
Makine Öğreniminde Sınıflandırma Nasıl Uygulanır?
Yayınlanan: 2021-03-12Makine Öğreniminin çeşitli alanlarda uygulanması son birkaç yılda büyük bir hızla arttı ve artmaya devam ediyor. Makine Öğrenimi modelinin en popüler görevlerinden biri, nesneleri tanımak ve onları belirlenmiş sınıflarına ayırmaktır.
Bu, Makine Öğreniminin en popüler uygulamalarından biri olan Sınıflandırma yöntemidir. Sınıflandırma, büyük miktarda veriyi 0/1, Evet/Hayır gibi ikili veya hayvanlar, arabalar, kuşlar vb. gibi çok sınıflı olabilecek bir dizi ayrık değere ayırmak için kullanılır.
Aşağıdaki makalede, Makine Öğreniminde Sınıflandırma kavramını, ilgili Veri türlerini anlayacağız ve çeşitli verileri sınıflandırmak için Makine Öğreniminde kullanılan en popüler Sınıflandırma algoritmalarından bazılarını göreceğiz.
İçindekiler
Denetimli Öğrenme nedir?
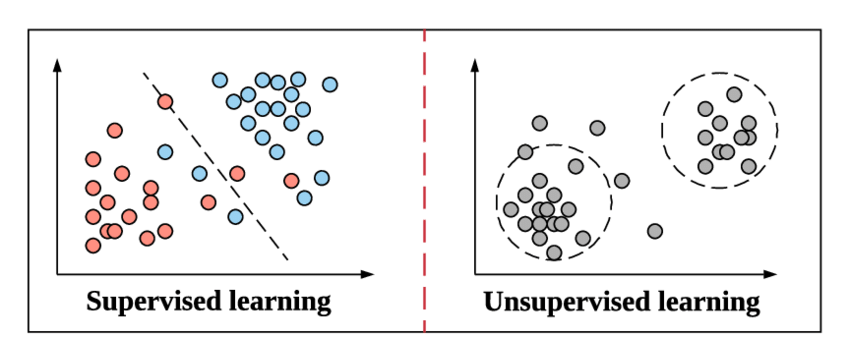
Sınıflandırma kavramına ve türlerine dalmaya hazırlanırken, Denetimli Öğrenmenin ne anlama geldiği ve bunun Makine Öğreniminde Denetimsiz Öğrenmenin diğer yönteminden nasıl farklı olduğu konusunda kendimizi hızla yenileyelim.
Bunu Lisedeki Fizik dersimizden basit bir örnek alarak anlayalım. Yeni bir yöntemi içeren basit bir problem olduğunu varsayalım. Aynı yöntemle çözmemiz gereken bir soru sorulsa, hepimiz aynı yöntemle örnek bir probleme atıfta bulunup onu çözmeye çalışmaz mıyız? Bu yöntemden emin olduğumuzda, ona tekrar başvurmamıza ve çözmeye devam etmemize gerek yoktur.
Kaynak

Bu, Denetimli Öğrenmenin Makine Öğreniminde çalışmasıyla aynıdır. Örnek olarak öğrenir. Bunu daha da basitleştirmek için, Denetimli Öğrenmede, tüm veriler ilgili etiketlerle beslenir ve bu nedenle eğitim süreci sırasında, Makine Öğrenimi modeli, belirli bir veri için çıktısını aynı verinin gerçek çıktısıyla karşılaştırır ve çalışır. hem tahmin edilen hem de gerçek etiket değeri arasındaki hatayı en aza indirin.
Bu makalede inceleyeceğimiz Sınıflandırma Algoritmaları, bu Denetimli Öğrenme yöntemini takip eder - örneğin, İstenmeyen Posta Algılama ve Nesne Tanıma.
Denetimsiz Öğrenme, verilerin etiketleriyle beslenmediği bir yukarıdaki adımdır. Verilerden örüntüler türetmek ve çıktıyı vermek Machine Learning modelinin sorumluluğuna ve verimliliğine bağlıdır. Kümeleme algoritmaları, bu Denetimsiz Öğrenme yöntemini takip eder.
Sınıflandırma nedir?
