ayrıca bu nedenle kesinlikle QUIC ve HTTP/3 dağıtmalısınız . Özellikle kullanıcılarınız sık sık hareket halindeyse veya hızlı hücresel ağlara erişimleri pek mümkün değilse, kablolu MacBook Pro'nuzda pek bir şey fark etmeseniz bile bu yeni protokoller büyük farklar yaratabilir. Daha fazla ayrıntı için Fastly'nin konuyla ilgili gönderisini şiddetle tavsiye ederim.
Bu sizi tam olarak ikna etmezse, QUIC ve HTTP/3'ün önümüzdeki yıllarda gelişmeye ve hızlanmaya devam edeceğini düşünün. Protokollerle ilgili bazı erken deneyimler elde etmek, yolun sonunda size fayda sağlayacak ve yeni özelliklerin avantajlarından mümkün olan en kısa sürede yararlanmanıza olanak tanıyacaktır. Ek olarak, QUIC, arka planda her yerde tüm kullanıcılara fayda sağlayan en iyi güvenlik ve gizlilik uygulamalarını zorunlu kılar.
Sonunda ikna oldun mu? Ardından, yeni protokolleri pratikte nasıl kullanabileceğinizi okumak için serinin 3. bölümüne geçin.
- Bölüm 1: HTTP/3 Tarihçesi ve Temel Kavramlar
Bu makale, genel olarak HTTP/3 ve protokollerde yeni olan kişilere yöneliktir ve temel olarak temelleri tartışır. - Bölüm 2: HTTP/3 Performans Özellikleri
Bu daha ayrıntılı ve teknik. Temel bilgileri zaten bilenler buradan başlayabilir. - Bölüm 3: Pratik HTTP/3 Dağıtım Seçenekleri
Dizideki bu üçüncü makale, HTTP/3'ü kendiniz dağıtmanın ve test etmenin zorluklarını açıklıyor. Web sayfalarınızı ve kaynaklarınızı nasıl ve değiştirmeniz gerekip gerekmediğini ayrıntılarıyla anlatır.