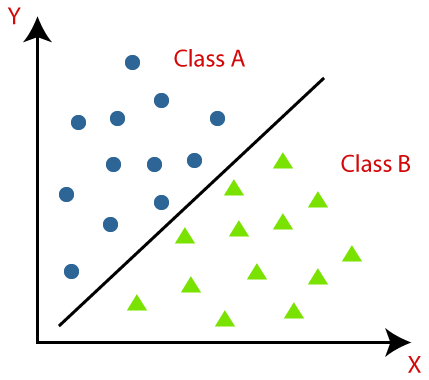
Sınıflandırma, nesneleri veya verileri önceden belirlenmiş sınıflarda tanıma, anlama ve gruplandırma olarak tanımlanır. Makine Öğrenimi modelinin eğitim sürecinden önce verileri kategorilere ayırarak, çeşitli sınıflandırma algoritmalarını kullanarak verileri birkaç sınıfa ayırabiliriz. Regresyondan farklı olarak, bir sınıflandırma problemi, çıktı değişkeninin "Evet" veya "Hayır" veya "Hastalık" veya "Hastalık Yok" gibi bir kategori olması durumudur.
Makine Öğrenimi problemlerinin çoğunda, veri seti programa yüklendikten sonra, eğitimden önce, veri setini eğitim seti ve test setini sabit oranlı olarak (Genellikle %70 eğitim seti ve %30 test seti) bölmek. Bu bölme işlemi, modelin, tahmin edilen değerin hatasını gerçek değere karşı birkaç matematiksel yaklaşımla düzeltmeye çalıştığı geri yayılımı gerçekleştirmesine izin verir.
Benzer şekilde, Sınıflandırmaya başlamadan önce eğitim veri seti oluşturulur. Sınıflandırma algoritması, bir çağ olarak bilinen her yinelemede test veri kümesi üzerinde test yaparken üzerinde eğitime tabi tutulur.
Kaynak
En yaygın Sınıflandırma Algoritmaları uygulamalarından biri, e-postaları "spam" veya "spam olmayan" olup olmadığına göre filtrelemektir. Kısacası, Makine Öğreniminde Sınıflandırmayı, eğitim verilerine uygulanan bu algoritmaların verilerden çeşitli kalıpları (benzer kelimeler veya sayı dizileri, duygular vb.) çıkarmak için kullanıldığı bir "Kalıp Tanıma" biçimi olarak tanımlayabiliriz. .).
Sınıflandırma, belirli bir veri kümesini sınıflara ayırma işlemidir; hem yapılandırılmış hem de yapılandırılmamış veriler üzerinde gerçekleştirilebilir. Verilen veri noktalarının sınıfını tahmin ederek başlar. Bu sınıflara aynı zamanda çıktı değişkenleri, hedef etiketler vb. olarak da atıfta bulunulur. Birkaç algoritma, girdi veri noktası değişkenlerinden çıktı hedef sınıfına eşleme işlevini yaklaşık olarak tahmin etmek için yerleşik matematiksel işlevlere sahiptir. Sınıflandırmanın birincil amacı, yeni verilerin hangi sınıfa/kategoriye gireceğini belirlemektir.
Makine Öğreniminde Sınıflandırma Algoritmaları Türleri
Sınıflandırma Algoritmalarının uygulandığı veri türüne bağlı olarak, Doğrusal ve Doğrusal olmayan modeller olmak üzere iki geniş algoritma kategorisi vardır.
Doğrusal Modeller
- Lojistik regresyon
- Destek Vektör Makineleri (SVM)
Doğrusal Olmayan Modeller
- K-En Yakın Komşular (KNN) Sınıflandırması
- Çekirdek SVM'si
- Saf Bayes Sınıflandırması
- Karar Ağacı Sınıflandırması
- Rastgele Orman Sınıflandırması
Bu yazıda, yukarıda bahsedilen algoritmaların her birinin arkasındaki kavramı kısaca gözden geçireceğiz.
Makine Öğreniminde Sınıflandırma Modelinin Değerlendirilmesi
Bu algoritmaların yukarıda bahsedilen kavramlarına geçmeden önce, bu algoritmaların üzerine inşa edilmiş Makine Öğrenimi modelimizi nasıl değerlendirebileceğimizi anlamalıyız. Modelimizin hem eğitim setinde hem de test setinde doğruluk açısından değerlendirilmesi önemlidir.
Çapraz Entropi Kaybı veya Günlük Kaybı
Bu, çıkışı 0 ile 1 arasında olan bir sınıflandırıcının performansını değerlendirirken kullanacağımız ilk kayıp fonksiyonu türüdür. Bu daha çok İkili Sınıflandırma modelleri için kullanılır. Günlük Kaybı formülü şu şekilde verilir,
Log Kaybı = -((1 – y) * log(1 – yhat) + y * log(yhat))
Burada tahmin edilen değer ve y gerçek değerdir.
karışıklık matrisi
Bir karışıklık matrisi, bir NXN matrisidir; burada N, tahmin edilen sınıfların sayısıdır. Karışıklık matrisi bize çıktı olarak bir matris/tablo sağlar ve modelin performansını tanımlar. Sınıflandırma modelini değerlendirmek için çeşitli performans ölçütlerini türetebileceğimiz bir matris biçimindeki tahmin sonuçlarından oluşur. şeklindedir,
| Gerçek Pozitif | Gerçek Negatif | |
| Öngörülen Pozitif | gerçek pozitif | Yanlış pozitif |
| Öngörülen Negatif | Yanlış Negatif | Gerçek Negatif |
Yukarıdaki tablodan elde edilebilecek performans ölçülerinden birkaçı aşağıda verilmiştir.
1. Doğruluk – toplam doğru tahmin sayısının oranı.
2. Pozitif Tahmin Değeri veya Kesinlik – doğru bir şekilde tanımlanan pozitif vakaların oranı.
3. Negatif Tahmin Değeri – doğru olarak tanımlanan negatif vakaların oranı.
4. Duyarlılık veya Geri Çağırma – doğru bir şekilde tanımlanmış gerçek pozitif vakaların oranı.
5. Özgüllük – doğru bir şekilde tanımlanmış gerçek olumsuz vakaların oranı.
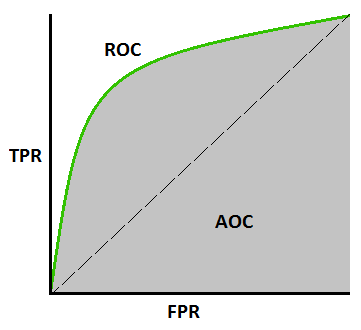
AUC-ROC Eğrisi –
Bu, herhangi bir Makine Öğrenimi modelini değerlendiren bir başka önemli eğri metriğidir. ROC eğrisi, Alıcı Çalışma Karakteristikleri Eğrisi anlamına gelir ve AUC, Eğrinin Altındaki Alan anlamına gelir. ROC eğrisi, TPR ve FPR ile çizilir; burada TPR (Gerçek Pozitif Oran) Y ekseninde ve FPR (Yanlış Pozitif Oran) X eksenindedir. Sınıflandırma modelinin performansını farklı eşiklerde gösterir.
Kaynak
1. Lojistik Regresyon
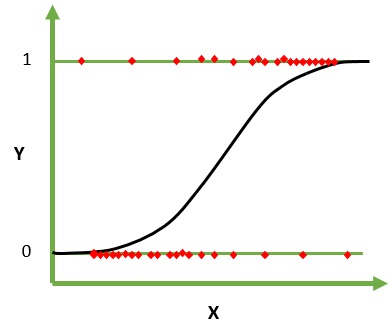
Lojistik Regresyon, Sınıflandırma için bir makine öğrenme algoritmasıdır. Bu algoritmada, tek bir denemenin olası sonuçlarını tanımlayan olasılıklar, bir lojistik fonksiyon kullanılarak modellenir. Girdi değişkenlerinin sayısal olduğunu ve Gauss (çan eğrisi) dağılımına sahip olduğunu varsayar.
Sigmoid fonksiyon olarak da adlandırılan lojistik fonksiyon, başlangıçta istatistikçiler tarafından ekolojideki nüfus artışını tanımlamak için kullanıldı. Sigmoid işlevi, tahmin edilen değerleri olasılıklara eşlemek için kullanılan matematiksel bir işlevdir. Lojistik Regresyon, S şeklinde bir eğriye sahiptir ve 0 ile 1 arasında değerler alabilir, ancak asla tam olarak bu sınırlarda değildir.

Kaynak
Lojistik Regresyon öncelikle Evet/Hayır ve Başarılı/Başarısız gibi ikili bir sonucu tahmin etmek için kullanılır. Bağımsız değişkenler kategorik veya sayısal olabilir, ancak bağımlı değişken her zaman kategoriktir. Lojistik Regresyon formülü şu şekilde verilir:
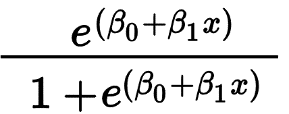
Burada e, 0 ile 1 arasında değerlere sahip S-şekilli eğriyi temsil eder.
2. Destek Vektör Makineleri
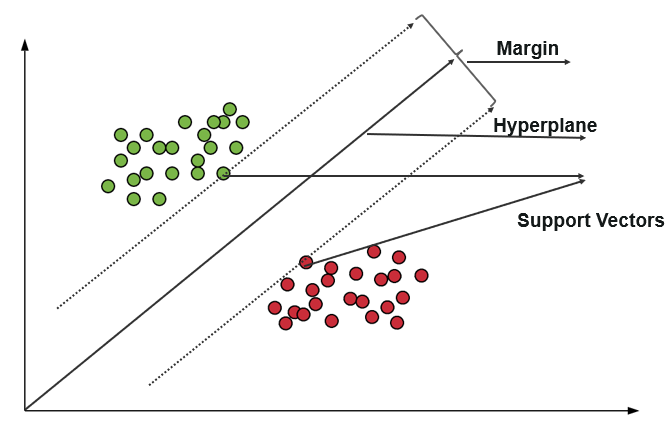
Bir destek vektör makinesi (SVM), verileri polarite dereceleri içinde eğitmek ve sınıflandırmak için algoritmalar kullanır ve onu X/Y tahmininin ötesinde bir dereceye götürür. SVM'de sınıfları ayırmak için kullanılan çizgiye Hiperdüzlem denir. Hiperdüzlemin her iki tarafındaki Hiperdüzlemin Hiperdüzlemine en yakın veri noktaları, sınır çizgisini çizmek için kullanılan Destek Vektörleri olarak adlandırılır.
Sınıflandırmadaki bu Destek Vektör Makinesi, eğitim verilerini, birçok kategorinin Hiperdüzlem kategorilerine ayrıldığı bir uzayda veri noktaları olarak temsil eder. Yeni bir nokta girdiğinde, hangi kategoriye girdiği ve belirli bir uzaya ait olduğu tahmin edilerek sınıflandırılır.
Kaynak
Destek Vektör makinesinin temel amacı, iki Destek Vektörü arasındaki marjı maksimize etmektir.
Kariyerinizi hızlandırmak için Dünyanın en iyi Üniversiteleri - Yüksek Lisanslar, Yönetici Yüksek Lisans Programları ve Makine Öğrenimi ve Yapay Zeka alanında İleri Düzey Sertifika Programından çevrimiçi makine öğrenimi kursuna katılın .
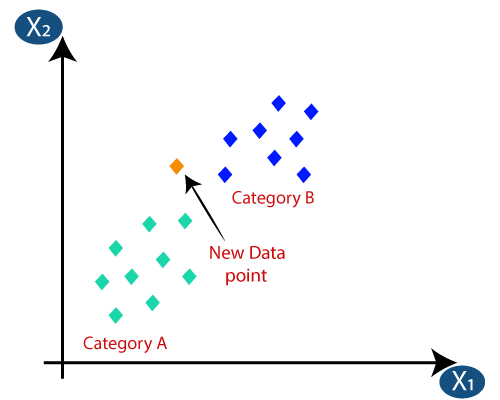
3. K-En Yakın Komşular (KNN) Sınıflandırması
KNN Sınıflandırması, Sınıflandırmanın en basit algoritmalarından biridir, ancak yüksek verimliliği ve kullanım kolaylığı nedeniyle oldukça yaygın olarak kullanılmaktadır. Bu yöntemde, tüm veri kümesi başlangıçta makinede saklanır. Ardından, komşu sayısını temsil eden bir – k değeri seçilir. Bu şekilde, veri kümesine yeni bir veri noktası eklendiğinde, o yeni veri noktasına en yakın k komşu sınıf etiketinin çoğunluk oyu alır. Bu oylama ile en yüksek oyu alan o sınıfa yeni veri noktası eklenir.
Kaynak
4. Çekirdek SVM'si
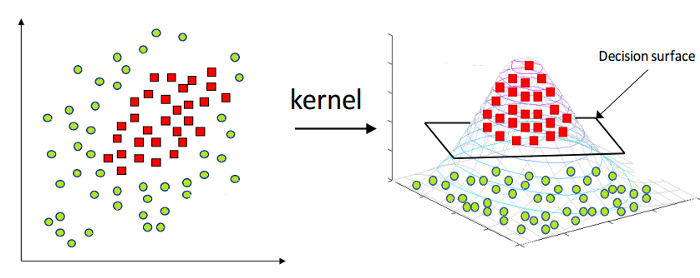
Yukarıda bahsedildiği gibi Lineer Destek Vektör Makinesi doğada sadece lineer verilere uygulanabilir. Ancak, dünyadaki tüm veriler doğrusal olarak ayrılabilir değildir. Bu nedenle, lineer olarak ayrılamayan verileri de hesaba katmak için bir Destek Vektör Makinesi geliştirmemiz gerekiyor. İşte Kernel Support Vector Machine veya Kernel SVM olarak da bilinen Kernel hilesi geliyor.
Kernel SVM'de RBF veya Gaussian Kernel gibi bir çekirdek seçiyoruz. Tüm veri noktaları, lineer olarak ayrılabilir hale geldikleri daha yüksek bir boyuta eşlenir. Bu şekilde, veri setinin farklı sınıfları arasında bir karar sınırı oluşturabiliriz.
Kaynak
Dolayısıyla, bu şekilde, Destek Vektör Makinelerinin temel kavramlarını kullanarak, doğrusal olmayan için bir Çekirdek SVM tasarlayabiliriz.
5. Saf Bayes Sınıflandırması
Naive Bayes Sınıflandırmasının kökleri, veri kümesinin tüm bağımsız değişkenlerinin (özelliklerinin) bağımsız olduğunu varsayarak Bayes Teoremine aittir. Sonucu tahmin etmede eşit öneme sahiptirler. Bayes Teoreminin bu varsayımı, 'Naif' adını verir. İstenmeyen posta filtreleme ve diğer metin sınıflandırma alanları gibi çeşitli görevler için kullanılır. Naive Bayes, bir veri noktasının belirli bir kategoriye girip girmeme olasılığını hesaplar.
Naive Bayes Sınıflandırmasının formülü şu şekilde verilir:
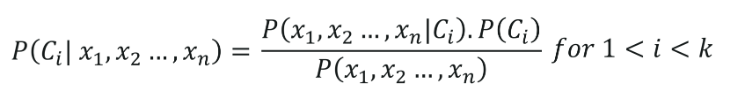
6. Karar Ağacı Sınıflandırması
Karar ağacı, sınıfları kesin bir düzeyde sıralayabildiğinden, sınıflandırma problemleri için mükemmel olan denetimli bir öğrenme algoritmasıdır. Her seviyedeki veri noktalarını ayırdığı bir akış şeması şeklinde çalışır. Son yapı, düğümleri ve yaprakları olan bir ağaca benziyor.

Kaynak
Bir karar düğümünün iki veya daha fazla dalı olacaktır ve yaprak bir sınıflandırma veya kararı temsil eder. Yukarıdaki Karar Ağacı örneğinde, birkaç soru sorarak, pazara gidip gitmeyeceğimizi tahmin etme gibi basit bir sorunu çözmemize yardımcı olan bir akış şeması oluşturulur.
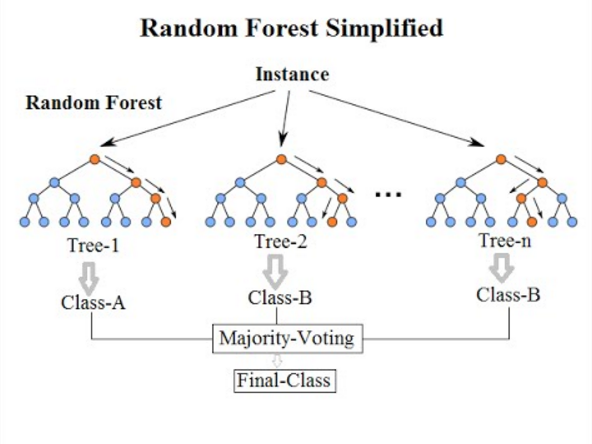
7. Rastgele Orman Sınıflandırması
Bu listenin son Sınıflandırma Algoritmasına gelince, Rastgele Orman, Karar Ağacı Algoritmasının yalnızca bir uzantısıdır. Rastgele Orman, birden fazla Karar Ağacı içeren bir topluluk öğrenme yöntemidir. Karar Ağaçları ile aynı şekilde çalışır.
Kaynak
Rastgele Orman Algoritması, büyük bir “ fazla uyum ” sorunu yaşayan mevcut Karar Ağacı Algoritmasına yönelik bir ilerlemedir. Ayrıca Karar Ağacı Algoritmasına kıyasla daha hızlı ve daha doğru olduğu düşünülmektedir.
Ayrıca Okuyun: Makine Öğrenimi Proje Fikirleri ve Konuları
Çözüm
Bu nedenle, Sınıflandırma için Makine Öğrenimi Yöntemleri hakkındaki bu makalede, Sınıflandırma ve Denetimli Öğrenmenin temellerini, Sınıflandırma modellerinin Türleri ve Değerlendirme metriklerini ve son olarak da en yaygın olarak kullanılan Sınıflandırma modellerinin tümünün bir özetini anladık Makine Öğrenimi.
Makine öğrenimi hakkında daha fazla bilgi edinmek istiyorsanız, çalışan profesyoneller için tasarlanmış ve 450+ saat zorlu eğitim, 30'dan fazla vaka çalışması ve ödev, IIIT sunan IIIT-B & upGrad'ın Makine Öğrenimi ve Yapay Zeka alanında Yönetici PG Programına göz atın. -B Mezunu statüsü, 5'ten fazla pratik uygulamalı bitirme projesi ve en iyi firmalarla iş yardımı.
S1. Makine öğreniminde en çok hangi algoritmalar kullanılır?
Makine öğrenimi, genel olarak üç ana türde sınıflandırılabilen birçok farklı algoritma kullanır: denetimli öğrenme algoritmaları, denetimsiz öğrenme algoritmaları ve pekiştirmeli öğrenme algoritmaları. Şimdi, en sık kullanılan algoritmalardan bazılarını daraltmak ve adlandırmak için, bunlardan bahsedilmesi gerekenler lineer regresyon, lojistik regresyon, SVM, karar ağaçları, rastgele orman algoritması, kNN, Naive Bayes teorisi, K-Ortalamalar, boyutsallık indirgeme, ve gradyan artırma algoritmaları. XGBoost, GBM, LightGBM ve CatBoost algoritmaları, gradyan artırma algoritmalarında özel olarak anılmayı hak ediyor. Bu algoritmalar hemen hemen her türlü veri problemini çözmek için uygulanabilir.
S2. Makine öğreniminde sınıflandırma ve regresyon nedir?
Hem sınıflandırma hem de regresyon algoritmaları, makine öğreniminde yaygın olarak kullanılmaktadır. Bununla birlikte, aralarında nihai olarak kullanımlarını veya amaçlarını belirleyen birçok fark vardır. Temel fark, sınıflandırma algoritmaları erkek-kadın veya doğru-yanlış gibi kesikli değerleri sınıflandırmak veya tahmin etmek için kullanılırken, regresyon algoritmaları maaş, yaş, fiyat vb. gibi kesikli olmayan, sürekli değerleri tahmin etmek için kullanılır. Karar ağaçları, Rastgele orman, Çekirdek SVM ve lojistik regresyon, en yaygın sınıflandırma algoritmalarından bazılarıdır; basit ve çoklu doğrusal regresyon, destek vektörü regresyonu, polinom regresyonu ve karar ağacı regresyonu, makine öğreniminde kullanılan en popüler regresyon algoritmalarından bazılarıdır.
S3. Makine öğrenimini öğrenmenin ön koşulları nelerdir?
Makine öğrenimine başlamak için yetkin bir matematikçi veya uzman programcı olmanıza gerek yoktur. Ancak, alanın genişliği göz önüne alındığında, makine öğrenimi yolculuğunuza başlamak üzereyken göz korkutucu gelebilir. Bu gibi durumlarda, ön koşulları bilmek, sorunsuz bir başlangıç yapmanıza yardımcı olabilir. Ön koşullar, makine öğrenimi kavramlarını anlamak için edinmeniz gereken temel becerilerdir. Bu yüzden her şeyden önce Python kullanarak nasıl kod yazılacağını öğrendiğinizden emin olun. Daha sonra, temel bir istatistik ve matematik anlayışı, özellikle lineer cebir ve çok değişkenli hesap, ek bir avantaj olacaktır.